
Going in the Deep-End: Batch-Generating Question Banks for ...
Upload
luba-elliottCategory
view
201download
0
Deep Image Generating Models /
Imperial College London
2016-11-23
Kai Arulkumaran @KaiLashArul

ForewordDeep learning is a great creative tool
We can generate novel media in unexpected ways (e.g. DeepDream/Inceptionism [1])
We can remix media (e.g. style transfer [2])
We can directly use deep generative models
The following applies to more than just images

SummaryGenerative adversarial networks (GANs) [3]
Variational autoencoders (VAEs) [4, 5]
Autoregressive networks [6-8]

GenerationLet's create an image using a starting value
Speci�cally, some random noise, maybe sampled from a Gaussian: z ∼ (0, 1)
Create a transformation model that takes and returns an image
f z
x
Images from space are generated from a value ∼ P(Z)
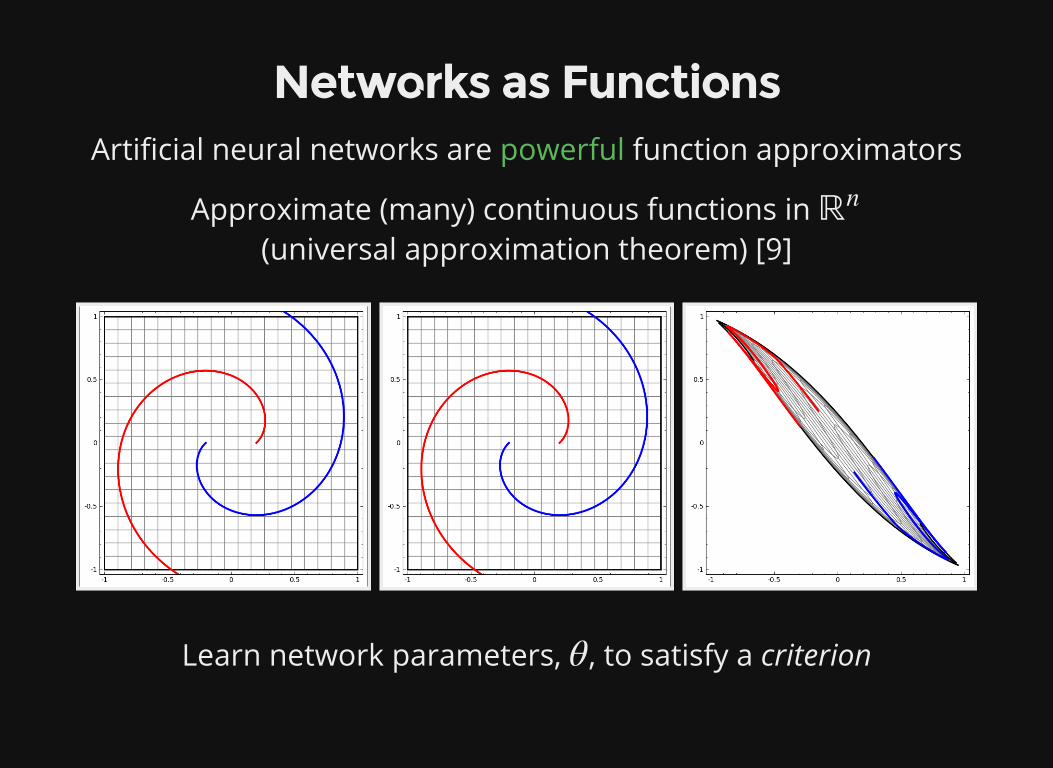
Networks as FunctionsArti�cial neural networks are powerful function approximators
Approximate (many) continuous functions in (universal approximation theorem) [9]
ℝn
Learn network parameters, , to satisfy a criterionθ

Generator FunctionLearn a generator function, , that creates images: G(z; θ) x = G(z)
What criterion to train ?G

Discriminator FunctionTrain a discriminator function, , to label images: D(x;ϕ) y = D(x)
Learn to distinguish real images: when Learn to distinguish fake images: when
(y = 1) x ∼ p(X)(y = 0) x = G(z)
Adjust to maximise both criterionsϕ

Minimax GameTrain using the minimax rule from game theory [3]G
[log(D(x))] + [1 − log(D(G(z)))]minθ maxϕ �x∼p(X) �z∼p(Z)
never sees real images, but learns to create images that would fool
GD
GANs turn density estimation into an easier problem - classi�cation

DCGANConvolutional neural networks improve GAN capabilities [10]

GAN GenerationsPreserve general image statistics, sharp edges
Fail to preserve spatial relationships/coherence

InterpolationsTake 2 samples, linearly spherically interpolate [11], generate

Image ArithmeticNetworks learn a manifold (locally Euclidean space)

Conditional GANsUse information about class of object [12-15]

InferenceImpose more meaning on latent space
Observation is generated by a latent variable x z
Inference tries to retrieve which was responsible for which z x
Probabilistically, generation is and inference is
x ∼ P(x|z)z ∼ P(z|x)
Autoencoders learn both together
for "true" distributions, for model distributionsP Q

AutoencodersNeural network encoder, , with encoding e z = e(x)
Decoder, , with decoding d x = d(z)
learns , learns e Q(z|x; θ) d Q(x|z; θ)
Compose networks, , and train jointlyd ∘ e
Criterion is minimising distance between real input and reconstruction
x
d(e(x))
Mean square error/cross entropy criterions correspond to maximising likelihood of reconstruction

Generative AutoencodersConstrain encodings to follow a prior probability distribution, P(Z)
Idea 1: Directly sample from stochastic neurons
Optimisation requires estimating gradient over expectation, naively requiring (Monte Carlo) sampling
Idea 2: Reparameterise to a deterministic function + noise source [4]
Encoder outputs parameters for a probability distribution
Criterion penalises di�erence between desired distribution parameters and encoder outputs
Stochastic samples via the reparameterisation trick

Variational AutoencodersVAEs are latent variable models trained with variational inference
Maximise variational/evidence lower bound
[log(p(x|z))] − [Q(Z|X)‖P(Z)]�q(z|x) DKL
KL divergence penalises deviating from Q(Z|X) P(Z)
Variational Bayes w/ mean-�eld approximation reverse KL divergence⟹

Divergence BehavioursForward KL divergence, , is "zero-avoiding",
covering, ensures whenever [P‖Q]DKL
q(z) > 0 p(z) > 0
Reverse KL divergence, , is "zero-forcing", �nds modes[Q‖P]DKL
Jensen-Shannon divergence = [P‖ ] + [Q‖ ]DJS
12DKL
P+Q
212DKL
P+Q
2
GANs minimise JS divergence assuming is Bayes optimalD

Discriminative RegularisationReconstruction (bottom) of real image (middle) is blurry
in uncertain regions (such as hair detail)
Discriminative loss using pretrained network (top) [16, 17]

MCMC Sampling does not perfectly match ; resolve with sampling [18]Q(Z) P(Z)
Sequential DrawingPaint on canvas using recurrent neural network [19]
DRAW: A Recurrent Neural Network For Image G...

Conditional on TextCondition generation on a text caption [20]

Independence AssumptionSo far, pixels were created independently of each other,
given the penultimate layer
Autoregressive networks generate pixels one at a time, conditional on the previous [6-8]

ConclusionDeep generative models have improved a lot in a few years
Images are intuitively interpretable for qualitative evaluation
Generative models are hard to evaluate quantitatively [21]
Potential uses, e.g. procedural content generation
For more depth, see Building Machines that Imagine and Reason

Figures1. 2. 3. 4. 5. 6. 7. 8.
Google Research Blog: Inceptionism: Going Deeper into Neural NetworksNeural Networks, Manifolds, and Topology -- colah's blogNewmu/dcgan_code - GitHubPattern Recognition and Machine Learning | Christopher Bishop | Springer[1602.03220] Discriminative Regularization for Generative Models[1610.09296] Improving Sampling from Generative Autoencoders with Markov ChainsDRAW: A Recurrent Neural Network For Image Generation by Google DeepMind - YouTube[1511.02793] Generating Images from Captions with Attention

References1. Mordvintsev, A., Olah, C., & Tyka, M. (2015). Inceptionism: Going deeper into neural networks. Google Research Blog.2. Gatys, L. A., Ecker, A. S., & Bethge, M. (2015). A neural algorithm of artistic style. arXiv preprint arXiv:1508.06576.3. Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. In Advances in
Neural Information Processing Systems (pp. 2672-2680).4. Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.5. Rezende, D. J., Mohamed, S., & Wierstra, D. (2014). Stochastic backpropagation and approximate inference in deep generative models. arXiv
preprint arXiv:1401.4082.6. Larochelle, H., & Murray, I. (2011). The Neural Autoregressive Distribution Estimator. In AISTATS (Vol. 1, p. 2).7. Gregor, K., Danihelka, I., Mnih, A., Blundell, C., & Wierstra, D. (2013). Deep autoregressive networks. arXiv preprint arXiv:1310.8499.8. van den Oord, A., Kalchbrenner, N., & Kavukcuoglu, K. (2016). Pixel Recurrent Neural Networks. arXiv preprint arXiv:1601.06759.9. Hornik, K. (1991). Approximation capabilities of multilayer feedforward networks. Neural networks, 4(2), 251-257.
10. Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks.arXiv preprint arXiv:1511.06434.
11. White, T. (2016). Sampling Generative Networks: Notes on a Few E�ective Techniques. arXiv preprint arXiv:1609.04468.12. Mirza, M., & Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784.13. Odena, A. (2016). Semi-Supervised Learning with Generative Adversarial Networks. arXiv preprint arXiv:1606.01583.14. Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved techniques for training gans. arXiv preprint
arXiv:1606.03498.15. Odena, A., Olah, C., & Shlens, J. (2016). Conditional Image Synthesis With Auxiliary Classi�er GANs. arXiv preprint arXiv:1610.09585.16. Dosovitskiy, A., & Brox, T. (2016). Generating images with perceptual similarity metrics based on deep networks. arXiv preprint
arXiv:1602.02644.17. Lamb, A., Dumoulin, V., & Courville, A. (2016). Discriminative Regularization for Generative Models. arXiv preprint arXiv:1602.03220.18. Arulkumaran, K., Creswell, A., & Bharath, A. A. (2016). Improving Sampling from Generative Autoencoders with Markov Chains. arXiv preprint
arXiv:1610.09296.19. Gregor, K., Danihelka, I., Graves, A., Rezende, D. J., & Wierstra, D. (2015). DRAW: A recurrent neural network for image generation. arXiv
preprint arXiv:1502.04623.20. Mansimov, E., Parisotto, E., Ba, J. L., & Salakhutdinov, R. (2015). Generating images from captions with attention. arXiv preprint
arXiv:1511.02793.21. Theis, L., Oord, A. V. D., & Bethge, M. (2015). A note on the evaluation of generative models. arXiv preprint arXiv:1511.01844.

ThanksFriends on Twitter for posts and discussions
Toni Creswell, equal contributor on [16]
Colleagues at BICV and Computational Neurodynamics


















