
Darshan Institute of Engineering & Technology 170704 ... · various nodes are associated to create...
36
Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology Ishan Rajani 1 1. What is cluster computing? Explain the scalable parallel computer architecture in detail. [Summer-14, Winter-12, Summer-12, Total: 21 marks] Cluster Computing: A computer cluster consists of a set of loosely connected or tightly connected computers that work together so that in many respects they can be viewed as a single system. Various Scalable parallel architectures are as follows: MPP o A large parallel processing system with a shared-nothing architecture o Consist of several hundred nodes with a high-speed interconnection network/switch o Each node consists of a main memory & one or more processors o Runs a separate copy of the OS SMP o 2-64 processors today o Shared-everything architecture o All processors share all the global resources available o Single copy of the OS runs on these system CC-NUMA o A scalable multiprocessor system having a cache-coherent non-uniform memory access architecture o Every processor has a global view of all of the memory Distributed systems o Considered conventional networks of independent computers o Have multiple system images as each node runs its own os o The individual machines could be combinations of mpps, smps, clusters, & individual computers Clusters o A collection of workstations of pcs that are interconnected by a high-speed network o Work as an integrated collection of resources o Have a single system image spanning all its nodes Key Characteristics of Scalable Parallel Computers
Transcript of Darshan Institute of Engineering & Technology 170704 ... · various nodes are associated to create...

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 1
1. What is cluster computing? Explain the scalable parallel computer architecture in detail.
[Summer-14, Winter-12, Summer-12, Total: 21 marks]
Cluster Computing: A computer cluster consists of a set of loosely connected or tightly connected
computers that work together so that in many respects they can be viewed as a single system.
Various Scalable parallel architectures are as follows:
MPP
o A large parallel processing system with a shared-nothing architecture
o Consist of several hundred nodes with a high-speed interconnection network/switch
o Each node consists of a main memory & one or more processors
o Runs a separate copy of the OS
SMP
o 2-64 processors today
o Shared-everything architecture
o All processors share all the global resources available
o Single copy of the OS runs on these system
CC-NUMA
o A scalable multiprocessor system having a cache-coherent non-uniform memory access
architecture
o Every processor has a global view of all of the memory
Distributed systems
o Considered conventional networks of independent computers
o Have multiple system images as each node runs its own os
o The individual machines could be combinations of mpps, smps, clusters, & individual
computers
Clusters
o A collection of workstations of pcs that are interconnected by a high-speed network
o Work as an integrated collection of resources
o Have a single system image spanning all its nodes
Key Characteristics of Scalable Parallel Computers

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 2
2. Define cluster computing and explain its components with an architecture diagram in detail?
[Summer 12, Winter 11, Total: 14 Marks]
Cluster computing is the use of a collection of computers or workstations working together as a
single, integrated computing resource connected via high speed interconnects.
Following are the components of a cluster computer:
High performance computers: These can be PCs, workstations, SMP. These nodes generally have
memory, I/O facility and operating system.
Modern operating system: OS should be layered or micro kernel based. Typical OS used in clusters
are Linux, Solaris, Windows NT.
High speed networks/Switches: Interconnects as Gigabit Ethernet, ATM etc are suitable and high
performance switches are used for connections.
Network Interface hardware is generally various NICs which is an interface to network.
Communication Software includes various fast communication protocols and services as AM, FM
which is used for speedy communication between nodes.
Cluster Middleware: its basic aim is to provide SSI and SAI services to the user. It includes
o Hardware like Hardware DSM, Memory channel etc.
o Operating system kernel also called the gluing layer like Solaris MC, GLUnix etc.
o Applications and subsystem like Software DSM, File systems Management tools, RMS
software etc
Parallel Programming environment and Tools: These provide portable, efficient and easy to use
tools to work in parallel environment and run applications simultaneously. E.g. PVM, MPI etc.
Applications: Sequential as well as parallel applications can be run on a cluster.
3. Explain design goal of middleware in cluster computing. Explain in brief the key services of SSI and
availability infrastructure. [Winter 13, Winter 11, Total: 14 marks]
Complete Transparency in Resource Management
o Allow user to use a cluster easily without the knowledge of the underlying system
architecture

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 3
o The user is provided with the view of a globalized file system, processes, and network
Scalable Performance
o Can easily be expanded, their performance should scale as well
o To extract the max performance, the SSI service must support load balancing & parallelism
by distributing workload evenly among nodes
Enhanced Availability
o Middleware service must be highly available at all times
o At any time, a point of failure should be recoverable without affe ti g a user’s appli atio o Employ check pointing & fault tolerant technologies
o Handle consistency of data when replicated
SSI Support Services:
SINGLE POINT OF ENTRY: The user can connect to the cluster as a single system instead of
individual nodes.
SINGLE FILE HIERARCHY: There is hierarchy of files and all the directories come under same root
director for every user. The hierarchy of files appears same to every user
SINGLE POINT OF MANAGEMENT: Entire cluster could be maintained and controlled from a
single window (like Task Manager in Windows).
SINGLE VIRTUAL NETWORKING: Any node can be accessed from any other node throughout the
cluster, whether there is a physical link between the nodes or not.
SINGLE MEMORY SPACE: It appears as there is a huge single, shared memory. Memories of
various nodes are associated to create an illusion of a single memory.
SINGLE JOB MANAGEMENT SYSTEM: User can submit job from any node and job can be run in
parallel, batch or interactive modes.
SINGLE USER INTERFACE: There should be a single cluster wide GUI interface for the user. The
look and feel of the interface should be uniform on every node.
Availability Support Services:
SINGLE I/O SPACE: Any node can perform I/O operations on local or remote peripheral devices.
SINGLE PROCESS SPACE: Every process is unique throughout the cluster and has a unique cluster
wide process ID. Process can create child process on same or different nodes. Cluster should
support global process management.
CHECKPOINTING AND PROCESS MIGRATION: In checkpointing, intermediate process results are
saved so that process can resume from last checkpoint in case of system failure.
Process migration is the moving and running of process on some other node when there is a
system crash or when the load on a particular node increases.
4. Explain cluster classification in detail. OR Explain Types of Clusters in detail.
[Summer 14(7 marks), Winter 12(7 marks), Total: 14 marks]
Classification of clusters are based on following factors:
Application target
Node ownership
Node hardware
Node OS
Node configuration
o Homogeneous and Heterogeneous
Level of clustering
o Group cluster
o Departmental cluster
o Organizational cluster

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 4
Types of clusters:
High availability cluster:
High-availability clusters (also known as HA clusters or failover clusters) are groups of computers
that support server applications that can be reliably utilized with a minimum of down-time.
They operate by harnessing redundant computers in groups or clusters that provide continued
service when system components fail.
Without clustering, if a server running a particular application crashes, the application will be
unavailable until the crashed server is fixed.
HA clustering remedies this situation by detecting hardware/software faults,
And immediately restarting the application on another system without requiring administrative
intervention, a process known as failover.
High performance cluster:
High performance clusters are designed to exploit the parallel processing power of multiple nodes.
Example of HPC is erkeley’s SETI@ho e proje t hi h is also further de eloped as a re olutio ary Grid computing project.
Load balancing cluster:
It can be operated by routing all work through one or more load balancing front-end nodes.
Then distributes the workload efficiently between the remaining active nodes.
Visualization based cluster:
It is an HPC cluster with the addition of powerful graphics cards, normally designed to work in
sync with each other to tackle high-resolution and real-time simulations.
Now it includes an ever-growing group of sub-categories.
A visualization based cluster is used for followings:
o Weather forecasting
o DNA sequence analysis
o Protein folding simulations
o WMD simulations
o Climate and environmental modeling etc.
5. What is Resource Management Scheduling (RMS) in cluster computing? Explain the services provided
by it. [Summer 14(7 marks), Winter 12(7 marks), Total: 14 marks]
A DRMS(Distributed Resource Management Scheduling) is an enterprise software application
That is in charge of unattended background executions, commonly known for historical reasons as
batch processing.
Synonyms are batch system, job scheduler, and Distributed Resource Manager (DRM).
Today’s jo s hedulers typically provide a graphical user interface and a single point of control for
definition and monitoring of background executions in a distributed network of computers.
Increasingly job schedulers are required to or chest rate the integration of real-time business
activities with traditional background IT processing.
Basic features expected of job scheduler software are:
Interface to define workflows and/or job dependencies
Automatic submission of executions
Interfaces to monitor the executions
Priorities and/or queues to control the execution order of unrelated jobs

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 5
If software from a completely different area includes all or some of those features, this software is
considered to have job scheduling capabilities.
Most operating system platforms such as Unix and Windows provide basic job scheduling
capabilities, for example Cron.
Many programs such as DBMS, backup, ERPs, and BPM also include relevant job scheduling
capabilities.
Operating system (OS) or point program supplied job scheduling will not usually provide the ability
to schedule beyond a single OS instance or outside the remit of the specific program.
Organizations needing to automate highly complex related and un-related IT workload will also be
expecting more advanced features from a job scheduler, such as:
o Real-time scheduling based on external, un-predictable events
o Automatic restart and recovery in event of failures
o Alerting and notification to operations personnel
o Generation of incident reports
o Audit trails for regulatory compliance purposes
These advance capabilities can be written by in-house developers but are more often provided by
solutions from suppliers that specialize in systems management software.
Main concepts :
There are many concept that are central to almost every job scheduler implementation and that are
widely recognized with minimal variations :
1. Jobs
2. Dependencies
3. Job Streams
4. Users
Beyond the basic, single OS instance scheduling tools there are two major architectures that exist for
job scheduling software.
Master/Agent architecture:
The historic architecture for job scheduling software.
The job scheduling software is installed on a single machine (Master) while on production machines
only a very small component (Agent) is installed.
That awaits command from the Master, executes them and returns the exit code back to the Master.
Cooperative architecture:
A decentralized model where each machine is capable of helping with scheduling and can offload
locally scheduled job to other cooperating machines.
This enables dynamic workload balancing to maximize hardware resource utilization and high
availability to ensure service delivery.
6. Explain HPVM (High Performance Virtual Machine) and CLUMPS (Clusters of SMP) with their
advantages. [Summer 14(4 marks), Winter 13(7 marks), Winter 12(7 marks), Total: 18 marks]
HPVM(High performance virtual machine):
It is tightly isolated software container that can run its own OS and applications as if it were a
physical computer.
It behaves exactly like a physical computer and contains own virtual CPU, RAM hard disk and
network interface card(NIC).
It depends on building, portable abstraction of a virtual machine with predictable, high performance
characteristics.
o Virtual machine must:
o Deliver a large fraction of underlying hardware performance

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 6
o Virtualized resource to provide portability and to reduce the efforts.
o Deliver predictable, high performance
It can increase the performance of distributed computational resources.
CLUMPS:
Clusters of symmetric shared-memory multiprocessors have become the most promising parallel
computing platforms for scientific computing.
SMP clusters consist of a set of multi-processor compute nodes connected via a high-speed
interconnection network.
While processors within a node have direct access to a shared memory, accessing data located on
other nodes has to be realized by means of message-passing.
To deal with shared memory programming issues like multithreading and synchronization can be
arises.
Distributed memory issues as data distribution and message passing can be there.
MPI program that are executed on clusters of SMPs usually do not directly utilize the shared-
memory available within nodes and thus may miss a number of optimization opportunities.
Current HPF(High performance fortran) compilers ignores the shared-memory aspect of SMP
clusters and treat such machines as distributed-memory.
7. Explain Beowulf Cluster and Berkeley NOW clusters.
[Summer 14(4 marks), Winter 11(7 marks), Total: 11 marks]
The Beowulf Project
o Investigate the potential of PC clusters for performing computational tasks
o Refer to a Pile-of-PCs (PoPC) to describe a loose ensemble or cluster of PCs
o Emphasize the use of mass-market commodity components, dedicated processors, and the
use of a private communication network
o Achieve the best overall system cost/performance ratio for the cluster
System Software
o The collection of software tools
o Resource management & support distributed applications
Communication
o Through TCP/IP over Ethernet internal to cluster
o Employ multiple Ethernet networks in parallel to satisfy the internal data transfer
bandwidth required
Achieved by hannel inding techniques
Extend the Linux kernel to allow a loose ensemble of nodes to participate in a number of
global namespaces
Two Global Process ID (GPID) schemes
o Independent of external libraries
o GPID-PVM compatible with PVM Task ID format & uses PVM as its signal transport
o The Berkeley Network of Workstations (NOW) Project
Demonstrate building of a large-scale parallel computer system using mass produced
commercial workstations & the latest commodity switch-based network components
Interprocess communication
o Active Messages (AM)
basic communication primitives in Berkeley NOW

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 7
A simplified remote procedure call that can be implemented efficiently on a
wide range of hardware
Global Layer Unix (GLUnix)
o An OS layer designed to provide transparent remote execution, support for
interactive parallel & sequential jobs, load balancing, & backward compatibility for
existing application binaries
o Aim to provide a cluster-wide namespace and uses Network PIDs (NPIDs), and
Virtual Node Numbers (VNNs)
o Network RAM
Allow to utilize free resources on idle machines as a paging device for busy machines
Serverless
any machine can be a server when it is idle, or a client when it needs more memory
than physically available
o xFS: Serverless Network File System
A serverless, distributed file system, which attempt to have low latency, high
bandwidth access to file system data by distributing the functionality of the server
among the clients
The function of locating data in xFS is distributed by having each client responsible
for servicing requests on a subset of the files
File data is striped across multiple clients to provide high bandwidth
8. What is cluster tuning? Explain the policies used for cluster tuning. OR List and explain steps for
System Tuning of cluster.
[Sum. 14(7 marks), Win. 13(7 marks), Win. 12(3 marks), Sum. 12(7 marks), Total: 24 marks ]
Cluster tuning is the process of adjusting the values of some properties of cluster to minimize the
cost function.
It is an iterative process that involves measuring, analysis, optimization and validation until the goal
is reached.
To successfully tune a cluster the goals of tuning should be known in advance.
i.e. whether you want high performance with some lapse in security allowed or secure nodes even if
it affects performance or low cost etc.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 8
System tuning includes:
Developing Custom Models for Bottleneck Detection
Identify the points in the cluster that may prove to be a bottleneck and hence adversely affecting
the performance.
Examples can include a file server or a heavily used node etc.
Once the bottlenecks have been identified, try to reduce the load on such nodes. Replica of
server can be created and other such measures can be taken.
Moreover, the measures taken in improving the performance of one node should not
deteriorate the performance of the other.
Focusing on Throughput or focusing on Latency
In conventional systems, main focus was to improve overall throughput.
Latencies were of no concern as the processes were not distributed and hence they did not
affect the performance.
However, in clusters data and processes may be widely distributed across various nodes.
In such case, latency can have huge impact on performance. Higher latency means more delay in
transfer among nodes and inter-node transfer and communication is not uncommon in cluster.
Hence, in clusters and distributed systems, focus is to reduce latency which in turn will improve
the overall throughput.
I/O Implications
The slowest part in a system is generally I/O. However, sophisticated i/o hardware is available
but generally it is used only in servers.
Nodes of a luster ge erally do ’t ha e u h i/o i te si e tasks and cheap disks perform equally
well except under heavy loads.
Servers which have to perform more i/o intensive tasks are installed with robust, faster and
expensive disk systems.
Caching Strategies
An important difference between conventional multiprocessors and cluster is the availability of
shared memory.
Traditionally, data was stored on disks. Nowadays, DSM is used and getting data from it using
low latency networks gives higher throughput than local disk.
Flow from various nodes can be aggregated to saturate the network so that network capacity is
not wasted.
Faster access is achieved by concurrent access to other nodes.
Fine tuning the OS
Virtual memory tuning: Optimization depends on the application. Large jobs benefit highly from
VM tuning. Highly tuned code will fit in the available memory and prevent the system from
paging. It also depends on the factors like read-ahead, write-back etc methods used.
Networking: For communication-intensive applications, big gains can be achieved by tuning the
network. Size of TCP, UDP window size and receive buffers can be increased for big transfers
that give a performance gain. For short range transmission, limit retransmission time-outs so
that se der does ’t ha e to ait for lo g to retra s it a fra e i ase of a loss.
Switches: switches having large buffers are beneficial but they cause delays during congestion.
So they should be tuned wisely and as per need.
Apart from these, various methods like heartbeat detection, web application settings, lazy
session validation etc. can be used for tuning purposes.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 9
9. Explain in detail the various steps involved in establishing a cluster.
[Winter 13(7 marks), Summer 12(7 marks), Total: 14 marks]
Following steps are involved in establishing a cluster:
Starting from Scratch
First of all, the purpose and nature of the cluster should be defined with as much details as
possible.
Interconnection Network: Technologies to be used to connect various nodes are decided.
o Network technology includes Fast Ethernet, Myrinet, SCI, ATM etc. topologies can be
either star or ring point to point etc depending on the need. Fast Ethernet can be used
with hubs or switches or their mixes.
o Some algorithms show very little performance degradation when changing from full port
switching to segment switching, and are cheap
o Direct point-to-point connection with crossed cabling can be used too.
o Hypercube can be used for 16 or 32 nodes because of the number of interfaces in each
node, the complexity of cabling and the routing (software side)
o Dynamic routing protocols improve efficiency and performance.
Front-end Setup: Most clusters include a Front-end where a user can login or submit a job..
however there are no single point dependencies and all the nodes are equal.
o Generally, clusters have one or more nodes which serve NFS to rest of the nodes and
hence can act as a front-end for NFS.
o NFS is not scalable or fast, but it works where user wants an easy way for their non I/O-
intensive jobs to work on the whole cluster with the same name space.
o Advantage of using Front-end:
o Keep the environment as similar to the node as possible
o Advanced IP routing capabilities: security improvements,load-balancing
o Provide ways to improve security
o Makes administration much easier: single system Management: install/remove
S/W, logs for problem, start/shutdown
o Global operations: running the same command, distributing commands on all or
selected nodes
Node Setup: This step deals with the issue of installing all of the nodes at a time.
o Various issues show up when nodes are setup.
o Network boot and automated remote installation can be done provided that all of nodes
will have same configuration
o The fastest way is usually to install a single node and then make clone and copy it to
other nodes
Directory Services inside the Cluster: A cluster is supposed to keep a consistent image across all
its nodes, such as same S/W, same configuration etc. hence, it needs a single unified way to
distribute the same configuration across the cluster.
This can be achieved by:
o NIS by Sun Microsystems: It is a client-server protocol for distributing system
configuration data such as user and host names between computers on a
network thus keeping a common user database.
o NIS+: It has substantial improvement over NIS, is not so widely available, is a
mess to administer, and still leaves much to be desired.
o LDAP: LDAP was defined by the IETF in order to encourage adoption of X.500
directories. Directory Access Protocol (DAP) was seen as too complex for simple

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 10
internet clients to use. LDAP defines a relatively simple protocol for updating
and searching directories running over TCP/IP.
o User authentication: Foolproof solution of copying the password file to each
node was used earlier. As for other configuration tables, there are different
solutions like develop dynamic routing daemons, use SNMP management etc.
DCE Integration: Distributed Computing Environment is a software application that provides
frameworks and tools for developing client-server applications.
o It provides
o A highly scalable directory service
o Security service
o A distributed file system
o Clock synchronization
o Threads
o RPCs
o DCE never became too main stream because of several issues.
o DCE threads are based on early POSIX draft and there have been significant
changes since then.
o DCE servers tend to be rather expensive and complex.
o However, DCE has several advantages too.
o DFS is better than NFS. It is easier to replicate and cache and is more secure.
o DCE RPC has some important advantages over the traditional RPC.
o It provides the option of local caching.
o DFS administrative domains and set of machines configured can be used as a
single unit.
o Integrating DCE with the cluster that is outside it is easier.
o It can be more useful large campus-wide network
Global Clock Synchronization: Homogeneous time is needed across the cluster, failure of which
can lead to difficulty in tracking errors.
o Serialization needs global time.
o Global time service can be implemented by:
o DCE DTS: (Distributed Time Service): better than NTP NTP (Network Time
Protocol)
o NTP: Widely employed on thousands of hosts across the Internet and provides
support for a variety of time resource.
o If UTC synchronization is not required then any time source can be used as a
time-server.
o A direct GPS receiver is also possible
o A couple of other nodes can also be maintained for redundancy.
Heterogeneous Clusters: These are clusters with nodes having different architecture.
o Reasons why people go for heterogeneous clusters are as follows.
o Exploiting higher floating point performance of certain architectures and the
low cost of other system, or for research purposes.
o NOWs. Making use of idle hardware.
o Automating administration work becomes more complex for heterogeneous clusters.
o File system layouts may be different.
o Software packaging is different.
o POSIX is attempting standardization but has little success.
o A per-architecture and per-OS set of wrappers with common external view can be
developed for medium to large heterogeneous clusters.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 11
10. Explain different policies used for load balancing. (In cluster computing) [Win. 12(4 marks)]
Requirements of load balancing algorithms:
o Scalability
o Location transparency
o Determinism
o Pre-emption
o Heterogeneity
Key goals:
To achieve overall improvement in system performance at a reasonable cost.
To treat all jobs in the system equally regardless of their origin.
It needs to have a degree of fault tolerance.
It has to maintain system stability.
Classification of load balancing algorithms:
1. Sender initiated: In this algorithm sender sends request message till it finds a receiver that can accept
the load.
2. Receiver initiated: Here description algorithms the receiver sends request message till it finds a
sender that can get the load.
3. Symmetric: It is combination of both Sender and Receiver initiated algorithms.
There are several algorithms for load balancing, some of the examples are as follows:
Random- weighted policy:
o It uses random selection method to map the name request to the server in the cluster.
o This policy evenly balance the load with time, but sometimes, the balance may vary due to the
random nature of the distribution algorithm used by the policy.
Round-robin policy:
o Maps the name request evenly to the servers in a cluster and uses the round-robin selection
algorithm for mapping.
o Mostly, the load of the cluster servers is evenly balance using the round-robin policy.
Weighted policy:
o Allows assigning weights to the servers in a cluster.
o A server is selected to serve the client request on the basis of weight assigned to it.
o It is used where some machines may process more client requests then the others.
Adaptive policy:
o It allows mapping the client requests to the less busy server machine
o Every server is assigned some weight, which is calculated using the sample of the existing load of
the server.
11. Explain FLS algorithm for resource sharing in detail along with its analysis. OR Explain FLS algorithm in
detail & explain resource location study.
Flexible Load Sharing Algorithm:
A flexible load-sharing algorithm is required to be general, adaptable, stable, scalable, fault
tolerant, transparent to the application and induce minimum overhead on the system.
In the flexible load sharing algorithm, the location policy is similar to the Threshold location

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 12
policy.
Like threshold location policy, in FLS algorithm limited number of nodes is probed. It terminates
probing as soon as it finds the node with a shorter queue length than the threshold value
defined. However, unlike Threshold policy, decisions are based on the local information
replicated at multiple nodes.
Various steps in this algorithm are:
o The system is divided into small subsets which may overlap. This makes the algorithm
scalable.
o These subsets form the cache held at a node. The cache of a node contains only the nodes of
mutual interest.
o Cache members are first discovered by random selection.
o Afterwards, biased random selection is done which keeps the nodes of mutual interest and
selects other nodes to replace the discarded entries.
o The cache is used by a node to seek a partner. This helps to constrain the search scope no
matter how big the system as a whole may be.
This algorithm supports mutual inclusion and exclusion and because of the cached data that is used
as hints, it is fail-safe.
It may not provide the best solution but an adequate one.
The nodes sharing mutual interest are retained in the cache so that a biased choice can be made.
Thus, premature deletion of cached data is prevented.
The information about nodes with mutual interest is maintained and updated regularly.
The policy of avoiding premature deletion and retaining the entries of nodes having mutual interest
in the cache shortens the time to find a partner having mutual interest.
This algorithm can be extended to solve other such problems in distributed systems.
12. Explain the basic requirement that resource sharing algorithm should meet in cluster. [Win. 11(7
marks)]
Resource sharing algorithm should meet the following requirements:
Adaptibility:
Algorithm should respond quickly to changes in system and adapt its operation to new evolving
conditions.
Generality :
Algorithm should be general to serve wide range of application and distributed environments. It
should not assume prior knowledge of system characteristics.
Minimum Overhead:
Algorithm should respond to request quickly,incovering minimal overhead on system.
Stability:
It is thprevente ability of algorithm to prevent poor resource allocation.
Scalability:
Algorith should e i i ally depe de t o syste ’s physi ally hara teristi s.
Transparency:
Recourse management should be transparent to application ,implying that program should not be
rewritten in order to use scheduling service.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 13
Fault Tolerance:
Failure of one or few nodes should have minimal impact on entire system.
Heterogeneity:
Complex network environment has to support Heterogeneity hardware and software environment.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 1
1. Define Grid Computing? What are components of Grid? Explain the applications of Grid Computing.
[Summer 14(7 marks), Summer 12(7 marks), Winter 11(7 marks), Total: 21 marks]
Grid computing is used for applying or combining various geographically scattered resources to form a
virtual platform for computation and data management.
Applications :
The Grid will be an enabling technology for a broad set of applications in science, business,
entertainment, health and other areas.
Life science applications
Computational biology, bioinformatics, genomics, computational neuroscience etc. are using Grid
technology as a way to access, collect and mine data.
For e.g. the Protein Data Bank, the myGrid Project, the Biomedical Information Research Network
(BIRN), accomplish large-scale simulation and analysis (e.g. MCell), and to connect to remote
instruments.
Engineering-oriented applications
One of the best approaches to deploying production Grid infrastructure and developing large-scale
engineering-oriented Grid applications is the NASA IPG in the United States.
It focuses on developing:
Pe siste t G id i f ast u tu e suppo ti g highl apa le o puti g a d data a age e t services that will locate and co-schedule the multicenter resources
Ancillary services needed to support the workflow management frameworks
Data-oriented applications
Over the next decade, data will come from everywhere - scientific instruments, experiments, and
sensors as well as thousands of new devices.
The Grid will be used to collect, store and analyze data and information, as well as to synthesize
knowledge from data.
DAME Grid to manage data from aircraft engine sensors
An example of a data-oriented application is Distributed Aircraft Maintenance Environment (DAME).
The project aims to build a Grid-based distributed diagnostics system for aircraft engines.
Physical science applications
When such Grids are used, each physics event can be processed independently, resulting in trillion-way
parallelism. Example: GriPhyN, Particle Physics Data Grid
The astronomy community has also targeted the Grid as a means of successfully collecting, sharing and
mining critical data about the universe. For example, the National Virtual Observatory Project in the
United States
Trends in research: e-Science in a collaborator
e-Science captures the new approach to science involving distributed global collaborations enabled by
the Internet
It very large data collections and terascale computing resources and high-performance visualizations.
e-Science is about global collaboration in key areas of science the Grid will enable it.
Computational science and information technology merge in e-Science.
In the last decade, focus was on simulation and its integration with science and engineering – this is
computational science.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 2
e-Science builds on this increasing data from all sources with the needed information technology to
analyze and assimilate the data into the simulations.
Commercial Applications
Here Grid are used in inventory control, enterprise computing, and games and so on. Ex: Butterfly Grid
and Everquest Grid
The success of SETI@home aims at identifying patterns of extraterrestrial intelligence from the data
received by the Arecibo radio telescope.
Enterprise computing areas where the Grid approach can be applied include are end-to-end automation,
security, virtual server hosting, disaster recovery, heterogeneous workload management, better
performance, Web-based access (portal) for control (programming) of enterprise function etc.
Grid Application Service Providers (ASPs) will also come in view which will provide services like,
Computing-on-demand,
Storage-on-demand,
Networking-on-demand,
Information-on-demand and so on.
Hence, we can view the Grid as a number of interacting components, and the information that is
conveyed in these interactions falls into a number of categories.
o The domain-specific content that is being processed.
o Information about components and their functionalities within the domain.
o Information about communication with the components.
o Information about the overall workflow and individual flows within it.
2. Discuss in detail the history of grid computing. [Summer 12(7 marks)]
First Generation of Grid:
FAFNER project:
FAFNER was set up to factor RSA130 public key encryption standard using a new numerical technique
called the NFS(Number field sieve) method using web servers.
The consortium produced a web interface to NFS.
Contributor could form one set of web pages, access a wide range of support services for factorisation.
That different services are as follows:
o NFS software distribution
o Project documentation
o Anonymous user registration
o Dissemination of sieving tasks
o Collection of relations
o Relation archival services
o Real-time sieving status reports
o The FAFNER project won an award in TeraFlop challenge at supercomputing 95(SC95) at San
Diego.
o It enhance the way of web based meta computing.
I-WAY project:
The information wide area year (I-WAY) was an experimental high-performance network linking many
high-performance computers and advanced visualization environments.
The I-WAY project was started in early 1995 with the idea to integrate existing high bandwidth networks.
The virtual environments, datasets, and computers used at 17 different US sites were connected by 10
networks of varying bandwidths and protocols, using different routing and switching technologies in this

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 3
project.
The network was based on Asynchronous Transfer Mode (ATM).
It supported both Transmission Control Protocol/Internet Protocol (TCP/IP) over ATM and direct ATM-
oriented protocols.
For standardization, key sites installed point-of-presence (I-POP) servers to act as gateways to I-WAY.
The I-POP servers were UNIX workstations configured uniformly and possessing a standard software
environment called I-Soft.
I-Soft attempted to overcome issues concerning heterogeneity, scalability, performance, and security.
Each site participating in I-WAY ran an I-POP server which provided uniform I-WAY authentication,
resource reservation, process creation, and communication functions.
Each I-POP server was accessible via the Internet.
A ATM i te fa e as the e fo o ito i g a d pote tial a age e t of the site s ATM s it h. The I-WAY project developed a resource scheduler known as the Computational Resource Broker (CRB)
with user-to-CRB and CRB-to-local-scheduler protocols.
For security, Kerberos was used and it provided authentication and encryption.
To support user-level tools, a low-level communications library, Nexus, was adapted.
The I-WAY project was application driven and defined several types of applications like supercomputing,
Access to Remote Resources, Virtual Reality etc.
I-WAY unified the resources at multiple supercomputing centres.
I-WAY was designed to cope with a range of diverse high-performance applications that typically needed
a fast interconnect and powerful resources.
Limitations of I-WAY:
I-WAY lacked scalability.
I-WAY was limited by the design of components that made up I-POP and I-Soft.
I-WAY embodied a number of features that would today seem inappropriate. The installation of an I-POP
platform made it easier to set up I-WAY services in a uniform manner, but it meant that each site needed
to be specially set up to participate in I-WAY.
In addition, the I-POP platform and server created one, of many, single points of failure in the design of
the I-WAY.
However, despite of the aforementioned features I-WAY was highly innovative and successful.
I-WAY was the forerunner of Globus and Legion.
Note: For 2nd
and 3rd
generation of Grid refer Que: 3 and 4
3. Explain second generation Meta Computing Projects in brief. [Winter 12(7 marks)]
FAFNER was forerunner at SETI@home and Distributed.NET and I-WAY was for Globus and Legion
Issues for 2nd generation of grid:
Heterogeneity
Scalability
Adaptability
2nd Generation requires large scale of data and computations, Some basic requirements to achieve it
are as follows:
Administrative hierarchy
Communication services
Information services
Naming services
Security

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 4
Resource management and scheduling
User and administrative GUIs
Some of the technologies or 2nd
generation:
Globus
Legion
Jini and RMI
SRB
Nimrod/G
Grid Architecture for Computational Economy(GRACE)
Grid portals
Integrated system
Introduction of some 2nd
generation core Grid technologies:
Globus:
• It is software architecture or layered architecture
• Global services are built upon the core-local services.
• For resource allocation and monitoring HTTP based GRAM is used.
• For high speed transfer extended FTP protocol, GridFTP is used.
• Authentication GSI(Grid security infrastructure)
• LDAP is for distributed access to state any information.
• LDAP(lightweight directory access protocol, build on TCP for querying state or remote database.)
Legion:
• Provides a software infrastructure to perform integration between different heterogeneous,
geographically distributed, and high-performance machines.
• Jini and RMI:
• Provides infrastructure for DE that offers plug and play facility.
SRB:
• Provides uniform access to the storage that is distributed over a network using an API.
• Also supports metadata of the file system.
• Nimrod/G resource broker:
• Its components:
• Task-farming engine
• Dispatcher
• Resource agents
• Scheduler
GRACE:
• It refers to a set of resource trading service that is used to manage supply and demand of resources
in the grid.
Grid portals
• Provide single point of access to compute-based resources
• Simplify access of the distributed resources across different member organizations.
• View the distributed resources as an integrated grid system or as separate machines.
4. Explain the service oriented model of 3rd
generation of grid in detail. [Winter 11(7 marks)]
Service-oriented model:
The service-oriented paradigm provides the flexibility required for the third-generation Grid.
Figure below depicts the three technologies (Grid, Agents, Web services).

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 5
Web services:
The creation of Web services standards an initiative by industry, with some of the emerging standards in
various states of progress through the World Wide Web Consortium (W3C).
The established standards include the following:
o SOAP (XML protocol): Simple object access protocol (SOAP) provides an envelope that
encapsulates XML data for transfer through the Web.
o Web services description language (WSDL): Describes a service in XML, using an XML Schema;
there is also a mapping to the RDF (Resource Description Framework).
o Universal description discovery and integration (UDDI): This is a specification for distributed
registries of Web services (like yellow and white pages services).
o UDDI suppo ts pu lish, fi d a d i d . o A service provider describes and publishes the service details to the directory, service requestors
ake e uests to the egist to fi d the p o ide s of a se i e, the se i es i d using the
technical details provided by UDDI.
The next Web service standards attracting interest are at the process level.
For example, Web Services Flow Language (WSFL) defines workflows as combinations of Web services
and enables workflows to appear as services.
Web services are closely aligned to the third-generation Grid requirements:
o They support a service-oriented approach
o They adopt standards to facilitate the information aspects such as service description
The Open Grid Services Architecture (OGSA) framework:
The OGSA Framework supports the creation, maintenance, and application of ensembles of services
maintained by Virtual Organizations (VOs).
Here a service is defined as a network-enabled entity that provides some capability, such as
computational resources, storage resources, networks, programs and databases.
Followings are the standard interfaces defined in OGSA:
o Discovery:
o Dynamic service creation:
o Notification:
o Manageability:
o Simple hosting environment:
o The Grid resource allocation and management (GRAM) protocol.
o The information infrastructure, metadirectory service (MDS-2)
o The Grid security infrastructure (GSI)
The future implementation of Globus Toolkit may be based on the OGSA architecture.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 6
Agents
Web services provide a means of interoperability, However, Web services do not provide a new solution
to many of the challenges of large-scale distributed systems, or provide new techniques for the
engineering of these systems.
Hence, it is important to look at other service-oriented models that are agent-based computing.
The agent-based computing paradigm provides a perspective/view on software systems in which entities
typically have the following properties, also known as weak agency.
o Autonomy: Agents operate without intervention and have some control over their actions and
internal state
o Social ability: Agents interact with other agents using an agent communication language
o Reactivity: Agents perceive and respond to their environment
o Pro-activeness: Agents exhibit goal-directed behavior
For interoperability between components, agreed common vocabularies are required which are
provided by Agent Communication Languages (ACLs).
For e.g. The Foundation for Intelligent Physical Agents (FIPA) activity provides approaches to establishing
semantics for this information in an interoperable manner.
5. Explain important role of grid middleware. OR Define Grid Computing, Explain Condor middleware in
detail. [Winter 13(7 marks), Winter 12(7 marks), Total: 14 marks]
Middle ware introduction:
"Middleware" is the software that organizes and integrates the resources in a grid.
Middleware is made up of many software programs, containing hundreds of thousands of lines of
computer code.
Together, this code automates all the "machine to machine" (M2M) interactions that create a single,
seamless computational grid.
Middleware automatically negotiate deals in which resources are exchanged, passing from a grid
resource provider to a grid user.
Middlewares as Agents and Brokers:
In these deals, some middleware programs act as "agents" and others as "brokers".
Agent programs present "metadata" (data about data) that describes users, data and resources.
Broker programs undertake the M2M negotiations required for user authentication and authorization,
and then strike the "deals" for access to, and payment for, specific data and resources.
Once a deal is set, the broker schedules the necessary computational activities and oversees the data
transfers.
At the same time, special "housekeeping" agents optimize network routings and monitor quality of
service.
And all this occurs automatically, in a fraction of the time that it would take humans at their
computers to do manually.
Driving inside middleware:
There are many other layers within the middleware layer.
For example, middleware includes a layer of "resource and connectivity protocols", and a higher layer of
"collective services".
Resource and connectivity protocols handle all grid-specific network transactions between different
computers and grid resources.
For example, computers contributing to a particular grid must recognize grid-relevant messages and
ignore the rest.
This is done with communication protocols, which allow the resources to communicate with each other,

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 7
enabling exchange of data, and authentication protocols, which provide secure mechanisms for verifying
the identity of both users and resources.
The collective services are also based on protocols: information protocols, which obtain information
about the structure and state of the resources on a grid, and management protocols, which negotiate
uniform access to the resources.
Collective services includes:
o Updating directories of available resources
o Brokering resources
o Monitoring and diagnosing problems
o Replicating data for generating multiple copies
o Providing membership/policy services for tracking who is allowed to do what and when
Example: Condor middleware:
Two common types of such jobs are data analysis:
1. In which a large dataset is divided into units that can be analyzed independently, and
2. Parameter studies, where a design space of many parameters is explored across many different
parameter values.
In the data analysis case, the output data must be collected and integrated into a single analysis, and this
is sometimes done as part of the analysis job and sometimes by collecting the data at the submitting site
where the integration is dealt with.
In both cases, in addition to the basic Grid services, a job manager is required to track these (typically
numerous) related jobs in order to ensure either that they have all run exactly once or a record is
provided of those that ran and those that failed.
The Condor-G job manager is a Grid task broker that provides this sort of service.
Condor-G is a client-side service and must be installed on the submitting systems.
A Condor manager server is started by the user and then jobs are submitted to this user job manager.
This a age deals ith ef eshi g the p o that the G id esou e ust ha e i o de to u the use s jobs
The user must supply new proxies to theCondor manager (typically once every 12 h).
The manager must stay alive while the jobs are running on the remote Grid resource in order to keep
track of the jobs as they complete.
There is also a Globus GASS server on the client side that manages the default data movement (binaries,
stdin/out/err, etc.) for the job.
Condor-G can recover from both server-side and client-side crashes.
This jo odel is also alled pee -to-pee s ste s. PVM is another distributed memory programming system that can be used in conjunction with Condor
and Globus to provide Grid functionality for running tightly coupled processes.
6. Define Production Grid. Explain OGSA (Open Grid Service Architecture) in detail. Give some example of
production grid. OR Discuss in detail implementing production grids.
[Summer 12(7 marks), Winter 11(7 marks), Total: 14 marks]
A production Gris is an infrastructure comprising a collection of multiple administrative domains.
It provides a network that enables large-scale resource and human interactions in a virtual manner.
The OGSA Framework supports the creation, maintenance, and application of ensembles of services
maintained by Virtual Organizations (VOs).
Here a service is defined as a network-enabled entity that provides some capability, such as
computational resources, storage resources, networks, programs and databases.
It tailors/modifies the Web services approach to meet some Grid specific requirements.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 8
OGSA Architecture
Followings are the standard interfaces defined in OGSA:
Discovery: Clients require mechanisms for discovering available services and for determining the
Characteristics of those services.
Dynamic service creation: A standard interface (Factory) and semantics that any service creation service
must provide.
Lifetime management: In a system that incorporates transient and stateful service instances,
mechanisms must be provided for reclaiming services and state associated with failed operations.
Notification: A collection of dynamic, distributed services must be able to notify each other
asynchronously of interesting changes to their state.
Manageability: The operations relevant to the management and monitoring of large numbers of Grid
service instances are provided.
Simple hosting environment: A simple execution environment is a set of resources located within a
single administrative domain and supporting native facilities for service management: for example, a
J2EE application server, Microsoft. NET system etc.
The parts of Globus that are impacted most by the OGSA are
o The Grid resource allocation and management (GRAM) protocol.
o The information infrastructure, metadirectory service (MDS-2)
o The Grid security infrastructure (GSI)
o The future implementation of Globus Toolkit may be based on the OGSA architecture.
E a ples of P odu tio g id a e: s ie e p og a , asia pa ifi , NASA s IPG et .
7. What is Virtual organization? Explain different protocol, services, and tools to build scalable Virtual
organization? OR Define Virtual Organization. Describe the nature of Grid Architecture in detail.
In grid computing, a virtual organization (VO) refers to a dynamic set of individuals or institutions
defined around a set of resource-sharing rules and conditions.
All these virtual organizations share some commonality among them, including common concerns and
requirements, but may vary in size, scope, duration, sociology, and structure.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 9
Virtual organizations comprises of a group of individuals and associated resources and services but not
located within a single administrative domain for security reasons.
Nature of Grid Architecture:
New technology is required for the establishment, management, and exploitation of dynamic, cross-
organizational VO sharing relationships.
The Grid architecture identifies fundamental system components, specifies the purpose and function of
these components, and indicates how these components interact with one another.
An effective VO operation requires sharing relationships among any potential participants.
Interoperability is thus the central issue to be addressed. In a networked environment, interoperability
means common protocols.
Hence, our Grid architecture is first and foremost protocol architecture, with protocols defining the basic
mechanisms by which VO users and resources negotiate, establish, manage, and exploit sharing
relationships.
A standards-based open architecture facilitates extensibility, interoperability, portability, and code
sharing; standard protocols make it easy to define standard services that provide enhanced capabilities.
We can also construct application programming interfaces and software development kits to provide the
programming abstractions required to create a usable Grid.
Together, this technology and architecture constitute middleware.
There are basically four areas of concern
o Interoperability
o Protocols
o Services
o APIs and SDKs
Interoperability
We need to ensure that sharing relationships can be initiated among arbitrary parties, accommodating
new participants dynamically, across different platforms, languages, and programming environments.
Thus mechanisms serve little purpose if they are not defined and implemented so as to be interoperable
across organizational boundaries, operational policies, and resource types.
Without interoperability, VO applications and participants are forced to enter into bilateral sharing
arrangements.
Without such assurance, dynamic VO formation is impossible, and the types of VOs that can be formed
are severely limited.
Just as the Web revolutionized information sharing by providing a universal protocol and syntax (HTTP
and HTML) for information exchange, so we require standard protocols and syntaxes for general
resource sharing.
Protocols
A protocol definition specifies how distributed system elements interact with one another in order to
achieve a specified behavior. It also specifies the structure of the information exchanged during this
interaction.
Focus is on externals (interactions) rather than internals (software, resource characteristics) and it has
important pragmatic benefits.
VOs tend to be fluid(changes dynamically and frequently); hence, the mechanisms used to discover
resources, establish identity, determine authorization, and initiate sharing must be flexible and
lightweight, so that resource-sharing arrangements can be established and changed quickly.
Since protocols govern the interaction between components, and not the implementation of the
components, local control is preserved.
Services

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 10
A service is defined solely by the protocol that it speaks and the behaviors that it implements.
The definition of standard services allows us to enhance the services offered to VO participants and also
to abstract away resource-specific details.
Such services include access to computation, access to data, resource discovery, coscheduling, data
replication, and so forth.
APIs and SDKs
Developers must be able to develop sophisticated applications in complex and dynamic execution
environments.
Users must be able to operate these applications.
Application robustness, correctness, development costs, and maintenance costs are all important
concerns.
Standard abstractions, APIs, and SDKs can accelerate code development, enable code sharing, and
enhance application portability.
APIs and SDKs are an addition and not an alternative to, protocols.
Without standard protocols, interoperability can be achieved at the API level only by using a single
implementation everywhere or by having every implementation know the details of every other
implementation.
Hence, Grid architecture emphasizes the identification and definition of protocols and services, first, and
APIs and SDKs, second.
8. Explain Grid architecture in detail.
[Summer 13(7 marks), Winter 13(7 marks), Winter 12(7 marks), Total: 21 marks]
Grid Computing an approach for building dynamically constructed problem-solving environments using
geographically and organizationally dispersed, high-performance computing and data handling
resources.
Grids also provide important infrastructure supporting multi-institutional collaboration.
The overall motivation for most current Grid projects is to enable the resource and human interactions
that facilitate large-scale science and engineering such as aerospace systems design, high-energy physics
data analysis, climate research, large-scale remote instrument operation, collaborative astrophysics etc.
Functionally, Grids are tools, middleware, and services for,
o Building the application frameworks that allow disciplined scientists to express and manage the
simulation, analysis, and data management aspects of overall problem solving
o Providing a uniform and secure access to a wide variety of distributed computing and data
resources
o Supporting construction, management, and use of widely distributed application systems
o Facilitating human collaboration through common security services, and resource and data
sharing
o Providing support for remote access to, and operation of, scientific and engineering
instrumentation systems
o Managing and operating this computing and data infrastructure as a persistent service
Two aspects of Grid:
o A set of uniform software services that manage and provide access to heterogeneous,
distributed resources
o A widely deployed infrastructure
The software architecture of a Grid is depicted in the figure below.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 11
Grid Architecture
Grid software is not a single, monolithic package, but rather a collection of interoperating software
packages.
The reason is that the Globus software is modularized and distributed as a collection of independent
packages, and as other systems are integrated with basic Grid services.
There is a set of basic functions that all Grids must have in order to be called a Grid: The Grid Common
Services.
These common services include:
o T he G id I fo atio Se i e ( GIS – the basic resource discovery mechanism)
o The G id Se u it I f ast u tu e ( GSI – the tools and libraries that provide Grid security)
o The Grid job initiator mechanism (e.g. Globus GRAM)
o A Grid scheduling function
o A basic data management mechanism such as GridFTP.
9. Discuss about inter grid protocols. [Winter 13(7 marks), Summer 12(7 marks), Total: 14 marks]
The Grid architecture establishes requirements for the protocols and APIs that enable sharing of
resources, services, and code.
It does not otherwise constrain the technologies that might be used to implement these protocols and
APIs.
It is quite feasible to define multiple instantiations of key Grid architecture elements.
For example, we can construct both Kerberos-and PKI-based protocols at the Connectivity layer – and
access these security mechanisms via the same API.
However, Grids constructed with these different protocols are not interoperable and cannot share
essential services – at least not without gateways.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 12
For this reason, the long-term success of Grid computing requires that we select and achieve widespread
deployment of one set of protocols at the Connectivity and Resource layers – and, to a lesser extent, at
the Collective layer.
Just like the core Internet protocols enable different computer networks to interoperate and exchange
information, these Intergrid protocols enable different organizations to interoperate and exchange or
share resources.
‘esou es that speak/i ple e t these p oto ols a e said to e o the G id.
Standard APIs are also highly useful if Grid code is to be shared.
The Globus toolkit has represented a somewhat successful approach for the identification of these
Intergrid protocols and APIs.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 1
1. Explain Infrastructure as a Service(IaaS), Platform as a Service(PaaS) and in Cloud Computing. Also explain
role of Virtualization. [Summer 14(7 marks), Winter 13(14 marks), Winter 12(7 marks), Winter 11(4
marks), Total: 32 marks]
Infrastructure as a service(IaaS):
Infrastructure as a Service (IaaS) is the delivery of computer hardware (servers, networking technology,
storage, and data center space) as a service.
It may also include the delivery of operating systems and virtualization technology to manage the
resources.
Characteristics of IaaS:
The IaaS customer rents computing resources instead of buying and installing them in their own data
center.
The service is typically paid for on a usage basis.
The service may include dynamic scaling so that if the customer winds up needing more resources than
expected, he can get them immediately (probably up to a given limit).
Dynamic scaling as applied to infrastructure means that the infrastructure can be automatically scaled
up or down, based on the requirements of the application.
Additionally, the arrangement involves an agreed-upon service level.
The service level states what the provider has agreed to deliver in terms of availability and response to
demand.
It might, for example, specify that the resources will be available 99.999 percent of the time and that
more resources will be provided dynamically if greater than 80 percent of any given resource is being
used.
Example: Amazon EC2
Currently, the most high-p ofile Iaa“ ope atio is A azo s Elasti Co pute Cloud A azo EC2 . It provides a Web interface that allows customers to access virtual machines.
EC2 offe s s ala ility u de the use s o t ol ith the user paying for resources by the hour.
The use of the term elastic i the a i g of A azo s EC2 is sig ifi a t. The elasticity refers to the ability that EC2 users have to easily increase or decrease the infrastructure
resources assigned to meet their needs.
The use eeds to i itiate a e uest, so this se i e p o ided is t dy a i ally s ala le. Users of EC2 can request the use of any operating system as long as the developer does all the work.
Amazon itself supports a more limited number of operating systems (Linux, Solaris, and Windows).
For an up-to-the-minute description of this service, go to http://aws.amazon.com/ec2.
Other applications of Iaas:
Companies with research-intensive projects are a natural fit for IaaS.
Cloud based computing services allow scientific and medical researchers to perform testing and analysis
at le els that a e t possi le ithout additio al access to computing infrastructure.
Other organizations with similar needs for additional computing resources may boost their own data
centres by renting the computer hardware appropriate allocations of servers, networking technology,
storage, and data centre space — as a service.
Instead of laying out the capital expenditure for the maximum amount of resources to cover their
highest level of demand, they purchase computing power when they need it.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 2
Platform as a service(PaaS):
With Platform as a Service (PaaS), the provider delivers more than infrastructure.
It delivers what you might call a solution stack — an integrated set of software that provides everything
a developer needs to build an application — for both software development and runtime.
PaaS can be viewed as an evolution of Web hosting.
In recent years, Webhosting companies have provided fairly complete software stacks for developing
Web sites.
PaaS takes this idea a step farther by providing lifecycle management — capabilities to manage all
software development stages from planning and design, to building and deployment, to testing and
maintenance.
Benefits of Paas:
The primary benefit of PaaS is having software development and deployment capability based entirely
in the cloud — hence, no management or maintenance efforts are required for the infrastructure.
Every aspect of software development, from the design stage onward (including source-code
management, testing, and deployment) lives in the cloud.
PaaS is inherently multi-tenant and naturally supports the whole set of Web services standards and is
usually delivered with dynamic scaling.
In reference to Platform as a Service, dynamic scaling means that the software can be automatically
scaled up or down.
Platform as a Service typically addresses the need to scale as well as the need to separate concerns of
access and data security for its customers.
Disadvantage of Paas:
The major drawback of Platform as a Service is that it may lock you in to the use of a particular
development environment and stack of software components.
2. Define Cloud Computing? Explain the features of Cloud Computing.
Service over a network (typically the internet). The name comes from the use of a cloud -shaped symbol
as an abstraction for the complex infrastructure it contains in system diagrams.
Cloud computing entrusts remote services with a user's data, software and computation.
Features Of Cloud Computing:
1. Resource Pooling and Elasticity
In cloud computing, resources are pooled to serve a large number of customers.
Cloud computing uses multi-tenancy where different resources are dynamically allocated and de-
allocated according to demand.
From the use s e d, it is ot possi le to k o he e the esou e a tually esides. The resource allocation should be elastic, in the sense that it should change appropriately and quickly
with the demand.
If on a particular day the demand increases several times, then the system should be elastic enough to
meet that additional need, and should return to the normal level when the demand decreases.
2. Self-Service and On-demand Services
Cloud computing is based on self-service and on-demand service model.
It should allow the user to interact with the cloud to perform tasks like building, deploying, managing,
and scheduling.
The user should be able to access computing capabilities as and when they are needed and without any

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 3
interaction from the cloud-service provider.
This would help users to be in control, bringing agility in their work, and to make better decisions on the
current and future needs.
3. Pricing
Cloud computing does not have any upfront cost. It is completely based on usage.
The user is billed based on the amount of resources they use. This helps the user to track their usage
and ultimately help to reduce cost.
Cloud computing must provide means to capture, monitor, and control usage information for accurate
billing.
The information gathered should be transparent and readily available to the customer.
This is necessary to make the customer realize the cost benefits that cloud computing brings.
4. Quality of Service
Cloud computing must assure the best service level for users.
Services outlined in the service-level agreements must include guarantees on round-the-clock
availability, adequate resources, performance, and bandwidth.
Any compromise on these guarantees could prove fatal for customers.
The decision to switch to cloud computing should not be based on the hype in the industry.
Knowing all the features will empower the business users to understand and negotiate with the service
providers in a proactive manner.
5. Small and medium scale industries
Small and medium scale industries can also be accommodated but only large companies can take
advantage of the availability, versatility, and power of cloud computing.
Huge businesses which transfer their applications which use up too much resources to the cloud in
order to free up their old dedicated servers to decrease cost of operation.
6. Agility
Agility improves with users' ability to rapidly and inexpensively re-provision technological infrastructure
resources.
7. Cost
Cost is claimed to be greatly reduced and capital expenditure is converted to operational expenditure.
This ostensibly lowers barriers to entry, as infrastructure is typically provided by a third-party and does
not need to be purchased for one-time or infrequent intensive computing tasks.
8. Device and location
Device and location independence enable users to access systems using a web browser regardless of
their location or what device they are using.
As infrastructure is off-site and accessed via the Internet, users can connect from anywhere.
9. Multi-tenancy
Multi-tenancy enables sharing of resources and costs across a large pool of users thus allowing for:
o Centralization of infrastructure in locations with lower costs
o Peak-load capacity increases
o Utilization and efficiency improvements for systems that are often only 10–20% utilized.
10. Reliability
Reliability is improved if multiple redundant sites are used, which makes well designed cloud computing
suitable for business continuity and disaster recovery.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 4
Nonetheless, many major cloud computing services have suffered outages, and IT and business
managers can at times do little when they are affected.
11. Scalability
Via dynamic ("on-demand") provisioning of resources on a fine-grained, self-service basis near real-
time, without users having to engineer for peak loads.
Performance is monitored and consistent and loosely coupled architectures are constructed using web
services as the system interface.
One of the most important new methods for overcoming performance bottlenecks for a large class of
applications is data parallel programming on a distributed data grid.
12. Security
Security is often as good as or better than under traditional systems, in part because providers are able
to devote resources to solving security issues that many customers cannot afford.
Providers typically log accesses, but accessing the audit logs themselves can be difficult or impossible.
Furthermore, the complexity of security is greatly increased when data is distributed over a wider area
and number of devices.
13. Maintenance
Cloud computing applications are easier to maintain, since they don't have to be installed on each
user's computer.
They are easier to support and to improve since the changes reach the clients instantly.
14.Metering
Cloud computing resources usage should be measurable and should be metered per client and
application on daily, weekly, monthly, and annual basis.
This will enable clients on choosing the vendor cloud on cost and reliability (QoS).
3. Explain benefit and limitations of Cloud Computing.
[Summer 14(7 marks), Winter 11(4 marks), Total: 11 marks]
Benefits:
Cost reduction - Cloud computing reduces paperwork, lowers transaction costs, and minimizes the
i est e t i ha d a e a d the esou es to a age it . Mo i g you usi ess to the loud also reduces the need for an IT staff.
Scalability - Like electricity and water, some cloud computing services allow businesses to only pay for
what they use. And as your business grows, you can accommodate by adding more server space.
Levels the playing field - Cloud computing providers offers small and mid-size businesses access to
more sophisticated technology at lower prices. Sharing IT resources with other companies reduces the
cost of licensing software and buying servers.
Easier collaboration - “i e se i es i the loud a e a essed a yti e f o a y o pute , it s easy to collaborate with employees in distant locations.
The ability to scale up IT capacity on-demand.
The ability to align use of IT resources directly with cost.
The ability to provide more IT agility to adapt to new business opportunities.
The ability to mix and match the right solutions for the business without having to purchase hardware &
software.
The ability to place business volatility into a single domain...the cloud.
The ability to reduce operational costs, while increasing IT effectiveness.
The ability to manage huge data sets.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 5
The ability to create customer-facing systems quickly.
The ability to shift capital dollars to other places needed by the business.
The ability balance processing between on-premise and cloud systems.
Limitations:
Availability - Will your cloud service go down unexpectedly, leaving you without important information
for hours or more?
Data mobility and ownership - Once you decide to stop the cloud service, can you get all your data
a k? Ho a you e e tai that the se i e p o ide ill dest oy you data o e you e a eled the service?
Privacy - How much data are cloud companies collecting and how might that information be used?
Security is largely immature, and currently requires specialized expertise.
Your dependent on the cloud computing provider for your IT resources, thus you could be exposed
around outages and other service interruptions.
Using the Internet can cause network latency with some cloud applications.
In some cases cloud providers are more expensive than on-premise systems.
Integration between on-premise and cloud-based systems can be problematic.
Data privacy issues could arise, if your cloud provider seeks to monetize the data in their system.
4. Explain the situation when we can use Cloud Computing and when we cannot use Cloud Computing.
Ought to move to cloud:
The ability to scale up IT capacity on-demand.
The ability to align use of IT resources directly with cost.
The ability to provide more IT agility to adapt to new business opportunities.
The ability to mix and match the right solutions for the business without having to purchase
hardware and software.
The ability to place business volatility into a single domain...the cloud.
The ability to reduce operational costs, while increasing IT effectiveness.
The ability to manage huge data sets.
The ability to create customer-facing systems quickly.
The ability to shift capital dollars to other places needed by the business.
The ability balance processing between on-premise and cloud systems.
Critical conditions for use of cloud:
Security is largely immature, and currently requires specialized expertise.
Much of the technology is proprietary, and thus can cause lock-in.
Your dependent on the cloud computing provider for your IT resources, thus you could be exposed
around outages and other service interruptions.
Using the Internet can cause network latency with some cloud applications.
In some cases cloud providers are more expensive than on-premise systems.
Not in control of costs if subscription prices go up in the future.
Integration between on-premise and cloud-based systems can be problematic.
Compliance issues could raise the risks of using cloud computing.
9. Data privacy issues could arise, if your cloud provider seeks to monetize the data in their system.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 6
10. M&A activity around cloud providers, could mean constantly adjusting and readjusting your
cloud computing solutions.
5. Mention the characteristics of Workload and Explain the different types of Workload. (Cloud Computing)
Discuss about workload in cloud.
A workload is an independent service or collection of code that can be executed. Therefore, a
o kload does t depe d o outside ele e ts. A workload can be a small or complete application.
Organizations have to actively manage workloads so they know
o How their applications are running
o What they e doi g
o How much an individual department should be charged for its use of services
A usi ess eeds to pla fo thei o kloads, e e he they e usi g a external cloud provider.
Management needs to understand the types of workloads they e putti g i to a loud. Workloads can be everything from a data-intensive workload to a storage or a transaction
processing workload.
Different workload types
Two types of workloads exist:
o Workloads that can be executed at any time in batch mode. Example: an insurance
company having a workload that calculates i te est ate. This does t ha e to happe immediately.
o Workloads that need to be executed in real time. Example: an online retail system that
calculates taxes on a purchase needs to be executed in real time.
You might have a single workload that s a e ti e appli atio used y a group of customers.
In other situations, a smaller service may be used in many different contexts.
The e ight e a o kload that s a pay e t se i e platfo . This pay e t se i e ight e li e i a cloud and may be used by many different software developers who all need a payment engine (so
they can collect payments from their customers without building their own engine).
Characteristics of Workloads
A workload has no dependencies. It s a dis ete set of application logic that can be executed
independently of a specific application.
The workload interface must be consistent. Currently, the most pragmatic, well-accepted
interfaces are based on XML(eXtensible Markup Language). XML-based interfaces can keep the data
independent of each implementation; the process understands how a service is used. For example,
the bill payment service with an XML interface knows that it calculates a bill based on usage.
A workload may have rules or policies that apply in specific situations. There may be authorization
and security policies associated with using a service for a particular function. There may be a rule
about when to use a specific workload.
Workloads can be dynamic.
These o kloads do t se e a si gle aste . They e used y a y diffe e t usto e s i a y different situations.
Workloads can be combined. This has the impact of creating dependencies between these
workloads, but in a controlled manner. Two workloads might be linked together to fulfill a task. As
long as this link is documented, it can be done safely.
A workload also needs to have well-defi ed i te fa es if they e to e used in many combinations.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 7
6. Explain Private Cloud, Public Cloud and Hybrid Cloud in detail. OR Explain important characteristics of
hybrid cloud.
Types of Clouds:
Cloud Computing can broadly be classified into 4 types. They are
Public Cloud
Private Cloud
Hybrid Cloud
Community Cloud
The types of cloud mentioned above are based on the type of application and environment being
considered before developing the application and on the basis of the location he e it s ee hosted.
Public Cloud – The a e pu li i the pu li loud o es f o the fa t that appli atio is hosted o the Hosting Providers location (Vendors). Though it is hosted in shared system, each resource operates in silo
and encrypted securely. With Public Cloud all the resources and the services are dynamically added and
removed (Scalable) based on the usage. Public cloud is more advantages for Small and Medium scale
industries since we are going to pay for the resources which we are going to use and specifically the
hardware and the bandwidth are going to be maintained by the hosting provider. Some of the examples of
Public Cloud in market are Amazon Web Services, Microsoft Azure and Google Apps.
Private Cloud – In this form, the cloud is deployed with in a corporate firewall and runs on premise IT
infrastructure. Private cloud is more expensive compared to the public cloud since the operating and
bandwidth costs are to be maintained by the organization, but this cloud is more secure than the public
cloud. Private Cloud provides more benefits to the corporate by capitalizing on the Data Security and
Corporate Governance and provides administrators more control over the operating environment.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 8
Hybrid Cloud – Hybrid Cloud are increasingly being used by corporations where there is a need to maintain
some of their applications on their internal infrastructure (because of regulatory compliance or sensitivity
of data), but also need the scalability and cost benefits of the public cloud.
Cloud bursting is the term normally used for this type of environment where internal applications are
deployed on private cloud for normal usage while internet applications are deployed on the public cloud to
handle variable loads.
Community Cloud – This type of cloud is specifically used for organizations that are shared such as different
government organizations. In this case, non-government organizations will not have access to this cloud.
The cloud could be located in-house, or on public cloud based on the needs of the organization.
7. Compare traditional and cloud data centre on cost factor. OR Compare traditional and cloud data centre
based on technology aspects.
Before making any decisions about moving your data center to a cloud, you need to take the time to
consider how cloud data centers compare to traditional data centers. Because of the high costs of
infrastructure and administration, data centers are often one of the first business areas that companies
consider switching to a cloud service.
When planning the cloud strategy, the first step is to simply find a cloud services provider, analyze how
much it charges for the services you need, and compare it to the costs of your own data center. However, it
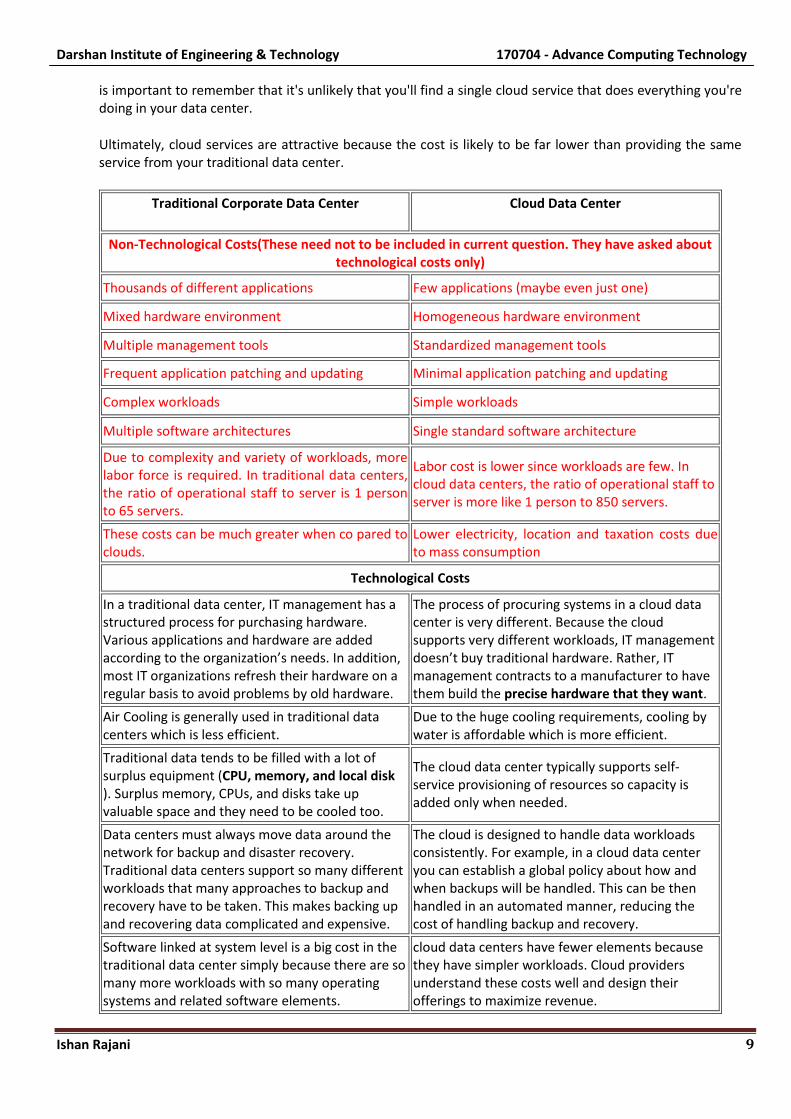
Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 9
is important to remember that it's unlikely that you'll find a single cloud service that does everything you're
doing in your data center.
Ultimately, cloud services are attractive because the cost is likely to be far lower than providing the same
service from your traditional data center.
Traditional Corporate Data Center
Cloud Data Center
Non-Technological Costs(These need not to be included in current question. They have asked about
technological costs only)
Thousands of different applications Few applications (maybe even just one)
Mixed hardware environment Homogeneous hardware environment
Multiple management tools Standardized management tools
Frequent application patching and updating Minimal application patching and updating
Complex workloads Simple workloads
Multiple software architectures Single standard software architecture
Due to complexity and variety of workloads, more
labor force is required. In traditional data centers,
the ratio of operational staff to server is 1 person
to 65 servers.
Labor cost is lower since workloads are few. In
cloud data centers, the ratio of operational staff to
server is more like 1 person to 850 servers.
These costs can be much greater when co pared to
clouds.
Lower electricity, location and taxation costs due
to mass consumption
Technological Costs
In a traditional data center, IT management has a
structured process for purchasing hardware.
Various applications and hardware are added
a o di g to the o ga izatio s eeds. In addition,
most IT organizations refresh their hardware on a
regular basis to avoid problems by old hardware.
The process of procuring systems in a cloud data
center is very different. Because the cloud
supports very different workloads, IT management
does t uy t aditio al ha d a e. ‘athe , IT
management contracts to a manufacturer to have
them build the precise hardware that they want.
Air Cooling is generally used in traditional data
centers which is less efficient.
Due to the huge cooling requirements, cooling by
water is affordable which is more efficient.
Traditional data tends to be filled with a lot of
surplus equipment (CPU, memory, and local disk
). Surplus memory, CPUs, and disks take up
valuable space and they need to be cooled too.
The cloud data center typically supports self-
service provisioning of resources so capacity is
added only when needed.
Data centers must always move data around the
network for backup and disaster recovery.
Traditional data centers support so many different
workloads that many approaches to backup and
recovery have to be taken. This makes backing up
and recovering data complicated and expensive.
The cloud is designed to handle data workloads
consistently. For example, in a cloud data center
you can establish a global policy about how and
when backups will be handled. This can be then
handled in an automated manner, reducing the
cost of handling backup and recovery.
Software linked at system level is a big cost in the
traditional data center simply because there are so
many more workloads with so many operating
systems and related software elements.
cloud data centers have fewer elements because
they have simpler workloads. Cloud providers
understand these costs well and design their
offerings to maximize revenue.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 10
Looking at the table, it becomes clear that the cloud data center is much simpler to organize and operate
and, because it is simple, it scales well. In other words, the larger you make it, the lower the costs per user
are.
8. List different types of data stored in Cloud. Compare traditional IT Service Provider and Cloud Service
Provider.
The amount and type of data available for company use is exploding. In fact, the very nature of data is
changing:
Data diversity is increasing. Data in the cloud is becoming more diverse. In addition to traditional
structured data (revenue, name, and so on), it includes emails, contracts, images, blogs, and more.
The amount of data is increasing. Just think of how many videos YouTube manages or all the
images Facebook handles. Even in the traditional data realm, organizations are starting to
aggregate huge amounts of data
Latency requirements are becoming more demanding. Companies are increasingly demanding
lower latency (for instance, the time for data to get from one point to another) for many
applications. This requires a powerful management environment.
The security parameters to be considered for the protection of data are listed below:
What are my security and privacy concerns
we talk a lot about security. We note that in most circumstances, cloud security needs to be approached
from a risk-management perspective. If your organization has risk-management specialists, involve them in
cloud security planning.
How available and reliable will my resources be?
When you ran the data center, availability and reliability were under your own company control. Your IT
organization probably has negotiated certain service level agreements with the departments in your
company based on the criticality of your applications. With a move to the cloud, you need to ask yourself
what levels of availability you need and what isk you e illi g to take if you se i e p o ide does t eet agreed-upo le els. The e ay e so e appli atio s he e you e illi g to take the isk
and some where you are not. But you need to assess the risk. Remember too that you may not be
compe sated the ay you thi k you should e if you p o ide s se i e goes do .
What about my data?
If you e thi ki g a out o i g appli atio s a d data to the loud, you eed to add ess a u e of uestio s. These i lude, ut a e t li ited to, the following:
• Ca y data e sto ed a y he e o does y o pa y ot allo
data to cross country boundaries?
• What happe s if the data is lost?
• Ca I e o e ?
• Who o s y data?
In other words, you need to weigh the risks associated with putting certain applications that rely on certain
types of data i to the loud. It ay ell e that you e o fo ta le ith the isk, ut you still eed to look at it. Look back at Chapter 8 for more information about managing data in the cloud.

Darshan Institute of Engineering & Technology 170704 - Advance Computing Technology
Ishan Rajani 11
✓ Is my vendor viable?
What happens if your service provider goes out of business? Will you be able to recover your assets? Who
owns the intellectual property?
✓ Will I be locked into one vendor?
Although there are some movements afoot to move to an open cloud model (see Chapter 14), the cloud
is t the e yet. This ea s the e a e p op ieta y data fo ats a d APIs out the e. Assess hat they a e a d whether it will be easy to move your assets from one provider to another.
✓ Are there other compliance or regulatory issues I need to be aware of?
Make sure that your provider can adhere to any regulatory or compliance issues your company has in place.
You also eed to ake su e that they e illi g to ha ge if so ethi g ha ges i you o i dust y. Assess the risk and the cost that might be associated with this. Much of this boils down to trust and doing your
homework. Do you trust your vendor and have you put the right contracts in place to protect yourself?
Ha e you do e you ho e o k? If you ha e t, you eed to do it. If you do t t ust the e do , you should t e o ki g ith the .


















