
Deep Learning in NLP: The Past, The Present, and The Future...Deep Learning in NLP: The Past, The...
38
Deep Learning in NLP: The Past, The Present, and The Future Tomas Mikolov, Facebook AI Research Meaning in Context Workshop Munich, 2015
Transcript of Deep Learning in NLP: The Past, The Present, and The Future...Deep Learning in NLP: The Past, The...

Deep Learning in NLP: The Past, The Present, and The Future
Tomas Mikolov, Facebook AI Research
Meaning in Context Workshop
Munich, 2015

Deep Learning in NLP: Overview
In this talk, focus on:
• The fundamental concepts
• Understanding the hype around deep learning
• Possible directions for future research
Tomas Mikolov, FAIR 2

Neural networks: motivation
• To come up with more precise way how to represent and model words, documents and language than the basic approaches (n-grams, word classes, logistic regression / SVM)
• There is nothing that neural networks can do in NLP that the basic techniques completely fail at
• But: the victory in competitions goes to the best, thus few percent gain in accuracy counts!
Tomas Mikolov, FAIR 3

Neuron (perceptron)
Tomas Mikolov, FAIR 4

Neuron (perceptron)
Tomas Mikolov, FAIR
Input synapses
5
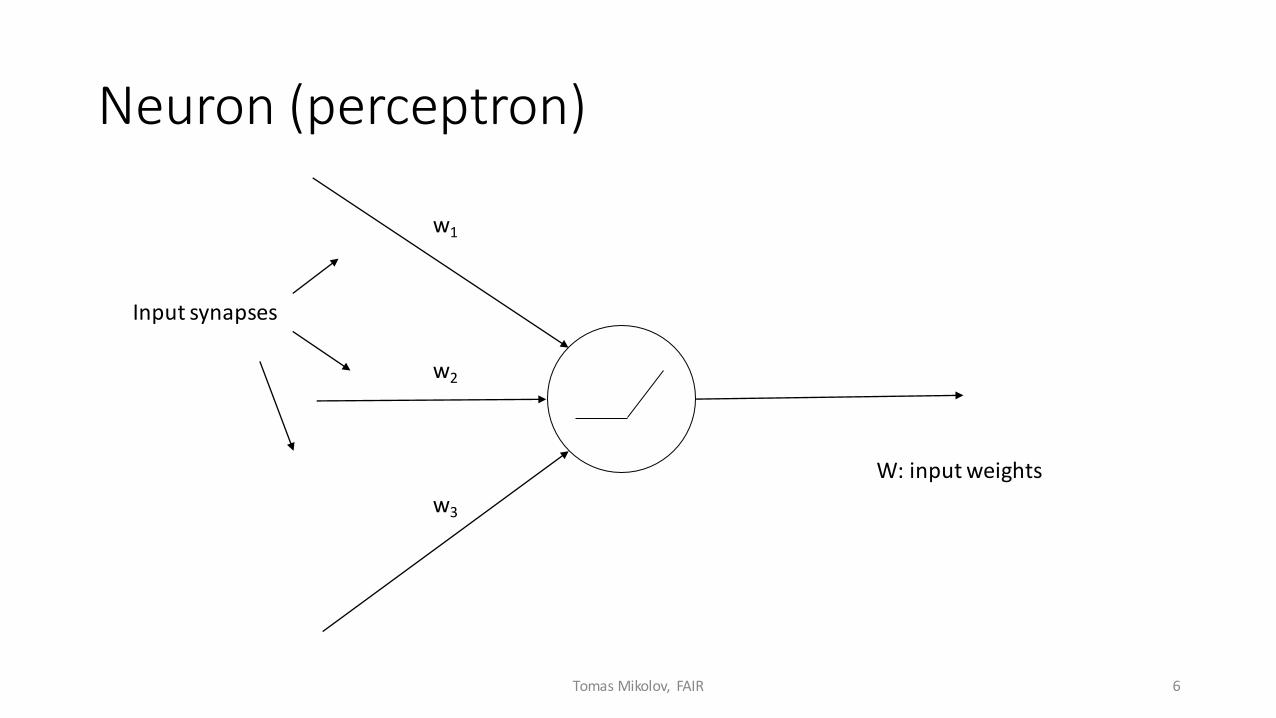
Neuron (perceptron)
Tomas Mikolov, FAIR
Input synapses
w1
w2
w3
W: input weights
6
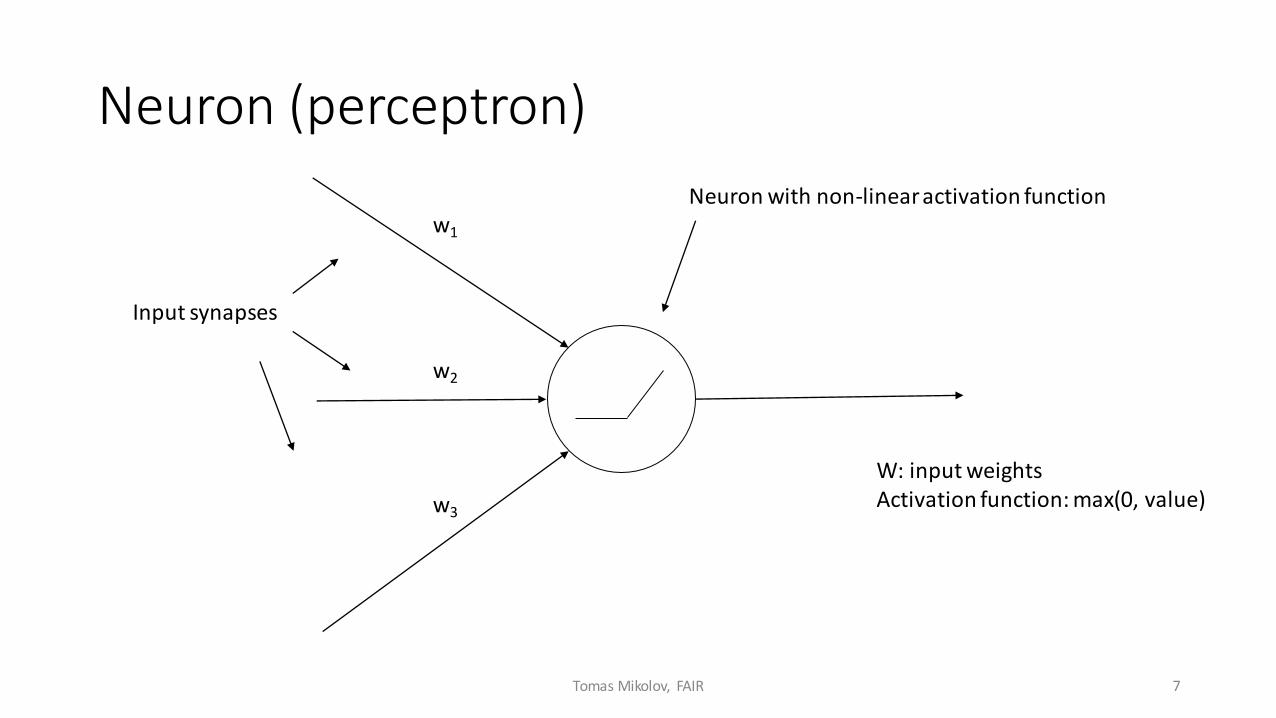
Neuron (perceptron)
Tomas Mikolov, FAIR
Input synapses
w1
w2
w3
W: input weightsActivation function: max(0, value)
Neuron with non-linear activation function
7

Neuron (perceptron)
Tomas Mikolov, FAIR
Input synapses
w1
w2
w3
W: input weightsActivation function: max(0, value)
Neuron with non-linear activation function
Output (axon)
8

Neuron (perceptron)
Tomas Mikolov, FAIR
Input synapses
w1
w2
w3
W: input weightsActivation function: max(0, value)I: input signal
𝑂𝑢𝑡𝑝𝑢𝑡 = max(0, 𝐼 ∙ 𝑊)
Neuron with non-linear activation function
Output (axon)
i1
i3
i2
9

Neuron (perceptron)
• It should be noted that the perceptron model is quite different from the biological neurons (those communicate by sending spike signals at different frequencies)
• The learning seems also quite different
• It would be better to think of artificial neural networks as non-linear projections of data
Tomas Mikolov, FAIR 10

Activation function
• In the previous example, we used max(0, value): this is usually referred to as “rectified activation function”
• Many other functions can be used
• Other common ones: sigmoid, tanh
Tomas Mikolov, FAIR
Figure from Wikipedia
11

Activation function
• The critical part is however the non-linearity
• Example: XOR problem
• There is no linear classifier that can solve this problem:
Tomas Mikolov, FAIR
?
12

Non-linearity: example
Intuitive NLP example:
• Input: sequence of words
• Output: binary classification (for example, positive / negative sentiment)
• Input: “the idea was not bad”
• Non-linear classifier can learn that “not” and “bad” next to each other means something else than “not” or “bad” itself
• “not bad” != “not” + “bad”
Tomas Mikolov, FAIR 13

Activation function
• The non-linearity is a crucial concept that gives neural networks more representational power compared to some other techniques (linear SVM, logistic regression)
• Without the non-linearity, it is not possible to model certain combinations of features (like Boolean XOR function), unless we do manual feature engineering
Tomas Mikolov, FAIR 14

Hidden layer
• Hidden layer represents learned non-linear combination of input features (this is different than SVMs with non-linear kernels that are not learned)
• With hidden layer, we can solve the XOR problem:
1. some neurons in the hidden layer will activate only for some combination of input features
2. the output layer can represent combination of the activations of the hidden neurons
Tomas Mikolov, FAIR 15

Hidden layer
• Neural net with one hidden layer is universal approximator: it can represent any function
• However, not all functions can be represented efficiently with a single hidden layer – we shall see that in the deep learning section
Tomas Mikolov, FAIR 16

Neural network layers
Tomas Mikolov, FAIR
INPUT LAYER HIDDEN LAYER OUTPUT LAYER
17

Objective function
• Objective function defines how well does the neural network perform some task
• The goal of training is to adapt the weights so that the objective function is maximized / minimized
• Example: classification accuracy, reconstruction error
Tomas Mikolov, FAIR 18

Training of neural networks
• There are many ways how to train neural networks
• The most widely used and successful in practice is to use stochastic gradient descent and backpropagation
• Many algorithms are introduced as superior to SGD, but when properly compared, the gains are not easy to achieve
Tomas Mikolov, FAIR 19

Deep Learning
• Deep model architecture is about having more computational steps (hidden layers) in the model
• Deep learning aims to learn patterns that cannot be learned efficiently with shallow models
Tomas Mikolov, FAIR 20

Deep Learning
• But: it was previously mentioned that one hidden layer neural net is universal approximator as it can represent any function
• Why would we need more hidden layers then?
Tomas Mikolov, FAIR 21

Deep Learning
• The crucial part to understand deep learning is the efficiency
• The “universal approximator” argument says nothing else than that a neural net with non-linearities can work as a look-up table to represent any function: some neurons can activate only for some specific range of input values
Tomas Mikolov, FAIR 22

Deep Learning
• Look-up table is not efficient: for certain functions, we would need exponentially many hidden units with increasing size of the input layer
• Example: parity function (N bits at input, output is 1 if the number of active input bits is odd) (Perceptrons, Minsky & Papert 1969)
Tomas Mikolov, FAIR 23

Deep Learning
• Having hidden layers exponentially larger than is necessary is bad
• If we cannot compactly represent patterns, we have to memorize them -> need exponentially more training examples
Tomas Mikolov, FAIR 24

Deep Learning
• Whenever we try to learn a complex function that is a composition of simpler functions, it may be beneficial to use deep architecture
Tomas Mikolov, FAIR
INPUT LAYER HIDDEN LAYER 1 HIDDEN LAYER 2 HIDDEN LAYER 3 OUTPUT LAYER
25

Deep Learning
• Historically, deep learning was assumed to be impossible to achieve by using SGD + backpropagation
• Recently there was a lot of success for tasks that contain signals that are very compositional (speech, vision) and where large amount of training data is available
Tomas Mikolov, FAIR 26

Deep Learning
• Deep learning is still an open research problem
• Many deep models have been proposed that do not learn anything else than a shallow (one hidden layer) model can learn: beware the hype!
• Not everything labeled “deep” is a successful example of deep learning
Tomas Mikolov, FAIR 27

Deep Learning in NLP: RNN language model
𝐬 𝑡 = 𝑓(𝐔𝐰 𝑡 +𝐖𝐬 𝑡 − 1 )𝐲 𝑡 = 𝑔(𝐕𝐬 𝑡 )
𝑓() is often sigmoid activation function:
𝑓 𝑧 =1
1 + 𝑒−𝑧
𝑔() is often the softmax function:
𝑔 𝑧𝑚 =𝑒𝑧𝑚
𝑘 𝑒𝑧𝑘
Tomas Mikolov, FAIR 28

Neural Networks for NLP
• More info in Coling 2014 tutorial:Using Neural Networks for Modelling and Representing Natural Languages
Tomas Mikolov, FAIR 29

Deep Learning: Understanding the Hype
• For researchers, it is important to understand which concepts do work, and which are just over-hyped
• The incentives in the last few years were too high to keep all researchers honest: hyping your work and (sometimes non-existing) contributions was rewarded by big companies
• Deep learning is sometimes like the moon landing / chess-playing computer: great for PR! (and, sometimes, quite useless too)
Tomas Mikolov, FAIR 30

Deep Learning: Understanding the Hype
• Because of the hype, it is difficult to distinguish which ideas truly work
• It is important to discuss which ideas do not work: this can save many people a lot of time!
Tomas Mikolov, FAIR 31

“Big, Deep Models Can Solve Everything”
• Claim: deep learning can do everything, just use big models with many hidden layers! And a lot of training data!
• Truth: it is as easy to break the current state of the art deep models as it was done already in the 60’s
• Example: memorization of variable-length sequence of symbols breaks all standard models (RNNs, LSTMs)
Tomas Mikolov, FAIR 32

Future of Deep Learning Research (for NLP)
• Using more hidden layers, more neurons and more data will not lead to new breakthroughs: this has already been done (incremental progress is however still possible)
• The existing techniques can still be applied to new datasets, but the novelty of such research is limited
• We should redefine our goals and be more ambitious: the new task should be AI-style language understanding (no fake chatbots…)
Tomas Mikolov, FAIR 33

Future of Deep Learning Research (for NLP)
In the future, we will probably need:
• Novel datasets that allow complex patterns in language to be learned
• Novel machine learning techniques that can represent and discover complex patterns
Tomas Mikolov, FAIR 34

Stack-Augmented RNN• Can discover some complex
patterns in sequential data• Learns how to construct and
operate structured long term memory
• Potentially unlimited capacity
Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets, Joulin & Mikolov, NIPS 2015
Code available: https://github.com/facebook/Stack-RNNTomas Mikolov, FAIR 35

Results
Counting patterns
Memorization patterns Binary additionTomas Mikolov, FAIR 36

Learning Binary Addition From Scratch
Learned computation performed by stacks
Tomas Mikolov, FAIR 37

Conclusion
• Basic concepts in artificial neural networks are simple
• There is a lot of hype around deep learning and a lot of big claims, many are overstated
• There is still a lot of research to be done in the future, particularlyin NLP: we need to learn more (complex) patterns
Tomas Mikolov, FAIR 38


















