
Decision Tree Induction in Hierarchic Distributed Systems With: Amir Bar-Or, Ran Wolff, Daniel...
14
Decision Tree Induction in Hierarchic Distributed Systems With: Amir Bar-Or, Ran Wolff, Daniel Keren
-
Upload
sheldon-marquess -
Category
Documents
-
view
214 -
download
0
Transcript of Decision Tree Induction in Hierarchic Distributed Systems With: Amir Bar-Or, Ran Wolff, Daniel...

Decision Tree Induction in Hierarchic Distributed
Systems
With:Amir Bar-Or, Ran Wolff, Daniel Keren

Motivation
Large distributed computation is costly
• Especially data intensive and synchronization intensive ones; e.g., data mining
• Decision tree induction:– Collect global statistics (thousands) for every
attribute (thousands) in every tree node (hundreds)
– Global statistics – global synchronization

Motivation
Hierarchy Helps
• Simplifies synchronization– Synchronize on each level
• Simplifies communication• An “industrial strength” architecture– The way real systems (including grids)
are often organized

Motivation
Mining highly dimensional data
• Thousands of sources • Central control• Examples:– Genomically enriched healthcare data– Text repositories

Objectives of the Algorithm
• Exact results– Common approaches would either• Collect a sample of the data• Build independent models at each site and
then use centralized meta-learning atop of them
• Communication efficiency– Naive approach: collect exact statistics
for each tree node would result in GBytes of communication

Decision tree in a Teaspoon
• A tree were at each level the learning samples are splitted according to one attribute’s value
• Hill-climbing heuristic is used to induce the tree– The attribute that maximized a gain
function is taken– Gain functions: Gini or Information Gain
• No real need to compute the gain

Main Idea
• Infer deterministic bounds on the gain of each attribute
• Improve bounds until best attribute is provenly better than the rest
• Communication efficiency is achieved because bounds require just limited data– Partial statistics for promising attributes– Rough bound on irrelevant attributes

Hierarchical Algorithm
• At each level of the hierarchy–Wait for reports from all descendants• Contain upper and lower bounds on the gain
of each attribute, number of samples from each class
– Use descendant's report to compute cumulative bounds
– If no clear separation, request descendants to tighten bounds by sending more data
– At worst, all data is gathered

Deterministic Bounds
• Upper bound
• Lower bound
iii nPGnPG /
2
111212
1
/1/1 n,nminn+nn+
PGPG

Performance Figures
• 99% reduction in communication bandwidth
• Out of 1000 SNP, only ~12 were reported to higher levels of the hierarchy
• Percent declines with hierarchy level
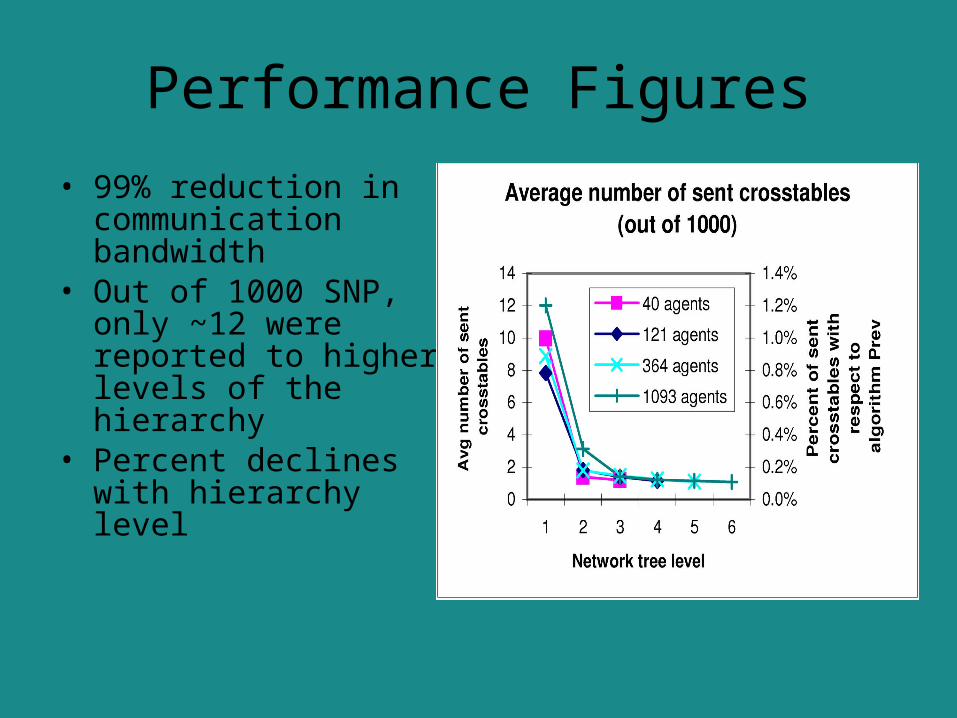
Performance Figures
• 99% reduction in communication bandwidth
• Out of 1000 SNP, only ~12 were reported to higher levels of the hierarchy
• Percent declines with hierarchy level

More Performance Figures
• Larger datasets require lower bandwidth
• Outlier noise is not a big issue– White noise even
better
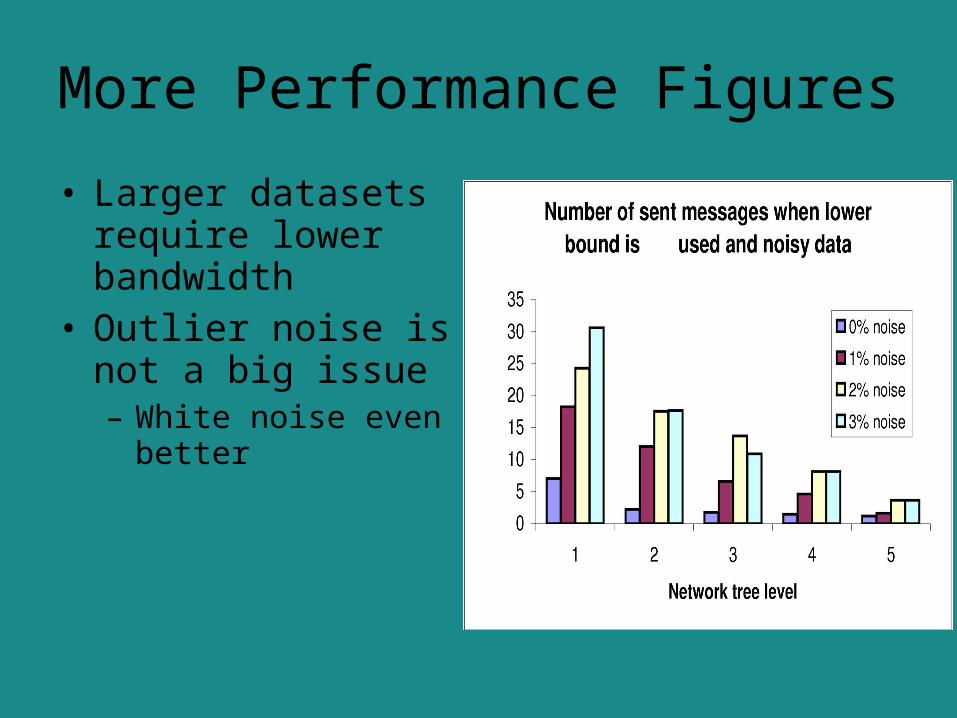
More Performance Figures
• Larger datasets require lower bandwidth
• Outlier noise is not a big issue– White noise even
better

Future Work
• Text mining• Incremental algorithm• Accommodation of failure• Testing on a real grid system• Is this a general framework?


















