
(ebook) Natural Language Processing
14
Page 1 Natural Language Processing in Biology Jeffrey Chang Russ Altman BMI 214 Literature in Biomedicine • Much literature generated quickly. – 11 million citations in MEDLINE. – 400,000 added yearly. • Need methods to deal with data. – Query – Summarize – Organize – Understand PubMed PubMed Central Two General Approaches 1. Statistical Natural Language Processing • Look at documents as a collection of words • Base analysis on the statistics of word occurrences, neighbors • Do not try to understand all sentence details. 2. Grammar-based, parsing techniques • Look at structure of sentences (or more) • Identify parts-of-speech (POS) • Develop deep model of what is said. Statistical methods have been applied mostly in biology, but fusion may be best… • Corpus (C, with N documents) Collection of documents. • Term Frequency (tf) Number of times a word appears in a document. • Document Frequency (df) Number of documents a word appears in. • Collection Frequency (cf) Total number of times a word appears in a corpus. Definitions
-
Upload
saeidmirkamali -
Category
Documents
-
view
739 -
download
6
Transcript of (ebook) Natural Language Processing

Page 1
Natural Language Processingin Biology
Jeffrey Chang Russ Altman
BMI 214
Literature in Biomedicine
• Much literature generated quickly.
– 11 million citations in MEDLINE.– 400,000 added yearly.
• Need methods to deal with data.
– Query– Summarize– Organize– Understand
PubMed PubMed Central
Two General Approaches1. Statistical Natural Language Processing
• Look at documents as a collection of words• Base analysis on the statistics of word occurrences,
neighbors• Do not try to understand all sentence details.
2. Grammar-based, parsing techniques• Look at structure of sentences (or more)• Identify parts-of-speech (POS)• Develop deep model of what is said.
Statistical methods have been applied mostly in biology, but fusion may be best…
• Corpus (C, with N documents)Collection of documents.
• Term Frequency (tf)Number of times a word appears in a document.
• Document Frequency (df)Number of documents a word appears in.
• Collection Frequency (cf)Total number of times a word appears in a corpus.
Definitions

Page 2
A document is summarized as a vector of word counts.Each dimension contains the number of times a word appears.
acid 2amino 2analysis 1comparison 1control 1environments 2[…]our 1
”Our analysis includes comparison of amino acid environments with random control environments as well as with each of the other amino acid environments.”
Documents as Vectors Comparing Two Documents
(Manning & Schuetze)
Vector Cosine
Cosine of angle betweentwo vectors.
Weighting the “important” words
Use Term Frequency and Inverse Document Frequency
[1 + log(tft,d)] * log (N/dft)
Fewer documents,more weight.
df = # of documents word is intf = # of times word in document
acid (1+log(2))*IDFacidamino (1+log(2))*IDFaminoanalysis (1+log(1))*IDFanalysis[…]our (1+log(1))*IDFour
Stemming
• Want to group together different variations of the same word.–Dehydrogenase vs. dehydrogenases–Activate vs. activated vs. activating
• Morphological stemmers require a lexicon.–Hard to compile for biomedical domain.
Suffix Stemming Algorithm
“Two words are considered to have the same stem if they have the same beginnings and their endings differ in one or two characters.”
(Andrade 1998)“kinase-” and “kinase-s”“transcript-s” and “transcript-ed”

Page 3
Porter (Rule-based) Stemming
73 rulesorganization -> organ (Krovetz 93)
static RuleList step1a_rules[] = { 101, "sses", "ss", 3, 1, -1, NULL,102, "ies", "i", 2, 0, -1, NULL,103, "ss", "ss", 1, 1, -1, NULL,104, "s", LAMBDA, 0, -1, -1, NULL,000, NULL, NULL, 0, 0, 0, NULL,
};
http://www.tartarus.org/~martin/PorterStemmer/Stopwords
Many of the words in the corpus contribute little to the meaning.
and, an, by, from, of, the, with (Hersh)(Can be specific to a corpus.)
So how many words do we need to use?
Porter Stemmer ExampleStep 1b
(m>0) EED -> EE feed -> feeagreed -> agree
(*v*) ED -> plastered -> plasterbled -> bled
(*v*) ING -> motoring -> motorsing -> sing
If the second or third of the rules in Step 1b is successful, the following is done:
AT -> ATE conflat(ed) -> conflateBL -> BLE troubl(ed) -> troubleIZ -> IZE siz(ed) -> size
SWISS-PROTRelease 37, Dec 9877,977 sequences59,835 references64Mb of text110081 unique words
http://www.expasy.ch/sprot/sprot-top.html
SWISS-PROT Record
ID KPEL_DROME STANDARD; PRT; 501 AA.AC Q05652;DT 01-OCT-1994 (Rel. 30, Created)DT 01-OCT-1994 (Rel. 30, Last sequence update)DT 30-MAY-2000 (Rel. 39, Last annotation update)DE PROBABLE SERINE/THREONINE-PROTEIN KINASE PELLE (EC 2.7.1.37).GN PLL.OS Drosophila melanogaster (Fruit fly).OC Eukaryota; Metazoa; Arthropoda; Tracheata; Hexapoda; Insecta;RN [1]RP SEQUENCE FROM N.A., AND MUTAGENESIS.RX MEDLINE; 93177834.RA Shelton C.A., Wasserman S.A.;RT "Pelle encodes a protein kinase required to establish dorsoventralRT polarity in the Drosophila embryo.";RL Cell 72:515-525(1993).CC -!- FUNCTION: REQUIRED FOR THE NUCLEAR IMPORT OF THE DORSAL PROTEINCC WHICH ESTABLISHES DORSOVENTRAL POLARITY IN DROSOPHILA EMBRYOS.CC -!- CATALYTIC ACTIVITY: ATP + A PROTEIN = ADP + A PHOSPHOPROTEIN.CC -!- DEVELOPMENTAL STAGE: EXPRESSED THROUGHOUT THE LIFE CYCLE WITHCC HIGHEST LEVELS IN 0-3 HOUR-OLD EMBRYOS AND ADULT FEMALES.DR FLYBASE; FBgn0010441; pll.DR INTERPRO; IPR002290; -.DR PROSITE; PS00107; PROTEIN_KINASE_ATP; 1.KW Transferase; Serine/threonine-protein kinase; ATP-binding.FT DOMAIN 213 499 PROTEIN KINASE.FT BINDING 240 240 ATP.SQ SEQUENCE 501 AA; 56160 MW; 4B29E2B40ACB81A8 CRC64;
MSGVQTAEAE AQAQNQANGN RTRSRSHLDN TMAIRLLPLP VRAQLCAHLD ALDVWQQLATAVKLYPDQVE QISSQKQRGR SASNEFLNIW GGQYNHTVQT LFALFKKLKL HNAMRLIKDYRQVTDRVPEN ETKKNLLDYV KQQWRQNRME LLEKHLAAPM GKELDMCMCA IEAGLHCTALDPQDRPSMNA VLKRFEPFVT D
//
Word Frequency in SP37

Page 4
Zipf's Law
Empirical observation of the pattern of usage frequencies of words.
CF * R = K
– CF - Collection Frequency– R - Rank– K - constant
Zipf for SP37
Information SummarizationClustering Microarray
Papers
• Use standard clustering algorithms.
• Documents are vectors of words.
(Altman & Raychaudhuri)
TextQuest: Concept Discovery
Cluster documents to discover broad themes in a corpus.
Find words that describe each cluster:
Score = log(fij/fi)fij - frequency of word i in cluster jfi – frequency of word i in corpus
K-Means clustering (I)
1. Choose K documents as “cluster centers”.2. Assign all documents to the nearest cluster.3. Recalculate new cluster centers.4. Repeat 2-4 until clusters do not change.
* Documents are vectors of word counts.

Page 5
K-Means clustering (II)
1. Choose K documents as “cluster centers”.2. Assign all documents to the nearest cluster.3. Recalculate new cluster centers.4. Repeat 2-4 until clusters do not change.
K-Means clustering (III)
1. Choose K documents as “cluster centers”.2. Assign all documents to the nearest cluster.3. Recalculate new cluster centers.4. Repeat 2-4 until clusters do not change.
K-Means clustering (IV)
1. Choose K documents as “cluster centers”.2. Assign all documents to the nearest cluster.3. Recalculate new cluster centers.4. Repeat 2-4 until clusters do not change.
K-Means clustering (V)
1. Choose K documents as “cluster centers”.2. Assign all documents to the nearest cluster.3. Recalculate new cluster centers.4. Repeat 2-4 until clusters do not change.
K-Means clustering (VI)
1. Choose K documents as “cluster centers”.2. Assign all documents to the nearest cluster.3. Recalculate new cluster centers.4. Repeat 2-4 until clusters do not change.
K-Means clustering (VII)
1. Choose K documents as “cluster centers”.2. Assign all documents to the nearest cluster.3. Recalculate new cluster centers.4. Repeat 2-4 until clusters do not change.

Page 6
K-Means clustering (VIII)
1. Choose K documents as “cluster centers”.2. Assign all documents to the nearest cluster.3. Recalculate new cluster centers.4. Repeat 2-4 until clusters do not change.
Cluster of Drosophila Development
Dorsoventral axis specification
Segmentation and embryonic patterning
Egg chamber / oocyte patterning
(Iliopoulos 2001)
PubMed queries:anterior-posteriordorsal-ventral
How Do We Summarize Protein Families?
• Use protein families from FSSP database.• Get articles for each family from SWISS-PROT.
frequency of word a in family i sequences in
family i with word a
sequences in family i
average frequency of word a
Families with word a1, if family has word a0, if family does not have word a
Describing Protein Families
Appears in few families very frequently
(Andrade 1998)
tokenizationartifact
Data Collection
Database
What kinds of data to collect?
• Genes and gene products.• Protein localization.• Disease associated with
proteins.• Protein-protein interactions.• Pathways.

Page 7
Collecting Data with Information Extraction (IE)
Find specific facts from free text.EntitiesRelations
Information Extraction
Relations from IE
LOCALIZED_TO(CYP3A4, LIVER)HAS_VARIABILITY(CYP3A4)AFFECTS(CYP3A4, INDINAVIR)
Diagram of an IE System
Rules
ExtractionAppPre-Processing
Pre-Processing
DT NN NN VBZ NN NN
This system synthesizes fibroblast growth factor.
NP NPV
POS TAGGING
synthes
PARSING
STEMMING
TOKENIZATION
Rules for IE
• Information Extraction systems typically rule-based.
• IF <pre-conditions> THEN <action>
• Rules typically developed by domain experts manually.
Rules
ExtractionAppPre-Processing
Examples of IE Rules
Role:<NP> receptor -> <protein> receptor
Relations:<protein> activates <protein>
<finding> in <bodyloc> <conj> <bodyloc>
Rules
ExtractionAppPre-Processing

Page 8
Protein-Protein Interactions inDrosophila Cell Cycle
• Look for pattern in MEDLINE abstracts:protein A -- action -- protein B
• Protein names specified by user• 14 possible actions:
(Blaschke 1999)
regulat-stabiliz-suppresstarget
inhibitinteractis conjugated tomodulat-phosphorylat-
acetylat-activat-associated withbinddestabiliz-
Interactions Found
Protein Names
Protein names come in many forms:
• Single word with mixed case or numbers. e.g. Nef, p53
• Compound word.e.g. interleukin 1-responsive kinase
• Single word all lowercase. e.g. actin, insulin
(Fukuda 1997)
Recognizing Protein Names• Finding “core terms” (candidate
protein names)
–Capital letters and numbers–P54 SAP kinase
• Identifying “f-terms” (high frequency associations)
–EGF receptor–Ras GTPase-activating protein
(Fukuda 1997)
Core-Terms for protein names• Include words with upper case, numerical
figures, and/or special symbols
• No lower case words longer than 9 characters with "-". (full-length)
• No words with more than half special symbols. (+/-)
• No units. (aa, AA, fold, bp)
• Ignore literature references. (Fukuda 1997)
Concatenate Core- and F- TermsLook at surface clues
• Connect adjacent termsSrc SH3 domain
• Include parenthesesUse a POS tagger
• Connect words if nouns, adjectives, or numbers insideRas guanine nucleotide exchange factor Sos
• Extend left to a determiner.the focal adhesion kinase
• Extend right if there is a single upper case letter or greek word.p85 alpha
(Fukuda 1997)

Page 9
Computing Biologically Application: How to find sequence homologies?
PSI-BLAST
• Iterative BLAST• More sensitive, but
subject to "profile drift"
Search Database
ConstructProfile
SequenceProfile
MultipleAlignment
SequenceDatabase
Augment with Literature
Search Database
ConstructProfile
ExamineLiterature
SequenceProfile
MultipleAlignment
SequenceDatabase
Using Text Increases Precision
0.8
0.85
0.9
0.95
1
0 0.1 0.2 0.3 0.4
Recall
Inte
rpol
ated
Pre
cisi
on
PSI-BLAST 5% tex t cutoff 10% tex t cutoff 20% tex t cutoff
precision - correct hits / all hitsrecall - correct hits / total correct answers
Application : Assigning GO codes to genes using literature
Genome Research 12(1), p 203-214
ProblemINPUT:
1. Controlled terminology of gene function--the Gene Ontology (GO)
2. Literature associated with a set of genes--SGD (yeast genome database)
OUTPUT:Algorithm to assign codes to genes

Page 10
Method
Focus on 21 high level GO process terms.
Standard Maximum Entropy classifier compared with:
• Naïve Bayes• Nearest Neighbor
0
0 .2
0 .4
0 .6
0 .8
1
0 0.2 0.4 0.6 0.8 1
Reca ll
Prec
isio
n
me tabo lism
cell_cyc le
me iosis
intrace llula r_prote in_ tra ffic
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Recall
Prec
isio
n
s igna l_transduc tion
cell_ fus ion
biogenesis
transport
ion_homeostas is
Documentclassification
into GOcodes

Page 11
Application: Assessing Functional Coherence of groups
of genes
Soumya RaychaudhuriHinrich SchuetzeRuss Altman
PROBLEM
Grouping genes together is common activity.
When a group of genes is produced from a novel technology (such as microarrays), how can we assess the significance of this grouping?
Gene Clustersfrom clusteringof yeast genes
based on expression
patterns under a variety of conditions
Manual labeling
Spindle pole formationProteasomemRNA splicingGlycolysisMitochondrial ribosomeATP synthesisChromatin structureRibosome/translationDNA replicationTCA cycle
Semantically similar articles refer to related genes
“Neighbor Divergence” score(comparison of observed/expected co-
references)
Count of neighbors referring to group genes
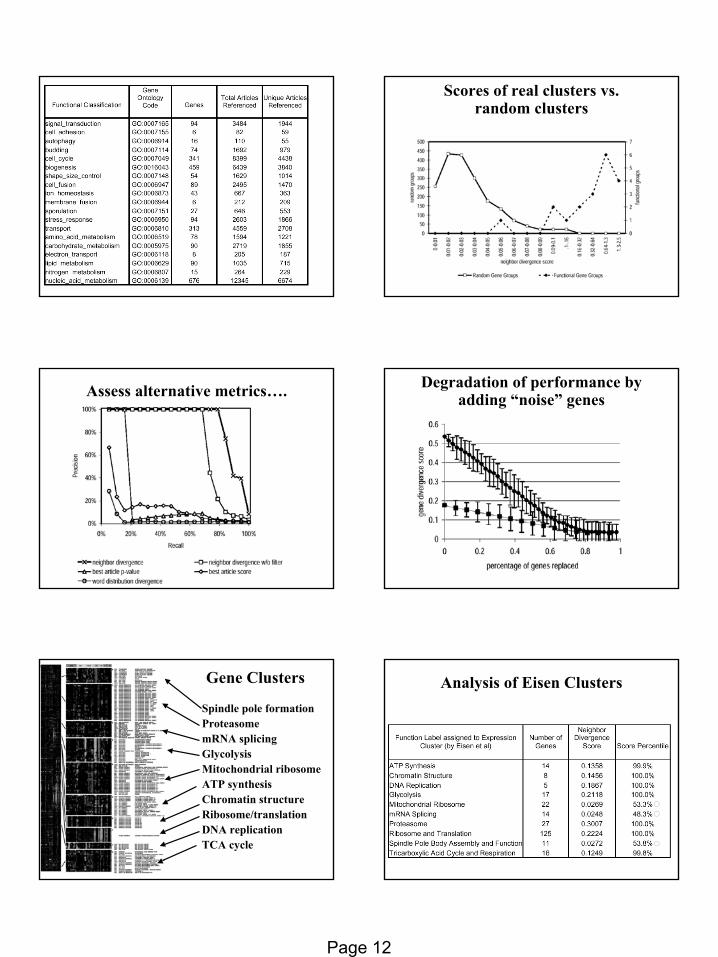
Page 12
Scores of real clusters vs. random clusters
Assess alternative metrics…. Degradation of performance by adding “noise” genes
Gene Clusters
Spindle pole formationProteasomemRNA splicingGlycolysisMitochondrial ribosomeATP synthesisChromatin structureRibosome/translationDNA replicationTCA cycle
Analysis of Eisen Clusters

Page 13
ConclusionsCan use literature to assess the functional
coherence of groups of genes.
Can distinguish “real” groups from random.
Can identify coherence in manual groups.
Some biases in method still need to be removed (e.g. large groups favored, can fuse two strong, but unrelated groups)
Application: Detecting abbreviations in biomedical
literature
PROBLEMIncreasing occurrence of abbreviations in
the biomedical literature.
Represents a challenge to both humans and text processing algorithms.
Can we detect abbreviations reliably in abstracts of PubMed?
NOTE: Excellent, but different approach published by Pustejovsky, Castano et al. =
ACROMED work.
Sample Alignments
NEUROPEPTIDE YN----P-------YN------P-----Y = NPY
Beta-EndorphinBETA-E----P--- =Beta-EP
c-Jun N-terminal Kinase--J---N----------K----- = JNK

Page 14
Features of Alignment Used
1. Lower case vs. upper case letters2. Beginning of word3. End of word4. Syllable boundary5. Neighbor6. Percent aligned7. Unused words8. Aligned/word
Abbreviation Server
http://abbreviation.stanford.edu/
Summary• Much biological information is encoded as
free text.
• NLP can analyze the text using a combination of statistical and rule-based approaches.
• Computational analyses of text can be useful, but are noisy and must be interpreted carefully.



![[Architecture eBook] Daylighting - Natural Light in Architecture](https://static.fdocuments.in/doc/165x107/55cf9971550346d0339d6b9b/architecture-ebook-daylighting-natural-light-in-architecture.jpg)










![[eBook]Colesterol - Tratamiento Natural Alimenticio](https://static.fdocuments.in/doc/165x107/577c81071a28abe054ab2c7e/ebookcolesterol-tratamiento-natural-alimenticio.jpg)


