![[PPT]Modified Booth Multiplier - Universidad Autónoma de …galia.fc.uaslp.mx/~rmariela/digital/ModifiedBooth.ppt · Web viewTitle Modified Booth Multiplier Author Dr. José Martin](https://static.fdocuments.in/doc/165x107/5b327a3d7f8b9aae458bff5a/pptmodified-booth-multiplier-universidad-autonoma-de-galiafcuaslpmxrmarieladigital.jpg)
Design and Implementation of High Radix Booth Multiplier ... · It has been performed the design...
7
129 Volume-4, Issue-6, December-2014, ISSN No.: 2250-0758 International Journal of Engineering and Management Research Available at: www.ijemr.net Page Number: 129-135 Design and Implementation of High Radix Booth Multiplier using Koggestone Adder and Carry Select Adder Y.Harika 1 , Dr. K.S.Srinivasan 2 . Principal, Turbo Machinery Institute of Technology and Sciences, INDIA M. Tech Scholar, VLSI and Embedded Systems, Turbo Machinery Institute of Technology and Sciences, INDIA ABSTRACT This paper presents the design and implementation of radix-16 booth Multiplier.The number of partialproducts are reduced to n/3 in radix-8.We can reduce the number of partial products even further to n/4 by using a higher radix- 16 in the multiplier encoding, thereby obtaining a simpler CSA tree .This implies less delay and a smaller area size .Since this multiplication operation is for both signed and unsigned numbers, cost of the system can also be reduced. The carry select adder (CSA) tree and the final adder can speed up the operation of multiplier. Koggestone adder is a parallel prefix form carry look ahead adder .We determine that by replacing carry select adder(CSA) and final two operand parallel prefix adder with parallel prefix adders of koggestone algorithm reduces delay further more resulting in substantial increase in speed of circuits.Since signed and unsigned multiplication operation is performed by the same multiplier unit the required hardware and the chip area reduces and this in turn reduces power dissipation and cost of a system. Keywords--- Booth algorithm, Radix-16, carry select adder, Koggestone adder, carry look ahead adder. I. INTRODUCTION Multipliers play an important part in digital signal processing (DSP) systems. They are used in implementations of recursive and transverse filters, discrete Fourier transforms, correlation, range measurement. Regular advances in technology allowed to design multipliers which are both high-speed and has regularity in layout suitable for VLSI implementation. In any multiplication algorithm, the operation is reduced to a partial product summation. Every partial product denotes a multiple of the multiplicand which should be added to the final result. In radix-2 algorithm,we form a series of products in between the multiplicand, Y, and each and every bit of the multiplier, X, resulting in partial products. After that, all the partial products are added. We use some redundant arithmetic to get the additions as fast as possible. Usually the speed can be increased by a CSA tree. In the conventional CSA tree, partial product bits with many inputs residing at the same bit position, are successively reduced to a final sum and carry pair with the help of a series of full adders which are single bit each. At the output, we will be left with sum and carry which has to be added by a carry-propagate adder (CPA).Where as radix-16 recoding provides gain in time while summing up the partial products as partial products are reduced to n/4 for n bits of multiplier and multiplicand compared to n/3 in radix-8. However our multiplier is designed such that to modification in the previous adder stages. In this way, generation of odd multiple is speeded up even further. Another interesting point in the use of radix-16 recoding is the less number of transistors resulting in a reduced power dissipation and area size compared to radix-8.We will also reduce number of partial products using a higher radix-16 booth technique in the multiplier and by replacing CSA tree with koggestone adder ,a parallel prefix form of carry look ahead adder we obtain a even lesser delay. II. PROPOSED RADIX-16 BOOTH MULTIPLIER TO OBTAIN PARTIAL PRODUCTS Radix 16 Modified booth multiplier is same as implementation of radix 2,4 and 8 only difference here is the recoding table which is different to different radix,Here the multiplication is divided according to the grouping of multiplier bits and generated partial products according to no.of groups formed. Case Study: Multiplicand=0000_0000_0000_0000_0000_0000_1000_1 000 Multiplier =0000_0000_0000_0000_0100_0000_0100_0110 0-pad bit at LSB According to the steps above explained in radix 8 booth multiplier we have to follow here
Transcript of Design and Implementation of High Radix Booth Multiplier ... · It has been performed the design...

129
Volume-4, Issue-6, December-2014, ISSN No.: 2250-0758
International Journal of Engineering and Management Research Available at: www.ijemr.net
Page Number: 129-135
Design and Implementation of High Radix Booth Multiplier using Koggestone Adder and Carry Select Adder
Y.Harika1, Dr. K.S.Srinivasan2
.Principal, Turbo Machinery Institute of Technology and Sciences, INDIA
M. Tech Scholar, VLSI and Embedded Systems, Turbo Machinery Institute of Technology and Sciences, INDIA
ABSTRACT
This paper presents the design and implementation of radix-16 booth Multiplier.The number of partialproducts are reduced to n/3 in radix-8.We can reduce the number of partial products even further to n/4 by using a higher radix-16 in the multiplier encoding, thereby obtaining a simpler CSA tree .This implies less delay and a smaller area size .Since this multiplication operation is for both signed and unsigned numbers, cost of the system can also be reduced. The carry select adder (CSA) tree and the final adder can speed up the operation of multiplier. Koggestone adder is a parallel prefix form carry look ahead adder .We determine that by replacing carry select adder(CSA) and final two operand parallel prefix adder with parallel prefix adders of koggestone algorithm reduces delay further more resulting in substantial increase in speed of circuits.Since signed and unsigned multiplication operation is performed by the same multiplier unit the required hardware and the chip area reduces and this in turn reduces power dissipation and cost of a system. Keywords--- Booth algorithm, Radix-16, carry select adder, Koggestone adder, carry look ahead adder.
I. INTRODUCTION
Multipliers play an important part in digital signal processing (DSP) systems. They are used in implementations of recursive and transverse filters, discrete Fourier transforms, correlation, range measurement. Regular advances in technology allowed to design multipliers which are both high-speed and has regularity in layout suitable for VLSI implementation. In any multiplication algorithm, the operation is reduced to a partial product summation. Every partial product denotes a multiple of the multiplicand which should be added to the final result. In radix-2 algorithm,we form a series of products in between the multiplicand, Y, and each and every bit of the multiplier, X, resulting in partial products. After that, all the partial products are added. We use some redundant arithmetic to get the additions as fast as possible. Usually the speed can be increased by a CSA tree.
In the conventional CSA tree, partial product bits with many inputs residing at the same bit position, are successively reduced to a final sum and carry pair with the help of a series of full adders which are single bit each. At the output, we will be left with sum and carry which has to be added by a carry-propagate adder (CPA).Where as radix-16 recoding provides gain in time while summing up the partial products as partial products are reduced to n/4 for n bits of multiplier and multiplicand compared to n/3 in radix-8.
However our multiplier is designed such that to modification in the previous adder stages. In this way, generation of odd multiple is speeded up even further. Another interesting point in the use of radix-16 recoding is the less number of transistors resulting in a reduced power dissipation and area size compared to radix-8.We will also reduce number of partial products using a higher radix-16 booth technique in the multiplier and by replacing CSA tree with koggestone adder ,a parallel prefix form of carry look ahead adder we obtain a even lesser delay.
II. PROPOSED RADIX-16 BOOTH MULTIPLIER TO OBTAIN PARTIAL
PRODUCTS
Radix 16 Modified booth multiplier is same as implementation of radix 2,4 and 8 only difference here is the recoding table which is different to different radix,Here the multiplication is divided according to the grouping of multiplier bits and generated partial products according to no.of groups formed. Case Study: Multiplicand=0000_0000_0000_0000_0000_0000_1000_1000 Multiplier =0000_0000_0000_0000_0100_0000_0100_0110 0-pad bit at LSB
According to the steps above explained in radix 8 booth multiplier we have to follow here

130
1. Denote each group as a partial product and add necessary bits to complete group of multiplier i.e., Grouping of bits:
1. Generate 8 partial products according to the grouping bits
of multiplier 2. we multiply two 32 bit values according to the steps
followed by radix 8 booth algorithm. That illustrated in following example Example Operation: 0000_0000_0000_0000_0000_0000_1000_1000- Multiplicand (MC) -128+8=136
Multiplier 16384+64+8+4= 16460 0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0011_0011_0000 pp1 0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0010_0010_0000 pp2 0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000 pp3 0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0010_0010_0000 pp4 0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000 pp5 0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000 pp6 0000_0000_0000_0000_0000_0000_0000_0000_0000_0000 pp7 0000_0000_0000_0000_0000_0000_0000_0000_0000 pp8 0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0010_0010_0010_0101_0011_0000–Output
The recoder table below helps to do the multiplication of 32 bit values like what do in radix 16 multiplier.
Table.2.1Radix 16 Booth Multiplier Table
III. CARRY SELECT ADDER-CARRY PROPAGATE ADDER
The carry select mechanism is employed in order
to parallelise the operation of a 16 bit carry propagate adder for 64 bits. a[31:16],b[31:16] are given to two 16 bit cpa’s assuming carry as 1 and 0 respectively. This is done while a single cpa is calculating carry C16 from a[15:0] and b[15:0].Thus once the carry C16 is computed multiplexer chooses required appropriate carry to end up with carry C32.This is the first module. Similarly next 32 bits that is a[63:32],b[63:32] are computed parallely with the first module to obtain carry C64 as shown in fig 1.The sum is finally calculated by performing xor operation between propagate terms Pi and the carries Ci. If Carry in =1, then the sum and carry out are given by, Sum (i) =a (i) xor b (i) xor '1'. Carry (i+1) = (a (i) and b (i)) or (b (i) or a (i)).

131
If Carry in =0, then the sum and carry out are given by,
Sum (i) = a (i) xor b (i). Carry (i+1) = (a (i) and b (i)).
The sum function:
Si=cisi0+ cisi 1
The carry function: C i+1=cici+10+cici+1
1.
FIGURE.1 CSLA-CPA
IV. KOGGESTONE ADDER
Figure.2 Basic block diagram
4.1 Parallel prefix adder basics
A Parallel Prefix Adder (PPA) is equivalent to the CLA adder. The two differ in the way their carry generation block is implemented Parallel prefix adders are fastest adders and these are used for high performance arithmetic circuits in industries. The meaning of Parallel Prefix Operation is:-
Prefix: The outcome of the operation depends on the initial inputs. Parallel: Involves the execution of an operation in parallel. This is done by segmentation into smaller pieces that are computed in parallel. Operation: Any arbitrary primitive operator “°” that is associative is parallelizable It is fast because the processing is accomplished in a parallel fashion.
For a large number of applications, the speed critical computation block includes adders: either as stand-alone blocks or integrated N bit multiplier architectures. Due to this, specialized speed optimized adder architectures are required for high performance systems. The Main Component is the arithmetic Unit of ALU. In ALU Most of the Calculations in Multiplier is done with the help of adder. PPA can be divided into three main parts, Pre-possessing stage: In this stage we compute, generate and propagate signals to each pair of inputs A and B. These signals are given by the logic equations (1) & (2): Pi=Ai xorBi............................... (1) Gi = Ai and Bi............................. (2) Carry generation network in this stage we compute carries corresponding to each bit. Execution of these operations is carried out in parallel [5]. After the computation of carries in parallel they are segmented into smaller pieces. It uses carry propagate and generate as intermediate signals which are Are given by the logic equations 3i,3ii.
FIGURE.3 Carry Operator
The operations involved in this figure are given
as: P=P’ and P’’..................... (3(i)) G= (P’ and G’’) or G’................ (3(ii)) Post processing: This is the final step to compute the summation of Input bits. It is common for all adders and the sum Bits are computed by logic equation (5) Ci-1=(Pi and Cin) or Gi.................. (4) Si=Pi xor Ci-1............................... (5)
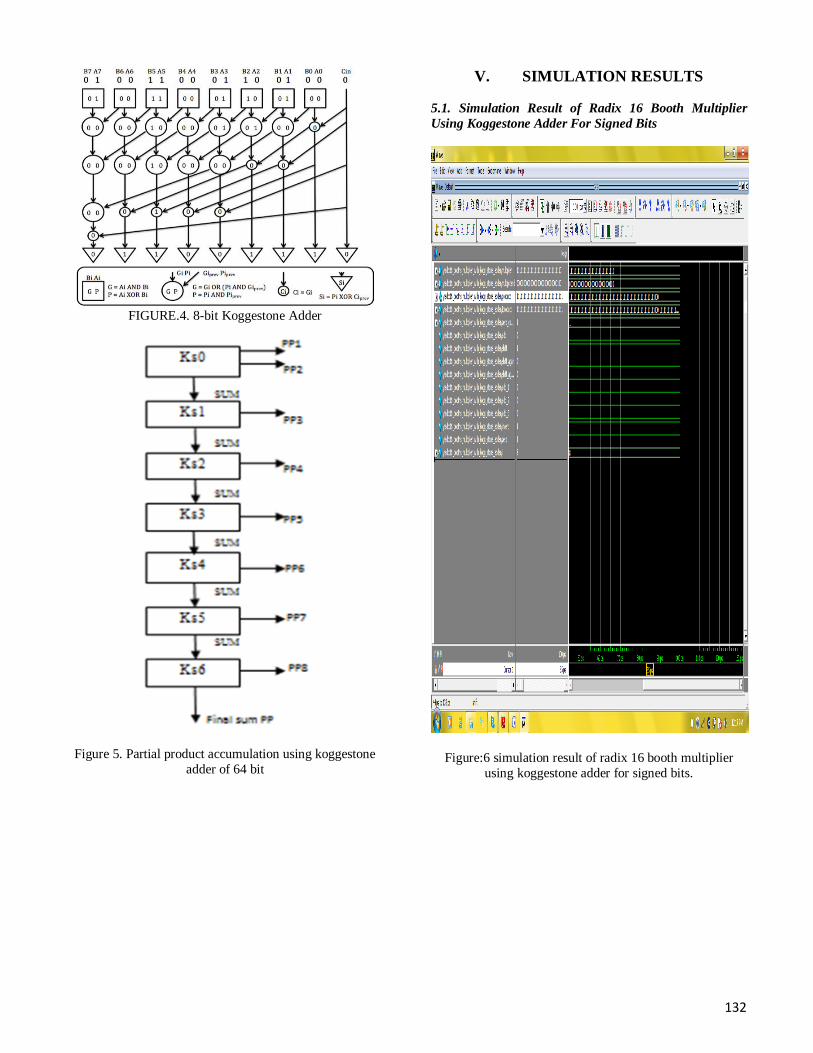
132
FIGURE.4. 8-bit Koggestone Adder
Figure 5. Partial product accumulation using koggestone
adder of 64 bit
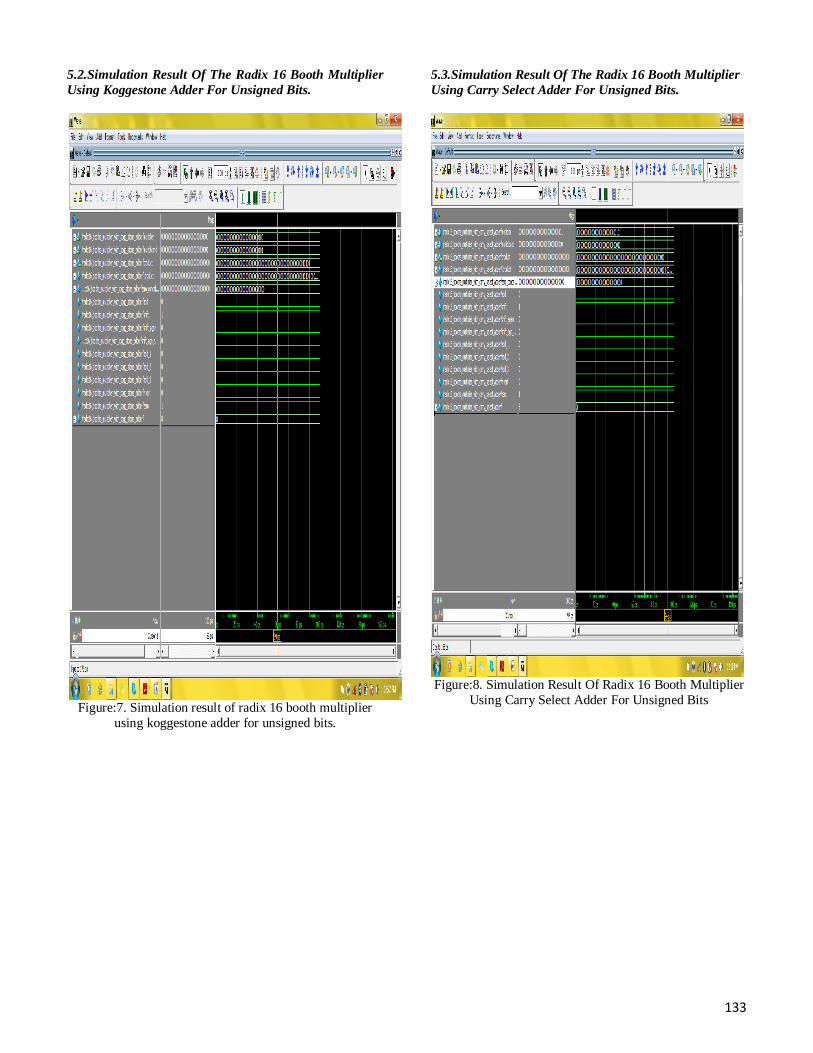
V. SIMULATION RESULTS 5.1. Simulation Result of Radix 16 Booth Multiplier Using Koggestone Adder For Signed Bits
Figure:6 simulation result of radix 16 booth multiplier using koggestone adder for signed bits.
133
5.2.Simulation Result Of The Radix 16 Booth Multiplier Using Koggestone Adder For Unsigned Bits.
Figure:7. Simulation result of radix 16 booth multiplier
using koggestone adder for unsigned bits.
5.3.Simulation Result Of The Radix 16 Booth Multiplier Using Carry Select Adder For Unsigned Bits.
Figure:8. Simulation Result Of Radix 16 Booth Multiplier
Using Carry Select Adder For Unsigned Bits

134
5.4.Simulation Result Of The Radix 16 Booth Multiplier Using Carry Select Adder For Signed Bits.
Figure:9. Simulation Result Of Radix 16 Booth Multiplier
Using Carry Select Adder For Signed Bits
VI. PERFORMANCE COMPARISON Target device : Spartan3E Device :xc3s500e Package :5fg320 Speed :-5
Table6.1 Result comparison table
VII. CONCLUSION
It has been performed the design and implementation of a 32 bit radix-16 booth multiplier. It has been proved that it can be useful to apply a radix-16 architecture in high speed multipliers because of the gain in time obtained due to reduction of partial products to n/4. The use of a radix-16 recoding is the less number of transistors resulting in a reduced power dissipation and area size, compared to a radix-8 architecture. Delay has been further reduced by replacing CSA with koggestone parallel prefix adder in the summation stage for both signed and unsigned bits. Due to this overall multiplication time has been reduced with our radix-16 architecture.
VIII. FUTURE WORK
This 32 bit multiplier can be further extended to 64 bit multiplier and 128 bit multiplier using the proposed method for multiplication operation can be done as future work.
REFERENCES [1]
[1] V.Vijayalaxmi,R.Sheshadri,” Design and Implementation of 32Bit Unisgned Multiplier Using CLAA and CSLA” in International journal,2013 [2] Z. Li, H. Chen, X. Yang “Research on disposal of negative partial products for booth algorithm,” in Proc. IEEE Conference on information theory and information security (ICITIS), Dec 2010, pp 1115-1117.

135
[3] W.C. Yeh and C.W. Jen, “High-speed booth encoded parallel multiplier design,” in IEEE Transaction on computer society, vol. 49, no. 7, Jul. 2000,pp. 692–701. [4] J.Y.Kang and J.L. Gaudiot “A simple high-speed multiplier design ,”IEEE Transaction on computer society, vol. 55, no. 10, Oct. 2006 ,pp. 1253–1258. [5] O. Salomon, J.M. Green, and H. Klar, “General algorithms for a simplified addition of 2’s complement numbers,” in IEEE Solid-state circuits, vol. 30, no. 7, Jul. 1995,pp. 839–844. [6] A. A. Farooqui, V. G. Oklobdzija “General data-path organization of a MAC unit for VLSI implementation of DSP processors”.IEEE interactive symposium on ISCAS, vol.2, June 1998. [7] F. Elguibaly, “A Fast parallel multiplier-accumulator using the modified booth’s algorithm”, IEEE Transactions on analog and digital signal processing, vol. 47 Sept. 2000, pp 902-908 [8] O.Hasan, S.Kort “Automated formal synthesis of wallace tree multipliers,” IEEE Transactions on MWSCAS, Aug 2007 pp 293-296.
[9] O.Hasan, S.Kort “Automated formal synthesis of wallace tree multipliers,” IEEE Transactions on MWSCAS, Aug 2007 pp 293-296.
[10] S.R. Kuang, J.P. Wang, and C.Y. Guo, “Modified booth multipliers with a regular partial product array,” in IEEE Transaction on circuits and systems-II, vol. 56, no. 5, May 2009, pp. 404-408.
Copyright © 2011-14. Vandana Publications. All Rights Reserved.


















