Distributed Cache With MapReduce
32
www.edureka.co/big-data-and-hadoop Distributed Cache With Map Reduce View Big Data and Hadoop Course at: http:// www.edureka.co/big-data-and-hadoop For more details please contact us: US : 1800 275 9730 (toll free) INDIA : +91 88808 62004 Email Us : [email protected] For Queries: Post on Twitter @edurekaIN: #askEdureka Post on Facebook /edurekaIN
-
Upload
edureka -
Category
Technology
-
view
262 -
download
0
Transcript of Distributed Cache With MapReduce

www.edureka.co/big-data-and-hadoop
Distributed Cache With Map Reduce
View Big Data and Hadoop Course at: http://www.edureka.co/big-data-and-hadoop
For more details please contact us: US : 1800 275 9730 (toll free)INDIA : +91 88808 62004Email Us : [email protected]
For Queries: Post on Twitter @edurekaIN: #askEdurekaPost on Facebook /edurekaIN
Slide 2 www.edureka.co/big-data-and-hadoop
Objectives
Analyze different use-cases where MapReduce is used
Differentiate between Traditional way and MapReduce way
Learn about Hadoop 2.x MapReduce architecture and components
Understand execution flow of YARN MapReduce application
What is Distributed Cache
Run a MapReduce Program with Distributed cache
At the end of this module, you will be able to

Slide 3 www.edureka.co/big-data-and-hadoop
Where MapReduce is Used?
Weather Forecasting
HealthCare
Problem Statement:» De-identify personal health information.
Problem Statement:» Finding Maximum temperature recorded in a year.
Slide 4 www.edureka.co/big-data-and-hadoop
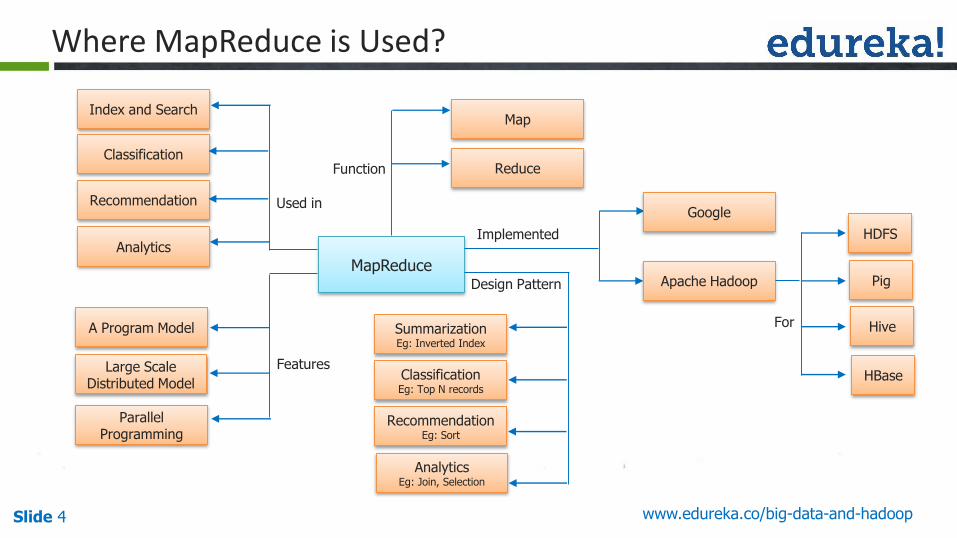
Where MapReduce is Used?
MapReduce
FeaturesLarge Scale Distributed Model
Used in
Function
Design Pattern
Parallel Programming
A Program Model
Classification
Analytics
Recommendation
Index and SearchMap
Reduce
ClassificationEg: Top N records
AnalyticsEg: Join, Selection
RecommendationEg: Sort
SummarizationEg: Inverted Index
Implemented
Apache Hadoop
HDFS
Pig
Hive
HBase
For
Slide 5 www.edureka.co/big-data-and-hadoop
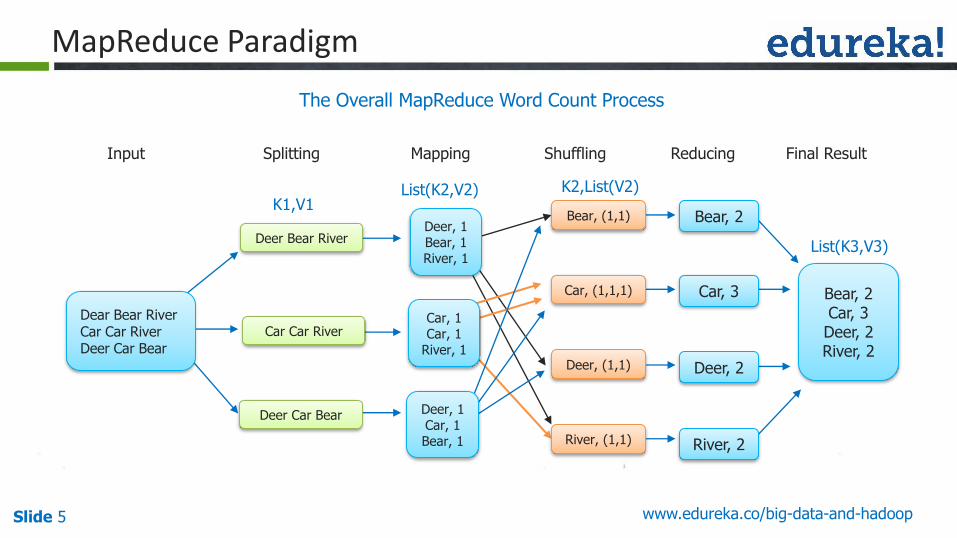
MapReduce Paradigm
The Overall MapReduce Word Count Process
Input Splitting Mapping Shuffling Reducing Final Result
List(K3,V3)Deer Bear River
Dear Bear RiverCar Car RiverDeer Car Bear
Bear, 2Car, 3Deer, 2River, 2
Deer, 1Bear, 1River, 1
Car, 1Car, 1
River, 1
Deer, 1Car, 1Bear, 1
K2,List(V2)List(K2,V2)K1,V1
Car Car River
Deer Car Bear
Bear, 2
Car, 3
Deer, 2
River, 2
Bear, (1,1)
Car, (1,1,1)
Deer, (1,1)
River, (1,1)

Slide 6 www.edureka.co/big-data-and-hadoop
MapReduce Application Execution
Executing MapReduce Application on YARN

Slide 7 www.edureka.co/big-data-and-hadoop
YARN MR Application Execution Flow
MapReduce Job Execution
» Job Submission
» Job Initialization
» Tasks Assignment
» Memory Assignment
» Status Updates
» Failure Recovery

Slide 8 www.edureka.co/big-data-and-hadoop
YARN MR Application Execution Flow
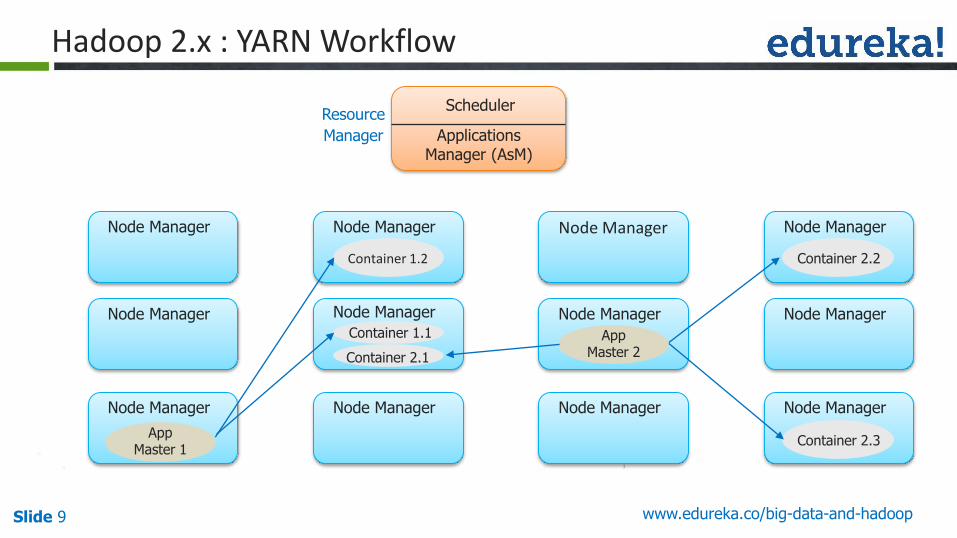
11.Task get Executed.
12.If any reducer in a Job Reducer, again AppMaster Request the Node Manager to start the and Allocate Container
13.Output of All the Maps given to reducer and Reducer get executed
14.Once Job finished, Application Master notify the Resource Manager and Client Library
15.Application Master closed.
Slide 9 www.edureka.co/big-data-and-hadoop
Hadoop 2.x : YARN Workflow
Node Manager
Node Manager
Node Manager
Node Manager
Node Manager
Node Manager
Node Manager
Node Manager
Node Manager
Node Manager
Node Manager
Node Manager
Container 1.2
Container 1.1
Container 2.1
Container 2.2
Container 2.3
AppMaster 2
AppMaster 1
Scheduler
Applications Manager (AsM)
Resource
Manager
Slide 10 www.edureka.co/big-data-and-hadoop
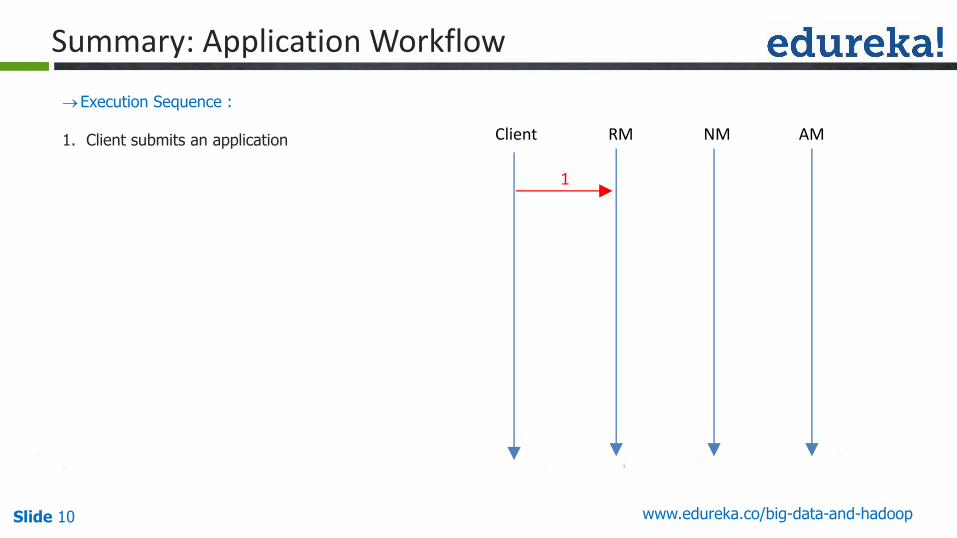
Summary: Application Workflow
Execution Sequence :
1. Client submits an application Client RM NM AM
1
Slide 11 www.edureka.co/big-data-and-hadoop
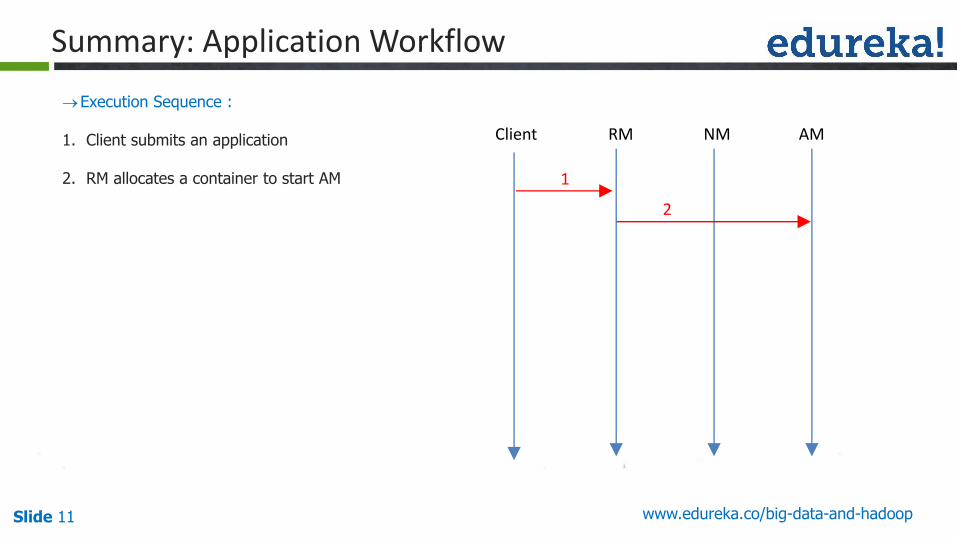
Summary: Application Workflow
Execution Sequence :
1. Client submits an application
2. RM allocates a container to start AM
Client RM NM AM
1
2
Slide 12 www.edureka.co/big-data-and-hadoop
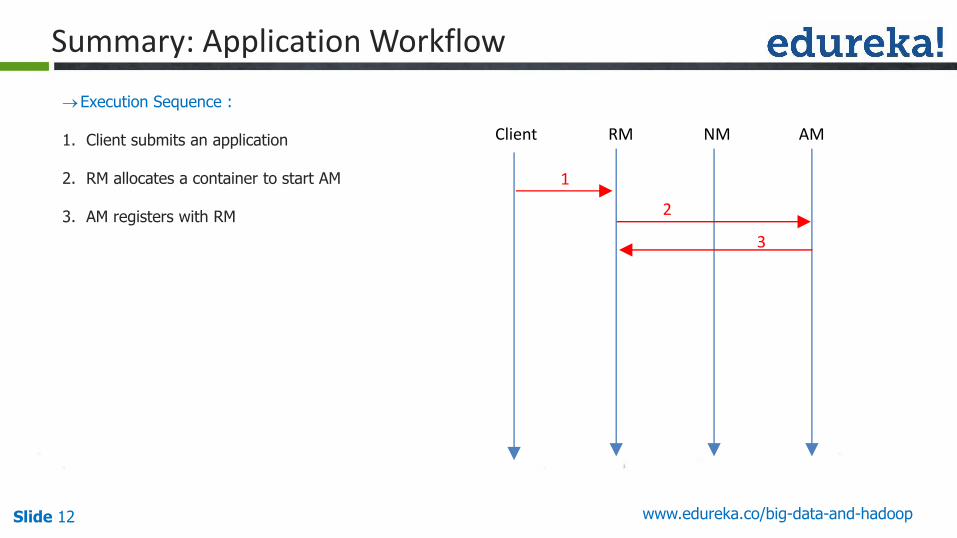
Summary: Application Workflow
Execution Sequence :
1. Client submits an application
2. RM allocates a container to start AM
3. AM registers with RM
Client RM NM AM
1
2
3

Slide 13 www.edureka.co/big-data-and-hadoop
Summary: Application Workflow
Execution Sequence :
1. Client submits an application
2. RM allocates a container to start AM
3. AM registers with RM
4. AM asks containers from RM
Client RM NM AM
1
2
3
4
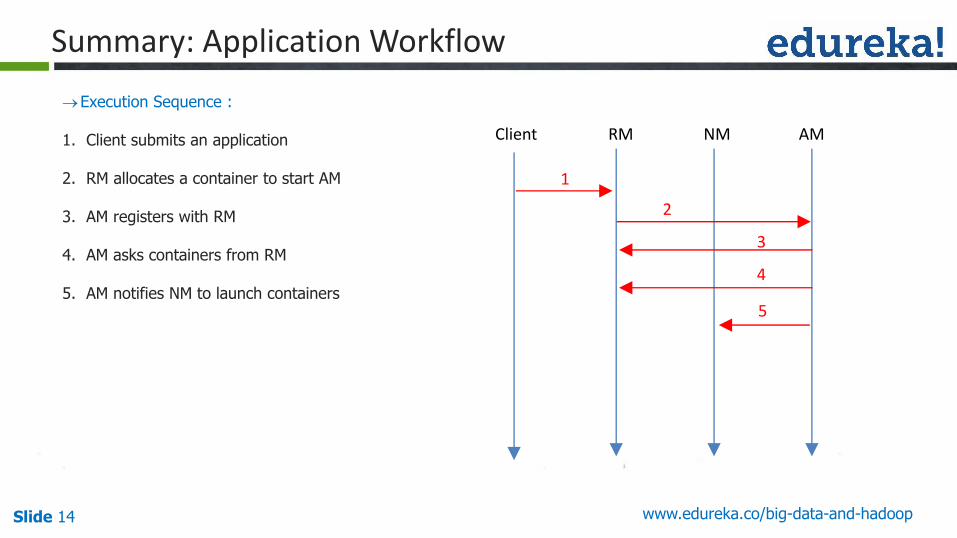
Slide 14 www.edureka.co/big-data-and-hadoop
Summary: Application Workflow
Execution Sequence :
1. Client submits an application
2. RM allocates a container to start AM
3. AM registers with RM
4. AM asks containers from RM
5. AM notifies NM to launch containers
Client RM NM AM
1
2
3
4
5
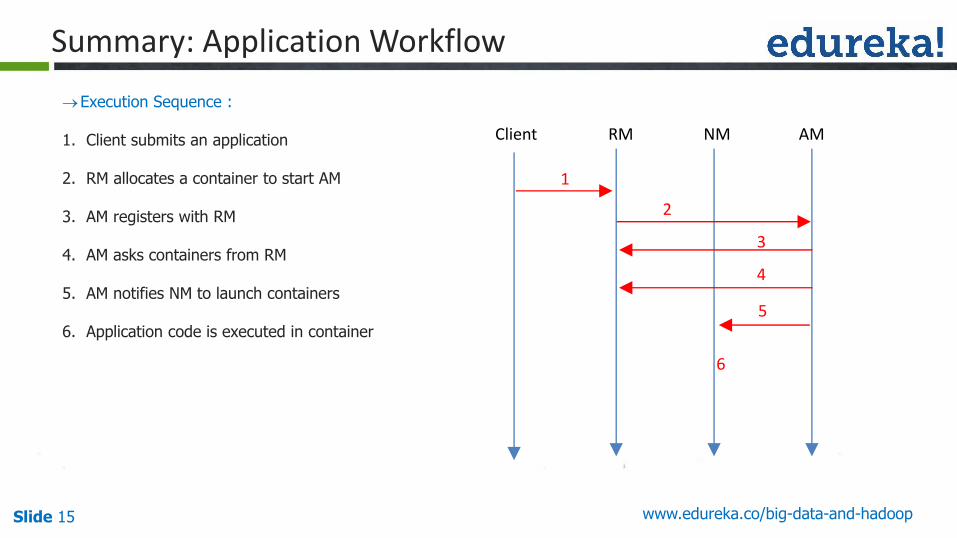
Slide 15 www.edureka.co/big-data-and-hadoop
Summary: Application Workflow
Execution Sequence :
1. Client submits an application
2. RM allocates a container to start AM
3. AM registers with RM
4. AM asks containers from RM
5. AM notifies NM to launch containers
6. Application code is executed in container
Client RM NM AM
1
2
3
4
5
6
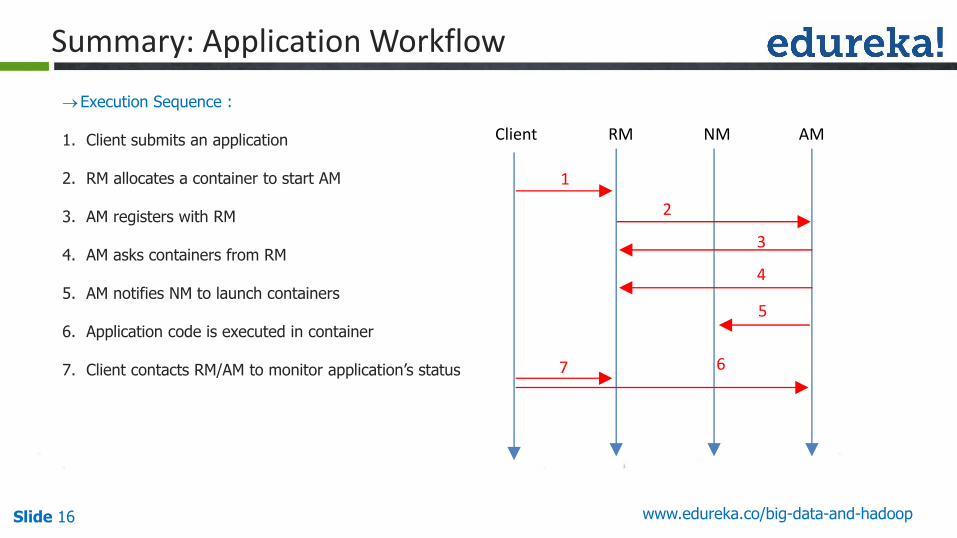
Slide 16 www.edureka.co/big-data-and-hadoop
Summary: Application Workflow
Execution Sequence :
1. Client submits an application
2. RM allocates a container to start AM
3. AM registers with RM
4. AM asks containers from RM
5. AM notifies NM to launch containers
6. Application code is executed in container
7. Client contacts RM/AM to monitor application’s status
Client RM NM AM
1
2
3
4
5
7 6
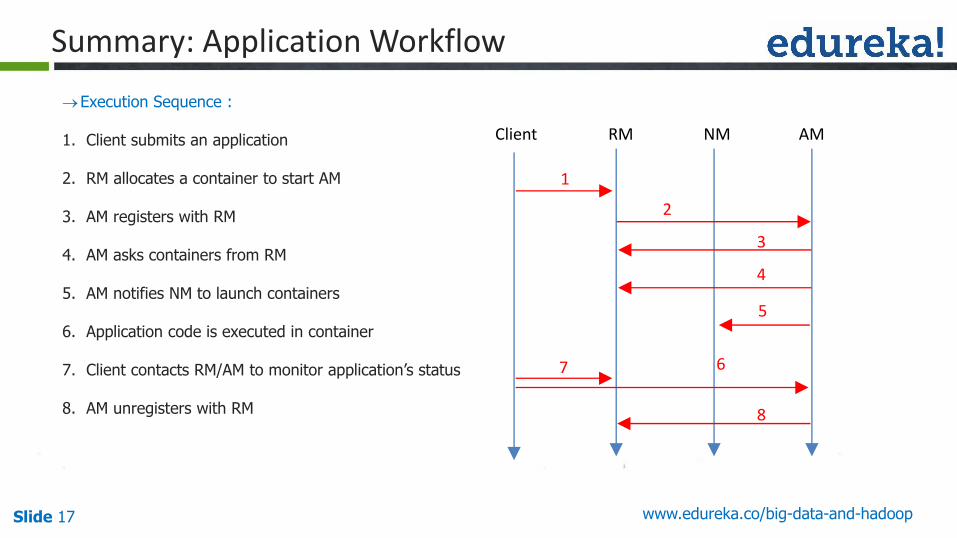
Slide 17 www.edureka.co/big-data-and-hadoop
Summary: Application Workflow
Execution Sequence :
1. Client submits an application
2. RM allocates a container to start AM
3. AM registers with RM
4. AM asks containers from RM
5. AM notifies NM to launch containers
6. Application code is executed in container
7. Client contacts RM/AM to monitor application’s status
8. AM unregisters with RM
Client RM NM AM
1
2
3
4
5
7
8
6
Slide 18 www.edureka.co/big-data-and-hadoop
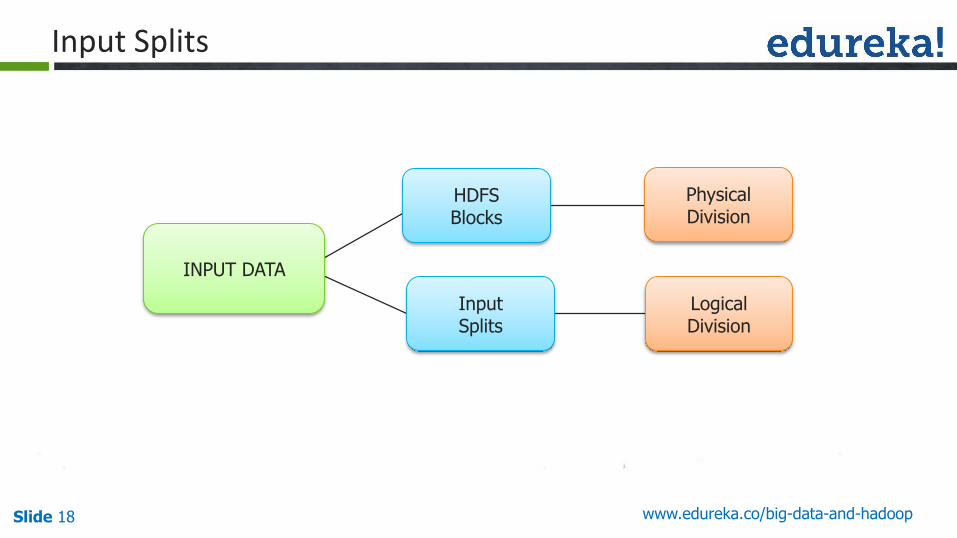
Input Splits
INPUT DATA
PhysicalDivision
LogicalDivision
HDFSBlocks
InputSplits
Slide 19 www.edureka.co/big-data-and-hadoop
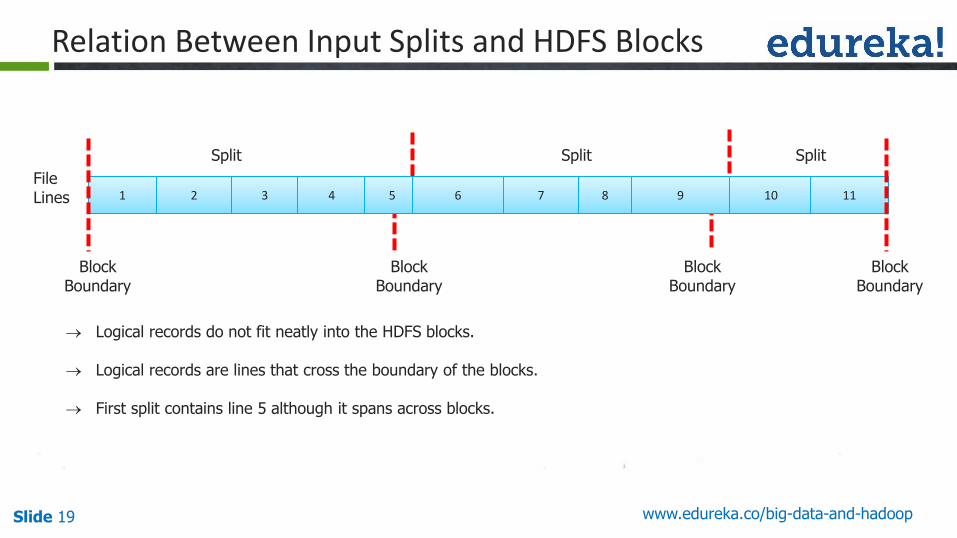
Relation Between Input Splits and HDFS Blocks
1 2 3 4 5 6 7 8 9 10 11
Logical records do not fit neatly into the HDFS blocks.
Logical records are lines that cross the boundary of the blocks.
First split contains line 5 although it spans across blocks.
FileLines
BlockBoundary
BlockBoundary
BlockBoundary
BlockBoundary
Split Split Split
Slide 20 www.edureka.co/big-data-and-hadoop
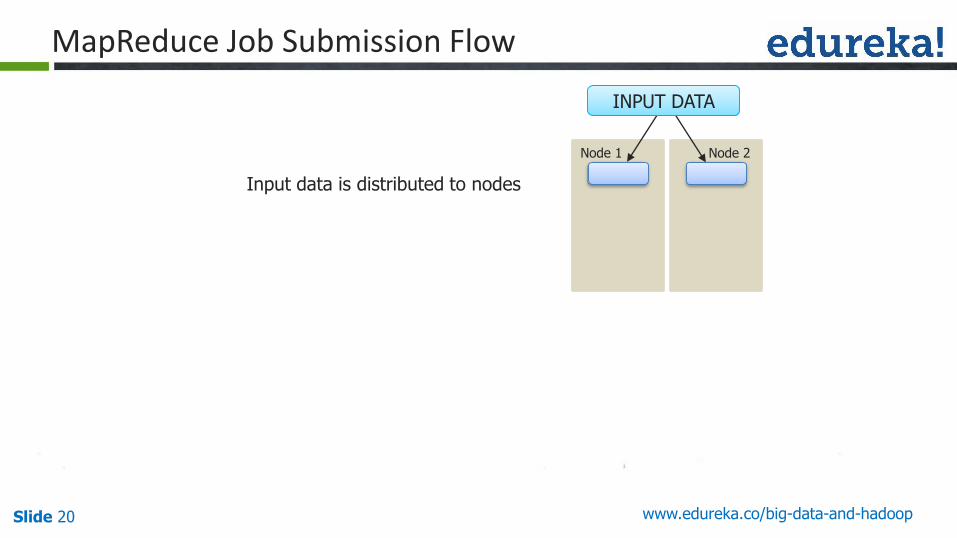
MapReduce Job Submission Flow
Input data is distributed to nodes
Node 1 Node 2
INPUT DATA
Slide 21 www.edureka.co/big-data-and-hadoop
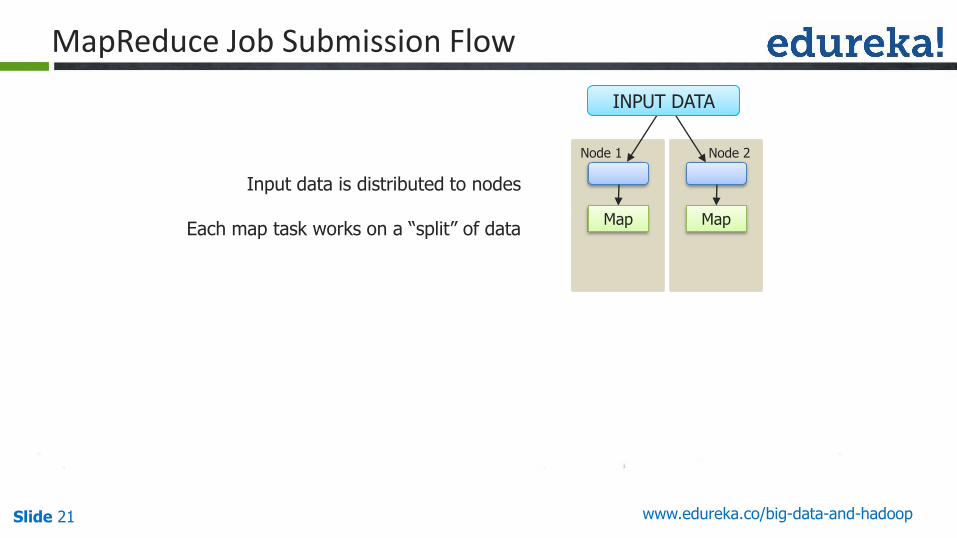
MapReduce Job Submission Flow
Input data is distributed to nodes
Each map task works on a “split” of dataMap
Node 1
Map
Node 2
INPUT DATA
Slide 22 www.edureka.co/big-data-and-hadoop
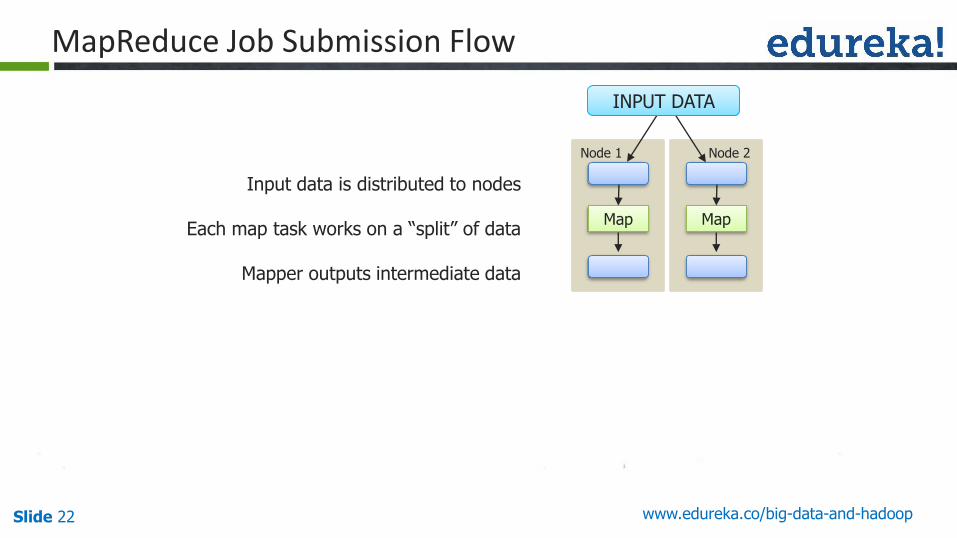
MapReduce Job Submission Flow
Input data is distributed to nodes
Each map task works on a “split” of data
Mapper outputs intermediate data
Map
Node 1
Map
Node 2
INPUT DATA
Slide 23 www.edureka.co/big-data-and-hadoop
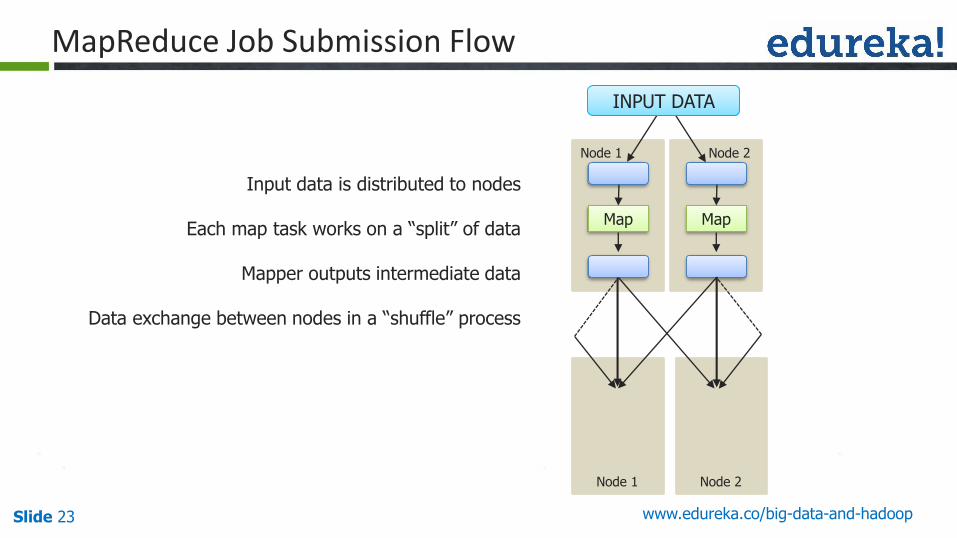
MapReduce Job Submission Flow
Input data is distributed to nodes
Each map task works on a “split” of data
Mapper outputs intermediate data
Data exchange between nodes in a “shuffle” process
Map
Node 1
Map
Node 2
Node 1 Node 2
INPUT DATA
Slide 24 www.edureka.co/big-data-and-hadoop
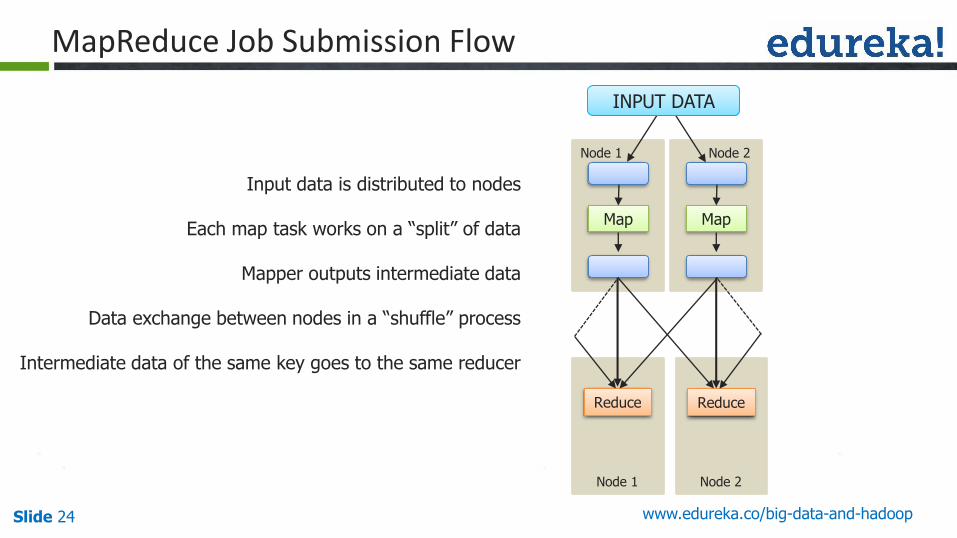
MapReduce Job Submission Flow
Input data is distributed to nodes
Each map task works on a “split” of data
Mapper outputs intermediate data
Data exchange between nodes in a “shuffle” process
Intermediate data of the same key goes to the same reducer
Map
Node 1
Map
Node 2
Reduce
Node 1
Reduce
Node 2
INPUT DATA
Slide 25 www.edureka.co/big-data-and-hadoop
MapReduce Job Submission Flow
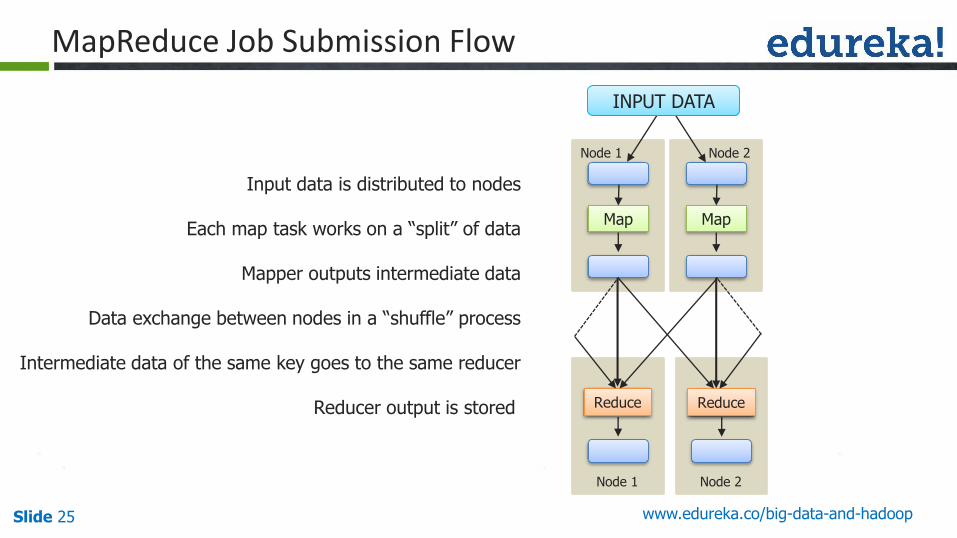
Input data is distributed to nodes
Each map task works on a “split” of data
Mapper outputs intermediate data
Data exchange between nodes in a “shuffle” process
Intermediate data of the same key goes to the same reducer
Reducer output is stored
Map
Node 1
Map
Node 2
Reduce
Node 1
Reduce
Node 2
INPUT DATA
Slide 26 www.edureka.co/big-data-and-hadoop
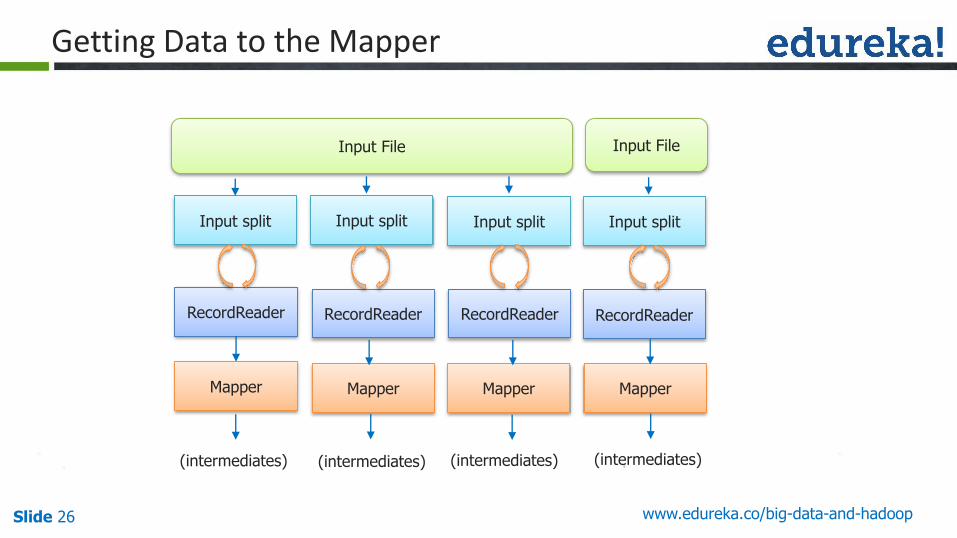
Getting Data to the Mapper
Input File Input File
Input split Input split Input split Input split
RecordReader RecordReader RecordReader RecordReader
Mapper Mapper Mapper Mapper
(intermediates) (intermediates) (intermediates) (intermediates)
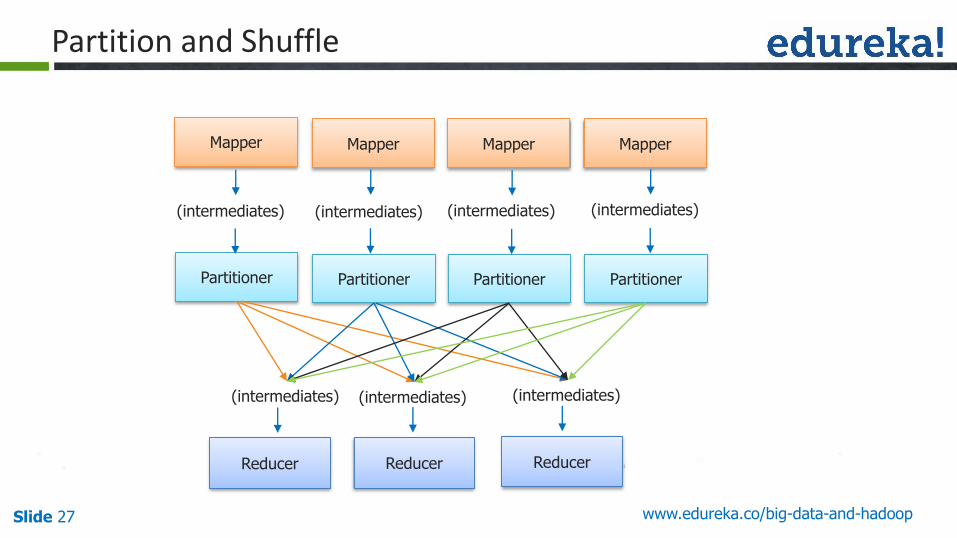
Slide 27 www.edureka.co/big-data-and-hadoop
Partition and Shuffle
Mapper Mapper Mapper Mapper
(intermediates) (intermediates) (intermediates) (intermediates)
Partitioner Partitioner Partitioner Partitioner
(intermediates) (intermediates) (intermediates)
Reducer Reducer Reducer
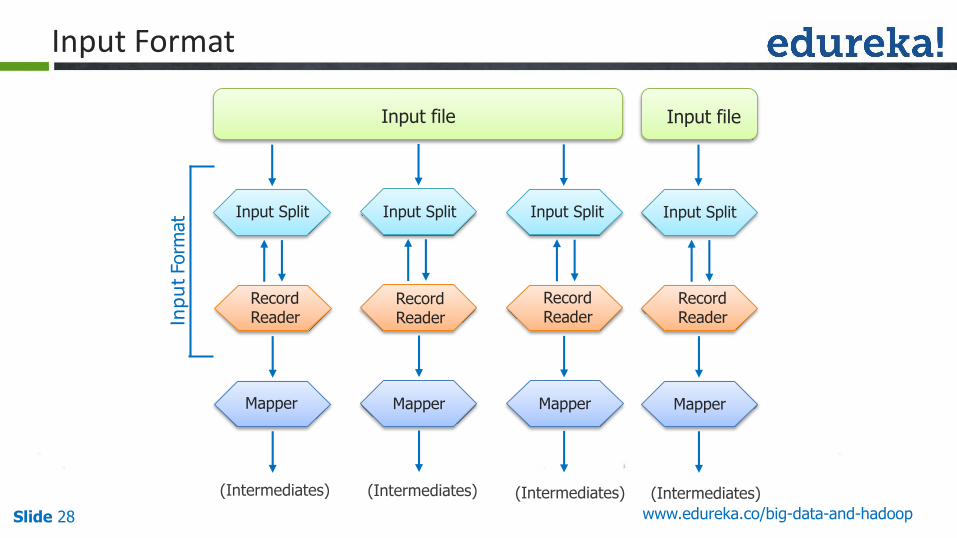
Slide 28 www.edureka.co/big-data-and-hadoop
Input file
Input Split Input Split Input Split
RecordReader
RecordReader
RecordReader
Mapper Mapper Mapper
(Intermediates) (Intermediates) (Intermediates)
Inp
ut
Form
at Input Split
RecordReader
Mapper
Input file
(Intermediates)
Input Format
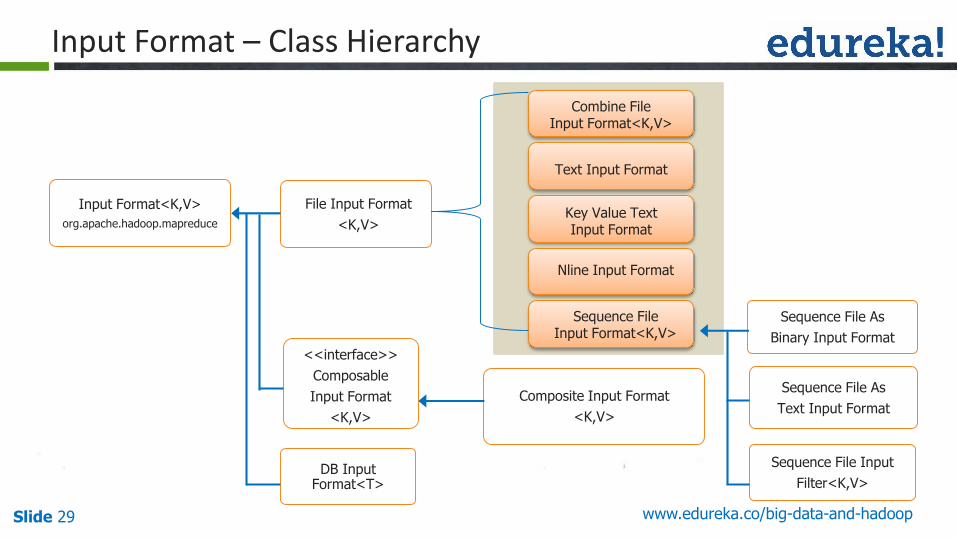
Slide 29 www.edureka.co/big-data-and-hadoop
Combine FileInput Format<K,V>
Text Input Format
Key Value Text Input Format
Nline Input Format
Sequence FileInput Format<K,V>
File Input Format
<K,V>
Input Format<K,V>
org.apache.hadoop.mapreduce
<<interface>>
Composable
Input Format
<K,V>
Composite Input Format
<K,V>
DB Input Format<T>
Sequence File As
Binary Input Format
Sequence File As
Text Input Format
Sequence File Input
Filter<K,V>
Input Format – Class Hierarchy

Slide 30 www.edureka.co/big-data-and-hadoop
What is Distributed cache
In computing, a distributed cache is an extension of the traditional concept of cache used in a single locale.
A distributed cache may span multiple servers so that it can grow in size and in transactional capacity.
The idea of distributed caching has become feasible now because main memory has become very cheap and
network cards have become very fast.
Distribute application-specific large, read-only files efficiently.
Distributed Cache is a facility provided by the Map-Reduce framework to cache files (text, archives, jars etc.)
needed by applications.

Slide 31 www.edureka.co/big-data-and-hadoop
Demo
Demo: Bulk Load with MR