
Disguised Face Identification (DFI) with Facial KeyPoints...
27
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601
Transcript of Disguised Face Identification (DFI) with Facial KeyPoints...

Disguised Face Identification (DFI) with Facial KeyPoints using
Spatial Fusion Convolutional Network
Nathan Sun
CIS601

Introduction
• Face ID is complicated by alterations to an individual’s appearance• Beard, glasses, sunglasses, wig, hairstyle, hair color, hat, etc.
• Results in decreased performance
• Facial keypoints are required to analyze the shape of the face
• Two main state-of-the-art methods:1. Use feature extraction algorithm (e.g. Gabor features) with texture-based
and shape-based features to detect different facial key-points
2. Use probabilistic graphical models to capture relationship between pixels and features to detect facial key-points
• DNN used in this way is very challenge because datasets are small• Larger training dataset = better performance

Transfer Learning
• Lack of data means designers have to use transfer learning
• Transfer Learning is machine learning research problem where knowledge gained from solving a problem is applied to a different but related problem (e.g. knowledge gained identifying cars can be used to identify trucks)
• Performance might be sufficient but may under-perform because of data insufficiency resulting in inability to fine tune pre-trained DNNs

Contributions of this Paper
• Disguised Face Identification (DFI) Framework:
• Use Spatial Fusion Deep Convolutional Network (DCN) to extract 14 key-point (essential to describe facial structure)
• Extracted points connected to form star-net and orientations of points are used by classification framework for face ID
• Simple and Complex Face Disguise Datasets:
• Proposed 2 simple and complex Face Disguise (FG) datasets that can be used by researchers in future to train DCN for facial key-point detection

14 Essential Facial key-points (S. Zhang et al. 2016)

Simple and Complex Face Disguise Datasets• Databases for disguise related
research have limited disguise variations
• DCN requires images of people with beard, glasses, different hairstyles, scarf, cap, etc.
• Propose two Face Disguise datasets of 2000 photos each with Simple and Complex backgrounds and varied illuminations
• 8 different backgrounds, 25 subjects, 10 different disguises
• Notice how complex backgrounds = higher % of background in picture as a whole

Convolutional Neural Networks: A Review

Overview of DCN Process
• 8 convolution layers to extract increasingly specific data
• End in Loss 1 function (solves regression problems by comparing output with ground truth)
• 5 spatial fusion layers• End in Loss 2 function
(solves classification problem by finding mean squared error)
• Heat Maps generated of 14 key-points and forms star-net structure
• Classification based on star-net orientation of points

Disguised Face Identification (DIC) Framework
• Spatial Fusion Convolutional Network predicts and temporally aligns the facial key points of all neighboring frames to a particular frame by warping backwards and forwards in time using tracks from dense optical flow
• Optical flow is pattern of apparent motion caused by relative motion between observer and a scene
• Dense optical flow takes into account every pixel while sparse optical flow picks a portion of all the pixels
• The confidence in the particular frame is strengthened with a set of “expert opinions” ( with corresponding confidences) from frames in the neighborhood, from which the facial key points can be estimated accurately
• Spatial fusion network more accurate in this respect when compared to other DNNs
• Points connected to a star-net and used in classification

Facial KeyPoint Detection
• Regression problem modeled by Spatial Fusion Convolutional network
• CNN takes an image and outputs pixel coordinates of each key-point• Output of last layer is i x j x k dimensional cube (here is 64 x 64 x 14 = 14 key-points)
• Training objective: estimate network weights lambda (λ) with available training data set D = (x, y) and regressor:
• Φ() is the activation function (rate of action potential firing inn the neurons)
• Where the Gaussian function Gi,j,k(yk) is:
• CNNs aren’t scale/shift invariant so we apply Gaussian distribution to put feature values in a known range
• Loss 2 function on squared pixel-wise differences between predicted and ground truth heat-map
• Use MatConvNet to train and validate Fusion Convolutional Network in MATLAB

Facial KeyPoint Detection Cont.
• Locations (coordinates) produced by networks from last slide are connected into a star network with “angles” used later for classification
• Nose key point is used as the reference point in determining angles for other points

Disguised Face Classification
• Compare disguised face to 5 non-disguised faces (including the person in the disguise)
• Classification is accurate is tau (τ) is the minimum for analysis between disguised image and non-disguised image of the same person
• Similarity is estimated by computing L1 norm between orientation of different key points (from net structure):
• τ is similarity, θi is orientation of the ith key point of disguised image, and φi is corresponding angles in the non-disguised image

Experimental Results
• Split between Simple Background Face Disguise data set and Complex Background Face Disguise data set
• Individual key point accuracy is presented along with comparison with other architecture
• Analyze classification performance

Spatial Fusion ConvNet Training
• Spatial Fusion CNN trained on 1000 images (500 validation images and 500 test images)
• Network trained for 90 cycles with batch size of 20
• 248x248 sub-image randomly cropped from every input image, randomly flipped, randomly rotated between -40 and 40 degrees and resized to 256x256 to be passed as input into CNN
• Variance of Gaussian set to 1.5
• Heat-map size is 64x64
• Base learning rate is 10^(-5), decreased to 10^(-6) after 20 iterations
• Momentum is 0.9• Momentum update results in better convergence on deep networks (based on
physical perspective of the optimization problem)

Key Point Detection
• Row 1: disguised images
• Row 2: key point mapping
• Row 3: net-star construction
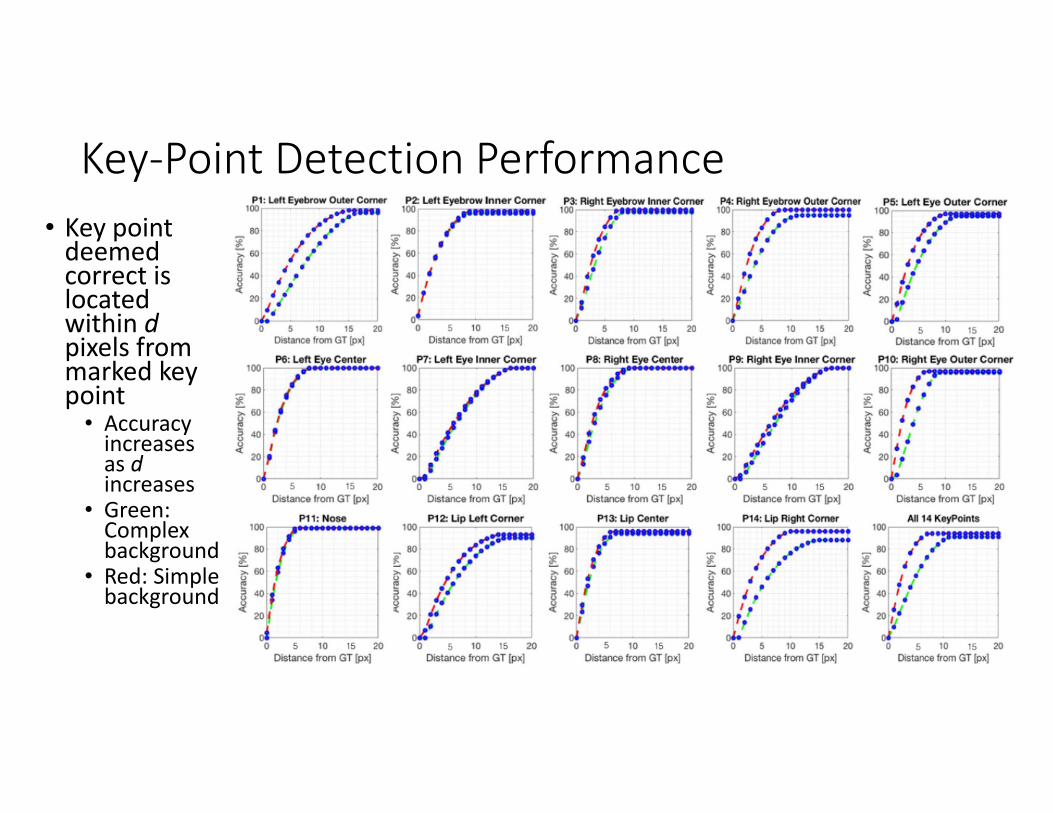
Key-Point Detection Performance
• Key point deemed correct is located within dpixels from marked key point
• Accuracy increases as dincreases
• Green: Complex background
• Red: Simple background

Key-Point Detection Performance Cont.
• Simple background higher accuracy than complex background
• Complex has lower performance b/c background clutter interferes with identifying outer region facial key points

Key-Point Performance Analysis with Reference to Background Clutter
• Background clutter significantly interferes with key point detection performance
• Background clutter observed by analyzing key-point detection in lips, nose and eye regions

Eye Region Key-Points Detection
• Relevant key points: P1 – P10
• P1, P4, P5, and P10 prominently affected (closest to face border)
• Accuracy at pixel distance closer to ground-truth is significantly higher for simple vs complex background

Nose Key-Point Detection Performance
• Nose key-point (P11) is not affected by background clutter
• Probably because P11 is buffered by surrounding key points

Lips Region Key-Point Detection Performance
• P12, P13, P14 comprise the lips region
• P12 and P14 are affected by background clutter while P13 is not
• P12 and P14 affected because they are closer to face edge than P13

Facial Key-Points Detection: Multiple Persons
• Use Viola Jones Face Detector to find all faces in the image
• Use DIC on each face
• The key-point detection classification performance for each simple and complex datasets:
• 2 faces in the image are 80% and 50%
• 3 faces in the image are 76% and 43%
• Single face: 85% and 56%
• Decrease in accuracy as number of faces increase

Comparison of KeyPoint Detection Performance with Other Architecture
• CN = CoordinateNet
• CNE = CoordinateNet Extended
• SpatialNet
• d = 5 from ground-truth
• In accordance with findings from other architectures, background clutter decreases accuracy

Classification Performance and comparison with the state-of-the-art
• More heavily disguise = accuracy decrease
• State-of-the-art is unnamed
• This paper’s framework outperforms current state-of-the-art

Conclusion
• Proposed two datasets that can be used to train future disguised face recognition networks
• Background clutter affects outer region key points
• Images taken should have the simplest background possible for highest accuracy
• Disguised Face Identification (DFI) Framework outperforms state-of-the-art by first detecting 14 facial key points and connects them to net-star

References
• https://arxiv.org/pdf/1708.09317.pdf

Thank you!


















