Thesis structure Professor: Ying-Jiun Hsieh Student: Hong Kong, Chen.
Upload
carolina-gentlesCategory
view
220download
1
Database for Data-Database for Data-AnalysisAnalysis
Developer: Ying Chen (JLab)Developer: Ying Chen (JLab) Computing 3(or N)-pt functionsComputing 3(or N)-pt functions
Many correlation functions (quantum numbers), at Many correlation functions (quantum numbers), at many momenta for a fixed configurationmany momenta for a fixed configuration
Data analysis requires a single quantum number over Data analysis requires a single quantum number over many configurations (called an many configurations (called an Ensemble Ensemble quantity)quantity)
Can be 10K to over 100K quantum numbersCan be 10K to over 100K quantum numbers Inversion problem:Inversion problem:
Time to retrieve 1 quantum number can be longTime to retrieve 1 quantum number can be long Analysis jobs can take hours (or Analysis jobs can take hours (or days) days) to run. Once to run. Once
cached, time can be considerably reducedcached, time can be considerably reduced Development:Development:
Require better storage technique and better analysis Require better storage technique and better analysis code driverscode drivers

Database for Data-Database for Data-AnalysisAnalysis
Developer: Ying Chen (JLab)Developer: Ying Chen (JLab) Computing 3(or N)-pt functionsComputing 3(or N)-pt functions
Many correlation functions (quantum numbers), at Many correlation functions (quantum numbers), at many momenta for a fixed configurationmany momenta for a fixed configuration
Data analysis requires a single quantum number over Data analysis requires a single quantum number over many configurations (called an many configurations (called an Ensemble Ensemble quantity)quantity)
Can be 10K to over 100K quantum numbersCan be 10K to over 100K quantum numbers Inversion problem:Inversion problem:
Time to retrieve 1 quantum number can be longTime to retrieve 1 quantum number can be long Analysis jobs can take hours (or Analysis jobs can take hours (or days) days) to run. Once to run. Once
cached, time can be considerably reducedcached, time can be considerably reduced Development:Development:
Require better storage technique and better analysis Require better storage technique and better analysis code driverscode drivers

DatabaseDatabase Requirements:Requirements:
For each config worth of data, will pay a one-time insertion costFor each config worth of data, will pay a one-time insertion cost Config data may insert out of orderConfig data may insert out of order Need to insert or deleteNeed to insert or delete
Solution: Solution: Requirements basically imply a Requirements basically imply a balanced treebalanced tree Try DB using Berkeley Sleepy Cat:Try DB using Berkeley Sleepy Cat:
Preliminary Tests:Preliminary Tests: 300 directories of binary files holding correlators (~7K files 300 directories of binary files holding correlators (~7K files
each dir.)each dir.) A single “key” of quantum number + config number hashed to a A single “key” of quantum number + config number hashed to a
stringstring About 9GB DB, retrieval on local disk about 1 sec, over NFS About 9GB DB, retrieval on local disk about 1 sec, over NFS
about 4 sec.about 4 sec.

Database and InterfaceDatabase and Interface Database “key”:Database “key”:
String = source_sink_pfx_pfy_pfz_qx_qy_qz_Gamma_linkpathString = source_sink_pfx_pfy_pfz_qx_qy_qz_Gamma_linkpath Not intending (at the moment) any relational capabilities among Not intending (at the moment) any relational capabilities among
sub-keyssub-keys Interface functionInterface function
Array< Array<double> > read_correlator(const string& key);Array< Array<double> > read_correlator(const string& key);
Analysis code interface (wrapper):Analysis code interface (wrapper): struct Arg {Array<int> p_i; Array<int> p_f; int gamma;};struct Arg {Array<int> p_i; Array<int> p_f; int gamma;}; Getter: Getter: Ensemble<Array<Real>> operator[](const Arg&);Ensemble<Array<Real>> operator[](const Arg&); or or
Array<Array<double>> operator[](const Arg&);Array<Array<double>> operator[](const Arg&); Here, Here, “ensemble”“ensemble” objects have jackknife support, namely objects have jackknife support, namely
operator*(Ensemble<T>, Ensemble<T>); operator*(Ensemble<T>, Ensemble<T>); CVS package CVS package adatadat

(Clover) Temporal (Clover) Temporal PreconditioningPreconditioning
Consider Dirac op Consider Dirac op det(D) = det(Ddet(D) = det(Dtt + D + Dss// Temporal precondition: Temporal precondition: det(D)=det(Ddet(D)=det(Dtt)det(1+ )det(1+
DDtt-1-1DDss//))
Strategy: Strategy: Temporal preconditiongTemporal preconditiong 3D even-odd preconditioning3D even-odd preconditioning
ExpectationsExpectations Improvement can increase with increasing Improvement can increase with increasing According to Mike Peardon, typically factors of 3 According to Mike Peardon, typically factors of 3
improvement in CG iterationsimprovement in CG iterations Improving condition number lowers fermionic forceImproving condition number lowers fermionic force

Multi-Threading Multi-Threading on Multi-Core on Multi-Core
ProcessorsProcessors
Jie Chen, Ying Chen, Balint Joo and Jie Chen, Ying Chen, Balint Joo and Chip WatsonChip Watson
Scientific Computing GroupScientific Computing Group
IT DivisionIT Division
Jefferson LabJefferson Lab

MotivationMotivation
Next LQCD ClusterNext LQCD Cluster What type of machines is going to used What type of machines is going to used
for the cluster?for the cluster? Intel Dual Core or AMD Dual Core?Intel Dual Core or AMD Dual Core?
Software Performance ImprovementSoftware Performance Improvement Multi-threadingMulti-threading

Test EnvironmentTest Environment Two Dual Core Intel 5150 Xeons (Woodcrest) Two Dual Core Intel 5150 Xeons (Woodcrest)
2.66 GHz2.66 GHz 4 GB memory (FB-DDR2 667 MHz)4 GB memory (FB-DDR2 667 MHz)
Two Dual Core AMD Opteron 2220 SE Two Dual Core AMD Opteron 2220 SE (Socket F) (Socket F) 2.8 GHz2.8 GHz 4 GB Memory (DDR2 667 MHz)4 GB Memory (DDR2 667 MHz)
2.6.15-smp kernel (Fedora Core 5)2.6.15-smp kernel (Fedora Core 5) i386i386 x86_64x86_64
Intel c/c++ compiler (9.1), gcc 4.1Intel c/c++ compiler (9.1), gcc 4.1

Multi-Core ArchitectureMulti-Core Architecture
Core 1 Core 2
Memory ControllerESB2I/O
PCI Express
FB DDR2
Core 1 Core 2
PCI-EBridge
PCI-EExpansion
HUB
PCI-XBridge
DDR2
Intel WoodcrestIntel Xeon 5100
AMD OpteronsSocket F

Multi-Core ArchitectureMulti-Core Architecture L1 CacheL1 Cache
32 KB Data, 32 KB Instruction32 KB Data, 32 KB Instruction L2 CacheL2 Cache
4MB Shared among 2 cores4MB Shared among 2 cores 256 bit width256 bit width 10.6 GB/s bandwidth to cores10.6 GB/s bandwidth to cores
FB-DDR2FB-DDR2 Increased LatencyIncreased Latency memory disambiguation memory disambiguation
allows load ahead store allows load ahead store instructionsinstructions
ExecutionsExecutions Pipeline length 14; 24 bytes Pipeline length 14; 24 bytes
Fetch width; 96 reorder Fetch width; 96 reorder buffersbuffers
3 128-bit SSE Units; One SSE 3 128-bit SSE Units; One SSE instruction/cycleinstruction/cycle
L1 CacheL1 Cache 64 KB Data, 64 KB Instruction64 KB Data, 64 KB Instruction
L2 CacheL2 Cache 1 MB dedicated1 MB dedicated 128 bit width128 bit width 6.4 GB/s bandwidth to cores6.4 GB/s bandwidth to cores
NUMA (DDR2)NUMA (DDR2) Increased latency to access Increased latency to access
the other memorythe other memory Memory affinity is importantMemory affinity is important
ExecutionsExecutions Pipeline length 12; 16 bytes Pipeline length 12; 16 bytes
Fetch width; 72 reorder Fetch width; 72 reorder buffersbuffers
2 128-bit SSE Units; One SSE 2 128-bit SSE Units; One SSE instruction = two 64-bit instruction = two 64-bit instructions.instructions.
Intel Woodcrest Xeon AMD Opteron

Memory System Memory System PerformancePerformance

Memory System Memory System PerformancePerformance
L1L1 L2L2 MemMem Rand Rand MemMem
IntelIntel 1.12901.1290 5.29305.2930 118.7118.7 150.3150.3
AMDAMD 1.07201.0720 4.30504.3050 71.471.4 173.8173.8
Memory Access Latency in nanoseconds

Performance of Performance of ApplicationsApplications
NPB-3.2 (gcc-4.1 x86-64)NPB-3.2 (gcc-4.1 x86-64)

LQCD Application (DWF) LQCD Application (DWF) PerformancePerformance

Parallel ProgrammingParallel Programming
Messages
Machine 1 Machine 2
OpenMP/Pthread OpenMP/Pthread
Performance Improvement on Multi-Core/SMP Performance Improvement on Multi-Core/SMP machinesmachines
All threads share address spaceAll threads share address spaceEfficient inter-thread communication (no Efficient inter-thread communication (no memory copies)memory copies)

Multi-Threads Provide Multi-Threads Provide Higher Memory Bandwidth Higher Memory Bandwidth
to a Processto a Process

Different Machines Provide Different Machines Provide Different Scalability for Different Scalability for Threaded ApplicationsThreaded Applications

OpenMPOpenMP
Portable, Shared Memory Multi-Portable, Shared Memory Multi-Processing APIProcessing API Compiler Directives and Runtime LibraryCompiler Directives and Runtime Library C/C++, Fortran 77/90C/C++, Fortran 77/90 Unix/Linux, WindowsUnix/Linux, Windows Intel c/c++, gcc-4.xIntel c/c++, gcc-4.x Implementation on top of native threadsImplementation on top of native threads
Fork-join Parallel Programming ModelFork-join Parallel Programming ModelMaster
Fork Join
Time

OpenMPOpenMP Compiler Directives (C/C++)Compiler Directives (C/C++)
#pragma omp parallel#pragma omp parallel{{
thread_exec (); /* all threads execute the code thread_exec (); /* all threads execute the code */*/
} /* all threads join master thread */} /* all threads join master thread */#pragma omp critical#pragma omp critical#pragma omp section#pragma omp section#pragma omp barrier#pragma omp barrier#pragma omp parallel reduction(+:result)#pragma omp parallel reduction(+:result)
Run time libraryRun time library omp_set_num_threads, omp_get_thread_numomp_set_num_threads, omp_get_thread_num

Posix ThreadPosix Thread
IEEE POSIX 1003.1c standard IEEE POSIX 1003.1c standard (1995)(1995) NPTL (Native Posix Thread Library) NPTL (Native Posix Thread Library)
Available on Linux since kernel 2.6.x.Available on Linux since kernel 2.6.x. Fine grain parallel algorithmsFine grain parallel algorithms
Barrier, Pipeline, Master-slave, ReductionBarrier, Pipeline, Master-slave, Reduction
ComplexComplex Not for general public Not for general public

QCD Multi-Threading QCD Multi-Threading (QMT)(QMT)
Provides Simple APIs for Fork-Join Provides Simple APIs for Fork-Join Parallel paradigmParallel paradigmtypedef void (*qmt_user_func_t)(void * arg);typedef void (*qmt_user_func_t)(void * arg);qmt_pexec (qmt_userfunc_t func, void* arg);qmt_pexec (qmt_userfunc_t func, void* arg);
The user “func” will be executed on multiple The user “func” will be executed on multiple threads. threads.
Offers efficient mutex lock, barrier and Offers efficient mutex lock, barrier and reductionreductionqmt_sync (int tid); qmt_spin_lock(&lock);qmt_sync (int tid); qmt_spin_lock(&lock);
Performs better than OpenMP generated Performs better than OpenMP generated code?code?

OpenMP Performance from OpenMP Performance from Different Compilers (i386)Different Compilers (i386)

Synchronization Overhead Synchronization Overhead for OMP and QMT on Intel for OMP and QMT on Intel
Platform (i386)Platform (i386)

Synchronization Overhead Synchronization Overhead for OMP and QMT on AMD for OMP and QMT on AMD
Platform (i386)Platform (i386)

QMT Performance on Intel QMT Performance on Intel and AMD (x86_64 and gcc and AMD (x86_64 and gcc
4.1)4.1)

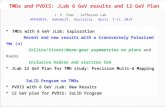
ConclusionsConclusions
Intel woodcrest beats AMD Opterons Intel woodcrest beats AMD Opterons at this stage of game.at this stage of game. Intel has better dual-core micro-Intel has better dual-core micro-
architecturearchitecture AMD has better system architectureAMD has better system architecture
Hand written QMT library can beat Hand written QMT library can beat OMP compiler generated code.OMP compiler generated code.