
DYNAMO vs. ADORE A Tale of Two Dynamic Optimizers Wei Chung Hsu Computer Science and Engineering...
53
DYNAMO vs. ADORE DYNAMO vs. ADORE A Tale of Two Dynamic A Tale of Two Dynamic Optimizers Optimizers Wei Chung Hsu Wei Chung Hsu Computer Science and Engineering Computer Science and Engineering Department Department University of Minnesota, Twin Cities University of Minnesota, Twin Cities
-
date post
21-Dec-2015 -
Category
Documents
-
view
213 -
download
0
Transcript of DYNAMO vs. ADORE A Tale of Two Dynamic Optimizers Wei Chung Hsu Computer Science and Engineering...

DYNAMO vs. ADOREDYNAMO vs. ADOREA Tale of Two Dynamic OptimizersA Tale of Two Dynamic Optimizers
Wei Chung HsuWei Chung Hsu
Computer Science and Engineering DepartmentComputer Science and Engineering Department
University of Minnesota, Twin CitiesUniversity of Minnesota, Twin Cities

Dynamic Binary OptimizationDynamic Binary Optimization
It It is the detection is the detection of program hot spots of program hot spots and and application of optimizations to application of optimizations to native native binarybinary code at run-time.code at run-time. Also called Also called runtimeruntime binary binary optimization.optimization.
Why is Why is staticstatic compiler optimization compiler optimization insufficient?insufficient?

Why Dynamic Why Dynamic Binary OptimizationBinary Optimization
One size does not fit allOne size does not fit all: runtime environments : runtime environments may be different from what the static binary was may be different from what the static binary was optimized for.optimized for.– Underlying micro-architecturesUnderlying micro-architectures
e.g. running Pentium code on Pentium-IIe.g. running Pentium code on Pentium-II
– Input data setsInput data sets
e.g.e.g. some data sets may not incur cache missessome data sets may not incur cache misses
– Dynamic phase behaviorDynamic phase behavior– Dynamic librariesDynamic libraries

Portable ExecutablePortable Executable
Compile
Info
Intermediate
Representation
.EXE
or
.SO

Common Binary (fat binary)Common Binary (fat binary)
Itanium-Ibinary
Annotation
Itanium-2binary
Annotation
Itanium-3binary
Annotation

Chubby BinaryChubby Binary
Itanium-Ispecific Annotation
Itanium-2specificAnnotation
Itanium-3specificAnnotation
Common Itanium Binary

Using More Accurate ProfilesUsing More Accurate Profiles
Optimize from Source
Optimize from Source with profile feedbackOptimize from binarywith profile feedback
Walk time (or Ahead of time) Optimization
Runtime Optimization
@ ISV Sites
@ User Sites

Dynamo Dynamo - Dynamo means “Dynamic Optimization System”Dynamo means “Dynamic Optimization System”- A collaborative project between HP Lab (under A collaborative project between HP Lab (under
Josh Fisher) and HP System Lab.Josh Fisher) and HP System Lab.- Build on the dynamic translation technology Build on the dynamic translation technology
developed for ARIES (which migrates PA binary to developed for ARIES (which migrates PA binary to the Itanium architecture).the Itanium architecture).
- Considered revolutionary and won the best paper Considered revolutionary and won the best paper award in PLDI’2000award in PLDI’2000
- Dynamo technology was enhanced and continued Dynamo technology was enhanced and continued by MIT and later became Dynamo/RIO.by MIT and later became Dynamo/RIO.
- Dynamo/RIO group now starts a company called Dynamo/RIO group now starts a company called Determina (Determina (http://www.determina.com/)http://www.determina.com/)

Migration vs. Dynamic OptimizationMigration vs. Dynamic Optimization
Migration (e.g. Aries) DynOpt (e.g. Dynamo)
existingIncompatible
binary
nativebinary
emulator/interpreter
emulator/interpreter
traceselector
dyncodecache
codecache
translatoroptimizer
Memory Memory

Migration DynOpt (e.g. Dynamo)
existingIncompatible
binary
nativebinary
emulator/interpreter
emulator/interpreter
traceselector
dyncodecache
codecache
translatoroptimizer
Optional AcceleratorOptimization is 2nd priority
Optional OptimizerOptimization is critical
Migration vs. Dynamic OptimizationMigration vs. Dynamic Optimization

Why not Static Binary Translation?Why not Static Binary Translation? The Code-Discovery ProblemThe Code-Discovery Problem
What is the target of an indirect jump?What is the target of an indirect jump? No guarantee that the locations immediately following a No guarantee that the locations immediately following a
jump contain valid instructionsjump contain valid instructions Some compilers intersperse data with instructionsSome compilers intersperse data with instructions More challenging for ISA with variable length instructionsMore challenging for ISA with variable length instructions padding to align instructionspadding to align instructions
The Code-Location ProblemThe Code-Location Problem How to translate indirect jumps? The target is not known How to translate indirect jumps? The target is not known
until runtime.until runtime. Other problemsOther problems
Self-modifying codeSelf-modifying code Self-referencing codeSelf-referencing code Precise trapsPrecise traps

How Dynamo WorksHow Dynamo Works
Interpret untiltaken branch
Lookup branchtarget
Start of tracecondition?
Jump to codecache
Increment counterfor branch target
Counter exceedthreshold?
Interpret +code gen
End-of-tracecondition?
Create trace& optimize it
Emit intocache
Signalhandler
Code Cache

Trace SelectionTrace Selection
A
B C
D
F
G H
I
E
call
return
trace selection
A
B
C
D
E
F
G
H
I
originallayout

Trace SelectionTrace Selection
A
B C
D
F
G H
I
E
A
C
D
F
G
I
E
call
returnto Bto H
back toruntime
Trace layout in
tracecache
trace selection

Flow of Control on Translated TracesFlow of Control on Translated Traces
EmulationManager
Translated Trace
StubStub
Translated Trace
StubStub
Translated Trace
StubStub

Highoverhead
Flow of Control on Translated TracesFlow of Control on Translated Traces
EmulationManager
Translated Trace
StubStub
Translated Trace
StubStub
Translated Trace
StubStub
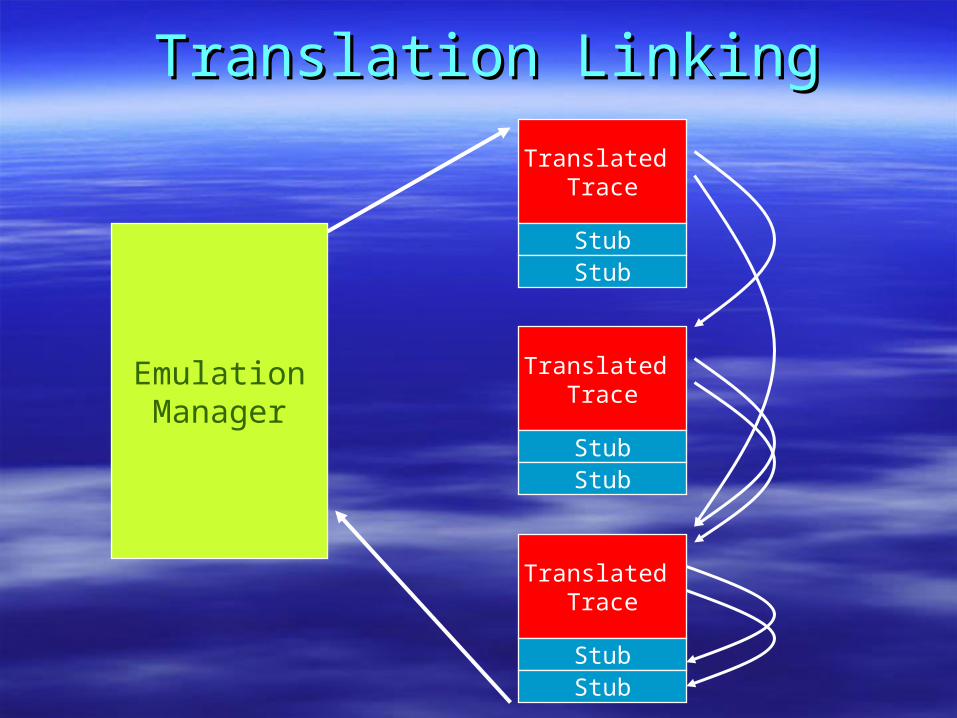
Translation LinkingTranslation Linking
EmulationManager
Translated Trace
StubStub
Translated Trace
StubStub
Translated Trace
StubStub

Backpatching/Trace LinkingBackpatching/Trace Linking
A
C
D
F
G
I
E
to Bto H
back toruntime
H
I
E
When H becomes hot,a new trace is selectedstarting from H, and thetrace exit branch in block F is backpatched to branchto the new trace.

Importance of Trace LinkingImportance of Trace Linking
Performance slowdown when linking is disabledPerformance slowdown when linking is disabled
Not a small trickNot a small trick
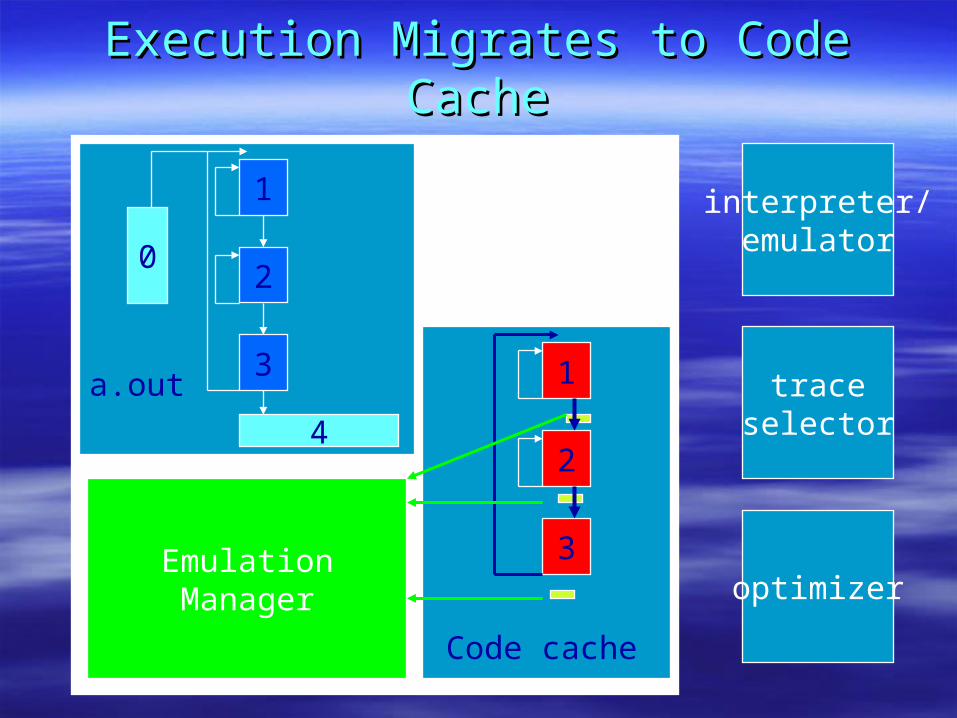
Execution Migrates to Code CacheExecution Migrates to Code Cache
a.out
1
2
3
Code cache
1
2
3
0
4
interpreter/emulator
traceselector
optimizerEmulationManager

Handle Indirect BranchesHandle Indirect Branches
Variable targets – cannot be linkedVariable targets – cannot be linked Must map addresses in original program to Must map addresses in original program to
the addresses in code cachethe addresses in code cache– Hash table lookupHash table lookup
– Compare the dynamic target with a predicted Compare the dynamic target with a predicted target target
jmp hashtable_lookup
cmp real_target, predicted_target je predicted_targetjmp hashtable_lookup

Handle Indirect Branches (cont.)Handle Indirect Branches (cont.)
Compare with a small number of predicted Compare with a small number of predicted targets.targets.
A software-based indirect-branch-target-cache to avoid going A software-based indirect-branch-target-cache to avoid going back to the emulation manager.back to the emulation manager.
cmp real_target, hot_target_1je hot_target_1cmp real_target, hot_target_2je hot_target_2call prof_routinejmp hashtable_lookup
jmp hashtable_lookup

PerformancePerformance
Trace formation – Partial procedure inline & code layoutTrace formation – Partial procedure inline & code layout SlowdownSlowdown
– Major slowdowns were avoided by early bail-outMajor slowdowns were avoided by early bail-out

Summary of DynamoSummary of Dynamo
Dynamic Binary Optimization customizes Dynamic Binary Optimization customizes performance delivery:performance delivery:– Code is optimized by how the code is usedCode is optimized by how the code is used– Code is optimized for the machine it runs onCode is optimized for the machine it runs on– Code is optimized when all executables are Code is optimized when all executables are
availableavailable– Code is optimized only the part that mattersCode is optimized only the part that matters

Dynamo Follow-upsDynamo Follow-ups Dynamo/RIO: Dynamo + RIO (Runtime Dynamo/RIO: Dynamo + RIO (Runtime
Introspection and Optimization) for x86 Introspection and Optimization) for x86 architecturearchitecture
More successful in “More successful in “IntrospectionIntrospection” than in ” than in ““OptimizationOptimization”.”.
Started the company Determina for system Started the company Determina for system security enforcementsecurity enforcement
Similar technology can be applied to migration, Similar technology can be applied to migration, fast simulation, dynamic instrumentation, program fast simulation, dynamic instrumentation, program introspection, security enforcement, power introspection, security enforcement, power management, … etc.management, … etc.

What happen to “Optimization”What happen to “Optimization”Dynamo has the following challenges:Dynamo has the following challenges: Profiling issuesProfiling issues
frequency based, not time basedfrequency based, not time based hard to detect really hot code, may end up with too hard to detect really hot code, may end up with too
much translationmuch translation Code duplication issuesCode duplication issues
trace generation could end up with excessive code trace generation could end up with excessive code duplicationduplication
Code cache management issuesCode cache management issues for real applications, it requires very large code cachefor real applications, it requires very large code cache
Indirect branch handling issuesIndirect branch handling issues Indirect branch handling is expensiveIndirect branch handling is expensive

ADOREADORE ADORE means ADaptive Object code RE-ADORE means ADaptive Object code RE-
optimizationoptimization Was developed at the CSE department, U. Was developed at the CSE department, U.
of Minnesotaof Minnesota Applied a different model for dynamic Applied a different model for dynamic
optimization systems (after rethinking of optimization systems (after rethinking of dynamic optimization)dynamic optimization)
Considered evolutionaryConsidered evolutionary

ADORE ModelADORE Model
Executable Code Cache
DynOptmanager
Branch/jumpinstruction

ADORE RationaleADORE Rationale If the executable is compatible, why should If the executable is compatible, why should
we use interpretation/emulation? we use interpretation/emulation? Instrumentation or interpretation based Instrumentation or interpretation based
profiling does not collect important profiling does not collect important performance events, why not use HPM?performance events, why not use HPM?
If a program runs well, why bother to If a program runs well, why bother to translate hot code?translate hot code?
Redirection of execution can be more Redirection of execution can be more effectively implemented using branches.effectively implemented using branches.

ADORE FrameworkADORE Framework
Hardware Performance Monitoring Unit (PMU)
Kernel
Phase Detection
Trace Selection
Optimization
Deployment
Main ThreadDynamic
OptimizationThread
Code Cache
Init PMU
Int. on Event
Int on K-buffer ovf
On phase change
Pass traces to opt
Init Code $ Optimized Traces
Patch traces
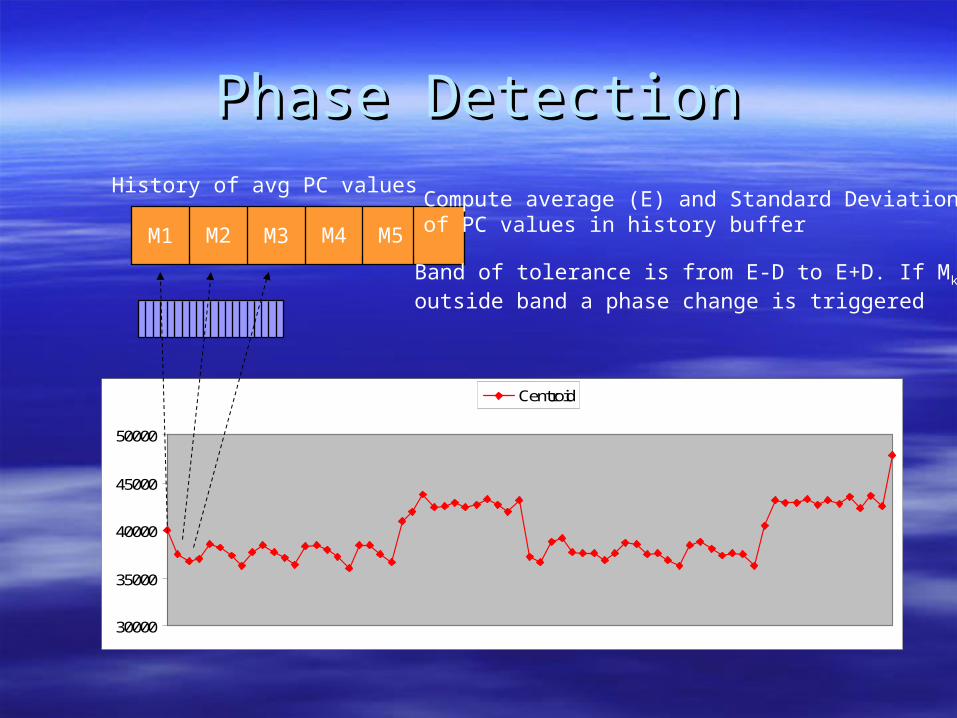
Phase DetectionPhase DetectionHistory of avg PC values
M1 M2 M3 M4 M5
Compute average (E) and Standard Deviation (D)of PC values in history buffer
Band of tolerance is from E-D to E+D. If Mk isoutside band a phase change is triggered
30000
35000
40000
45000
50000
Centroid

Phase DetectionPhase DetectionHistory of avg PC values
M1 M2 M3 M4 M5
Compute average (E) and Standard Deviation (D)of PC values in history buffer
Band of tolerance is from E-D to E+D. If Mk isoutside band a phase change is triggered
30000
35000
40000
45000
50000
Band of tolerance Centroid
Phase Change

Phase DetectionPhase DetectionHistory of avg PC values
M1 M2 M3 M4 M5
Compute average (E) and Standard Deviation (D)of PC values in history buffer
Band of tolerance is from E-D to E+D. If Mk isoutside band a phase change is triggered
30000
35000
40000
45000
50000
Band of tolerance Centroid Phase Change

Trace SelectionTrace Selection A trace is a single entry, multiple exit code A trace is a single entry, multiple exit code
sequence (e.g. a superblock)sequence (e.g. a superblock) Trace selection is guided by the path profile Trace selection is guided by the path profile
constructed from the branch trace samples constructed from the branch trace samples (BTB samples).(BTB samples).
Traces can be stitches together to form longer Traces can be stitches together to form longer traces.traces.
Trace end conditions:Trace end conditions:procedure return, backward branch that forms a procedure return, backward branch that forms a loop, not highly biased branches, trace size loop, not highly biased branches, trace size exceeds a preset threshold.exceeds a preset threshold.
Function calls are considered fall-through. Function calls are considered fall-through.

Runtime D-Cache Pre-fetchingRuntime D-Cache Pre-fetching
Locate the most recent delinquent loadsLocate the most recent delinquent loads If the load instruction is in a loop-type trace, If the load instruction is in a loop-type trace,
determines the reference pattern via address determines the reference pattern via address dependence analysis.dependence analysis.
Calculate the stride if the reference has Calculate the stride if the reference has spatial or structural locality. spatial or structural locality.
If the reference is pointer-chasing, insert If the reference is pointer-chasing, insert codes to detect possible strides at runtime.codes to detect possible strides at runtime.
Insert and schedule pre-fetch instructions.Insert and schedule pre-fetch instructions.

Identify Delinquent LoadsIdentify Delinquent Loads
Using sampled EAR information to identify the Using sampled EAR information to identify the delinquent loads in a selected trace. delinquent loads in a selected trace.
Calculate the average latency and the total miss Calculate the average latency and the total miss penalty of each delinquent load.penalty of each delinquent load.
{ .mii ldfd f60=[r15],8 // average latency: 129 penalty ratio: 6.38% add r8=16,r24;; add r42=8,r24}

Determine Reference PatternDetermine Reference Pattern
// i++; a[ i++]=b; // b= a[ i++];
Loop: … add r14= 4, r14 st4 [r14] = r20, 4 ld4 r20 = [r14] add r14 = 4, r14 … br.cond Loop
// c = b[a[k++] – 1];
Loop: … ld4 r20=[r16], 4 add r15 = r25,r20 add r15 = –1, r15 ld8 r15=[r15] … br.cond Loop
//tail = arcin-> tail;//arcin = tail-> mark;
Loop: … add r11= 104, r34 ld8 r11= [r11] ld8 r34= [r11] … br.cond Loop
A. direct array B. indirect array C. pointer chasing

Perf. of ADORE/Itanium on SPECPerf. of ADORE/Itanium on SPEC

Performance on BLASTPerformance on BLAST
-15%
0%
15%
30%
45%
60%
blastnnt.1
blastnnt.10(4)
blastnnt.10(5)
blastnnt.10(7)
blastpaa.1
blastxnt.1
tblastnaa.1
Queries
% S
peed
-up
GCC O2 ORC O2 ECC O2

Static Optimizations on BLASTStatic Optimizations on BLAST
-10%
0%
10%
20%
30%
40%
50%
60%
blastn nt.1 blastn nt.10(5) blastp aa.1 blastx nt.1 tblastn aa.1 Average
Selected Queries
Sp
eed
-up
ove
r G
CC
O1
ORC O1
ECC O1
GCC O2
ORC O2
ECC O2
GCC O3
ORC O3
ECC O3
Performance can often degrade at higher Performance can often degrade at higher optimization levels in all three compilers optimization levels in all three compilers
Long query which has a high fraction of stall Long query which has a high fraction of stall cycles did not benefit from static optimizationscycles did not benefit from static optimizations
Static prefetching ineffective
O1
O2
O3
O1O2
O3

Profile Based OptimizationsProfile Based Optimizations
-30%-25%-20%-15%-10%-5%0%5%
10%
blastn nt.1 blastnnt.10(5)
blastp aa.1 blastx nt.1 tblastn aa.1 All
Queries used to generate profile
Spee
d-up
w.r.
t EC
C O
2blastn nt.1 blastn nt.10(5) blastp aa.1 blastx nt.1 tblastn aa.1
Less than 5% gain for some inputsLess than 5% gain for some inputs Large slowdown for othersLarge slowdown for others Combining profiles results in moderate gain for some inputsCombining profiles results in moderate gain for some inputs

Slowdown from PBOSlowdown from PBO
Large increase in system timeLarge increase in system time ECC inserts speculative load for future iteration in ECC inserts speculative load for future iteration in
a loop, which causes TLB missesa loop, which causes TLB misses TLB miss exception is handled by OS for TLB miss exception is handled by OS for
speculative loads immediatelyspeculative loads immediately Reconfigured kernel to defer TLB miss on Reconfigured kernel to defer TLB miss on
speculative loads to hardwarespeculative loads to hardware– On TLB miss for speculative load, the NAT bit is set. On TLB miss for speculative load, the NAT bit is set.
Recovery code will load data if neededRecovery code will load data if needed

PBO (Kernel Reconfigured)PBO (Kernel Reconfigured)
-15%
-10%
-5%
0%
5%
10%
15%
blastn nt.1 blastnnt.10(5)
blastp aa.1 blastx nt.1 tblastn aa.1 All
Queries used to generate profile
Sp
eed
-up
w.r
.t E
CC
O2
blastn nt.1 blastn nt.10(5) blastp aa.1 blastx nt.1 tblastn aa.1
Difficult to find right set of combined training input
PBO can give performance but has limitations

ADORE vs. DynamoADORE vs. DynamoTasksTasks DynamoDynamo ADOREADORE
ObservationObservation
(profiling)(profiling)
Interpretation/ Interpretation/ instrumentation instrumentation basedbased
HPM and branch HPM and branch trace sampling trace sampling basedbased
OptimizationOptimization Trace layout and Trace layout and classic optclassic opt
D-cache related D-cache related optimizationsoptimizations
Code cacheCode cache Need large Code$Need large Code$ Small Code$ Small Code$ sufficientsufficient
Re-directionRe-direction Interpretation and Interpretation and dynamic linkingdynamic linking
Patching branchesPatching branches

Mis-conceptions about ADOREMis-conceptions about ADORE Compiler optimizations are very complex, Compiler optimizations are very complex,
doing them at runtime is a bad idea.doing them at runtime is a bad idea. Current ADORE deals with only cache Current ADORE deals with only cache
misses. It does not handle traditional compiler misses. It does not handle traditional compiler optimizations. (It is a optimizations. (It is a complementcomplement, not a , not a replacementreplacement, of compiler optimization), of compiler optimization)
Inserting cache prefetch instructions (and/or Inserting cache prefetch instructions (and/or branch prediction hints) are safe branch prediction hints) are safe optimizations. No correctness issues.optimizations. No correctness issues.

Performance at Different Sampling RatesPerformance at Different Sampling Rates((based on Adore/Itanium perf. of Spec2000based on Adore/Itanium perf. of Spec2000))
0.00%
2.00%
4.00%
6.00%
8.00%
10.00%
100000 200000 400000 800000 1000000 2000000 4000000 8000000
Net Speedup Dynopt Overhead

Mis-conceptions about DynOptMis-conceptions about DynOpt Compilation/Optimization overhead is usually Compilation/Optimization overhead is usually
amortized by thousands execution of the binary. amortized by thousands execution of the binary. How can runtime optimization overhead be How can runtime optimization overhead be amortized for only one execution?amortized for only one execution?
Spec92Spec92 Spec95Spec95 Spec2kSpec2k Spec2005Spec2005
AverageAverage
InstructionInstruction
reusereuse
5K5K 320K320K 3M3M 30M30M

Mis-conceptions about ADOREMis-conceptions about ADORE ADORE will be unreliable, hard to debug, difficult ADORE will be unreliable, hard to debug, difficult
to maintain.to maintain.ADOREADORE performs simple transformations, it could performs simple transformations, it could be more reliable than a static optimizer.be more reliable than a static optimizer.Current ADORE can run real large applications:Current ADORE can run real large applications: Adore/Itanium on the Bio-informatics application Adore/Itanium on the Bio-informatics application
BLAST (millions lines of code). BLAST (millions lines of code). 58% speed up on some long queries58% speed up on some long queries
Adore/Sparc on the application FluentAdore/Sparc on the application Fluent 14.5% speed up on Panther14.5% speed up on Panther

ADORE/SparcADORE/Sparc
ADORE has been ported to Sparc/Solaris platform ADORE has been ported to Sparc/Solaris platform since 2005.since 2005.
ADORE uses the ADORE uses the libcpclibcpc interface on Solaris to interface on Solaris to conduct runtime profiling. A kernel buffer conduct runtime profiling. A kernel buffer enhancement is added to Solaris 10.0 to reduce enhancement is added to Solaris 10.0 to reduce profiling and phase detection overheadprofiling and phase detection overhead
Reachability is a true problem. (e.g. Oracle, Reachability is a true problem. (e.g. Oracle, Dyna3D)Dyna3D)
Lack of branch trace buffer is painful. (e.g. Blast)Lack of branch trace buffer is painful. (e.g. Blast)

Performance of In-Thread Opt. (USIII+)Performance of In-Thread Opt. (USIII+)
-10.00%
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
Base
Peak

Helper Thread Prefetching for CMPHelper Thread Prefetching for CMP
Main threadMain thread
Second coreSecond core
Prefetches initiatedPrefetches initiated
Cache miss avoidedCache miss avoided L2L2
CacheCacheMissMiss
timeFirst CoreFirst Core
Trigger to activate (About 65 cycles delay)
Spin Waiting Spin again waiting for the next trigger

Performance of Helper ThreadPerformance of Helper Thread
-20.00%
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
Base
Peak

Summary of ADORESummary of ADORE
ADORE uses Hardware Performance Monitoring ADORE uses Hardware Performance Monitoring capability to implement a light weight runtime capability to implement a light weight runtime profiling systemprofiling system. . Efficient profiling and phase Efficient profiling and phase detection is the key to the success of ADORE.detection is the key to the success of ADORE.
ADORE can speed up real-world large ADORE can speed up real-world large applications optimized by production compilers.applications optimized by production compilers.
ADORE works on two architectures: Itanium and ADORE works on two architectures: Itanium and SPARC.SPARC.
ADORE can generate helper threads for current ADORE can generate helper threads for current and future CMP’s.and future CMP’s.


















