


Digital Signal Processing Group School of Electronics Dept ...dsp_agh_15.pdf · 4 Psychoacoustic...
57
1 Digital Signal Processing Group School of Electronics Dept of Computer Science, Electronics and Telecommunications AGH University of Science and Technology, Kraków, Poland dsp.agh.edu.pl
Transcript of Digital Signal Processing Group School of Electronics Dept ...dsp_agh_15.pdf · 4 Psychoacoustic...

1
Digital Signal Processing Group
School of Electronics
Dept of Computer Science, Electronics
and Telecommunications
AGH University of Science and
Technology, Kraków, Poland
dsp.agh.edu.pl

2
• Automatic speech recognition
• Speaker verification, identification and
profiling
• Natural language processing
• 3D sound simmulation
• Speech enhancement
Topics of our research

3
Automatic speech
recognition
4
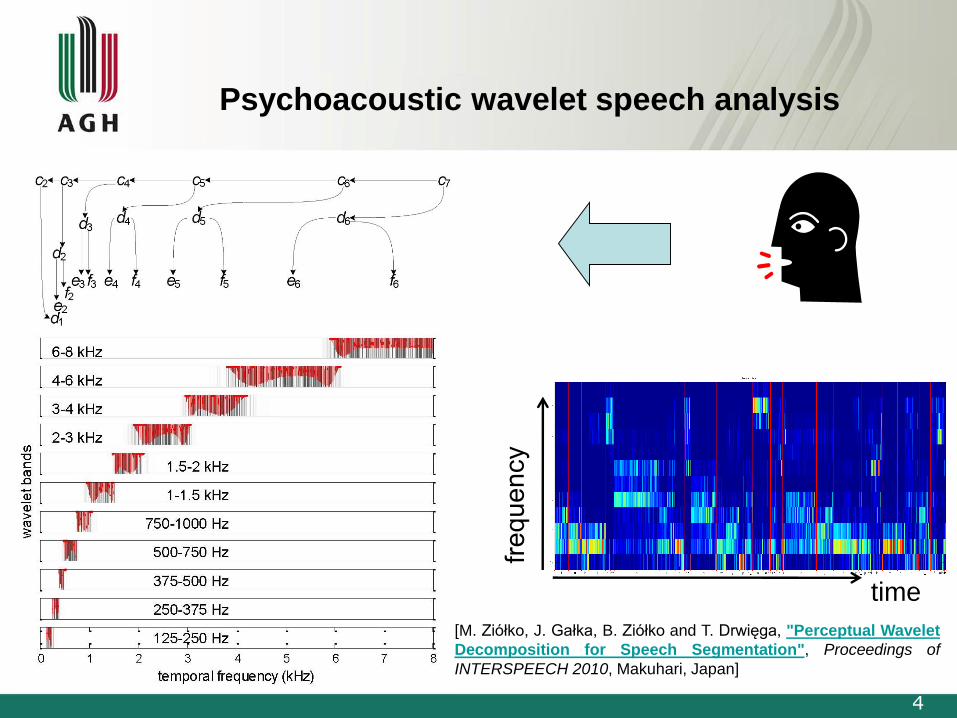
Psychoacoustic wavelet speech analysis
time
[M. Ziółko, J. Gałka, B. Ziółko and T. Drwięga, "Perceptual Wavelet
Decomposition for Speech Segmentation", Proceedings of
INTERSPEECH 2010, Makuhari, Japan]
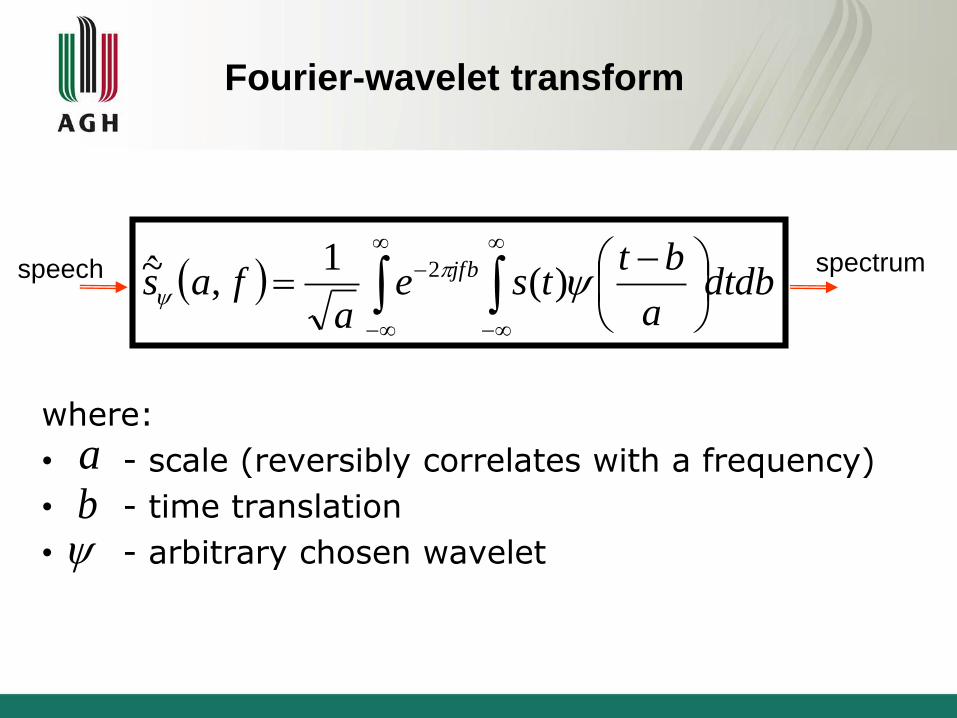
Fourier-wavelet transform
dbdta
bttse
afas jfb
)(1
,~̂ 2
where:
• - scale (reversibly correlates with a frequency)
• - time translation
• - arbitrary chosen wavelet
ab
speech spectrum
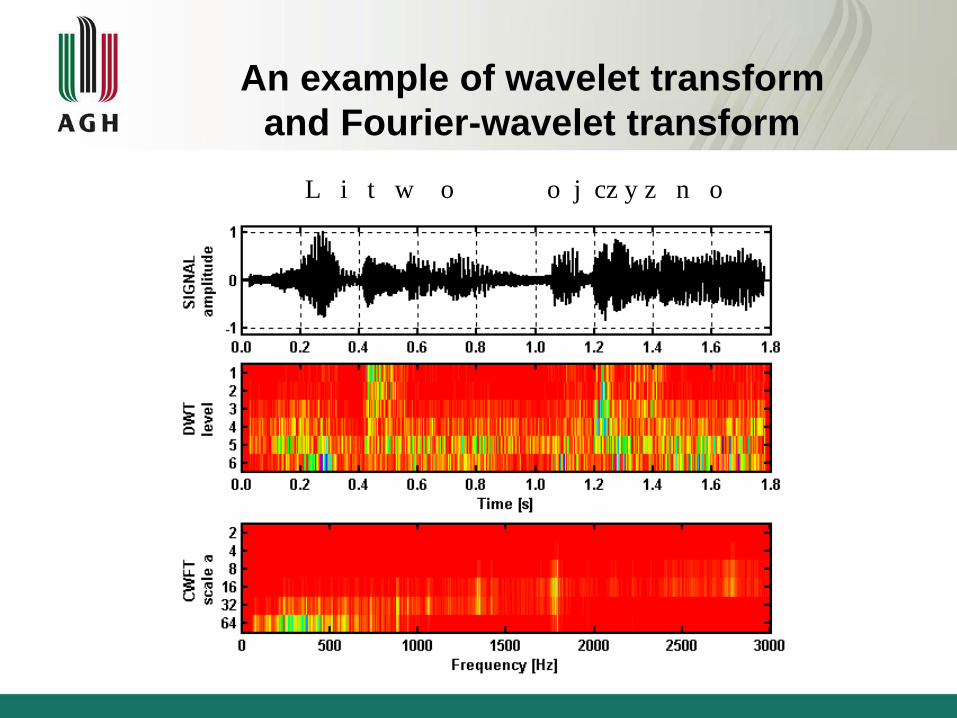
An example of wavelet transform
and Fourier-wavelet transform
L i t w o o j cz y z n o

Boundaries detection
End of sentence End of sentence
(…) oczywiście, znowu, no, jest to sprawa nakładów. Na to też jest dużo pieniędzy,
głównie ze względu na weteranów wojennych. Ostatnio w Stanach te badania się (…)
[B. Ziółko, P. Żelasko, D. Skurzok, ”Statistics of diphones and triphones presence on the wordboundaries in the Polish language. Applications to ASR, XXII Pacific Voice Conference, 2014]
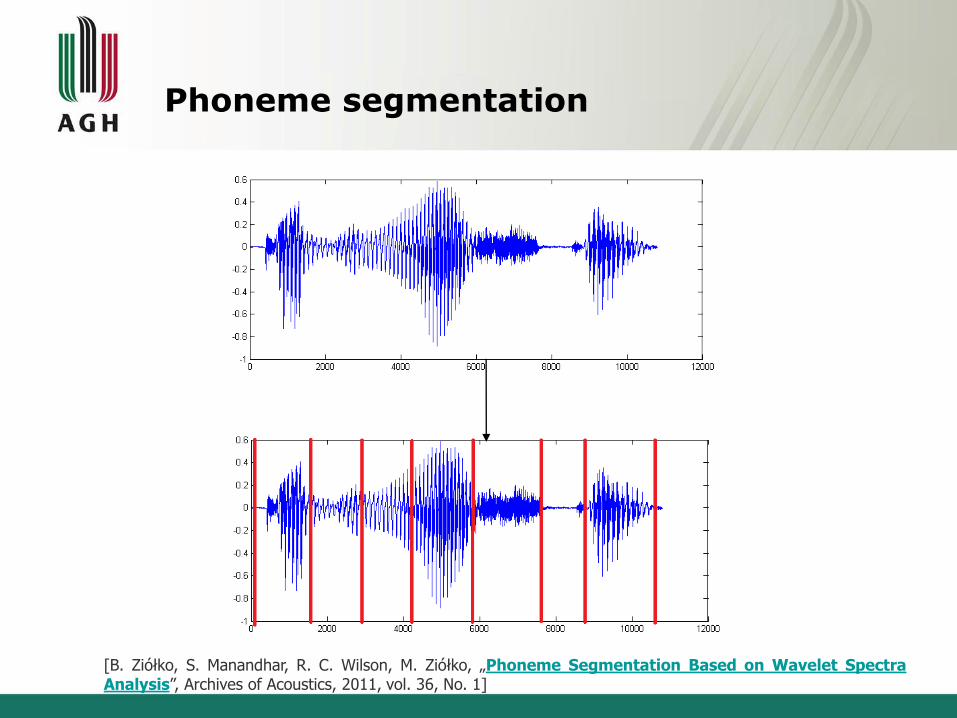
Phoneme segmentation
[B. Ziółko, S. Manandhar, R. C. Wilson, M. Ziółko, „Phoneme Segmentation Based on Wavelet SpectraAnalysis”, Archives of Acoustics, 2011, vol. 36, No. 1]
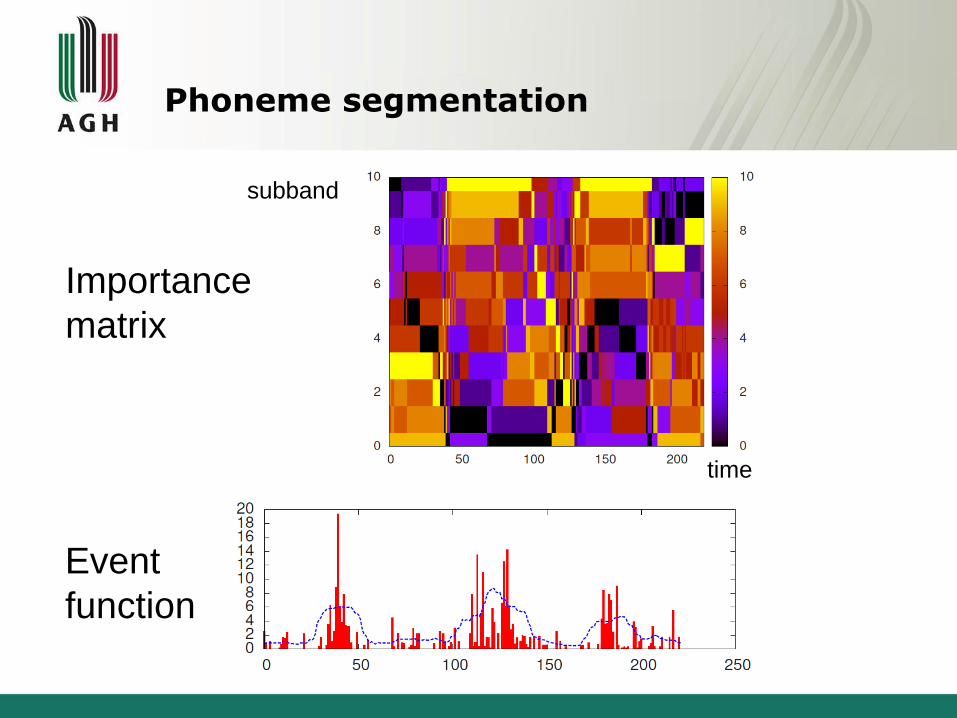
Phoneme segmentation
Importance
matrix
Event
function
subband
time
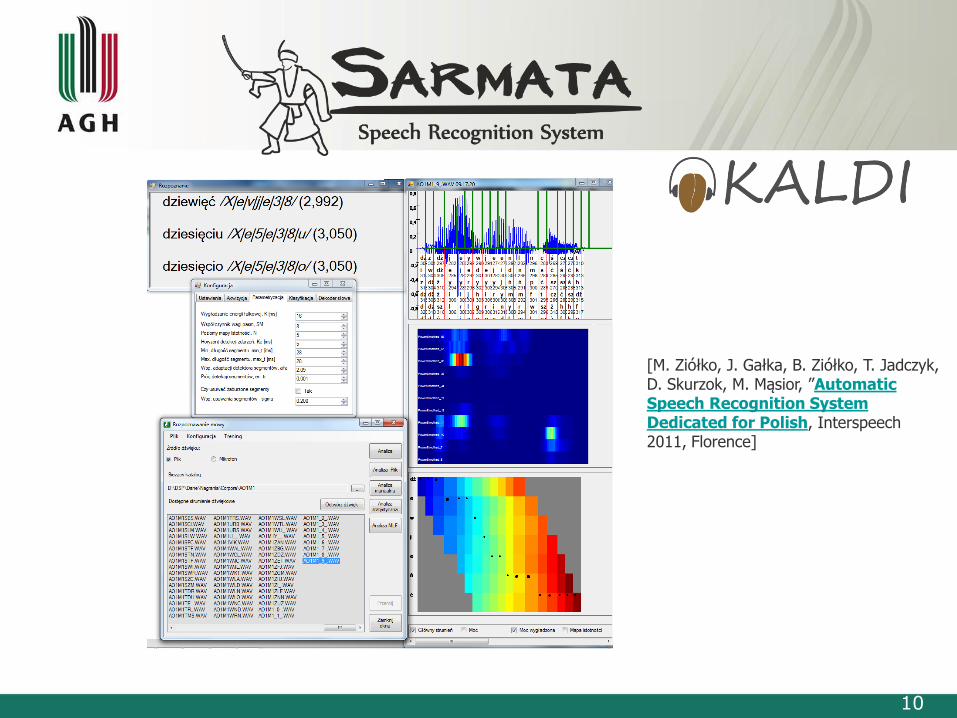
10
[M. Ziółko, J. Gałka, B. Ziółko, T. Jadczyk, D. Skurzok, M. Mąsior, ”Automatic Speech Recognition System Dedicated for Polish, Interspeech2011, Florence]
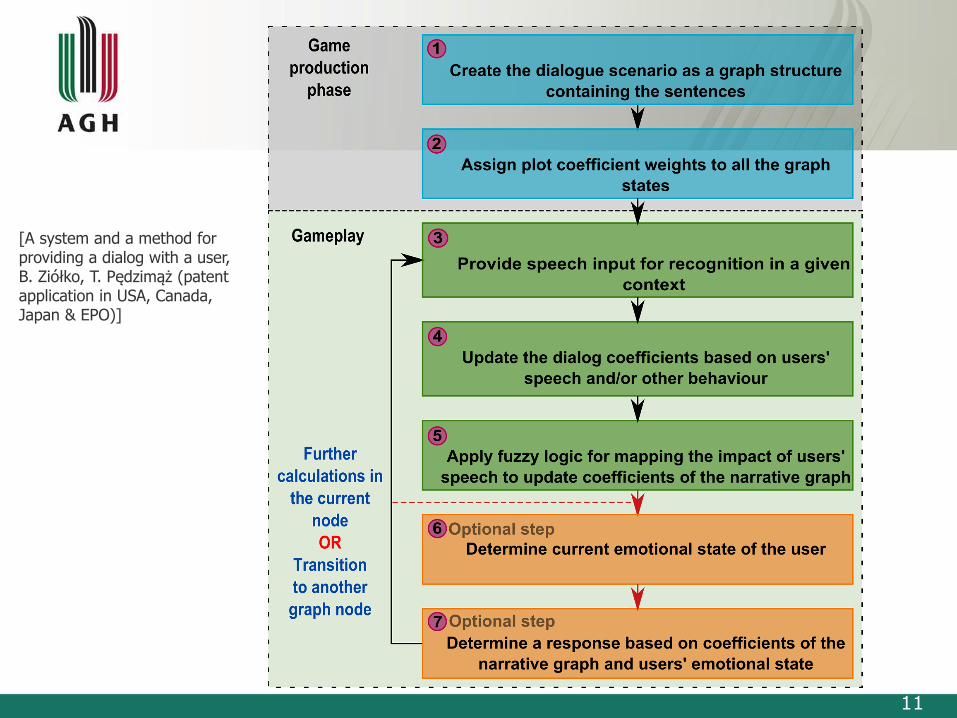
11
[A system and a method for providing a dialog with a user, B. Ziółko, T. Pędzimąż (patent application in USA, Canada, Japan & EPO)]
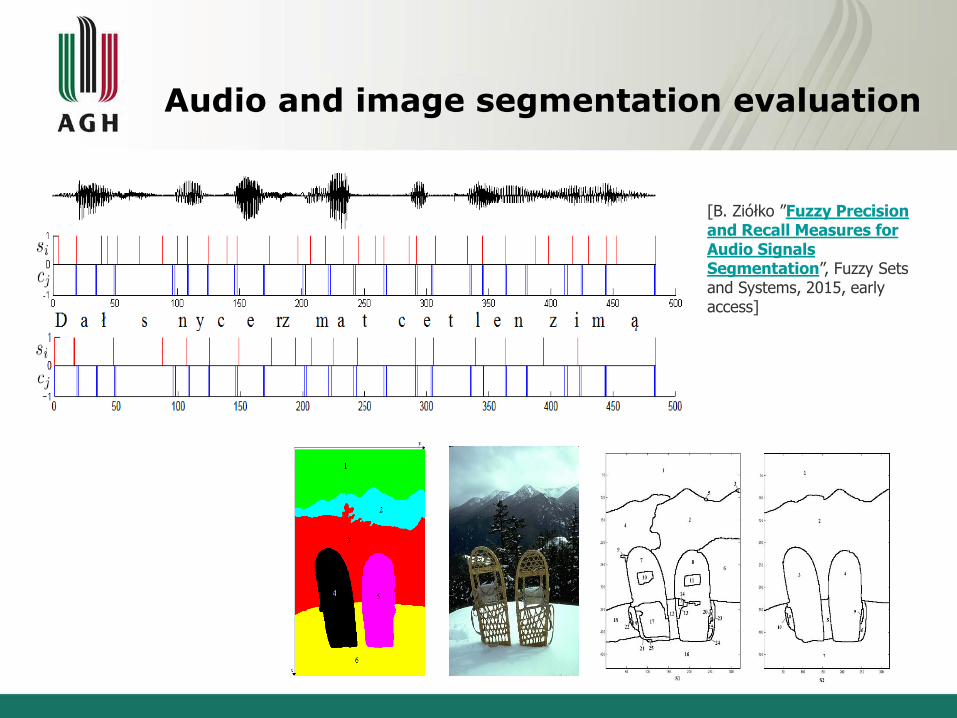
Audio and image segmentation evaluation
[B. Ziółko ”Fuzzy Precision and Recall Measures for Audio Signals Segmentation”, Fuzzy Sets and Systems, 2015, earlyaccess]

Applications
13

Automatic dialect and languagerecognition
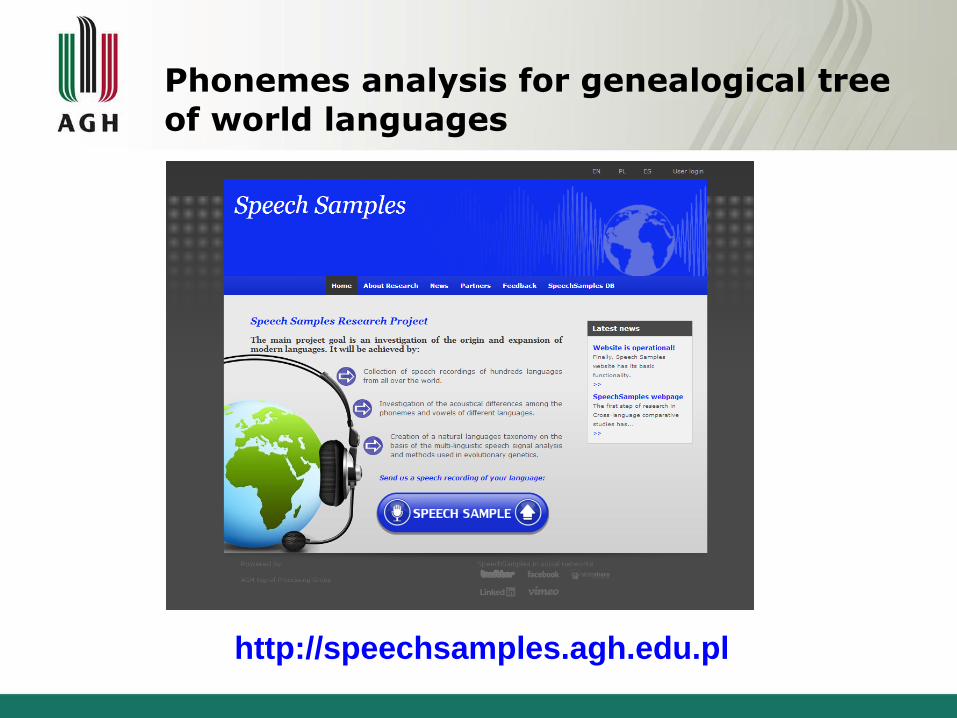
Phonemes analysis for genealogical tree
of world languages
http://speechsamples.agh.edu.pl

16
Speaker verification,
identification and
profiling
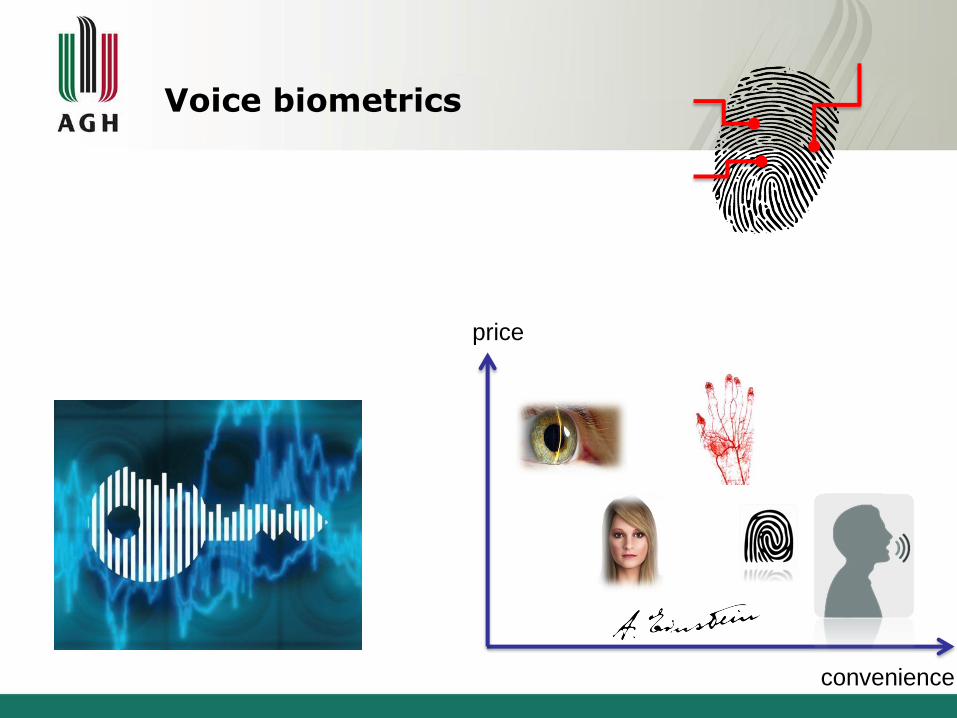
Voice biometrics
convenience
price

Recording Matching Decision
Voiceprint database
YES NO
Speaker verification

System supporting speaker identification in emergency call center
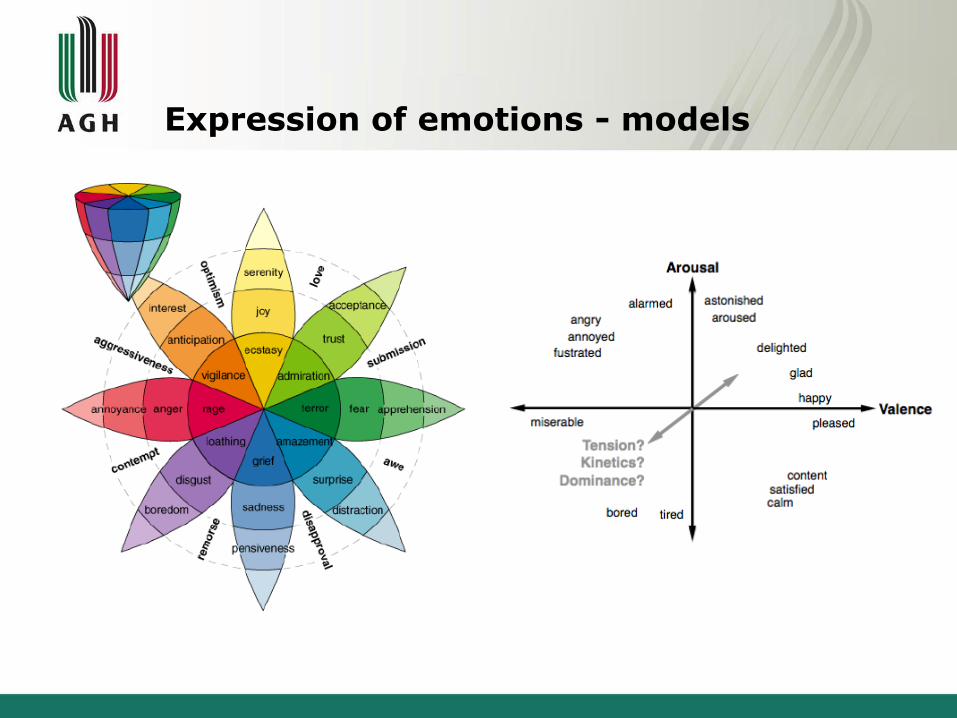
Expression of emotions - models
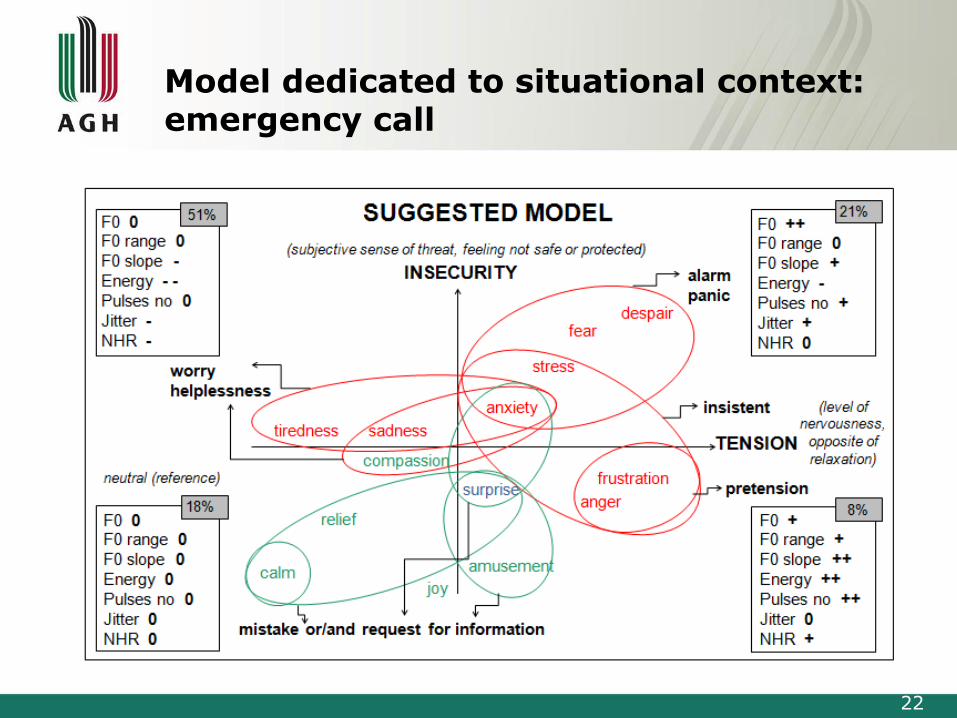
Model dedicated to situational context:emergency call
22
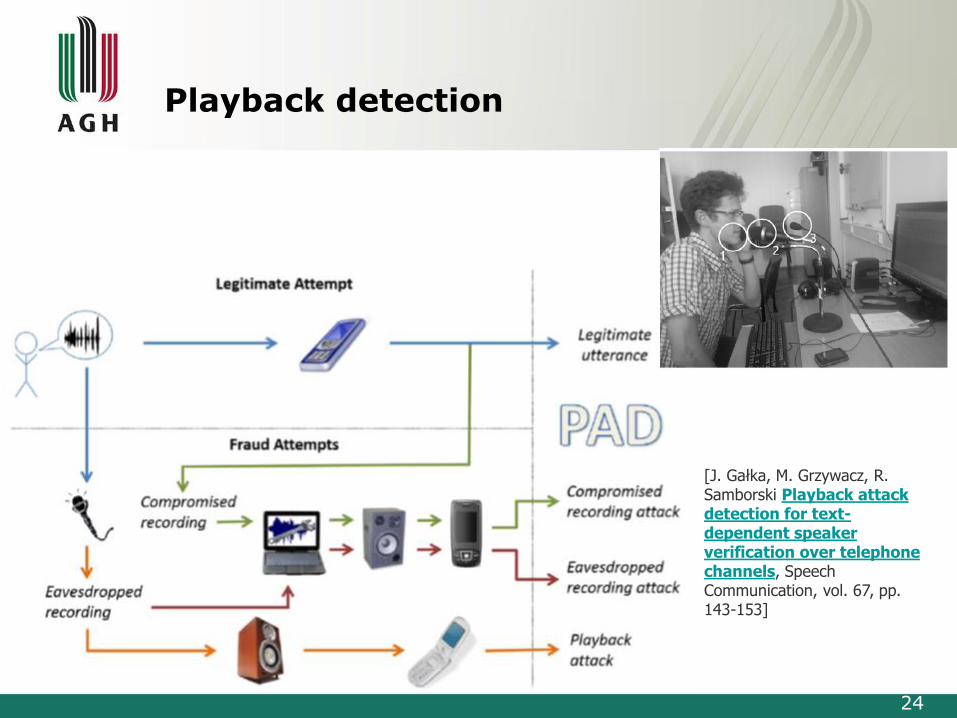
Playback detection
24
[J. Gałka, M. Grzywacz, R. Samborski Playback attackdetection for text-dependent speaker verification over telephonechannels, Speech Communication, vol. 67, pp. 143-153]
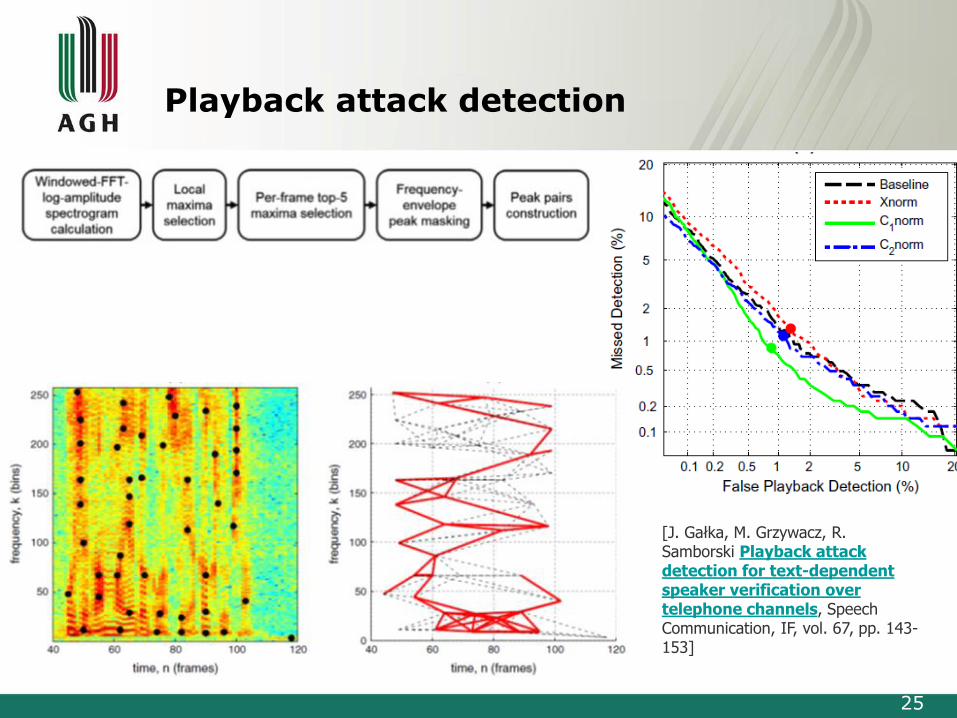
Playback attack detection
25
[J. Gałka, M. Grzywacz, R. Samborski Playback attackdetection for text-dependent speaker verification overtelephone channels, Speech Communication, IF, vol. 67, pp. 143-153]

SafeLock
• Cortex M4
• STM32F407VGT6
• PN/EN for access control systems
[J. Gałka, M. Mąsior, M. Salasa Voice authentication embedded solution for secured access control, IEEE Transactions on Consumer Electronics, vol. 60, issue 40, pp. 653-661]

28
Natural language
processing
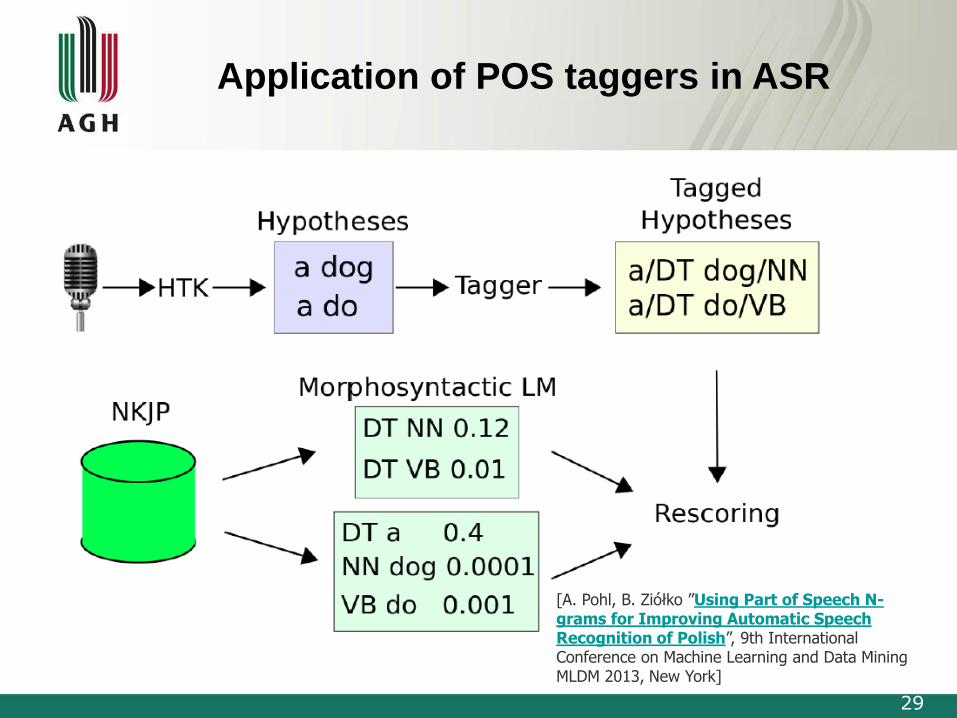
29
Application of POS taggers in ASR
[A. Pohl, B. Ziółko ”Using Part of Speech N-grams for Improving Automatic Speech Recognition of Polish”, 9th International Conference on Machine Learning and Data Mining MLDM 2013, New York]

30
Results – taggers performance
[A. Pohl, B. Ziółko ”A Comparison of Polish Taggers in the Applicationfor Automatic Speech Recognition”, LTC, Poznań, 2013]
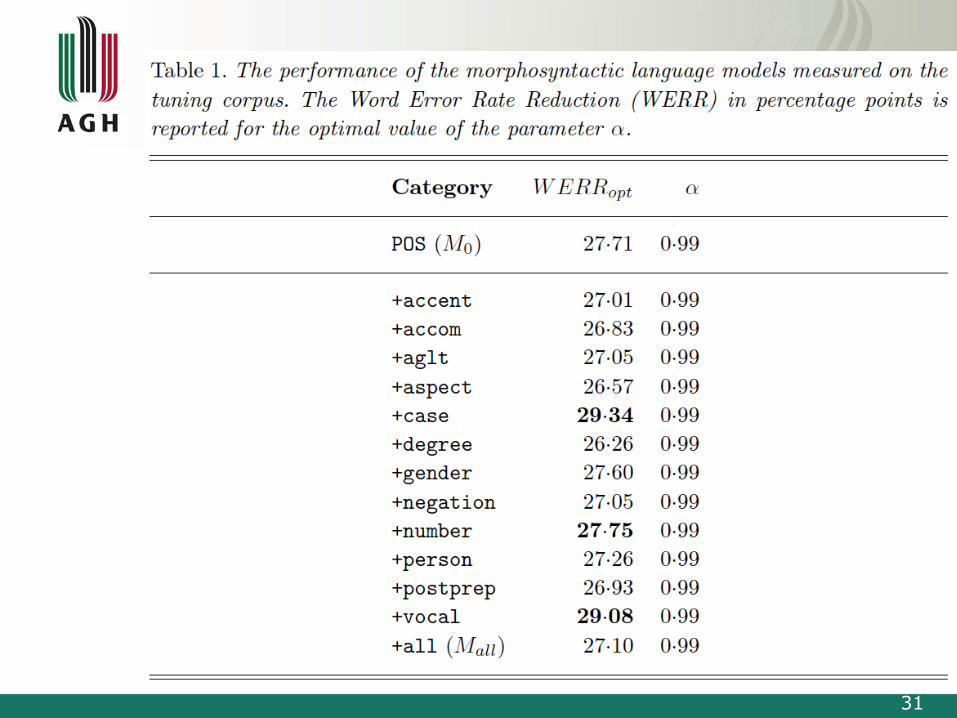
31

32
Classification of Wikipedia articles

33
Classification of Wikipedia articles
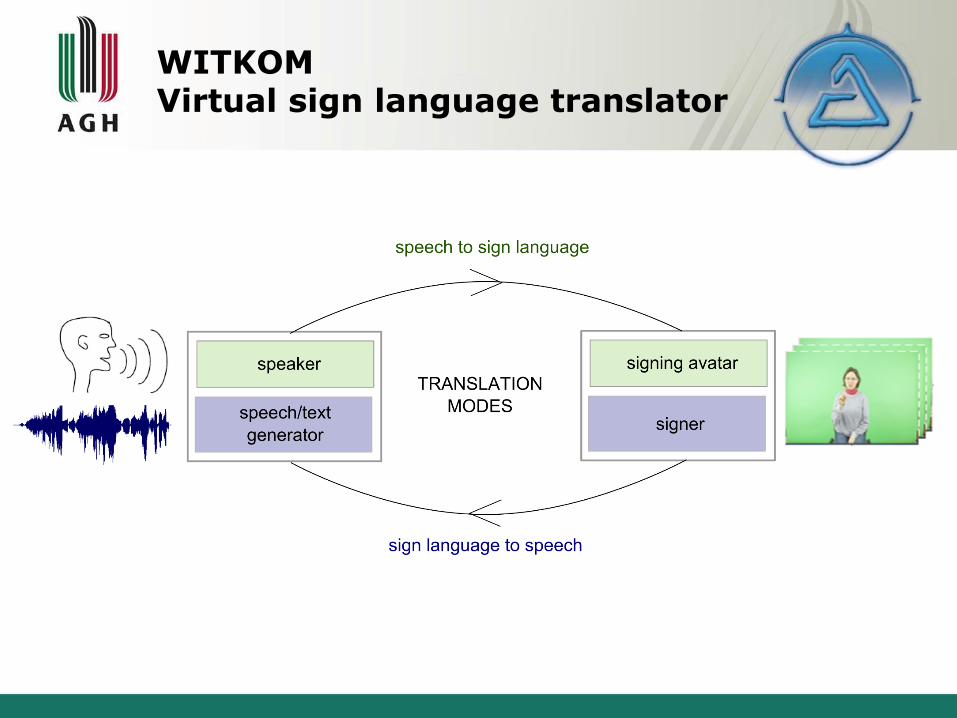
WITKOMVirtual sign language translator

Sign language acquisition, motion capture

Sensor glove
42
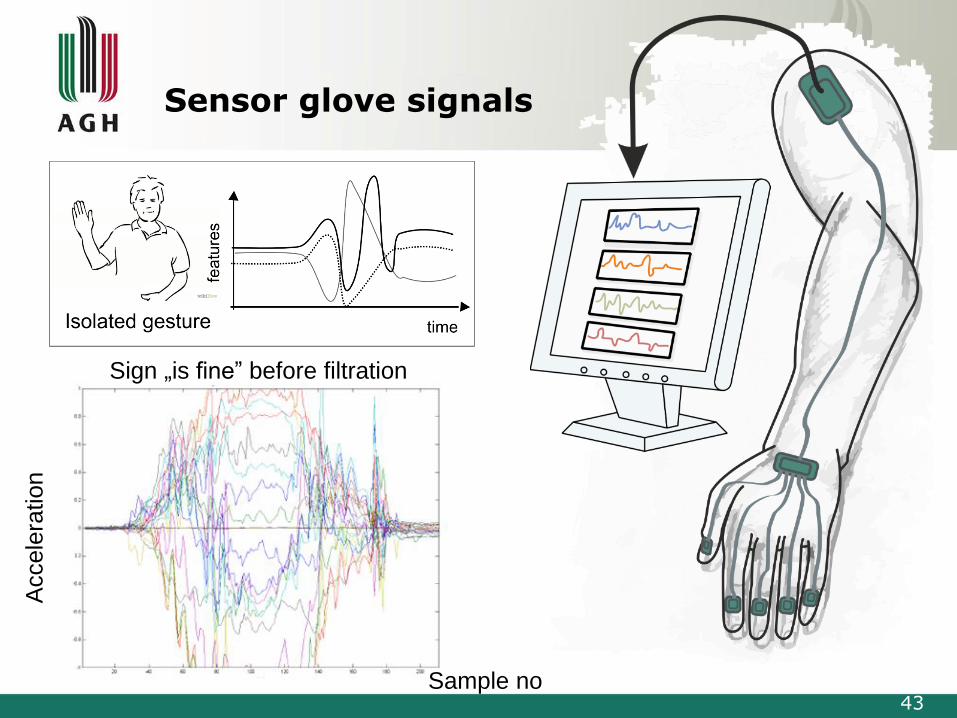
Sensor glove signals
43Sample no
Accele
ration
Sign „is fine” before filtration
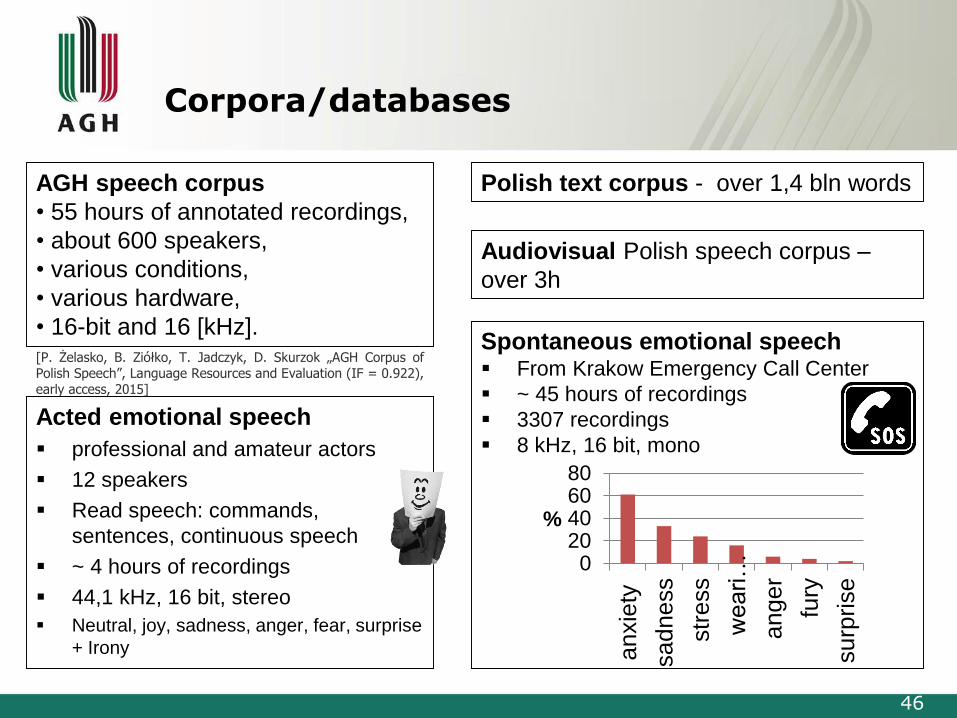
Corpora/databases
Acted emotional speech
professional and amateur actors
12 speakers
Read speech: commands,
sentences, continuous speech
~ 4 hours of recordings
44,1 kHz, 16 bit, stereo
Neutral, joy, sadness, anger, fear, surprise
+ Irony
Spontaneous emotional speech From Krakow Emergency Call Center
~ 45 hours of recordings
3307 recordings
8 kHz, 16 bit, mono
46
020406080
anxie
ty
sad
ness
str
ess
weari…
an
ger
fury
surp
rise
%
AGH speech corpus
• 55 hours of annotated recordings,
• about 600 speakers,
• various conditions,
• various hardware,
• 16-bit and 16 [kHz].
Polish text corpus - over 1,4 bln words
Audiovisual Polish speech corpus –
over 3h
[P. Żelasko, B. Ziółko, T. Jadczyk, D. Skurzok „AGH Corpus ofPolish Speech”, Language Resources and Evaluation (IF = 0.922),early access, 2015]

47
3D sound simmulation
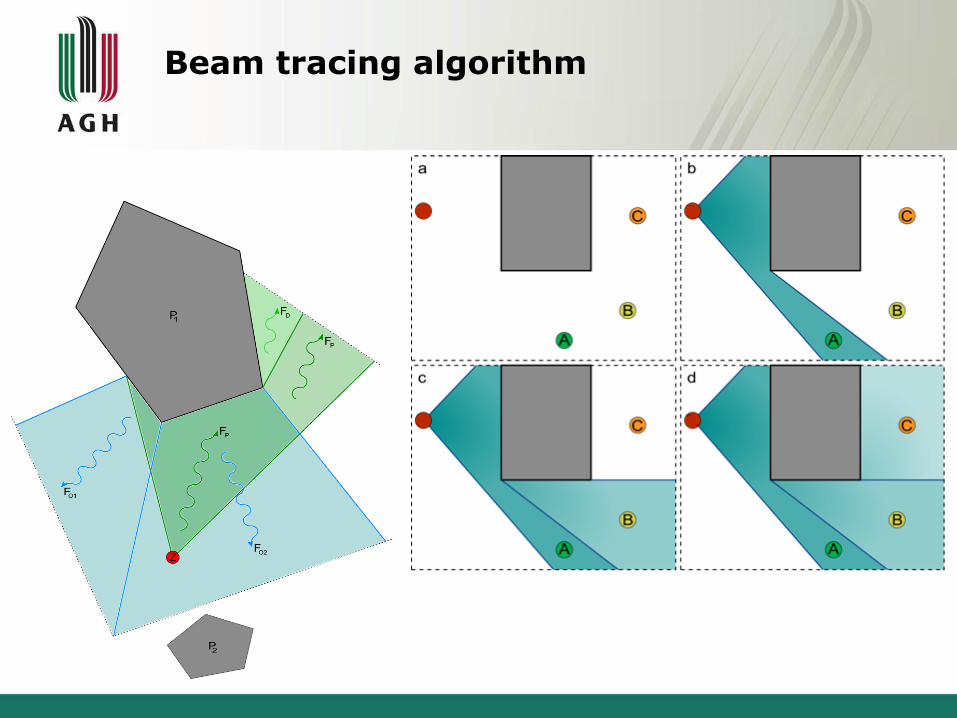
Beam tracing algorithm
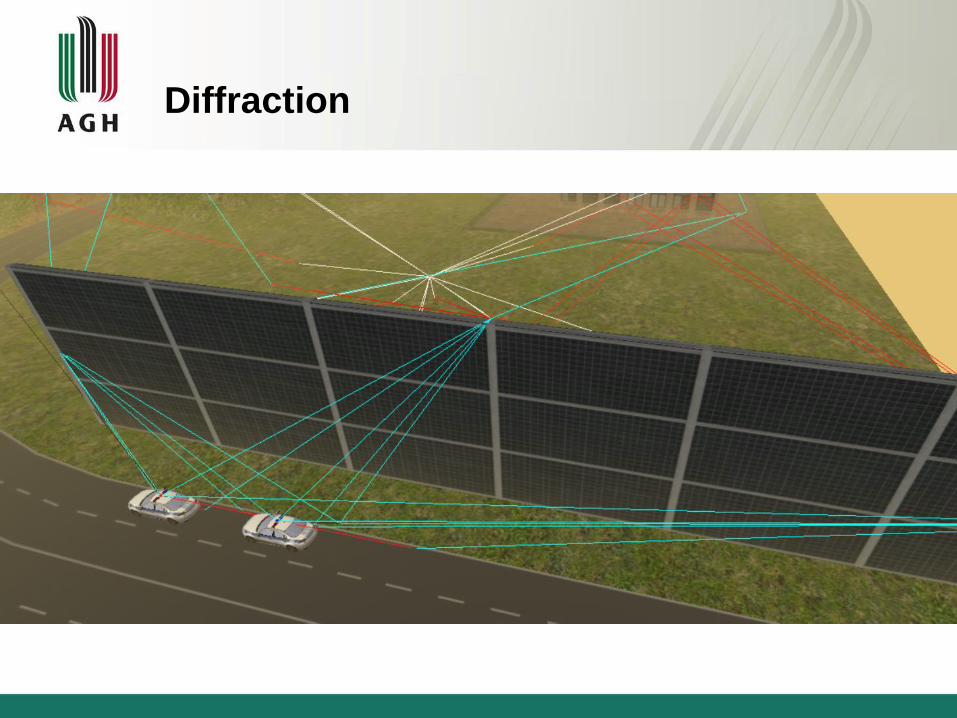
Diffraction
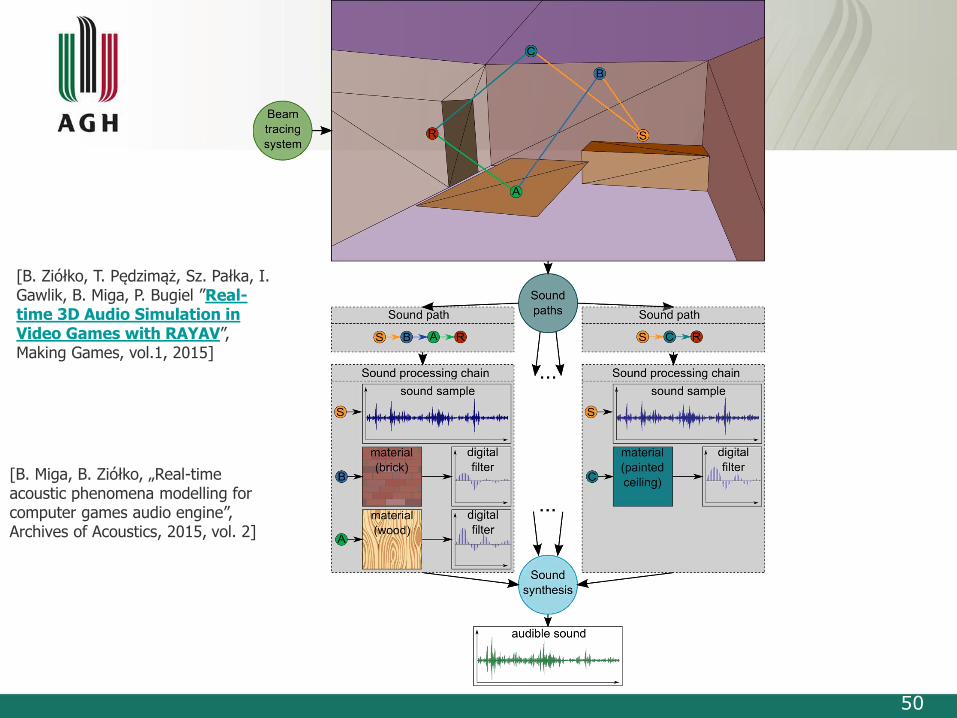
50
[B. Ziółko, T. Pędzimąż, Sz. Pałka, I. Gawlik, B. Miga, P. Bugiel ”Real-time 3D Audio Simulation in Video Games with RAYAV”, Making Games, vol.1, 2015]
[B. Miga, B. Ziółko, „Real-timeacoustic phenomena modelling for computer games audio engine”, Archives of Acoustics, 2015, vol. 2]
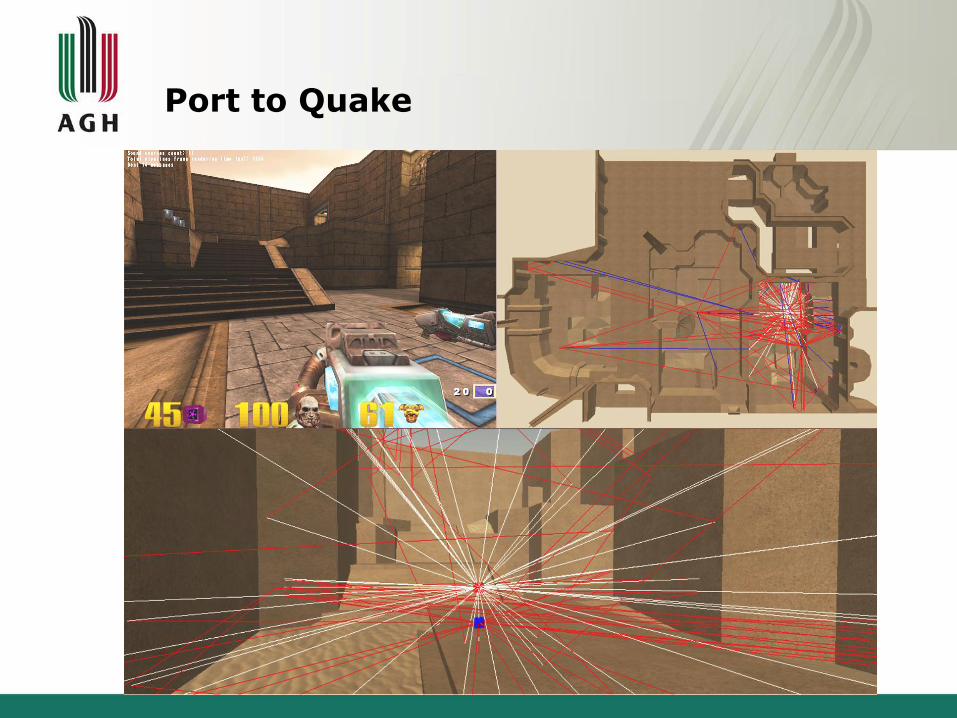
Port to Quake

Wave-based Room Acoustic Simulations
• Applications: – Acoustic prediction for architectural design
– Auralization of virtual rooms
• Most accurate sound field modelling methods (outperform geometrical methods)
• Computational cost very high but real-time capability on GPGPUs
www.agh.edu.pl
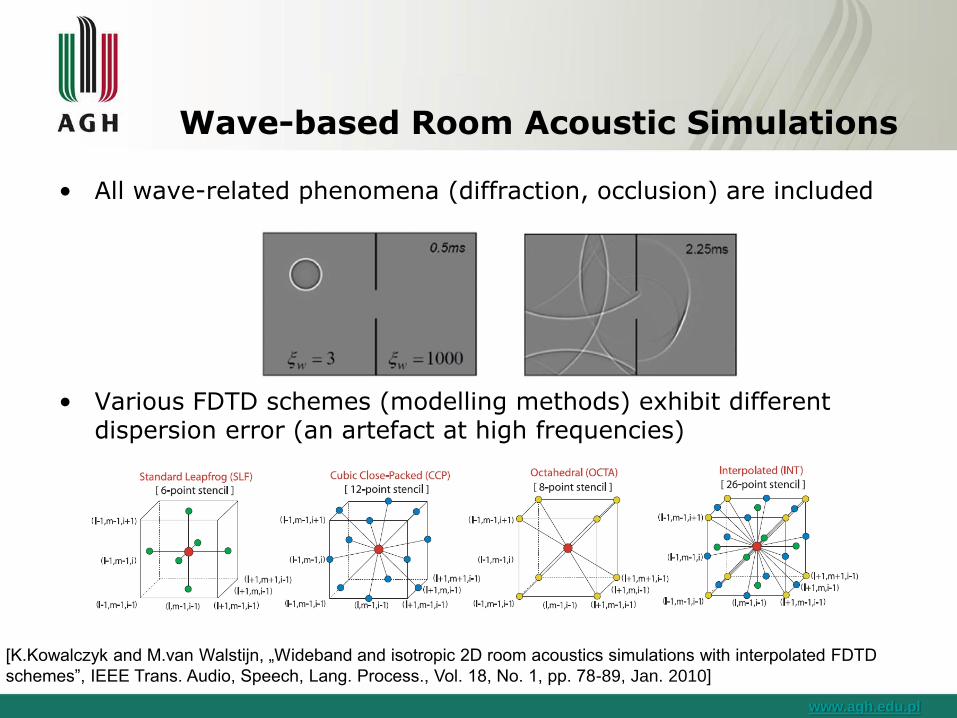
Wave-based Room Acoustic Simulations
• All wave-related phenomena (diffraction, occlusion) are included
• Various FDTD schemes (modelling methods) exhibit differentdispersion error (an artefact at high frequencies)
www.agh.edu.pl
[K.Kowalczyk and M.van Walstijn, „Wideband and isotropic 2D room acoustics simulations with interpolated FDTD
schemes”, IEEE Trans. Audio, Speech, Lang. Process., Vol. 18, No. 1, pp. 78-89, Jan. 2010]

56
Speech enhancement

5757
Microphone array
m1
m2
m3
m4

58
Microphone arrays
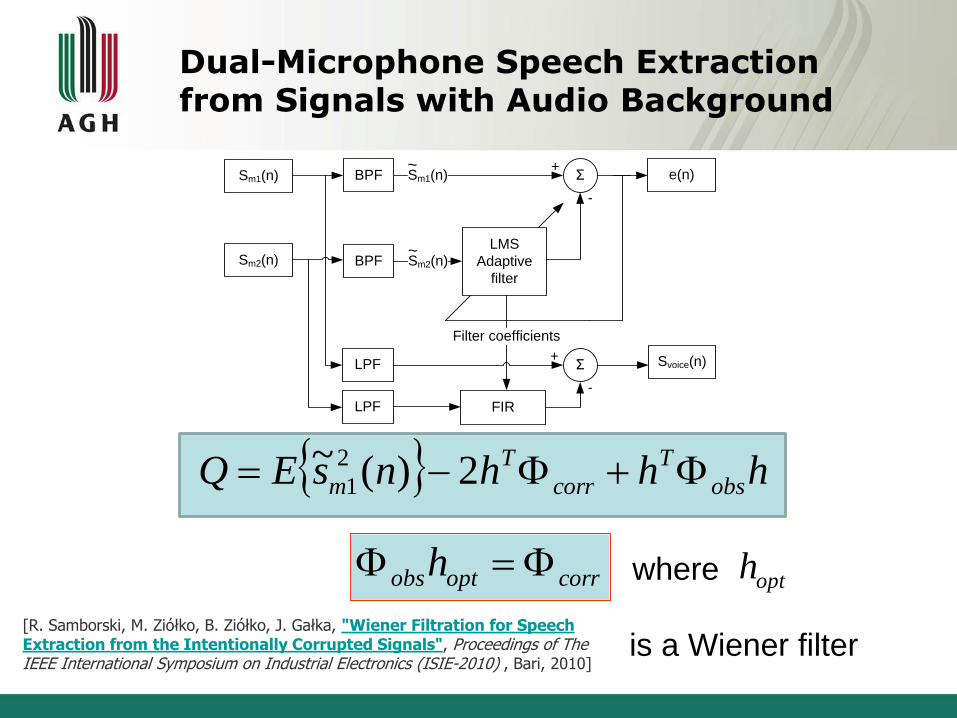
hhhnsEQ obs
T
corr
T
m 2)(~2
1
corroptobsh opth
is a Wiener filter
where
Sm2(n)
Sm1(n)
LMS
Adaptive
filter
ΣSm1(n)
-
+BPF
BPF Sm2(n)
e(n)~
~
Σ
-
+
FIR
Filter coefficients
Svoice(n)LPF
LPF
Dual-Microphone Speech Extraction from Signals with Audio Background
[R. Samborski, M. Ziółko, B. Ziółko, J. Gałka, "Wiener Filtration for Speech Extraction from the Intentionally Corrupted Signals", Proceedings of The IEEE International Symposium on Industrial Electronics (ISIE-2010) , Bari, 2010]
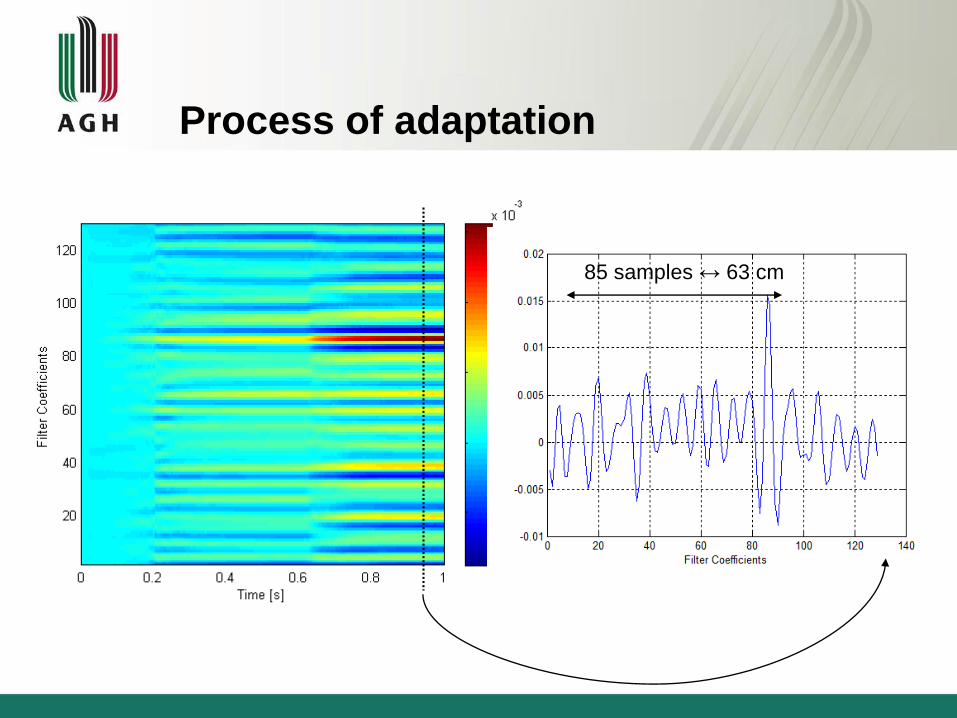
85 samples ↔ 63 cm
Process of adaptation

Virtual Microphones for Speech Enhancement
• Applications: Modern hands-free communication (e.g. teleconference systems)
• Aim: Capture signal of a desired (distant) speaker, while suppressing interfering speaker signals and noise
• When: Positioning of the physical microphones near the desired speaker is challenging
www.agh.edu.pl

Virtual Microphones for Speech Enhancement
• Goal: Synthesize a Virtual Microphone (VM) signal at anarbitrary position, which sounds perceptually similar to the signal that would be recorded by a real microphone located in the same position
• Applied methods: Parametric signal processing based on the signals recorded using 2 distant microphone arrays
www.agh.edu.pl
[K.Kowalczyk et al., „Parametric Spatial Sound Processing”, IEEE Signal Process. Magazine, Special
Issue on Assisted Listening, pp. 31-42, Vol. 32, Nr. 2, Mar. 2015]
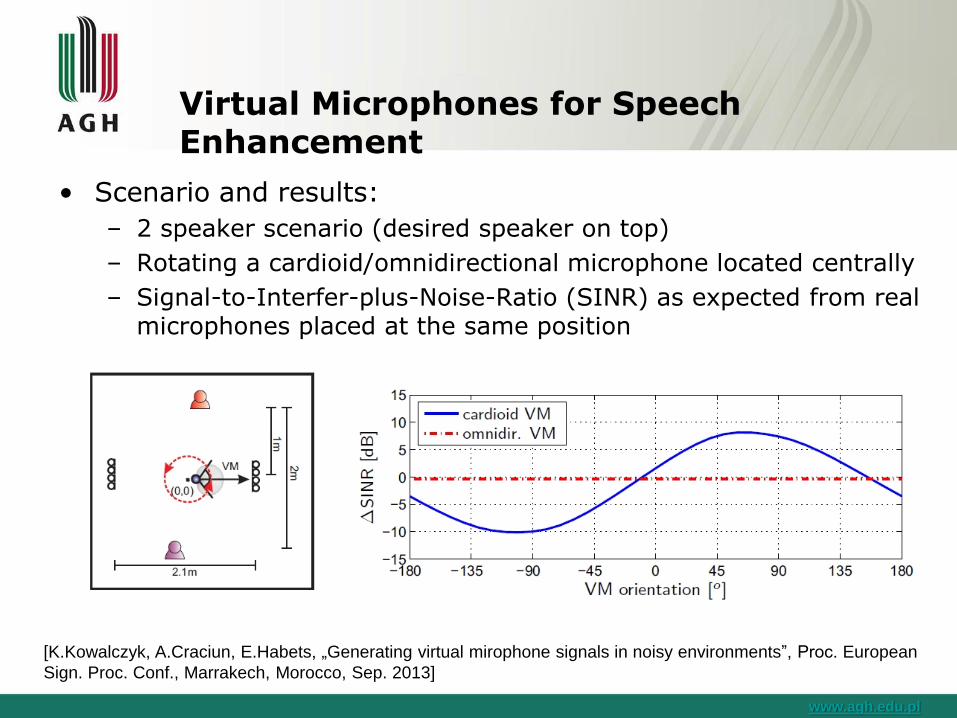
Virtual Microphones for Speech Enhancement
• Scenario and results:
– 2 speaker scenario (desired speaker on top)
– Rotating a cardioid/omnidirectional microphone located centrally
– Signal-to-Interfer-plus-Noise-Ratio (SINR) as expected from real microphones placed at the same position
www.agh.edu.pl
[K.Kowalczyk, A.Craciun, E.Habets, „Generating virtual mirophone signals in noisy environments”, Proc. European
Sign. Proc. Conf., Marrakech, Morocco, Sep. 2013]

Speech vs. music discrimination
There is energy modulation in speech signal with frequency
around 4 Hz. It is a result of average length of a syllable - 250 ms.
[S. Kacprzak, M. Ziółko ”Speech/Music Discrimination via Energy Density Analysis”, SLSP, Tarragona, 2013]
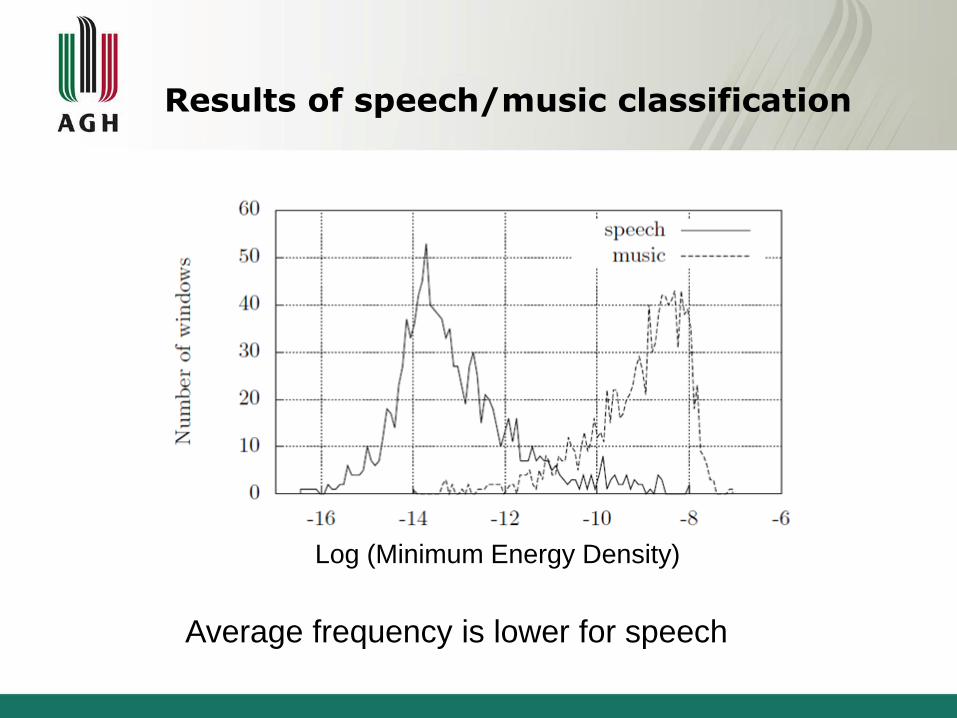
Results of speech/music classification
Average frequency is lower for speech
Log (Minimum Energy Density)

XXIII PVC will be held in Santa Clara, California

Medals and Prizes

70
Our partners















![Acoustic and psychoacoustic aspects of vocal · PDF fileSTL-QPSR 2-31] 994 Acoustic and psychoacoustic aspects of vocal vibrato Johan sundberg Abstract This article reviews research](https://static.fdocuments.in/doc/165x107/5a9e0aef7f8b9a29228ccf45/acoustic-and-psychoacoustic-aspects-of-vocal-2-31-994-acoustic-and-psychoacoustic.jpg)


