
DEVELOPMENT OF ITERATIVE TECHNIQUES FOR THE SOLUTION ... · DEVELOPMENT OF ITERATIVE TECHNIQUES FOR...
14
NASA-CR-196657 DEVELOPMENT OF ITERATIVE TECHNIQUES FOR THE SOLUTION OF UNSTEADY COMPRESSIBLE VISCOUS FLOWS Grant NAG-l-1217 Supplement 2 Final Report Submitted to / _,,'__ ,,_ /__J NASA Langley Research Center Hampton, VA 23665 Attn: Dr. Woodrow Whitlow Chief, Unsteady Aerodynamics Branch Prepared by Lakshmi N. Sankar and Duane Hixon School of Aerospace Engineering Georgia Institute of Technology, Atlanta, GA 30332 November 1993 (_.;_ A-C_-194o57) jEVELOPMENT OF IT!_IATIV;_ TECN'_I,_UES FJR TH{ 5,2LI..'TIUH .PF U_!STLADY COMPRESSIoLE VI.,CdUS FI.LJVJS Final Report (Georr;i a Inst. of Tech.) 14 p N94-17129 Unclas G3/34 0193073 https://ntrs.nasa.gov/search.jsp?R=19940012656 2018-08-22T04:05:33+00:00Z
Transcript of DEVELOPMENT OF ITERATIVE TECHNIQUES FOR THE SOLUTION ... · DEVELOPMENT OF ITERATIVE TECHNIQUES FOR...

NASA-CR-196657
DEVELOPMENT OF ITERATIVE TECHNIQUES FOR THE SOLUTION
OF
UNSTEADY COMPRESSIBLE VISCOUS FLOWS
Grant NAG-l-1217
Supplement 2
Final Report
Submitted to
/ _,,'__ ,,_ /__J
NASA Langley Research Center
Hampton, VA 23665
Attn: Dr. Woodrow Whitlow
Chief, Unsteady Aerodynamics Branch
Prepared by
Lakshmi N. Sankar and Duane Hixon
School of Aerospace Engineering
Georgia Institute of Technology, Atlanta, GA 30332
November 1993
(_.;_ A-C_-194o57) jEVELOPMENT OF
IT!_IATIV;_ TECN'_I,_UES FJR TH{
5,2LI..'TIUH .PF U_!STLADY COMPRESSIoLE
VI.,CdUS FI.LJVJS Final Report
(Georr;i a Inst. of Tech.) 14 p
N94-17129
Unclas
G3/34 0193073
https://ntrs.nasa.gov/search.jsp?R=19940012656 2018-08-22T04:05:33+00:00Z

SUMMARY
The work done under this project was documented in detail as the Ph.D.
dissertation of Dr. Duane Hixon. It may be recalled that the objectives of the
research project were:
1) Evaluation of the Generalized Minimum Residual method (GMRES) as a
tool for accelerating 2-D and 3-D unsteady flows, and
2) Evaluation of the suitability of the GMRES algorithm for unsteady flows,
computed on parallel computer architectures.
Both these objectives were met.
In addition to the Ph.D. dissertation of Mr. Duane Hixon, the following
three AIAA papers were pulished, under the present work. Two of these papers
also appeared as journal articles.
1. Hixon, R. and Sankar, L. N., " Application of a Generalized Minimum
Residual Method to 2-D Unsteady Flows," AIAA Paper 92-0422; also, AIAA
Journal, Volume 31, No. 10, October 1993, pp 1955-1957.
2. Hixon, R., Tsung, Fu-Lin and Sankar, L. N., "A Comparison of Two
methods for Solving 3-D Unsteady Compressible Viscous Flows," AIAA paper 93-
0537, to appear in AIAA Journal, 1994.
3. Hixon, R. and Sankar, L. N., "Unsteady Compressible Two-Dimensional
Calculations on a MIMD Parallel Supercomputer," AIAA paper 94-0757.
The first two publications as well as a detailed, final report were previously
mailed to the sponsor. The AIAA paper 94-0757 is enclosed here, as an
appendix.

APPENDIX

AIAA 94-0757
Unsteady Compressible 2-D FlowCalculations on aMIMD Parallel Supercomputer
Duane Hixon and Lakshmi N. SankarSchool of Aerospace EngineeringGeorgia Institute of TechnologyAtlanta, GA 30332
32nd Aerospace SciencesMeeting & Exhibit
January 10-13, 1994 / Reno, NV
For permission to copy or republish, contact the Amedcan Institute of Aeronautics and Astronautics370 L'Enfant Promenade, S.W., Washington, D.C. 20024

Unsteady Compressible 2-D Flow Calculations on a MIMD ParallelSupercomputer
Duane Hixon" and Lakshmi N. Sankar"°School of Aerospace Engineering
Georgia Institute of TechnologyAtlanta, GA 30332
ABSTRACT
An existing sequential 2-D Altemating Direction Implicit(ADI) unsteady compressible viscous flow solver hasbeen modified to run on an Intel iPSC/860 parallelsupercomputer. Techniques for implementation ofboundary conditions, and the inversion of the implicitmatrix equations are discussed. A Generalized MinimalResidual method is added to the parallel algorithm andtested. Results are presented for steady viscous flowpast a NACA 0012 airfoil at 13.4 degree angle ofattack, and for a NACA 64-A010 airfoil performing asinusoidal plunging motion under transonic flightconditions. It concluded that implicit time marchingalgorithms may be efficiently implemented on parallelmessage passing architectures.
INTRODUCTION
During the past two decades, there has beensignificant progress in numerical simulation ofunsteady compressible viscous flows. At present, avariety of solution techniques exist such as thetransonic small disturbance analyses (TSD) 1,2,3transonic full potential equation based methods 40s,e,unsteady Euier solvers7,e,and unsteady Navier-Stokessolvers °,1°,11,12. This progress has been driven bydevelopments in three areas: (1) Improved numericalalgorithms, (2) Automation of body-fitted gridgeneration schemes, and (3) Advanced computerarchitectures with vector processing and parallelprocessing features.
Despite these advances, numerical simulation ofunsteady viscous flows still remains a computationallyintensive problem even in two dimensions. For
* Postdoctoral Researcher, Presently at NASA LewisResearch Center, Member AIAA.
" Professor, School of Aerospace Engineering.Senior Member AIAA.
Copyright © 1993 by Ray Hixon and L.N. Sankar.Published by the American Institute of Aeronauticsand Astronautics, Inc. with permission.
example, unsteady 3-D Navier-Stokes simulations of ahelicopter rotor blade in forward flight may require over30,000 time steps for a full revolution of the rotor1°. Inother unsteady flows, such as the high angle of attackflow past fighter configurations, a systematic parametricstudy of the flow is currently not practical due to thevery large CPU time necessary for such simulations13Thus, it is clear that significant improvements to theexisting algorithms, and dramatic improvements incomputer architectures, will be needed beforeunsteady two and three dimensional viscous flowanalyses become practical day-to-day engineeringtools.
One numerical scheme that has been of recentinterest is the Generalized Minimal RESidual (GMRES)method originally proposed by Saad and Schultz_4.This procedure uses a conjugate gradient method toaccelerate the convergence of existing flow solvers.GMRES was added to existing steady flow solvers byWigton, Yu, and Young Is, and has been used on manydifferent types of solvers ls'21. Saad has also used asimilar Krylov subspace projection method on a steady,incompressible Navier-Stokes problem and anunsteady one-dimensional wave propagationequation The present researchers have successfullyused the GMRES scheme to accelerate 2-D and 3-Dunsteady viscous flow computations on vectorsupercomputers 23.24.
In the area of improved computer architectures,emphasis has shifted towards the use of multipleprocessors. Four different strategies have beenpursued by the computer designers. On the CrayY/MP class of systems, a relatively few sophisticatedCPU units tightly connected to each other are used.On massively parallel computers of the CM-5 class,several thousand (relatively) simple processors tightlyconnected to each other are used. On machines of theIntel iPSC/860 class, a small number of processors (32or more) tightly connected to each other are used.Finally distributed systems, where a collection ofheterogeneous systems connected to each other viastandard Ethemet interface lines are coming of age,and rely on a combination of software (e.g. ParallelVirtual Machine interface) and hardware (faster CPUs,high speed communication links) to achieve increasedthroughput.

Inthiswork,theGMRESschemeis consideredasacandidatefor the accelerationof an iterative timemarching scheme for unsteady 2-D compressible flowcalculations on an Intel iPSCI860 parallel=Jpercomputer. In the past, researchers have ported anumber of steady applications to this machine. In theseapplications, the flow field is divided into a number ofblocks, and each CPU node is tasked with advancingthe flow field by one pseudo-time step. However,porting a true unsteady flow solver to this machineIntroduces new difficulties. For example, the practiceof lagging boundary conditions at the blockboundaries can create serious phase errors inunsteady flow simulations, particularly if largedisturbances such as shock waves and strong vorticesmove across the block boundaries. Most steady flowsolvers use an explicit time marching scheme, and theindividual blocks (and the CPU nodes) are only looselycoupled to each other. In unsteady viscous flows,implicit schemes are commonly used because of theirsuperior stability characteristics. Unfortunately, implicitschemes require a tight coupling between the blocks,and the CPU nodes. Unless an implicit algorithm iscarefully designed, the I/O penalties associated withthe data transfer between the nodes can make animplicit algorithm unsuitable for parallel implementation.
MATHEMATICAL AND NUMERICALFORMULATION
The unsteady, 2-D, compressible ADI code23used inthis study solves the Navier-Stokes equations, given incurvilinear coordinates as:
qt+ E_+ G_ =S_+T;
(1)
with an implicit scheme similar to that of Steger 2s.Here, q is the flow properties vector; E and G containthe information regarding the mass, momentum andenergy fluxes; S and T contain the viscous stress,heat conduction and viscous work effects. Second orfourth order central differences are used for the spatialderivatives, and a first order backward difference isused for the time dedvative.
An tterative ADI scheme is used to numericallyintegrate the Navier-Stokes equations. At each timestep, the following equation is tteratively solved:
[I + _ &_A]n*'.k[I + &'¢_]r"l.k{6¢l} = R
where, R is the residual being driven to zero, given by
R = -&z [(qn+,.k. qn)/At] + _(S- E) + 6_;(T- G)]n+l,k
(2)
and _1 is the change in the flow properties betweens4Jcc_ssive iterations,
Aq . _.1.k.1 . _.l,k
(3)
Also, 'n' refers to the time level, and 'k' to the iterationlevel. The time step is given as At, while &¢ is a localtime step used in the iterative process. The matrices Aand C are the Jacobians of the flux vectors E and G,and are computed using the information at theprevious iteration level 'k'.
Since the left side of Eq. (2) is invertible, this equationmay formally be written as:
qn+l,k.1 = r.(qn.,.k )
(4)
A non-iterative ADI scheme simply means that only oneiteration step is performed at each time level.
Note that the right side of Eq. (2) can be computed bya variety of methods: finite volume, finite element,finite difference, etc. The left side ADI matrix may bereplaced" by an LU form, or even a simple diagonalform. The GMRES formulation does not concern itselfwith such details of the implementation, but insteadtreats the flow solver as a 'black box' used only toevaluate Eq. (4).
Of course, the success of the GMRES solver willdepend on the left side matrix chosen. Implicitformulations such as ADI and LU schemes are knownto perform significantly better than explicit forms2_.
The unsteady GMRES solver attempts to find theqr_,k that will minimize the equation:
M(qn,.-1.k)., qn+l.k.l . qn+l.k = 0
at each time step.
(5)
In a non-iterative ADI scheme, the time step isrestricted to prevent errors introduced by the
2

linearization of the flux terms and the approximatefactorization of the linear matrix operator from affectingthe unsteady solution. Since the GMRES method isbeing used on an iterative time marching scheme, thetime step is now dependent only on the ability of thediscretized equations to follow the physics of the flow.A reduction in CPU time is achieved if the GMRESmethod requires fewer evaluations of the residual R toarrive at a given time level than the non-iterstive ADImethodology to arrive at the same time level.
The GMRES solver works by assuming that the errorvector M(q a+l.k) is spanned by a small set of ortho-normal direction vectors. For two dimensionalcompressible flows, there are a total of (imax x kmax x4) possible orthonormal directions that the correctionvector to the flow variables, _1 may lie in.
The GMRES solver uses the underlying iterative ADIscheme to choose a small set of orthogonal directions(a user input, which is usually less than 20). The slopeof the residual in each direction is numericallycomputed. From this, a least squares problem issolved to minimize the magnitude of the 12 norm of theerror vector M(q n÷l,k),
In contrast, the classical iterative ADI scheme given inequation (2) considers only one direction in eachiteration; each new iteration computes a new directionwhich has no relation to the directions that havealready been used. This causes, in many cases, theiterative process to stall, and no further reduction in theerror vector M(q n÷l.k) is achieved.
Closely following the development given in Ref. 15,the direction vectors are found as follows:
The initial direction is computed as
dl "M(q "+Lk)
(6)
and normalized as
(7)
To compute the remaining directions (j=1,2 .... J-l),take
where
n+Lk._bij - (M_ , j),d i)
and
M_;aj) - M(_ + r_:)- M(_)£
Here, ¢ is taken to be some small number.it is set to 0.001.
(8)
(9)
(10)
In this work,
dj÷_ is normalized before the nextThe new direction
direction is computed:
(11)
(12)
bj+t,j " Hl_.i ÷i I
and
bj.l,j
After obtaining the components of &q along thesedirections, the solution vector is updated using
(13)
J
j-1
where the coefficients aI are chosen to minimize:
3

..,.,+
I- I'(14)
PARALLEL IMPLEMENTATION
"rhe GMRES code has been extensively evaluated fora number of unsteady flows in two- and three-dimensions 23,24.These eadler calculations done wereon vector machines of the Cray Y/MP class, or onadvanced workstations. The thrust of the presentstudy is to evaluate if the GMRES algorithm performswell on parallel machines of the Intel iPSC/860 class,and determine any modifications needed to tune thealgorithm to these machines.
The iPSCI860 is a MIMD machine; the individualprocessors work with different subsets of the datasimultaneously, and each processor mayindependently execute different instructions at thesame time. Furthermore, the iPSC/860 is a distributed-memory machine, where each processor has its ownseparate memory. In order to obtain information fromanother processor, a message-passing routine mustbe explicitly coded. Since the message passingprocess is a relatively slow sequential process, themost efficient code will usually have the least numberof messages.
As a first step, a non-iterative 2-D ADI code (that solvesequation (2), but uses only one iteration) was modifiedto run on an Intel iPSC/860 machine located at theNASA Langley Research Center. In order toaccomplish this goal, the computational domain wasdivided into a number of blocks or sub-domains asshown in FKjure 1. As is common with block structuredgrid solvers, each sub-domain overlaps its neighborsby two "ghost" cells. Each processor performs an ADIstep over one or more blocks. The boundaryconditions for the ghost cells are updated by passingmessages at the end of each step.
A number of 2-D steady flow calculations were firstcarried out with the non-iterative ADI solverimplemented on the iPSC/860 architecture. Thesteady state solutions were identical to the resultsobtained on sequential machines. As stated earlier,this approach of lagging the flow properties at the
block boundaries (ghost cells) works well only forsteady flows.
Iterative Thomas AI0orithm
Since the goal of this work was to solve the unsteadyNavier-Stokas equations in a "-_ fashion, aniterative solution procedure was implemented. Thebottleneck in such an implementation is inversion thetridiagonal matrix system in the streamwise (I_-)direction.
It should be noted that a parallel ADI step is quitedifferent from that of the sequential version. Adescription of the current implementation follows:
First, the order of the sweeps is reversed:
[I + AT0¢C][-I + A'r0_A]{Aq} = {R °÷''_}
(15)
and the _-swsep is performed first.
[l + -_{ Ro''.'}
(16)
Since this sweep requires information only within agiven block, and never requires information acrossblock boundaries, this matdx inversion was done, inparallel on all the processors, using the Thomasalgorithm in a manner identical to the sequentialversion of the flow solver.
When equation (16) has been solved in all the blocksm
by all the CPU nodes, the values for Aq are knownthroughout the flow field. Next, the streamwise sweepis performed:
[I + {nq'}
(17)
This sweep, performed using Thomas algorithm,usually requires information across block boundaries,because the nodes along the F,- direction in all theblocks are implicitly coupled. In the iterative approachwe lagged the _q values at the block boundaries byone iteration, or set these values to zero. This strategyremoves the implicit coupling between the individualblocks.
4

Wefoundtheaboveapproachto beunsatisfactoryfora number of reasons. A large number of iterations wereneeded to drive the &q values, and the associatedphase errors to zero. This algorithm required twomessage passes per iteration for each processor,which increases the run time dramatically. Also, theconvergence of the &q values near the blockboundaries was not uniform between iterations.
Block Cyclic Reduction (BCR) Routine
To avoid the difficulties involved in the iterativeThomas algorithm, a Block Cyclic Reduction (BCR)routine was next implemented, for solving equation(17) in the F_-sweep.
While the Thomas algorithm requires the leastoperation count to solve the matrix system, it also is aninherently sequential method (i.e., for each step in theinversion procedure, information is required from thestep previously performed). Therefore, the Thomasalgorithm is not directly paralletizable.
The Block Cyclic Reduction routine is a more efficientway of solving the tridiagonal matrix equations. Given atridiagonal matrix that is (2%1) x (2"+1), this proceduredirectly solves the matrix system as described in Ref.27.
The BCR routine has three drawbacks. First, theprocessors must communicate before every round ofreduction and back-substitution to obtain matrix valuesthat lie outside its block. These messages arerelatively shod, however. Second, during the end ofthe reduction and the beginning of the back-substitution process when there are few lines left tocompute, several processors wait in idle. It wasanticipated that the savings in computation timecompared to the parallel iterative routine will make upfor the idle time encountered. Third, for bestperformance, the BCR routine must have 2n + 1equations to solve. Thus, the gdd required for thisroutine is less flexible than that for the iterative parallelcode.
It should be emphasized that the BCR routine is adirect solution procedure in this implementation.There is no need to lag the &q values at the blockboundaries, as required by the iterative Thomasalgorithm described eadier.
_IMRES Implementation
The GMRES routines were finally added to the paralleliterative ADI code after the ADI code was validated.When the GMRES algorithm was implemented, a
question arose as to the definition of the residual to beminimized.
Two ideas were tried. The first idea was a completelyparallel GMRES implementation, where eachprocessor ran a GMRES routine to minimize the 12norm of the error vector M for nodes only in itsparticular block. When a function evaluation isrequired, the processors work in parallel to computethe residual R and the error vector M in all the blocks.The GMRES routine on each processor is onlyconcerned with minimizing the error vector in its ownblock. This is equivalent to allowing each direction tohave a different weighting coefficient in each block.
The second idea was a global GMRES implementation.In this scheme, the processors work as before tocompute the search directions and the residual in itssub-domain, but at the end of each functionevaluation, the global norm of the error vector M iscomputed and used. This is now directly equivalent tothe sequential GMRES code in that a single weightingcoefficient is used for each direction throughout theflow field.
Initial tests showed that the global GMRESimplementation performed significantly better than thelocal GMRES; thus, the global GMRES was used for allruns. The GMRES algorithm was implemented on boththe Thomas and BCR versions of the code. Thenumber of search directions were limited to 5 due tomemory limitations.
RESULTS AND DISCUSSIONS
The parallel ADI code was implemented on the NASALangley 32 processor Intel iPSC/860 MIMD parallelsupercomputer. Both the iterative Thomas algorithmand the BCR versions were extensively tested. TheBCR solver was typically four times faster than theiterative Thomas algorithm. Here we document onlythe calculations with the Block Cyclic Reductionmethod.
The notation used for the GMRES discussion is asfollows. The notation ' GMRES(5) ' refers to a steadyflow calculation with 5 search directions used at eachstep. The notation ' GMRES (5/10) ' refers to anunsteady flow calculation with 5 search directions usedat each time step; each time step, however, is 10timesthat taken by the non-iterative ADI solver.
The steady flow validation case was that of a subsonicviscous flow about a NACA 0012 airfoil at a 13.4" angleof attack. The treestream Mach number was 0.301,and the Reynolds number was 3,950,000. This casewas tested experimentally by McAlister, at. al2e. A C-grid topology was used, with 259 streamwise points
5

and 41 normal points. The Baldwin-Lomax turbulencemodel was used for all viscous calculations.
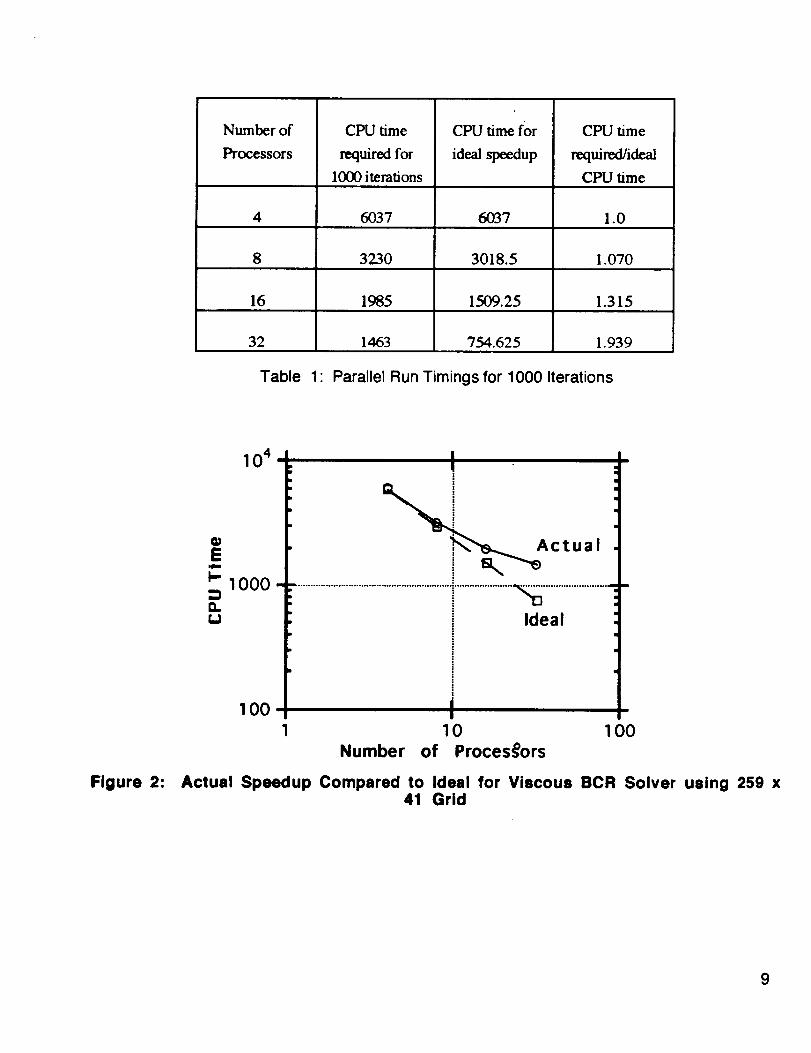
The non-iterative ADI code was run for 1000 iterationson 4,8,16, and 32 processors, and the speedupobtained is shown in Figure 2 and in Table I below. Itcan be seen that the speedup is not ideal, but this islargely due to the low number of points on eachproceesor. In other words, the processors spent asignificant portion of the time passing boundarycondition information from block to block. The I/0 timeassociated with the message passing was large, andcomparable to the CPU time for the parallel task ofcomputing the residual R or the error vector M.
From this point on, all results shown are obtained using8 processors. All GMRES solutions are obtained using5 search directions per step.
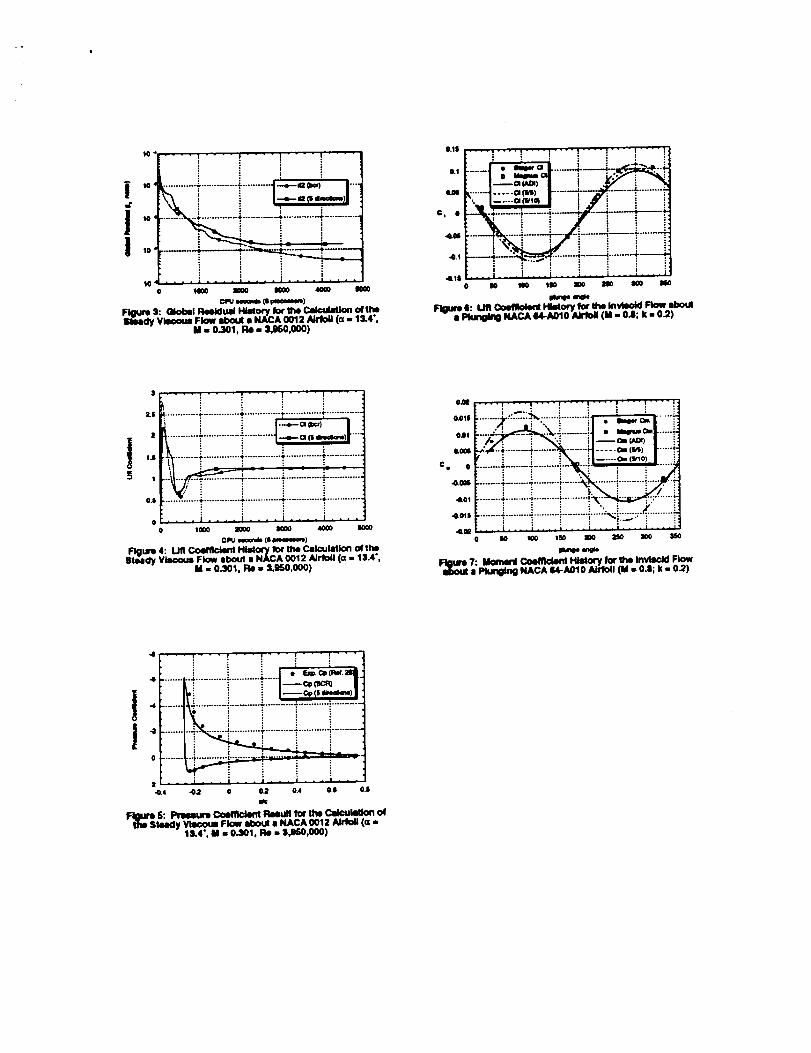
Results for the steady runs are shown in Figures 3, 4,and 5. Figure 3 shows the global residual histories forthe ADI solver and the GMRES solver. It should benoted that it was only possible to use 5 searchdirections due to the memory limitations of themachine; previous tests on a sequential computerhave shown that GMRES provides significantspeedups with more search directions.
Figure 4 shows the lift coefficient history for this run.Note that the GMRES solver converges to the final liftcoefficient much faster than the non-iterative BCRsolver.
Figure 5 shows the pressure coefficient computed byboth the ADI and GMRES(5) solver compared to theexperimental results of McAlister, et. al. Goodagreement is obtained with experiment, and thesolvers return identical answers, even though theGMRES solver has stalled at a relatively high residual.More search directions would have eliminated thisproblem.
Next, an unsteady validation case was run. Theproblem studied was that of inviscid transonic flowabout a plunging NACA 64-A010 airfoil. Thefreestream Mach number is 0.8, and the reducedfrequency is 0.2. The plunging motion is defined bythis equation:
Y, - -M=sin(l°)sin(Qrr) (18)
This is a challenging case for unsteady flow solvers,because of the formation and motion of strong shockwaves on the upper and lower surfaces. The shockspeed is sensitive to the errors in the discretization,and errors introduced at the block boundaries will beexpected to adversely affect the solution accuracy.
This case has been studied by many researchers; ourresults are compared to those of Steger 2s andMagnus2e..
The grid used here is a parabolic C-grid, with 259streamwise and 21 normal grid points. The non-iterative ADI solver uses a non-dimensional time stepof .01.
The GMRES solutions shown are computed using 5search directions and 5 and 10 times the ADI time step(GMRES (5/5) and GMRES (5/10), respectively). Localtime stepping is used as a preconditioner for theGMRES solver; this improves the convergencedramatically.
The results shown are for the fourth cycle of oscillation.Figure 6 shows the lift coefficient histories as afunction of the phase angle. It can be seen that theADI and both GMRES solutions agree well with theearlier studies of Steger and Magnus. Goodagreement between different methods for the liftcoefficient may be deceptive, because the errors (inshock locations and shock speeds) on the upper andlower surfaces tend to offset each other. The pitchingmoment is much more sensitive to the shock location,and serves as a more suitable indicator of the solutionaccuracy.
Figure 7 shows the moment coefficient histories forthe same case. It is seen that the ADI and GMRES(5/5) solutions agree well with the earlier studies ofSteger and Magnus, while the moment coefficient forthe GMRES (5/10) run is not close at all. This is due tothe errors in the computed shock speed as a largertime step is used.
In this study we used a simple preconditioner tostabilize the calculations. The time pseudo time stepA-E shown in equation (2) was different from thephysical time step At. Of course, the pseudo-stepdoes not have any effect on the final convergedsolutionat a given time step. In some earlier studies ona sequential computer, the preconditioner was notused (i.e. &¢ = &It). In these earlier calculations, 10search directions were necessary to stabilize theunsteady GMRES procedure (i.e., GMRES (10/5)),while now 5 are sufficient.
It should be noted that this case is a worst-casescenario for the GMRES solver. On most problems,the GMRES solver (both the parallel implementationand the sequential implementation) can speed up thesolution procedure by a factor of 3, over the baselineiterative ADI solver. The present problem, with itsmoving shocks and nonlinear flow field, is a harsh testof the GMRES solver.
6

CONCLUSIONS
An existing sequential unsteady 2-D compressibleviscous flow solver was rewritten for implementation onan Inter iPSC/860 MIMD parallel supercomputer. Twomethods were investigated for the parallel solution ofthe tridiagonal block matdces encountered in the ADIprocedure, the Block Cyclic Reduction techniqueproved to be four times faster than an iterative ThomasIdgorithm.
The code was validated for steady and unsteady,,viscous and inviscid flow cases. A GMRES solutionmethod was added and validated, and the effect ofpreconditioning on the GMRES parallelimplementation was investigated. This proved to havea very beneficial effect, and halved the number ofsearch directions odginally required for this problem.
The GMRES method proved to be highlyparallelizable,requiring only one very short message to be passedfor each search direction. The main shortcomingsencountered were in the parallelization of theunderlying ADI algorithm. Algorithms such as the BCRalgorithm described here, or other procedures thatexploit the parallel architecture more efficiently thanBCR can result in dramatic speedups with the GMRESsolver.
ACKNOWLEDGMENTS
The research reported here was supported by a grantfrom the NASA Langley Research Center (Grant No.NAG-l-1217). Dr. Woodrow Whitlow was the technicalmonitor.
REFERENCES
1 Borland, C.J. and Rizzetta, D., "Nonlinear TransonicRutter Analysis," AIAA Paper 81-0608-CP, AIAADynamic Specialists Conference, 1981.
2. Rizzetta, D.P. and Bodand, C., "Numerical Solutionof Unsteady Transonic Row over Wings with Viscous-Inviscid Interaction," AIAA Paper 82-0352, Jan. 1982.
3. Batina, J.T., "Unsteady Transonic AlgorithmImprovements for Realistic Aircraft Applications",Joumal of Aircraft, Vol. 26, No. 2, Feb. 1989, p. 131-9.
4. Sankar, L.N., Malone, J.B., and Tassa, Y., "AnImplicit Conservative Algorithm for Steady andUnsteady Three Dimensional Transonic PotentialRows', AIAA Paper 81-1016-CP, June 1981.
5. Malone, J.B. and Sankar, L.N, "Application of aThree-Dimensional Steady and Unsteady Full PotentialMethod for Transonic Row Computations", AFWAL-TR-84-3011, Flight Dynamics Laboratory, WrightPatterson Air Force Base, Dayton, OH, May 1984.
6. Shankar, V., Ide, H., Gorski, J., and Osher, S, "AFast, Time-Accurate Unsteady Full Potential Scheme,"AIAA Paper 85-1512-CP, July 1985.
7. Pulliam, T.H. and Steger, J.L., "Implicit Finite-Difference Simulations of 3-D Compressible Flow',AIAA Journal, Vol. 18, Feb. 1980, pp. 159-167.
8. Batina, J.T., "Unsteady Euler Solutions UsingUnstructured Dynamic Meshes," AIAA Paper 89-0115, Jan. 1989.
9. Sankar, L.N. and Tang, W., "Numerical Solution ofUnsteady Viscous Row Past Rotor Sections," AIAAPaper 85-0129.
10. Wake, B.E. and Sankar, L.N, "Solutions of theNavier-Stokas Equations for the Row About a RotorBlade', Journal of the American Helicopter Society,Vol. 34, No. 2, April 1989, pp. 13-23.
11. Rai, M.M, "Navier-Stokes Simulations of Rotor-Stator Interaction Using Patched and Overlaid Grids,"AIAA Paper 85-1519-CP, July 1985.
12. Gatlin, B. and Whitfield, D.L., "An Implicit UpwindFinite Volume Scheme for Solving the Three-Dimensional Thin-Layer Navier-Stokes Equations,"AIAA Paper 87-1149-CP, June 1987.
13. Kwon, O.J. and Sankar, L.N., "Viscous FlowSimulation of a Fighter Aircraft', Journal of Aircraft, Vol.29, No. 5, SOp-Oct. 1992, pp. 886-891.
14. Saad, Y. and Schultz, M.H, "GMRES: AGeneralized Minimum Residual Algorithm for SolvingNonsymmetric Linear Systems", SIAM J. Sci. Star.Comp., Vol. 7, No. 3, 1986, pp.856-869.
15. Wigton, L. B., Yu, N. J., and Young, D. P.,"GMRES Acceleration of Computational FluidDynamics Codes', AIAA Paper 85-1494-CP, 1985.
16. Venkatakdshnan, V. and Mawiplis, D. J., "ImplicitSolvers for Unstructured Meshes', ICASE Report 91-40, May 1991.
17. Giannakoglou, K., Chaviaropoulos, P., andPapailiou, K., "Acceleration of Standard Full-Potentialand Elliptic Euler Solvers, Using Preconditioned
7

GeneralizedMinimalResidualTechniques',ASMEFEDv. 69,PublishedbyASME,NewYork,NY,USA.pp.45-52.
18. Young,D.P., Melvin,R.G., Bieterman,MB.,Johnson, F.T., and Samant, S.S., "GlobalConvergence of Inexact Newton Methods forTransonic Flow', International Journal for NumericalMethods in Fluids, Vol. 11, No. 8, Dec. 1990, pp.1075-1095.
19. Vuik, C., "Solution of the DiscretizedIncompressible Navier-Stokes Equations with theGMRES Method', Netherlands Mathematical InstituteREPT-91-24, 1991.
20. Adams, L.M., and Ong, E.G., "Comparison ofPreconditioners for GMRES on Parallel Computers',AMD Symposia Series, Vol. 86. Published by ASME,New York, NY, USA., pp. 171-186.
21. Qin, X., and Richards, B.E., "a-GMRES: A NewParallelizable Iterative Solver for Large Sparse Non-Symmetric Linear Systems Arising from CFD',International Journal for Numerical Methods in Ruids,Vol. 15, No. 5, Sep. 15, 1992, pp.113-23.
22. Saad, Y. and Semeraro, B. D. , Application ofKrylov Exponential Propagation to Fluid DynamicsEquations", AIAA Paper 91-1567-CP, 1991.
23. Hixon, R. and Sankar, L.N., "Application of aGeneralized Minimal Residual Method to 2-D UnsteadyRows," AIAA Paper 92-0422, Jan. 1992.
24. Hixon, R., Tsung, F.L., and Sankar, L.N., "AComparison of Two Methods for Solving 3-D UnsteadyCompressible Flows', AIAA Paper 93-0537, Jan.1993.
25. Steger, J. L., "Implicit Finite Difference Simulationof Row about Arbitrary Two-Dimensional Geometries",AIAA Joumal, Vol. 16, July 1978, p. 679-86.
26. Magnus, R. and Yoshihara, H., "UnsteadyTransonic Row over an Airfoil', AIAA Journal, Vol. 14,Dec. 1975, pp. 1622-1628.
27. Wake, B.E. and Egolf, T.A., "Implementation of aRotary-Wing Navier-Stokes Solver on a MassivelyParallel Computer', AIAA Journal, Vol. 29, No. 1, Jan.1991, p. 58-67.
28. McAlister, K.W., Pucci, S.L., McCroskey, W.J., andCarr, L.W., "An Experimental Study of Dynamic Stallon Advanced Airfoil Sections, Volume 2: Pressureand Force Data", NASA TM 84245, Sept. 1982.
byProcessor #3
J
Computed byProcessor #4
I
IComputed by ,,.., by
Processor #2 I Processor # l
.44
Figure 1. Domain Decomposition for Implementation on a Four Processor ParallelComputer
8
Number of
Processors
CPU time
required for
1000 iterations
CPU time for
ideal speedup
CPU time
required/ideal
CPU time
4 6037 6037 1.0
8 3230 3018.5 1.070
16 1985 1509.25 1.315
32 1463 754.625 1.939
Table 1 Parallel Run Timings for 1000 Iterations
Figure 2:
a)E
I--
CI.
10 4
1000 -
_Actual
• .............................................................................. ....._ ..........................
i--I
Ideal
1 O0
1 10 100
Number of Proces@ors
Actual Speedup Compared to Ideal for Viscous BCR Solver41 Grid
using 259 x
9
q
tO
10
tO
.... : .... ! .... ! .... ! ....
i
-'--4..............,'...........1"_-'_ I....i tT"-'_"-)n
..........._ ! i+............ +........... -+ ............ _ ............: !_-
.... i .... i .... ; . . . • i ....
_ ttm_b (i p_omtNm)
M - 0.301, Re - _950,000)
0.tl
0.1
tC:, •
4.1
.4L15
' ; o ; ; J"...... J • ,,,-,L.____--__.++, l_a (_4_)l _ .9/ ;- .......... a 0vs) .... : :..... _ .........,, 1..... ..........
4 .... ;.......... ;--- , --'_. _ ......
_--_ii ' i ! _ "'-....... "----_ ...... H----.:_-_-
....] .... _ .... i ._._ .... i ......• I0 IO0 II0 _ ,mr, _
pOunt* mPqP
• IqunolnO NACA f,4-A010 Alrlml (I - v.s; a - v._;
:1 .... , .... ! .... ! .... I ....
I.l ............. ÷ .............. + .............. ÷ .............. ÷ .............i I
I ''-°_ I. "L---........._.............."..........1--°._',1 ....
J , _ ..........;.............._............. _...............;..............
o__'.'_...,.----..............÷..............:.:÷............-[..............
, , . . I .... I .... I .... I ....
1000 I_0 _00 40_
Ol_l m (I pllol,m,o_)
dy VtlcOUS Flow about • NACA 0012 Nrlo41 ((z = 15.4,M = 0.301, Re • $,950,000)
One
{LOSS
0.01
_kOOS
¢. 0
_.01
,,Ik_
.... ' .... ' .... ' .... I .... 1.... I .... "......_;"::::,"-::....... ii• ",'_t ......
_____......: .....:lit__,.._).,,.,,,o.n.t....... ":1 ..... "(_) [ ......! _ i , il ..... c,,, O_o) l
.... _."....... ._........ ._..
...... _....... 4......... i.......___ ........_...........:-----.--_ _ i. i _ /
...................._...........:..........,__:;.-- -..! ! .!..........i...'::._i.........Z..
i
: .... ] .... i .... i .... * .... i .... | ....
I0 tOO _0 30O _ IO0 3SO
7: _ Coelltdent HIMory for _ In_ Flow_m Plunging NACA $4-A010 Alrloll (M - 0.l; k 0.2)
•I_ - . . i - . . i - . . i - . . i - . . i - . .: : : : : .: : ! ; i '
I: i ! : ! . _,_0_._111'
"r.......r,,'............i............,."I--_,_ /
:_ .4 i[-...... -_............. ":!.......... -i........... "!........... 41............
• ............... i............_............" ............i ............
_ .... i.._i...;...i ..-'---
•o.4 ..o, o _ o_ o.o o_
Fl_re S: pnmamm _ RwuN for the Caicuiltion of
li.4", M = OJl01, Ro • a,=m_,vwj

![Iterative Techniques in Matrix Algebra [0.125in]3.250in0 ...](https://static.fdocuments.in/doc/165x107/616d92da9f960300402c3bcb/iterative-techniques-in-matrix-algebra-0125in3250in0-.jpg)





![Iterative Techniques in Matrix Algebra [0.125in]3.250in0 ...mamu/courses/231/Slides/CH07_3A.pdf · Iterative Techniques in Matrix Algebra Jacobi & Gauss-Seidel Iterative Techniques](https://static.fdocuments.in/doc/165x107/5e112f948a9fc45c2a0d92ca/iterative-techniques-in-matrix-algebra-0125in3250in0-mamucourses231slidesch073apdf.jpg)


![Iterative Techniques in Matrix Algebra [0.125in]3.250in0.02in … · 2012. 8. 2. · Iterative Techniques in Matrix Algebra Jacobi & Gauss-Seidel Iterative Techniques II Numerical](https://static.fdocuments.in/doc/165x107/60d554aa32c484202c6296ed/iterative-techniques-in-matrix-algebra-0125in3250in002in-2012-8-2-iterative.jpg)

![Iterative Techniques in Matrix Algebra [0.125in]3.250in0 ...mamu/courses/231/Slides/CH07_3B.pdf · Iterative Techniques in Matrix Algebra Jacobi & Gauss-Seidel Iterative Techniques](https://static.fdocuments.in/doc/165x107/5acf14947f8b9a4e7a8c2ac6/iterative-techniques-in-matrix-algebra-0125in3250in0-mamucourses231slidesch073bpdfiterative.jpg)





