
Distributed Computing COEN 317 DC2: Naming, part 1.
22
Distributed Computing COEN 317 DC2: Naming, part 1
-
Upload
preston-bartholomew-doyle -
Category
Documents
-
view
224 -
download
0
Transcript of Distributed Computing COEN 317 DC2: Naming, part 1.

Distributed Computing
COEN 317
DC2: Naming, part 1

Topics
• What’s in a Name?
• Naming Objects
• Finding Objects (directories) chapter 9

Name Space
• Name Space is a general term used for the “space” of all possible names using given rules or constructions.
• For example, “names” are 4 letter words, no numbers or other characters. The name space includes 264 symbols so we can name that many objects in this name space.

What is a Name?
• Something that:• Identifies a resource
– Uniquely?– Describes the resource?
• Enables us to locate that resource– Directly?– With help?
• How is the name used? – Disambiguate? Access? Locate?

Names
• Must humans remember or recognize it?
• Is resource static?– Never moves– Change in location should change name– Resource may move– Resource is mobile
• Name vs Identifier vs Address

Identifier and Address
• Globally unique identifier (no hierarchy)– Ethernet– Solves identification, but not description or
location
• Hierarchically assigned globally unique identifier (hierarchy is location-based)– Telephone number, IP address– Solves identification, not description– Helps with location, need local directories

Names, Identifiers, Addresses
• Domain Name System (DNS) for the Internet is widely accepted standard– Hierarchically assigned globally unique– Hierarchy is descriptive– Only names machines– Doesn’t handle mobility

Distributed Database Example: R*
• R* developed at IBM Almaden Research – first distributed relational database
• Wanted mobility of resources– Supports fault tolerance– But movement rare
• Performance is critical• Solution: Two components to name
– Unique ID assigned by “birthplace”– Local catalog maps ID to:
• Birthplace (maintains current location)• Presumed current location

Security Considerations
• Does name give away information?– Social Security Numbers– URL– Batched IDs (e.g., Ethernet)– Sequentially assigned IDs
• Solution: Define what name SHOULD do– Ensure it meets goals– Look for reasons it doesn’t

Directories
• Unless you use physical locations for names and objects never move, you will need directories.
• How to organize?
• Who uses it? How often?
• How to modify (when object moves)?

Domain Name Service
• A distributed naming database
• Name structure reflects administrative structure of the Internet
• Rapidly resolves domain names to IP addresses
– exploits caching heavily
– typical query time ~100 milliseconds
• Scales to millions of computers
– partitioned database
– caching
• Resilient to failure of a server
– replication

DNS Name Space Distribution
• An example partitioning of the DNS name space, including Internet-accessible files, into three layers.

Basic DNS algorithm
• DNS algorithm for name resolution (domain name -> IP number)
• Look for the name in the local cache
• Try a superior DNS server, which responds with:– another recommended DNS server– the IP address (which may not be entirely up
to date)

DNS Servers
• Main function is to resolve domain names for computers, i.e. to get their IP addresses– caches the results of previous searches until they
pass their 'time to live'
• Other functions:– get mail host for a domain – reverse resolution - get domain name from IP address– Host information - type of hardware and OS– Well-known services - a list of well-known services
offered by a host– Other attributes can be included (optional)

Iterative Name Resolution
• Iterative name resolution.

Iterative Name Resolution
• Reason for NFS iterative name resolution• This is because the file service may encounter a
symbolic link (i.e. an alias) when resolving a name. A symbolic link must be interpreted in the client’s file system name space because it may point to a file in a directory stored at another server. The client computer must determine which server this is, because only the client has the info.

Recursive Name Resolution
In recursive name resolution, the root name server does more work, but can cache intermediate results for future requests.

Name Resolution
• The comparison between recursive and iterative name resolution with respect to communication costs.

DNS Issues
• Name tables change infrequently, but when they do, caching can result in the delivery of stale data.– Clients are responsible for detecting this and recovering
• Its design makes changes to the structure of the name space difficult. For example:– merging previously separate domain trees under a new root
– moving subtrees to a different part of the structure (e.g. if Scotland became a separate country, its domains should all be moved to a new country-level domain.
• See Section 9.4 on GNS, a research system that solves the above issues.
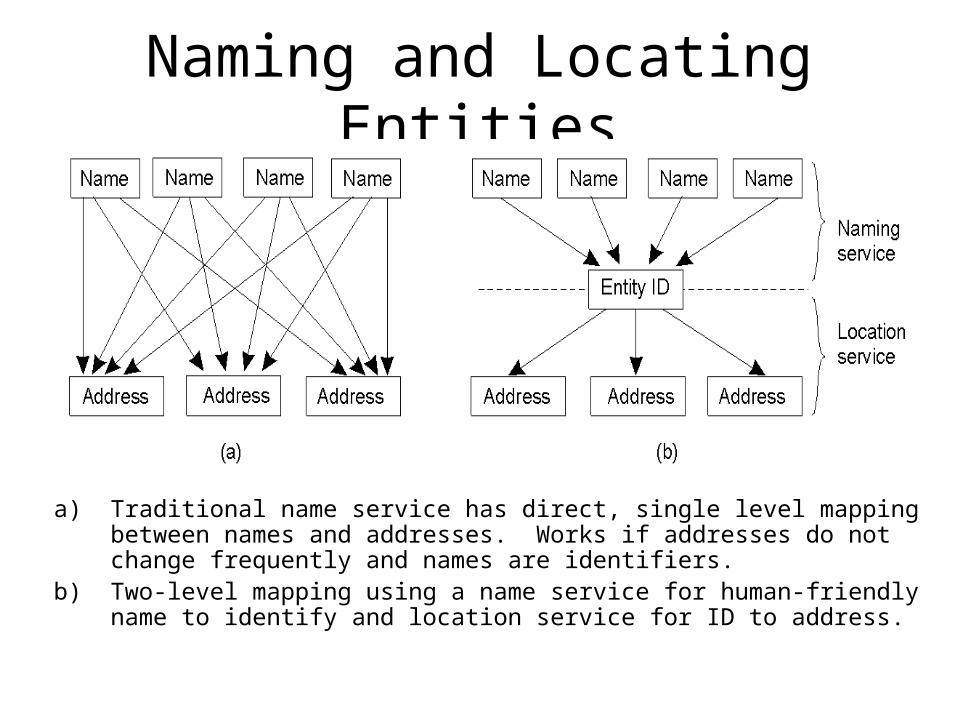
Naming and Locating Entities
a) Traditional name service has direct, single level mapping between names and addresses. Works if addresses do not change frequently and names are identifiers.
b) Two-level mapping using a name service for human-friendly name to identify and location service for ID to address.

Home-Based Approaches
• The principle of Mobile IP.

Directory vs Discovery Services
• Directory service:- 'yellow pages' for the resources in a network
– Retrieves the set of names that satisfy a given description
– e.g. X.500, LDAP, MS Active Directory Services• (DNS holds some descriptive data, but:
– the data is very incomplete
– DNS isn't organised to search it)
• Discovery service:- a directory service that also:
– is automatically updated as the network configuration changes
– meets the needs of clients in spontaneous networks
– discovers services required by a client (who may be mobile) within the current scope, for example, to find the most suitable printing service for image files after arriving at a hotel.
– Example of discovery service: Jini discovery service.


















