Type UB-3502A, UB-4002A, UB-4502A, UB-5002A Forced-Air Heater


Rama ChellappaUniversity of Maryland
Deep Understanding of Faces

Deep Understanding of Faces
Rama ChellappaUniversity of Maryland
3
This research is based upon work supported by the Office of the Director of National Intelligence (ODNI),
Intelligence Advanced Research Projects Activity (IARPA), via IARPA R&D Contract No. 2014-
14071600012. The views and conclusions contained herein are those of the authors and should not be
interpreted as necessarily representing the official policies or endorsements, either expressed or implied,
of the ODNI, IARPA, or the U.S. Government. The U.S. Government is authorized to reproduce and
distribute reprints for Governmental purposes notwithstanding any copyright annotation thereon.

Outline
• Historical comments• Artificial neural networks (mid 80’s – early 90’s)
• Early attempts at using deep networks
• What has changed since 2012?• Large annotated data, GPU and approximation to nonlinearities
• Applications pulling theory!
• Applications• Too numerous to list
• Unconstrained face verification/recognition
• Open issues
( 4

My involvements with 3-layer and deep convolutional neural networks
• Stereo, optic flow computation and texture segmentation using ANNs• Artificial neural networks for computer vision, Springer (with Y.T. Zhou) (1991)
• MRF-based algorithms and ANNs
• MRFs and Boltzman machines
• Face recognition using a version of dynamic link architecture (CVPR 1992)
• CNNs for automatic target recognition (with ARL folks, CVIU 2001)
• Revenge of the networks• By adding more layers, deep learning networks are beating SVMs
• LeNets, (1989, 1998), AlexNet (2012), …

Convolutional neural networks (LeCun)
• LeNet (Since late eighties)
• MNIST results
• Non-linear mapping from image to labels
• Not widely welcomed by computer vision researchers• Immense scope for information theory, control systems, signal processing and
mathematical statistics researchers!

Unconstrained face verification..(IARPA JANUS Program)
• Since 2014• Currently in Phase II• Most challenging effort• Face verification, search, detection, subject specific
clustering• Very high levels of performance• At FAR of 10-4, TAR should be above 85%• UMD (Lead), CMU, Columbia, Rutgers, UB, UCCS,
UTD.

UMD Janus phase II architecture
Faculty: Chellappa, Davis, Jacobs, Boult, Chang, Govindaraju, O’Toole, Patel, Ramanan
Senior researchers: Castillo, Chen, Gunther, Karaman, Morariu, Setlur, Tulyakov, Yacoob
15 graduate students

UMD Janus phase II architectureTask 1 CS4 1:1 Mixed Verification (stills/frames)This protocol consists of 15.79 million comparisons between mixed-media templates (images and video frames). It has about 3,548 unique subjects with a total of 23,221 templates. There are 19,673 genuine and 15,770,621 impostor matches.
Task 2 CS4 1:1 Covariate VerificationThis protocol contains 47,795,011 pair of 1 : 1 comparison using single image-based templates (7,846,524 genuine and 39,948,487 poster pairs)
Task 4 CS4 1:N Mixed Search (Open Set)The gallery data is divided into two disjoint splits. Split 1 in the gallery contains 1,782subjects and split 2 contains the rest of the 1,766 subjects. Probe data contain all3,548 subjects with 459,621 probe templates.
Task 6 CS4 Face DetectionThe protocol consists of 148,881 unique files (stills/frames/non-face images) with 262,305 faces.

Task 7 CS4 Subject ClusteringThe clustering protocol is designed to test an algorithm's ability to identify multiple instances of the same subject from a collection of various pieces of media. In experiment 7, there are four clustering sub-protocols with 32 subjects (956 faces), 1,024 subjects (41,287 faces), 1,845 subjects (71,694 faces), and 3,548 (141,339 faces).
Task 9 CS4 Wild Probe with Still Images and FramesThe task is to identify subjects of interest from a collection of 9,693 still images, 117,543 frames, and 10,044 non-face images. It requires to detect faces and search each detected face against the CS4 galleries. Then, 1:N search test is evaluated between the templates and the curated CS4 galleries (G1 and G2).
Task 10 CS4 Wild Probe with Full Motion VideoSame as task 9 but with 11,799 full motion videos used as input.
Task 11 CS4 Wild Probe MixedThe wild probe mixed protocol is designed to test an algorithm's ability to create and match templates from a collection of media (9693 still images, 10,044 non-face images, and 11,799 full-motion video) to a curated gallery. It requires to build templates for all identities determined to be within the collection of media by creating templates from single images or videos, clustering those templates, and then creating multi-media templates from the clustering output.

Data sets
• IJB-A dataset: 500 subjects with a total of 25,813 images taken from photos and video frames (5,399 still images and 20,414 video frames). Available for public.
• CS3 dataset is a superset of IJB-A dataset which contains 1,871 subjects with 11,876 still images and 55,372 video frames sampled from 7,094 videos. Will be publicly released soon.IJB-B is a subset of CS3 and is available for public.
• CS4 dataset is a superset of IJB-A and CS3 datasets which contains 3,548 subjects with 21,295 still images and 117542 video frames sampled from 11,799 videos in addition to 10,044 non-face images as distractors.

Unique features of UMD-led team’s work on JANUS
• Multi-task learning in deep networks• Face and gender detection, pose and age estimation, fiducial extraction
• Network of networks• Fusion of short and taller networks
• Relatively small training data sets
• Facial attributes; Hashing; Full motion video processing
• State-of-the art performance on face verification, search, clustering tasks.
• Extensive publication record
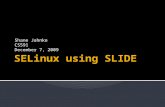
• Multi-task Learning regularizes the shared parameters of the network and reducesoverfitting.
• Enables the network to learn the correlations between data from different distributions inan effective way
UltraFace
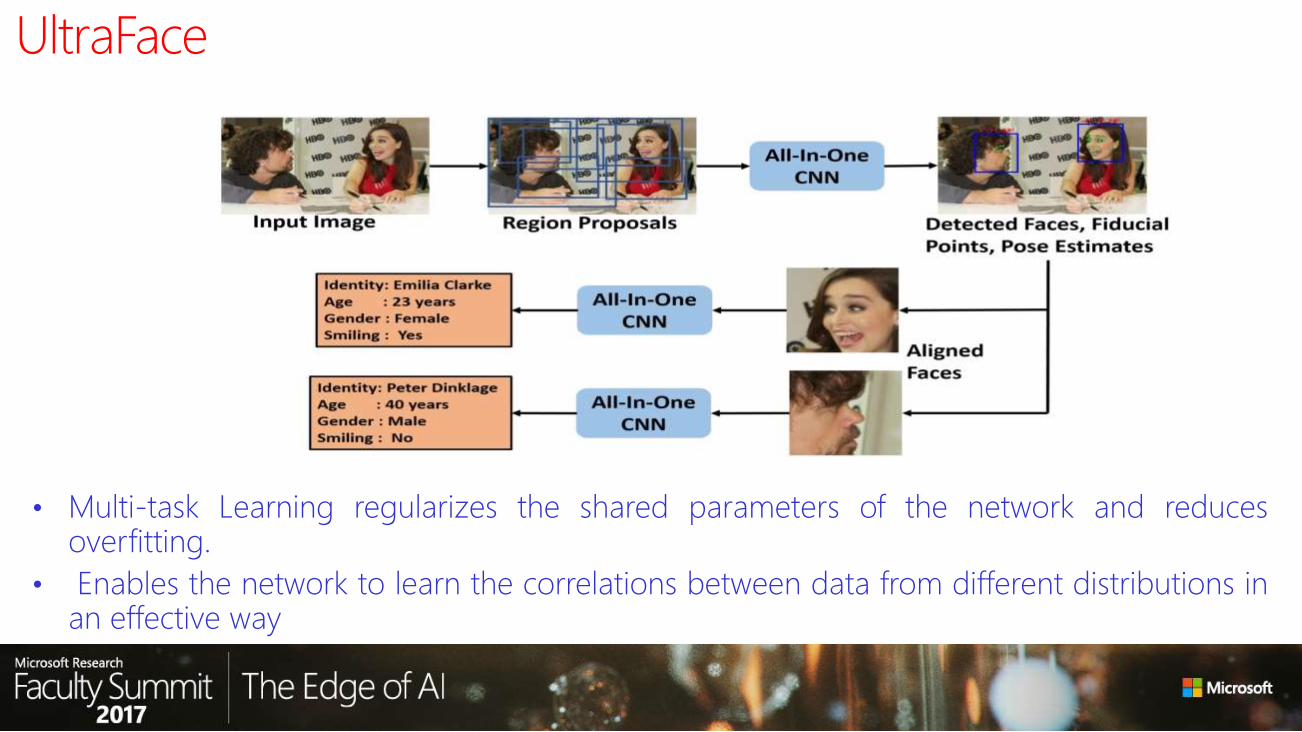
UltraFace architecture
• Subject-independent tasks (face-detection, fiducials, pose, smile)share the lower layers of thenetwork
• Subject-specific features are pooled
from deeper layers of the network
• For proposal, SSD, fast and caffe-
based
• Parameters initialized from face
identification network

• Training Loss Functions• Face Detection: Cross Entropy Loss• Landmarks: Euclidean Loss weighted with visibility• Pose: Euclidean Loss• Gender, Smile: Cross Entropy Loss• Age: Gaussian Loss• Identification: Cross Entropy Loss
TrainingDataset Tasks #Training Samples
CASIA Identification, Gender 490,356
MORPH Age, Gender 55,608
IMDB + WIKI Age, Gender 224, 840
Adience Age 19,370
CelebA Smile, Gender 182,637
AFLW Detection, Pose, Fiducials 20,342
Total 993,153

Sample outputs

Community of networks
Rajeev Swami Ankan
Training set MS1M-curated MS1M-curated MS1M+UMDFaces
Base architecture ResNet AlexNet Inception ResNet
Loss function L2-Softmax Softmax Softmax
Embedding TPE (UMDFaces-stills) TPE (UMDFaces-stills) TPE (UMDFaces- stills)
Strengths Good at High FAR Good at Low FAR,
covariates
Good at Low FAR
Alignment + Box size Ultraface, 227x227 Ultraface, 224x224 Ultraface, 299x299
Overlapping subjects between training data and CS4 removed.
S. Sankaranarayanan, A. Alavi, C. D. Castillo, and R. Chellappa. Triplet probabilistic embedding for face verification and
clustering. In 2016 IEEE 8th BTAS, 2016
R. Ranjan, C. D. Castillo and R. Chellappa. "L2-constrained Softmax loss for discriminative face verification." arXiv preprint
arXiv:1703.09507 (2017).
W.-A. Lin, J.-C. Chen and R. Chellappa, A proximity-aware hierarchical clustering of faces, FG 2017.
A. Bansal, C. Castillo, R. Ranjan and R. Chellappa, “The Do’s and Don’ts for CNN-based face verification” (Under review)

Training details - 1
• Deep convolutional networks for faces (Swami-FG17)– Training data: MS1M - curated• 57k subjects, 3.7 million images.
• Faces of overlapping subjects removed from training stage.
– Training time: 100 hours (using 750K iterations over 50K subjects) on GPU (NVidia Titan X).
• Deep fusion network – Training data: UMDFaces - stills: 378k face images for 8510 unique subjects.
– Training time: 45 minutes (using 2K iterations) on GPU (NVidia Titan X).

Training details - 2
• Metric learning: TPE – Training data: UMDFaces –stills: 378k face images for 8,510 unique subjects.
– Training time: 15 minutes.
• L2-Softmax (Resnet-101)– Training data: MS1M-curated: 3.7 million faces images for 57k unique subjects.
– Training time: 32 hours (8 NVidia Quadro P6000)
Y. Guo, L. Zhang, Y. Hu, X. He, J. Gao, MS-Celeb-1M: A Dataset and Benchmark
for Large-Scale Face Recognition, ECCV, 2016

Fusion CNN
• CNN with• Fully connected layers
• Non linear activations
• Scaling layers
• Trained using• DCNN (JC) and DCNN (Swami)
• UMD Faces
• Not exploiting yaw, roll, pitch or gender

UMD faces dataset
378k stills face annotations of 8501 subjects; 3.2 million frame
annotations from 3090 subjects from 19.5k videos; Face box and
identity annotations verified by humans; Wide range of poses and
expressions; Annotations also provided for fiducial keypoints, 3-D
pose, and gender generated by UltraFace
Fig: Performance on AFW dataset of a
network trained on our dataset compared
with state-of-the-art methods trained on
other datasets

CS4 results
GOTS
UMD Phase II deliverable
(06/15/17)
FAR = 1e-06 0.121 0.217
FAR = 1e-05 0.164 0.401
FAR = 1e-04 0.221 0.655
FAR = 1e-03 0.296 0.831
FAR = 1e-02 0.398 0.916
FAR = 1e-01 0.504 0.956
Task 2: Covariate verification
GOTS
UMD Phase II deliverable
(06/15/17) Phase II metrics
FAR = 1e-06 0.036 0.501
FAR = 1e-05 0.073 0.836
FAR = 1e-04 0.153 0.912 0.85
FAR = 1e-03 0.328 0.953 0.95
FAR = 1e-02 0.574 0.975
FAR = 1e-01 0.727 0.988
Task 1: 1 to 1 verification (stills/frames)
R. Ranjan, C. D. Castillo, and R. Chellappa. "L2-constrained Softmax Loss for Discriminative Face Verification." arXiv
preprint arXiv:1703.09507 (2017).0.960

Performance of ensemble of deep networks
Task 1: CS4 1:1 Mixed
Verification
Task 2: CS4 1:1 Covariate
Verification
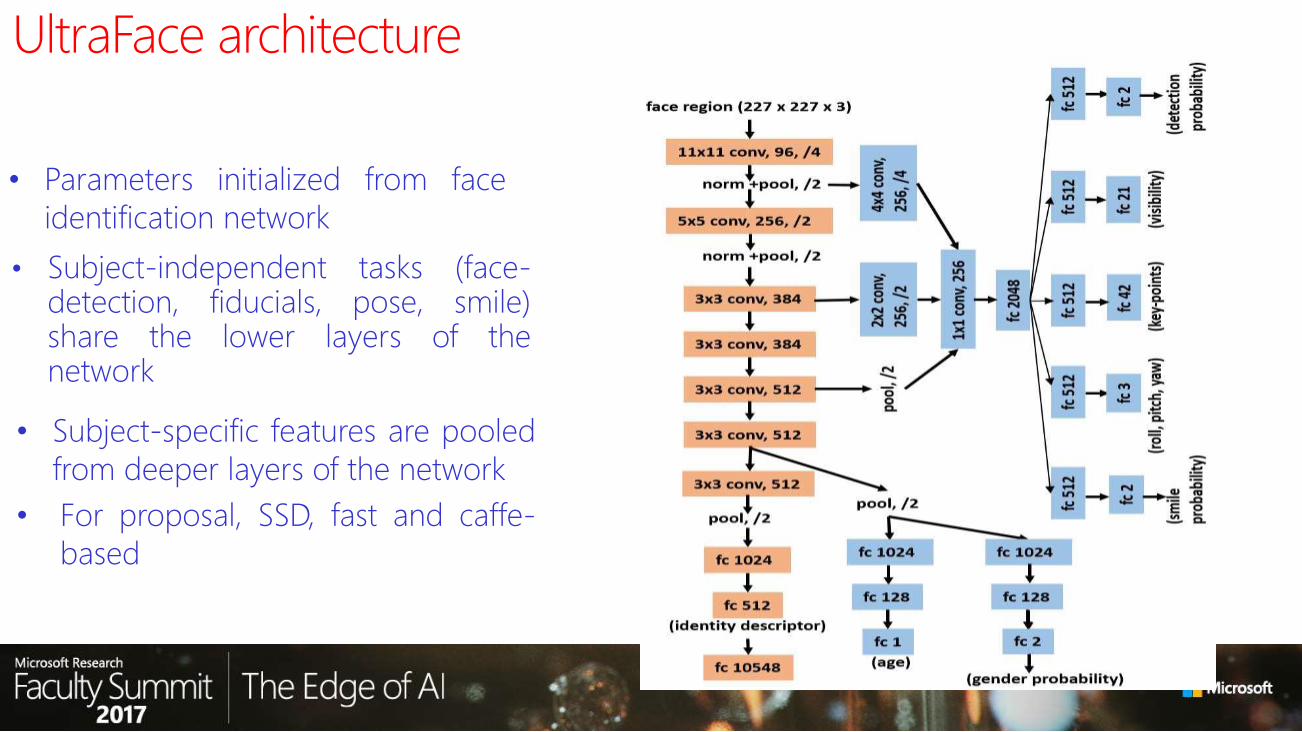
Task 4: Search (mixed queries)
GOTSUMD-Phase II
deliverable (6/15/17) Phase II metrics
Rank1 0.385 0.95
Rank5 0.527 0.96
Rank10 0.587 0.97
Rank20 0.640 0.975 0.95
Rank50 0.707 0.981
GOTS UMD-datacall
FAR = 1e-06 0.000082 0.000079
FAR = 1e-05 0.001371 0.000787
FAR = 1e-04 0.014770 0.007867
FAR = 1e-03 0.118504 0.078671
FAR = 1e-02 0.470230 0.570283
FAR = 1e-01 0.675825 0.782364
Task 7: Face detection


Curated MS-Celeb-1M using subject clustering

Related efforts
• Performance bounds for deep networks• When training and test data have the same distribution
• When training and test data have different distributions
• Smart sampling of training data
• Expression recognition, attribute extraction
• Generative adversarial networks and domain adaptation

Open issues• Deep networks are here to stay
• Great equalizer!• Accessible to high school students • Easily portable software
• Deep features and networks allow end-to-end solutions to challenging problems provided• “Sufficient” annotated data is available
• Challenges remain• Incorporating invariances• Handling occlusions and other degradations• Reasonable training data• Are all data good? Strategies for reducing the size of training data.
• Theoretical understanding • Adversarial training• Incorporating domain knowledge