
Document Image Analysis Lecture 11: Word Recognition and Segmentation
32
UC Berkeley CS294-9 Fall 2000 11- 1 Document Image Analysis Lecture 11: Word Recognition and Segmentation Richard J. Fateman Henry S. Baird University of California – Berkeley Xerox Palo Alto Research Center
-
Upload
dylan-potter -
Category
Documents
-
view
46 -
download
1
description
Document Image Analysis Lecture 11: Word Recognition and Segmentation. Richard J. Fateman Henry S. Baird University of California – Berkeley Xerox Palo Alto Research Center. The course so far…. DIA overview, objectives, measuring success Isolated-symbol recognition: - PowerPoint PPT Presentation
Transcript of Document Image Analysis Lecture 11: Word Recognition and Segmentation

UC Berkeley CS294-9 Fall 2000 11- 1
Document Image AnalysisLecture 11: Word Recognition and
Segmentation
Richard J. FatemanHenry S. Baird
University of California – BerkeleyXerox Palo Alto Research Center

UC Berkeley CS294-9 Fall 2000 11- 2
The course so far….
• DIA overview, objectives, measuring success
• Isolated-symbol recognition:– Symbols/glyphs, models/features/classifiers
– image metrics, scaling up to 100 fonts of full ASCII
– last 2 lectures: • ‘best’ classifier none dominates but: voting helps
• combinations of randomized features/ classifiers!

UC Berkeley CS294-9 Fall 2000 11- 3
Recall: we can often spot words when characters are unclear…
• Crude segmentation into columns,
paragraphs, lines, words
• Bottom up, by smearing horiz/ vert … or
• Top down, by recursive x-y cuts
• what we really want is WORD recognition,
most of the time.
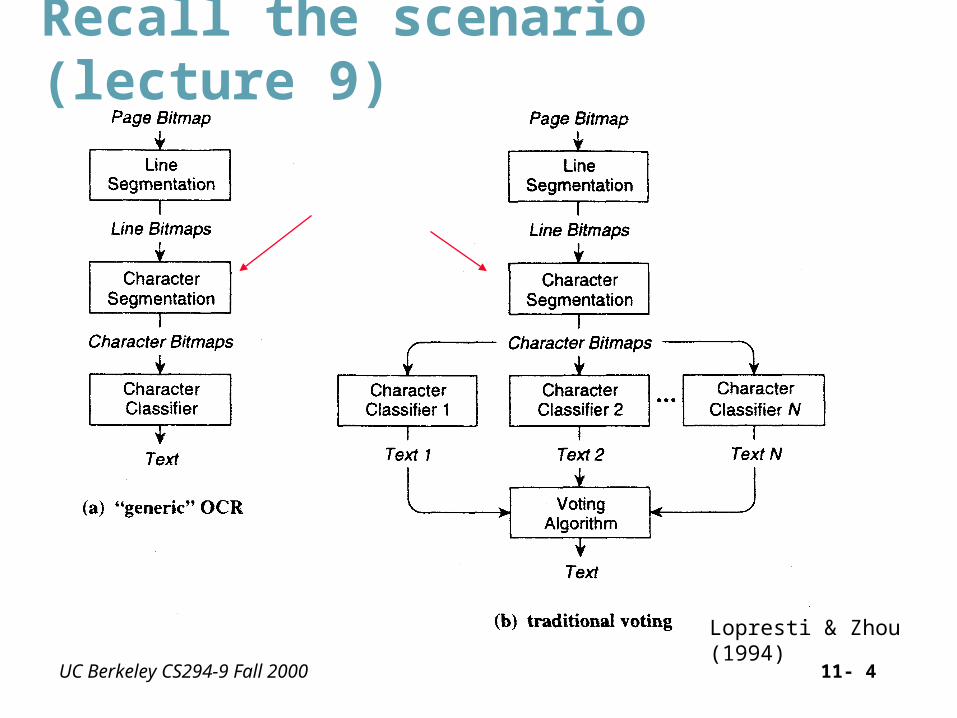
UC Berkeley CS294-9 Fall 2000 11- 4
Recall the scenario (lecture 9)
Lopresti & Zhou (1994)

UC Berkeley CS294-9 Fall 2000 11- 5
The flow goes one way
• No opportunity to correct failures in segmentation at symbol stage
• No opportunity to object to implausible text at the next stage.
• (providing alternative character choices gives limited flexibility)
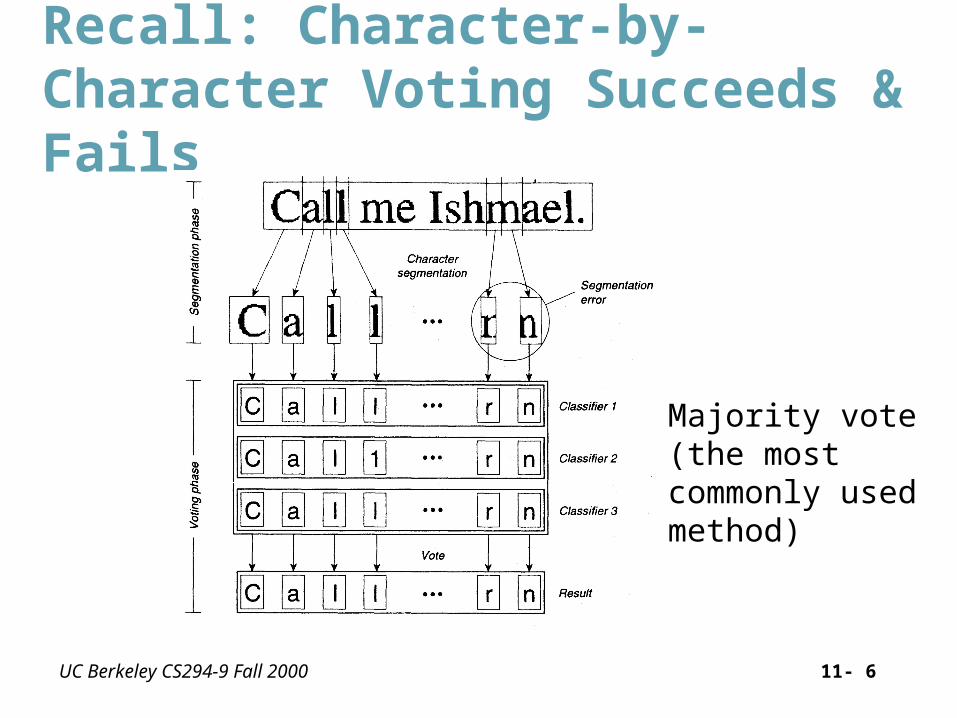
UC Berkeley CS294-9 Fall 2000 11- 6
Recall: Character-by-Character Voting Succeeds & Fails
Majority vote (the most commonly used method)

UC Berkeley CS294-9 Fall 2000 11- 7
High accuracy requires some cleverness
• In fact, some words, even in cleanly typeset text
high-resolution scanned, have touching characters
• In noisy or low resolution images, adjacent
characters may be nearly entirely touching or broken
(or both touching and broken!)
• If we accept the flowchart model: we need perfect
segmentation to feed the symbol recognition module
• If we reject the flowchart: OK, where do we go from
here?

UC Berkeley CS294-9 Fall 2000 11- 8
Compare alternative approaches
• First clarify the word recognition problem and see how to approach it.
• Next we see how good a job can we do on segmentation (a fall-back when can’t use the word recognition model).
• Robustness might require both approaches (multiple algorithms again!)

UC Berkeley CS294-9 Fall 2000 11- 9
Formalize the word recognition problem (TKHo)
Machine printed, ordinary fonts (var. width)• Cut down on the variations
– NOT:
• A word is all in same font/size [shape= feature]• [we could trivialize task with one font, e.g. E-13B]
• Known lexicon (say 100,000 English words)• 26^6 is 308 million; our lexicon is < 0.3% of this• [trivialize with 1 item (check the box, say “yes”..)]
• Applications in mind: post office, UNLV bakeoff

UC Berkeley CS294-9 Fall 2000 11- 10
Word Recognition: Objective

UC Berkeley CS294-9 Fall 2000 11- 11
At Least Three Approaches
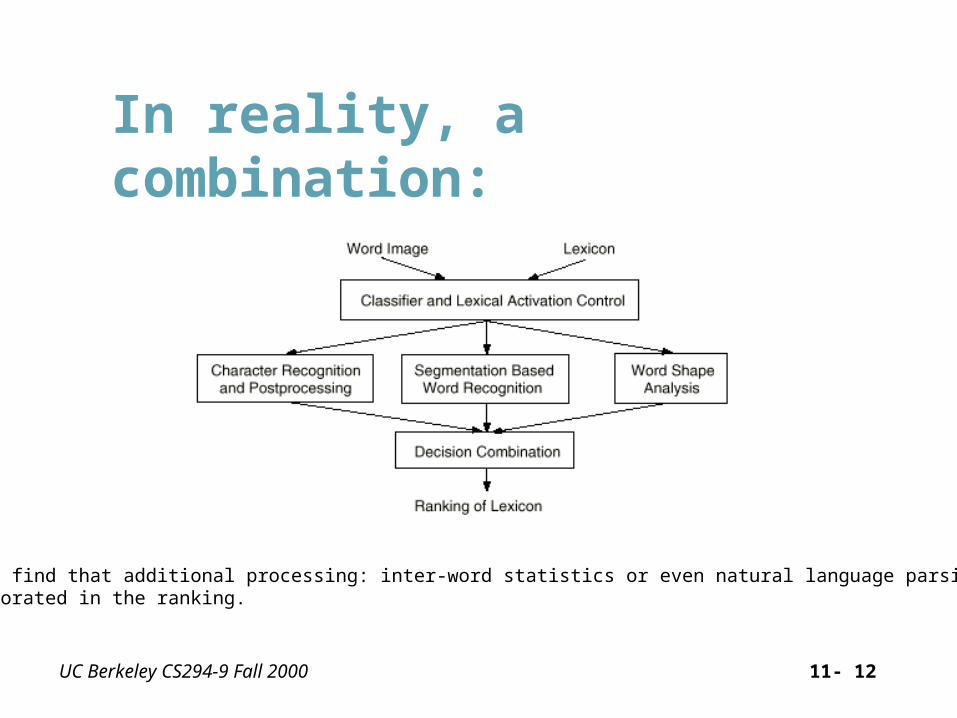
UC Berkeley CS294-9 Fall 2000 11- 12
In reality, a combination:
Later we will find that additional processing: inter-word statistics or even natural language parsing may be incorporated in the ranking.
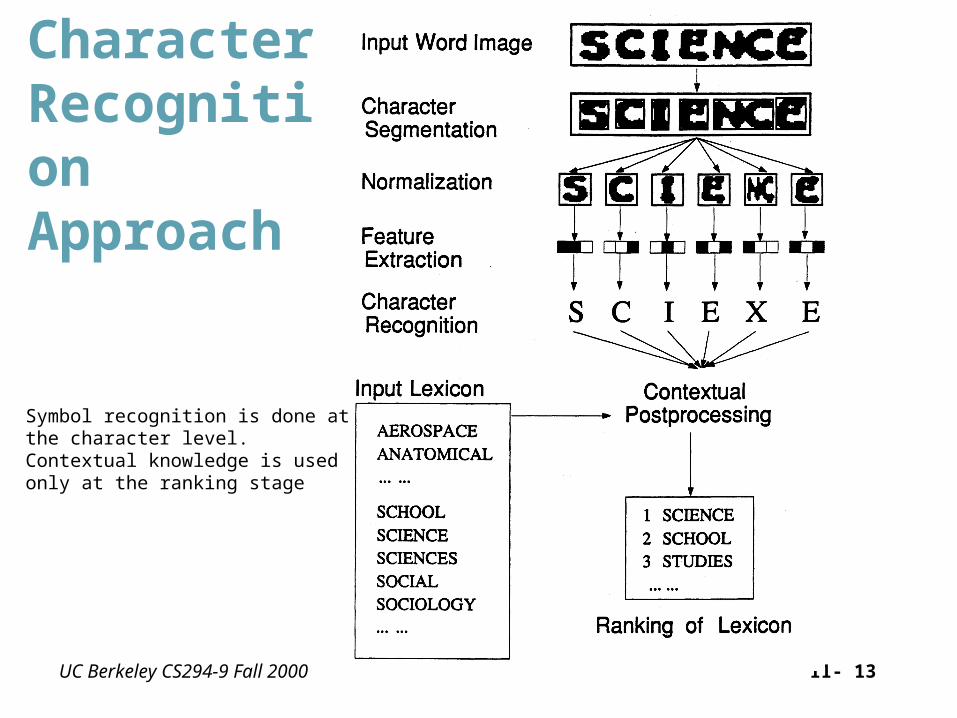
UC Berkeley CS294-9 Fall 2000 11- 13
CharacterRecognitionApproach
Symbol recognition is done at the character level.Contextual knowledge is used only at the ranking stage

UC Berkeley CS294-9 Fall 2000 11- 14
One error in character segmentation can distort many characters
Input word image
Character Segmentation
Segmented and normalized characters
Recognition decisions

UC Berkeley CS294-9 Fall 2000 11- 15
How to segment words to characters?
•Aspect ratio (fixed width, anyway)•Projection profile•Other tricks

UC Berkeley CS294-9 Fall 2000 11- 16
Projection Profiles
UC Berkeley CS294-9 Fall 2000 11- 17
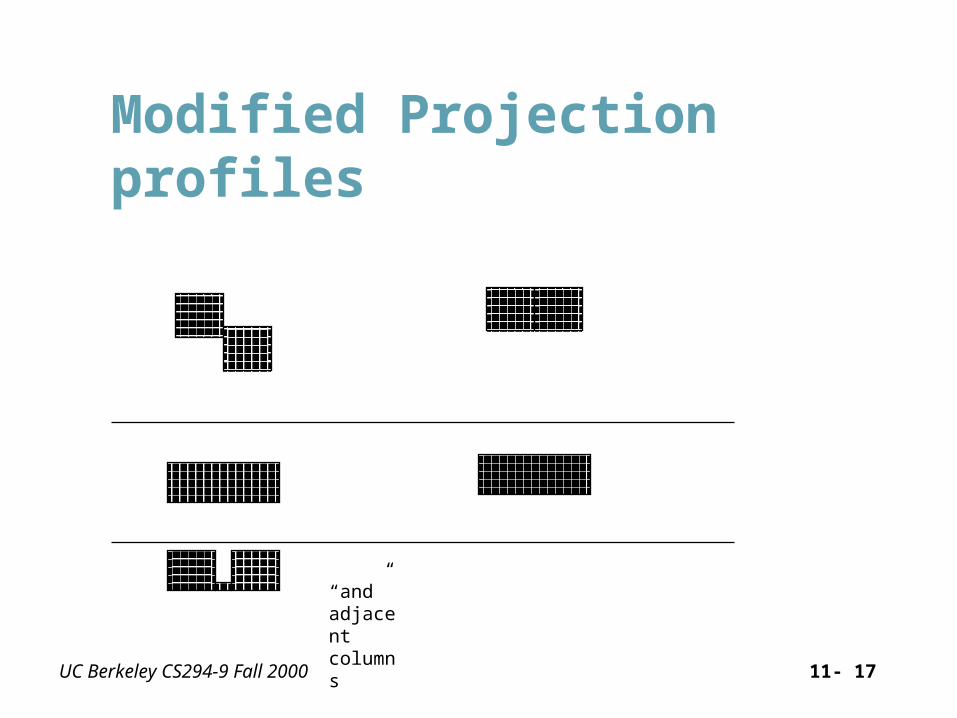
Modified Projection profiles
“and” adjacent columns

UC Berkeley CS294-9 Fall 2000 11- 18
Poor images: confusing profiles

UC Berkeley CS294-9 Fall 2000 11- 19
The argument for more context
Similar shapes in different contexts, in each case different characters, or parts of them.

UC Berkeley CS294-9 Fall 2000 11- 20
Segmentation- basedApproach
Segment the word to characters. Extract the features from normalized charcter images. Concatenate the feature vectors to form a word feature vector. The character features are compared in the context of a word.
(Works if segmentation is easy but characters are difficult to recognize in isolation)
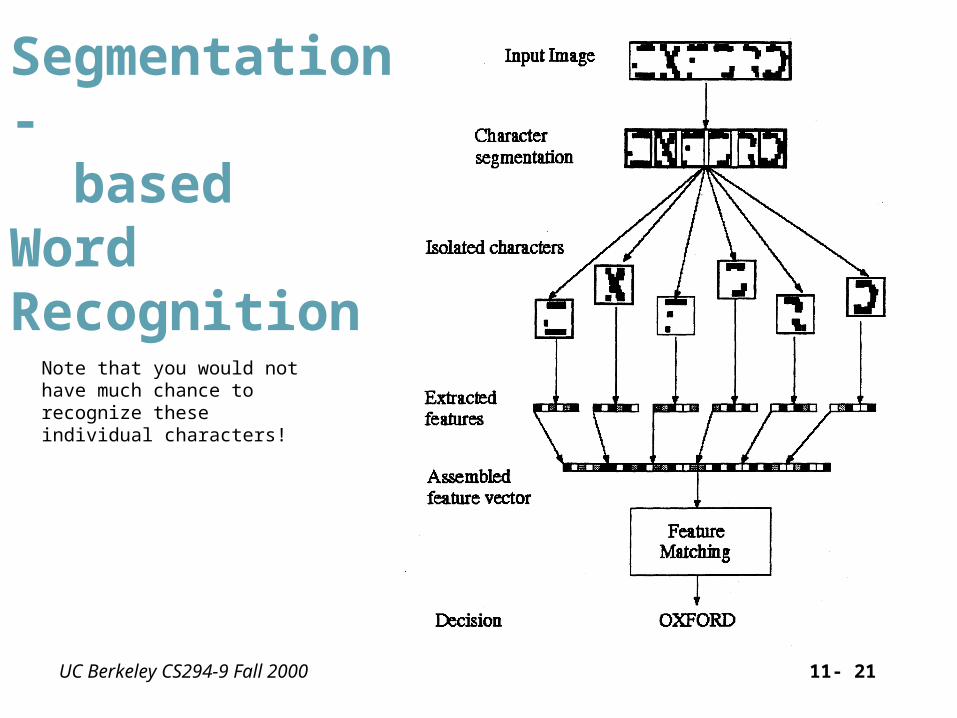
UC Berkeley CS294-9 Fall 2000 11- 21
Segmentation- basedWordRecognition
Note that you would not have much chance to recognize these individual characters!
UC Berkeley CS294-9 Fall 2000 11- 22
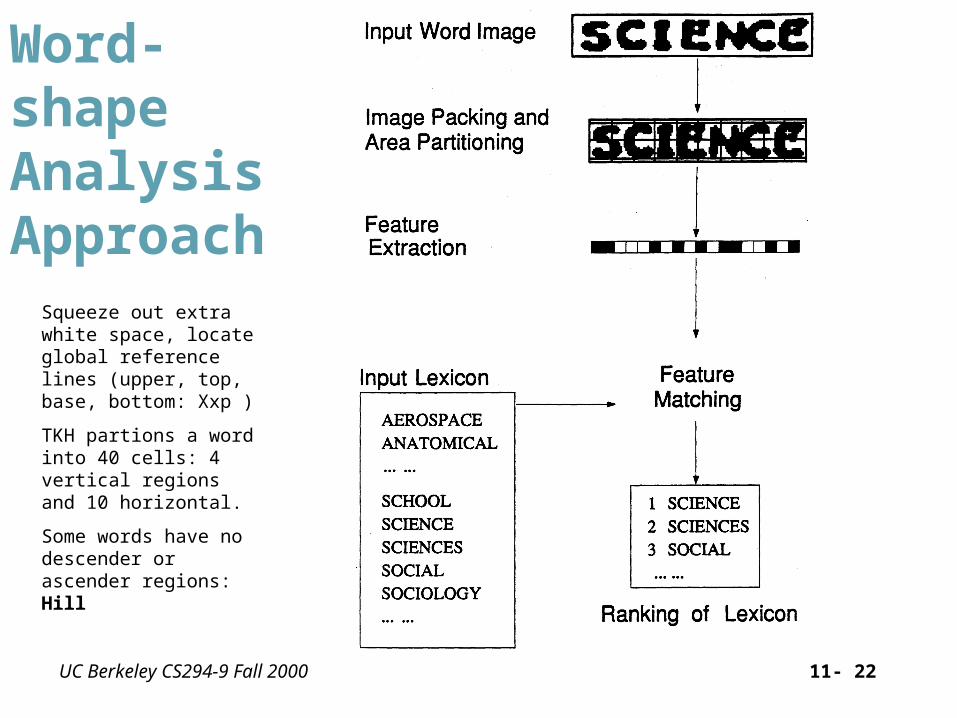
Word-shapeAnalysisApproach
Squeeze out extra white space, locate global reference lines (upper, top, base, bottom: Xxp )
TKH partions a word into 40 cells: 4 vertical regions and 10 horizontal.
Some words have no descender or ascender regions: Hill
UC Berkeley CS294-9 Fall 2000 11- 23
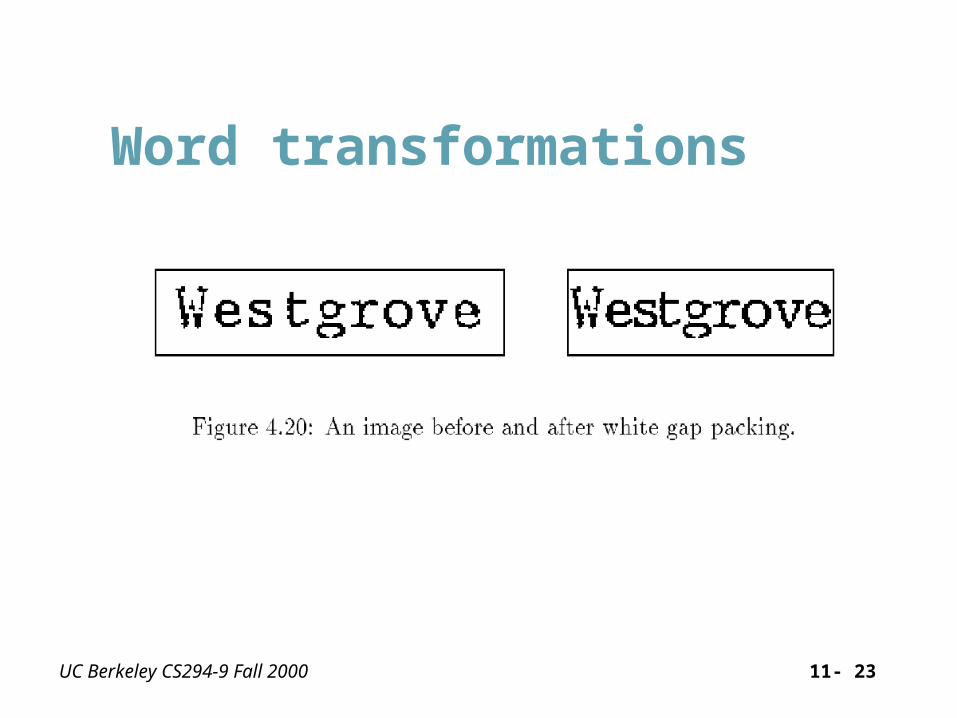
Word transformations

UC Berkeley CS294-9 Fall 2000 11- 24
Detecting base, upper, top by smearing

UC Berkeley CS294-9 Fall 2000 11- 25
The 40 area partitions

UC Berkeley CS294-9 Fall 2000 11- 26
Stroke Directions

UC Berkeley CS294-9 Fall 2000 11- 27
Edges, Endpoints

UC Berkeley CS294-9 Fall 2000 11- 28
Cases Each Approach isBest At …

UC Berkeley CS294-9 Fall 2000 11- 29
Most effective features?
•Best: Defined locally, yet containing shape information: stroke vectors, Baird templates
•Less effective: very high level “holes”; very low level “pixel values”
•Uncertainly/ partial matching is important/•TK Ho..

UC Berkeley CS294-9 Fall 2000 11- 30
TKHo’s experiments
•Context: Zip code recognition•Redundancy check requires reading the whole address•33850 Postal words•Character recognizer trained on 19151 images•77 font samples were used to make prototypes

UC Berkeley CS294-9 Fall 2000 11- 31
TKHo’s experiments
Five (10?) methods used in parallel1. A fuzzy character template matcher
plus heuristic contextual postprocessor
2. Six character recognizers3. Segmentation-based word
recognizer using pixel values4. Word shape analyzer using strokes5. Word shape analyzer using Baird
templates

UC Berkeley CS294-9 Fall 2000 11- 32
TKHo’s experiments
Many interesting conclusions..1. If several methods agree, they are
almost always (99.6%) correct or right on second choice (100%)
2. Classifiers can be dynamically selected


















