Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE...
41
Software implementation of pairings Diego de Freitas Aranha September 21, 2011 Department of Computer Science University of Bras´ ılia Joint work with K. Karabina, P. Longa, C. Gebotys, J. L´ opez, D. Hankerson, A. Menezes, E. Knapp, F. Rodr´ ıguez-Henr´ ıquez, L. Fuentes-Casta˜ neda, J.-L. Beuchat, J. Detrey, N. Estibals. Diego F. Aranha Software implementation of pairings
Transcript of Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE...
![Page 1: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/1.jpg)
Software implementation of pairings
Diego de Freitas Aranha
September 21, 2011
Department of Computer ScienceUniversity of Brasılia
Joint work withK. Karabina, P. Longa, C. Gebotys, J. Lopez, D. Hankerson,
A. Menezes, E. Knapp, F. Rodrıguez-Henrıquez,L. Fuentes-Castaneda, J.-L. Beuchat, J. Detrey, N. Estibals.
Diego F. Aranha Software implementation of pairings
![Page 2: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/2.jpg)
Introduction
Pairing-Based Cryptography enables many elegant solutions tocryptographic problems:
Identity-based encryption
Short signatures
Non-interactive authenticated key agreement
Pairing computation is the most expensive operation in PBC.
Important: Make it faster!
Diego F. Aranha Software implementation of pairings
![Page 3: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/3.jpg)
Objective
Explore new ways to accelerate serial and parallel implementationsof cryptographic pairings:
Maximize throughput
Minimize latency
Applications: servers, real-time services.
Contributions
Lazy reduction in extension fields
Elimination of penalty for negative parameterizations
Compressed cyclotomic squarings
Parallelization of Miller’s Algorithm
Delayed squarings and new formulations
Notes on high security levels and current state-of-the-art
Diego F. Aranha Software implementation of pairings
![Page 4: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/4.jpg)
Bilinear pairings
Let G1 = 〈P〉 and G2 = 〈Q〉 be additive groups and GT be amultiplicative group such that |G1| = |G2| = |GT | = prime n.
An efficiently-computable map e : G1 ×G2 → GT is anadmissible bilinear map if the following properties are satisfied:
1 Bilinearity: given (V , W ) ∈ G1 ×G2 and (a, b) ∈ Z∗q:
e(aV , bW ) = e(V ,W )ab = e(abV ,W ) = e(V , abW ).
2 Non-degeneracy: e(P,Q) 6= 1GT, where 1GT
is the identity ofthe group GT .
Diego F. Aranha Software implementation of pairings
![Page 5: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/5.jpg)
Bilinear pairings
Diego F. Aranha Software implementation of pairings
![Page 6: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/6.jpg)
Bilinear pairings
If G1 = G2, the pairing is symmetric.
Diego F. Aranha Software implementation of pairings
![Page 7: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/7.jpg)
Barreto-Naehrig curves
Let u be an integer such that p and n below are prime:
p = 36u4 + 36u3 + 24u2 + 6u + 1
n = 36u4 + 36u3 + 18u2 + 6u + 1
Then E : y2 = x3 + b, b ∈ Fp is a curve of order n andembedding degree k = 12.
Example: u = −(262 + 255 + 1), b = 2 (implementation-friendly).
Diego F. Aranha Software implementation of pairings
![Page 8: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/8.jpg)
Pairing computation
The pairing er (P,Q) is defined by the evaluation of fr ,P at adivisor related to Q.
[Miller 1986] constructed fr ,P in stages combining Millerfunctions evaluated at divisors.
Diego F. Aranha Software implementation of pairings
![Page 9: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/9.jpg)
Pairing computation
Let lU,V be the line equation through points U,V ∈ E (Fqk ) andvU the shorthand for lU,−U .
For any integers a and b, we have:
1 fa+b,P(D) = fa,P(D) · fb,P(D) ·laP,bP(D)
v(a+b)P(D);
2 f2a,P(D) = fa,P(D)2 · laP,aP(D)v2aP(D) ;
3 fa+1,P(D) = fa,P(D) · l(a)P,P(D)v(a+1)P(D)
.
[Barreto et al. 2002] showed how to evaluate fr ,P at Q using thefinal exponentiation in the Tate pairing.
Diego F. Aranha Software implementation of pairings
![Page 10: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/10.jpg)
Pairing computation
Algorithm 1 Miller’s Algorithm.
Input: r =∑log2 r
i=0 ri2i ,P,Q.
Output: er (P,Q).
1: T ← P2: f ← 13: for i = blog2(r)c − 1 downto 0 do4: f ← f 2 · lT ,T (Q)5: T ← 2T6: if ri = 1 then7: f ← f · lT ,P(Q)8: T ← T + P9: end if
10: end for11: return f (q
k−1)/n
Diego F. Aranha Software implementation of pairings
![Page 11: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/11.jpg)
Asymmetric pairing
aopt : G2 ×G1 → GT
(Q,P) → (fr ,Q(P) · lrQ,πp(Q)(P) · lrQ+πp(Q),−π2p(Q)(P))
p12−1n
with r = 6u + 2,G1 = E (Fp),G2 = E ′(Fp2)[n].
The towering is:
Fp2 = Fp[i ]/(i2 − β), where β = −1.
Fp4 = Fp2 [s]/(s2 − ξ), where ξ = 1 + i .
Fp6 = Fp2 [v ]/(v3 − ξ), where ξ = 1 + i .
Fp12 = Fp4 [t]/(t3 − s) or Fp6 [w ]/(w2 − v).
Diego F. Aranha Software implementation of pairings
![Page 12: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/12.jpg)
Generalized lazy reduction
Intuitively, it is a trade-off between addition and modular reduction:
(a · b) mod p + (c · d) mod p = (a · b + c · d) mod p
Observation: Pairings use non-sparse primes for Fp!
Previous state-of-the-art (3M + 2R in Fp2):
a · b = (a0b0 + a1b1β) + [(a0 + a1)(b0 + b1)− a0b0 − a1b1] i ,
For k = 2i3j , total of (3i · 6j)M + (2 · 3i−1 · 6j)R.
Diego F. Aranha Software implementation of pairings
![Page 13: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/13.jpg)
Generalized lazy reduction
Intuitively, it is a trade-off between addition and modular reduction:
(a · b) mod p + (c · d) mod p = (a · b + c · d) mod p
Observation: Pairings use non-sparse primes for Fp!
Previous state-of-the-art (3M + 2R in Fp2):
a · b = (a0b0 + a1b1β) + [(a0 + a1)(b0 + b1)− a0b0 − a1b1] i ,
For k = 2i3j , total of (3i · 6j)M + (2 · 3i−1 · 6j)R.
Diego F. Aranha Software implementation of pairings
![Page 14: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/14.jpg)
Generalized lazy reduction
Idea: Suppose Fp2 is a higher extension and apply recursively!
Any component c of an element in Fpk is ultimately computed asc =
∑±aibj mod p, requiring a single reduction.
New state-of-the-art: total of (3i · 6j)M + kR.
Remark 1: Montgomery bounds should be maintained forintermediate results. Choose |p| acoordingly.
Remark 2: Same idea applies to arithmetic in E ′(Fp2).
Example: Multiplication in Fp12 goes from 54M + 36R to54M + 12R. In total, 40% of reductions are saved.
Diego F. Aranha Software implementation of pairings
![Page 15: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/15.jpg)
Generalized lazy reduction
Idea: Suppose Fp2 is a higher extension and apply recursively!
Any component c of an element in Fpk is ultimately computed asc =
∑±aibj mod p, requiring a single reduction.
New state-of-the-art: total of (3i · 6j)M + kR.
Remark 1: Montgomery bounds should be maintained forintermediate results. Choose |p| acoordingly.
Remark 2: Same idea applies to arithmetic in E ′(Fp2).
Example: Multiplication in Fp12 goes from 54M + 36R to54M + 12R. In total, 40% of reductions are saved.
Diego F. Aranha Software implementation of pairings
![Page 16: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/16.jpg)
Removing the inversion penalty
Consider (p12 − 1)/n = (p6 − 1)(p2 + 1)(p4 − p2 + 1)/n.
The hard part is (p4 − p2 + 1)/n which requires 3 |u|-th powers.
If u < 0, from pairing definition:
aopt(Q,P) =[f|r |,Q(P)−1 · h
] p12−1n .
By distributing the power (p12 − 1)/n, we can compute instead:
aopt(Q,P) =[f|r |,Q(P)p
6 · h] p12−1
n.
Diego F. Aranha Software implementation of pairings
![Page 17: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/17.jpg)
Revised pairing computation
Algorithm 2 Miller’s Algorithm for general r , even k .
Input: r =∑log2 r
i=0 ri2i ,P,Q.
Output: er (P,Q).
1: T ← P2: f ← 13: for i = blog2(r)c − 1 downto 0 do4: f ← f 2 · lT ,T (Q)5: T ← 2T6: if ri = 1 then7: f ← f · lT ,P(Q)8: T ← T + P9: end if
10: end for11: if u < 0 then T ← −T , f ← f q
k/2
12: return f (qk−1)/n
Diego F. Aranha Software implementation of pairings
![Page 18: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/18.jpg)
Compressed cyclotomic squarings
Consider Fp12 = Fp4 [t]/(t3 − s).
Let g =∑2
i=0 (g2i + g2i+1s)t i ∈ Gφ6(Fp2) and
g2 =∑2
i=0 (h2i + h2i+1s)t i with gi , hi ∈ Fp2 .
Given C (g) = [g2, g3, g4, g5], it is efficient to computeC (g2) = [h2, h3, h4, h5] .
Important: Decompression map D requires one inversion in Fp2 .
Diego F. Aranha Software implementation of pairings
![Page 19: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/19.jpg)
Compressed cyclotomic squarings
Recall that |u| = 262 + 255 + 1.
Idea: g |u| can now be computed in three steps:
1 Compute C(g2i ) for 1 ≤ i ≤ 62 and store C(g255) and C(g262)
2 Compute D(C(g255)) = g255 and D(C(g262)) = g262
3 Compute g |u| = g262 · g255 · g
Remark: Montgomery’s simultaneous inversion allowssimultaneous decompression.
Example: Computing a |u|-th power is now 30% faster.
Diego F. Aranha Software implementation of pairings
![Page 20: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/20.jpg)
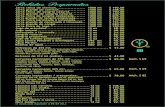
Implementation results
Table: Operation counts for different implementations of the Optimal Atepairing at the 128-bit security level.
Work Phase Operations in Fp
Beuchat et al. 2010ML 6992M + 5040RFE 4647M + 4244R
ML+FE 11639M + 9284R
Aranha et al. 2011ML 6504M + 2736RFE 3648M + 1926R
ML+FE 10152M + 4662R
[Pereira et al. 2011] has a slightly faster operation count, butwhich produces a slower implementation in the target platform.
Diego F. Aranha Software implementation of pairings
![Page 21: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/21.jpg)
Implementation results
Table: Timings in cycles for the asymmetric setting on 64-bit processors.
Beuchat et al. 2010Operation Phenom II Core i7 Opteron Core 2 Duo
Mult in Fp2 440 435 443 590Squaring in Fp2 353 342 355 479Miller Loop 1,338,000 1,330,000 1,360,000 1,781,000Final Exp. 1,020,000 1,000,000 1,040,000 1,370,000Pairing 2,358,000 2,330,000 2,400,000 3,151,000
Aranha et al. 2011Operation Phenom II Core i5 Opteron Core 2 Duo
Mult in Fp2 368 412 390 560Squaring in Fp2 288 328 295 451Miller Loop 898,000 978,000 988,000 1,275,000Final Exp. 664,000 710,000 722,000 919,000Pairing 1,562,000 1,688,000 1,710,000 2,194,000
Improvement 34% 28% 29% 30%
Important: Latency of around 0.5 milisec in a 3GHz Phenom II X4.Diego F. Aranha Software implementation of pairings
![Page 22: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/22.jpg)
Parallelization
Property of Miller functions
fa·b,P(D) = f b,P(D)a · f a,bP(D)
We can write r = 2w r1 + r0 and compute fr ,P(D):
fr ,P(D) = f2w r1+r0,P(D)
= f r1,P(D)2w · f 2w ,r1P(D) · f r0,P(D) ·
l(2w r1)P,r0P(D)
vrP(D).
If r has low Hamming weight, w can be chosen so that r0 is small.
For many processors, we can:
Apply the formula recursively
Write r as r = 2wi ri + · · ·+ 2w2r2 + 2w1r1 + r0
If P is fixed (private key), riP can also be precomputed.
Diego F. Aranha Software implementation of pairings
![Page 23: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/23.jpg)
Parallelization
Property of Miller functions
fa·b,P(D) = f b,P(D)a · f a,bP(D)
We can write r = 2w r1 + r0 and compute fr ,P(D):
fr ,P(D) = f2w r1+r0,P(D)
= f r1,P(D)2w · f 2w ,r1P(D) · f r0,P(D) ·
l(2w r1)P,r0P(D)
vrP(D).
If r has low Hamming weight, w can be chosen so that r0 is small.
For many processors, we can:
Apply the formula recursively
Write r as r = 2wi ri + · · ·+ 2w2r2 + 2w1r1 + r0
If P is fixed (private key), riP can also be precomputed.
Diego F. Aranha Software implementation of pairings
![Page 24: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/24.jpg)
Parallelization
Property of Miller functions
fa·b,P(D) = f b,P(D)a · f a,bP(D)
We can write r = 2w r1 + r0 and compute fr ,P(D):
fr ,P(D) = f2w r1+r0,P(D)
= f r1,P(D)2w · f 2w ,r1P(D) · f r0,P(D) ·
l(2w r1)P,r0P(D)
vrP(D).
If r has low Hamming weight, w can be chosen so that r0 is small.
For many processors, we can:
Apply the formula recursively
Write r as r = 2wi ri + · · ·+ 2w2r2 + 2w1r1 + r0
If P is fixed (private key), riP can also be precomputed.
Diego F. Aranha Software implementation of pairings
![Page 25: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/25.jpg)
Load balancing
Problem: We must determine an optimal partition wi .
Let c1(1) be the cost of a serial loop and cπ(i) be the cost of aparallel loop for processor 1 ≤ i ≤ π.
We can count the operations executed by each processor and solvethe system cπ(1) = cπ(i) to obtain wi . The speedup is:
s(π) = c1(1)+expcπ(1)+par+exp ,
where par is the cost of parallelization and exp is the cost of thefinal exponentiation.
Diego F. Aranha Software implementation of pairings
![Page 26: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/26.jpg)
Load balancing
Problem: We must determine an optimal partition wi .
Let c1(1) be the cost of a serial loop and cπ(i) be the cost of aparallel loop for processor 1 ≤ i ≤ π.
We can count the operations executed by each processor and solvethe system cπ(1) = cπ(i) to obtain wi . The speedup is:
s(π) = c1(1)+expcπ(1)+par+exp ,
where par is the cost of parallelization and exp is the cost of thefinal exponentiation.
Diego F. Aranha Software implementation of pairings
![Page 27: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/27.jpg)
Symmetric pairing
A pairing-friendly supersingular binary elliptic curve is the setof solutions (x , y) ∈ F2m × F2m satisfying the equation
y2 + y = x3 + x + b,
where b ∈ {0, 1}, and a point at infinity ∞.
Diego F. Aranha Software implementation of pairings
![Page 28: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/28.jpg)
Symmetric pairing
Choosing T = 2m − N and a prime n dividing N,[Barreto et al. 2004] defined the reduced ηT pairing:
ηT : E (F2m)[n]× E (F2m)[n]→ F∗24m
ηT (P,Q) = fT ′,P′(ψ(Q))24m−1
N ,
where T ′ = ±T and P ′ = ±P.
The function f is a Miller function and ψ is the distortion mapψ(x , y) = (x2 + s, y + sx + t).
Diego F. Aranha Software implementation of pairings
![Page 29: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/29.jpg)
Implementation results
For the asymmetric setting, estimated speedup of only 10%.
For the symmetric setting:
0
2
4
6
8
10
12
14
10 20 30 40 50 60
Speedup
Number of processors
Beuchat et al. 2009Aranha et al. 2010
Diego F. Aranha Software implementation of pairings
![Page 30: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/30.jpg)
Implementation results
Figure: Timings in the symmetric setting taken on an Intel Core 2 45nm.
0
5
10
15
20
25
30
Late
ncy
(m
illio
ns
of
cycl
es)
1 2 4 8Number of threads
Beuchat et al. 2009
23.03
13.14
9.08 8.93
Aranha et al. 2010
17.40
9.34
5.083.02
Diego F. Aranha Software implementation of pairings
![Page 31: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/31.jpg)
Implementation results
New parallelization:
No significant storage costs and almost-linear scalability
Latency improvement of 28%, 44% and 66% in 2, 4, 8processors
Limitations in the asymmetric setting:
Serial final exponentiation
Expensive point doublings
Expensive extension field squarings
Diego F. Aranha Software implementation of pairings
![Page 32: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/32.jpg)
Delayed squaring
Idea: Delay the squarings until we reach the cyclotomic subgroup!
Recall the parallelization (M = qk−1r ):
fr ,P(D)M =(f r1,P(D)M
)2w · f 2w ,r1P(D)M ·
(fr0,P(D) ·
l(2w r1)P,r0P(D)
vrP(D)
)M .
Remark: Delayed squarings increase speedup to 18-20%.
Diego F. Aranha Software implementation of pairings
![Page 33: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/33.jpg)
Parallel pairing derivations
Hess’ instantiation (α-Weil)
α(P,Q) =
f2u+1,P(Q)
f2u+1,Q(P)
(fu,(6u+2)P(Q)f u6u+2,P(Q)
fu,(6u+2)Q(P)f u6u+2,Q(P)
)p2(p6−1)(p2+1)
Critical path:
((f uu,(6u+2)Q(P)
)p2)(p6−1)(p2+1)
Diego F. Aranha Software implementation of pairings
![Page 34: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/34.jpg)
Parallel pairing derivations
New instantiation (β-Weil)
β(P,Q) =
((fp,h,P(Q)
fp,h,Q(P)
)p fp,h,pP(Q)
fp,h,Q(pP)
)(p6−1)(p2+1)
Critical path: pP, (fp,h,Q(pP))(p6−1)(p2+1)
Optimization:
pP = 2u(p2 − 2)P + p2P − P = 2u(φ(P)− 2P) + φ(P)− P.
Diego F. Aranha Software implementation of pairings
![Page 35: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/35.jpg)
Implementation results
0
0.5
1
1.5
2
1 2 3 4 5 6 7 8
Sp
eed
up
Number of processors
Optimal ateOptimal ate with delayed squaring
α-Weil pairingβ-Weil pairing
Best results until now:
Optimal ate pairing reaches speedup of 1.45 with 4 processors
β-Weil pairing reaches speedup of 1.86 with 8 processors
Diego F. Aranha Software implementation of pairings
![Page 36: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/36.jpg)
Curve choice at higher security levels
Important: Pairing security is defined by the hardness of the DLPin G1,G2,GT .
Barreto-Naehrig curves are optimal at the 128-bit level
Security usually scaled by increasing embedding degree
Kachisa-Scott-Schaefer curves with k = 18 have been pointedas the best family known for the 192-bit level
What about other families?
Diego F. Aranha Software implementation of pairings
![Page 37: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/37.jpg)
Curve choice at higher security levels
Table: Operation counts for the Optimal Ate pairing at the 192-bitsecurity level. M is the cost of multiplying two 512-bit integers in a64-bit machine.
Family Phase Operations in Fp
BLS (k = 24, |p| = 478)ML 14990MFE 25785M
ML+FE 40775M
BN (k = 12, |p| = 638)ML 26084MFE 11284M
ML+FE 37368M
KSS (k = 18, |p| = 512)ML 13817MFE 23022M
ML+FE 36839M
BW (k = 12, |p| = 638)ML 16823MFE 12647M
ML+FE 29470M
Diego F. Aranha Software implementation of pairings
![Page 38: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/38.jpg)
State-of-the-art
Table: Timings in 103 cycles on an Intel Core i7 Sandy Bridge 32nm atthe 128-bit security level using the fastest multipliers available.
Number of threadsAsymmetric pairing 1 2 4 8Optimal ate 1562 1287 1137 1107
Improved optimal ate – 1260 1080 1056
α-Weil – – 1272 936
β-Weil – – 1104 840
Symmetric pairing 1 2 4 8Genus-1 ηT 6455 3370 1794 1034
Genus-2 Optimal η – general 8265 – – –
Genus-2 Optimal η – degenerate 2358 – – –
Diego F. Aranha Software implementation of pairings
![Page 39: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/39.jpg)
Conclusions and future
New techniques for implementing pairings:
Speed records for pairing computation in software (hardware)
Dependency on architectural features
Scalable parallelization
New pairing derivations
Emphasis on implementation of protocols:
Pairing type and optimizations differ greatly
Higher security levels should be more interesting
Diego F. Aranha Software implementation of pairings
![Page 40: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/40.jpg)
RELIC cryptographic library:http://code.google.com/p/relic-toolkit/
Thank you for your attention!Any questions?
Diego F. Aranha Software implementation of pairings
![Page 41: Diego de Freitas Aranhaecc2011.loria.fr/slides/aranha.pdfAranha et al. 2011 ML 6504M + 2736R FE 3648M + 1926R ML+FE 10152M + 4662R [Pereira et al. 2011] has a slightly faster operation](https://reader036.fdocuments.in/reader036/viewer/2022071218/605350b123f89865576bc19a/html5/thumbnails/41.jpg)
References
D. F. Aranha, J. Lopez, D. Hankerson. High-speed parallelsoftware implementation of ηT pairing. CT-RSA 2010,89–105.
D. F. Aranha, J.-L. Beuchat, J. Detrey, N. Estibals. OptimalEta Pairing on Supersingular Genus-2 Binary HyperellipticCurves. Cryptology ePrint Archive, Report 2010/559.
D. F. Aranha, K. Karabina, P. Longa, C. Gebotys, J. Lopez.Faster Explicit Formulas for Computing Pairings over OrdinaryCurves. EUROCRYPT 2011, 48–68.
D. F. Aranha, E. Knapp, A. Menezes,F. Rodrıguez-Henrıquez. Parallelizing the Weil and TatePairings. IMA-CC 2011, To appear.
Diego F. Aranha Software implementation of pairings