
Data Mining CS 341, Spring 2007 Lecture14: Association Rules.
32
Data Mining Data Mining CS 341, Spring 2007 CS 341, Spring 2007 Lecture14: Association Lecture14: Association Rules Rules
-
date post
21-Dec-2015 -
Category
Documents
-
view
217 -
download
0
Transcript of Data Mining CS 341, Spring 2007 Lecture14: Association Rules.

Data MiningData Mining
CS 341, Spring 2007CS 341, Spring 2007
Lecture14: Association RulesLecture14: Association Rules

© Prentice Hall 2
Data Mining Core TechniquesData Mining Core Techniques
ClassificationClassification ClusteringClustering
Association RulesAssociation Rules

© Prentice Hall 3
Association Rules OutlineAssociation Rules Outline
Goal: Provide an overview of basic Provide an overview of basic Association Rule mining techniquesAssociation Rule mining techniques
Association Rules Problem OverviewAssociation Rules Problem Overview– Large itemsetsLarge itemsets
Association Rules AlgorithmsAssociation Rules Algorithms– AprioriApriori– SamplingSampling– PartitioningPartitioning

© Prentice Hall 4
Example: Market Basket DataExample: Market Basket Data Items frequently purchased together:Items frequently purchased together:
Bread Bread PeanutButterPeanutButter Uses:Uses:
– Placement Placement – AdvertisingAdvertising– SalesSales– CouponsCoupons
Objective: increase sales and reduce Objective: increase sales and reduce costscosts

© Prentice Hall 5
Association Rule DefinitionsAssociation Rule Definitions
Set of items:Set of items: I={I I={I11,I,I22,…,I,…,Imm}}
Transactions:Transactions: D={t D={t11,t,t22, …, t, …, tnn}, t}, tjj I I
Itemset:Itemset: {I {Ii1i1,I,Ii2i2, …, I, …, Iikik} } I I Support of an itemset:Support of an itemset: Percentage of Percentage of
transactions which contain that itemset.transactions which contain that itemset. Large (Frequent) itemset:Large (Frequent) itemset: Itemset Itemset
whose number of occurrences is above whose number of occurrences is above a threshold.a threshold.

© Prentice Hall 6
Association Rules ExampleAssociation Rules Example
I = { Beer, Bread, Jelly, Milk, PeanutButter}
Support of {Bread,PeanutButter} is 60%
Support of {Bread, Milk} is ?

© Prentice Hall 7
Association Rule DefinitionsAssociation Rule Definitions
Association Rule (AR): Association Rule (AR): implication X implication X Y where X,Y Y where X,Y I and X I and X Y = Y = ;;
Support of AR (s) X Support of AR (s) X YY: : Percentage of transactions that Percentage of transactions that contain X contain X YY
Confidence of AR (Confidence of AR () X ) X Y: Y: Ratio of Ratio of number of transactions that contain X number of transactions that contain X Y to the number that contain X Y to the number that contain X

© Prentice Hall 8
Association Rules Ex (cont’d)Association Rules Ex (cont’d)

© Prentice Hall 9
Association Rule ProblemAssociation Rule Problem Given a set of items I={IGiven a set of items I={I11,I,I22,…,I,…,Imm} and a } and a
database of transactions D={tdatabase of transactions D={t11,t,t22, …, t, …, tnn} } where twhere tii={I={Ii1i1,I,Ii2i2, …, I, …, Iikik} and I} and Iijij I, the I, the Association Rule ProblemAssociation Rule Problem is to is to identify all association rulesidentify all association rules X X Y Y with with a minimum support and confidence.a minimum support and confidence.
Link AnalysisLink Analysis NOTE:NOTE: Support of Support of X X Y Y is same as is same as
support of X support of X Y. Y.

© Prentice Hall 10
Association Rule TechniquesAssociation Rule Techniques
1.1. Find Large Itemsets.Find Large Itemsets.1.1. Large/frequent itemsets: number of Large/frequent itemsets: number of
occurrences is above a thresholdoccurrences is above a threshold
2.2. Techniques differ at this step.Techniques differ at this step.
2.2. Generate rules from frequent itemsets.Generate rules from frequent itemsets.

© Prentice Hall 11
Algorithm to Generate ARsAlgorithm to Generate ARs

© Prentice Hall 12
Association Rules OutlineAssociation Rules Outline
Goal: Provide an overview of basic Provide an overview of basic Association Rule mining techniquesAssociation Rule mining techniques
Association Rules Problem OverviewAssociation Rules Problem Overview– Large itemsetsLarge itemsets
Association Rules AlgorithmsAssociation Rules Algorithms– AprioriApriori– SamplingSampling– PartitioningPartitioning

© Prentice Hall 13
AprioriApriori
Large Itemset Property:Large Itemset Property:
Any subset of a large itemset is large.Any subset of a large itemset is large. Contrapositive:Contrapositive:
If an itemset is not large, If an itemset is not large,
none of its supersets are large.none of its supersets are large.

© Prentice Hall 14
Large Itemset PropertyLarge Itemset Property

© Prentice Hall 15
Apriori Ex (cont’d)Apriori Ex (cont’d)
s=30% = 50%

© Prentice Hall 16
Apriori AlgorithmApriori Algorithm
1.1. CC11 = Itemsets of size one in I; = Itemsets of size one in I;
2.2. Determine all large itemsets of size 1, LDetermine all large itemsets of size 1, L1;1;
3. i = 1;
4.4. RepeatRepeat
5.5. i = i + 1;i = i + 1;
6.6. CCi i = Apriori-Gen(L= Apriori-Gen(Li-1i-1););
7.7. Count CCount Cii to determine L to determine L i;i;
8.8. until no more large itemsets found;until no more large itemsets found;

© Prentice Hall 17
Apriori-GenApriori-Gen
Generate candidates of size i+1 from Generate candidates of size i+1 from large itemsets of size i.large itemsets of size i.
Approach used: join large itemsets of Approach used: join large itemsets of size i if they agree on i-1 size i if they agree on i-1
May also prune candidates who have May also prune candidates who have subsets that are not large.subsets that are not large.
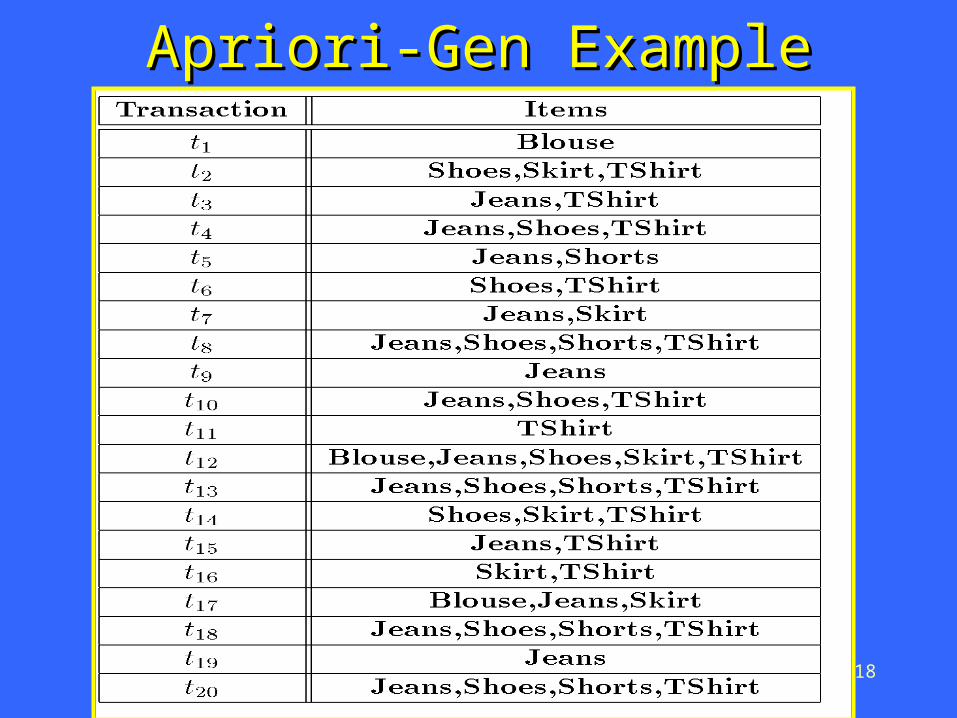
© Prentice Hall 18
Apriori-Gen ExampleApriori-Gen Example
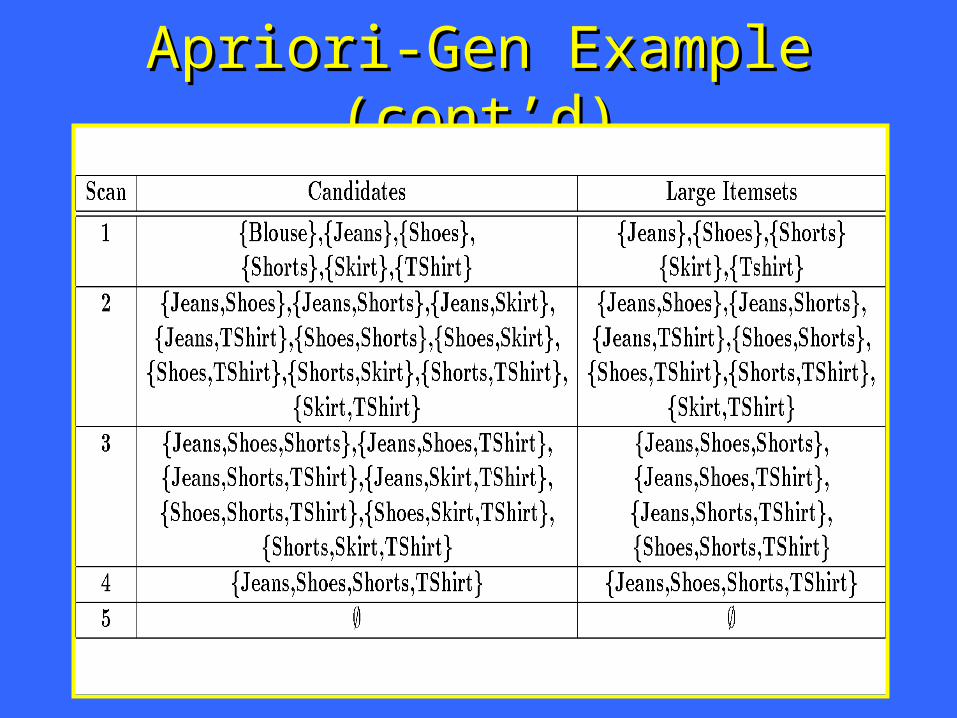
© Prentice Hall 19
Apriori-Gen Example (cont’d)Apriori-Gen Example (cont’d)

© Prentice Hall 20
Apriori Adv/DisadvApriori Adv/Disadv
Advantages:Advantages:– Uses large itemset property.Uses large itemset property.– Easily parallelizedEasily parallelized– Easy to implement.Easy to implement.
Disadvantages:Disadvantages:– Assumes transaction database is memory Assumes transaction database is memory
resident.resident.– Requires up to m database scans.Requires up to m database scans.

© Prentice Hall 21
Association Rules OutlineAssociation Rules OutlineGoal: Provide an overview of basic Provide an overview of basic
Association Rule mining techniquesAssociation Rule mining techniques Association Rules Problem OverviewAssociation Rules Problem Overview
– Large itemsetsLarge itemsets Association Rules AlgorithmsAssociation Rules Algorithms
– AprioriApriori– SamplingSampling– PartitioningPartitioning

© Prentice Hall 22
SamplingSampling Large databasesLarge databases Sample the database and apply Apriori to the Sample the database and apply Apriori to the
sample. sample. Potentially Large Itemsets (PL):Potentially Large Itemsets (PL): Large Large
itemsets from sampleitemsets from sample Negative Border (BD Negative Border (BD -- ): ):
– Generalization of Apriori-Gen applied to Generalization of Apriori-Gen applied to itemsets of varying sizes.itemsets of varying sizes.
– Minimal set of itemsets which are not in PL, Minimal set of itemsets which are not in PL, butbut whose subsets are all in PL. whose subsets are all in PL.
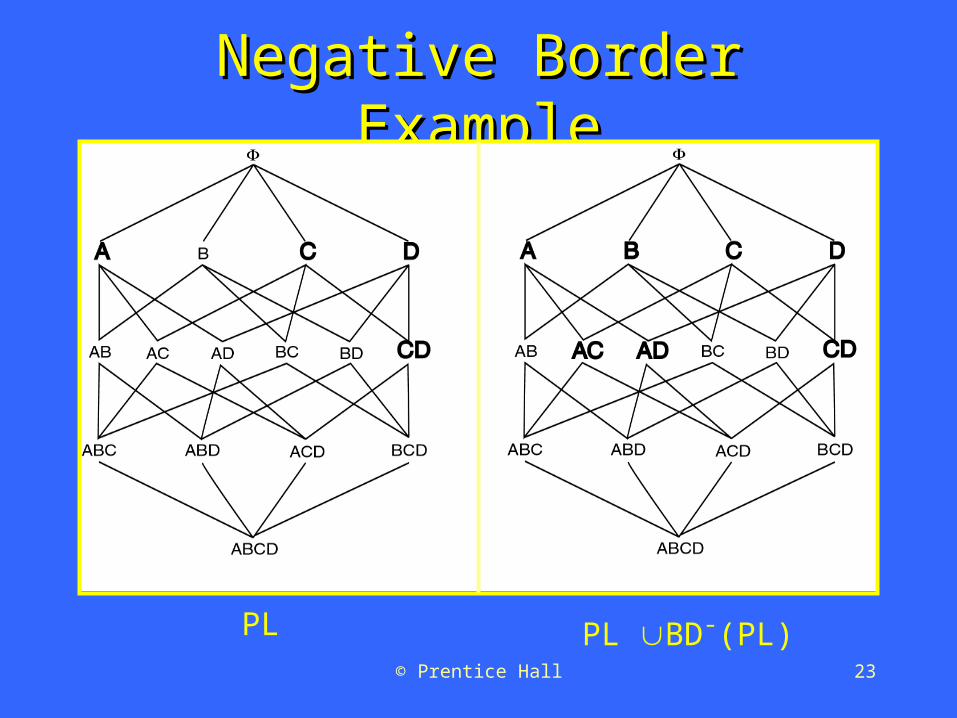
© Prentice Hall 23
Negative Border ExampleNegative Border Example
PL PL BD-(PL)

© Prentice Hall 24
Sampling AlgorithmSampling Algorithm
1.1. DDss = sample of Database D; = sample of Database D;
2.2. PL = Large itemsets in DPL = Large itemsets in Dss using smalls; using smalls;
3.3. C = PL C = PL BDBD--(PL);(PL);4.4. Count C in Database using s;Count C in Database using s;
5.5. ML = large itemsets in BDML = large itemsets in BD--(PL);(PL);6.6. If ML = If ML = then donethen done
7.7. else C = repeated application of BDelse C = repeated application of BD-;-;
8.8. Count C in Database;Count C in Database;

© Prentice Hall 25
Sampling ExampleSampling Example Find AR assuming s = 20%Find AR assuming s = 20% DDss = { t = { t11,t,t22}} Smalls = 10%Smalls = 10% PL = {{Bread}, {Jelly}, {PeanutButter}, PL = {{Bread}, {Jelly}, {PeanutButter},
{Bread,Jelly}, {Bread,PeanutButter}, {Jelly, {Bread,Jelly}, {Bread,PeanutButter}, {Jelly, PeanutButter}, {Bread,Jelly,PeanutButter}}PeanutButter}, {Bread,Jelly,PeanutButter}}
BDBD--(PL)={{Beer},{Milk}}(PL)={{Beer},{Milk}} ML = {{Beer}, {Milk}} ML = {{Beer}, {Milk}} Repeated application of BDRepeated application of BD- - generates all generates all
remaining itemsetsremaining itemsets

© Prentice Hall 26
Sampling Adv/DisadvSampling Adv/Disadv
Advantages:Advantages:– Reduces number of database scans to one Reduces number of database scans to one
in the best case and two in worst.in the best case and two in worst.– Scales better.Scales better.
Disadvantages:Disadvantages:– Potentially large number of candidates in Potentially large number of candidates in
second passsecond pass

© Prentice Hall 27
Association Rules OutlineAssociation Rules Outline
Goal: Provide an overview of basic Provide an overview of basic Association Rule mining techniquesAssociation Rule mining techniques
Association Rules Problem OverviewAssociation Rules Problem Overview– Large itemsetsLarge itemsets
Association Rules AlgorithmsAssociation Rules Algorithms– AprioriApriori– SamplingSampling– PartitioningPartitioning

© Prentice Hall 28
PartitioningPartitioning
Divide database into partitions DDivide database into partitions D11,D,D22,,…,D…,Dpp
Apply Apriori to each partitionApply Apriori to each partition Any large itemset must be large in at Any large itemset must be large in at
least one partition.least one partition.

© Prentice Hall 29
Partitioning AlgorithmPartitioning Algorithm
1.1. Divide D into partitions DDivide D into partitions D11,D,D22,…,D,…,Dp;p;
2. For I = 1 to p do
3.3. LLii = Apriori(D = Apriori(Dii););
4.4. C = LC = L11 … … L Lpp;;
5.5. Count C on D to generate L;Count C on D to generate L;

© Prentice Hall 30
Partitioning ExamplePartitioning Example
D1
D2
S=10%
L1 ={{Bread}, {Jelly}, {Bread}, {Jelly}, {PeanutButter}, {PeanutButter}, {Bread,Jelly}, {Bread,Jelly}, {Bread,PeanutButter}, {Bread,PeanutButter}, {Jelly, PeanutButter}, {Jelly, PeanutButter}, {Bread,Jelly,PeanutButter}}{Bread,Jelly,PeanutButter}}
L2 ={{Bread}, {Milk}, {Bread}, {Milk}, {PeanutButter}, {Bread,Milk}, {PeanutButter}, {Bread,Milk}, {Bread,PeanutButter}, {Milk, {Bread,PeanutButter}, {Milk, PeanutButter}, PeanutButter}, {Bread,Milk,PeanutButter}, {Bread,Milk,PeanutButter}, {Beer}, {Beer,Bread}, {Beer}, {Beer,Bread}, {Beer,Milk}}{Beer,Milk}}

© Prentice Hall 31
Partitioning Adv/DisadvPartitioning Adv/Disadv
Advantages:Advantages:– Adapts to available main memoryAdapts to available main memory– Easily parallelizedEasily parallelized– Maximum number of database scans is Maximum number of database scans is
two.two. Disadvantages:Disadvantages:
– May have many candidates during second May have many candidates during second scan.scan.

© Prentice Hall 32
Announcements:Announcements: Homework 4:Homework 4:
– Page161: 2, 6, 9Page161: 2, 6, 9– Page190: 1Page190: 1
Next week: five topics on perlNext week: five topics on perl– Overview of PerlOverview of Perl– Types of variables and operationsTypes of variables and operations– Input and output (file, keyboard, screen)Input and output (file, keyboard, screen)– Program controls &subroutines/functionsProgram controls &subroutines/functions– Regular expressions in PerlRegular expressions in Perl


















