
David Gerster: Hands on Machine Learning
20
Hands-on Machine Learning David Gerster VP Data Science
-
Upload
david-gerster -
Category
Data & Analytics
-
view
53 -
download
0
Transcript of David Gerster: Hands on Machine Learning

Hands-on Machine LearningDavid Gerster
VP Data Science

2
Agenda
Part 1: What is “machine learning”?Part 2: Finding patterns in an actual data set

4
“Machine Learning”: Finding patterns in data• Famous “Iris” data set has measurements for 150 flowers• Given a flower’s measurements, can we predict its species?
Iris setosa Iris versicolor Iris virginica

Peta
l Wid
th (c
m)
Petal Length (cm)
Iris setosa, red dots
Iris versicolor, green dots
Iris virginica, blue dots

Peta
l Wid
th (c
m)
Petal Length (cm)
Congratulations! You just trained a model.

Peta
l Wid
th (c
m)
Petal Length (cm)
Peta
l Wid
th (c
m)
Petal Length (cm)
Prediction: Iris setosa
Prediction: Iris versicolor
Prediction: Iris virginica
Prediction:Iris virginica

Peta
l Wid
th (c
m)
Petal Length (cm)
Prediction: Iris setosa
Prediction: Iris versicolor
Prediction: Iris virginica
Prediction:Iris virginicaCongratulations! You just scored four
previously unseen flowers using yourmodel, and made a prediction aboutthe species of each one.

9
• Data is just a table of values• Each row is an “instance”, an
example of the concept to be learned• Each column is an “attribute” or
“feature” of the instance• The column we want to predict is
the “label”
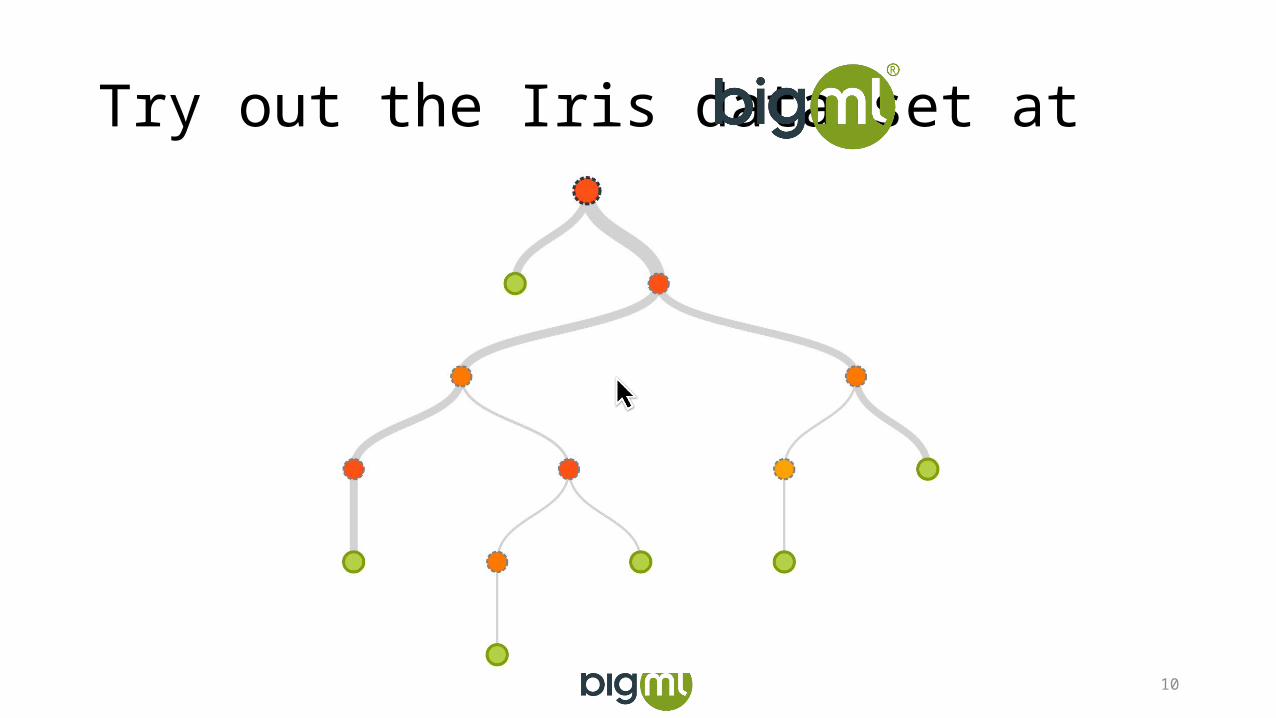
Try out the Iris data set at

Try out the Iris data set at

12
That was easy! … So What?

13
Training versus Scoring
• This process had two steps: training and scoring• When training on historical data, you’re often looking for patterns
that emerge over weeks, months or even years• When scoring new data points, you want the answer immediately
(in “real time”)

14
Do you really need to train in “real time”?• Many real-world cases rely heavily on historical data• Credit scores, fraud detection, movie ratings, web search relevance, disease
diagnosis, customer churn, yield on a silicon wafer …• Extreme example: text recognition!
• You might add fresh training data daily or hourly, but you will still have lots of historical data in the training set.• You definitely want to score in real time, because you’re typically
using this model in some sort of app

15

16
What “Real Time” Really Means
• The next time you hear someone talk about “real time” machine learning, make yourself look really smart and ask if they mean training or scoring

• W
What do you mean, real time training or real time scoring?
What? I don’t …

19
The StumbleUpon Dataset
• StumbleUpon is an app that recommends web pages• Dataset of 7,400 web pages is provided, with each page labeled as
either “evergreen” or “ephemeral”• We want to predict the page’s class using this historical data
While some pages we recommend, such as news articles or seasonal recipes, are only relevant for a short period of time, others maintain a timeless quality and can be recommended to users long after they are discovered. In other words, pages can either be classified as "ephemeral" or "evergreen".

20
Training a model on StumbleUpon data• Live demo: training a model on StumbleUpon data• Key concepts:• “Bag of words” text analysis• Evaluating the model using a holdout set• Combining multiple models to improve accuracy

21
Final Thought
• The two datasets we trained on were not “big”• Iris dataset: 150 rows, less than 5K• StumbleUpon dataset: 7400 rows, 21MB
• Data doesn’t need to be big to be useful

22


















