
Decision Trees and Naïve Bayes
17
Decision Trees and Naïve Bayes 3/29/17
Transcript of Decision Trees and Naïve Bayes

DecisionTreesandNaïveBayes
3/29/17
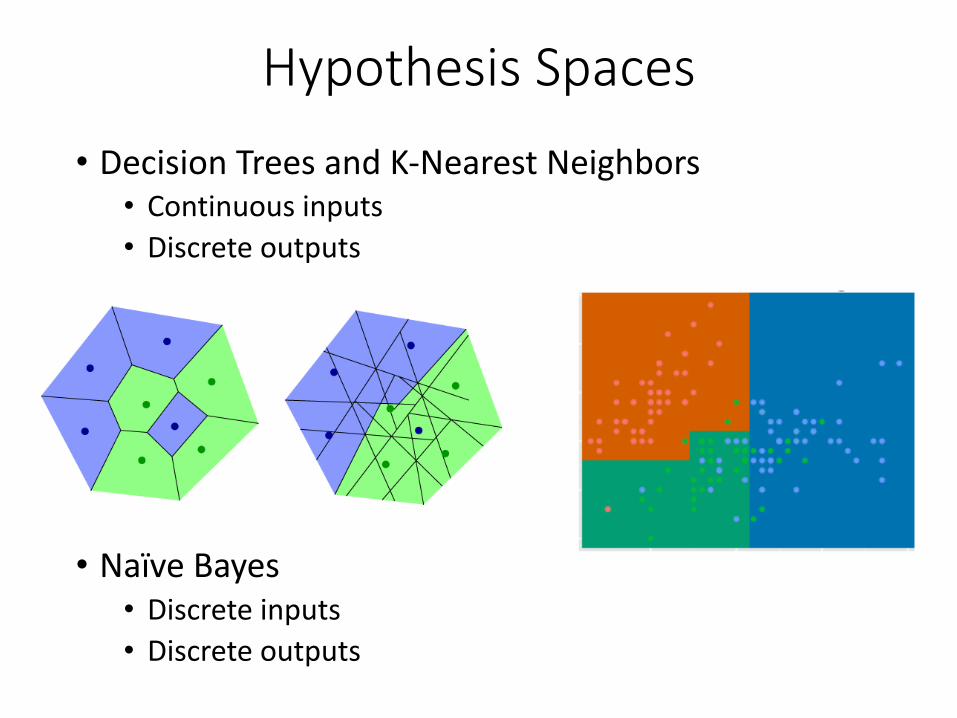
HypothesisSpaces• DecisionTreesandK-NearestNeighbors• Continuousinputs• Discreteoutputs
• NaïveBayes• Discreteinputs• Discreteoutputs
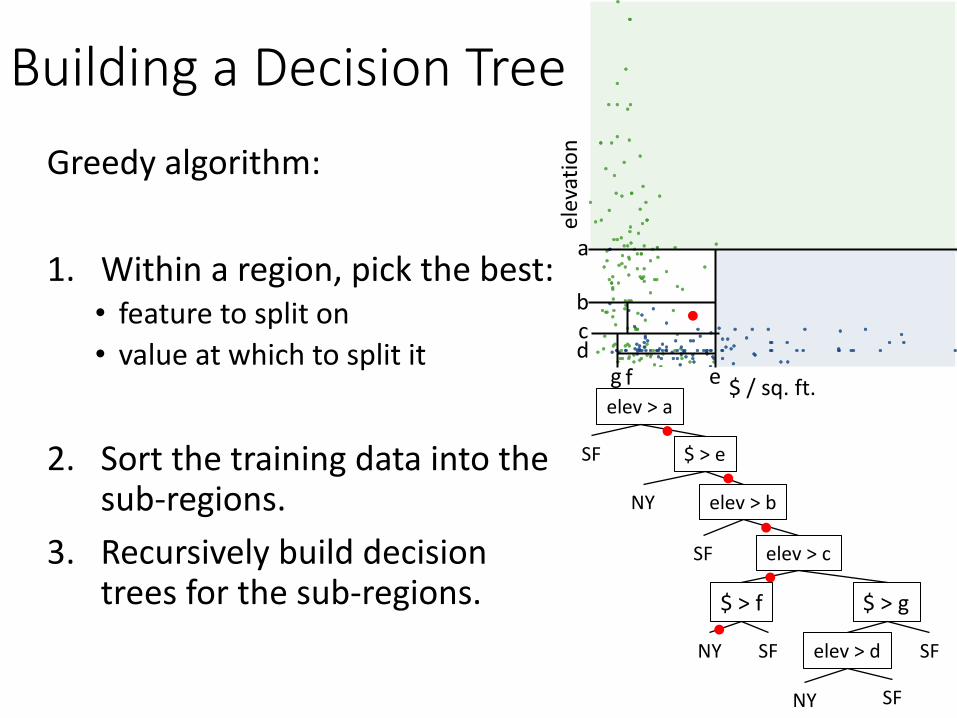
BuildingaDecisionTreeGreedyalgorithm:
1. Withinaregion,pickthebest:• featuretospliton• valueatwhichtosplitit
2. Sortthetrainingdataintothesub-regions.
3. Recursivelybuilddecisiontreesforthesub-regions.
elevation
$/sq.ft.elev >a
elev >b
elev >c
$>e
$>f $>g
SF
NY
SF
elev >dNY SF SF
SFNY
a
e
bc
fgd

PickingtheBestSplitKeyidea:minimizeentropy
• Sisacollectionofpositiveandnegativeexamples• Pos:proportionofpositiveexamplesinS• Neg:proportionofnegativeexamplesinS
Entropy(S)=-Pos *log2(Pos)- Neg *log2(Neg)
• Entropyis0whenallmembersofSbelongtothesameclass,forexample:Pos =1andNeg =0• Entropyis1whenScontainsequalnumbersofpositiveandnegativeexamples:Pos =½andNeg =½

SearchingfortheBestSplitTryallfeatures.Tryallpossiblesplitsofthatfeature.IffeatureFis______,thereare________possiblesplitstoconsider.
• binary...one• discreteandordered...|F| - 1• discreteandunordered…2|F|- 1 – 1
• (twooptionsforwheretoputeachvalue)• continuous…|trainingset|- 1
• (anysplitbetweentwopointsisthesame)
NumberofvaluesFcouldhave

Canwedobetter?Tryallfeatures.Tryallpossiblesplitsofthatfeature.IffeatureFis______,thereare________possiblesplitstoconsider.
• binary...one• discreteandordered...|F|- 1• discreteandunordered…2|F|- 1 – 1
• (twooptionsforwheretoputeachvalue)• continuous…|trainingset|- 1
• (anysplitbetweentwopointsisthesame)
Howcanweavoidtryingallpossiblesplits?
BinarySearch Local
Search

Whendowestopsplitting?Badidea:• Wheneverytrainingpointisclassifiedcorrectly.• Whyisthisabadidea?• Overfitting
Betteridea:• Stopatsomelimitondepth,#points,orentropy• Howshouldwechoosethelimit?• Training/testsplit• Crossvalidation(moreonFriday)

BayesianApproachtoClassification
Keyidea:usetrainingdatatoestimateaprobabilityforeachlabelgivenaninput.
Classifyapointasitshighest-probabilitylabel.

EstimatingProbabilitiesfromDataSupposeweflipacoin10timesandobserve:
7 3
Whatdowebelievetobethetrue P(H )?
Nowsupposeweflipit1000timesandobserve:
700 300

PriorProbability
Weneedtocombineourinitialbeliefswithdata.
Empiricalfrequency:
Priorforacointoss:
Addm “observations”ofthepriortothedata:

EstimatingLabelProbabilities• Wewanttocompute• Conditionalonaparticularinputpointwhatistheprobabilityofeachlabel?
• Estimatingthisempiricallyrequiresmanyobservationsofeverypossibleinput.• Insuchacase,wearen’treallylearning:there’snogeneralizationtonewdata.
• Wewanttogeneralizefrommanytrainingpointstogetestimateaprobabilityatanunobservedtestpoint.

TheNaïvePartofNaïveBayes
Assumethatallfeaturesareindependent.
Thisletsusestimateprobabilitiesforeachfeatureseparately,thenmultiplythemtogether:
Thisassumptionisalmostneverliterallytrue,butmakestheestimationfeasibleandoftengivesagoodenoughclassifier.
P (l | x) = P (l | x1)P (l | x2) . . . P (l | xn)

EmpiricalProbabilitiesforClassification
Givenadatasetconsistingof• Inputs• Labesl l
Foreachpossiblevalueofxi andl,wecancomputeanempiricalfrequency:

BayesRule• Wecanempiricallyestimate• Butweactuallywant
• WecangetitusingBayesrule:

BayesRuleAppliedTocompute fromourdata,weneedtoestimatetwomorequantitiesfromdata:• P( x1 )• P( l )
• Thismeansdoingadditionalempiricalestimatesacrossourdatasetforeachpossiblevalueofeachinputdimensionandthelabel.

NaïveBayesTraining• Weneedtoestimatetheprobabilityofeachvalueforeachdimension• Forexample:P(x1 = 5)
• Weneedtoestimatetheprobabilityofeachlabel• Forexample:P(l = +1)
• Weneedtoestimatetheprobabilityofeachvalueforeachdimensionconditionaloneachlabel• Forexample:P(x1 = 5 | l = −1)
Alloftheseareestimatedempirically,withsomeprior(usuallyuniform).

NaïveBayesPredictionGivenanewinput:
Computeforeachpossiblelabel:
Usingthenaïveassumptionthisisestimatedas:
Returnthehighest-probabilitylabel.
P (l | x) = P (l)P (x1 | l)P (x2 | l)P (x3 | l)P (x)


















