

Data Vault Automation at the Bijenkorf
21
Data Vault Automation at de Bijenkorf PRESENTED BY ROB WINTERS ANDREI SCORUS
-
Upload
rob-winters -
Category
Data & Analytics
-
view
637 -
download
3
Transcript of Data Vault Automation at the Bijenkorf

Data Vault Automation at
de BijenkorfPR ESEN T ED BY
ROB WINTERS
ANDREI SCORUS

Presentation agenda◦ Project objectives
◦ Architectural overview
◦ The data warehouse data model
◦ Automation in the data warehouse
◦ Successes and failures
◦ Conclusions

About the presenters
Rob Winters
Head of Data Technology, the Bijenkorf
Project role:◦ Project Lead
◦ Systems architect and administrator
◦ Data modeler
◦ Developer (ETL, predictive models, reports)
◦ Stakeholder manager
◦ Joined project September 2014
Andrei Scorus
BI Consultant, Incentro
Project role:◦ Main ETL Developer
◦ ETL Developer
◦ Modeling support
◦ Source system expert
◦ Joined project November 2014

Project objectives
◦ Information requirements◦ Have one place as the source for all reports
◦ Security and privacy
◦ Information management
◦ Integrate with production
◦ Non-functional requirements◦ System quality
◦ Extensibility
◦ Scalability
◦ Maintainability
◦ Security
◦ Flexibility
◦ Low Cost
Technical Requirements
• One environment to quickly generate customer insights
• Then feed those insights back to production
• Then measure the impact of those changes in near real time

Source system landscape
Source Type Number of Sources Examples Load Frequency Data Structure
Oracle DB 2 Virgo ERP 2x/hour Partial 3NF
MySQL 3 Product DB, Web Orders, DWH
10x/hour 3NF (Web Orders), Improperly normalized
Event bus 1 Web/email events 1x/minute Tab delimited with JSON fields
Webhook 1 Transactional Emails 1x/minute JSON
REST APIs 5+ GA, DotMailer 1x/hour-1x/day JSON
SOAP APIs 5+ AdWords, Pricing 1x/day XML

Architectural overviewTools
AWS◦ S3
◦ Kinesis
◦ Elasticache
◦ Elastic Beanstalk
◦ EC2
◦ DynamoDB
Open Source◦ Snowplow Event Tracker
◦ Rundeck Scheduler
◦ Jenkins Continuous Integration
◦ Pentaho PDI
Other◦ HP Vertica
◦ Tableau
◦ Github
◦ RStudio Server

DWH internal architecture
• Traditional three tier DWH• ODS generated automatically from
staging• Ops mart reflects data in original
source form• Helps offload queries from
source systems• Business marts materialized
exclusively from vault

Bijenkorf Data Vault overviewData volumes
• ~1 TB base volume
• 10-12 GB daily
• ~250 source tables
Aligned to Data Vault 2.0
•Hash keys
•Hashes used for CDC
• Parallel loading
•Maximum utilization of available resources
•Data unchanged in to the vault
Some statistics
18 hubs
• 34 loading scripts
27 links
• 43 loading scripts
39 satellites
• 43 loading scripts
13 reference tables
• 1 script per table
Model contains
• Sales transactions
• Customer and corporate locations
• Customers
• Products
• Payment methods
• Phone
• Product grouping
• Campaigns
• deBijenkorf card
• Social media
Excluded from the vault
◦ Event streams
◦ Server logs
◦ Unstructured data

Deep dive: Transactions in DV•Transactions

Deep dive: Customers in DV•Same as link on customer

Challenges encountered during data modelingChallenge Issue Details Resolution
Source issues • Source systems and original data unavailable for most information
• Data often transformed 2-4 times before access was available
• Business keys (ex. SKU) typically replaced with sequences
• Business keys rebuilt in staging prior to vault loading
Modeling returns • Retail returns can appear in ERP in 1-3 ways across multiple tables with inconsistent keys
• Online returns appear as a state change on original transaction and may/may not appear in ERP
• Original model showed sale state on line item satellite
• Revised model recorded “negative sale” transactions and used a new link to connect to original sale when possible
Fragmentedknowledge
• Information about the systems was being held by multiple people
• Documentation was out-of-date
• Talking to as many people as possible and testing hypotheses on the data

Targeted benefits of DWH automation
Objective Achievements
Speed of development • Integration of new sources or data from existing sources takes 1-2 steps• Adding a new vault dependency takes one step
Simplicity • Five jobs handle all ETL processes across DWH
Traceability • Every record/source file is traced in the database and every row automaticallyidentified by source file in ODS
Code simplification • Replaced most common key definitions with dynamic variable replacement
File management • Every source file automatically archived to Amazon S3 in appropriate locations sorted by source, table, and date
• Entire source systems, periods, etc can be replayed in minutes

Source loading automationo Design of loader focused on process abstraction, traceability, and minimization of “moving parts”
o Final process consisted of two base jobs working in tandem: one for generating incremental extracts from source systems, one for loading flat files from all sources to staging tableso Replication was desired but rejected due to limited access to source systems
Source tables duplicated in staging with addition of loadTs and sourceFilecolumns
Metadata for source file
added
Loader automatically
generates ODS, begins tracking source files for duplication and
data quality
Query generator
automatically executes full
duplication on first execution
and incrementals
afterward
CREATE TABLE stg_oms.customer(customerId int, customerName varchar(500), customerAddress varchar(5000), loadTs timestamp NOT NULL, sourceFile varchar(255) NOT NULL)ORDER BY customerIdPARTITION BY date(loadTs);INSERT INTO meta.source_to_stg_mapping(targetSchema, targetTable, sourceSystem, fileNamePattern, delimiter, nullField)VALUES('stg_oms','customer','OMS','OMS_CUSTOMER','TAB','NULL');
Example: Add additional table from existing sourceWorkflow of source integration

Vault loading automation
• New sources automatically added
• Last change epoch based on load stamps, advanced each time all dependencies execute successfully
All Staging Tables
Checked for Changes
• Dependencies declared at time of job creation
• Load prioritization possible but not utilized
List of Dependent Vault Loads Identified
• Jobs parallelized across tables but serialized per job
• Dynamic job queueing ensures appropriate execution order
Loads Planned in Hub, Link, Sat Order
• Variables automatically identified and replaced
• Each load records performance statistics and error messages
Loads Executed
o Loader is fully metadata driven with focus on horizontal scalability and management simplicity
o To support speed of development and performance, variable-driven SQL templates used throughout

Design goals for mart loading automation
Requirement Solution Benefit
Simple, standardized
models
Metadata-driven Pentaho PDI
Easy development using parameters
and variables
Easily Extensible
Plugin frameworkRapid integration
of new functionality
Rapid new job development
Recycle standardized jobs
and transformations
Limited moving parts, easy
modification
Low administration
overhead
Leverage built in logging and
tracking
Easily integrated mart loading
reporting with other ETL reports

Data Information mart automation flow
Retrievecommands
• Each dimension and fact is processed independently
Get dependencies
• Based on defined transformation, get all related vault tables: links, satellites or hubs
Retrievechanged data
• From the related tables, build a list of unique keys that have changed since the last update of the fact or dimension
• Store the data in the database until further processing
Executetransformations
• Multiple Pentaho transformations can be processed per command using the data captured in previous steps
Maintentance
• Logging happens throughout the whole process
• Cleanup after all commands have been processed

Primary uses of Bijenkorf DWHC
ust
om
er A
nal
ysis • Provided first unified
data model of customer activity
• 80% reduction in unique customer keys
• Allowed for segmentation of customers based on combination of in-store and online activity
Pers
on
aliz
atio
n • DV drives recommendation engine and customer recommendations (updated nightly)
• Data pipeline supports near real time updating of customer recommendations based on web activity B
usi
nes
s In
telli
gen
ce • DV-based marts replace joining dozens of tables across multiple sources with single facts/ dimensions
• IT-driven reporting being replaced with self-service BI
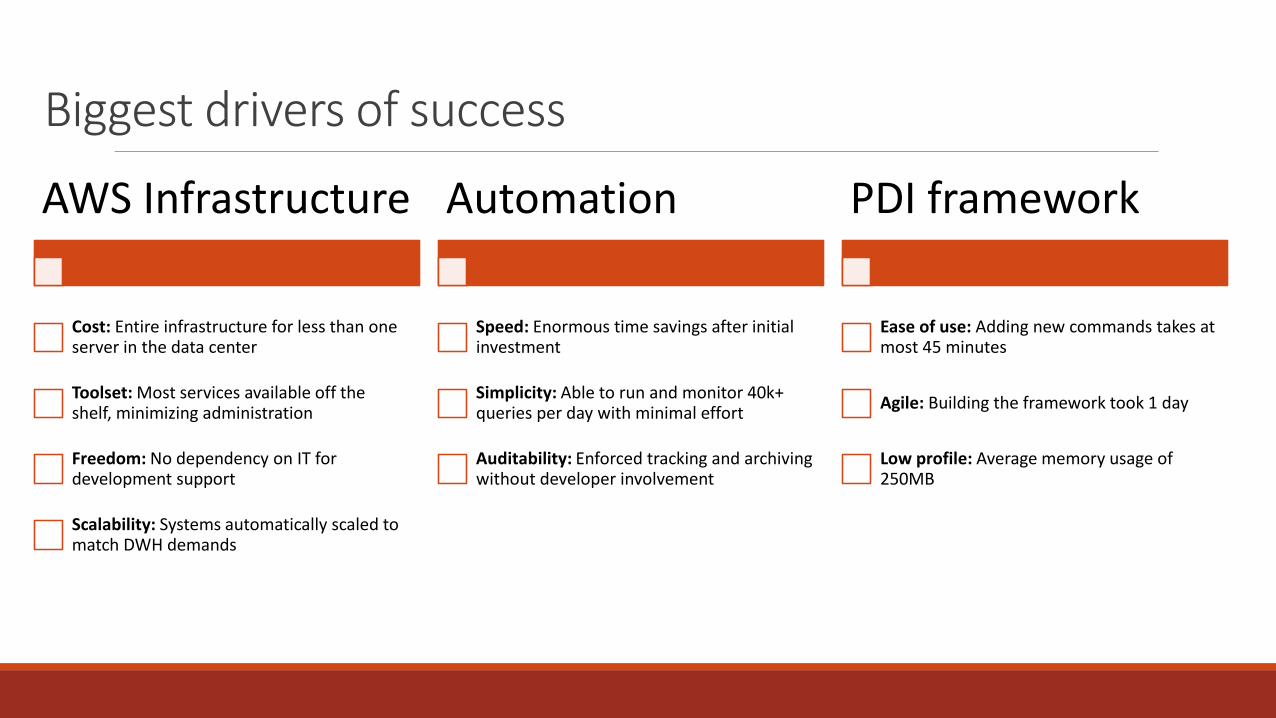
Biggest drivers of success
AWS Infrastructure
Cost: Entire infrastructure for less than one server in the data center
Toolset: Most services available off the shelf, minimizing administration
Freedom: No dependency on IT for development support
Scalability: Systems automatically scaled to match DWH demands
Automation
Speed: Enormous time savings after initial investment
Simplicity: Able to run and monitor 40k+ queries per day with minimal effort
Auditability: Enforced tracking and archiving without developer involvement
PDI framework
Ease of use: Adding new commands takes at most 45 minutes
Agile: Building the framework took 1 day
Low profile: Average memory usage of 250MB

Biggest mistakes along the way
• Initial integration design was based on provided documentation/models which was rarely accurate
• Current users of sources should have been engaged earlier to explain undocumented caveats
Reliance on documentation and requirements over expert users
• Variables were utilized late in development, slowing progress significantly and creating consistency issues
• Good initial design of templates will significantly reduce development time in mid/long run
Late utilization of templates and variables
• We attempted to design and populate the entire data vault prior to focusing on customer deliverables like reports (in addition to other projects)
• We have shifted focus to continuous release of new information rather than waiting for completeness
Aggressive overextension of resources

Primary takeaways
◦ Sources are like cars: the older they are, the more idiosyncrasies. Be cautious with design automation!
◦ Automation can enormously simplify/accelerate data warehousing. Don’t be afraid to roll your own
◦ Balance stateful versus stateless and monolithic versus fragmented architecture design
◦ Cloud based architecture based on column store DBs is extremely scalable, cheap, and highly performant
◦ A successful vault can create a new problem: getting IT to think about business processes rather than system keys!


















