
Dean Zadok Daniel McDuff Ashish Kapoor Microsoft Research, … · 2019-12-25 · Dean Zadok1;...
8
Affect-based Intrinsic Rewards for Exploration and Learning Dean Zadok 1,2* , Daniel McDuff 2 and Ashish Kapoor 2 Abstract— Positive affect has been linked to increased inter- est, curiosity and satisfaction in human learning. In reinforce- ment learning, extrinsic rewards are often sparse and difficult to define, intrinsically motivated learning can help address these challenges. We argue that positive affect is an important intrinsic reward that effectively helps drive exploration that is useful in gathering experiences. We present a novel approach leveraging a task-independent intrinsic reward function trained on spontaneous smile behavior that captures positive affect. To evaluate our approach we trained several downstream computer vision tasks on data collected with our policy and several baseline methods. We show that the policy based on intrinsic affective rewards successfully increases the duration of episodes, the area explored and reduces collisions. The impact is the increased speed of learning for several downstream computer vision tasks. I. INTRODUCTION Reinforcement learning (RL) is most commonly achieved via policy specific rewards that are designed for a predefined task or goal. Such extrinsic rewards can be sparse and difficult to define and/or only apply to the task at hand. We are interested in exploring the hypothesis that RL frameworks can be designed in a task agnostic fashion and that this will enable us to efficiently learn general representations that are useful in solving several tasks related to perception in robotics. In particular, we consider intrinsic rewards that are akin to affect mechanisms in humans and encourage efficient and safe explorations. These rewards are task-independent; thus, the experiences they gather are not specific to any particular activity and can be harnessed to build general representations. Furthermore, intrinsically motivated learning can have advantages over extrinsic rewards as they can reduce the sample complexity by producing rewards signals that indicate success or failure before the episode ends [1]. A key question we seek to answer is how to define such an intrinsic policy. We propose a framework that comprises mechanisms motivated by human affect. The core insight is that learning agents motivated by drives such as delight, fear, curiosity, hunger, etc. can garner rich experiences that are useful in solving multiple types of tasks. For instance, in reinforcement learning contexts there is a need for an agent to adequately explore its environment [2]. This can be performed by randomly selecting actions, or employing a more intelligent strategy, directed exploration, that incentives *This paper is the product of work during an internship at Microsoft Research. 1 Computer Science Department, Technion, Haifa, Israel [email protected] 2 Microsoft Research, Redmond, WA, USA {damcduff,akapoor}@microsoft.com Our implementation is on https://github.com/microsoft/affectbased. Fig. 1: We present a novel approach leveraging a positive affect-based intrinsic reward to motivate exploration. We use this policy to collect data for self-supervised pre-training and then use the learned representations for multiple downstream computer vision tasks. The red regions highlight the parts of the architecture trained at each stage. exploration of unexplored regions [3]. Curiosity is often defined by using the prediction error as the reward signal [4], [5]. As such, the uncertainty, or mistakes, made by the system are assumed to represent what the system should want to learn more about. However, this is a simplistic view as it fails to take into account that new stimuli are not always very informative or useful [6]. Savinov et al.uses the analogy of becoming glued to a TV channel surfing when there is the rest of the world outside the window. Their work proposed a new novelty bonus that features episodic memory. McDuff and Kapoor [1] took another approach focusing on safe exploration, proposing intrinsic rewards mimicking responses to that of a human’s sympathetic nervous system (SNS) to avoid catastrophic mistakes during the learning phase, but not necessarily promoting exploration. In this paper, we specifically focus on the role of pos- arXiv:1912.00403v6 [cs.CV] 2 Mar 2020
Transcript of Dean Zadok Daniel McDuff Ashish Kapoor Microsoft Research, … · 2019-12-25 · Dean Zadok1;...

Affect-based Intrinsic Rewards for Exploration and Learning
Dean Zadok1,2∗, Daniel McDuff2 and Ashish Kapoor2
Abstract— Positive affect has been linked to increased inter-est, curiosity and satisfaction in human learning. In reinforce-ment learning, extrinsic rewards are often sparse and difficultto define, intrinsically motivated learning can help addressthese challenges. We argue that positive affect is an importantintrinsic reward that effectively helps drive exploration that isuseful in gathering experiences. We present a novel approachleveraging a task-independent intrinsic reward function trainedon spontaneous smile behavior that captures positive affect. Toevaluate our approach we trained several downstream computervision tasks on data collected with our policy and severalbaseline methods. We show that the policy based on intrinsicaffective rewards successfully increases the duration of episodes,the area explored and reduces collisions. The impact is theincreased speed of learning for several downstream computervision tasks.
I. INTRODUCTION
Reinforcement learning (RL) is most commonly achievedvia policy specific rewards that are designed for a predefinedtask or goal. Such extrinsic rewards can be sparse anddifficult to define and/or only apply to the task at hand. Weare interested in exploring the hypothesis that RL frameworkscan be designed in a task agnostic fashion and that this willenable us to efficiently learn general representations thatare useful in solving several tasks related to perception inrobotics. In particular, we consider intrinsic rewards that areakin to affect mechanisms in humans and encourage efficientand safe explorations. These rewards are task-independent;thus, the experiences they gather are not specific to anyparticular activity and can be harnessed to build generalrepresentations. Furthermore, intrinsically motivated learningcan have advantages over extrinsic rewards as they canreduce the sample complexity by producing rewards signalsthat indicate success or failure before the episode ends [1].
A key question we seek to answer is how to define suchan intrinsic policy. We propose a framework that comprisesmechanisms motivated by human affect. The core insightis that learning agents motivated by drives such as delight,fear, curiosity, hunger, etc. can garner rich experiences thatare useful in solving multiple types of tasks. For instance,in reinforcement learning contexts there is a need for anagent to adequately explore its environment [2]. This canbe performed by randomly selecting actions, or employing amore intelligent strategy, directed exploration, that incentives
*This paper is the product of work during an internship at MicrosoftResearch.
1Computer Science Department, Technion, Haifa, [email protected]
2Microsoft Research, Redmond, WA, USA{damcduff,akapoor}@microsoft.com
Our implementation is on https://github.com/microsoft/affectbased.
Fig. 1: We present a novel approach leveraging a positiveaffect-based intrinsic reward to motivate exploration. We usethis policy to collect data for self-supervised pre-training andthen use the learned representations for multiple downstreamcomputer vision tasks. The red regions highlight the parts ofthe architecture trained at each stage.
exploration of unexplored regions [3]. Curiosity is oftendefined by using the prediction error as the reward signal [4],[5]. As such, the uncertainty, or mistakes, made by the systemare assumed to represent what the system should want tolearn more about. However, this is a simplistic view as itfails to take into account that new stimuli are not always veryinformative or useful [6]. Savinov et al.uses the analogy ofbecoming glued to a TV channel surfing when there is therest of the world outside the window. Their work proposeda new novelty bonus that features episodic memory. McDuffand Kapoor [1] took another approach focusing on safeexploration, proposing intrinsic rewards mimicking responsesto that of a human’s sympathetic nervous system (SNS) toavoid catastrophic mistakes during the learning phase, butnot necessarily promoting exploration.
In this paper, we specifically focus on the role of pos-
arX
iv:1
912.
0040
3v6
[cs
.CV
] 2
Mar
202
0

itive emotions and study how such intrinsic motivationscan enable learning agents to explore efficiently and learnuseful representations. In research on education, positiveaffect has been shown to be related to increased interest,involvement and arousal in learning contexts [7]. Kort etal.’s [8] model of emotions in learning posits that the statesof curiosity and satisfaction are associated with positiveaffect in the context of a constructive learning experience.Human physiology is informative about underlying affectivestates. Smile behavior [9] and physiological signals [1] havebeen effectively used as feedback in learning systems butnot in the context of intrinsic motivation or curiosity. Weleverage facial expressions as an unobtrusive measure ofexpressed positive affect. The key challenges here entail bothdesigning a system that can first model the intrinsic rewardappropriately, and then building a learning framework thatcan efficiently use the data to solve multiple downstreamtasks related to perception in robotics.
The core contributions of this paper (summarized in Fig. 1)are to (1) present a novel learning framework in whichreward mechanisms motivated by positive affect-mechanismsin humans are used to carry out explorations while beingagnostic to any specific tasks, (2) show how the data col-lected in such an unsupervised manner can be used to buildgeneral representations useful for solving downstream taskswith minimal task-specific fine-tuning, and (3) report theresults on experiments showing that the framework improvesexploration as well as enabling efficient learning for solvingmultiple data-driven tasks. In summary, we argue that suchan intrinsically motivated learning framework inspired byaffective mechanisms can be effective in increasing thecoverage during exploration, decreasing the number catas-trophic failures and that the garnered experiences can helpus learn general representations for solving tasks includingdepth estimation, scene segmentation, and sketch-to-imagetranslation.
II. RELATED WORK
Our work is inspired by intrinsically motivated learning[10], [11], [12]. One key property of intrinsic rewards is thatthey are non-sparse [6], this helps aid learning even if thesignal is weak. Much of the work in this domain uses acombination of intrinsic and extrinsic rewards in learning.Curiosity is one example of an intrinsic reward that grantsa bonus when an agent discovers something new and isvital for discovering successful behavioral strategies. Forexample, [4], [5] models curiosity via the prediction error asa surrogate and shows that such intrinsic reward mechanismperformed similarly to hand-designed extrinsic rewards inmany environments. Similarly, Savinov et al.[6] defined adifferent curiosity metric based on how many steps it takesto reach the current observation from those in memory,thus capturing environment dynamics. Their motivation wasthat previous approaches were too simplistic in assumingthat all changes in the environment should be consideredequal. McDuff and Kapoor [1] provided an example ofhow an intrinsic reward mechanism could motivate safer
learning, utilizing human physiological responses to shortenthe training time and avoid critical states. Our work isinspired by the prior art, but with the key distinction that wespecifically aim to build intrinsic reward mechanisms thatare visceral and trained on signals correlated with humanaffective responses.
Imitation learning (IL) is a popular method for derivingpolicies. In IL, the model is trained on previously generatedexamples to imitate the recorded behavior. It has beensuccessfully implemented using data collected from manydomains [13], [14], [15], [16], [17], [18]. Simulated environ-ments have been successfully used for training and evaluatingIL systems [19], [20]. We use IL as a baseline in our workand perform experiments to show how a combination of ILand positive affect-based rewards can lead to greater andsafer exploration.
One of our goals is to explore whether our intrinsicmotivation policy can help us learn general representations.Fortunately, the rise of unsupervised generative models,such as generative adversarial networks (GANs) [21] andvariational auto-encoders (VAE) [22], has led to progressacross many interesting challenges in computer vision thatinvolve image-to-image translation [23], [24]. In our work,we use three tasks in our data evaluation process: scene seg-mentation [25], depth estimation [26], and sketch-to-imagetranslation [27]. The first two tasks are common in drivingscenarios and augmented reality [28], [29], [30], while thethird is known for helping people render visual content [31]or synthesize imaginary images [32]. In this paper, we showthat by pre-training a VAE in a self-supervised way firstusing our exploration policy we can obtain better results onall three tasks.
III. OUR FRAMEWORK
Fig. 1 describes the overall framework. The core ideabehind the proposed methodology is that the agents haveintrinsic motivations that lead to extensive exploration. Con-sequently, an agent on its own is able to gather experiencesand data in a wide variety of conditions. Note that unliketraditional machine intelligence approaches, the agent isnot fixated on a given task - all it is encouraged to dois explore as extensively as possible without getting intoperilous situations. The rich data that is being gathered thenneeds to be harnessed into building representations that willeventually be useful in solving many perceptions tasks. Thus,the framework consists of three core components: (1) Apositive-affect based exploration policy, (2) a self-supervisedrepresentation learning component and (3) mechanisms thatutilize these representations efficiently to solve various tasks.
A. Affect-Based Exploration Policy
The approach here is to create a model that encouragesthe agent to explore the environment. We want a rewardmechanism that positively reinforces behaviors that mimicsa human’s affective responses and lead to discovery and joy.Positive Intrinsic Reward Mechanism: In our work, weuse a Convolutional Neural Network (CNN) to model the

affective responses of a human, as if we were in the samescenario as the agent. We train the CNN model to predicthuman smile responses as the exploration evolves. Based onthe fact that positive affect plays a central role in curiosityand learning [8], we chose to measure smiles as an ap-proximate measure of positive affect. Smiles are consistentlylinked with positive emotional valence [33], [34] and have along history of study [35] using electromyography [33] andautomated facial coding [36]. We must emphasize that in thiswork we were not attempting to model the psychologicalprocesses that cause people to smile explicitly. We areonly using smiles as an outward indicator of situations thatare correlated with positive affect as people explore newenvironments. In particular, the NN was trained to infer thereward h(xi, a) directly given that an action a was takenwhen at state xi. We defer the details of the NN architecture,the process of data collection and the training procedure toSections IV and V.Choosing Actions with Intrinsic Rewards: Given theintrinsic reward mechanism, we can use any off-the-shelfsequential decision-making framework, such as RL [1], tolearn a policy. It is also feasible to modify an existingpolicy that is trained to explore or collect data. While theformer approach is a desirable one theoretically, it requiresa very large number of training episodes to return a usefulpolicy. We focus on the later, where we assume there existsa function f(xi) which can predict a vector of actionsprobabilities p(a) when the agent observes state xi. Formally,given an observation xi and a model f , the next action, ai+1,is gets selected as: ai+1 = argmaxa f(xi). Such a functioncan be trained on human demonstrations while they explorethe environment.
We then use the intrinsic positive affect model to changethe action selection such that it biases the actions thatpromise to provide better intrinsic rewards. Intuitively, in-stead of simply using the output of the pre-trained policy fto decide on the next action, we consider the impact of theintrinsic motivation for every possible action consideration.Formally, given the positive affect model h, a pre-trainedexploration policy f , observation xi, the next action, ai+1,being selected becomes:
ai+1 = argmaxa
f(xi) + γh(xi, a) (1)
The above equation adds a weighted intrinsic motivationcomponent to the action probabilities from the original modelf . The weighting parameter γ defines the trade-off betweenthe original policy and the effect of the intrinsic reward.
B. Self-Supervised Learning
Given the exploration policy, the agent has the ability toexplore and collect rich data. The next component aims to usethis data to build rich representations that eventually could beused for various visual recognition and understanding tasks.
The challenge here is that since the collected data wastask agnostic there are no clear labels that could be usedfor supervised learning. We consequently, use the task of
jointly learning an autoencoder and decoder, through a low-dimensional latent representation. Formally, we use a varia-tional autoencoder (VAE) to build such representations. Forexample, a VAE can be trained to restore just the input image,with the loss constructed as the combination of negative log-likelihood and KL divergence, as follows:
L(θ, φ) = −Ez∼qθ(z|x)[log pφ(x|z)]+KL(qθ(z|x)||pφ(z))
(2)
Where the encoder is denoted by qθ, the decoder is denotedby pφ and z denotes the low-dimensional projection ofthe input x. The key intuition here is that if the VAEcan successfully encode and decode frames then implicitlyit is considering aspects such as depth, segmentation, andtextures that are critical to making successful predictions.Thus, it should be possible to tweak and fine-tune these VAEnetworks to solve a host of visual recognition and perceptiontasks with minimal effort.
C. Fine-tuning for Vision Tasks
Given the VAE representation, our goal now is to reuse thelearned weights to solve standard machine perception tasks.Formally, given some labeled data corresponding to a visualtask, similar to supervised learning, we optimize the negativelog-likelihood:
L(φ) = −Ez∼qθ(z|x)[log pφ(x|z)] (3)
Note that the goal is to minimally modify the network. Inour experiments, we show how we can solve depth mapestimation and scene segmentation by only tweaking theweights for the first or last few layers just before the decoderoutput. We also show how we can use those weights forsketch-to-image translation, even with a small amount ofannotated samples.
IV. EXPERIMENTS
We conducted experiments to analyze (1) the potentialadvantages of affect-based exploration policy over otherheuristics, (2) the ability to learn general representations and(3) if it was possible to solve diverse computer vision tasksby building upon and minimally modifying the model.
We used a high fidelity simulation environment [37] forautonomous systems, contains a customized 3D maze (di-mensions: 2,490 meters by 1,500 meters), a top-down viewcan be seen in Fig. 3. The maze is composed of walls andramps, frames from the environment can be seen in Fig. 2.The agent we used was a vehicle capable of maneuveringcomfortably within the maze. To generate random startingpoints that allowed us to deploy the agent into the maze,we constructed a navigable area, according to the vehicledimensions and surroundings (the green region in Fig. 3).
A. Data and Model Training
Affect-based Intrinsic Reward: We collected data fromfive subjects (four males, one female; ages: 23 - 40 years)exploring in the simulated environment. All participants werequalified drivers with multiple years of driving experience.
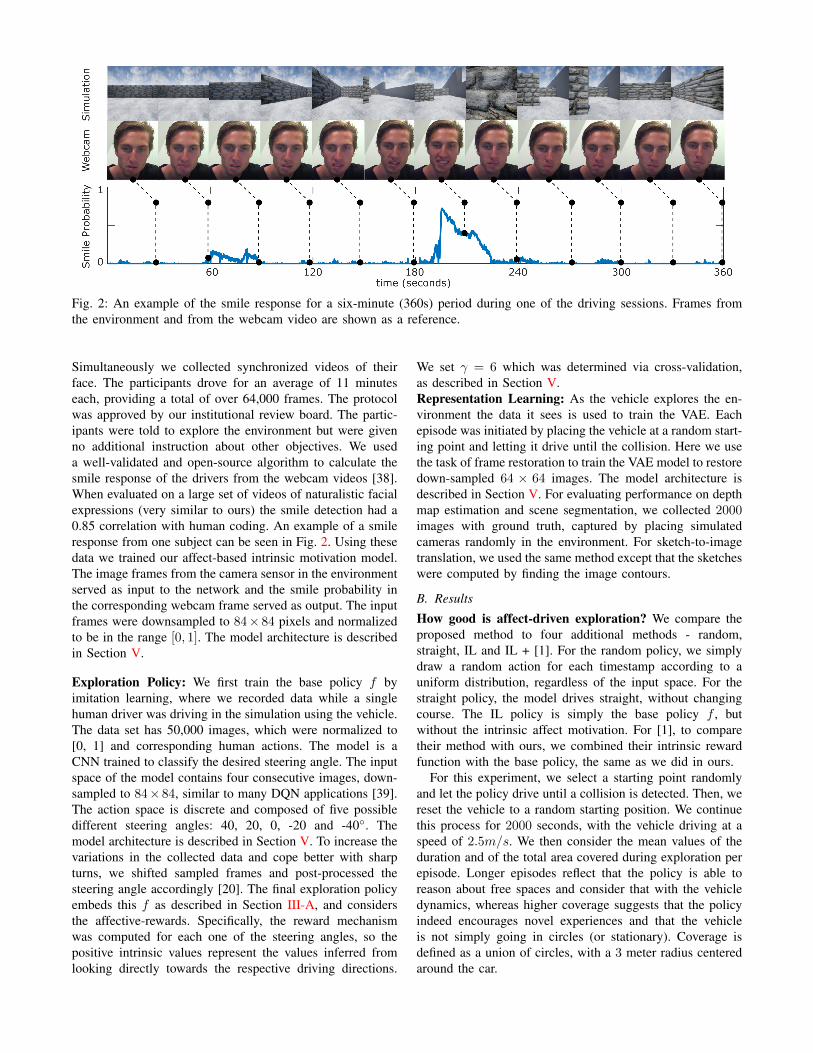
Fig. 2: An example of the smile response for a six-minute (360s) period during one of the driving sessions. Frames fromthe environment and from the webcam video are shown as a reference.
Simultaneously we collected synchronized videos of theirface. The participants drove for an average of 11 minuteseach, providing a total of over 64,000 frames. The protocolwas approved by our institutional review board. The partic-ipants were told to explore the environment but were givenno additional instruction about other objectives. We useda well-validated and open-source algorithm to calculate thesmile response of the drivers from the webcam videos [38].When evaluated on a large set of videos of naturalistic facialexpressions (very similar to ours) the smile detection had a0.85 correlation with human coding. An example of a smileresponse from one subject can be seen in Fig. 2. Using thesedata we trained our affect-based intrinsic motivation model.The image frames from the camera sensor in the environmentserved as input to the network and the smile probability inthe corresponding webcam frame served as output. The inputframes were downsampled to 84× 84 pixels and normalizedto be in the range [0, 1]. The model architecture is describedin Section V.
Exploration Policy: We first train the base policy f byimitation learning, where we recorded data while a singlehuman driver was driving in the simulation using the vehicle.The data set has 50,000 images, which were normalized to[0, 1] and corresponding human actions. The model is aCNN trained to classify the desired steering angle. The inputspace of the model contains four consecutive images, down-sampled to 84×84, similar to many DQN applications [39].The action space is discrete and composed of five possibledifferent steering angles: 40, 20, 0, -20 and -40◦. Themodel architecture is described in Section V. To increase thevariations in the collected data and cope better with sharpturns, we shifted sampled frames and post-processed thesteering angle accordingly [20]. The final exploration policyembeds this f as described in Section III-A, and considersthe affective-rewards. Specifically, the reward mechanismwas computed for each one of the steering angles, so thepositive intrinsic values represent the values inferred fromlooking directly towards the respective driving directions.
We set γ = 6 which was determined via cross-validation,as described in Section V.Representation Learning: As the vehicle explores the en-vironment the data it sees is used to train the VAE. Eachepisode was initiated by placing the vehicle at a random start-ing point and letting it drive until the collision. Here we usethe task of frame restoration to train the VAE model to restoredown-sampled 64 × 64 images. The model architecture isdescribed in Section V. For evaluating performance on depthmap estimation and scene segmentation, we collected 2000images with ground truth, captured by placing simulatedcameras randomly in the environment. For sketch-to-imagetranslation, we used the same method except that the sketcheswere computed by finding the image contours.
B. Results
How good is affect-driven exploration? We compare theproposed method to four additional methods - random,straight, IL and IL + [1]. For the random policy, we simplydraw a random action for each timestamp according to auniform distribution, regardless of the input space. For thestraight policy, the model drives straight, without changingcourse. The IL policy is simply the base policy f , butwithout the intrinsic affect motivation. For [1], to comparetheir method with ours, we combined their intrinsic rewardfunction with the base policy, the same as we did in ours.
For this experiment, we select a starting point randomlyand let the policy drive until a collision is detected. Then, wereset the vehicle to a random starting position. We continuethis process for 2000 seconds, with the vehicle driving at aspeed of 2.5m/s. We then consider the mean values of theduration and of the total area covered during exploration perepisode. Longer episodes reflect that the policy is able toreason about free spaces and consider that with the vehicledynamics, whereas higher coverage suggests that the policyindeed encourages novel experiences and that the vehicleis not simply going in circles (or stationary). Coverage isdefined as a union of circles, with a 3 meter radius centeredaround the car.
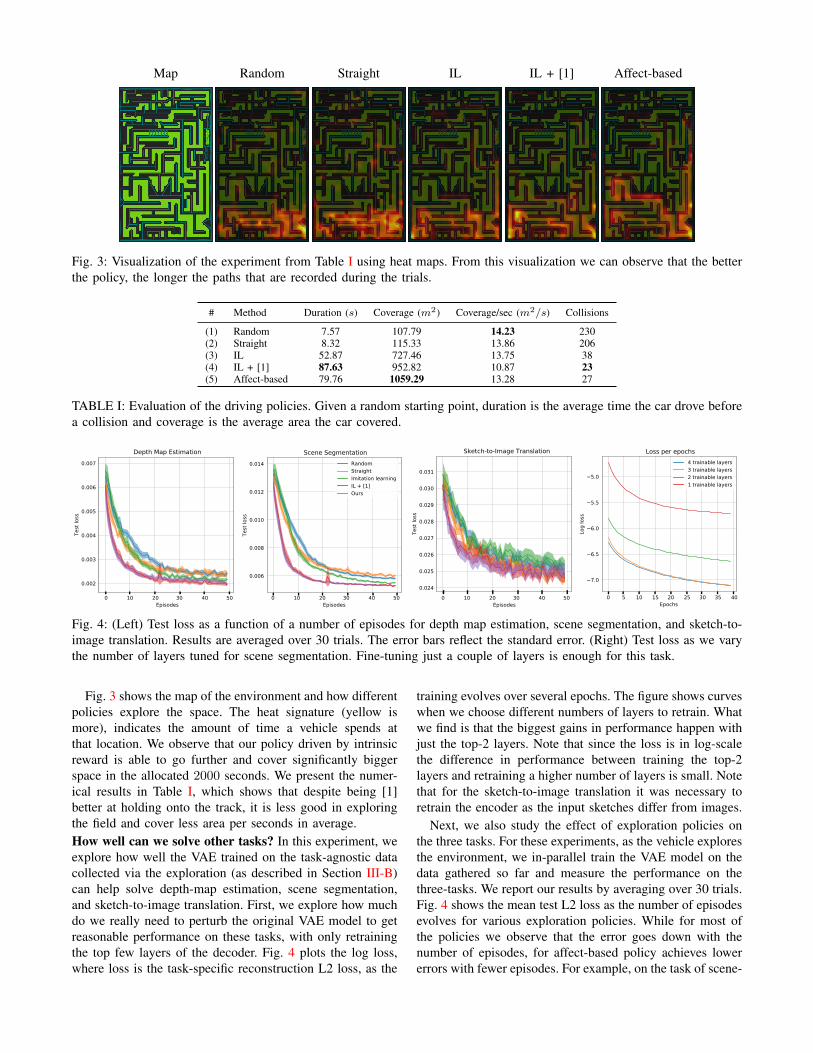
Map Random Straight IL IL + [1] Affect-based
Fig. 3: Visualization of the experiment from Table I using heat maps. From this visualization we can observe that the betterthe policy, the longer the paths that are recorded during the trials.
# Method Duration (s) Coverage (m2) Coverage/sec (m2/s) Collisions
(1) Random 7.57 107.79 14.23 230(2) Straight 8.32 115.33 13.86 206(3) IL 52.87 727.46 13.75 38(4) IL + [1] 87.63 952.82 10.87 23(5) Affect-based 79.76 1059.29 13.28 27
TABLE I: Evaluation of the driving policies. Given a random starting point, duration is the average time the car drove beforea collision and coverage is the average area the car covered.
Fig. 4: (Left) Test loss as a function of a number of episodes for depth map estimation, scene segmentation, and sketch-to-image translation. Results are averaged over 30 trials. The error bars reflect the standard error. (Right) Test loss as we varythe number of layers tuned for scene segmentation. Fine-tuning just a couple of layers is enough for this task.
Fig. 3 shows the map of the environment and how differentpolicies explore the space. The heat signature (yellow ismore), indicates the amount of time a vehicle spends atthat location. We observe that our policy driven by intrinsicreward is able to go further and cover significantly biggerspace in the allocated 2000 seconds. We present the numer-ical results in Table I, which shows that despite being [1]better at holding onto the track, it is less good in exploringthe field and cover less area per seconds in average.How well can we solve other tasks? In this experiment, weexplore how well the VAE trained on the task-agnostic datacollected via the exploration (as described in Section III-B)can help solve depth-map estimation, scene segmentation,and sketch-to-image translation. First, we explore how muchdo we really need to perturb the original VAE model to getreasonable performance on these tasks, with only retrainingthe top few layers of the decoder. Fig. 4 plots the log loss,where loss is the task-specific reconstruction L2 loss, as the
training evolves over several epochs. The figure shows curveswhen we choose different numbers of layers to retrain. Whatwe find is that the biggest gains in performance happen withjust the top-2 layers. Note that since the loss is in log-scalethe difference in performance between training the top-2layers and retraining a higher number of layers is small. Notethat for the sketch-to-image translation it was necessary toretrain the encoder as the input sketches differ from images.
Next, we also study the effect of exploration policies onthe three tasks. For these experiments, as the vehicle exploresthe environment, we in-parallel train the VAE model on thedata gathered so far and measure the performance on thethree-tasks. We report our results by averaging over 30 trials.Fig. 4 shows the mean test L2 loss as the number of episodesevolves for various exploration policies. While for most ofthe policies we observe that the error goes down with thenumber of episodes, for affect-based policy achieves lowererrors with fewer episodes. For example, on the task of scene-
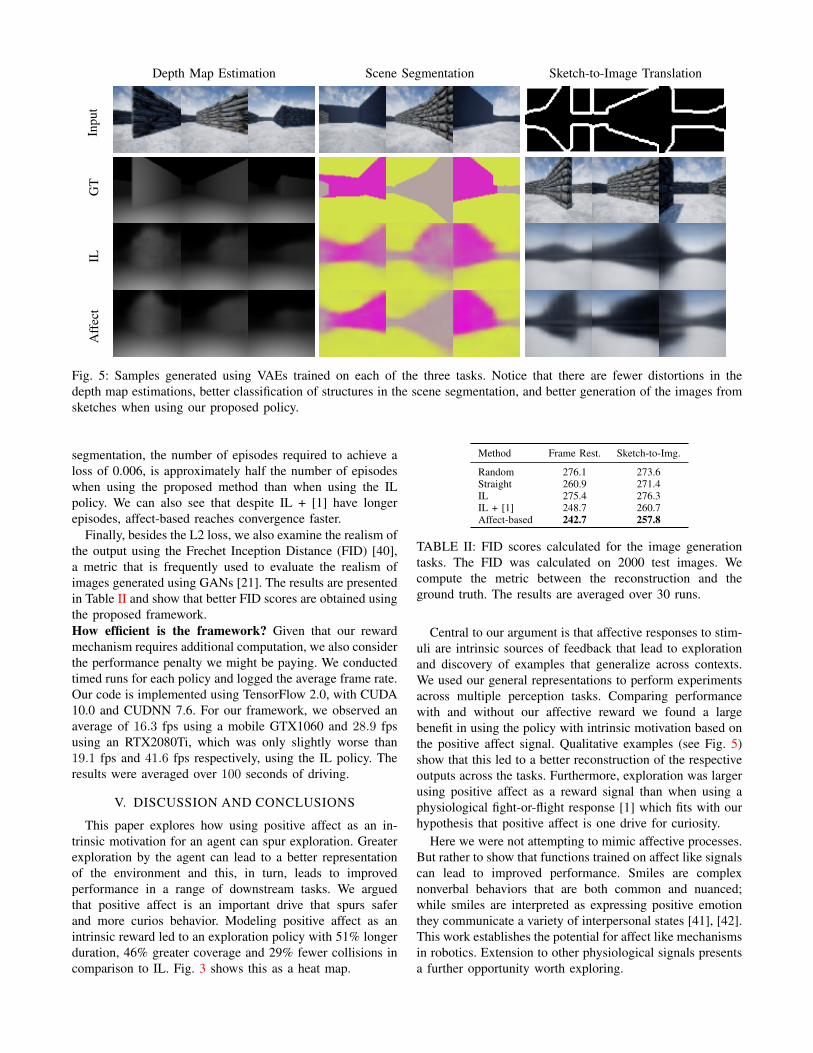
Depth Map Estimation Scene Segmentation Sketch-to-Image TranslationIn
put
GT
ILA
ffec
t
Fig. 5: Samples generated using VAEs trained on each of the three tasks. Notice that there are fewer distortions in thedepth map estimations, better classification of structures in the scene segmentation, and better generation of the images fromsketches when using our proposed policy.
segmentation, the number of episodes required to achieve aloss of 0.006, is approximately half the number of episodeswhen using the proposed method than when using the ILpolicy. We can also see that despite IL + [1] have longerepisodes, affect-based reaches convergence faster.
Finally, besides the L2 loss, we also examine the realism ofthe output using the Frechet Inception Distance (FID) [40],a metric that is frequently used to evaluate the realism ofimages generated using GANs [21]. The results are presentedin Table II and show that better FID scores are obtained usingthe proposed framework.How efficient is the framework? Given that our rewardmechanism requires additional computation, we also considerthe performance penalty we might be paying. We conductedtimed runs for each policy and logged the average frame rate.Our code is implemented using TensorFlow 2.0, with CUDA10.0 and CUDNN 7.6. For our framework, we observed anaverage of 16.3 fps using a mobile GTX1060 and 28.9 fpsusing an RTX2080Ti, which was only slightly worse than19.1 fps and 41.6 fps respectively, using the IL policy. Theresults were averaged over 100 seconds of driving.
V. DISCUSSION AND CONCLUSIONS
This paper explores how using positive affect as an in-trinsic motivation for an agent can spur exploration. Greaterexploration by the agent can lead to a better representationof the environment and this, in turn, leads to improvedperformance in a range of downstream tasks. We arguedthat positive affect is an important drive that spurs saferand more curios behavior. Modeling positive affect as anintrinsic reward led to an exploration policy with 51% longerduration, 46% greater coverage and 29% fewer collisions incomparison to IL. Fig. 3 shows this as a heat map.
Method Frame Rest. Sketch-to-Img.
Random 276.1 273.6Straight 260.9 271.4IL 275.4 276.3IL + [1] 248.7 260.7Affect-based 242.7 257.8
TABLE II: FID scores calculated for the image generationtasks. The FID was calculated on 2000 test images. Wecompute the metric between the reconstruction and theground truth. The results are averaged over 30 runs.
Central to our argument is that affective responses to stim-uli are intrinsic sources of feedback that lead to explorationand discovery of examples that generalize across contexts.We used our general representations to perform experimentsacross multiple perception tasks. Comparing performancewith and without our affective reward we found a largebenefit in using the policy with intrinsic motivation based onthe positive affect signal. Qualitative examples (see Fig. 5)show that this led to a better reconstruction of the respectiveoutputs across the tasks. Furthermore, exploration was largerusing positive affect as a reward signal than when using aphysiological fight-or-flight response [1] which fits with ourhypothesis that positive affect is one drive for curiosity.
Here we were not attempting to mimic affective processes.But rather to show that functions trained on affect like signalscan lead to improved performance. Smiles are complexnonverbal behaviors that are both common and nuanced;while smiles are interpreted as expressing positive emotionthey communicate a variety of interpersonal states [41], [42].This work establishes the potential for affect like mechanismsin robotics. Extension to other physiological signals presentsa further opportunity worth exploring.
APPENDIX
A. Network Architectures
Table III shows the network architecture for the drivingpolicy described in Subsection III-A. The architecture con-tains three convolutional layers and two dense layers. Theinput shape is [84× 84× 4] (four consecutive grayscale im-ages). The output is a vector of probabilities with dimensionsequal to the number of possible actions.
Table IV shows the network architecture for the affect-based reward function described in Subsection III-A. Thearchitecture contains three convolutional layers and twodense layers. Batch normalization is applied prior to eachintermediate layer. The input shape is [84 × 84 × 3] andcontains a single RGB image. The output is a vector of twointrinsic values. The first is the positive intrinsic value thatis being used by our affect-based policy, and the second isthe intrinsic value from [1] which is being examined usingour model architecture in the fourth baseline described inSubsection IV-B.
Layer Act. Out. shape Parameters
Conv2D ReLU 16× 8× 8 4.1kConv2D ReLU 32× 4× 4 8.2kConv2D ReLU 32× 3× 3 9.2kDense ReLU 256 401kDense Softmax 5 1.2k
Total trainable parameters 424k
TABLE III: CNN architecture for the navigation policy.
Layer Act. Out. shape Parameters
Conv2D ReLU 32× 5× 5 2.4kConv2D ReLU 48× 4× 4 24.6kConv2D ReLU 64× 4× 4 49.2kDense ReLU 2048 8.4MDense Linear 2 4k
Total trainable parameters 8.4M
TABLE IV: CNN architecture for the affect-based rewardfunction.
Layer Act. Out. shape Parameters
Encoding LayersConv2D ReLU 64× 4× 4 3.1kConv2D ReLU 128× 4× 4 131kConv2D ReLU 256× 4× 4 524kDense ReLU 1024 9.4MDense Linear 16 16.4k
Decoding LayersDense ReLU 1024 9.2kDense ReLU 6272 6.4MConv2D Transpose ReLU 128× 4× 4 262kConv2D Transpose ReLU 64× 4× 4 131kConv2D Transpose Sigmoid 3× 4× 4 3k
Total trainable parameters 16.9M
TABLE V: Architecture for the convolutional VAE model.
Table V shows the network architecture for the VAE modeldescribed in Subsection III-B. The encoder and the decodercomposed of five layers each, with batch normalization priorto each intermediate layer. The input shape is [64×64×3] andcontains a single RGB image. The output of the encoder is an8-dimensional latent space representation. The output shapeof the decoder is [64×64×3] for a single RGB/segmentationimage, or [64× 64× 1] for a depth estimation map.
For more details about the training procedureand parameters, our code is publicly available onhttps://github.com/microsoft/affectbased.
B. Reward Multiplication Factor
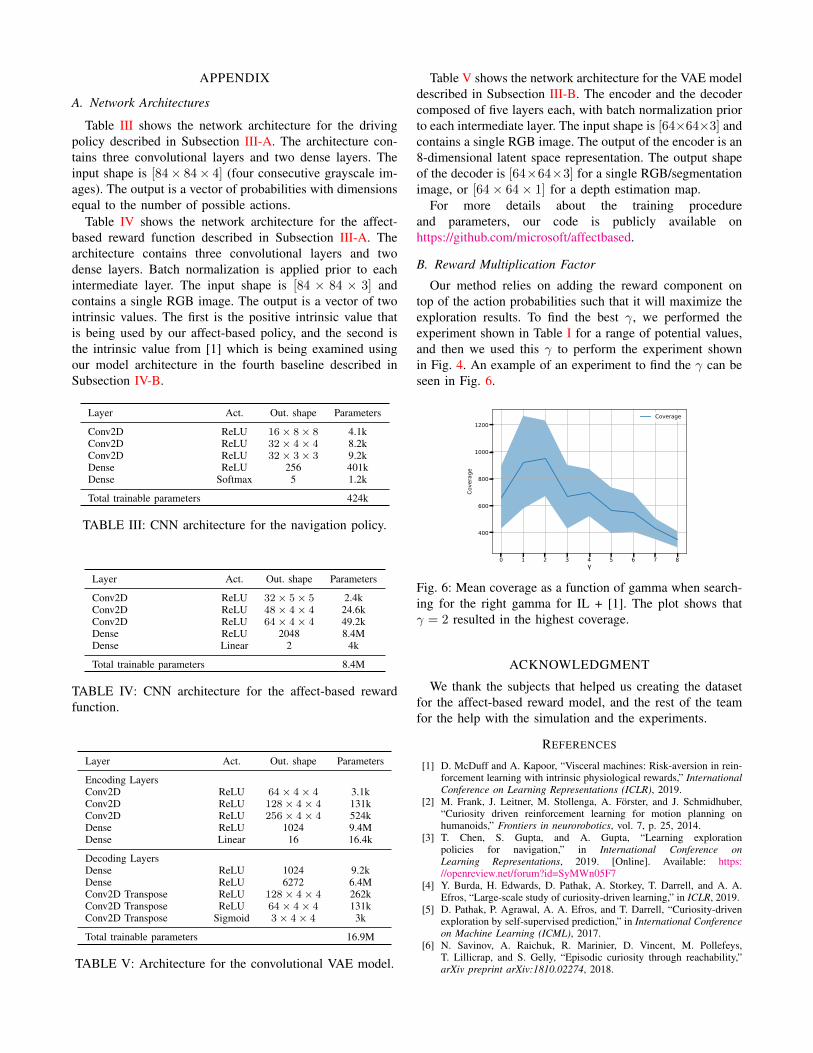
Our method relies on adding the reward component ontop of the action probabilities such that it will maximize theexploration results. To find the best γ, we performed theexperiment shown in Table I for a range of potential values,and then we used this γ to perform the experiment shownin Fig. 4. An example of an experiment to find the γ can beseen in Fig. 6.
γ
Fig. 6: Mean coverage as a function of gamma when search-ing for the right gamma for IL + [1]. The plot shows thatγ = 2 resulted in the highest coverage.
ACKNOWLEDGMENT
We thank the subjects that helped us creating the datasetfor the affect-based reward model, and the rest of the teamfor the help with the simulation and the experiments.
REFERENCES
[1] D. McDuff and A. Kapoor, “Visceral machines: Risk-aversion in rein-forcement learning with intrinsic physiological rewards,” InternationalConference on Learning Representations (ICLR), 2019.
[2] M. Frank, J. Leitner, M. Stollenga, A. Forster, and J. Schmidhuber,“Curiosity driven reinforcement learning for motion planning onhumanoids,” Frontiers in neurorobotics, vol. 7, p. 25, 2014.
[3] T. Chen, S. Gupta, and A. Gupta, “Learning explorationpolicies for navigation,” in International Conference onLearning Representations, 2019. [Online]. Available: https://openreview.net/forum?id=SyMWn05F7
[4] Y. Burda, H. Edwards, D. Pathak, A. Storkey, T. Darrell, and A. A.Efros, “Large-scale study of curiosity-driven learning,” in ICLR, 2019.
[5] D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell, “Curiosity-drivenexploration by self-supervised prediction,” in International Conferenceon Machine Learning (ICML), 2017.
[6] N. Savinov, A. Raichuk, R. Marinier, D. Vincent, M. Pollefeys,T. Lillicrap, and S. Gelly, “Episodic curiosity through reachability,”arXiv preprint arXiv:1810.02274, 2018.

[7] J. C. Masters, R. C. Barden, and M. E. Ford, “Affective states,expressive behavior, and learning in children.” Journal of Personalityand Social Psychology, vol. 37, no. 3, p. 380, 1979.
[8] B. Kort, R. Reilly, and R. W. Picard, “An affective model of interplaybetween emotions and learning: Reengineering educational pedagogy-building a learning companion,” in Proceedings IEEE InternationalConference on Advanced Learning Technologies. IEEE, 2001, pp.43–46.
[9] N. Jaques, J. McCleary, J. Engel, D. Ha, F. Bertsch, R. Picard,and D. Eck, “Learning via social awareness: Improving a deepgenerative sketching model with facial feedback,” arXiv preprintarXiv:1802.04877, 2018.
[10] N. Chentanez, A. G. Barto, and S. P. Singh, “Intrinsically motivatedreinforcement learning,” in Advances in neural information processingsystems, 2005, pp. 1281–1288.
[11] N. Haber, D. Mrowca, S. Wang, L. F. Fei-Fei, and D. L. Yamins,“Learning to play with intrinsically-motivated, self-aware agents,” inAdvances in Neural Information Processing Systems, 2018, pp. 8388–8399.
[12] Z. Zheng, J. Oh, and S. Singh, “On learning intrinsic rewards for policygradient methods,” in Advances in Neural Information ProcessingSystems, 2018, pp. 4644–4654.
[13] A. Billard and M. J. Mataric, “Learning human arm movementsby imitation:: Evaluation of a biologically inspired connectionistarchitecture,” Robotics and Autonomous Systems, vol. 37, no. 2-3, pp.145–160, 2001.
[14] V. Blukis, N. Brukhim, A. Bennett, R. A. Knepper, and Y. Artzi, “Fol-lowing high-level navigation instructions on a simulated quadcopterwith imitation learning,” arXiv preprint arXiv:1806.00047, 2018.
[15] M. Bojarski, D. Del Testa, D. Dworakowski, B. Firner, B. Flepp,P. Goyal, L. D. Jackel, M. Monfort, U. Muller, J. Zhang, et al., “End toend learning for self-driving cars,” arXiv preprint arXiv:1604.07316,2016.
[16] L. Cardamone, D. Loiacono, and P. L. Lanzi, “Learning drivers fortorcs through imitation using supervised methods,” in 2009 IEEEsymposium on computational intelligence and games. IEEE, 2009,pp. 148–155.
[17] S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learningand structured prediction to no-regret online learning,” in Proceedingsof the fourteenth international conference on artificial intelligence andstatistics, 2011, pp. 627–635.
[18] S. Ross, N. Melik-Barkhudarov, K. S. Shankar, A. Wendel, D. Dey,J. A. Bagnell, and M. Hebert, “Learning monocular reactive uavcontrol in cluttered natural environments,” in 2013 IEEE internationalconference on robotics and automation. IEEE, 2013, pp. 1765–1772.
[19] F. Codevilla, M. Miiller, A. Lopez, V. Koltun, and A. Dosovitskiy,“End-to-end driving via conditional imitation learning,” in 2018 IEEEInternational Conference on Robotics and Automation (ICRA). IEEE,2018, pp. 1–9.
[20] D. Zadok, T. Hirshberg, A. Biran, K. Radinsky, and A. Kapoor,“Explorations and lessons learned in building an autonomous formulasae car from simulations,” SIMULTECH, 2019.
[21] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley,S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” inAdvances in neural information processing systems, 2014, pp. 2672–2680.
[22] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,”arXiv preprint arXiv:1312.6114, 2013.
[23] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-imagetranslation with conditional adversarial networks,” in Proceedings ofthe IEEE conference on computer vision and pattern recognition,2017, pp. 1125–1134.
[24] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” inProceedings of the IEEE international conference on computer vision,2017, pp. 2223–2232.
[25] L. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille,“Deeplab: Semantic image segmentation with deep convolutional nets,atrous convolution, and fully connected crfs,” CoRR, 2017 IEEETransactions on Pattern Analysis and Machine Intelligence, vol.abs/1606.00915, 2017.
[26] C. Godard, O. Mac Aodha, and G. J. Brostow, “Unsupervised monoc-ular depth estimation with left-right consistency,” in Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition,2017, pp. 270–279.
[27] W. Chen and J. Hays, “Sketchygan: Towards diverse and realisticsketch to image synthesis,” in Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition, 2018, pp. 9416–9425.
[28] X. Pan, Y. You, Z. Wang, and C. Lu, “Virtual to real reinforcementlearning for autonomous driving,” arXiv preprint arXiv:1704.03952,2017.
[29] J. E. Swan, A. Jones, E. Kolstad, M. A. Livingston, and H. S. Small-man, “Egocentric depth judgments in optical, see-through augmentedreality,” IEEE transactions on visualization and computer graphics,vol. 13, no. 3, pp. 429–442, 2007.
[30] D. Wang, C. Devin, Q.-Z. Cai, P. Krahenbuhl, and T. Darrell, “Monoc-ular plan view networks for autonomous driving,” arXiv preprintarXiv:1905.06937, 2019.
[31] M. Eitz, J. Hays, and M. Alexa, “How do humans sketch objects?”ACM Trans. Graph., vol. 31, no. 4, pp. 44–1, 2012.
[32] T. Chen, M.-M. Cheng, P. Tan, A. Shamir, and S.-M. Hu,“Sketch2photo: Internet image montage,” in ACM transactions ongraphics (TOG), vol. 28, no. 5. ACM, 2009, p. 124.
[33] S.-L. Brown and G. E. Schwartz, “Relationships between facialelectromyography and subjective experience during affective imagery,”Biological psychology, vol. 11, no. 1, pp. 49–62, 1980.
[34] K. S. Kassam, Assessment of emotional experience through facialexpression. Harvard University, 2010.
[35] M. LaFrance, Lip service: Smiles in life, death, trust, lies, work,memory, sex, and politics. WW Norton & Company, 2011.
[36] B. Martinez, M. F. Valstar, B. Jiang, and M. Pantic, “Automaticanalysis of facial actions: A survey,” IEEE transactions on affectivecomputing, 2017.
[37] S. Shah, D. Dey, C. Lovett, and A. Kapoor, “Airsim: High-fidelityvisual and physical simulation for autonomous vehicles,” in Field andservice robotics. Springer, 2018, pp. 621–635.
[38] T. Baltrusaitis, A. Zadeh, Y. C. Lim, and L.-P. Morency, “Openface2.0: Facial behavior analysis toolkit,” in 2018 13th IEEE InternationalConference on Automatic Face & Gesture Recognition (FG 2018).IEEE, 2018, pp. 59–66.
[39] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou,D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcementlearning,” arXiv preprint arXiv:1312.5602, 2013.
[40] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter,“Gans trained by a two time-scale update rule converge to a local nashequilibrium,” in Advances in Neural Information Processing Systems,2017, pp. 6626–6637.
[41] P. Ekman and W. V. Friesen, “Felt, false, and miserable smiles,”Journal of Nonverbal Behavior, vol. 6, no. 4, pp. 238–252, 1982.
[42] M. Rychlowska, R. E. Jack, O. G. B. Garrod, P. G. Schyns, J. D.Martin, and P. M. Niedenthal, “Functional smiles: Tools for love,sympathy, and war,” Psychological Science, vol. 28, no. 9, pp. 1259–1270, 2017.


















