
“DATA E WEB MINING” Introduzione - dsi.unive.itdm/Slides/1_Intro_DM.pdf · Parte delle slide...
76
1 Data e Web Mining - S. Orlando “DATA E WEB MINING” Introduzione Salvatore Orlando Parte delle slide del corso sono state parzialmente riprese da tutorial e corsi disponibili su web. In particolare Vipin Kumar, corso su Data mining presso University of Minnesota Jiawei Han, slide distribuite con il libro Data mining: concepts and techniques Li Yang, corso su Data mining presso Western Michigan University Giannotti/Pedreschi, Corso di Dottorato su Data mining presso Università di Pisa
-
Upload
dangkhuong -
Category
Documents
-
view
224 -
download
0
Transcript of “DATA E WEB MINING” Introduzione - dsi.unive.itdm/Slides/1_Intro_DM.pdf · Parte delle slide...

1 Data e Web Mining - S. Orlando
“DATA E WEB MINING”
Introduzione
Salvatore Orlando
Parte delle slide del corso sono state parzialmente riprese da tutorial e corsi disponibili su web. In particolare
Vipin Kumar, corso su Data mining presso University of Minnesota Jiawei Han, slide distribuite con il libro Data mining: concepts and techniques Li Yang, corso su Data mining presso Western Michigan University Giannotti/Pedreschi, Corso di Dottorato su Data mining presso Università di Pisa

2 Data e Web Mining - S. Orlando
Obiettivi del corso
Il corso fornisce le motivazioni ed i fondamenti del Data Mining (DM)
Analizza con un certo grado di dettaglio le principali tecniche di DM
Usa come caso di studio il Web, e le opportunità di estrarre utili conoscenze dall'analisi di mining della struttura ad hyperlink del Web, dai contenuti e dai log di uso.

3 Data e Web Mining - S. Orlando
Notizie generali sul corso
Sito Web: – http://www.dsi.unive.it/~dm – Iscriversi alla lista di discussione
Modalità di esame – Relazione di approfondimento e presentazione / Progetto – Scritto a domande aperte
Testi – P.-N. Tan, M. Steinbach, V. Kumar. Introduction to Data Mining. Pearson
Addison-Wesley. – J. Han, M. Kamber. Data mining: concepts and techniques. Morgan
Kaufmann. – M. H. Dunham. Data Mining: Introductory and Advanced Topics.
Prentice Hall.
– Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data. Springer-Verlag, 2006.
– Toby Segaran. Programming Collective Intelligence: Building Smart Web 2.0 Applications. O'Reilly, 2007.

4 Data e Web Mining - S. Orlando
Contenuti del corso

5 Data e Web Mining - S. Orlando
Ricchezza di dati Povertà di informazioni/conoscenze
Le basi di dati elettroniche sono sempre più grandi – Terrorbytes! – Siamo sommersi di dati … una vera inondazione – Immaginiamo che essi contengano molte informazioni nascoste ⇒ nuove conoscenze
Cosa ha portato a questo fenomeno? – Tecnologie per raccogliere dati
• Lettori di codici a barre, scanner, macchine fotografiche, ecc. – Tecnologie per memorizzare dati
• Basi di Dati, Data warehouses, altri tipi repository
Un esempio per tutti: – il WEB !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!

6 Data e Web Mining - S. Orlando
Mining Grandi Data Sets - Motivazioni
I dati contengono informazioni/conoscenze “nascoste” Gli analisti “umani” possono impiegare settimane per scoprire
queste informazioni La maggior parte dei dati finisce per non essere mai analizzata
The Data Gap
Total new disk (TB) since 1995
Number of analysts
From: R. Grossman, C. Kamath, V. Kumar, “Data Mining for Scientific and Engineering Applications”

7 Data e Web Mining - S. Orlando
Grandi quantità di dati vengono, in maniera routinaria, collezionati e immagazzinati – Web data, e-commerce – Acquisti presso supermercati – Transazioni Bancarie e di carte di
Credito
Dal punto di vista tecnologico, i computer sono diventati più potenti, capienti e meno cari, e abbiamo assistito ad un’evoluzione nelle reti
La competizione commerciale è molto forte – Fornire servizi migliori e
personalizzati per un segmento della clientela (e.g. in Customer Relationship Management)
Why Mine Data? Commercial Viewpoint

8 Data e Web Mining - S. Orlando

9 Data e Web Mining - S. Orlando
Why Mine Data? Scientific Viewpoint
I dati sono collezionati e memorizzati con enormi velocità (GB/hour) – sensori remoti – telescopi e satelliti che sondano i
cieli – microarray (applicazione di
bioinformatica) – simulazioni scientifiche che
generano terabyte di dati Tecniche tradizionali non applicabili
sui dati grezzi (non elaborati) Il data mining può aiutare gli
scienziati – in classificare e segmentare i dati – nella formulazione di nuove ipotesi

10 Data e Web Mining - S. Orlando
Data Mining e definizioni alternative
Data mining: – Estrazione di conoscenze non note e interessanti da grandi database,
come ad esempio pattern ricorrenti nascosti
Data mining: nome sbagliato o ambiguo? – Dovrebbe essere pattern mining in analogia con gold mining
Nomi alternativi – knowledge discovery (mining) in databases (KDD) – knowledge extraction – data/pattern analysis – data archeology – data dredging (dragare) – information harvesting (raccolta) – business intelligence, ecc.

11 Data e Web Mining - S. Orlando
Data Mining Query vs. Query tradizionali a DB
Query tradizionali e Output – accesso al DB operazionale (OLTP) con query ben definite espresse in un
linguaggio standard come SQL – output: sottoinsieme dei dati del DB, o specifiche aggregazioni semplici
Data mining query – query non definite precisamente. Natura esplorativa del processo di mining, con
impiego di strumenti e parametri differenti Data mining data
– Dati spesso differenti da quelli operazionali. Fase di selezione, pulitura e trasformazione precede solitamente il mining
Data mining output – L’output non è un sottoinsieme dei dati operazionali. Può ad esempio un
modello di conoscenza, che l’analista può usare per scopi di predizione.
Standard? – Non abbiamo ancora standard di Data Mining per quanto riguarda query
language, modelli dei dati, strumenti di mining

12 Data e Web Mining - S. Orlando

13 Data e Web Mining - S. Orlando
Esempio di analisi di data mining
Supponiamo che una società di gestione di carte di credito debba decidere se autorizzare o meno un’emissione
La società ha grandissime quantità di dati storici relativi a passate richieste di emissione
Ciascuna richiesta passata di emissione è stata classificata 1. autorizza 2. chiedi ulteriori informazioni 3. non autorizza 4. non autorizza e informa le autorità per possibili truffe
Si costruisce un modello dai dati storici (training) – Quali valori degli attributi hanno causato l’associazione di una delle4
classi alle varie richieste passate?
Si usa il modello per classificare e prendere decisioni rispetto a nuove richieste (classificazione) – Qual è l’etichetta di classe più plausibile da associare al record
associato con un nuovo cliente

14 Data e Web Mining - S. Orlando
Knowledge Discovery in Database

15 Data e Web Mining - S. Orlando
Cos’è quindi il KDD?
E’ un processo iterativo !!!
Consiste di passi sucessivi per la selezione e l’elaborazione di dati per:
– L’identificazione di nuovi, accurati, e utili pattern nei dati – La modellizzazione di fenomeni reali
Data mining (DM) è uno dei maggiori componenti del processo di KDD – scoperta automatica di pattern e sviluppo di modelli predittivi o
esplicativi del fenomeno
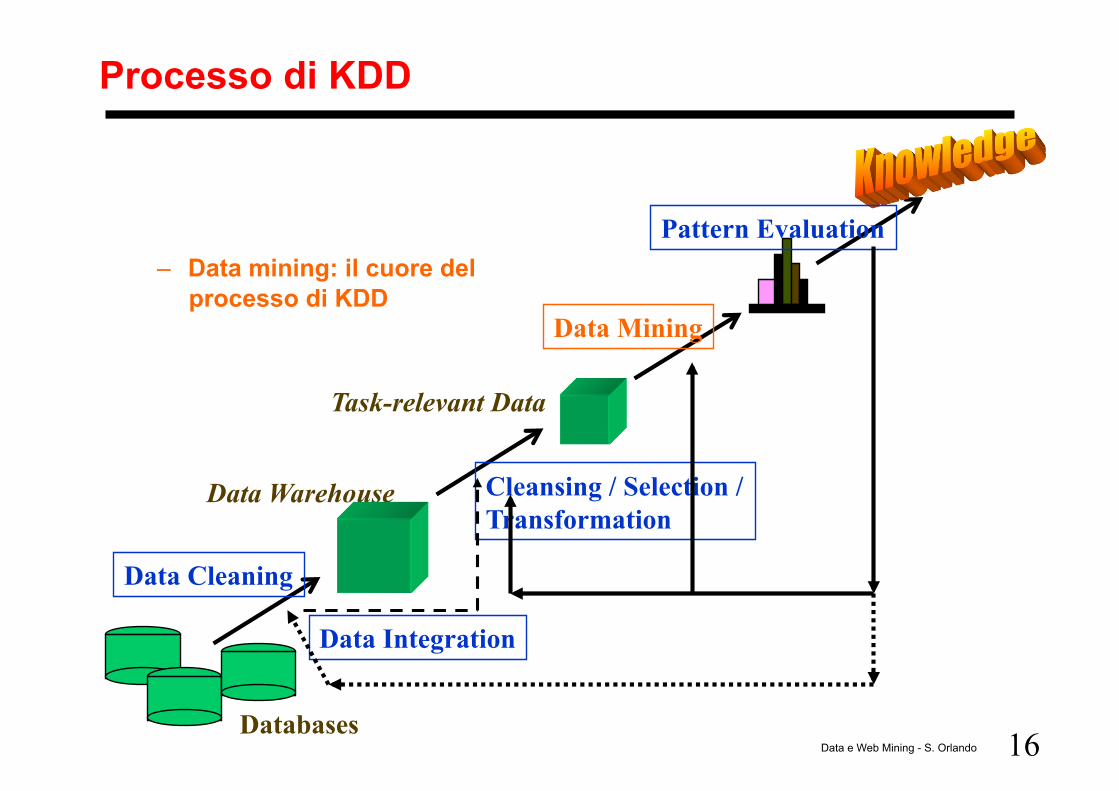
16 Data e Web Mining - S. Orlando
Processo di KDD
– Data mining: il cuore del processo di KDD
Data Cleaning
Data Integration
Databases
Data Warehouse
Task-relevant Data
Cleansing / Selection / Transformation
Data Mining
Pattern Evaluation

17 Data e Web Mining - S. Orlando
Passi di un processo di KDD Comprensione del campo applicativo
– conoscenza rilevante già disponibile e scopi dell'applicazione.
Creazione di un insieme di dati per l'analisi: selezione dei dati. Pulizia dei dati e pre-processing.
– fino al 60% dello sforzo complessivo.
Riduzione dei dati e trasformazione. – Questo passo ha a che fare con l'individuazione di caratteristiche utili, con la
riduzione del numero di attributi o della dimensionalità degli stessi
Individuazione delle funzioni di data mining: – classificazione, regressione, associazione, clustering.
Scelta degli algoritmi di data mining. Data mining: Ricerca dei pattern di interesse tramite gli strumenti
scelti. Valutazione dei pattern e presentazione della conoscenza
– visualizzazione, trasformazione, rimozione dei pattern ridondanti, ecc.
Uso della conoscenza acquisita.

18 Data e Web Mining - S. Orlando
KDD come confluenza di molte discipline

19 Data e Web Mining - S. Orlando
Analisi tradizionale dei dati Verification-driven
– L’utente formula ipotesi – Verifica le ipotesi tramite query OLAP su dati consolidati multi-
dimensionali Problemi:
– L’utente spesso non sa dove cercare le ipotesi giuste – Gli strumenti verification-driven estraggono dati
• L’utente deve generare informazione (conoscenza) sulla base della propria interpretazione

20 Data e Web Mining - S. Orlando
Un nuovo processo di analisi permesso dal DM
Discovery-driven – Il computer setaccia milioni di ipotesi e presenta solo le più
interessanti/valide
Esempio: – Da un campione di clienti che hanno trasferito il proprio conto
su una banca concorrente – identifica le caratteristiche dei clienti che sono correlati strettamente. Usando questi attributi, classifica il resto dei clienti e valuta quanto fortemente sono correlati al gruppo campione.

21 Data e Web Mining - S. Orlando
Data Mining versus Statistics
Statistica: – Analisi primaria: i dati sono raccolti per rispondere a domande
specifiche – piccole quantità di dati – significatività statistica
Data mining: – Analisi secondaria: i dati sono raccolti per scopi diversi – Grandissime quantità di data – Altre misure di interesse (compreso il gusto dell’utente)

22 Data e Web Mining - S. Orlando
Su che tipo di dati si effettua il DM?
Flat Files Legacy databases Relational databases
– e altri DB: Object-oriented and object-relational databases Transactional databases
– Transaction(TID, Timestamp, UID, {item1, item2, …})
Data warehouses Multimedia databases Spatial Databases Time Series Data and Temporal Data Grafi Text Documents WWW
– The content, The structure, The usage

23 Data e Web Mining - S. Orlando
Data Warehouse
Diverse definizioni, anche se non molto rigorose – Un database di supporto alle decisioni che è mantenuto separatamente
dal database operazionale dell’azienda – Fornisce una solida piattaforma di dati consolidati e storici per l’analisi
– “A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile collection of data in support of management’s decision-making process.”—W. H. Inmon
OLTP (on-line transaction processing) – Operazioni tradizionali in DBMS relazionali
OLAP (on-line analytical processing) OLAP – Operazioni tipiche dei data warehouse system – Analisi dei dati per il supporto alle decisioni

24 Data e Web Mining - S. Orlando
Dati multidimensionali
Un data warehouse è basato su un modello dei dati multi-dimensionale e multi-risoluzione
– Dati visti in forma di data cube
Esempio: i fatti del datawarehouse sono le vendite, che possiamo misurare in termini dei volumi di vendita
– Volumi di vendite come una funzione di prodotti, mesi, e regioni
Prod
uct
Month
Dimensions: Product, Location, Time +
Hierarchical summarization paths
Industry Region Year
Category Country Quarter
Product City Month Week
Office Day

25 Data e Web Mining - S. Orlando
Modellazione dimensionale
Una dimensione è una collezione di attributi logicamente correlati di una tabella relazionale
All’interno di ogni dimensione, gli attributi (entità) possono essere organizzati in gerarchie
I livelli all’interno di ogni gerarchia possono essere parzialmente/totalmente ordinati
Quando esiste un ordine tra due livelli (es. City < Country), possiamo definire un tipo di aggregazione tra i fatti relativi – es. l’incasso per ogni Country è la somma dell’incasso ottenuto nelle
varie City all’interno delle varie Country – in pratica, le gerarchie fissano i possibili group-by (aggregazioni)
L’operazione di aggregazione non è sempre la somma – es. se volessimo informazioni sul costo di ogni articolo venduto, invece
che sugli incassi totali, potremo essere interessati ad aggregare con operazioni di media, max, min
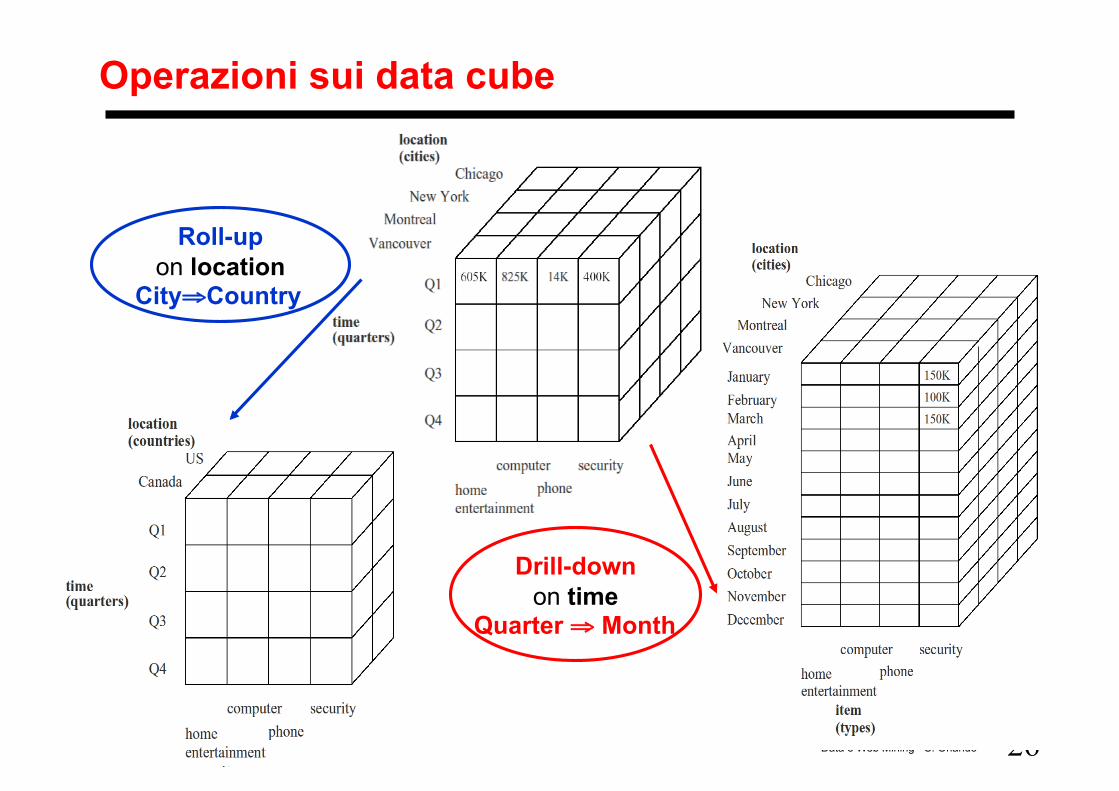
26 Data e Web Mining - S. Orlando
Operazioni sui data cube
Drill-down on time
Quarter ⇒ Month
Roll-up on location
City⇒Country

27 Data e Web Mining - S. Orlando
Come sono fatti i dati su cui effettuiamo il mining?
Collezioni di oggetti e loro attributi
Un attributo è una proprietà/caratteristica di un oggetto – Esempi: colore degli occhi
di una persona, temperatura in certo luogo e tempo, ecc.
– Nomi alternativi: variabile, field, caratteristica, o feature
Una collezione di attributi descrive un oggetto – Nomi alternativi: record,
punto, caso, campione, entità o istanza
Attributes
Objects

28 Data e Web Mining - S. Orlando
Valori degli attributi
I valori degli attributi che caratterizzano un dato oggetto sono numeri o simboli
Distinguiamo tra attributi e relativi valori – Stesso attributo può essere messo in relazione con differenti
scale di misura e quindi con differenti valori • Es.: altezza misurata in piedi o metri
– Le proprietà dell’attributo di un oggetto possono essere diverse dalle proprietà della misura, associata all’attributo in accordo ad una certa scala di misurazione
• Es.: I valori degli attributi di ID e age sono interi • Ma le proprietà degli attributi sono diverse
– ID non ha in generale un limite sup. o inf., mentre age ha un massimo ed un minimo
– anche se possiamo calcolare la media di un insieme di interi, non ha senso la media degli ID

29 Data e Web Mining - S. Orlando
Misura associata all’attributo Lunghezza
Il modo in cui associamo valori agli attributi potrebbe non riflettere certe proprietà degli attributo stesso
Cattura l’ordine Cattura l’ordine e la proprietà additiva della lunghezza

30 Data e Web Mining - S. Orlando
Tipi di attributi
Categorici – In numero finito e differenti in tipo
Numerici – Valori ordinati, spesso con insiemi infiniti di valori assunti
Più precisamente – Categorici (Qualitativi, tipicamente Discreti)
• Nominali: Insiemi di valori distinti: es. Sesso, ecc. (=, ≠) • Ordinali: Valori discreti ordinati: es. Titolo di Studio (<, >)
– Numerici (Quantitativi, spesso Continui) • Interval: Valori con una misura di distanza: es. Temperatura • Ratio: Valori con distanza e zero assoluto, dove il rapporto tra misure è
significativo: es.: Età, Guadagno, Lunghezza

31 Data e Web Mining - S. Orlando
Proprietà dei valori dei vari tipi di attributo
Il tipo di un attributo dipende dalle seguenti proprietà: – Distinctness: = ≠ – Order: < > – Addition: + - – Multiplication: * /
– Nominal: distinctness – Ordinal: distinctness & order – Interval: distinctness, order & addition – Ratio: all 4 properties
Categorical (Qualitative)
Numeric (Quantitative)

32 Data e Web Mining - S. Orlando
ßΩ Attribute Type
Description Examples Operations
Nominal The values of a nominal attribute are just different names, i.e., nominal attributes provide only enough information to distinguish one object from another. (=, ≠)
zip codes, employee ID numbers, eye color, sex: {male, female}
mode, entropy, contingency correlation, χ2 test
Ordinal The values of an ordinal attribute provide enough information to order objects. (<, >)
hardness of minerals, {good, better, best}, grades, street numbers
median, percentiles, rank correlation, run tests, sign tests
Interval For interval attributes, the differences between values are meaningful, i.e., a unit of measurement exists. The ratio of two measures is not meaningful (+, - )
calendar dates, temperature in Celsius or Fahrenheit
mean, standard deviation, Pearson's correlation, t and F tests
Ratio For ratio variables, both differences and ratios are meaningful. (*, /)
I can say measure 500 is two times measure 250, since 500/250=2
temperature in Kelvin, monetary quantities, counts, age, mass, length, electrical current
geometric mean, harmonic mean, percent variation

33 Data e Web Mining - S. Orlando
Attribute Level
Transformation Comments
Nominal Any permutation of values If all employee ID numbers were reassigned, would it make any difference?
Ordinal An order preserving change of values, i.e., new_value = f(old_value) where f is a monotonic function.
An attribute encompassing the notion of good, better best can be represented equally well by the values {1, 2, 3} or by { 0.5, 1, 10}.
Interval new_value =a * old_value + b where a and b are constants
Thus, the Fahrenheit and Celsius temperature scales differ in terms of where their zero value is and the size of a unit (degree).
Ratio new_value = a * old_value Length can be measured in meters or feet.

34 Data e Web Mining - S. Orlando
Tipi di dataset su cui si effettua il mining
Record – Data Matrix – Document Data – Transactional Data
Graph – World Wide Web – Molecular Structures
Ordered – Spatial Data – Temporal Data – Sequential Data – Genetic Sequence Data

35 Data e Web Mining - S. Orlando
Record data
Una tabella relazione, dove ogni record è associato con un numero fisso di attributi

36 Data e Web Mining - S. Orlando
Transactional Data
Un tipo speciale di record, dove – ogni record (transazione) coinvolge un insieme variabile di item. – Per esempio, consideriamo la visita ad un supermercato da parte di un
cliente: • Transazione = Scontrino fiscale • Insieme di prodotti (item) acquistati
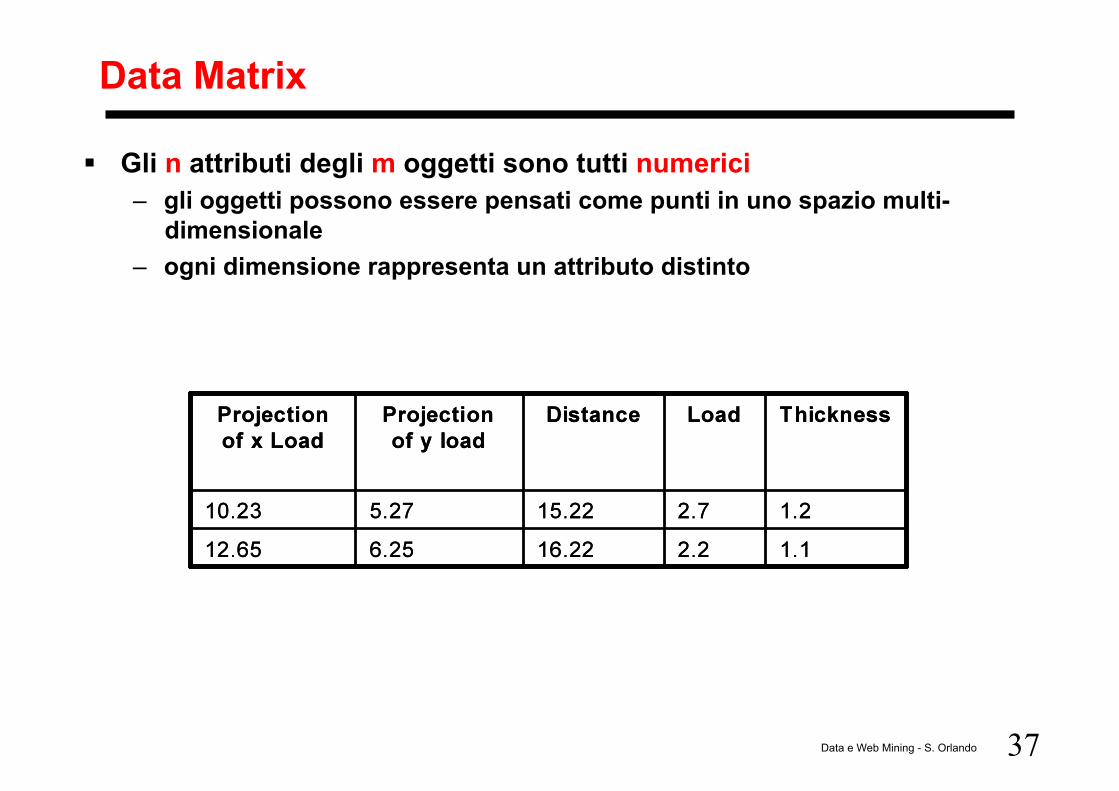
37 Data e Web Mining - S. Orlando
Data Matrix
Gli n attributi degli m oggetti sono tutti numerici – gli oggetti possono essere pensati come punti in uno spazio multi-
dimensionale – ogni dimensione rappresenta un attributo distinto

38 Data e Web Mining - S. Orlando
Document Data
Ogni documento diventa un vettore dei termini – ogni termine = componente (attributo) di un vettore – valore di ogni componente = numero di volte il termine corrispondente
occorre nel documento
In generale, la matrice dei documenti è una matrice sparsa, dove i termini 0 sono meno importanti e sono preponderanti (significato asimmetrico dei valori degli attributi) – Anche la rappresentazione 0-1 di un database transazionale è una matrice
sparsa

39 Data e Web Mining - S. Orlando
Graph Data
Esempi: Grafo Generico e link HTML – Le etichette degli archi possono riflettere il numero di visite da parte di
una comunità di utenti

40 Data e Web Mining - S. Orlando
Molecular Structures
Benzene Molecule: C6H6

41 Data e Web Mining - S. Orlando
Ordered Data
Sequential data = Sequenze di transazioni (ordinate temporalmente) – ogni riga/sequenza associata ad un unico soggetto (es. un cliente di un
supermercato)
Un elemento della sequenza = Transazione/Evento
Items
Sequenza
Un timestamp esplicito t può essere associato con ogni elemento

42 Data e Web Mining - S. Orlando
Ordered Data
Genomic sequence data

43 Data e Web Mining - S. Orlando
Ordered Data
Spatio-Temporal Data
Average Monthly Temperature of land and ocean

44 Data e Web Mining - S. Orlando
Qualità dei dati
Quali sono i problemi relativi alla qualità dei dati? Come possiamo fare per scoprire e risolvere questi problemi?
Esempi: – Noise: Modifica dei valori originali – Missing: Mancanza dei valori – Duplicate data
• Gestione: – Eliminazione di oggetti/record – Stima di valori missing – Ignorare i valori durante l’analisi
– Outliers • Oggetti considerevolmente diversi
rispetto alla maggioranza

45 Data e Web Mining - S. Orlando
Data preprocessing
Aggregation Sampling Dimensionality Reduction Feature subset selection Feature creation Discretization and Binarization Attribute Transformation

46 Data e Web Mining - S. Orlando
Aggregation
Combinare più attributi (o oggetti) in un singolo attributo (o oggetto)
Scopo – Data reduction
• Ridurre il numero di attributi o oggetti – Change of scale
• Città aggregate in province, regioni, nazioni, ecc. – More “stable” data
• Dati aggregati tendono ad avere meno variabilità

47 Data e Web Mining - S. Orlando
Aggregation
Standard Deviation of Average Monthly
Precipitation
Standard Deviation of Average Yearly
Precipitation
Variazione delle precipitazioni in Australia

48 Data e Web Mining - S. Orlando
Sampling
Il Sampling è spesso la principale tecnica impiegata per il Data Selection
E’ spesso usata per effettuare analisi preliminari, ma per le analisi finali
Statistica vs. Data Mining – Nel primo caso i dati sono campionati perché ottenere l’intero dataset è
troppo costoso in termini di costo o tempo – Nel secondo caso, i dati sono campionati perché processare l’intero
data set potrebbe essere troppo costoso in termini di tempo
Un efficace sampling deve rispondere ai seguenti principi chiave: – Usando un sampled dataset rappresentativo, otteniamo risultati simili a
quelli ottenuti processando l’intero dataset – Il campionamento è rappresentativo se ha approssimativamente le
stesse proprietà del dataset originale

49 Data e Web Mining - S. Orlando
Tipi di Sampling
Simple Random Sampling – Uguale probabilità di selezionare ogni item/oggetto
Simple Random Sampling without replacement – Una volta estratto, l’item è rimosso dal dataset e NON è
rimpiazzato nel dataset (un item può essere scelto solo una volta)
Simple Random Sampling with replacement – Una volta estratti, gli item sono rimessi nel dataset (lo stesso
item può essere selezionato più volte) Stratified sampling
– Spezza i dati in tanti partizioni disgiunte, e poi estrai campioni casuali da ogni partizione
– Serve a ottenere campioni rappresentativi anche se i dati sono skewed (distribuzioni non simmetriche).
– Ad esempio, se partizioniamo dati demografici rispetto all’età, riusciamo a campionare anche gruppi con bassa numerosità

50 Data e Web Mining - S. Orlando
Sample Size
8000 points 2000 Points 500 Points

51 Data e Web Mining - S. Orlando
Task di Data Mining
ID Home Owner
Marital Status
Annual Income
Defaulted borrower
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 80K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes
DATA

52 Data e Web Mining - S. Orlando
Caratterizzazione dei Task di DM
Metodi Predittivi – Usa alcune variabili per predire valori futuri o sconosciuti di altre
variabili Metodi Descrittivi
– Trova pattern interpretabili che descrivono caratteristiche dei dati
Classification [Predittivo] Clustering [Descrittivo] Association Rule Discovery [Descrittivo] Sequential Pattern Discovery [Descrittivo] Regression [Predittivo] Deviation Detection [Predittivo]

53 Data e Web Mining - S. Orlando
Task di DM
Classificazione – Suddividi/Classifica un insieme di record in classi differenti
• costruisci il dataset di training – Induci un modello a partire dal dataset di training – Il modello è usato per la predire la classe di nuovi record da classificare
(supervised classification)
– Esempi: • Classifica studenti, usando i voti come etichetta di classe • Classifica nazioni, usando il clima come etichetta di classe
– Presentazione del modello: • Alberi di decisioni, regole di classificazione, reti neurali
Predizione – Predici alcuni valori numerici sconosciuti o mancanti

54 Data e Web Mining - S. Orlando
Task di Data Mining
Classificazione
Test Set
Training Set Model
Learn Classifier

55 Data e Web Mining - S. Orlando
Task di DM
Classificazione: Alberi di Decisione
Refund
MarSt
TaxInc
YES NO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Splitting Attributes
L’attributo di splitting è scelto in base alla sua capacità di discriminare rispetto al database in input

56 Data e Web Mining - S. Orlando
Task di DM
Association rules (correlazione e causalità) – Dati
• Collezione di articoli (item) • Insiemi di transazioni, ognuna contente un sottoinsieme di item
trova affinità tra gli item
– Esempi: • il 42% dei compratori che acquistano latte, comprano anche pane
• age(X, “20..29”) ^ income(X, “20..29K”) buys(X, “PC”) [support = 2%, confidence = 60%]

57 Data e Web Mining - S. Orlando
Task di DM
Esempio di Regole Associative per il Market Basket Analysis (MBA)
Market-Basket Transactional database
Esempio di regola associativa:
Supporto = 60% Confidenza = 75%
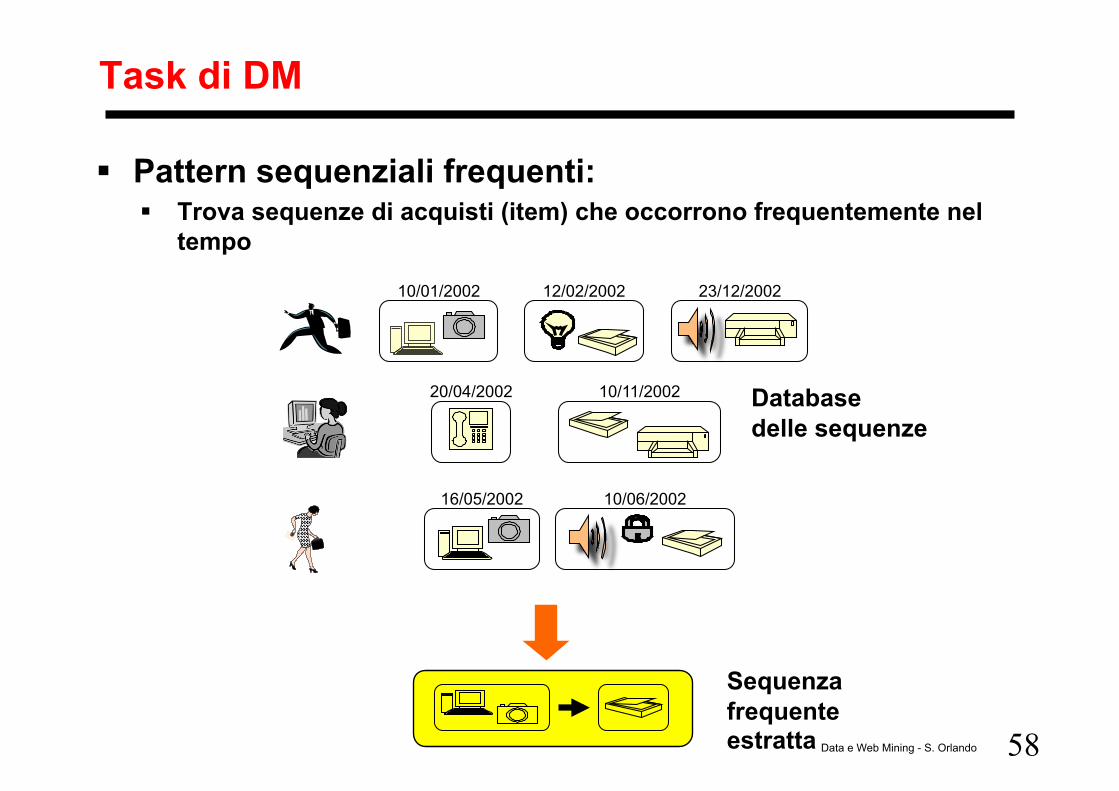
58 Data e Web Mining - S. Orlando
Task di DM
Pattern sequenziali frequenti: Trova sequenze di acquisti (item) che occorrono frequentemente nel
tempo
10/01/2002 12/02/2002 23/12/2002
10/11/2002 20/04/2002
16/05/2002 10/06/2002
Database delle sequenze
Sequenza frequente estratta

59 Data e Web Mining - S. Orlando
Task di DM
Clustering – Segmenta un database in sottoinsiemi (i cluster)
• L’etichetta delle classi associati ai record è sconosciuta • Unsupervised classification
– Clustering basato sul principio seguente:
• minimizza la similarità inter-classe e massimizza la similarità intra-class
– Es.: raggruppa un insieme di individui in base ai dati demografici

60 Data e Web Mining - S. Orlando
Task di DM
Analisi degli outlier – Outlier: un oggetto/dato che non è conforme rispetto alle
caratteristiche generali degli altri dati – Possono essere considerati come rumore o eccezioni, ma
possono essere utili per individuare frodi, analisi di eventi rari, ecc.
– Esistono algoritmi di clustering che come effetto collaterale riescono ad individuare gli outlier
Similar Time Sequences – Trova tutte le occorrenze di sottosequenze simili a specifiche
sequenze temporali

61 Data e Web Mining - S. Orlando
I pattern estratti sono interessanti ?
Un sistema di DM può generare migliaia di pattern, ma non tutte sono interessanti – I risultati possono essere così tanti che possiamo aver bisogno di
strumenti di mining per estrarre i pattern più interessanti (Meta-Mining?)
Come misuriamo se un pattern è interessante? – Se facilmente comprensibile dagli utenti, o è nuovo e potenzialmente
utile – Se valida ipotesi che un utente cercava di confermare – Se testato su nuovi dati, è valido con un certo grado di certezza
Misure di interesse oggettive vs. soggettive – Oggettive: basate su misure statistiche, es. supporto, confidenza, ecc. – Soggettive: basate sull’intuito/esperienza dell’utente, es. inaspettato,
nuovo, ecc.

62 Data e Web Mining - S. Orlando
Principali applicazioni del DM
Financial Service – Combat attrition – Fraud detection – Loan default
Telecommunications – Identify high value
customers – Identify cross-sell
opportunity Life Science
– Find factors associated with healthy or unhealthy patients
Retail and Marketing – Market Basket Analysis – Loyalty program – Cross-sell & Up-sell – Fraud detection – More targeted & successful
campains Insurance & Government
– Flag accountancy anomalies
– Reduce cost of investigating suspicious activities or false claims
Web and Electronic Commerce – Recommender Systems – Ranking of Search Results

63 Data e Web Mining - S. Orlando
Caso d’uso: CRM
Customer Relationship Management (CRM) – Suddivisione dei clienti in gruppi, sulla base di variabili che riassumono il
valore di ciascun gruppo di clienti • profitto realizzabile, misure di fidelizzazione, misure di rischio
Gruppo di clienti a basso rischio, alto profitto e che producono un alto valore del fatturato ⇒ Da mantenere (retention) – In molti tipi di business questo tipo di gruppo rappresenta dal 10 al 20% dei
clienti, e crea dal 50% all'80%del profitto aziendale. – L'azienda non vuole perdere questi clienti. Iniziative promozionali per
rafforzare il legame di fedeltà. Gruppo di clienti che dà luogo ad alti fatturati, ma a bassi profitti
⇒ Potrebbe contenere clienti che da mantenere e coltivare. – Incrementare il profitto per questo gruppo. – cross-selling (vendita di nuovi prodotti, ispirandosi al comportamento del
gruppo più redditizio) – up-selling (vendere più prodotti di quanto i clienti comprano
correntemente).

64 Data e Web Mining - S. Orlando
Caso d’uso: CRM
Clustering e Market Baset Analysis (MBA) applicata per identificare stragegie di marketing per il CRM (figura adattata dall' IBM Red Book dal titolo "Intelligent Miner for Data Applications Guide", March 1999)

65 Data e Web Mining - S. Orlando
Caso d’uso: Web mining
Il Web Mining consiste nell’applicazione di tecniche di DM al WWW
Data Mining – DM applicato a database strutturati
Web mining – applicato a dati meno strutturati, molto dinamici, e di enormi
dimensioni – non solo contenuti, ma anche hyperlink, e log di accessi e uso
Tre tipi di WM – Web Content Mining – Web Structure Mining – Web Usage Mining
Knowledge www

66 Data e Web Mining - S. Orlando
Web Mining
Web: – A huge, widely-distributed, highly heterogeneous, semistructured,,
interconnected, evolving, hypertext/hypermedia information repository
Principali problemi – Abbondanza delle informazioni sul Web:
• Il 99% delle informazioni sono di nessun interesse per il 99% delle persone – Copertura limilata delle informazioni disponibili:
• La maggior parte delle risorse e delle informazioni sono nascoste nei DBMS. – Search Engine con interfacce limitate
• Solo query con insiemi di keyword per esprimire i bisogni informativi degli utenti
– Poca personalizzazione rispetto ai singoli individui • Navigazione e Search
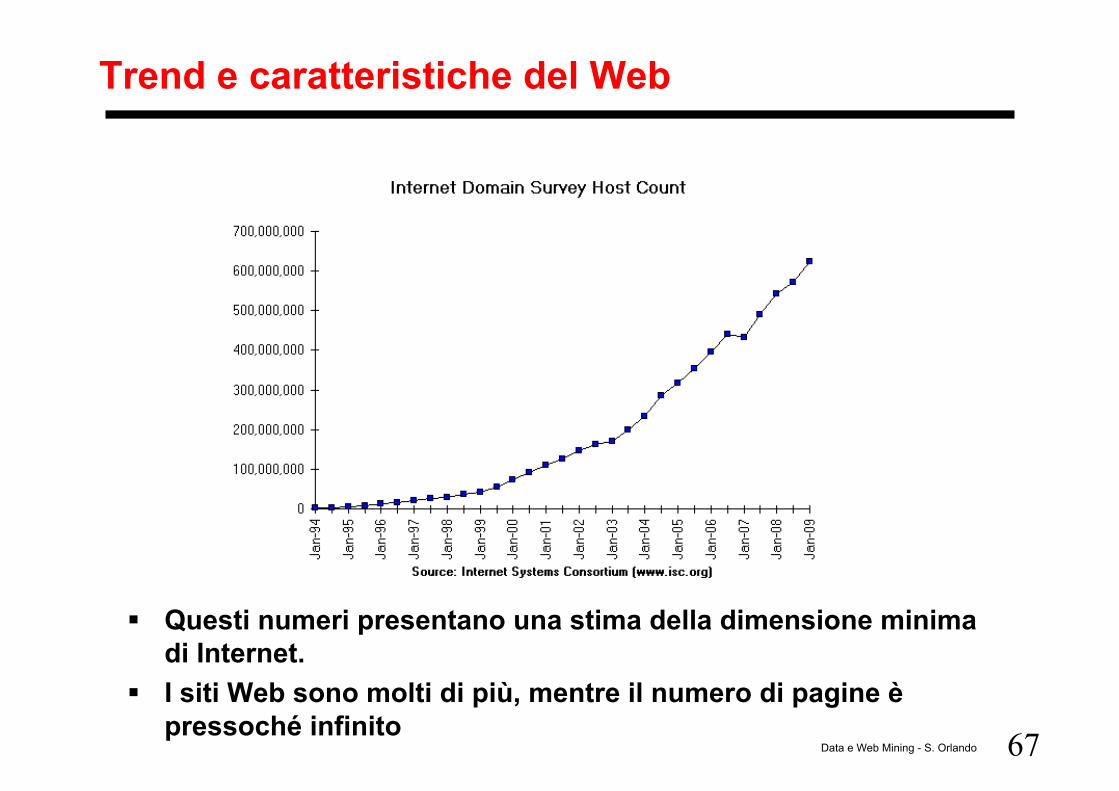
67 Data e Web Mining - S. Orlando
Trend e caratteristiche del Web
Questi numeri presentano una stima della dimensione minima di Internet.
I siti Web sono molti di più, mentre il numero di pagine è pressoché infinito

68 Data e Web Mining - S. Orlando
Trend e caratteristiche del Web
Google nel luglio del 2007 ha annunciato di aver individuato circa 1 trilione (1012) di pagine/URL uniche sul Web – Dopo aver rimosso i duplicati (stimati intorno al 30%-40%) !!! – Crescita stimata: diversi miliardi di pagine al giorno – Fonte: http://googleblog.blogspot.com/2008/07/we-knew-web-was-
big.html Nota che molte pagine sono create dinamicamente …. e questo
complica le cose ai sistemi come Google – Pensiamo ad un calendario sul Web …. ed ad un link prossimo mese …
potremmo seguirlo all’infinito e creare sempre nuove pagine

69 Data e Web Mining - S. Orlando
Trend e caratteristiche del Web
Ma quanti dischi mi servirebbero per contenere tutte le pagine Web? – Consideriamo solo il testo (HTML) – Una media di 10K Byte (≅ 104 caratteri)
per pagina – Moltiplichiamo per un trilione di pagine !! !Abbiamo circa 1016 Byte
– Se la taglia di un tipico Hard Disk permette la memorizzazione di circa 100 Gbyte (≅ 1011 caratteri)
!! Abbiamo bisogno di circa 100.000 dischi Le cose peggiorano drammaticamente con i dati
multimediali, come immagini e video

70 Data e Web Mining - S. Orlando
Trend e caratteristiche del Web
Oltre alla crescente creazione di nuove pagine, le pagine sono continuamente aggiornate o cancellate – Circa il 23% delle pagine viene modificato giornalmente
– Nel dominio .com questa percentuale sale al 40% – In media, dopo circa 10 giorni, la metà delle pagine viene
cancellata • Le loro URL non sono più valide
A. Arasu et al., “Searching the Web”, ACM Transaction on Internet Technology, 1(1), 2001.

71 Data e Web Mining - S. Orlando
Trend e caratteristiche del Web
La struttura del grafo del Web (Bow-tie ) – 28% delle pagine
• cuore della rete • pagine importanti …
molto connesse tra loro
– 22% delle pagine • raggiungibile a partire
da pagine del cuore, ma non viceversa
– 22% delle pagine • può raggiungere pagine del cuore, ma non viceversa
– Il resto delle pagine sono disconnesse dal cuore della rete
Andrei Broder, et al. “Graph structure in the web: experiments and models” 9th WWW, 2000.

72 Data e Web Mining - S. Orlando
Trend e caratteristiche del Web
Andrei Broder, et al. “Graph structure in the web: experiments and models” 9th WWW, 2000.
Power law.

73 Data e Web Mining - S. Orlando
La Power law (Long Tail) è onnipresente
Contenuto – Parolenelle pagine
Struttura – In-degrees / Out-degrees / Numbero di pagine per sito
Usage patterns – Numbero di visitatori – Query/Termini sottomettesse dagli utenti di un motore di ricerca – Popolarità di prodotti, musica, film, …

74 Data e Web Mining - S. Orlando
Ancora Long Tail (popolarità di prodotti - songs)

75 Data e Web Mining - S. Orlando
Possibili sfide per il WM
Trovare informazioni rilevanti – informazioni/risorse di qualità rispetto ad un determinato argomento/
problema/necessità
Creare conoscenza dalle informazione disponibile Imparare dal comportamento di clienti/utenti
– Imparare dai comportamenti di acquisto – Imparare dai comportamenti di navigazione – Imparare dai comportamenti di query issuing
Personalizzazione del delivery della conoscenza

76 Data e Web Mining - S. Orlando
Web mining taxonomy


















