
Diktat StatMat I
88
DIKTAT KULIAH STATISTIKA MATEMATIKA I Disusun Oleh Dr.rer.nat. Wayan Somayasa, S.Si., M.Si. FMIPA UNHALU-KENDARI KENDARI 2008
-
Upload
prima-tahapary -
Category
Documents
-
view
88 -
download
9
description
Diktat Statistika Matematika I
Transcript of Diktat StatMat I

DIKTAT KULIAHSTATISTIKA MATEMATIKA I
Disusun Oleh
Dr.rer.nat. Wayan Somayasa, S.Si., M.Si.
FMIPA UNHALU-KENDARI
KENDARI 2008

Table of Contents
Table of Contents 1
1 Statistik dan distribusi sampling 3
1.1 Sampel random . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Statistik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3 Distribusi sampling dari populasi normal . . . . . . . . . . . . . . . . 7
1.3.1 Distribusi chi-kuadrat . . . . . . . . . . . . . . . . . . . . . . 9
1.3.2 Distribusi t student . . . . . . . . . . . . . . . . . . . . . . . . 13
1.3.3 Distribusi F . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.4 Soal-soal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2 Estimasi titik 18
2.1 Metode momen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.2 Estimator dengan likelihood terbesar . . . . . . . . . . . . . . . . . 21
2.2.1 Kasus satu parameter (k = 1) . . . . . . . . . . . . . . . . . . 22
2.2.2 Kasus k parameter . . . . . . . . . . . . . . . . . . . . . . . . 23
2.3 Keriteria-keriteria memilih estimator . . . . . . . . . . . . . . . . . . 26
2.3.1 Ketakbiasan . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.3.2 Keterkonsentrasian dan UMVUE . . . . . . . . . . . . . . . . 27
2.4 Soal-soal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3 Statistik cukup, keluarga lengkap dan keluarga eksponensial 33
3.1 Statistik cukup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.2 Keluarga lengkap . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.3 Keluarga eksponensial . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.4 Soal-soal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
1

2
4 Estimasi interval 47
4.1 Metode kuantitas pivot (pivotal quantity) . . . . . . . . . . . . . . . . 50
4.1.1 Membandingkan dua populasi normal . . . . . . . . . . . . . . 54
4.2 Metode umum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.2.1 Kasus h1 dan h2 monoton naik . . . . . . . . . . . . . . . . . 57
4.2.2 Kasus h1 dan h2 monoton turun . . . . . . . . . . . . . . . . . 59
4.3 Soal-soal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5 Uji hipotesis 62
5.1 Pendahuluan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.1.1 Menentukan daerah kritik . . . . . . . . . . . . . . . . . . . . 64
5.1.2 Nilai p (p-value) . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.2 Metode memilih tes terbaik . . . . . . . . . . . . . . . . . . . . . . . 70
5.2.1 Tes UMP untuk hipotesis sederhana . . . . . . . . . . . . . . 70
5.2.2 Tes UMP untuk hipotesis komposit . . . . . . . . . . . . . . . 73
5.2.3 Keluarga monotone likelihood ratio (MLR) . . . . . . . . . . . 75
5.3 Tes dengan membandingkan fungsi likelihood . . . . . . . . . . . . . . 79
5.4 Soal-soal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6 Teori sampel besar 85
7 Teori Bayes 86
8 Estimasi dengan metode bootstrap 87

Chapter 1
Statistik dan distribusi sampling
Pada bagian ini kita akan membahas konsep tentang statistik (engl.: statistic) dan
distribusi sampling. Harap diperhatikan perbedaan antara statistik dan statistika
(engl.: statistics). Sebelumnya kita akan mengajak pembaca untuk membahas penger-
tian sampel random dan peranannya dalam statistika.
1.1 Sampel random
Misalkan seorang peneliti tertarik untuk mengamati proporsi ikan tuna yang tersebar
di teluk Kendari. Tentu saja proporsi ini tidak diketahui kecuali kalau si peneliti tadi
bisa menghitung semua ikan yang hidup di teluk Kendari dan kemudian menghitung
berapa bagian dari total jumlah ikan tadi yang merupakan ikan tuna. Apakah ini
mungkin dilakuan? Berapa banyak waktu, biaya dan tenaga yang perlu diinvestasikan
kalau cara ini yang ditempuh?
Sebagai statistikawan kita bisa membantu si peneliti tadi dengan statistika seba-
gai berikut. Kita misalkan populasi ikan di teluk Kendari sebagai ruang probabilitas
3

4
(Ω,F ,P). Misalkan ΩT adalah himpunan semua ikan tuna, maka proporsi ikan tuna
dalam populasi itu adalah P(ΩT ) = ]ΩT
]Ω, yaitu jumlah ikan tuna dibagi jumlah ikan
keseluruhan. Kita misalkan konstanta yang tidak diketahui ini sebagai p ≥ 0. Mis-
alkan X : Ω → R adalah indikator dari ΩT , yaitu suatu fungsi yang didefinisikan
sebagai berikut
X(ω) :
1 : jika ω ∈ ΩT
0 : jika ω 6∈ ΩT
.
Maka X adalah sebuah variabel random (fungsi terukur) Bernoulli yang mengambil
nilai pada ruang sampel (R,B,PX), dimana untuk setiap himpunan bagian B ∈ B,
PX(B) := Pω ∈ Ω : X(ω) ∈ B. Misalkan ambil kasus dimana B = 1, maka
PX(1) := Pω ∈ Ω : X(ω) = 1 = P(ΩT ) = p. Selanjutnya PX disebut sebagai
distribusi peluang dari X. Sebaliknya kalau B = 0, maka PX(0) := Pω ∈ Ω :
X(ω) = 0 = P(ΩCT ) = 1 − p, dimana ΩC
T adalah komplemen dari ΩT . Jadi model
distribusi peluang ikan tuna di teluk Kendari di gambarkan oleh model distribusi
peluang dari X dengan fungsi densitas fX(x) := PX(x) = PX = x = px(1−p)1−x,
x = 0, 1. Selanjutnya fX(x) disebut sebagai fungsi densitas populasi.
Misalkan dari suatu eksperimen yang dilakukan misalkan dengan memancing ikan
lalu mencatat hasilnya pada setiap pemancingan sebagi 1 jika yang didapat adalah
tuna dan 0 jika hasilnya bukan ikan tuna. Andaikan pemancingan dilakukan n
kali, maka data yang diperoleh adalah x1, . . . , xn, dengan xi ∈ 0, 1, i = 1, . . . , n.
Dalam statistika kita memandang data sebagai realisasi (nilai) dari variabel random
X1, . . . , Xn yang terdefinisi pada (Ω,F ,P), yaitu Xi(ω) = xi, untuk suatu ω ∈ Ω,
i = 1, . . . , n. Kita nyatakan distribusi peluang bersama dari X1, . . . , Xn dengan
⊗ni=1PXi yang terdefinisi pada (Rn,Bn).
Definisi 1.1.1. Suatu himpunan random variable X1, . . . , Xn dikatakan sebagai

5
sampel random berukuran n dari suatu populasi X, jika dan hanya jika
⊗ni=1PXi⊗n
i=1(−∞, ti] = Πni=1PXi((−∞, ti]) = Πn
i=1PX((−∞, ti]),
dimana ⊗ni=1(−∞, ti] := (−∞, t1]×· · ·×(−∞, tn]. Jika populasi X mempunyai fungsi
densitas f(x), maka X1, . . . , Xn dikatakan sebagai sampel random berukuran n dari
suatu populasi X, jika dan hanya jika
fX1,...,Xn(x1, . . . , xn) = Πni=1f(xi).
Jadi suatu sampel random harus memenuhi kondisi dimana X1, . . . , Xn saling in-
dependen dan masing-masing mempunyai distribusi peluang yang sama dengan dis-
tribusi peluang populasinya (sering juga dikatakan i.i.d sebagai singkatan dari inde-
pendent and identically distributed).
Kembali ke kasus semula jika pada setiap pemancingan (trial) ikan dilepas lagi,
maka hasil berikutnya tidak akan terpengaruh dari hasil sebelumnya (saling indepen-
den) dan masing-masing akan mengikuti distribusi yang sama yaitu Bernoulli dengan
parameter p. Jadi eksperimen kita akan menghasilkan sampel random berukuran n
dari populasi ikan tuna di teluk Kendari.
Sebagai contoh lain, misalkan suatu pabrik lampu dalam setahun memproduksi
500000 lampu pijar dengan jenis yang sama, misalkan jenis A. Karena suatu hal,
daya tahan lampu yang dihasilkan ternyata berbeda-beda. Andaikan produsen ter-
tarik untuk menyelidiki proporsi lampu yang mempunyai daya tahan sesuai spesifikasi
tertentu, misalkan daya tahannya melebihi t jam. Andaikan populasi lampu jenis A
dimisalkan sebagai ruang (Ω,F ,P) dan Y : (Ω,F ,P) → (R≥0,B(R≥0),PY ) dengan

6
Y (ω) adalah daya tahan bola lampu ω ∈ Ω. Andaikan Y mengikuti distribusi expo-
nensial dgn parameter θ > 0, maka proporsi bola lampu jenis A yang daya tahan-
nya lebih dari atau sama dengan t jam adalah PY ([t,∞)) =∫∞
t1θexp−y/θdy =
exp−t/θ, t ≥ 0. Andaikan Y1, . . . , Yn adalah sampel random dari populasi Y , maka
⊗ni=1PYi(⊗n
i=1[ti,∞)) = Πni=1 exp−ti/θ = exp−1
θ
∑ni=1 ti.
1.2 Statistik
Pada subbab sebelumnya kita mengenal p dan θ sebagai konstanta-konstanta (parameter-
parameter) yang tidak diketahui nilainya. Tujuan dari statistika adalah merumuskan
suatu konsep inferensi atau pendugaan terhadap parameter-parameter tersebut. Alat
utama yang digunakan adalah apa yang disebut statistik.
Definisi 1.2.1. Misalkan X1, . . . , Xn adalah himpunan n ∈ N variabel random
teramati dari suatu populasi tertentu. Statistik adalah sembarang fungsi T :=
t(X1, . . . , Xn) yang tidak bergantung pada sembarang parameter yang tidak diketahui.
Selanjutnya distribusi dari suatu statistik disebut distribusi sampling.
Catatan:
Pada Definisi 1.2.1 kata teramati mengandung pengertian bahwa melalui suatu ekspe-
rimen n titik data yang diperoleh adalah realisasi dari X1, . . . , Xn. Variabel-variabel
ini harus teramati, karena kalau tidak, maka fungsi t tidak bisa dihitung.
Contoh 1.2.2. Misalkan X1, . . . , Xn adalah sampel random dari suatu populasi den-
gan mean µ dan variansi σ2 > 0. Mean sampel X := 1n
∑ni=1 Xi and variansi
sampel S2 := 1n−1
∑ni=1(Xi − X)2 merupakan statistik dengan sifat-sifat sebagai
berikut:

7
1. E(X) = µ and V ar(X) = σ2/n.
2. E(S2) = σ2 and V ar(S2) = 1n(µ′4 − n−3
n−1σ4), dengan µ′4 := E(X4).
Untuk kasus penyelidikan ikan tuna di teluk Kendari, proporsi sampel adalah p :=
1n
∑ni=1 Xi, dengan Xi i.i.d. Bin(1, p). Maka E(p) = p dan V ar(p) = p(1− p).
1.3 Distribusi sampling dari populasi normal
Pada bagian ini kita akan mempelajari distribusi dari beberapa statistik yang meru-
pakan fungsi dari sampel random dari populasi normal. Kita batasi pembicaraan
pada populasi normal saja karena selain secara matematika mudah diturunkan, juga
karena model distribusi ini banyak dipakai di lapangan.
Teorema 1.3.1. Misalkan X1, . . . , Xn saling independen dan berdistribusi N(µi, σ2i ).
Maka Y :=∑n
i=1 aiXi ∼ N (∑n
i=1 aiµi,∑n
i=1 a2i σ
2i ), untuk ai ∈ R, i = 1, . . . , n.
Proof. Hasil ini dapat dibuktikan dengan konvolusi dari variabel random normal.
Yaitu jumlah dari beberapa variabel random normal adalah normal. Karena dis-
tribusi normal ditentukan secara tunggal hanya oleh mean dan variansinya, berarti
kita hanya perlu menghitung mean dan variansi dari Y yang diberikan oleh∑n
i=1 aiµi
dan∑n
i=1 a2i σ
2i . Cara lain adalah dengan metode ketunggalan fungsi pembangkit mo-
men (Moment Generating Functions/MGF). Secara umum jika X ∼ N(µ, σ2), maka
MX(t) = exptµ +1
2t2σ2, t ∈ R. (1.3.1)
Karena Xi saling independen, maka berlaku
MY (t) = Πni=1MXi
(ait) = Πni=1 exptaiµi +
1
2t2a2
i σ2i

8
= exptn∑
i=1
aiµi +1
2t2
n∑i=1
a2i σ
2i . (1.3.2)
Selanjutnya dengan membandingkan (1.3.1) dan (1.3.2), teorema terbukti.
Contoh 1.3.2. Misalkan X1, . . . , Xn1 dan Y1, . . . , Yn2 merupakan dua sampel random
yang saling bebas masing-masing berukuran n1 dan n2. Jika Xi ∼ N(µ1, σ21) dan Yj ∼
N(µ2, σ22), i = 1, . . . , n1 dan j = 1, . . . , n2, maka X− Y ∼ N(µ1−µ2, σ
21/n1 +σ2
2/n2).
Proof. Pernyataan ini dapat ditunjukan dengan menggunakan secara langsung hasil
pada Teorema 1.3.1 dan kenyataan X− Y = 1n1
X1 + . . .+ 1n1
Xn1 − 1n2
Y1− . . .− 1n2
Yn2 .
Cara lain adalah dengan metode MGF sebagai berikut:
MX−Y (t) = MX(t)MY (−t) (kedua sampel saling independen)
= Πn1i=1MXi
(t/n1)Πn2j=1MYj
(−t/n2)
= Πn1i=1 exp
t
n1
µ1 +1
2
t2
n21
σ21
Πn2
i=1 exp
−t
n2
µ2 +1
2
t2
n22
σ22
= exp
t(µ1 − µ2) +
1
2t2(σ2
1/n1 + σ22/n2)
.
Persamaan yang terakhir adalah MGF dari N(µ1 − µ2, σ21/n1 + σ2
2/n2).
Contoh 1.3.3. Dari hasil pada Contoh 1.3.2 tentukan suatu konstanta c sedemikian
hingga 95% dari populasinya mempunyai selisih mean sampel lebih dari c.
Jawab:
Dengan menggunakan transformasi variabel diperoleh
PX − Y ≥ c
= 0, 95 ⇔ P
(X − Y )− (µ1 − µ2)√
σ21/n1 + σ2
2/n2
≥ c− (µ1 − µ2)√σ2
1/n1 + σ22/n2
= 0, 95.
Selanjutnya karena (X−Y )−(µ1−µ2)√σ21/n1+σ2
2/n2
∼ N(0, 1), maka konstanta c adalah penyelesaian
dari persamaan
c− (µ1 − µ2)√σ2
1/n1 + σ22/n2
= z0,05 ⇒ c = (µ1 − µ2) + z0.05
√σ2
1/n1 + σ22/n2.

9
1.3.1 Distribusi chi-kuadrat
Definisi 1.3.4. Suatu variabel random X dikatakan berdistribusi chi-kuadrat dengan
derajat bebas ν (X ∼ χ2(ν)), jika dan hanya jika X ∼ Gamma(2, ν/2).
Remark 1.3.5. Sifat-sifat distribusi chi-kuadrat dapat diturunkan langsung dari sifat-
sifat distribusi Gamma. Jika X ∼ χ2(ν), maka
1. MX(t) = (1− 2t)−ν/2,
2. E(Xr) = 2r Γ(ν/2+r)Γ(ν/2)
, r ∈ Z,
3. E(X) = ν dan V ar(X) = 2ν.
Teorema 1.3.6. Jika X ∼ Gamma(θ, κ), maka 2X/θ ∼ χ2(2κ).
Proof. Bukti yang paling sederhana adalah dengan metode ketunggalan MGF:
M 2Xθ
(t) = MX(2t/θ) =
(1− θ
2t
θ
)−κ
= (1− 2t)−2κ/2.
Jadi terbukti 2X/θ ∼ χ2(2κ).
Contoh 1.3.7. Andaikan bahwa daya tahan batu batrai yang diproduksi oleh suatu
pabrik mengikuti distribusi Gamma(θ, κ). Jika pabrik ingin memberikan suatu jam-
inan bahwa 90% dari produknya mempunyai daya tahan lebih dari t0 tahun, maka
tentukan t0.
Jawab:
Andaikan X adalah daya tahan batu batrai dalam satuan tahun. Yang ingin diten-
tukan oleh pabrik adalah t0 sedemikian hingga PX ≥ t0 = 0, 90. Tetapi dari Teo-
rema 1.3.6, P2X/θ ≥ 2t0/θ = 0, 90. Maka t0 = χ20,10(2κ)/2. Disini χ2
α(2κ) adalah
suatu konstanta yang memenuhi persamaan Pχ2(2κ) ≤ χ2α(2κ) = α atau disebut
juga pesensil ke alpha dari distribusi χ2(2κ).

10
Teorema berikut memberikan hasil yang sangat penting dari distribusi chi-kuadrat.
Teorema 1.3.8. Misalkan Y1, . . . , Yn saling independen dan Yi ∼ χ2(νi). Maka V =
∑ni=1 Yi ∼ χ2(
∑ni=1 νi).
Proof. Kita buktikan hasil ini dengan ketunggalan MGF. Dari asumsi bahwa Yi saling
independen berlaku: MV (t) = Πni=1(1− 2t)−νi/2 = (1− 2t)−
∑ni=1 νi/2 yang merupakan
MGF dari χ2(∑n
i=1 νi).
Hasil berikut menjelaskan hubungan antara distribusi normal standar dan dis-
tribusi chi-kuadrat.
Teorema 1.3.9. Jika Z ∼ N(0, 1), maka Z2 ∼ χ2(1).
Proof.
MZ2(t) = E(exptZ2) =
∫ ∞
−∞
1√2π
exptz2 − z2/2dz
=1√
1− 2t
∫ ∞
−∞
√1− 2t√
2πexp−z2(1− 2t)/2dz
= (1− 2t)−1/2,
yang merupakan MGF dari χ2(1).
Akibat 1.3.10. Jika X1, . . . , Xn adalah sampel random dari populasi N(µ, σ2), maka
berlaku:
1.∑n
i=1(Xi−µ)2
σ2 ∼ χ2(n),
2. n(X−µ)2
σ2 ∼ χ2(1).
Pada Contoh 1.3.2 kita sudah menurunkan distribusi dari mean sampel. Teorema
berikut memberikan distribusi dari variansi sampel S2 yang didefinisikan pada Contoh
1.2.2.

11
Teorema 1.3.11. Jika X1, . . . , Xn menyatakan sampel random dari N(µ, σ2), maka
1. Antara X dan (Xi − X), i = 1, . . . , n saling independen.
2. Antara X dan S2 saling independen,
3. (n− 1)S2/σ2 ∼ χ2(n− 1).
Proof. Kita definisikan transformasi variabel berikut: y1 = x dan yi = xi − x, untuk
i = 2, . . . , n, sehingga diperoleh: xi = y1 + yi, i = 2, . . . , n dan x1 = y1 −∑n
i=2 yi.
Jacobian dari transformasi ini adalah
J =
1 −1 −1 · · · −1
1 1 0 · · · 0
1 0 1 · · · 0
......
......
...
1 0 0 · · · 0
⇒ det(J) = n.
Selanjutnya dari x1 − x = −∑ni=2(xi − x) = −∑n
i=2 yi diperoleh
n∑i=1
(xi − x)2 = (x1 − x) +n∑
i=2
(xi − x)2 =
(−
n∑i=2
yi
)2
+n∑
i=2
y2i . (1.3.3)
Karena saling bebas, fungsi densitas bersama dari X1, . . . , Xn adalah
fX1,...,Xn(x1, . . . , xn) =1
(2π)n/2σnexp
− 1
2σ2
n∑i=1
(xi − µ)2
=1
(2π)n/2σnexp
− 1
2σ2
(n∑
i=1
(xi − x)2 + n(x− µ)2
).
Sehingga dari (1.3.3) fungsi densitas bersama dari variabel Y1, . . . , Yn adalah
gY1,...,Yn(y1, . . . , yn) =det(J)
(2π)n/2σnexp
−
1
2σ2
(−
n∑i=2
yi
)2
+n∑
i=2
y2i + n(y1 − µ)2
=1√
2πσ2/nexp
− 1
2σ2/n(y1 − µ)2
×

12
√n
(2π)(n−1)/2σ(n−1)exp
−
1
2σ2
(−
n∑i=2
yi
)2
+n∑
i=2
y2i
.
Persamaan yang terakhir menunjukan bahwa fungsi densitas bersama dari Y1, . . . , Yn
dapat difaktorkan sebagai hasil prgandaan antara fungsi densitas dari Y1 dan fungsi
densitas bersama dari Y2, . . . , Yn. Jadi Y1 = X independen terhadap Yi = Xi − X
untuk i = 2, . . . , n. Selanjutnya karena X1 − X = −∑ni=2(Xi − X), berarti X juga
independen terhadap X1 − X. Jadi pernyataan 1 terbukti.
Karena S2 merupakan fungsi dari Xi − X untuk i = 1, . . . , n, maka pernyataan 2
hanyalah merupakan akibat langsung dari pernyataan 1.
Kita menggunakan metode ketunggalan MGF untuk membuktikan pernyataan 3 :
Misalkan V1 :=∑n
i=1(Xi−µ)2
σ2 ∼ χ2(n), V2 := n(X−µ)2
σ2 ∼ χ2(1) dan V3 = (n−1)S2
σ2 . Dari
definisi dari S2 diperoleh: V1 = V3 + V2 dan dari pernyataan 2 jelaslah V2 dan V3
saling independen, sehingga berlaku
MV1(t) = MV3+V2(t) = MV3(t)MV2(t)
⇒ MV3(t) =MV1(t)
MV2(t)=
(1− 2t)−n/2
(1− 2t)−1/2= (1− 2t)−(n−1)/2,
yang merupakan MGF dari χ2(n− 1).
Contoh 1.3.12. Misalkan sebaran nilai ujian akhir mata kuliah Kewiraan mahasiwa
FMIPA Unhalu angkatan 2007/2008 diasumsikan berdistribusi N(60, 36). Untuk men-
guji kebenaran klaim bahwa σ2 = 36, sebuah sampel random berukuran 25 diambil dari
populasi ini. Asumsi akan ditolak jika S2 ≥ 54, 63 dan sebaliknya asumsi akan dito-
lak jika S2 < 54, 63. Tentukan berapa peluang menolak asumsi ini jika benar bahwa
populasinya N(60, 36).
Jawab:

13
Dari Teorema 1.3.11 pernyataan 3 kita peroleh:
PS2 ≥ 54, 63
= P
24S2
36≥ 36, 42
= 1− P
χ2(24) < 36, 42
= 0, 05
1.3.2 Distribusi t student
Teorema 1.3.13. Misalkan Z ∼ N(0, 1) dan Y ∼ χ2(ν). Jika Z dan Y saling
independen, maka T := Z√Y/ν
dikatakan berdistribusi t student dengan derajat bebas
ν. Selanjutnya dituliskan sebagai T ∼ t(ν). Fungsi densitas dari T adalah:
fT (t; ν) =Γ
(ν+12
)
Γ(
ν2
) 1√νπ
(1 +
t2
ν
)−(ν+1)/2
(1.3.4)
Proof. Kita definisikan transformasi T = Z√Y/ν
dan W = Y yang berakibat Z =
T√
W/ν dan Y = W . Jakobian dari transformasi yariabel t = z√y/ν
dan w = y
adalah
J =
√w/ν t
2√
w/ν
0 1
⇒ det(J) =
√w/ν.
Karena Z dan Y saling independen, maka fungsi densitas bersamanya adalah:
fZ,Y (z, y) = fZ(z)fY (y) =e−z2/2
√2π
yν/2−1e−y/2
2ν/2Γ(ν/2)=
yν/2−1e−(y/2+z2/2)
√2πΓ(ν/2)2ν/2
.
⇒ fT,W (t, w) = fZ,Y (z, y)det(J) =wν/2−1e−w/2e−t2w/2ν
√2πΓ(ν/2)2ν/2
√w/ν
=(w/2)ν/2−1/2e−w/2(1+t2/ν)
√4πνΓ(ν/2)
, −∞ < t < ∞, 0 < w < ∞.
Maka fungsi densitas marginal dari T adalah
fT (t) =
∫ ∞
0
(w/2)ν/2−1/2e−w/2(1+t2/ν)
√4πνΓ(ν/2)
dw.
14
Dengan memisalkan u := w/2(1+ t2/ν),maka integral ini dapat disederhanakan men-
jadi
fT (t) =
∫∞0
u(ν/2+1/2−1)e−u du√πνΓ(ν/2)(1 + t2/ν)(ν+1)/2
=Γ
(ν+12
)√
πνΓ(ν/2)(1 + t2/ν)−
(ν+1)2
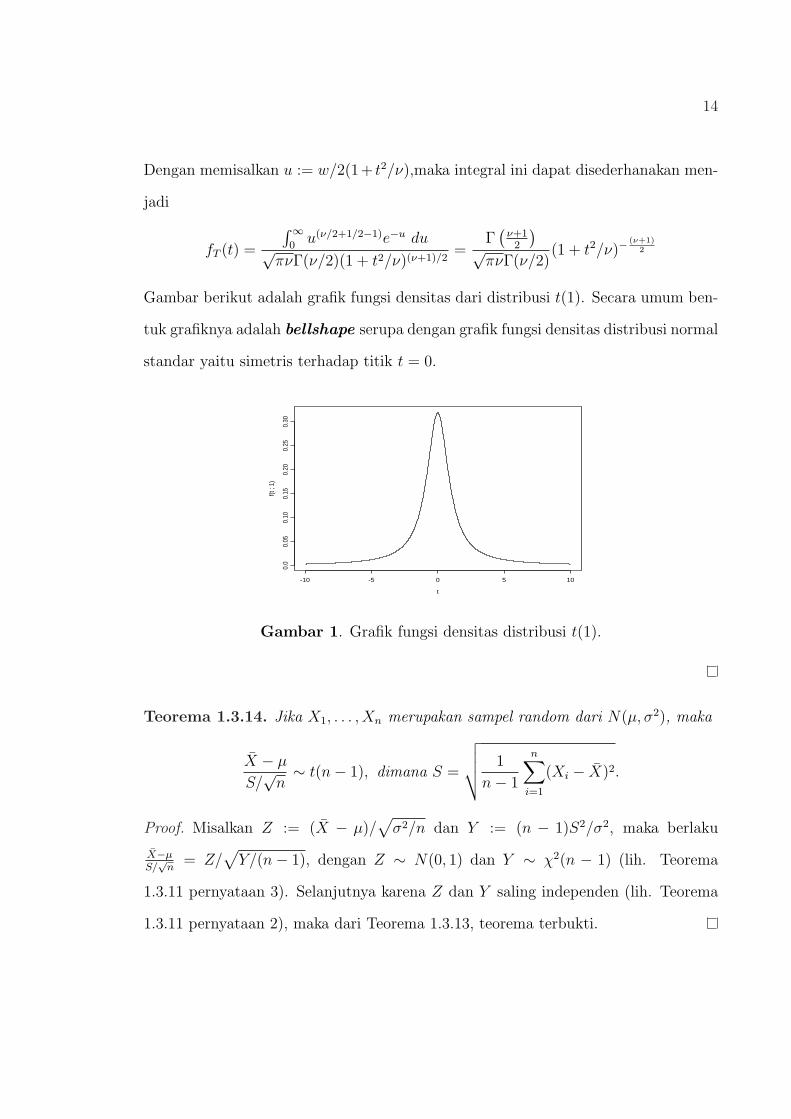
Gambar berikut adalah grafik fungsi densitas dari distribusi t(1). Secara umum ben-
tuk grafiknya adalah bellshape serupa dengan grafik fungsi densitas distribusi normal
standar yaitu simetris terhadap titik t = 0.
t
f(t ;
1)
-10 -5 0 5 10
0.0
0.05
0.10
0.15
0.20
0.25
0.30
Gambar 1. Grafik fungsi densitas distribusi t(1).
Teorema 1.3.14. Jika X1, . . . , Xn merupakan sampel random dari N(µ, σ2), maka
X − µ
S/√
n∼ t(n− 1), dimana S =
√√√√ 1
n− 1
n∑i=1
(Xi − X)2.
Proof. Misalkan Z := (X − µ)/√
σ2/n dan Y := (n − 1)S2/σ2, maka berlaku
X−µS/√
n= Z/
√Y/(n− 1), dengan Z ∼ N(0, 1) dan Y ∼ χ2(n − 1) (lih. Teorema
1.3.11 pernyataan 3). Selanjutnya karena Z dan Y saling independen (lih. Teorema
1.3.11 pernyataan 2), maka dari Teorema 1.3.13, teorema terbukti.

15
Sebagai catatan, untuk melakukan inferensi terhadap µ dari populasi N(µ, σ2),
maka quantitas X−µ√σ2/n
tidak bisa dipakai apabila σ2 tidak diketahui. Karena itu kita
melakukan estimasi dahulu terhadap σ2 dengan S2. Jadi disinilah letak penggunaan
dari distribusi t.
1.3.3 Distribusi F
Salah satu alasan kenapa distribusi F penting untuk di pelajari adalah jika kita
mempunyai 2 sampel random X1, . . . , Xn1 dari populasi N(µ1, σ21) dan Y1, . . . , Yn2
dari populasi N(µ2, σ22) dan kita ingin melakukan inferensi terhadap rasio σ2
1/σ22.
Teorema 1.3.15. Misalkan U ∼ χ2(r1) dan V ∼ χ2(r2). Jika U dan V saling inde-
penden, maka X := U/r1
V/r2berdistribusi F dengan derajat bebas r1 dan r2. Selanjutnya
distribusi ini kita tuliskan sebagai F (r1, r2). Persensil fγ(r1, r2) adalah konstanta
yang memenuhi persamaan PX ≤ fγ(r1, r2) = γ. Fungsi densitas dari X adalah:
fX(x; r1, r2) =
(r1
r2
)r1/2
Γ(
r1+r2
2
)x(r1/2−1)
Γ(r1/2)Γ(r2/2)(xr1/r2 + 1)(r1+r2)/2(1.3.5)
Proof. Kita definisikan transformasi variabel X = U/r1
V/r2dan Y = V , maka U =
XY r1/r2 dan V = Y . Jacobian dari transformasi u = xyr1/r2 dan v = y adalah:
J =
yr1/r2 xr1/r2
0 1
⇒ det(J) = yr1/r2.
Selanjutnya karena U dan V saling independen, fungsi densitas bersamanya adalah
fU,V (u, v; r1, r2) = fU(u; r1)fV (v; r2) =ur1/2−1vr2/2−1 exp−(u + v)/2
Γ(r1/2)Γ(r2/2)2(r1+r2)/2.
Maka fungsi densitas bersama antara X adan Y adalah:
fX,Y (x, y; r1, r2) = fU,V (u, v; r1, r2) det(J)

16
=(xy)
r12−1
(r1
r2
) r12−1
yr22−1
Γ(r1/2)Γ(r2/2)2(r1+r2)/2exp−(xyr1/r2)/2− y/2yr1/r2
=
(r1
r2
) r12
y(r1+r2)/2−1xr12−1
Γ(r1/2)Γ(r2/2)2(r1+r2)/2exp−y
2(xr1/r2 + 1).
Fungsi densitas marginal dari X adalah fX(x; r1, r2) =∫∞0
fX,Y (x, y; r1, r2) dy. Den-
gan menggunakan substitusi variabel w = y2(xr1/r2 + 1) atau y = 2w/(xr1/r2 + 1)
kita peroleh
fX(x; r1, r2) =
∫ ∞
0
(r1
r2
) r12
xr12−1w(r1+r2)/2−1 exp−w
Γ(r1/2)Γ(r2/2)(xr1/r2 + 1)(r1+r2)
2
dw,
yang menghasilkan (1.3.5).
Teorema 1.3.16. Jika X ∼ F (r1, r2), maka
E(Xr) =
(r1
r2
)r
Γ (r1/2 + r) Γ (r2/2− r)
Γ (r1/2) Γ (r2/2), r2 > 2r, (1.3.6)
E(X) =r2
r2 − 2, r2 > 2, (1.3.7)
V ar(X) =2r2
2(r1 + r2 − 2)
r1(r2 − 2)2(r2 − 4), r2 > 4 (1.3.8)
Proof. Karena U dan V saling bebas, maka berlaku
E(Xr) = E(U/r1)rE(V/r2)
−r =
(r1
r2
)r
E(U r)E(V −r).
Selanjutnya hasil di atas diperoleh dengan substitusi langsung terhadap E(U r) dan
E(V −r) untuk variabel chi kuadrat. Pernyataan yang lainnya adalah kejadian khusus
dari pernyataan pertama.
Contoh 1.3.17. Misalkan X1, . . . , Xn1 dan Y1, . . . , Yn2 merupakan dua sampel ran-
dom yang saling independen dari populasi, dimana Xi ∼ N(µ1, σ21) dan Yj ∼ N(µ2, σ
22).

17
Dari Teorema 1.3.11, jelaslah
(n1 − 1)S2
X
σ21
∼ χ2(n1 − 1) dan (n2 − 1)S2
Y
σ22
∼ χ2(n2 − 1),
dan keduanya jelas saling independen, sehingga
P
S2Xσ2
2
S2Y σ2
1
≤ fγ(n1 − 1, n2 − 1)
= γ ⇔ P
S2
X
S2Y fγ(n1 − 1, n2 − 1)
≤ σ21
σ22
= γ
1.4 Soal-soal
1. Misalkan Z1, . . . , Z16 adalah sampel random dari populasi N(0, 1). Dengan
menggunakan tabel atau software S-PLUS tentukan peluang berikut:
(a) P∑16
i=1 Z2i < 32
(b) P∑16
i=1(Zi − Z)2 < 25
2. Jika T ∼ t(ν), tentukan distribusi dari T 2?

Chapter 2
Estimasi titik
Pada chapter ini kita akan membahas beberapa metode estimasi yang penting, yaitu
metode momen dan metode estimasi dengan likelihood terbesar.
Seperti yang sudah dibahas pada Chapter 1, populasi atau phenomena yang men-
jadi perhatia, kita gambarkan dengan variabel random X : (Θ,F ,P) → (R,B,PX).
Secara umum populasi X diasumsikan mempunyai distribusi probabilitas dengan
fungsi densitas merupakan anggota dari keluarga
PX(θ1,...,θk) :=
fX(·; θ1, . . . , θk) : (θ1, . . . , θk) ∈ Θ := Θ1 × · · · ×Θk ⊂ Rk
,
dimana (θ1, . . . , θk), k ∈ N adalah bilangan-bilangan yang tidak diketahui nilainya
atau disebut juga parameter. Kita namakan Θ ruang parameter. Misalnya,
PX(µ,σ2) :=
1√
2πσ2exp− 1
2σ2(· − µ)2 : (µ, σ2) ∈ (−∞,∞)× (0,∞) ⊂ R2
,
yang berarti populasi X termasuk anggota dari keluarga distribusi normal dimana
setiap elemen dari keluarga ini diidentifikasi oleh suatu parameter µ dan σ2 yang tidak
diketahui nilainya. Tujuan dari estimasi titik adalah untuk menentukan nilai yang
18

19
sesuai dari parameter-parameter θ1, . . . , θk berdasarkan data hasil observasi terhadap
populasinya. Data x1, . . . , xn yang diperoleh dipandang secara matematik sebagai
realisasi atau nilai dari n variabel random yang saling independen X1, . . . , Xn dengan
Xi : (Θ,F ,P) → (R,B,PXi) dan Xi ∼ fX(·; θ1, . . . , θk), (θ1, . . . , θk) ∈ Θ. Fungsi
densitas bersama dari sampel random ini yang dihitung pada titik data x1, . . . , xn,
yaitu
fX1,...,Xn(x1, . . . , xn; θ1, . . . , θk) = Πni=1fX(xi; θ1, . . . , θk), (θ1, . . . , θk) ∈ Θ,
memberikan hubungan fungsional antara parameter-parameter yang tidak diketahui
dan data. Dengan kata lain dari data yang diperoleh dapat diidentifikasi berapa nilai
parameter yang sesuai.
Definisi 2.0.1. Statistik θ1 := t1(X1, . . . , Xn), . . . , θk := tk(X1, . . . , Xn) yang digu-
nakan untuk mengestimasi θ1, . . . , θk disebut estimator. Sedangkan nilainya yang
dihitung pada titik data, yaitu t1(x1, . . . , xn), . . . , tk(x1, . . . , xn) disebut estimasi un-
tuk θ1, . . . , θk.
Contoh 2.0.2. Misalkan X1, . . . , X10 adalah sampel random dari populasi N(µ, σ2),
dengan (µ, σ2) ∈ (−∞,∞) × (0,∞). Mean sampel X =∑10
i=1 Xi/10 sering dipakai
sebagai suatu estimator untuk µ. Jika pada suatu eksperimen diperoleh data misalnya
10, 20, 15, 30, 25, 30, 20, 15, 25, 5, maka rata-ratanya merupakan estimasi untuk
µ. Jadi suatu estimator jelas merupakan variabel random, sedangkan estimasi adalah
suatu bilanagn real.

20
2.1 Metode momen
Misalkan X ∼ fX(·; θ1, . . . , θk), (θ1, . . . , θk) ∈ Θ adalah populasi yang menjadi per-
hatian kita dan (θ1, . . . , θk) adalah parameter-parameter yang tidak diketahui. Mo-
mem ke j dari populasi ini terhadap titik pusat adalah µ′j := E(Xj). Biasanya µ′j
bergantung pada θ1, . . . , θk karena itu kita notasikan sebagai µ′j = µ′j(θ1, . . . , θk), j =
1, . . . , k. Misalkan X1, . . . , Xn adalah sampel random dari populasi fX(·; θ1, . . . , θk),
(θ1, . . . , θk) ∈ Θ. Momen sampel ke j didefinisikan sebagai M ′j := 1/n
∑ni=1 Xj
i ,
j = 1, . . . , k. Karena µ′j sangat dekat dengan M ′j, estimator θ1, . . . , θk dapat ditu-
runkan dengan meyelesaikan system persamaan
µ′j(θ1, . . . , θk) = M ′j, j = 1, . . . , k, (2.1.1)
secara simultan untuk θ1, . . . , θk. Selanjutnya estimator yang diperoleh dengan cara
seperti ini kita sebut sebagai estimator metode momen (moment method esti-
mator) disingkat MME.
Contoh 2.1.1. Misalkan X ∼ fX(·; µ, σ2), (µ, σ2) ∈ (−∞,∞) × (0,∞) dengan
E(X) = µ dan V ar(X) = σ2. Dalam hal ini kita mempunyai k = 2 dengan
θ1 = µ dan θ2 = σ2, sehingga MME µ dan σ2 adalah penyelesaian dari persamaan
µ = M ′1 dan σ2 + µ2 = M ′
2. Jadi µ = X dan σ2 = M ′2 − X2 = (n − 1)S2/n. Jadi
µ = t1(X1, . . . , Xn) = X dan σ2 = t2(X1, . . . , Xn) = (n− 1)S2/n.
Contoh 2.1.2. Misalkan X1, . . . , Xn adalah sampel random dari populasi Gamma(θ, κ).
Karena E(X) = κθ dan E(X2) = κ(1 + κ)θ2, maka MME θ dan κ dapat diperoleh
dengan menyelesaikan persamaan κθ = M ′1 dan κ(1 + κ)θ2 = M ′
2, untuk θ dan κ.
Jadi diperoleh κ = X/θ dengan θ =∑n
i=1(Xi − X)2/(nX) = [(n− 1)/(nX)]S2.

21
Contoh 2.1.3. Misalkan X1, . . . , Xn adalah sampel random dari populasi Gamma(θ).
Andaikan kita tertarik untuk mencari MME untuk PXi ≥ 1 = exp−1/θ. Karena
E(Xi) = θ, maka MME θ = X. Misalkan p := exp−1/θ, maka θ = −1/ ln(p).
MME untuk p adalah penyelesaian dari persamaan −1/ ln(p) = X untuk p. Jadi
p = exp−1/X.
2.2 Estimator dengan likelihood terbesar
Definisi 2.2.1. Misalkan X1, . . . , Xn merupakan n variabel random dengan Xi ∼fXi
(·; θ1, . . . , θk), (θ1, . . . , θk) ∈ Θ, i = 1, . . . , n. Misalkan x1, . . . , xn merupakan
data atau suatu realisasi dari X1, . . . , Xn. Fungsi L : Θ → R≥0, sedemikian hingga
L(θ1, . . . , θk) = fX1,...,Xn(x1, . . . , xn; θ1, . . . , θk) disebut fungsi likelihood. Sebagai ke-
jadian yang lebih khusus, jika X1, . . . , Xn merupakan suatu sampel random, maka
L(θ1, . . . , θk) = Πni=1fXi
(xi; θ1, . . . , θk).
Selanjutnya, nilai-nilai dari (θ1, . . . , θk) ∈ Θ yang dinyatakan sebagai (θ1, . . . , θk)
sedemikian hingga
L(θ1, . . . , θk) = max(θ1,...,θk)∈Θ
L(θ1, . . . , θk)
disebut estimasi dengan likelihood terbesar (engl. Maximum Likelihood Estimate).
Biasanya (θ1, . . . , θk) merupakan fungsi dari data x1, . . . , xn, misalkan sebagai θi =
ti(x1, . . . , xn), i = 1, . . . , k. Jika fungsi-fungsi ini kita terapkan terhadap sampel ran-
dom X1, . . . , Xn, maka θi = ti(X1, . . . , Xn) disebut estimator dengan likelihood terbe-
sar (engl. Maximum Likelihood Estimator), disingkat MLE untuk θi, i = 1, . . . , k.
Dari definisi di atas adalah jelas bahwa permasalahan menentukan MLE adalah
termasuk permasalahan optimisasi. Nilai-nilai dari (θ1, . . . , θk) memberikan global

22
maksimum dari L(θ1, . . . , θk) pada Θ. Karena nilai-nilai dari (θ1, . . . , θk) yang
memaksimumkan L(θ1, . . . , θk) juga memaksimumkan log-likelihood ln L(θ1, . . . , θk),
maka untuk memudahkan perhitungan, kita akan perhatikan fungsi ln L(θ1, . . . , θk)
saja.
2.2.1 Kasus satu parameter (k = 1)
Jika ruang parameter Θ merupakan interval terbuka, dan jika L(·) terdiferensialkan
pada Θ, maka titik-titik extrim terjadi pada titik-titik yang merupakan penyelesaian
dari persamaan
d ln L(θ)
dθ= 0. (2.2.1)
Andaikan θ merupakan satu-satunya penyelesaian, maka titik θ adalah MLE, jika
d2 ln L(θ)
dθ2< 0. (2.2.2)
Jika penyelesaian dari (2.2.1) tidak tunggal, misalkan sebagai θ1, . . . , θm, m ∈ N dan
semuanya memenuhi (2.2.2), maka MLE adalah
arg maxθ1,...,θm
L(θ1), . . . , L(θm). (2.2.3)
Contoh 2.2.2. Misalkan X1, . . . , Xn adalah sampel random dari populasi X ∼ POI(λ),
λ > 0. Fungsi likeihood dari datanya adalah
L(λ) = Πni=1
e−λλxi
xi!=
e−nλλ∑n
i=1 xi
Πni=1(xi!)
.
Fungsi log-likelihoodnya adalah
ln L(λ) = −nλ +n∑
i=1
xi ln λ− Πni=1(xi!).
⇒d ln L(λ)
dλ= 0 ⇔ −n +
1
λ
n∑i=1
xi = 0 ⇔ λ = x.

23
Selanjutnya uji turunan ke dua pada titik λ = x memberikan
d2 ln L(λ)
dλ2= − 1
x2
n∑i=1
xi = −n
x< 0.
Jadi MLE untuk λ adalah λ = X.
Catatan :
Tidak selamanya MLE dapat diperoleh melalui metode diferensial seperti pada kasus
berikut.
Contoh 2.2.3. Misalkan X1, . . . , Xn adalah sampel random dari populasi X ∼ Exp(1, η),
x ≥ η. Fungsi likelihoodnya adalah
L(η) =
Πni=1 exp−(xi − η) = exp−∑n
i=1(xi − η) ; untuk xi ≥ η, ∀i0 ; untuk xi < η, untuk suatu i
.
Karena d ln L(η)dη
= n, maka metode diferensial jelas tidak dapat diterapkan, oleh karena
itu kita harus mencari metode alternatif. Misalkan x1:n, . . . , xr:n, . . . , xn:n merupakan
sampel terurut, yaitu x1:n ≤ x2:n ≤ . . . ≤ xr−1:n ≤ xr:n ≤ xr+1:n ≤ . . . ≤ xn:n. Maka
fungsi likelihood dapat pula di nyatakan sebagai
L(η) =
expn(η − x) ; untuk x1:n ≥ η
0 ; untuk η > x1:n
.
Berarti MLE η = X1:n, yaitu sampel terkecil.
2.2.2 Kasus k parameter
Misalkan ruang parametr Θ merupakan himpunan terbuka pada ruang Euclid Rk dan
L(·) terdiferensialkan pada Θ. Titik-titik ekstrim adalah titik-titik yang merupakan

24
penyelesaian dari system persamaan
∂ ln L(θ1, . . . , θk)
∂θj
= 0, j = 1, . . . , k. (2.2.4)
Selanjutnya apakah titik-titik ekstrim ini memberikan nilai maksimum, harus diver-
ifikasi. Untuk kasus k = 2, kita gunakan alat dari kalkulus sebagai berikut. Mis-
alkan L(θ1, θ2) terdiferensialkan sampai order kedua, dan misalkan (θ1, θ2) merupakan
penyelesaian tunggal dari persamaan (2.2.4). Misalkan
D(θ1, θ2) :=
(∂2 ln L(θ1, θ2)
∂θ21
)(∂2 ln L(θ1, θ2)
∂θ22
)−
(∂2 ln L(θ1, θ2)
∂θ1∂θ2
). (2.2.5)
Jika D(θ1, θ2) > 0 dan ∂2 ln L(θ1,θ2)
∂θ21
(θ1, θ2) < 0, maka (θ1, θ2) merupakan MLE. Dalam
kasus penyelesaian dari (2.2.4) tidak tunggal, semua penyelesaian harus diverifikasi
apakah dia merupakan titik maksimum atau bukan. Selanjutnya MLE adalah titik
(θ1, θ2) dengan L(θ1, θ2) terbesar.
Contoh 2.2.4. Misalkan X1, . . . , Xn adalah sampel random dengan Xi ∼ N(µ, σ2).
Kita mempunyai
L(µ, σ2) = Πni=1
1√2πσ2
exp
−1
2σ2(xi − µ)2
, (µ, σ2) ∈ (−∞,∞)× (0,∞)
=1
(2π)n/2σnexp
− 1
2σ2
n∑i=1
(xi − µ)2
ln L(µ, σ2) = −n
2ln(2π)− n
2ln σ2 − 1
2σ2
n∑i=1
(xi − µ)2. (2.2.6)
Dari dua persamaan
∂ ln L(µ, σ2)
∂µ=
1
σ2
n∑i=1
(xi − µ) = 0
∂ ln L(µ, σ2)
∂σ2= − n
2σ2+
1
2σ4
n∑i=1
(xi − µ)2 = 0,

25
diperoleh µ = x dan σ2 =∑n
i=1(xi−x)2
n=: s2
n. Selanjutnya masih harus diverifikasi,
apakah syarat untuk D(σ2, s2n) dipenuhi. Dari persamaan diatas, kita peoleh
∂2 ln L(µ, σ2)
∂µ2(σ2, s2
n) = − n
s4n
∂2 ln L(µ, σ2)
∂(σ2)2(σ2, s2
n) =n
2(σ2)4− 1
(σ2)3
n∑i=1
(xi − x)2 = − n
2s4n
∂2 ln L(µ, σ2)
∂µ∂σ2(σ2, s2
n) = − 1
(s2n)2
n∑i=1
(xi − x) = 0.
Jadi D(σ2, s2n) > 0, dan karena −n/(s2
n)2 selalu negatif, maka dapat dipastikan X
dan S2n :=
∑ni=1(Xi − X)2/n merupakan MLE untuk µ dan σ2.
Contoh 2.2.5. Perhatikan sampel random X1, . . . , Xn dari distribusi Exp(θ, η). Fungsi
densitas populasinya adalah
f(x; θ, η) =
1θexp(x− η)/θ ; x ≥ η
0 ; η > x.
Maka
ln L(θ, η) =
−n ln θ −∑n
i=1(xi − η)/θ ; untuk x1:n ≥ η, ∀i0 ; untuk x1:n < η, untuk suatu i
.
Karena ln L(θ, η) tidak terdiferensial terhadap η pada titik dimana ln L(θ, η) mencapai
maksimum, maka MLE untuk η adalah η = X1:n. Selanjutnya dari persamaan
∂ ln L(η, θ)
∂θ= −n
θ+
1
θ2
n∑i=1
(xi − x1:n) = 0,
diperoleh MLE untuk θ,
θ =1
n
n∑i=1
(Xi −X1:n).

26
2.3 Keriteria-keriteria memilih estimator
Pada dua subbab sebelumnya telah dibahas metode-metode untuk menurunkan es-
timator terhadap parameter-parameter dari populasi. Pada subbab ini kita akan
merumuskan beberapa keriteria untuk membandingkan estimator sehingga kita bisa
memilih yang mana yang ”terbaik”.
2.3.1 Ketakbiasan
Definisi 2.3.1. Misalkan X1, . . . , Xn merupakan sampel random dari populasi fX(·; θ),θ ∈ Θ ⊂ R. Misalkan τ : Θ → R merupakan fungsi real pada ruang parameter. Suatu
estimator T := t(X1, . . . , Xn) disebut estimator tak bias jika E(T ) = τ(θ), ∀θ ∈ Θ.
Sebaliknya, jika kondisi ini tidak dipenuhi, kita sebut T estimator bias.
Contoh 2.3.2. Sebagai contoh misalkan X1, . . . , Xn merupakan sampel random dari
populasi dengan mean µ dan variansi σ2. Dari Contoh 1.2.2, mean sampel X adalah
tak bias untuk µ dan variansi sampel S2 adalah tak bias untuk σ2. Dalam kasus ini
kita memilih τ sebagai fungsi identitas.
Suatu estimator yang bias untuk τ(θ) dapat dimodifikasi dengan cara sedemikian
rupa sehingga hasil modifikasinya tak bias, seperti yang diperagakan pada contoh
berikut.
Contoh 2.3.3. Misalkan X1, . . . , Xn merupakan sampel random dari populasi Exp(θ)
atau Gamma(θ, 1). Jelaslah X tak bias untuk θ. Tetapi 1/X bias terhadap 1/θ,
seperti ditunjukan berikut. Misalkan Y := 2nX/θ =∑n
i=1 2Xi/θ. Maka Y ∼ χ2(2n).

27
Dari Remark 1.3.5, untuk kasus r = −1, berlaku
E(Y −1) =1
2(n− 1)=
θ
2nE
(1
X
)⇒ E
(1
X
)=
n
(n− 1)
1
θ.
Jadi 1/X adalah bias terhadap 1/θ. Misalkan T := (n − 1)/(nX), maka T jelas tak
bias terhadap 1/θ. Berapakah variansi dari T?
2.3.2 Keterkonsentrasian dan UMVUE
Definisi 2.3.4. Misalkan T1 dan T2 merupakan estimator (tidak harus tak bias) untuk
τ(θ). T1 dikatakan lebih terkonsentrasi disekitar τ(θ) daripada T2 jika untuk setiap
ε > 0 berlaku,
P|T1 − τ(θ)| < ε ≥ P|T2 − τ(θ)| < ε. (2.3.1)
Definisi 2.3.5. Misalkan Aτ(θ) merupakan himpunan semua estimator (tidak harus
tak bias) untuk τ(θ). T ∗ dikatakan paling terkonsentrasi disekitar τ(θ) jika untuk
setiap ε > 0 berlaku,
P|T ∗ − τ(θ)| < ε = supT∈Aτ(θ)
P|T − τ(θ)| < ε. (2.3.2)
Remark 2.3.6. Misalkan Uτ(θ) merupakan himpunan semua estimator tak bias untuk
τ(θ). Dengan ketaksamaan Chebychev diperoleh
P|T − τ(θ)| < ε ≥ 1− V ar(T )
ε2, ∀ε > 0. (2.3.3)
Jadi berdasarkan ketaksamaan (2.3.3), jika T ∗ ∈ Uτ(θ), maka T ∗ merupakan estimator
tak bias yang paling terkonsentrasi disekitar τ(θ) dibandingkan dengan estimator-
estimator lainnya di dalam Uτ(θ), jika dipenuhi
V ar(T ∗) = infT∈Uτ(θ)
V ar(T ), ∀θ ∈ Θ. (2.3.4)

28
Kriteria ini menghasilkan suatu konsep baru dalam pemilihan estimator terbaik, yaitu
konsep estimator tak bias dengan variansi minimum seragam (uniformly minimum
variance unbiased estimator), disingkat UMVUE. Selanjutnya estimator tak bias yang
memenuhi (2.3.4) disebut UMVUE.
Teorema 2.3.7. (Batas bawah Cramer-Rao)
Misalkan X1, . . . , Xn merupakan sampel random dari f(·; θ), θ ∈ Θ. Jika T :=
t(X1, . . . , Xn) merupakan estimator tak bias untuk τ(θ), dan jika τ ′(θ) := dτ(θ)/dθ
ada. Maka batas bawah Cramer-Rao untuk τ(θ) adalah
V ar(T ) ≥ [τ ′(θ)]2
nE(
∂∂θ
ln f(Xi; θ))2 (2.3.5)
Proof. Pertama-tama kita definisikan suatu fungsi u : Rn → R, dimana
u(x1, . . . , xn; θ) :=∂
∂θln f(x1, . . . , xn; θ) =
1
f(x1, . . . , xn; θ)
∂
∂θf(x1, . . . , xn; θ)
⇒u(x1, . . . , xn, θ)f(x1, . . . , xn; θ) =∂
∂θf(x1, . . . , xn; θ).
Selanjutnya kita definisikan suatu quantitas random yang masih bergantung pada θ,
yaitu U := u(X1, . . . , Xn; θ). Maka
E(U) =
∫ ∞
−∞· · ·
∫ ∞
−∞u(x1, . . . , xn; θ)f(x1, . . . , xn; θ) dx1 · · · dxn
=
∫ ∞
−∞· · ·
∫ ∞
−∞
∂
∂θf(x1, . . . , xn; θ) dx1 · · · dxn
=∂
∂θ
∫ ∞
−∞· · ·
∫ ∞
−∞f(x1, . . . , xn; θ) dx1 · · · dxn
=∂
∂θ1 = 0.
Pada perhitungan ekspektasi dari U , pertukaran tanda integral dan diferensial dapat
dilakukan karena domain dari integran-nya tidak bergantung pada θ. Dari asumsi T

29
tak bias terhadap τ(θ), diperoleh
τ ′(θ) =∂
∂θE(T )
=∂
∂θ
∫ ∞
−∞· · ·
∫ ∞
−∞t(x1, . . . , xn)f(x1, . . . , xn; θ) dx1 · · · dxn
=
∫ ∞
−∞· · ·
∫ ∞
−∞t(x1, . . . , xn)
∂
∂θf(x1, . . . , xn; θ) dx1 · · · dxn
=
∫ ∞
−∞· · ·
∫ ∞
−∞t(x1, . . . , xn)u(x1, . . . , xn; θ)f(x1, . . . , xn; θ) dx1 · · · dxn
= E(TU).
Dari kedua hasil diatas diperoleh Cov(T, U) = E(TU)−E(T )E(U) = τ ′(θ). Pada sisi
lain, ketaksamaan Cauchy-Schwarz memberikan [Cov(T, U)]2 ≤ V ar(T )V ar(U),
sehingga V ar(T ) ≥ [Cov(T, U)]2/V ar(U) = [τ ′(θ)]2/V ar(U). Selanjutnya kita veri-
fikasi lebih lanjut bentuk dari V ar(U). Mengingat X1, . . . , Xn adalah sampel random,
maka
V ar(U) =V ar
(∂
∂θln Πn
i=1f(Xi; θ)
)= V ar
(n∑
i=1
∂
∂θln f(Xi; θ)
)
=n∑
i=1
V ar
(∂
∂θln f(Xi; θ)
)= nE
(∂
∂θln f(Xi; θ)
)2
.
Dari hasil yang terakhir ini, diperoleh Ketaksamaan (2.3.5).
Catatan :
Jika V ar(T ) mencapai batas bawah Cramer-Rao, maka T jelas merupakan UMVUE.
Contoh 2.3.8. Misalkan X1, . . . , Xn merupakan sampel random dari Exp(θ). Kita
ingin menentukan batas bawah Cramer-Rao untuk τ(θ) = θ. Karena f(Xi; θ) =
1θexp−Xi/θ, maka
E(
∂
∂θln f(Xi; θ)
)2
= E(
Xi − θ
θ2
)2
=V ar(Xi)
θ4=
1
θ2.

30
Batas bawah Cramer-Rao untuk θ adalah θ2/n. Karena X merupakan estimator tak
bias untuk θ dengan V ar(X) = θ2/n, maka X merupakan UMVUE untuk θ.
Catatan:
Variansi dari suatu estimator tak bias T untuk τ(θ) akan mencapai (sama dengan)
batas bawah Cramer-Rao untuk τ(θ), jika [Cov(T, U)]2 = V ar(T )V ar(U). Dengan
kata lain korelasi antara T dan U harus sama dengan 1 atau −1. Ini terjadi, jika dan
hanya jika T merupakan fungsi linear dari U , yaitu fungsi yang berbentuk T = aU +b
untuk suatu konstanta a dan b.
Contoh 2.3.9. Misalkan X1, . . . , Xn merupakan sampel random dari distribusi Geo(p),
dengan f(Xi; p) = p(1− p)1−Xi, Xi = 0, 1, dan E(X) = 1/p. Kita ingin menentukan
estimator T yang tak bias terhadap 1/p, sedemikian hingga T = aU + b, untuk suatu
konstanta a dan b. Dari rumus fungsi densitasnya, kita dapatkan
U =n∑
i=1
∂
∂p(ln p + (Xi − 1) ln(1− p)) =
n∑i=1
(1
p− Xi − 1
1− p
).
Sehingga setelah penyederhanaan diperoleh
T := aU + b =an
p− 1X +
(b− an
p(p− 1)
)= cX + d,
dimana c := anp−1
dan d := b − anp(p−1)
. Karena X merupakan estimator tak bias
untuk 1/p, sehingga agar T juga tak bias terhadap 1/p, maka harus dipilih c = 0 dan
d = 0. Variansi dari X adalah (1−p)/(np2) dan dipastikan sama dengan batas bawah
Cramer-Rao untuk 1/p.
Definisi 2.3.10. Misalkan T , T ∗ ∈ Uτ(θ), dimana Uτ(θ) adalah himpunan semua
estimator tak bias untuk τ(θ). Efisiensi relatif dari T terhadap T ∗ adalah
re(T, T ∗) :=V ar(T ∗)V ar(T )
. (2.3.6)

31
Estimator T ∗ ∈ Uτ(θ) dikatakan efisien jika re(T, T ∗) ≤ 1, ∀T ∈ Uτ(θ) and ∀θ ∈ Θ.
Selanjutnya, jika T ∗ merupakan estimator yang efisien, maka efisiensi dari suatu
estimator T ∈ Uτ(θ) diberikan oleh e(T ) := re(T, T ∗).
Definisi 2.3.11. Misalkan T merupakan sembarang estimator untuk τ(θ). Bias dari
T terhadap τ(θ), dinotasikan sebagai b(T ) adalah
b(T ) := E(T )− τ(θ). (2.3.7)
Sedangkan mean dari kudrat kesalahan mengestimasi τ(θ) dengan T disebut MSE
(engl. mean squared error) dari T , adalah
MSE(T ) := E (T − τ(θ))2 . (2.3.8)
Teorema 2.3.12. If T merupakan suatu estimator untuk τ(θ), maka
MSE(T ) = V ar(T ) + [b(T )]2.
Proof.
MSE(T ) =E (T − E(T ) + E(T )− τ(θ))2
=E (T − E(T ))2 + (E(T )− E(T )) (E(T )− τ(θ)) + (E(T )− τ(θ))2
=E (T − E(T ))2 + (E(T )− τ(θ))2
=V ar(T ) + [b(T )]2.
Keriteria MSE mengakomodasi dua quantitas yaitu variansi dan bias. Kriteria ini
akan sesuai dengan kriteria UMVUE jika perhatian kita batasi pada estimator tak
bias.

32
2.4 Soal-soal
1. Jika X1, . . . , Xn merupakan sampel random yang diambil dari populasi berikut.
Tentukan MME dan MLE untuk parameter-parameternya!
(a) f(x; θ) =
θxθ−1 ; 0 < x < 1
0 ; x ≤ 0 atau x ≥ 1, θ > 0.
(b) f(x; θ) =
(θ + 1)x−θ−2 ; 1 < x
0 ; x ≤ 1, θ > 0.
(c) f(x; θ) =
θ2xe−θx ; 0 < x
0 ; x ≤ 0, θ > 0.
(d) Xi ∼ PAR(θ, κ), θ dan κ tidak diketahui.
(e) f(x; θ1, η) =
θηθx−θ−1 ; η ≤ x
0 ; x < η, 0 < θ, 0 < η < ∞.

Chapter 3
Statistik cukup, keluarga lengkap
dan keluarga eksponensial
Pada chapter ini kita akan membahas konsep statistik cukup (engl. sufficient statis-
tic), statistik lengkap (engl. complete statistic) dan suatu keluarga fungsi distribusi
probabilitas yang disebut keluarga eksponensial (engl. exponential family). Ketiga
konsep ini sangat penting karena melandasi konsep perumusan prosudur inferensi pa-
rameter, seperti estimasi interval dan uji hipotesis yang akan dibahas pada 2 chapter
berikutnya.
3.1 Statistik cukup
Sebelum kita memberikan definisi formal dari statistik cukup, kita ikuti ilustrasi
berikut. Misalkan X1, . . . , Xn merupakan sampel random dari populasi BIN(1, θ),
0 < θ < 1. Fungsi densitas bersama dari X1, . . . , Xn dihitung pada titik (x1, . . . , xn)
33

34
adalah
fX1,...,Xp(x1, . . . , xn; θ) =
θ
∑ni=1 xi(1− θ)n−∑n
i=1 xi ; jika xi ∈ 0, 1, ∀i0 ; jika xi 6∈ 0, 1
.
Andaikan kita tertarik pada statistik Y1 :=∑n
i=1 Xi. Jelas Y1 berdistribusi BIN(n, θ),
sehingga fungsi densitas dari Y1 adalah
fY1(y1; θ) =
(n
y1
)θy1(1− θ)n−y1 ; jika y1 ∈ 0, 1, . . . , n
0 ; jika y1 6∈ 0, 1, . . . , n.
Misalkan A := ω ∈ Ω : Y1(X1(ω), . . . , Xn(ω)) = y1. Untuk suatu titik (x1, . . . , xn)
yang tertetu, misalkan B := ω ∈ Ω : X1(ω) = x1, . . . , Xn(ω) = xn. Maka B ∩ A =
B, jika Y1(x1, . . . , xn) = y1. Sebaliknya jika Y1(x1, . . . , xn) 6= y1, maka B ∩ A = ∅.Sehingga peluang bersyarat
P X1 = x1, . . . , Xn = xn | Y1 = y1 = P(B | A) =P(B ∩ A)
P(A)
=
θ∑n
i=1 xi (1−θ)n−∑ni=1 xi
n
y1
θy1 (1−θ)n−y1
; jika Y1(x1, . . . , xn) = y1
0 ; jika Y1(x1, . . . , xn) 6= y1
=
1
n
y1
; jika∑n
i=1 xi = y1
0 ; jika∑n
i=1 xi 6= y1
.
Jadi P X1 = x1, . . . , Xn = xn | Y1 = y1 tidak bergantung pada θ untuk setiap titik
(data) (x1, . . . , xn) yang memenuhi sifat∑n
i=1 xi = y1. Statistik Y1 yang memenuhi
sifat ini disebut statistik cukup untuk θ.
Definisi 3.1.1. Misalkan X1, . . . , Xn merupakan sampel random dari populasi dengan
fungsi densitas fX(·; θ), θ ∈ Θ ⊆ R. Misalkan Y1 = u1(X1, . . . , Xn) merupakan

35
statistik dengan fungsi densitas gY1(·; θ), θ ∈ Θ. Maka Y1 adalah statistik cukup
untuk θ, jika dan hanya jika
fX1,...,Xn(x1, . . . , xn; θ)
gY1(y1; θ)= H(x1, . . . , xn), (3.1.1)
dimana H(x1, . . . , xn) adalah fungsi yang tidak bergantung pada θ untuk setiap titik
(data) (x1, . . . , xn) dengan sifat u1(x1, . . . , xn) = y1.
Catatan :
Jika Y1 merupakan statistik cukup untuk θ, semua informasi tentang parameter θ
dibawa oleh Y1. Ini berarti inferensi tentang θ harus didasarkan pada Y1 bukan pada
statistik yang lain. Selanjutnya, pada bagian ini kita batasi pembicaraan pada kasus
variabel kontinu dengan satu parameter, yaitu Θ ⊆ R. Kasus diskrit ditangani secara
analog.
Teorema 3.1.2. (Teorema Faktorisasi)
Misalkan X1, . . . , Xn merupakan sampel random dari populasi dengan fungsi densitas
fX(·; θ), θ ∈ Θ. Statistik Y1 = u1(X1, . . . , Xn) merupakan statistik cukup untuk θ,
jika dan hanya jika terdapat fungsi-fungsi tidak negatif k1 dan k2 sedemikian hingga
fX1,...,Xn(x1, . . . , xn; θ) = k1(u1(x1, . . . , xn); θ)k2(x1, . . . , xn),
dimana untuk setiap titik (x1, . . . , xn) yang bersifat y1 = u1(x1, . . . , xn), k2(x1, . . . , xn)
tidak bergantung pada θ.
Proof. (⇐) Pertama-tama kita definisikan suatu transformasi satu-satu
y1 = u1(x1, . . . , xn), . . . , yn = un(x1, . . . , xn)
dengan invers
x1 = w1(y1, . . . , yn), . . . , xn = wn(y1, . . . , yn).

36
Maka fungsi densitas bersama dari Y1, . . . , Yn adalah
fY1,...,Yn(y1, . . . , yn; θ) = fX1,...,Xn(x1, . . . , xn; θ) |J |
= k1(u1(x1, . . . , xn); θ)k2(x1, . . . , xn) |J |
= k1(y1; θ)k2(w1(y1, . . . , yn), . . . , wn(y1, . . . , yn)) |J | .
Fungsi densitas marginal dari Y1 adalah
gY1(y1; θ) =
∫ ∞
−∞· · ·
∫ ∞
−∞k1(y1; θ)k2(w1(y1, . . . , yn), . . . , wn(y1, . . . , yn)) |J | dy2 · · · dyn
= k1(y1; θ)
∫ ∞
−∞· · ·
∫ ∞
−∞k2(w1(y1, . . . , yn), . . . , wn(y1, . . . , yn)) |J | dy2 · · · dyn
= k1(y1; θ)m(y1),
dimana m(y1) :=∫∞−∞ · · ·
∫∞−∞ k2(w1(y1, . . . , yn), . . . , wn(y1, . . . , yn)) |J | dy2 · · · dyn. Di
sini jelas bahwa m(y1) merupakan fungsi yang tidak bergantung pada θ maupun
y2, . . . , yn, melainkan hanya pada y1. Sehingga
fX1,...,Xn(x1, . . . , xn; θ)
gY1(y1; θ)=
k1(u1(x1, . . . , xn); θ)k2(x1, . . . , xn)
k1(u1(x1, . . . , xn); θ)m(u1(x1, . . . , xn))
=k2(x1, . . . , xn)
m(u1(x1, . . . , xn)).
Karena ruas kanan dari persamaan yang terakhir tidak bergantung pada θ untuk
setiap (x1, . . . , xn) yang bersifat y1 = u1(x1, . . . , xn), sesuai Definisi (3.1.1), Y1 adalah
statistik cukup untuk θ.
(⇒) Jika Y1 = u1(X1, . . . , Xn) merupakan statistik cukup untuk θ, maka sesuai Defin-
isi (3.1.1), berlaku
fX1,...,Xn(x1, . . . , xn; θ)
gY1(y1; θ)= H(x1, . . . , xn),
dimana H(x1, . . . , xn) merupakan suatu fungsi yang tidak bergantung pada θ untuk
setiap (x1, . . . , xn) yang bersifat u1(x1, . . . , xn) = y1. Selanjutnya dengan mengambil

37
k1(u1(x1, . . . , xn); θ) := gY1(y1; θ) dan k2(x1, . . . , xn) := H(x1, . . . , xn), maka syarat
perlu terbukti.
Contoh 3.1.3. Misalkan X1, . . . , Xn merupakan sampel random dari N(µ, σ2), den-
gan −∞ < µ < ∞ dan diasumsikan σ2 diketahui. Apakah X merupakan statistik
cukup untuk µ?. Karena
fX1,...,Xn(x1, . . . , xn; µ, σ2) =1
(2π)n/2σnexp
− 1
2σ2
n∑i=1
(xi − µ)2
=1
(2π)n/2σnexp
− 1
2σ2
(n∑
i=1
(xi − x)2 + n(x− µ)2
)
Kita akan menerapkan Teorema Faktorisasi, karena itu kita harus mengelompokan x
dan µ ke dalam argumen dari k1, sedangkan k2 tidak boleh bergantung pada µ. Ambil
k1(x; µ) := exp−n(x−µ)2
2σ2 dan k2(x1, . . . , xn) := 1(2π)n/2σn exp− 1
2σ2
∑ni=1(xi − x)2.
Maka berlaku fX1,...,Xn(x1, . . . , xn; µ, σ2) = k1(x; µ)k2(x1, . . . , xn). Karena k2 tidak
bergantung pada µ maka X merupakan statistik cukup untuk µ.
Contoh 3.1.4. Misalkan X1, . . . , Xn merupakan samplel random dari populasi den-
gan fungsi densitas f(x; θ) =
θxθ−1 ; 0 < x < 1
0 ; x ≤ 0 atau x ≥ 1, θ > 0. Dengan fak-
torisasi,
fX1,...,Xn(x1, . . . , xn; θ) =
θn (Πni=1xi)
θ−1 ; 0 < xi < 1, ∀i0 ; ∃i, xi ≤ 0 atau xi ≥ 1
, θ > 0.
Atau fX1,...,Xn(x1, . . . , xn; θ) = θn (Πni=1xi)
θ 1Πn
i=1xi, 0 < xi < 1, ∀i. Dengan mendefin-
isikan k1(Πni=1xi; θ) := θn (Πn
i=1xi)θ dan k2(x1, . . . , xn) := 1
Πni=1xi
, statistik Πni=1Xi
merupakan statistik cukup untuk θ.
Catatan
Misalkan Y1 := u1(X1, . . . , Xn) merupakan statistik cukup untuk θ ∈ Θ. Jika Z :=

38
u(Y1) atau Z = u(u1(X1, . . . , Xn)) := ν(X1, . . . , Xn) dengan invers Y1 := w(Z), maka
Z juka merupakan statistik cukup untuk θ. Ini terjadi karena
fX1,...,Xn(x1, . . . , xn; θ) = k1(u1(x1, . . . , xn); θ)k2(x1, . . . , xn)
= k1(w(ν(x1, . . . , xn)); θ)k2(x1, . . . , xn)
Karena k1 hanya bergantung pada z = ν(x1, . . . , xn) dan θ sedangkan k2 tidak bergan-
tung pada θ, maka teorema faktorisasi Z = u(Y1) merupakan statistik cukup untuk
θ ∈ Θ.
Teorema 3.1.5. Misalkan X1, . . . , Xn merupakan sampel random dari populasi X
dengan fungsi densitas fX(·, θ), θ ∈ Θ. Jika Y1 = u1(X1, . . . , Xn) merupakan statistik
cukup untuk θ dan θ adalah MLE untuk θ dengan θ tunggal, maka terdapat suatu
fungsi h : R→ R, sedemikian hingga θ = h(Y1).
Proof. Dari teorema faktorisasi diperoleh
L(θ) = fX1,...,Xn(x1, . . . , xn; θ)
= k1(u1(x1, . . . , xn); θ)k2(x1, . . . , xn)
⇒ L(θ) = maxθ∈Θ
k1(u1(x1, . . . , xn); θ)k2(x1, . . . , xn).
Karena k2 merupakan fungsi yang tidak bergantung pada θ, maka berlaku
k1(u1(x1, . . . , xn); θ) = maxθ∈Θ
k1(u1(x1, . . . , xn); θ).
Dengan kata lain θ memaksimumkan L(θ) dan k1(u1(x1, . . . , xn); θ) secara simultan.
Dari persamaan yang terakhir θ merupakan suatu fungsi dari u1(x1, . . . , xn), yaitu
θ = h(u1(x1, . . . , xn)) untuk setiap (x1, . . . , xn) yang bersifat u1(x1, . . . , xn) = y1.
Jadi θ = h(Y1).

39
Teorema 3.1.6. (Teorema Rao-Blackwell)
Misalkan X dan Y merupakan dua variabel random. Misalkan µX := E(X) dan
µY := E(Y ). Misalkan ϕ : R→ R dengan ϕ(x) := E(Y | X = x). Maka
1. E(ϕ(X)) = µY , dengan kata lain ϕ(Y ) adalah tak bias terhadap µY .
2. V ar(ϕ(X)) ≤ V ar(Y ).
Proof. Kita buktikan teorema ini untuk kasus X dan Y variabel random kontinu,
sedangkan pembukiannya analog dengan kasus kontinu. Misalkan fX(·) dan fY (·)masing-masing merupakan fungsi densitas marginal dari X dan Y . Misalkan fX,Y (·)merupakan fungsi densitas bersama dari X dan Y , sedangkan fY |X(· | x) merupakan
fungsi densitas bersyarat dari Y diberikan X = x untuk suatu x ∈ R. Maka
ϕ(x) = E(Y | X = x) =
∫ ∞
−∞yfY |X(y | x)dy =
∫ ∞
−∞yfX,Y (x, y)
fX(x)dy
⇒ϕ(x)fX(x) =
∫ ∞
−∞yfX,Y (x, y)dy.
Sehingga
E(ϕ(X)) =
∫ ∞
−∞ϕ(x)fX(x)dx =
∫ ∞
−∞
(∫ ∞
−∞yfX,Y (x, y)dy
)dx
=
∫ ∞
−∞y
(∫ ∞
−∞fX,Y (x, y)dx
)dy =
∫ ∞
−∞yfY (y)dy = µY .
Ini membuktikan pernyataan pertama. Untuk membuktikan pernyataan kedua, kita
berjalan dari definisi dasar dari V ar(Y ). Dari definisi diperoleh
V ar(Y ) = E (Y − µY )2 = E (Y − ϕ(X) + ϕ(X)− µY )2
= E (Y − ϕ(X))2 + E (ϕ(X)− µY )2 + 2E (Y − ϕ(X)) (ϕ(X)− µY )
= E (Y − ϕ(X))2 + V ar (ϕ(X)) + 2E (Y − ϕ(X)) (ϕ(X)− µY )

40
Pernyataan ke dua akan terbukti jika 2E (Y − ϕ(X)) (ϕ(X)− µY ) = 0. Karena
fX,Y (x, y) = fX(x)fY |X(y | x), maka diperoleh
E (Y − ϕ(X)) (ϕ(X)− µY ) =
∫ ∞
−∞
∫ ∞
−∞(y − ϕ(x))(ϕ(x)− µY )fX,Y (x, y)dydx
=
∫ ∞
−∞(ϕ(x)− µY )
(∫ ∞
−∞(y − ϕ(x))fY |X(y | x)dy
)fX(x)dx.
Tetapi
∫ ∞
−∞(y − ϕ(x))fY |X(y | x)dy =
∫ ∞
−∞yfY |X(y | x)dy −
∫ ∞
−∞ϕ(x)fY |X(y | x)dy
=
∫ ∞
−∞yfY |X(y | x)dy − ϕ(x)
∫ ∞
−∞fY |X(y | x)dy
= ϕ(x)− ϕ(x) = 0.
Selanjutnya karena E (Y − ϕ(X))2 ≥ 0, maka terbukti V ar(ϕ(X)) ≤ V ar(Y ).
Catatan :
Jika P (X,Y )(x, y) ∈ R2 : y − ϕ(x) = 0 = 0, maka kita peroleh ketaksamaan tegas
(engl. strick): V ar(ϕ(X)) < V ar(Y ). Ini terjadi karena hal berikut
E (Y − ϕ(X))2 =
∫ ∞
−∞
∫ ∞
−∞(y − ϕ(x))2fX,Y (x, y)dxdy
=
∫
(x,y)∈R2:(y−ϕ(x))2=0(y − ϕ(x))2fX,Y (x, y)dxdy
+
∫
(x,y)∈R2:(y−ϕ(x))2>0(y − ϕ(x))2fX,Y (x, y)dxdy
= 0 +
∫ ∞
−∞1(x,y)∈R2:(y−ϕ(x))2>0(y − ϕ(x))2fX,Y (x, y)dxdy
> 0
∫ ∞
−∞fX,Y (x, y)dxdy = 0,
dimana untuk suatu A ⊂ R2, 1A adalah indikator untuk A yang didefinisikan sebagai
1A(x, y) :=
1; jika (x, y) ∈ A
0; jika (x, y) 6∈ A

41
Contoh 3.1.7. Misalkan X ∼ N(µ1, σ21) dan Y ∼ N(µ2, σ
22), Cor(X, Y ) = ρ. Maka,
E (Y | X = x) =
∫ ∞
−∞yfX,Y (x, y; µ1, µ2, σ
21, σ
22)
fX(x; µ1, σ21)
dy
=µ2 + ρσ2
σ1
(x− µ1) =: ϕ(x),
(lihat Hogg dan Craig, 1978, hal. 117-118). Sehingga kita peroleh
E (ϕ(X)) = E(
µ2 + ρσ2
σ1
(X − µ1)
)= µ2.
Jadi hasil ini sesui dengan pernyataan pertama dari teorema Rao-Blackwell. Tetapi
ϕ(X) bukan merupakan statistik, karena dia bergantung pada lima parameter yang
tidak diketahui. Selanjutnya
V ar(ϕ(X)) = E(
µ2 + ρσ2
σ1
(X − µ1)− µ2
)2
= E(
ρσ2
σ1
(X − µ1)
)2
= ρ2σ22
σ21
σ21 = ρ2σ2
2.
Karena −1 < ρ < 1, yang berakibat ρ2 < 1, maka V ar(ϕ(X)) < σ22. Jadi hasil ini
sesuai dengan pernyataan kedua dari teorema Rao-Blackwell bahkan dengan ketak-
samaan tegas.
Kita selanjutnya akan membahas aplikasi dari teorema Rao-Blackwell pada konsep
statistik cukup dan konsep pemilihan estimator titik dengan variansi minimum.
Teorema 3.1.8. Misalkan X1, . . . , Xn merupakan sampel random dari suatu populasi
X dengan fungsi densitas fX(·; θ), θ ∈ Θ. Misalkan Y1 := u1(X1, . . . , Xn) merupakan
statistik cukup untuk θ dan Y2 := u2(X1, . . . , Xn) merupakan estimator tak bias un-
tuk θ, tetapi Y2 merupakan fungsi bukan hanya dari Y1 saja. Selanjutnya misalkan
ϕ(y1) := E(Y2 | Y1 = y1), y1 ∈ R. Maka berlaku:

42
1. ϕ(Y1) merupakan statistik.
2. ϕ(Y1) merupakan estimator tak bias untuk θ.
3. V ar(ϕ(Y1)) ≤ V ar(Y2).
Proof. Teorema ini merupakan akibat langsung dari teorema Rao-Blackwell. Karena
Y2 merupakan statistik cukup untuk θ, maka
fY2|Y1(y2 | y1) =fY1,Y2(y1, y2; θ)
fY2(y2; θ)
tidak bergantung pada θ. Ini berakibat
ϕ(y1) := E(Y2 | Y1 = y1) =
∫ ∞
−∞y2
fY1,Y2(y1, y2; θ)
fY2(y2; θ)dy2
tidak bergantung pada θ ∈ Θ. Jadi ϕ(Y1) adalah statistik. Lebih lanjut, dari teorema
Rao-Blackwell diperoleh pernyataan kedua dan ketiga.
Catatan :
Teorema 3.1.8 merupakan alat bantu dalam memperoleh suatu estimator tak bias
dengan variansi minimum untuk suatu parameter. Jika kita diberikan suatu statistik
cukup untuk parameter θ, misalkan Y1 dan misalkan diketahui Y2 merupakan suatu
quantitas (merupakan fungsi bukan hanya dari Y1) yang tak bias terhadap θ, maka
kita selalu bisa mendefinisikan suatu statistik ϕ(Y1) sebagai estimator tak bias untuk
θ dengan variansi yang lebih kecil dari V ar(Y2).
3.2 Keluarga lengkap
Definisi 3.2.1. Misalkan PX merupakan suatu ukuran probabilitas pada R yang di
induce oleh variabel random X. Suatu sifat(pernyataan) p dikatakan dipenuhi PX-
hampir pasti, ditulis PX-h.p., jika terdapat suatu himpunan N ⊂ R dengan PX(N) = 0

43
sedemikian hingga jika x ∈ N c, maka berlaku p.
Definisi 3.2.2. Misalkan X merupakan variabel random kontinu atau diskrit dengan
fungsi densitas didalam keluarga PXΘ := fX(·; θ); θ ∈ Θ. Keluarga PX
Θ dikatakan
keluarga lengkap jika dipenuhi: E(u(X)) = 0, ∀θ ∈ Θ berakibat u(x) = 0, PX-h.p.
Contoh 3.2.3. Misalkan X1, . . . , Xn merupakan sampel random dari populasi berdis-
tribusi POIS(θ), θ > 0. Maka Y1 :=∑n
i=1 Xi ∼ POIS(nθ), θ > 0 dengan fungsi
densitas
fY1(y1; θ) =(nθ)y1e−nθ
y1!, y1 ∈ 0, 1, 2, . . ..
Selanjutnya karena e−nθ > 0, ∀θ > 0, berlaku
E(u(Y1)) = 0,∀θ > 0 ⇒∞∑
y1=0
u(y1)(nθ)y1
y1!= 0, ∀θ > 0
⇒ u(y1)(nθ)y1
y1!= 0, ∀y1 ∈ 0, 1, 2, . . .
⇒ u(y1) = 0, ∀y1 ∈ 0, 1, 2, . . ..
Jadi terdapat N := ∅ sedemikian hingga u(y1) = 0, jika y1 ∈ N c = 0, 1, 2, . . ..Dengan kata lain keluarga Poisson adalah keluarga lengkap.
Contoh 3.2.4. Misalkan fungsi densitas dari Z merupakan anggota dari keluarga
Exp(θ), θ > 0, dengan fZ(z; θ) = 1θe−z/θ, z > 0 dan θ > 0. Jika E(u(Z)) = 0,
∀θ > 0, maka
1
θ
∫ ∞
0
u(z)e−z/θ dz = 0, ∀θ > 0 ⇒∫ ∞
0
u(z)e−z/θ dz = 0, ∀θ > 0
⇒ u(z) = 0, PZ − h.p.
Kesimpulan ini bisa diambil karena integral yang terakhir adalah transformasi Laplace
dari u(z) kesuatu fungsi dari θ dengan hasil transformasi identik dengan fungsi nol.
Fungsi yang memenuhi sifat tersebut pastilah fungsi nol sendiri.

44
Teorema 3.2.5. Misalkan X1, . . . , Xn merupakan sampel random dari populasi X
dengan fungsi densitas fX(·; θ), θ ∈ Θ. Misalkan Y1 := u1(X1, . . . , Xn) meru-
pakan statistik cukup untuk θ dengan fungsi densitas merupakan anggota dari keluarga
lengkap fY1(·; θ); θ ∈ Θ. Jika terdapat suatu fungsi dari Y1 yang merupakan estima-
tor tak bias untuk θ, untuk setiap θ ∈ Θ, maka fungsi tersebut tunggal PY1-h.p. dan
fungsi ini merupakan estimator dengan variansi terkecil.
Proof. Misalkan Y2 merupakan suatu quantitas yang tak bias terhadap θ, maka menu-
rut Teorema 3.1.8, terdapat sekurang-kurangnya satu fungsi dari Y1, yaitu ϕ(Y1) den-
gan E(ϕ(Y1)) = θ, ∀θ ∈ Θ. Andaikan terdapat fungsi lain, misalkan ψ(Y1) dengan
sifat E(ψ(Y1)) = θ, ∀θ ∈ Θ, maka E(ϕ(Y1)− ψ(Y1)) = 0, ∀θ ∈ Θ. Karena fungsi den-
sitas dari Y1 termasuk keluarga lengkap, ini berakibat terdapat (−∞, 0] =: N ⊂ R
dengan PY1(N) = 0 sedemikian hingga ϕ(y1) = ψ(y1), ∀y1 ∈ N c := (0,∞). Jadi
ϕ = ψ PY1-h.p. Menurut teorema Rao-Blackwell, ϕ(Y1) mempunyai variansi terkecil
diantara semua estimator tak bias untuk θ ∈ Θ.
3.3 Keluarga eksponensial
Definisi 3.3.1. Milsakan PΘ := f(·; θ); θ ∈ Θ merupakan keluarga fungsi densi-
tas, dimana Θ adalah suatu interval, misalkan sebagai γ < θ < δ dengan γ dan δ
merupakan konstanta-konstanta yang diketahui. Misalkan fungsi densitas ini dapat
dituliskan sebagai
f(x; θ) = expp(θ)K(x) + S(x) + q(θ), x ∈ A
dimana A := x ∈ R; f(x; θ) > 0. Maka PΘ adalah keluarga eksponensial
reguler tipe kontinu, jika dipenuhi:

45
1. A tidak bergantung pada θ, γ < θ < δ.
2. p(θ) merupakan fungsi nontrivial dan kontinu pada γ < θ < δ.
3. dK(x)/dx 6= 0 dan kontinu pada A.
4. S(x) merupakan fungsi kontinu pada A.
Selanjutnya PΘ dikatakan keluarga eksponensial reguler tipe diskrit jika dipenuhi
kondisi-kondisi berikut:
1. A tidak bergantung pada θ, γ < θ < δ.
2. p(θ) merupakan fungsi nontrivial dan kontinu pada γ < θ < δ.
3. K(x) kontinu pada A.
Catatan :
Jika X1, . . . , Xn merupakan sampel random dari populasi dengan fungsi densitas dari
keluarga f(·; θ) : γ < θ < δ yang merupakan keluarga exsponensial reguler (kontinu
atau diskrit), maka fungsi densitas bersama dari X1, . . . , Xn adalah
fX1,...,Xn(x1, . . . , xn; θ) = exp
p(θ)
n∑i=1
K(xi) +n∑
i=1
S(xi) + nq(θ)
Contoh 3.3.2. Keluarga N(0, θ) : θ > 0 adalah keluarga eksponensial reguler tipe
kontinu, karena fungsi densitasnya dapat dituliskan sebagai
f(x; θ) =1√2πθ
exp
−x2
2θ
, 0 < θ < ∞
= exp
−x2
2θ− 1
2ln(2πθ)
.
Selanjutnya misalkan p(θ) := −1/θ, K(x) := x2, S(x) := 0 dan q(θ) := − ln(2πθ)/2.
Maka kondisi 1-4 diatas dipenuhi.

46
Teorema 3.3.3. Jika X1, . . . , Xn merupakan sampel random dari populasi dengan
fungsi densitas dari keluarga f(·; θ) : γ < θ < δ yang merupakan keluarga exspo-
nensial reguler (kontinu atau diskrit). Maka Y1 :=∑n
i=1 K(Xi) merupakan statistik
cukup untuk θ dan keluarga fY1(·; θ) : γ < θ < δ merupakan keluarga lengkap.
Selanjutnya Y1 disebut statistik cukup dan lengkap.
Contoh 3.3.4. Pada Contoh 3.3.2, Y1 =∑n
i=1 X2i merupakan statistik cukup dan
lengkap untuk θ. Misalkan ϕ(Y1) := Y1/n, maka E(ϕ(Y1)) = θ. Jadi Y1/n juga
statistik cukup dan lengkap. Lebih jauh, Y1 merupakan estimator tak bias dengan
variansi minimum dengan ϕ tunggal PY1-h.p.
Contoh 3.3.5. Misalkan X1, . . . , Xn merupakan sampel random dari populasi POIS(θ),
θ > 0. Karena f(x; θ) = expln θx + ln(x!) − θ, jadi POIS(θ), θ > 0 merupakan
keluarga eksponensial reguler diskrit, sehingga
fX1,...,Xn(x1, . . . , xn; θ) = exp
ln θ
n∑i=1
xi +n∑
i=1
ln(xi!)− nθ
.
Menurut Teorema 3.3.3, Y1 :=∑n
i=1 Xi merupakan statistik cukup dan lengkap untuk
θ. Selanjutnya Y1/n = X juga merupakan statistik cukup dan lengkap untuk θ dengan
E(Y1/n) = θ, ∀θ > 0. Jadi X merupakan estimator tak bias terbaik untuk θ.
3.4 Soal-soal

Chapter 4
Estimasi interval
Pada Chapter 2 dan Chapter 3 telah dibahas beberapa metode menentukan estimasi
titik untuk suatu parameter, misalnya θ, serta keriteria-keriteria untuk memilih es-
timator terbaik untuk θ. Tetapi estimator titik tidak memberikan informasi tentang
akurasi. Salah satu penyelesaian terhadap masalah ini adalah dengan merumuskan su-
atu interval random, yaitu interval untuk θ yang batas-batasnya merupakan statistik.
Ineterval ini dikonstruksikan dengan cara sedemikian, sehingga peluangnya sebesar
mungkin.
Misalkan X1, . . . , Xn merupakan n variabel random dengan fungsi densitas bersama
fX1,...,Xn(x1, . . . , xn; θ), θ ∈ Θ ⊆ R. Misalkan θL, dan θU merupakan statistik dengan
θL := `(X1, . . . , Xn) dan θU := u(X1, . . . , Xn). Jika (x1, . . . , xn) merupakan realisasi
dari X1, . . . , Xn, maka `(x1, . . . , xn) dan u(x1, . . . , xn) merupakan nilai-nilai teramati
dari θL dan θU .
Definisi 4.0.1. Untuk suatu γ ∈ (0, 1), jika
P `(X1, . . . , Xn) < θ < u(X1, . . . , Xn) = γ, ∀θ ∈ Θ,
47

48
maka interval (`(x1, . . . , xn), u(x1, . . . , xn)) disebut interval kepercayaan dua sisi 100γ%
untuk θ. Selanjutnya nilai-nilai teramati `(x1, . . . , xn) disebut batas bawah, sedangkan
u(x1, . . . , xn) disebut batas atas.
Catatan:
1. Batas-batas dari interval random (θL, θU) haruslah merupakan statistik, se-
hingga nilai-nilainya untuk setiap pengamatan dapat ditentukan. Selanjutnya
interval random (θL, θU) disebut estimator interval untuk θ. Sedangkan interval
yang batas-batasnya merupakan bilangan `(x1, . . . , xn) dan u(x1, . . . , xn) dise-
but estimasi interval untuk θ.
2. Bentuk interval tidak selamanya terbuka, tetapi bisa juga interval tertutup
sesuai dengan jenis variabelnya apakah kontinu atau diskrit.
Definisi 4.0.2. Interval (`(x1, . . . , xn),∞) disebut batas kepercayaan bawah 100γ%
untuk θ ∈ Θ, jika P `(X1, . . . , Xn) < θ = γ, ∀θ ∈ Θ. Sedangkan (−∞, u(x1, . . . , xn))
disebut batas kepercayaan atas 100γ% untuk θ ∈ Θ, jika P θ < u(X1, . . . , Xn) = γ,
∀θ ∈ Θ.
Contoh 4.0.3. Misalkan daya tahan bola lampu yang diproduksi oleh pabrik A dia-
sumsikan berdistribusi Exp(θ), θ > 0. Andaikan kita ingin mengkonstruksikan inter-
val kepercayaan 95% untuk θ, θ > 0. Untuk menyelesaiakn masalah ini, kita ambil
sampel random X1, . . . , Xn dari populasi Exp(θ). Jelaslah X merupakan statistik
cukup dan merupakan UMVUE untuk θ, ∀θ > 0. Karena 2nX/θ berdistribusi χ2(2n),
secara umum kita pilih konstanta α1 dan α2, 0 < α1, α2 < 1 dengan α1 + α2 =
α ∈ (0, 1), sedemikian hingga Pχ2
α1(2n) < 2nX/θ < χ2
1−α2(2n)
= 1 − (α2 + α1) =

49
1−α =: γ, dimana χ2α(2n) adalah kuantil ke α dari distribusi chi-square dengan dera-
jat bebas 2n (lihat Chapter 1). Biasanya dipilih α1 = α2 = α/2. Jika dipilih α = 0, 05
atau α/2 = 0, 025, maka Pχ2
0,025(2n) < 2nX/θ < χ20,975(2n)
= 0, 95. Karena
χ2
0,025(2n) < 2nX/θ < χ20,975(2n)
dan
2nX/χ2
0,975(2n) < θ < 2nX/χ20,025(2n)
me-
rupakan dua kejadian yang ekuivalen, maka interval(2nx/χ2
0,975(2n), 2nx/χ20,025(2n)
)
merupakan interval kepercayaan dua sisi 95% untuk θ. Andaikan dari suatu penga-
matan dengan n = 40 diperoleh data dengan x = 93, 1, maka interval dengan batas
bawah 69, 9 dan batas atas 130, 3 disebut sebagai suatu interval kepercayaan 95% un-
tuk θ. Selanjutnya karena P2nX/θ < χ2
0,95(2n)
= 0.95, maka(2nX/χ2
0,95(2n),∞)
adalah batas bawah 95% untuk θ. Sedangkan interval(−∞, 2nX/χ2
0,05(2n))
adalah
batas atas 95% untuk θ. Nilai-nilai untuk χ20,05(2n) maupun χ2
0,975(2n) dapat dili-
hat pada tabel distribusi chi-square yang tesedia pada buku-buku teks standard, atau
dihitung dengan komputer.
Terhadap interval (69, 9; 130, 3) yang diberikan pada contoh di atas tidak dapat
diambil kesimpulan bahwa nilai θ yang sebenarnya terletak pada interval ini. Nilai θ
yang sebenarnya mungkin tidak terletak pada interval ini. Interpretasi yang paling
tepat adalah dengan frekuensi relatif. Misalkan m menyatakan banyaknya trial yang
dilakukan. Jika m → ∞, persentase dari interval(2nx/χ2
0,975(2n), 2nx/χ20,025(2n)
)
memuat nilai θ yang sebenarnya akan mendekati 95%. Selanjutnya, karena popu-
lasinya berdistribusi kontinu, maka interval terbuka dan tertutup keduanya meru-
pakan interval kepercayaan dua sisi 95% untuk θ.
Contoh 4.0.4. Misalkan X1, . . . , Xn merupakan sampel random dari N(µ, σ2), den-
gan −∞ < µ < ∞ tidak diketahui, sedangkan 0 < σ2 < ∞ diasumsikan diketahui.

50
Jika zα merupakan kuantil ke α ∈ (0, 1) dari distribusi N(0, 1), maka
1− α =Pzα/2 <
√n(X − µ)/σ < z1−α/2
=PX − z1−α/2σ/
√n < µ < X − zα/2σ/
√n
.
Jadi interval(x− z1−α/2σ/
√n, x− zα/2σ/
√n)
adalah interval kepercayaan dua sisi
100(1− α)% untuk µ, atau[x− z1−α/2σ/
√n, x− zα/2σ/
√n].
Pada kasus ini kita mengasumsikan σ2 diketahui agar batas-batas intervalnya
dapat dihitung. Jika σ2 tidak diketahui, maka ujung-ujung interval tidak dapat
dihitung. Parameter seperti ini disebut juga parameter pengganggu (nuisance pa-
rameter). Permasalahan yang dihadapi dalam mengkonstruksi interval kepercayaan
adalah kehadiran parameter pengganggu. Masalah ini bisa diatasi dengan melakukan
modofikasi seperti terangkum pada beberapa sub bab berikut.
Prinsip dasar dalam mengkonstruksikan interval kepercayaan untuk suatu param-
eter θ adalah bahwa kita harus dapat menentukan suatu kuantitas yang hanya bergan-
tung pada sampel dan θ, tetapi distribusi probabilitasnya tidak bergantung pada θ
dan parameter-parameter lain yang tidak diketahui. Seperti pada Contoh 4.0.3, kuan-
titas X/θ berdistribusi GAM(1/n, n) yang tidak bergantung pada θ, tetapi karena
kuantil dari GAM(1/n, n) tidak tersedia pada tabel, kita lakukan sedikit modifikasi
dengan mendefinisikan quantitas 2nX/θ yang diketahui berdistribusi χ2(2n) yang
tidak bergantung pada θ dan kuntil-kuantilnya tersedia pada tabel.
4.1 Metode kuantitas pivot (pivotal quantity)
Definisi 4.1.1. Misalkan ϕ : χ → R merupakan fungsi yang terdefinisi pada ru-
ang sampel χ ⊆ Rn dengan ϕ(X1, . . . , Xn; θ) merupakan fungsi hanya dari sampel

51
X1 . . . , Xn dan θ ∈ θ. Jika distribusi probabilitas dari ϕ(X1, . . . , Xn; θ) tidak bergan-
tung pada θ dan parameter lainnya yang tidak diketahui, maka ϕ(X1, . . . , Xn; θ) dise-
but quantitas pivot untuk θ.
Catatan:
Jika qα/2 dan q1−α/2 merupakan kuantil-kuantil ke α/2 dan (1 − α/2) dari quantitas
pivot ϕ(X1, . . . , Xn; θ), maka Pqα/2 < ϕ(X1, . . . , Xn; θ) < q1−α/2
= 1 − α. Ini be-
rartiθ ∈ θ : qα/2 < ϕ(X1, . . . , Xn; θ) < q1−α/2
merupakan interval kepercayaan dua
sisi 100× (1− α)% untuk θ. Untuk setiap titik (x1, . . . , xn) ∈ χ, didefinisikan fungsi
ϕ(x1,...,xn) : θ → R, dengan ϕ(x1,...,xn)(θ) := ϕ(x1, . . . , xn; θ). Jika ϕ(x1,...,xn) merupakan
fungsi monoton naik untuk setiap (x1, . . . , xn) ∈ χ, maka interval kepercayaan dua
sisi 100 × (1 − α)% untuk θ adalah(ϕ−1
(x1,...,xn)(qα/2), ϕ−1(x1,...,xn)(q1−α/2)
). Sebaliknya,
jika ϕ(x1,...,xn) merupakan fungsi monoton turun untuk setiap (x1, . . . , xn) ∈ χ, maka
interval kepercayaan dua sisi 100(1− α)% untuk θ adalah
(ϕ−1
(x1,...,xn)(q1−α/2), ϕ−1(x1,...,xn)(qα/2)
).
Definisi 4.1.2. Misalkan X merupakan populasi dengan fungsi densitas f(x; θ), θ ∈Θ ⊆ R. Jika terdapat suatu fungsi non negatif fo sedemikian hingga f(x; θ) = f0(x−θ), ∀θ ∈ Θ, maka θ disebut parameter lokasi. Jika f(x; θ) = 1
θf0(
xθ), ∀θ ∈ Θ, maka
θ disebut parameter skala. Untuk kasus dua parameter θ1 dan θ2, jika f(x; θ1, θ2) =
1θ2
f0(x−θ1
θ2), ∀θ1, θ2 maka θ1 dan θ2 disebut parameter lokasi-skala.
Teorema 4.1.3. Misalkan X1, . . . , Xn merupakan sampel random dari populasi den-
gan fungsi densitas fX(·; θ), θ ∈ θ. Andaikan MLE untuk θ, yaitu θ ada.
1. Jika θ merupakan parameter lokasi, maka (θ − θ) merupakan kuantitas pivot
untuk θ, θ ∈ Θ.

52
2. Jika θ merupakan parameter skala, maka θ/θ merupakan kuantitas pivot untuk
θ, θ ∈ Θ.
Contoh 4.1.4. Kembali ke Contoh 4.0.4, jika σ2 diasumsikan diketahui, maka X−µ
merupakan kuantitas pivot untuk µ, dimana (X − µ) ∼ N(0, σ2/n). Pada kasus ini
X merupakan statistik cukup dan tak bias untuk θ. Jadi X − µ dapat digunakan
untuk mengkonstruksi interval kepercayaan untuk µ. Selanjutnya, jika diasumsikan
σ2 tidak diketahui, maka σ2/σ2 adalah kuantitas pivot untuk σ2, dengan nσ2/σ2 =
(n−1)S2/σ2 ∼ χ2(n−1) (lihat Teorema 1.3.11). Dalam hal ini σ2 adalah MLE untuk
σ2 (lihat Contoh 2.2.4). Jadi σ2/σ2 bisa digunaka untuk mengkonstruksikan interval
kepercayaan dua sisi 100(1− α)% untuk σ2, yaitu
((n− 1)s2
χ21−α/2(n− 1)
,(n− 1)s2
χ2α/2(n− 1)
), s2 :=
n∑i=1
(xi − x)/(n− 1).
Teorema 4.1.5. Misalkan X1, . . . , Xn merupakan sampel random dari suatu popu-
lasi dengan parameter lokasi-skala θ1 dan θ2. Jika MLE θ1 dan θ2 ada, maka θ1−θ1
θ2
merupakan kuantitas pivot untuk θ1 dan θ2
θ2merupakan kuantitas pivot untuk θ2.
Contoh 4.1.6. Pada kasus Xi ∼ N(µ, σ2), −∞ < µ < ∞ dan 0 < σ2 < ∞, dengan
µ dan σ2 tidak diketahui. Dapat ditunjukkan, µ dan σ2 merupakan parameter lokasi-
skala, karena itu X−µσ2 merupakan kuantitas pivot untuk µ. Jadi dalam kasus dimana
σ2 tidak diketahui (σ2 sebagai parameter pengganggu), interval kepercayaan untuk µ
dapat diturunkan dari kuantitas pivot ini. Dengan sedikit modifikasi, yaitu
X − µ√σ2/(n− 1)
=(X − µ)/(σ/
√n)√
nσ2/σ2(n− 1)
=(X − µ)/(σ/
√n)√
S2/σ2=
N(0, 1)√χ2(n− 1)/(n− 1)
∼ t(n− 1).

53
Jadi interval kepercayaan dua sisi 100(1− α)% untuk µ adalah
(x− t1−α/2
s√n
, x + t1−α/2s√n
)
Catatan:
Misalkan (`(x1, . . . , xn), u(x1, . . . , xn)) merupakan interval epercayaan dua sisi 100×(1 − α)% untuk θ. Jika τ : θ → R merupakan fungsi monoton naik, maka interval
kepercayaan dua sisi 100(1− α)% untuk τ(θ) adalah
(τ(`(x1, . . . , xn)), τ(u(x1, . . . , xn))).
Sebaliknya, jika τ monoton turun, maka interval kepercayaan dua sisi 100(1 − α)%
untuk τ(θ) adalah (τ(u(x1, . . . , xn)), τ(`(x1, . . . , xn))).
Contoh 4.1.7. Kembali pada Contoh 4.0.3. Interval kepercayaan dua sisi 100(1−α)%
untuk PX > t = exp−t/θ, t > 0 adalah
(exp
−χ2
0,975(2n)
2nx
< exp−t/θ < exp
−χ2
0,025(2n)
2nx
).
Dari sampel random X1, . . . , Xn yang diambil dari suatu populasi dengan fungsi
distribusi kumulatif (cdf: cumulative distribution function) kontinu dengan parameter
θ ∈ Θ ⊆ R pasti dapat ditemukan sekurang-kurangnya satu kuantitas pivot. Misalkan
CDF dari Xi dinyatakan sebagai FXi(x; θ), maka FXi
(Xi; θ) ∼ UNIF (0, 1). Misalkan
Yi := − ln FXi(Xi; θ), maka Yi ∼ Exp(1), sehingga 2nY = −2
∑ni=1− ln FXi
(Xi; θ) ∼χ2(2n). Jadi P
θ ∈ Θ : χ2
α/2(2n) < −2∑n
i=1− ln FXi(Xi; θ) < χ2
1−α/2(2n)
= 1 − α,
sehingga interval kepercayaan dua sisi 100(1 − α)% untuk θ secara umum diberikan
oleh himpunan berikut
θ ∈ Θ : χ2α/2(2n) < −2
n∑i=1
− ln FXi(xi; θ) < χ2
1−α/2(2n)
. (4.1.1)

54
Jika (4.1.1) tidak dapat disederhanakan secara analitis, cara alternatif adalah dengan
penyelesaian secara numerik. Cara lain adalah dengan penyederhanaan lebih lanjut,
yaitu 1− FXi(Xi; θ) ∼ UNIF (0, 1), sehingga −2
∑ni=1 ln(1− FXi
(Xi; θ)) ∼ χ2(2n).
Contoh 4.1.8. Misalkan Xi ∼ PAR(1, κ), maka FXi(Xi; κ) = 1 − (1 + Xi)
−κ.
Dengan menerapkan cara yang terkhir, kita peroleh −2∑n
i=1 ln(1 − FXi(Xi; κ)) =
2κ∑n
i=1 ln(1 + Xi) ∼ χ2(2n), Jadi interval kepercayaan dua sisi 100(1 − α)% untuk
κ adalah (χ2
α/2(2n)
2∑n
i=1 ln(1 + Xi),
χ21−α/2(2n)
2∑n
i=1 ln(1 + Xi)
).
4.1.1 Membandingkan dua populasi normal
Misalkan seorang peneliti ingin menyelidiki dan membandingkan efektivitas dari dua
metode pembelajaran matematika yang ada. Suatu percobaan dilakukan dengan
menerapkan metode I terhadap klas A dan metode II terhadap klas B. Kedua klas
dianggap mempunyai kemampuan yang seimbang pada bidang matematika. Pada
akhir semester diselenggarakan tes pada kedua kelas secara serentak dengan soal-soal
yang sama, selanjutnya nilai-nilai test dicatat secara bebas satu sama lain. Jika nilai
test dianggap berdistribusi N(µ, σ2), −∞ < µ < ∞, 0 < σ2 < ∞, maka hasil penga-
matan dapat dianggap sebagai realisasi dari dua sampel random yang yang saling
bebas X1, . . . , XnAdari populasi N(µA, σ2
A) dan Y1, . . . , YnBdari populasi N(µB, σ2
B),
dimana nA dan nB masing-masing menyatakan banyaknya nilai yang dicatat pada
klas A dan klas B, µA dan µB masing-masing menyatakan mean dari populasi nilai
pada klas A dan klas B, sedangkan σ2A dan σ2
B masing-masing menyatakan variansi
dari populasi nilai pada klas A dan klas B.

55
4.1.1.1 Membandingkan σ2A dan σ2
B
Perbedaan efektivitas yang signifikan antara kedua metode pembelajaran dapat dili-
hat dari rasio . Jika interval kepercayaan dua sisi 100(1−α)% untuk σ2A/σ2
B memuat
1, maka kita boleh yakin dengan peluang 1 − α bahwa σ2A = σ2
B. Sebaliknya, jika
interval kepercayaan dua sisi 100(1 − α)% untuk σ2A/σ2
B tidak memuat 1, maka kita
yakin 100(1 − α)% bahwa σ2A 6= σ2
B. Selanjutnya, karena S2Aσ2
B/S2Bσ2
A merupakan
kuantitas pivot yang berdistribusi F (nA − 1, nB − 1) (lihat Contoh 1.3.17), maka
interval kepercayaan dua sisi 100(1− α)% untuk σ2A/σ2
B adalah(
s2B
s2A
Fα/2(nA − 1, nB − 1),s2
B
s2A
F1−α/2(nA − 1, nB − 1)
),
dimana
s2A :=
1
nA − 1
nA∑i=1
(xi − x)2 dan s2B :=
1
nB − 1
nB∑i=1
(yi − y)2.
4.1.1.2 Membandingkan µA dan µB
Perbedaan efektivitas antara metode I dan metode II juga dapat dilihat dari selisih
antara µA dan µB. Jika σ2A dan σ2
B diketahui, maka
(X − Y )− (µA − µB)√σ2
A
nA+
σ2B
nB
∼ N(0, 1)
merupakan kuantitas pivot untuk µA−µB. Jadi interval kepercayaan dua sisi 100(1−α)% untuk µA − µB adalah
x− y − z1−α/2
√σ2
A
nA
+σ2
B
nB
, x− y − zα/2
√σ2
A
nA
+σ2
B
nB
Dalam kasus σ2A dan σ2
B tidak diketahui, kita bisa mengasumsikan σ2A = σ2
B =: σ2
untuk menyederhanakan permasalahan. Estimator tak bias untuk σ2 adalah
S2p :=
(nA − 1)S2A + (nB − 1)S2
B
nA + nB − 2.

56
Selanjutnya, karena
(nA + nB − 2)S2
p
σ2= (nA − 1)
S2A
σ2+ (nB − 1)
S2B
σ2∼ χ2(nA + nB − 2),
maka
(X − Y )− (µA − µB)√S2
p
(1
nA+ 1
nB
) =
(X−Y )−(µA−µB)√σ2
(1
nA+ 1
nB
)
√S2
p
σ2
∼ t(nA + nB − 2).
Jadi interval kepercayaan dua sisi 100(1− α)% untuk µA − µB adalah
((x− y)− t1−α/2(nA + nB − 2)
√S2
p
(1
nA
+1
nB
),
(x− y)− tα/2(nA + nB − 2)
√S2
p
(1
nA
+1
nB
) ).
4.1.1.3 Sampel berpasangan
Untuk dapat menarik kesimpulan bahwa suatu obat baru dapat menurunkan suhu
badan, n pasien diukur suhu badannya 15 menit sebelum dan 15 menit sesudah
minum obat tersebut. Misalkan suhu badan pasien ke i sebelum minum obat adalah
Xi dan sesudah minum obat adalah Yi, i = 1, . . . , n. Misalkan Di := Xi − Yi ∼N(µ1 − µ2, σ
21 + σ2
2 − 2σ12), dimana µ1 := E(Xi), µ2 := E(Yi), σ21 := V ar(Xi),
σ22 := V ar(Yi) dan σ12 := Cov(Xi, Yi), maka
(n− 1)S2
D
σ21 + σ2
2 − 2σ12
∼ χ2(n− 1),
dimana S2D :=
∑ni=1(Di − D)/(n− 1), E(S2
D) = σ21 + σ2
2 − 2σ12, D :=∑n
i=1 Di/n. Ini
berakibat
D − (µ1 − µ2)√S2
D
n
∼ t(n− 1).

57
Jadi interval kepercayaan dua sisi 100(1− α)% untuk µ1 − µ2 adalah(
d− t1−α/2(n− 1)
√S2
D
n, d− tα/2(n− 1)
√S2
D
n
).
4.2 Metode umum
Pada dasarnya interval kepercayaan untuk parameter θ ∈ Θ selalu dapat dikonstruk-
sikan meskipun kuantitas pivot untuk θ tidak tersedia asalkan ada suatu statistik
yang distribusinya bergantung hanya pada θ. Secara umum misalkan X1, . . . , Xn
mempunyai fungsi densitas bersama fX1,...,Xn(·; θ) dan misalkan S : w(X1, . . . , Xn)
merupakan statistik dengan fungsi densitas fS(·; θ) dan fungsi distribusi kumulatif
FS(·; θ), dengan FS(s; θ) =∫ s
−∞ fS(t; θ) dt. Selanjutnya misalkan h1, h2 : θ → R
merupakan fungsi-fungsi sedemikian hingga
P h1(θ) < S < h2(θ) = 1− α, α ∈ (0, 1).
Jika s merupakan suatu nilai pengamatan dari S, maka θ ∈ Θ : h1(θ) < s < h2(θ)merupakan daerah kepercayaan 100(1−α)% untuk θ. Kita sebut himpunan ini daerah
kepercayaan karena belum tentu merupakan interval pada R.
4.2.1 Kasus h1 dan h2 monoton naik
Jika h1 dan h2 merupakan fungsi monoton naik dari θ, maka berlaku
θ ∈ Θ : h1(θ) < s < h2(θ) =θ ∈ Θ : θ < h−1
1 (s) ∩
θ ∈ Θ : h−12 (s) < θ
Jika θU dan θL merupakan penyelesaian dari persamaan h1(θU) = s dan h2(θL) =
s, maka θ ∈ Θ : h1(θ) < s < h2(θ) = θ ∈ Θ : θL < θ < θU. Jadi interval keper-
cayaan dua sisi 100(1− α)% untuk θ adalah (θL, θU). Untuk menentukan h1 dan h2

58
kita mulai dari persamaan P h1(θ) < S < h2(θ) = 1 − α. Salah satu kemungkinan
yang dipenuhi oleh h1 dan h2 adalah
FS(h2(θ); θ) = 1− α/2 dan FS(h1(θ); θ) = α/2, α ∈ (0, 1).
Contoh 4.2.1. Misalkan X1, . . . , Xn merupakan sampel random dari populasi dengan
fungsi densitas
f(x; θ) =
(1/θ2) exp−(x− θ)/θ2 ; x ≥ θ
0 ; x < θ
Misalkan kita akan mengkonstruksikan interval kepercayaan dua sisi 90% untuk θ.
Ambil S = X1:n := minX1, . . . , Xn, maka untuk x ≥ θ,
P S ≤ x =1− P minX1, . . . , Xn > x
=1− P Xi > x, ∀i = 1, . . . , n
=1− Πni=1P Xi > x
=1− Πni=1 (1− P Xi ≤ x)
=1− Πni=1
(1−
∫ x
θ
(1/θ2) exp−(t− θ)/θ2 dt
)
Dengan substitusi u = −(t − θ)/θ2, diperoleh P Xi ≤ x = 1 − exp−(x − θ)/θ2.Jadi
FS(x; θ) =
1− exp−n(x− θ)/θ2 ; x ≥ θ
0 ; x < θ.
Fungsi-fungsi h1 dan h2 dipilih dengan menyelesaiakn persamaan
FS(h1(θ); θ) = 0, 05 ⇔ 1− exp−n(h1(θ)− θ)/θ2 = 0, 05
FS(h2(θ); θ) = 0, 95 ⇔ 1− exp−n(h2(θ)− θ)/θ2 = 0, 95,

59
yang menghasilkan penyelesaian
h1(θ) = θ − ln(0, 95)θ2/n ≈ θ + 0, 0513θ2/n
h2(θ) = θ − ln(0, 05)θ2/n ≈ θ + 2, 996θ2/n.
Dapat disimpulkan bahwa h1 dan h2 merupakan fungsi monoton naik. Misalkan dari
suatu pengamatan diperoleh s = 2, 50, maka dari persamaan h1(θU) = 2, 50 dan
h2(θL) = 2, 50, diperoleh θU = 2, 469 dan θL = 1, 667. Jadi interval kepercayaan dua
sisi 90% untuk θ adalah (1, 667; 2, 469).
Catatan:
Meskipun secara matematik S tidak disyaratkan merupakan statistik cukup ataupun
MLE untuk θ, tetapi dianjurkan S yang dipilih sebaiknya merupakan statistik cukup
atau MLE untuk θ.
4.2.2 Kasus h1 dan h2 monoton turun
Jika h1 an h2 merupakan fungsi-fungsi yang monoton turun terhadap θ ∈ Θ, maka
untuk setiap hasil pengamatan s berlaku
θ ∈ Θ : h1(θ) < s < h2(θ) =θ ∈ Θ : h−1
1 (s) < θ ∩
θ ∈ Θ : θ < h−12 (s)
=θ ∈ Θ : h−1
1 (s) < θ < h−12 (s)
.
Jadi jika h1 dan h2 memenuhi FS(h2(θ); θ) = 1− α/2 dan FS(h1(θ); θ) = α/2, maka
interval(h−1
1 (s), h−12 (s)
)merupakan interval kepercayaan dua sisi 100(1−α)% untuk
θ. Misalkan θL dan θU merupakan penyelesaian dari persamaan h1(θL) = s dan
h2(θU) = s, maka interval (θL, θU) merupakan interval kepercayaan dua sisi 100(1 −α)% untuk θ.

60
4.3 Soal-soal
1. Misalkan X1, . . . , Xn merupakan sampel random dari populasi N(µ, σ2).
(a) Misalkan σ2 = 9. Tentukan interval kepercayaan dua sisi 90% untuk µ,
jika x = 19, 3 dan n = 16.
(b) Misalkan σ2 tidak diketahui. Tentukan interval kepercayaan dua sisi 90%
untuk µ, jika x = 19, 3, s2 = 10, 24 dan n = 16.
2. Misalkan X1, . . . , Xn merupakan sampel random dari populasi WEI(θ, 2)
(a) Tunjukan bahwa Q := 2∑n
i=1 X2i /θ2 ∼ χ2(2n).
(b) Gunakan Q untuk mengkonstruksikan interval kepercayaan dua sisi 100γ%
untuk θ.
(c) Konstruksikan interval kepercayaan dua sisi 100γ% untuk PX > t.
3. Misalkan X1, . . . , Xn1 sampel random dari Exp(θ1) dan Y1, . . . , Yn2 sampel ran-
dom dari Exp(θ2) dimana kedua sampel saling bebas.
(a) Tunjukkan (θ2/θ1)(X/Y ) ∼ F (2n1, 2n2).
(b) Konstruksikan interval kepercayaan 100γ% untuk θ2/θ1.
4. Misalkan X1, . . . , Xn merupakan sampel random dari populasi dengan fungsi
distribusi kumulatif
FXi(x; θ) =
1− exp−θ(x− θ) ; x ≥ θ
0 ; x < θ,
dengan θ > 0.
(a) Tentukan CDF FS(·; θ) untuk S := minX1, . . . , Xn.

61
(b) Tentukan fungsi h(θ) sedemikian hingga G(h(θ); θ) = 1−α, dan tunjukkan
bahwa h bukan fungsi monoton.
(c) Tentukan penyelesaian dari persamaan h(θ) = s.
5. Misalkan f(x; p) := pfX1(x) + (1 − p)fX2(x), dimana X1 ∼ N(1, 1) dan X2 ∼N(0, 1). Dengan berdasarkan pada sampel berukuran n = 1 diambil dari
f(x; p), konstruksikan interval kepercayaan dua sisi 100γ% untuk p. (Petun-
juk: gunakan transformasi integeral probabilitas!)
6. Diberikan dua sampel random yang saling bebas X1, . . . , Xn1 dari N(µ1, σ21) dan
Y1, . . . , Yn2 dari N(µ2, σ22). Jika µ1 dan µ2 diasumsikan diketahui, konstruksikan
interval kepercayaan dua sisi 100(1 − α)% untuk σ22/σ
21 dengan menggunakan
statistik cukup.

Chapter 5
Uji hipotesis
Pengertian dan prosudur estimasi titik dan estimasi interval untuk parametr-parameter
suatu populasi telah dibahas pada Chapter 2 dan Chapter 4. Pada chapter ini kita
akan membahas metode inferensi yang lain yaitu uji hipotesis. Berbeda dengan esti-
masi titik atau interval, pada uji hipotesis pendugaan awal terhadap distribusi dari
populasi diberikan, selanjutnya berdasarkan sampel ditarik kesimpulan apakah pen-
dugaan awal tersebut ditolak atau diterima. Pada chapter ini pembicaraan akan
dibatasi pada kasus parametrik, yaitu fungsi densitas dari populasinya diidentifikasi
oleh parameter-parameter yang tidak diketahui. Ruang sampel tetap kita nyatakan
dengan χ ⊆ Rn.
5.1 Pendahuluan
Definisi 5.1.1. Misalkan X ∼ fX(·; θ), θ ∈ Θ ⊆ R. Hipotesis statistik adalah
pernyataan tentang distribusi dari X. Dalam kasus parametrik ini hipotesis statistik
adalah pernyataan tentang θ.
62

63
Dalam uji hipotesis ruang parameter Θ dibagi menjadi dua himpunan bagian
yang saling asing, yaitu Θ0 ⊂ Θ dan Θ1 := Θ − Θ0. Bersesuaian dengan Θ0 dan
Θ1, hipotesis statistik juga terdiri dari dua pernyataan yang saling berlawanan, yaitu
hipotesis nol (H0) yang menyatakan bahwa θ ∈ Θ0 dan hipotesis alternatif (H1) yang
menyatakan bahwa θ ∈ Θ1. Biasanya kedua hipotesis ini dituliskan sebagai H0 : θ ∈Θ0 vs H1 : θ ∈ Θ1. Jika diberikan sampel yang diambil dari populasi fX(·; θ), θ ∈ Θ,
prosudur uji hipotesis harus mampu menetukan apakah H0 ditolak atau diterima.
Karena itu kita membagi ruang sampel χ menjadi dua himpunan bagian yang saling
asing, yaitu C := (x1, . . . , xn) ∈ χ : H0 ditolak dan χ − C. Selanjutnya C disebut
daerah penolakan (daerah kritis), sedangkan χ− C disebut daerah penerimaan.
Definisi 5.1.2. Suatu tes untuk hipotesis H0 : θ ∈ Θ0 vs H1 : θ ∈ Θ1 adalah suatu
fungsi ψ : χ → 0, 1, sedemikian hingga ∀(x1, . . . , xn) ∈ χ,
ψ(x1, . . . , xn) =
1 ; jika (x1, . . . , xn) ∈ C
0 ; jika (x1, . . . , xn) 6∈ C.
Jadi ψ merupakan fungsi penolakan dari H0, dimana H0 akan ditolak jika ψ = 1 dan
tidak ditolak jika ψ = 0. Selanjutnya berlaku E(ψ) = P(menolak H0)
Pada setiap eksperimen yang melibatkan pengamatan pasti ada kesalahan yang
berimbas pada proses pengambilan keputusan terhadap H0. Ada dua tipe kesalahan
yang dapat dilakukan dalam penolakan terhadap H0, yaitu
1. Kesalahan tipe I, yaitu kesalahan yang dilakukan karena menolak H0 padahal
H0 benar.
2. Kesalahan tipe II, yaitu kesalahan yang dilakukan karena tidak menolak H0
padahal H0 salah.

64
Probabilitas kedua kesalahan dinyatakan sebagai
P(kesalahan tipe I) = P(C | θ ∈ Θ0) = E(ψ) di bawah H0,
P(kesalahan tipe II) = 1− P(C | θ ∈ Θ1) = 1− E(ψ) di bawah H1.
Definisi 5.1.3. Fungsi power dari tes ψ adalah suatu fungsi Gψ : Θ → [0, 1] yang
diberikan oleh Gψ(θ) := P(C | θ ∈ Θ) = E(ψ) untuk θ ∈ Θ. Selanjutnya, ukuran
(size) dari ψ adalah supθ∈Θ0Gψ(θ). Untuk suatu bilangan α ∈ (0, 1), tes ψ dikatakan
tes dengan signifikansi α jika Gψ(θ) ≤ α, ∀θ ∈ Θ0. Karena untuk setiap θ ∈ Θ0,
Gψ(θ) ≤ supθ∈Θ0Gψ(θ), maka setiap tes adalah tes dengan tingkat signifikansi yang
diberikan oleh ukurannya.
Definisi 5.1.4. Suatu hipotesis yang berbentuk H0 : θ = θ0 vs H1 : θ = θ1 untuk
suatu θ0, θ1 ∈ Θ disebut hipotesis sederhana. Sedangkan hipotesis yang menyatakan
bahwa θ berada pada suatu interval disebut hipotesis komposit. Jadi hipotesis yang
berbentuk H0 : θ < θ1 vs H1 : θ ≥ θ1 untuk suatu θ1 ∈ Θ adalah hipotesis komposit.
Catatan:
Untuk hipotesis sederhana H0 : θ = θ1 vs H1 : θ = θ2 untuk θ1 6= θ2, berlaku
supθ∈Θ0Gψ(θ) = maxθ∈θ0 Gψ(θ) = Gψ(θ0). Maka ψ adalah tes dengan ukuran yang
diberikan oleh Gψ(θ0). Jadi dalam kasus ini Gψ(θ0) juga dapat diambil sebagai tingkat
signifikansinya.
5.1.1 Menentukan daerah kritik
Dari penjelasan di atas secara logika tes yang baik adalah tes yang meminimumkan
P(kesalahan tipe I) dan P(kesalahan tipe II) secara simultan. Akan tetapi karena
kedua kesalahan ini tidak dapat diminimumkan secara bersamaan (lihat Lehmann

65
dan Romano, 2005, hal. 57), prosudur terbaik yang dapat dilakukan adalah kita
memilih terlebih dahulu bilangan kecil α, biasanya dipilih α = 0, 01 atau α = 0, 05
sebagai tingkat signifikansi sedemikian hingga P(kesalahan tipe I) ≤ α dan pada
sisi lain P(kesalahan tipe II) dibuat minimum. Karena P(kesalahan tipe II) = 1 −Gψ(θ), ∀θ ∈ Θ1, jadi daerah kritik yang dipilih adalah daerah kritik yang memenuhi
P(kesalahan tipe I) ≤ α sedemikian hingga power dibawah H1 maksimum, yaitu
Gψ(θ), ∀θ ∈ Θ1 maksimum.
Contoh 5.1.5. Ada atau tidaknya kandungan minyak bumi pada suatu daerah dapat
diperediksi dengan melihat kecepatan reaksi dari tanah dipermukaan daerah tersebut
dengan suatu zat A yang diasumsikan berdistribusi N(µ, 16). Dari pengalaman dike-
tahui bahwa µ = 10 jika tidak ada kandungan minyak dan µ = 11 jika sebaliknya.
Untuk dapat menarik kesimpulan ya atau tidak sebuah eksperimen dilakukan dengan
mengambil sampel random berukuran n = 25, yaitu X1, . . . , X25, dimana Xi adalah
kecepatan reaksi diukur dalam ml/detik dan menguji hipotesis H0 : µ = 10 =: µ0 vs
H1 : µ = 11 =: µ1. Karena X merupakan statistik cukup dan MLE untuk µ, adalah
masuk akal untuk menduga sifat-sifat dari µ dengan sifat-sifat dari X. Selanjutnya
karena µ1 > µ0, nilai-nilai X yang besar akan menunjukan bahwa sampel mendukung
H1, karena itu masuk akal jika daerah kritik didefinisikan sebagai
C := (x1, . . . , xn) ∈ χ : x ≥ k =ω ∈ Ω : X(ω) ≥ k
,
dimana k adalah konstanta yang ditentukan kemudian. Kita definisikan tes ψ : χ →0, 1, sedemikian hingga ∀(x1, . . . , xn) ∈ χ,
ψ(x1, . . . , xn) =
1 ; jika x ≥ k
0 ; jika x < k.

66
Karena hipotesisnya merupakan hipotesis sederhana, tes atau daerah kritik berukuran
α = 0, 05 diturunkan dari persamaan
Gψ(µ0) = 0, 05
⇔ PX ≥ k | µ = µ0 = 10
= 0, 05
⇔ P
X − µ0
4/5≥ k − µ0
4/5
= 0, 05
⇔ P
Z ≥ k − µ0
4/5
= 0, 05,
ini berakibat k−µ0
4/5= z1−α, atau k = µ0 + z1−α4/5 = 11, 316. Jadi daerah kritik
berukuran 0, 05 adalah
C = (x1, . . . , xn) ∈ χ : x ≥ 11, 316
=
(x1, . . . , xn) ∈ χ :
x− 10
4/5≥ 1, 645
.
Ini berarti tes berukuran 0, 05 akan menolak H0 jika data yang diperoleh menunjukan
x ≥ 11, 316 atau x−104/5
≥ 1, 645. Sebaliknya jika data memberikan nilai sedemikian
hingga x < 11, 316 atau x−104/5
< 1, 645, maka H0 tidak ditolak. Selanjutnya kita
selidiki power dari ψ dibawah H1 yang diberikan oleh
Gψ(µ1) =P
X − µ0
4/5≥ 1, 645 | µ = µ1
=P
X − µ1
4/5≥ 1, 645 +
µ0 − µ1
4/5
=P
X − µ1
4/5≥ 1, 645− 5/4
= 0, 346.
Mari kita bandingkan tes diatas dengan tes yang didefinisikan sebagai berikut: γ :
χ → 0, 1, sedemikian hingga ∀(x1, . . . , xn) ∈ χ,
γ(x1, . . . , xn) =
1 ; jika 10 ≤ x ≤ 10.1006
0 ; jika x < 10 atau 10.1006 < x

67
untuk menguji hipotesis sederhana H0 : µ = 10 =: µ0 vs H1 : µ = 11 =: µ1. Tes ini
juga merupakan tes dengan ukuran 0, 05, karena
Gγ(µ0) =P10 ≤ X ≤ 10, 1006 | µ = 10
=P
0 ≤ X − 10
4/5≤ 0, 1006
4/5
= 0, 05.
Akan tetapi power dari γ di bawah H1 adalah
Gγ(µ1) =P10 ≤ X ≤ 10, 1006 | µ = 11
=PX ≤ 10, 1006 | µ = 11
− PX ≤ 10 | µ = 11
=P
X − µ1
4/5≤ 0, 12575− 5/4
− P
X − µ1
4/5≤ −5/4
=0.130− 0.106 = 0, 024.
Ini berarti power dari ψ dibawah H1 jauh lebih besar dibandingkan dengan power dari
γ dibawah H1. Dengan demikian diantara kedua tes tersebut, ψ lebih powerful dari γ.
Contoh 5.1.6. Misalkan X1, . . . , Xn merupakan sampel random dari populasi N(µ, σ2),
σ2 diasumsikan tidak diketahui.
1. Tes berukuran α untuk hipotesis H0 : µ ≤ µ0 vs H1 : µ > µ0 adalah menolak H0
jika√
n(x−µ0)/s ≥ t1−α(n−1). Sebaliknya H0 tidak ditolak jika√
n(x−µ0)/s <
t1−α(n− 1). Selanjutnya fungsi power di bawah H1 adalah
Gψ(µ) = P√
n(X − µ0)
S≥ t1−α(n− 1) | µ > µ0
= P√
n(X − µ + µ− µ0)
S≥ t1−α(n− 1)
= P
√
n(X − µ)/σ +√
n(µ− µ0)/σ√(n−1)S2
σ2 /(n− 1)≥ t1−α(n− 1)

68
= P
Z + ∆√
V/ν≥ t1−α(n− 1)
,
dimana ∆ :=√
n(µ − µ0)/σ > 0, V := (n − 1)S2/σ2, ν := n − 1. Dalam hal
ini Z + ∆/√
V/ν berdistribusi t students non central dengan derajat bebas ν
dan parameter non central ∆. Jika ∆ = 0, maka power dibawah alternatif akan
mencapai ukuran dari tes tersebut, yaitu α.
2. Tes berukuran α untuk hipotesis H0 : µ ≥ µ0 vs H1 : µ < µ0 adalah menolak H0
jika√
n(x−µ0)/s ≤ tα(n−1). Sebaliknya H0 tidak ditolak jika√
n(x−µ0)/s >
tα(n− 1).
3. Tes berukuran α untuk hipotesis H0 : µ = µ0 vs H1 : µ 6= µ0 adalah menolak
H0 jika√
n(x − µ0)/s ≥ t1−α/2(n − 1) atau√
n(x − µ0)/s ≤ −t1−α/2(n − 1).
Sebaliknya H0 tidak ditolak jika −t1−α/2 <√
n(x− µ0)/s < t1−α/2(n− 1).
5.1.2 Nilai p (p-value)
Untuk sembarang α ∈ (0, 1), misalkan Cα merupakan daerah kritik dari tes berukuran
α untuk hipotesis H0 : θ ∈ Θ0 vs H1 : θ ∈ Θ1 berdasarkan sampel random X1, . . . , Xn.
Secara umum Cα akan mempunyai bentuk sebagai berikut:
Cα := (x1, . . . , xn) ∈ χ : q(x1, . . . , xn) ≥ q1−α ,
dimana q1−α adalah quantil ke 1−α untuk distribusi dari statistik q(X1, . . . , Xn). Un-
tuk sembarang α1 dan α2, jika α1 < α2, maka q1−α1 > q1−α2 . Fakta ini mengakibatkan
Cα1 ⊂ Cα2 . Ini berarti, jika kita diberikan dua konstanta α1 dan α2, jika H0 ditolak
pada tingkat signifikansi α1, maka H0 pasti ditolak juga pada tingkat signifikansi α2.
Permasalahan sebaliknya adalah jika diberikan suatu data (x1, . . . , xn) ∈ χ, apakah

69
H0 ditolak atau tidak pada tingkat signifikansi α1 dan α2? Permasalahan ini mem-
perkenalkan kita pada konsep nilai p atau p−value.
Definisi 5.1.7. Diberikan data (x1, . . . , xn) ∈ χ, nilai p dari suatu tes adalah nilai α
terkecil sedemikian hingga H0 ditolak. Dengan kata lain
p-value := infα∈(0,1)
Cα, sedemikian hingga (x1, . . . , xn) ∈ Cα.
Jika Cα = (x1, . . . , xn) ∈ χ : q(x1, . . . , xn) ≥ q1−α, maka berlaku
p-value := infα∈(0,1)
q1−α, sedemikian hingga q(x1, . . . , xn) ≥ q1−α
=P q(X1, . . . , Xn) ≥ q(x1, . . . , xn) .
Sebaliknya, jika Cα = (x1, . . . , xn) ∈ χ : q(x1, . . . , xn) ≤ qα, maka
p-value := infα∈(0,1)
qα, sedemikian hingga q(x1, . . . , xn) ≤ qα
=P q(X1, . . . , Xn) ≤ q(x1, . . . , xn) .
Contoh 5.1.8. Pada Contoh 5.1.6 bagian 1, misalkan hipotesisnya adalah H0 : µ ≤80 vs H1 : µ > 80, jika dari eksperimen diperoleh data dengan n = 40, x = 85 dan
s2 = 100, maka
p-value =P
√40(X − 80)
S≥√
40(85− 80)
10
=P T (39) ≥ 3, 162 = 0, 0015,
dimana T (39) menyatakan variabel berdistribusi t dengan derajat bebas 39. Jadi
keputusan yang diambil berdasarkan data tersebut akan menolak H0 untuk setiap
α ≥ 0, 0015.

70
5.2 Metode memilih tes terbaik
Dari Contoh 5.1.5, tes berukuran α untuk suatu hipotesis yang sama adalah tidak
tunggal. Dua atau lebih tes dapat mempunyai ukuran yang sama, tetapi power di
bawah alternatif H1 belum tentu sama. Pada sub bab ini kita akan merumuskan
metode memilih tes yang terbaik (tes dengan power di bawah H1 terbesar) diantara
semua tes berukuran α.
Definisi 5.2.1. Misalkan ψ1 dan ψ2 merupakan dua tes dengan ukuran α untuk
hipotesis H0 : θ ∈ Θ0 vs H1 : θ ∈ Θ1. Tes ψ1 dikatakan secara seragam lebih baik dari
ψ2, jika Gψ1(θ) ≥ Gψ2(θ), ∀θ ∈ Θ1. Misalkan Cα merupakan himpunana semua tes
berukuran α untuk hipotesis H0 : θ ∈ Θ0 vs H1 : θ ∈ Θ1. Suatu tes ψ ∈ Cα dikatakan
terbaik secara seragam (Uniformly Most Powerful Test) atau tes UMP berukuran α,
jika Gψ(θ) ≥ Gψ∗(θ), ∀θ ∈ Θ1 dan ∀ψ∗ ∈ Cα.
5.2.1 Tes UMP untuk hipotesis sederhana
Misalkan X1, . . . , Xn merupakan n variabel random dengan fungsi densitas bersama
f(x1, . . . , xn; θ), θ ∈ Θ ⊆ R. Suatu tes ϕ : χ → 0, 1 untuk hipotesis H0 : θ = θ0
vs H1 : θ = θ1, dengan θ0, θ1 ∈ Θ, θ0 6= θ1, disebut tes Neyman-Pearson (tes N-P)
berukuran α, jika
ϕ(x1, . . . , xn) =
1 ; jika f(x1,...,xn;θ0)f(x1,...,xn;θ1)
≤ k
0 ; jika f(x1,...,xn;θ0)f(x1,...,xn;θ1)
> k,
untuk setiap titk (x1, . . . , xn) ∈ χ, dimana k ∈ [0,∞) merupakan sembarang kon-
stanta yang akan ditentukan dari persamaan Gϕ(θ0) = α. Pada definisi ini diasum-
sikan f(x1, . . . , xn; θ1) > 0.

71
Teorema 5.2.2. Tes di atas adalah tes UMP berukuran α.
Proof. Misalkan ψ merupakan sembarang tes berukuran α untuk hipotesis sederhana
H0 : θ = θ0 vs H1 : θ = θ1, yaitu Gψ(θ0) = α. Misalkan
M≥ : (x1, . . . , xn) ∈ χ : ϕ(x1, . . . , xn) ≥ ψ(x1, . . . , xn)
M< : (x1, . . . , xn) ∈ χ : ϕ(x1, . . . , xn) < ψ(x1, . . . , xn) .
Jika (x1, . . . , xn) ∈ M≥, maka ϕ(x1, . . . , xn) > 0. Ini berakibat f(x1, . . . , xn; θ0) ≤kf(x1, . . . , xn; θ1). Sebaliknya, jika (x1, . . . , xn) ∈ M<, maka ϕ(x1, . . . , xn) < 1. Ini
berakibat f(x1, . . . , xn; θ0) > kf(x1, . . . , xn; θ1). Maka
Gϕ(θ1)−Gψ(θ1) = Eθ1 (ϕ− ψ)
=
∫
χ
(ϕ(x1, . . . , xn)− ψ(x1, . . . , xn))f(x1, . . . , xn; θ1)dx1, . . . , dxn
=
∫
M≥(ϕ(x1, . . . , xn)− ψ(x1, . . . , xn))f(x1, . . . , xn; θ1)dx1, . . . , dxn
+
∫
M<
(ϕ(x1, . . . , xn)− ψ(x1, . . . , xn))f(x1, . . . , xn; θ1)dx1, . . . , dxn
≥∫
M≥(ϕ(x1, . . . , xn)− ψ(x1, . . . , xn))
1
kf(x1, . . . , xn; θ0)dx1, . . . , dxn
+
∫
M<
(ϕ(x1, . . . , xn)− ψ(x1, . . . , xn))1
kf(x1, . . . , xn; θ0)dx1, . . . , dxn
=
∫
χ
(ϕ(x1, . . . , xn)− ψ(x1, . . . , xn))1
kf(x1, . . . , xn; θ0)dx1, . . . , dxn
=1
k(Gϕ(θ0)−Gψ(θ0)) =
1
k(α− α) = 0.
Jadi Gϕ(θ1) ≥ Gψ(θ1). Disini Eθ1 menyatakan ekspektasi dibawah H1.
Contoh 5.2.3. Misalkan X1, . . . , Xn merupakan sampel random dari populasi bedis-
tribusi Exp(θ), θ > 0. Kita akan merumuskan tes N-P berukuran α untuk hipotesis

72
H0 : θ = θ0 vs H1 : θ = θ1, dimana diasumsikan θ1 > θ0. Karena
f(x1, . . . , xn : θ0)
f(x1, . . . , xn; θ1)≤ k ⇔
(θ1
θ0
)n
exp
(1/θ1 − 1/θ0)
n∑i=1
xi
≤ k
⇔n∑
i=1
xi ≥ k1, dimana k1 :=ln k − n ln(θ1/θ0)
1/θ1 − 1/θ0
.
Pada kasus ini (1/θ1 − 1/θ0) < 0 sehingga tanda ”≤” berubah menjadi ”≥”. Maka
daerah penolakan berukuran α diturunkan dari persamaan:
P
n∑
i=1
Xi ≥ k1 | θ = θ0
= α ⇔ P
2∑n
i=1 Xi
θ0
≥ 2k1
θ0
= α.
Selanjutnya karena 2∑n
i=1 Xi/θ0 berdistribusi χ2(2n), maka 2k1/θ0 = χ21−α(2n). Jadi
tes N-P berukuran α akan menolak H0 jika 2∑n
i=1 xi/θ0 ≥ χ21−α(2n) atau
∑ni=1 xi ≥
θ0χ21−α(2n)/2, untuk θ1 > θ0. Jika diasumsikan θ2 > θ0, maka dapat ditunjukan
bahwa tes N-P berukuran α untuk hipotesis H0 : θ = θ0 vs H1 : θ = θ2 akan menolak
H0 jika 2∑n
i=1 xi/θ0 ≥ χ21−α(2n) atau
∑ni=1 xi ≥ θ0χ
21−α(2n)/2. Kedua tes tersebut
adalah sama asalkan θ1 dan θ2 diasumsikan lebih besar dari θ0.
Contoh 5.2.4. Misalkan X1, . . . , Xn merupakan sampel random dari populasi bedis-
tribusi N(0, σ2), 0 < σ2 < ∞. Kita ingin merumuskan tes N-P berukuran α untuk
menguji hipotesis H0 : σ2 = σ20 vs H1 : σ2 = σ2
1, dimana diasumsikan σ21 > σ2
0.
Karena
f(x1, . . . , xn; σ20)
f(x1, . . . , xn; σ21)≤ k ⇔
(σ2
1
σ20
)2
exp
n∑
i=1
x2i
(1/2σ2
1 − 1/2σ20
)≤ k
⇔n∑
i=1
x2i ≥ k1, dimana k1 :=
ln k − n ln(σ21/σ
20)
1/2σ21 − 1/2σ2
0
.
Konstanta k1 ditentukan dari persamaan
P
n∑
i=1
X2i ≥ k1 | σ2 = σ2
0
= α ⇔ P
n∑
i=1
(Xi
σ0
)2
≥ k1
σ20
= α.

73
Karena∑n
i=1
(Xi
σ0
)2
berdistribusi χ2(n), maka tes N-P berukuran α akan menolak H0
jika∑n
i=1
(xi
σ0
)2
≥ χ21−α(n) atau
∑ni=1 x2
i ≥ σ20χ
21−α(2n).
Contoh 5.2.5. (Kasus diskrit)
Misalkan X1, . . . , Xn merupakan sampel random dari populasi bedistribusi POIS(λ),
λ > 0. Andaikan kita ingin merumuskan tes N-P berukuran α untuk menguji hipotesis
H0 : λ = λ0 vs H1 : λ = λ1, dimana diasumsikan λ1 > λ0. Karena
f(x1, . . . , xn; σ20)
f(x1, . . . , xn; σ21)≤ k ⇔ exp n(λ1 − λ0) (λ0/λ1)
∑ni=1 xi ≤ k ⇔
n∑i=1
xi ≥ k1,
dimana k1 := k expn(λ0 − λ1)/ ln(λ0/λ1). Perubahan tanda ”≤” menjadi tanda
”≥” terjadi karena asumsi λ1 > λ0, sehingga ln(λ0/λ1) < 0. Misalkan S :=∑n
i=1 Xi,
maka dibawah H0, S berdistribusi POIS(nλ0). Jika P S ≥ i | λ = λ0 = αi, dan
misalkan αi ≤ α ≤ αi+1, maka tes yang menolak H0, jika∑n
i=1 xi ≥ i adalah tes N-P
berukuran αi.
Catatan :
Pada kasus diskrit, tes N-P berukuran α mungkin tidak bisa dicapai secara eksak.
Tetapi, diberikan α, kita bisa memilih k sedemikian hingga menghasilkan tes dengan
ukuran sebesar-besarnya α.
5.2.2 Tes UMP untuk hipotesis komposit
Kita akan mengkonstruksikan tes UMP berukuran α untuk hipotesis H0 : θ = θ0 vs
H1 : θ < θ1. Metode yang ditempuh adalah dengan pertama-tama mendefinisikan
tes N-P berukuran α untuk hipotesis sederhana H0 : θ = θ0 vs H1 : θ = θ1 untuk
sembarang θ1 dengan θ1 < θ0. Jika dapat ditunjukkan bahwa tes ini tidak bergantung

74
pada θ1, maka tes ini adalah tes UMP berukuran α untuk hipotesis komposit H0 :
θ = θ0 vs H1 : θ < θ1.
Contoh 5.2.6. Kita perhatikan kembali Contoh 5.2.3. Misalkan ψ : χ → 0, 1merupakan tes untuk hipotesis H0 : θ = θ0 vs H1 : θ = θ1 untuk sembarang θ1 dengan
θ1 > θ0, dimana ∀(x1, . . . , xn) ∈ χ,
ψ(x1, . . . , xn) =
1; jika f(x1,...,xn;θ0)f(x1,...,xn;θ1)
≤ k
0; jika f(x1,...,xn;θ0)f(x1,...,xn;θ1)
> k
Tes UMP berukuran α untuk hipotesis ini akan menolak H0 jika 2nx/θ0 ≥ χ21−α(2n).
Tes ini tidak akan berubah selama θ1 > θ0. Jadi ψ merupakan tes N-P berukuran α
yang tidak bergantung pada θ1 selama θ1 > θ0. Maka ψ adalah tes UMP berukuran α
untuk hipotesis H0 : θ = θ0 vs H1 : θ > θ0. Fungsi power dari ψ adalah
Gψ(θ) =P
2nX
θ0
≥ χ21−α(2n) | θ
= P
2nX
θ
θ
θ0
≥ χ21−α(2n)
=P
2nX
θ≥ θ0
θχ2
1−α(2n)
= 1− Fχ2(2n)
(θ0
θχ2
1−α(2n)
),
dimana Fχ2(2n)(x) adalah fungsi distribusi kumulatif dari variabel χ2(2n). Karena
θ0
θχ2
1−α(2n) merupakan fungsi turun dari θ, maka Gψ(θ) merupakan fungsi monoton
naik dari θ, sehingga berlaku supθ≤θ0Gψ(θ) = Gψ(θ0) = α. Berdasarkan hasil ini,
ψ juga merupakan tes UMP berukuran α untuk hipotesis komposit H0 : θ ≤ θ0 vs
H1 : θ > θ0.
Secara analog tes UMP berukuran α berdasarkan sampel random dari populasi
Exp(θ) untuk menguji hipotesis H0 : θ = θ0 vs H1 : θ < θ0, akan menolak H0 jika
2nx/θ0 ≤ χ2α(2n). Misalkan tes ini sebagai ψ∗, maka fungsi power dari ψ∗ adalah
Gψ∗(θ) =P
2nX
θ0
≤ χ2α(2n) | θ
= P
2nX
θ
θ
θ0
≤ χ2α(2n)
= Fχ2(2n)
(θ0
θχ2
α(2n)
).

75
Jelaslah Gψ∗(θ) merupakan fungsi turun dari θ, oleh karena itu supθ≥θ0Gψ∗(θ) =
Gψ∗(θ0) = α. Jadi ψ∗ merupakan tes UMP berukuran α untuk hipotesis H0 : θ ≥ θ0
vs H1 : θ < θ0.
5.2.3 Keluarga monotone likelihood ratio (MLR)
Misalkan X1, . . . , Xn mempunyai fungsi densitas bersama f(x1, . . . , xn; θ), dengan
θ ∈ Θ ⊂ R. Misalkan T : χ → R merupakan statistik. Maka f(x1, . . . , xn; θ)
dikatakan dari keluarga monotone likelihood ratio (MLR) dalam T , jika terdapat
suatu fungsi non negatif g(t) sedemikian hingga untuk setiap θ1 dan θ2 dengan θ1 < θ2
berlaku:
f(x1, . . . , xn; θ2)
f(x1, . . . , xn; θ1)= g(T (x1, . . . , xn); θ1, θ2)
dengan g(T (x1, . . . , xn); θ1, θ2) monoton naik dalam T (x1, . . . , xn).
Contoh 5.2.7. Misalkan X1, . . . , Xn merupakan sampel random dari POIS(λ), de-
ngan λ > 0. Maka untuk λ1 < λ2, berlaku
f(x1, . . . , xn; λ2)
f(x1, . . . , xn; λ1)= en(λ1−λ2)(λ2/λ1)
∑ni=1 xi .
Misalkan T (x1, . . . , xn) :=∑n
i=1 xi, karena λ2/λ1 > 1, maka ruas kanan dari per-
samaan di atas merupakan fungsi monoton naik dari T (x1, . . . , xn). Jadi fungsi den-
sitas bersama f(x1, . . . , xn; λ) = e−nλλ∑n
i=1 xi/Πni=1(xi!) adalah dari keluarga MLR
dalam T (X1, . . . , Xn) =∑n
i=1 Xi.
Teorema 5.2.8. Misalkan X1, . . . , Xn mempunyai fungsi densitas bersama yang da-
pat dituliskan sebagai:
f(x1, . . . , xn; θ) = expq(θ)T (x1, . . . , xn) + h(x1, . . . , xn) + c(θ), θ ∈ Θ ⊂ R,

76
dimana h merupakan fungsi hanya dari (x1, . . . , xn), sedangkan c dan q adalah fungsi-
fungsi dari θ saja. Jika q monoton naik secara tegas, maka f(x1, . . . , xn; θ) merupakan
anggota keluarga MLR dalam T (X1, . . . , Xn).
Proof. Jika θ1 < θ2, maka
f(x1, . . . , xn; θ2)
f(x1, . . . , xn; θ1)= exp(q(θ2)− q(θ1))T (x1, . . . , xn) + c(θ2)− c(θ1).
Karena q merupakan fungsi monoton naik secara tegas dari θ, maka ruas kanan dari
persamaan di atas merupakan fungsi monoton dari T (x1, . . . , xn). Jadi f(x1, . . . , xn; θ)
merupakan anggota keluarga MLR dalam T .
Contoh 5.2.9. Jika X1, . . . , Xn merupakan sampel random dari populasi N(µ, 16),
dengan −∞ < µ < ∞, maka berlaku
f(x1, . . . , xn; µ) =1
4√
2πexp
− 1
32
n∑i=1
(xi − µ)2
= exp
nµ
16x−
∑ni=1 x2
i
32−
(µ2
32+ ln(4
√2π)
)
= exp q(θ)T (x1, . . . , xn) + h(x1, . . . , xn) + c(θ) ,
dengan q(θ) := nµ/16, h(x1, . . . , xn) := −∑ni=1 x2
i /32, c(µ) := −µ2/32 − ln(4√
2π),
dan T (x1, . . . , xn) := x. Jelaslah q merupakan fungsi monoton naik tegas dari µ,
sehingga dapat disimpulkan f(x1, . . . , xn; µ) dari keluarga MLR dalam X.
Teorema 5.2.10. Jika f(x1, . . . , xn; θ), θ ∈ Θ ⊂ R merupakan anggota dari keluarga
MLR dalam T (X1, . . . , Xn), maka tes UMP berukuran α untuk hipotesis H0 : θ ≤ θ0
vs H1 : θ > θ0 adalah
ϕ∗(x1, . . . , xn) =
1; jika T (x1, . . . , xn) ≥ k
0; jika T (x1, . . . , xn) < k,

77
dimana k adalah konstanta yang ditentukan dari persamaan
P T (X1, . . . , Xn) ≥ k | θ = θ0 = α.
Jika nilai k yang memenuhi persamaan ini adalah k∗, maka daerah kritik dari tes ini
adalah
Cϕ∗ := (x1, . . . , xn) ∈ χ : T (x1, . . . , xn) ≥ k∗ .
Proof. Pertama-tama akan ditunjukkan bahwa ϕ∗ merupakan tes N-P berukuran α
untuk hipotesis sederhana H ′0 : θ = θ0 vs H ′
1 : θ = θ1, untuk sembarang θ1 ∈ Θ dengan
θ1 > θ0, dan ditunjukkan bahwa tes ini tidak bergantung pada θ1 asalkan θ1 > θ0.
Kedua, kita tunjukkan bahwa fungsi power Gϕ∗(θ) merupakan fungsi monoton naik
dari θ. Karena g(t; θ0, θ1) merupakan fungsi monoton naik dari t, maka berlaku:
T (x1, . . . , xn) ≥ k ⇔g(T (x1, . . . , xn); θ0, θ1) ≥ g(k; θ0, θ1)
⇔f(x1, . . . , xn; θ1)
f(x1, . . . , xn; θ0)≥ g(k; θ0, θ1) ⇔ f(x1, . . . , xn; θ0)
f(x1, . . . , xn; θ1)≤ k∗,
dimana k∗ := 1/g(k; θ0, θ1). Jadi tes ϕ∗ equivalen dengan
ϕ∗(x1, . . . , xn) =
1; jika f(x1,...,xn;θ0)f(x1,...,xn;θ1)
≤ k∗
0; jika f(x1,...,xn;θ0)f(x1,...,xn;θ1)
> k∗.
Selanjutnya,
α = P T (X1, . . . , Xn) ≥ k | θ = θ0 = P
f(x1, . . . , xn; θ0)
f(x1, . . . , xn; θ1)≤ k∗ | θ = θ0
.
Jadi ϕ∗ adalah tes N-P berukuran α untuk hipotesis H ′0 : θ = θ0 vs H ′
1 : θ = θ1. Tes
ini tidak bergantung pada pemilihan θ1 ∈ Θ, asalkan θ1 > θ0. Sehingga ϕ∗ adalah
tes UMP berukuran α untuk hipotesis H ′0 : θ = θ0 vs H1 : θ > θ0. Bahwa fungsi

78
power Gϕ∗(θ) monoton naik pada Θ dapat dilihat pada Pruscha (2000), hal. 229-230.
Akibat dari kemonotonan dari Gϕ∗(θ), berlaku: supθ≤θ0Gϕ∗(θ) = Gϕ∗(θ0) = α. Jadi
ϕ∗ adalah tes UMP berukuran α untuk hipotesis H0 : θ ≤ θ0 vs H1 : θ > θ0.
Contoh 5.2.11. Dari Contoh 5.2.9, distribusi bersama dari X1, . . . , Xn adalah dari
keluarga MLR dalam X. Berdasarkan Teorema 5.2.10, tes UMP berukuran alpha
untuk hipotesis H0 : µ ≤ µ0 vs H1 : µ > µ0 adalah
ϕ∗(x1, . . . , xn) =
1; jika x ≥ k
0; jika x < k,
dengan PX ≥ k | µ = µ0
= α. Jika µ0 merupakan nilai sebenarnya dari µ, maka
daerah kritik dari ϕ∗ adalah
Cϕ∗ =(x1, . . . , xn) ∈ χ :
√n(x− µ0)/4 ≥ z1−α
=(x1, . . . , xn) ∈ χ : x ≥ µ0 + 4z1−α/
√n
.
Remark 5.2.12. Jika f(x1, . . . , xn; θ) merupakan anggota dari keluarga MLR dalam
T (X1, . . . , Xn), maka tes UMP berukuran α untuk hipotesis H0 : θ ≥ θ0 vs H1 : θ < θ0
adalah
ϕ∗(x1, . . . , xn) =
1; jika T (x1, . . . , xn) ≤ k
0; jika T (x1, . . . , xn) > k,
dimana k adalah konstanta yang ditentukan dari persamaan
P T (X1, . . . , Xn) ≤ k | θ = θ0 = α.
Catatan:
Jika f(x1, . . . , xn; θ) merupakan anggota dari keluarga MLR dalam T (X1, . . . , Xn),

79
untuk θ1 < θ0, maka f(x1,...,xn;θ1)f(x1,...,xn;θ0)
merupakan fungsi monoton turun dari T (x1, . . . , xn),
sehingga
(x1, . . . , xn) ∈ χ : T (x1, . . . , xn) ≤ k ⊆
(x1, . . . , xn) ∈ χ :f(x1, . . . , xn; θ1)
f(x1, . . . , xn; θ0)≥ k∗
untuk suatu k∗, dimana k∗ := g(k; θ0, θ1).
5.3 Tes dengan membandingkan fungsi likelihood
Tes dengan membandingkan fungsi likelihood (engl. Likelihood Ratio Test) disingkat
LRT merupakan salah satu tes yang berhubungan langsung dengan maksimum like-
lihood estimator yang dibahas pada Chapter 2. Pada sub bab sebelumnya prosudur
tes UMP diturunkan terbatas pada hipotesis sederhana dan hipotesis komposit satu
sisi. Tetapi untuk hipotesis komposit dua sisi H0 : θ = θ0 vs H1 : θ 6= θ0 tes UMP
tidak dapat diturunkan. Permasalahan ini dan permasalahan tes dengan kehadiran
parameter pengganggu dapat ditangani dengan tes likelihood ratio.
Definisi 5.3.1. Misalkan L(θ; x1, . . . , xn) merupakan fungsi likelihood dari variabel
random X1, . . . , Xn. Misalkan
λ(x1, . . . , xn) :=supθ∈H0
L(θ; x1, . . . , xn)
supθ∈Θ L(θ; x1, . . . , xn).
Tes LR berukuran α untuk hipotesis H0 : θ ∈ Θ0 vs H1 : θ ∈ Θ1 adalah
φ(x1, . . . , xn) =
1; jika λ(x1, . . . , xn) ≤ k
0; jika λ(x1, . . . , xn) > k,
dimana 0 < k < 1 adalah konstanta yang tidak diketahui yang ditentukan dari per-
samaan
supθ∈H0
Pλ(X1, . . . , Xn) ≤ k = α.

80
Remark 5.3.2. Misalkan θ0 adalah MLE untuk θ pada daerah yang dibatasi pada Θ0
(MLE yang dibatasi pada H0) dan θ adalah MLE untuk θ pada daerah Θ (MLE yang
tidak dibatasi). Maka
λ(x1, . . . , xn) =L(θ0; x1, . . . , xn)
L(θ; x1, . . . , xn).
Jadi daerah kritik dari tes LR dikonstruksikan dengan cara sedemikian rupa sehingga
titik-titik sampel mempunyai rasio yang kecil.
Contoh 5.3.3. Misalkan X1, . . . , Xn merupakan sampel random dari populasi N(µ, 1),
dimana µ tidak diketahui, −∞ < µ < ∞. Kita tertarik untuk mengkonstruksikan tes
LR untuk hipotesis H0 : µ = µ0 vs H1 : µ 6= µ0, dimana µ0 adalah konstanta yang
diketahui (ditentukan oleh ekperimenter). Karena pada H0 dispesifikasikan dengan
jelas bahwa Θ0 = µ0, maka supµ∈H0L(µ; x1, . . . , xn) = maxµ∈H0 L(µ; x1, . . . , xn) =
L(µ0; x1, . . . , xn). MLE untuk µ pada daerah −∞ < µ < ∞ adalah µ = X, maka
berlaku
λ(x1, . . . , xn) =L(µ0; x1, . . . , xn)
L(x; x1, . . . , xn)= exp
−1/2
[n∑
i=1
(xi − µ0)2 −
n∑i=1
(xi − x)2
].
Selanjutnya, karena∑n
i=1(xi − µ0)2 =
∑ni=1(xi − x)2 + n(x− µ0)
2, maka diperoleh
λ(x1, . . . , xn) = exp
−1
2n(x− µ0)
2
.
Selanjutnya
supµ∈H0
P λ(X1, . . . , Xn) ≤ k = P λ(X1, . . . , Xn) ≤ k | µ = µ0 = α
⇔ P
exp
−1
2n(X − µ0)
2
≤ k
= α
⇔ P(√
n(X − µ0))2 ≥ −2 ln k
= α.

81
Karena (√
n(X − µ0))2 berdistribusi χ2(n), maka tes LR berukuran α akan menolak
H0, jika n(x− µ0)2 ≥ χ2(n)1−α atau k = exp−χ2
1−α(n)/2. Cara lain adalah
P(√
n(X − µ0))2 ≥ −2 ln k
= α
⇔P√
n(X − µ0) ≤ −√−2 ln k atau
√n(X − µ0) ≥
√−2 ln k
= α.
Karena√
n(X − µ0) berdistribusi N(0, 1), maka tes LR berukuran α akan menolak
H0, jika√
n(x− µ0) ≤ −z1−α/2 atau√
n(x− µ0) ≥ z1−α/2.
Contoh 5.3.4. Misalkan X1, . . . , Xn merupakan sampel random dari populasi N(µ, σ2),
dengan µ dan σ2 parameter-parameter yang tidak diketahui, −∞ < µ < ∞ dan
0 < σ2 < ∞. Kita akan menurunkan prosudur tes LR berukuran α untuk hipotesis
H0 : µ = µ0 vs H1 : µ 6= µ0, dimana µ0 adalah bilangan yang diketahui. Pada kasus
ini ruang parameter Θ0 dan Θ adalah
Θ0 = (µ, σ2) : µ = µ0, 0 < σ2 < ∞ = µ0 × (0,∞),
Θ = (µ, σ2) : −∞ < µ < ∞, 0 < σ2 < ∞ = (−∞,∞)× (0,∞).
Dari Contoh 2.2.4 pada Chapter 2 diperoleh MLE untuk µ dan σ2 pada Θ adalah
µ = X dan σ2 = 1n
∑ni=1(Xi − X)2. Sedangkan MLE untuk µ dan σ2 pada Θ0 adalah
µ0 = µ0 dan σ20 = 1
n
∑ni=1(Xi − µ0)
2. Sehingga
λ(x1, . . . , xn) =(2πσ2
0)−n/2 exp
− 1
2σ20
∑ni=1(xi − µ0)
2
(2πσ2)−n/2 exp− 1
2σ2
∑ni=1(xi − x)2
=
(σ2
0
σ2
)−n/2
exp
−1
2
∑ni=1(xi − µ0)
2
1n
∑ni=1(xi − µ0)2
+1
2
∑ni=1(xi − x)2
1n
∑ni=1(xi − x)2
=
(σ2
0
σ2
)−n/2
=
(1 +
n(x− µ0)2
∑ni=1(xi − x)2
)−n/2
=
(1 +
[√
n(x− µ0)]2/(n− 1)
s2
)−n/2
.

82
Selanjutnya,
supµ∈H0
P λ(X1, . . . , Xn) ≤ k = α
⇔P(
1 +[√
n(X − µ0)]2/(n− 1)
S2
)−n/2
≤ k
= α
⇔PT 2(n− 1) ≥ k1
= α ⇔ P
T (n− 1) ≥
√k1 atau T (n− 1) ≤ −
√k1
= α
dimana T (n − 1) := [√
n(X − µ0)]/S, dan k1 := (n − 1)k−2/n. Karena T (n − 1)
berdistribusi t dengan derajat bebas n−1, maka tes LR berukuran α akan menolak H0
jika [√
n(x − µ0)]/s ≥ t1−α/2(n − 1) atau [√
n(x − µ0)]/s ≤ −t1−α/2(n − 1). Karena
T 2(n − 1) berdistribusi F (1; n − 1), maka H0 juga ditolak jika [√
n(x − µ0)]2/s2 ≥
f1−α(1; n− 1).
5.4 Soal-soal
1. Suatu kotak berisi empat kelereng, θ berwarna putih dan 4−θ berwarna hitam.
Hipotesis H0 : θ = 2 vs H1 : θ 6= 2 dites dengan cara berikut: Dua klereng
diambil dengan pengembalian, selanjutnya H0 ditolak jika kedua klereng yang
terambil mempunyai warna yang sama.
(a) Hitung PKesalahan tipe I.
(b) Hitung PKesalahan tipe II.
(c) Kerjakan (a) dan (b) jika pengambilan dilakukan tanpa pengembalian.
2. Misalkan X1, . . . , Xn merupakan sampel random dari populasi EXP (1, η). Hipote-
sis H0 : η ≤ η0 vs H1 : η > η0 akan dites berdasarkan statistik X1:n.
(a) Tentukan Cα yang berbentuk (x1, . . . , xn) ∈ χ : x1:n ≥ c.

83
(b) Tentukan fungsi power untuk tes pada (a).
3. Diberikan suatu distribusi dengan fungsi densitas
f(x; θ) =
θxθ−1 ; jika 0 < x < 1
0 ; jika x ≤ 0 atau x ≥ 1
(a) Berdasar pada sampel random berukuran n, konstruksikan tes MP beruku-
ran α = 0, 05 untuk hipoptesis H0 : θ = 1 vs H1 : θ = 2.
(b) Tentukan power dibawah alternatif dari tes pada (a).
4. Jika X1, . . . , Xn mempunyai fungsi densitas bersama f(x1, . . . , xn; θ) dan S
adalah statistik cukup untuk θ. Tunjukkan bahwa tes MP untuk hipotesis
H0 : θ = θ0 vs H1 : θ = θ1 dapat dinyatakan dalam S.
5. Misalkan X1, . . . , Xn merupakan sampel random dari populasi dengan fungsi
densitas
f(x; θ) =
(3x2/θ)e−x3/θ ; jika 0 < x
0 ; jika x ≤ 0.
Tentukan daerah kritik dari suatu tes UMP berukuran α untuk hipotesis H0 :
θ = θ0 vs H1 : θ > θ0.
6. Misalkan X1, . . . , Xn merupakan sampel random dari suatu populasi diskrit
dengan fungsi densitas
f(x; θ) =
[θ/(θ+1)]x
(θ+1); jika x ∈ 0, 1, . . .
0 ; jika x 6∈ 0, 1, . . ..
Tentukan tes UMP untuk hipotesis H0 : θ = θ0 vs H1 : θ > θ0.
7. Misalkan X1, . . . , Xn merupakan sampel random dari populasi WEI(θ, 2). Tu-
runkan suatu tes UMP untuk hipotesis H0 : θ ≥ θ0 vs H1 : θ < θ0.

84
8. Misalkan X1, . . . , Xn merupakan sampel random dari populasi EXP (θ).
(a) Turunkan suatu tes RL untuk hipotesis H0 : θ = θ0 vs H1 : θ 6= θ0.
(b) Turunkan tes RL untuk hipotesis H0 : θ = θ0 vs H1 : θ > θ0.
9. Perhatikan dua sampel random yang saling bebas Xi ∼ N(µ1, σ21) dan Yj ∼
N(µ2, σ22).
(a) Turunkan suatu tes RL untuk H0 : σ21 = σ2
2 jika diasumsikan µ1 dan µ2
diketahui.
(b) Turunkan suatu tes RL untuk H0 : σ21 = σ2
2 jika diasumsikan µ1 dan µ2
tidak diketahui.
10. Misalkan X1, . . . , Xn merupakan sampel random dari populasi EXP (θ, η). Mis-
alkan θ dan η merupakan MLE untuk θ dan η.
(a) Tunjukkan bahwa θ dan η saling bebas.
(b) Misalkan V1 = 2n(X−θ)/η, V2 = 2n(η−η)/θ, dan V3 = 2nθ/θ. Tunjukkan
bahwa V1 ∼ χ2(2n), V2 ∼ χ2(2), dan V3 ∼ χ2(2n− 2).
(c) Tunjukkan bahwa (n− 1)(η − η)/θ ∼ F (2; 2n− 2).
(d) Turunkan tes RL untuk hipotesis H0 : η = η0 vs H1 : η ≥ η0.
(e) Tunjukkan bahwa daerah kritik berukuran α dari tes RL adalah
Cα =
(x1, . . . , xn) ∈ χ : (n− 1)(η − η0)/θ ≥ f1−α(2; 2n− 2)
.

Chapter 6
Teori sampel besar
85

Chapter 7
Teori Bayes
86

Chapter 8
Estimasi dengan metode bootstrap
87


















