

Distilling Insights @ Appsflyer
25
Distilling insights @ Arnon RotemGalOz Chief Data Officer
-
Upload
arnon-rotem-gal-oz -
Category
Technology
-
view
824 -
download
3
Transcript of Distilling Insights @ Appsflyer

Distilling insights @
Arnon Rotem-‐Gal-‐OzChief Data Officer



Kafka
Columnar Database(Redshift- evaluating Vertica)
IMDG(Ignite - evaluating Geode)
Secor
Spark
Aggregations
SparkSQL(evaluating
Drill, Presto)
SQL
SQL
Raw(sequence
files)
DW(parquet
files)
DM(Aggregations)
Application dashboard
Self-serveBI
(TBD)SparkETLSparkSparkML
Latest Events
Scoring
exploration
Agg. logic
Internal tools
installs clicksinapplaunches
Accounts

Data’s hierarchy of needs*
*With apologies to Maslow
Actedupon
presented
Distilled
Usable
Accessible
Exist

Exist

Kafka
Columnar Database(Redshift- evaluating Vertica)
IMDG(Ignite - evaluating Geode)
Secor
Spark
Aggregations
SparkSQL(evaluating
Drill, Presto)
SQL
SQL
Raw(sequence
files)
DW(parquet
files)
DM(Aggregations)
Application dashboard
Self-serveBI
(TBD)SparkETLSparkSparkML
Latest Events
Scoring
exploration
Agg. logic
Internal tools
installs clicksinapplaunches
Accounts

Kafka
Columnar Database(Redshift- evaluating Vertica)
IMDG(Ignite - evaluating Geode)
Secor
Spark
Aggregations
SparkSQL(evaluating
Drill, Presto)
SQL
SQL
Raw(sequence
files)
DW(parquet
files)
DM(Aggregations)
Application dashboard
Self-serveBI
(TBD)SparkETLSparkSparkML
Latest Events
Scoring
exploration
Agg. logic
Internal tools
installs clicksinapplaunches
Accounts

Working off of RAW data

“Malting”Just slap SQL on everything
Accessible

Kafka
Columnar Database(Redshift- evaluating Vertica)
IMDG(Ignite - evaluating Geode)
Secor
Spark
Aggregations
SparkSQL(evaluating
Drill, Presto)
SQL
SQL
Raw(sequence
files)
DW(parquet
files)
DM(Aggregations)
Application dashboard
Self-serveBI
(TBD)SparkETLSparkSparkML
Latest Events
Scoring
exploration
Agg. logic
Internal tools
installs clicksinapplaunches
Accounts

Fermenting
Usable
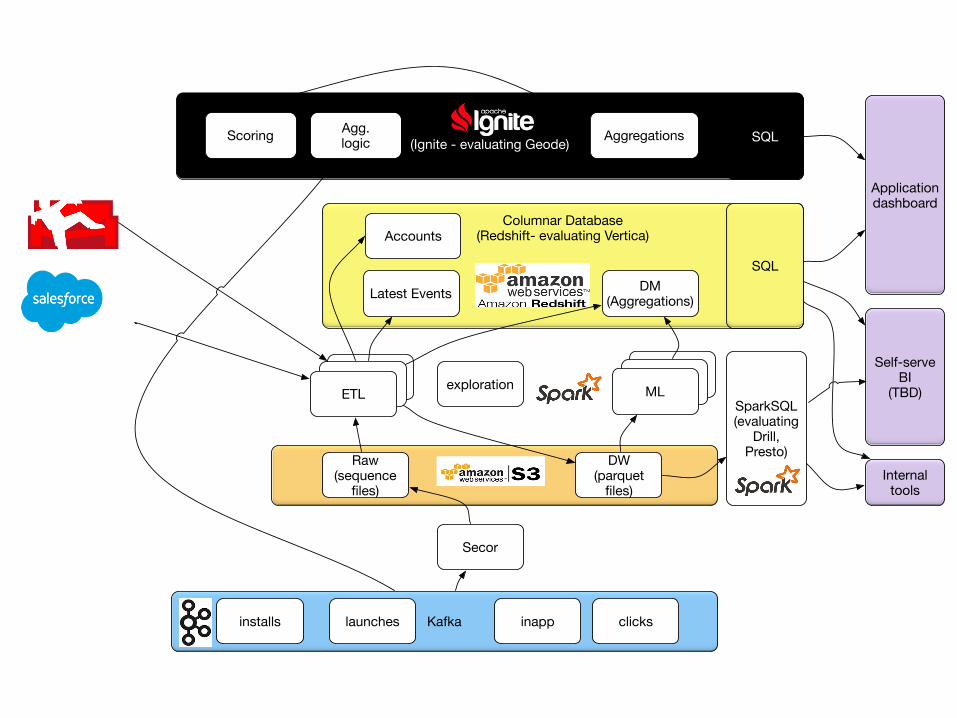
Kafka
Columnar Database(Redshift- evaluating Vertica)
IMDG(Ignite - evaluating Geode)
Secor
Spark
Aggregations
SparkSQL(evaluating
Drill, Presto)
SQL
SQL
Raw(sequence
files)
DW(parquet
files)
DM(Aggregations)
Application dashboard
Self-serveBI
(TBD)SparkETLSparkSparkML
Latest Events
Scoring
exploration
Agg. logic
Internal tools
installs clicksinapplaunches
Accounts

Distilling
Distilled

Kafka
Columnar Database(Redshift- evaluating Vertica)
IMDG(Ignite - evaluating Geode)
Secor
Spark
Aggregations
SparkSQL(evaluating
Drill, Presto)
SQL
SQL
Raw(sequence
files)
DW(parquet
files)
DM(Aggregations)
Application dashboard
Self-serveBI
(TBD)SparkETLSparkSparkML
Latest Events
Scoring
exploration
Agg. logic
Internal tools
installs clicksinapplaunches
Accounts

RT insights
Predictive
Prescriptive
Dashboards
whatnotpresented

Sidetrack:On use of Spark

Hadoop & Mesos


Land data in a queue

All data is time-‐series

Enrich with foreignkeys before persisting

Analyze and balance jobs

Not everything is big data

















