
Customer Applications Of Hadoop On Red Hat Storage Server
43
CUSTOMER APPLICATIONS OF HADOOP ON RED HAT STORAGE Jacob Shucart Sr. Solution Architect, Red Hat Erin Boyd Principle Software Engineer, Red Hat Diane Feddema Principle Software Engineer, Red Hat
-
Upload
redhatstorage -
Category
Technology
-
view
147 -
download
2
description
"If analyzing data were easy, wouldn’t everybody do it? The fact is, several steps are necessary to effectively use Hadoop out of the box to process data for the information you need. From preprocessing relevant data to preparing it for consumption to copying large data sets to another location for analysis—the time it takes to get value from your data might be so long that the data is no longer relevant. So why bring your data to the analytics engine when you can bring the analytics engine to your data? In this session, you’ll learn how Red Hat customers use Red Hat Storage Server to more quickly start mining their data by allowing the application that generates the data they need to write directly to where the analytics will run. And in the process of doing so, they can skip making an extra copy of the data."
Transcript of Customer Applications Of Hadoop On Red Hat Storage Server

CUSTOMER APPLICATIONS OF HADOOP ON RED HAT STORAGEJacob ShucartSr. Solution Architect, Red HatErin BoydPrinciple Software Engineer, Red HatDiane FeddemaPrinciple Software Engineer, Red Hat

CUSTOMER APPLICATIONS OF HADOOP ON RED HAT STORAGEA real world scenario

AGENDA
What is Red Hat Storage Server?
•Overview of technology
How does it integrate with Hadoop?
•Summary of integration
Customer use case
•DreamWorks Animation
Demonstration
Q&A
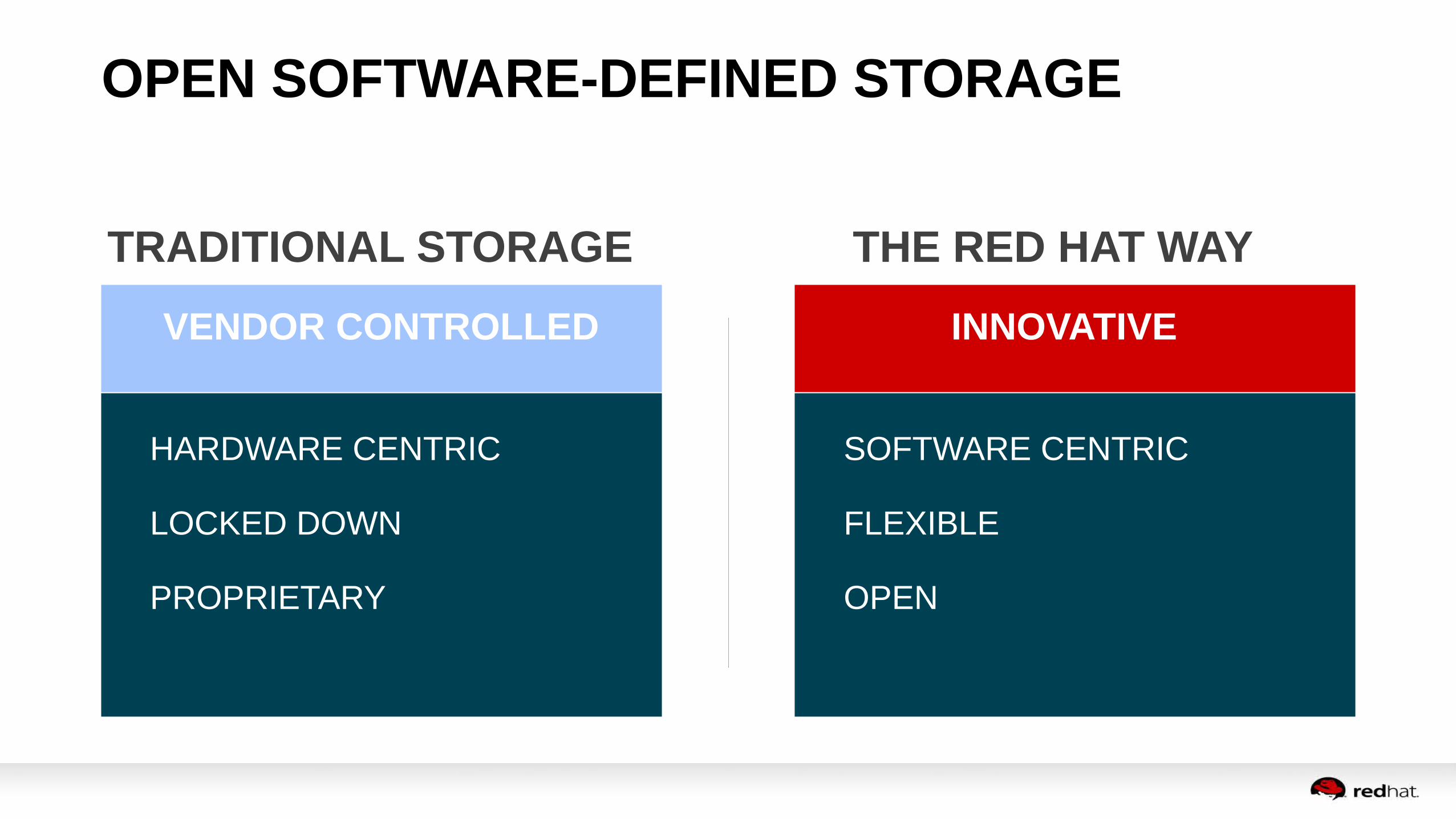
OPEN SOFTWARE-DEFINED STORAGE
TRADITIONAL STORAGE THE RED HAT WAY
HARDWARE CENTRIC
LOCKED DOWN
PROPRIETARY
SOFTWARE CENTRIC
FLEXIBLE
OPEN
INNOVATIVEVENDOR CONTROLLED

ARCHITECTURAL HIGHLIGHTS
DESIGNED FOR THE NEW DATA LANDSCAPE – PETABYTE SCALE
LINEAR SCALABILITY – PERFORMANCE AND CAPACITY
HIGHLY AVAILABLE – WITHOUT BREAKING THE BANK
ACCESSIBLE – FROM ANY APPLICATION, THROUGH ANY DEVICE
OPEN AND INTEROPERABLE – STANDARDS AND OPEN TECHNOLOGIES
SELF-HEALING, SELF-MANAGING – REDUCING OPERATIONAL OVERHEAD
HYBRID DATACENTER FOUNDATION - PRIVATE, PUBLIC, AND HYBRID CLOUDS
EXTENSIBLE – INNOVATE TO MEET YOUR UNIQUE BUSINESS REQUIREMENTS
DESIGNED FOR TODAY’S IT ECONOMICS – DO MORE WITH WHAT YOU HAVE
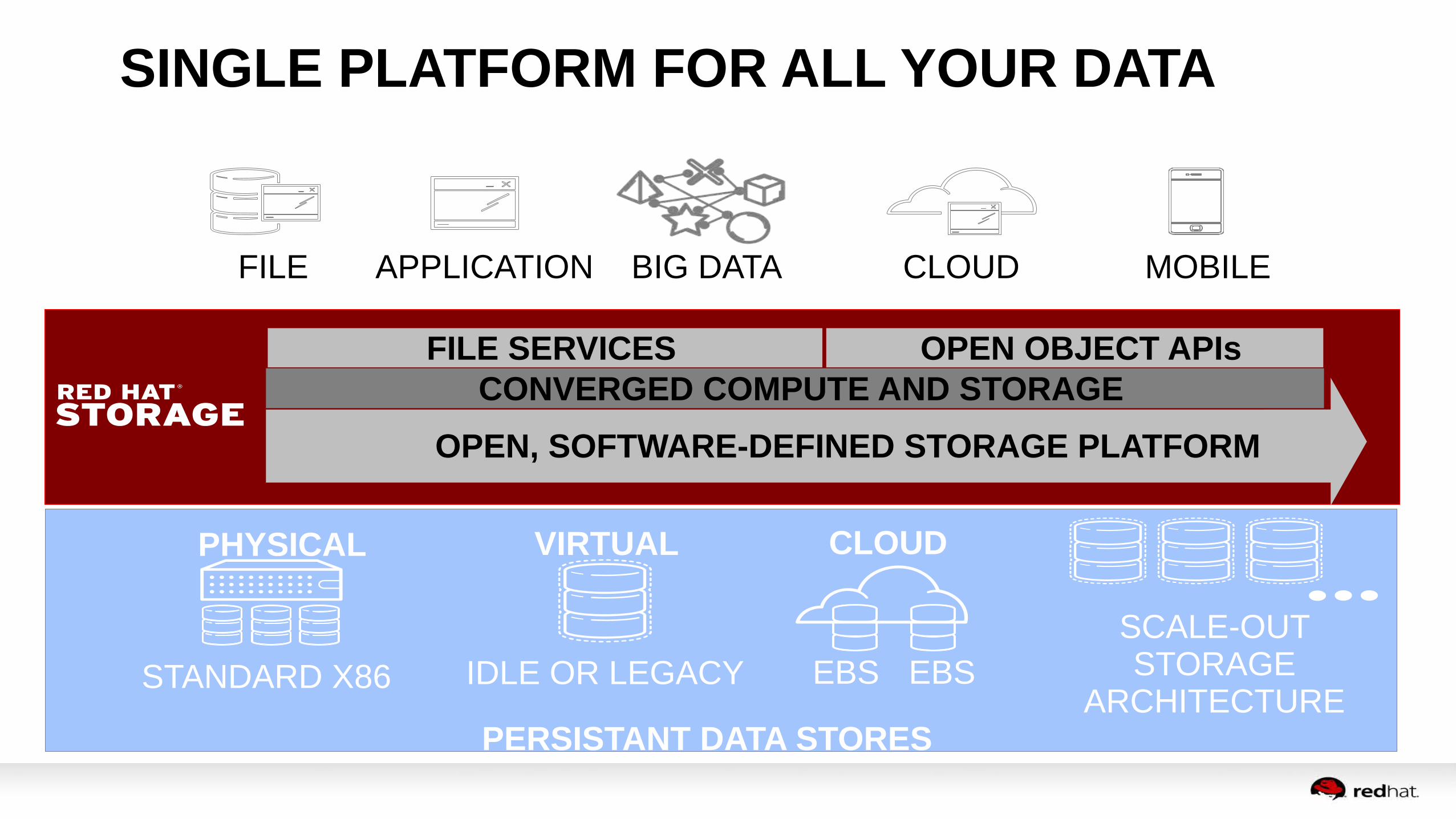
SINGLE PLATFORM FOR ALL YOUR DATA
CONVERGED COMPUTE AND STORAGEFILE SERVICES OPEN OBJECT APIs
OPEN, SOFTWARE-DEFINED STORAGE PLATFORM
PERSISTANT DATA STORES
APPLICATION BIG DATA
PHYSICAL
STANDARD X86
FILE
VIRTUAL
IDLE OR LEGACY
CLOUD MOBILE
CLOUD
EBSEBSSCALE-OUT STORAGE
ARCHITECTURE
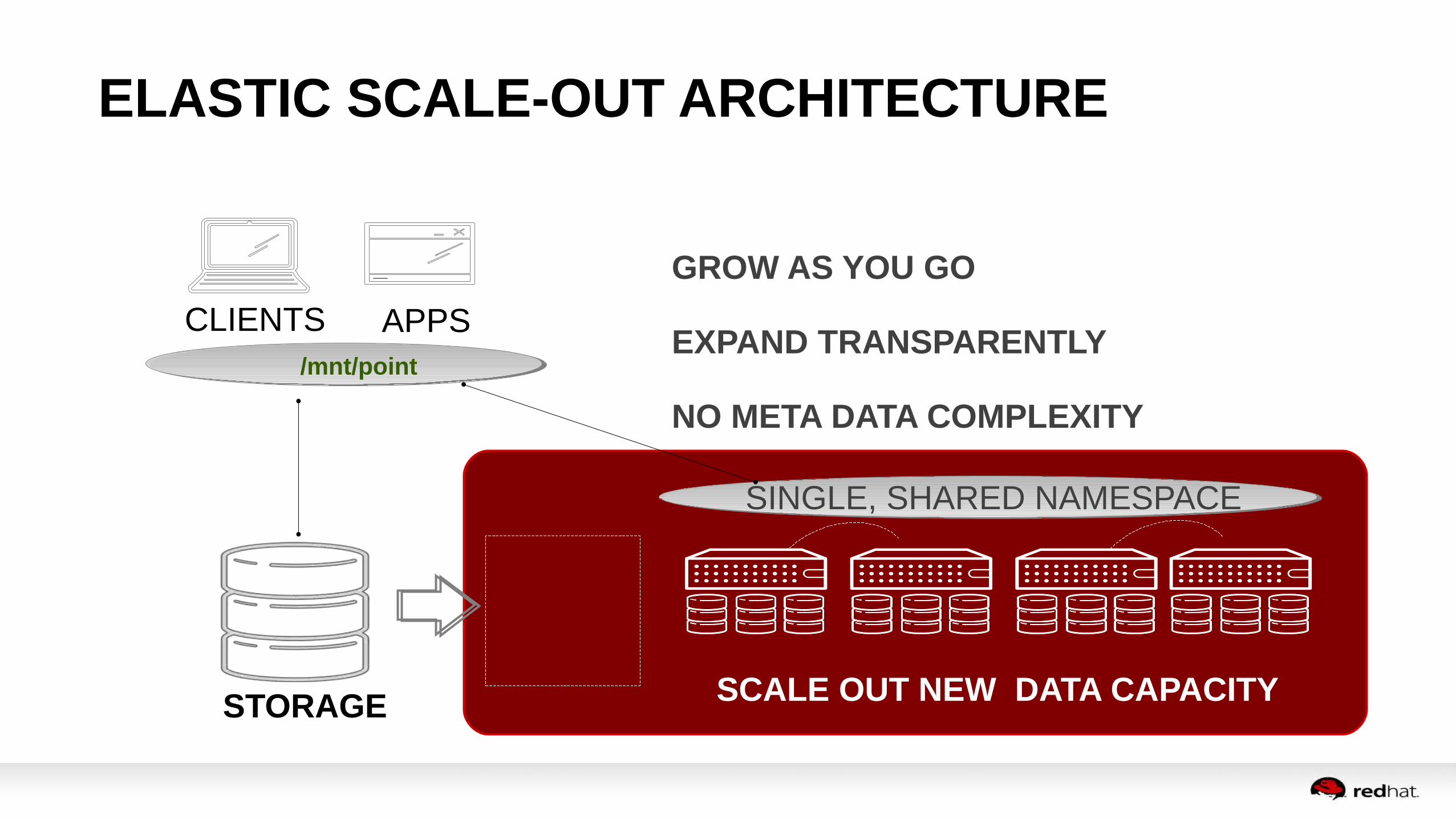
ELASTIC SCALE-OUT ARCHITECTURE
APPS
GROW AS YOU GO
EXPAND TRANSPARENTLY
NO META DATA COMPLEXITY
CLIENTS
SCALE OUT NEW DATA CAPACITYSTORAGE
SINGLE, SHARED NAMESPACE
/mnt/point

HIGHLY AVAILABLE HERE OR THERE
SITE HERE SITE THERE
REMOTE SITE / DR

BRING APPLICATIONS CLOSER TO THE DATA
DATA LOCALITY
REDUCE FOOTPRINT
ISOLATE WORKLOAD
REMAIN SUPPORTED
STORAGE RESIDENT APPLICATIONS

FOUNDATION FOR BIG DATA
DIRECT DATA ACCESS
DON'T COPY YOUR DATA
FULL API COMPATIBILITY
SCALES AS NEEDED
BRING HADOOP TO DATA

HADOOP ON RHS ARCHITECTURE DIAGRAM

ENABLING HADOOP ON RHS VIA AMBARI
Ambari provides ease of installation and configuration of Hadoop
•High Touch Beta (HTB) enabled the ability to install and configure Hadoop on GlusterFS
• Initial Goals• Remove the tightly coupled bond to HDFS creating crippling dependencies between services
• Enable GlusterFS presence on the UI
• Enable minimal monitoring of GlusterFS

HDP STACKS
•Hadoop services are loaded into Ambari via the concept of a stack
•A stack consists of service definitions, rpms and configurations for Hadoop services
•Development enabled GlusterFS as a client service is a new HDP/RHS stack• Client services have no control enablement (stop/start function) from the management console
• Client services are not able to be monitored via Ganglia
• GlusterFS client was deployed via stanard Ambari agents and validated to be running properly for Hadoop installation
•
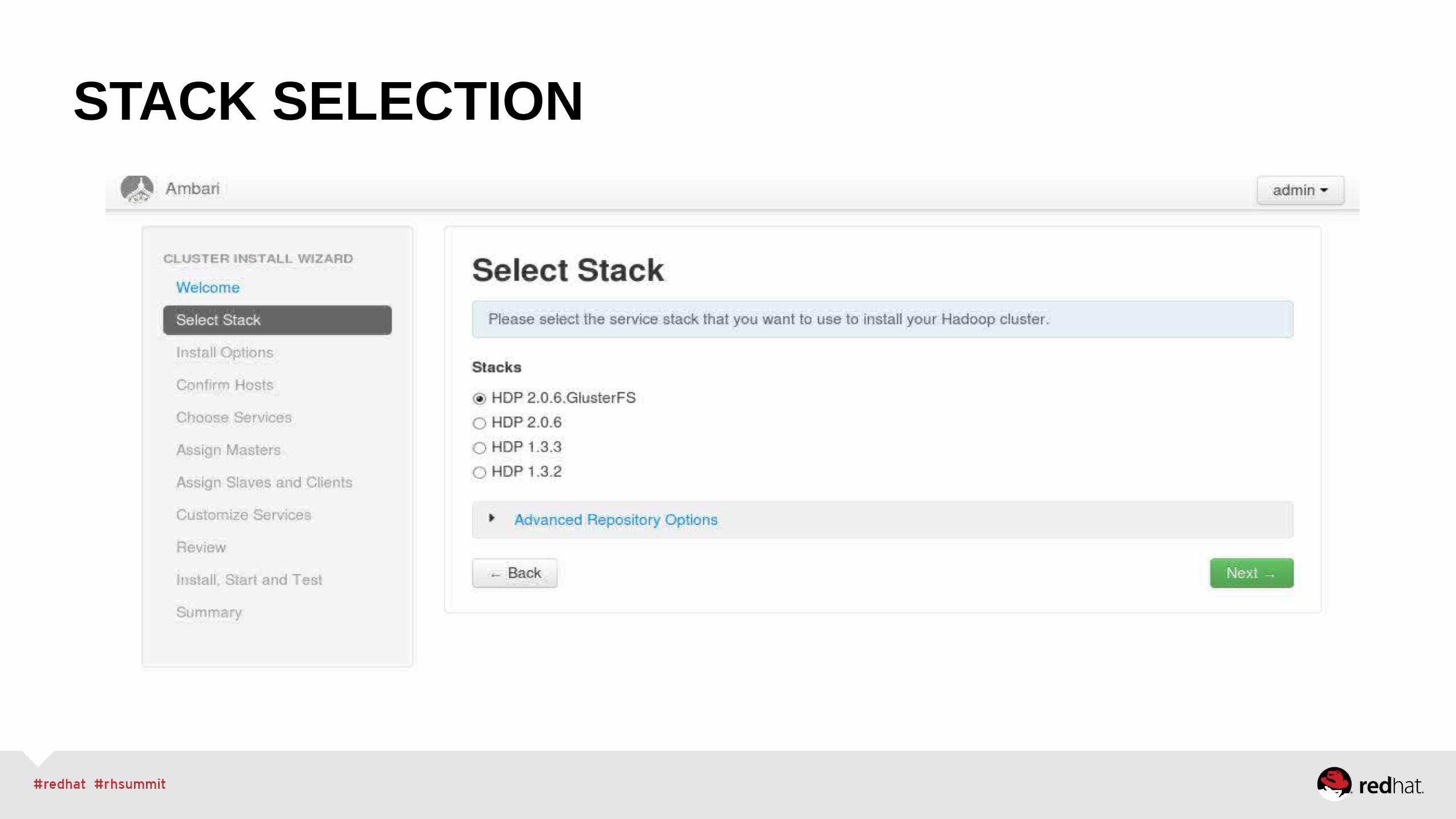
STACK SELECTION

SERVICES IN THE STACK
Stack 2.0.6.GlusterFS•Contains all the core services of 2.0.6 with the addition of GlusterFS:
•GANGLIA, NAGIOS, GLUSTERFS •HBASE •HDFS •MAPREDUCE2 •OOZIE •SQOOP •YARN•GLUSTERFS •HCATALOG •HIVE •PIG •WEBHCAT •ZOOKEEPER

EXPOSE GLUSTERFS OPTIONS FOR HADOOP
•Enabling Raw local filesystem
•Security enablement for multiusers
•Allow users in Hadoop group to run on Hadoop without compromising other’s data

DREAMWORKS ANIMATION WITH HADOOP ON RED HAT STORAGE
Diane FeddemaPrinciple Software Engineer
Red Hat

OVERVIEW
Introduction● What does DreamWorks Animation want to know?
Using RHS to do big data analysis in place● Price effective and uses existing infrastructure
What we found● Some surprise findings
What we learned● How to find the right questions and produce the appropriate log data for the
questions

DREAMWORKS ANIMATION WEB SERVICE INFRASTRUCTURE
Render farm 2with traffic servers
Render farm 3with traffic servers
Render farm 1with traffic servers

Data volume:• 1 ms granularity • ~3.5 TB per week• From 8 traffic servers • Currently much if the data is discarded
Data Analysis to date• Hourly analysis using Splunk –expensive, DreamWorks Animation thinks provides
generic, limited answers to their questions• There remain a number of outstanding questions about work flow and efficiencies
THE NATURE OF DREAMWORKS ANIMATION WEB SERVICE INFRASTRUCTURE DATA

The present log files provide:• One record for each Service Request ( & sub-service request )
Each record provides:– Unix era time stamp and duration (ms) of a process– Type of data being transferred (e.g. JSON, jpeg)
Source, traffic and destination IP information etc.– Code for movie name – Payload size and payload headers etc.– Cache results – HIT or MISS– Correlation ID – unique job/sub-job identifiers
THE NATURE OF DREAMWORKS ANIMATION WEB SERVICE INFRASTRUCTURE DATA


THE DREAMWORKS ANIMATION QUESTIONS
DreamWorks Animation wanted to answer six questions about their web service infrastructure:
1.Determine the service infrastructure HIT and MISS rate over time?2.What does the dominant service call look like?
– What chain of sub calls is most common?3.How often are Correlation IDs reused?4.Compare production vs. non-production jobs for these questions?
– there are jobs which run to test the health of the system that are NOT production runs. Production and non-production runs are mixed together on these traffic servers at all times.
5.What is the average service call duration per traffic server?6.Determine number of non-zero duration events for traffic server cache hits and misses?

QUESTION 1 What is the service infrastructure HIT and MISS rate over time?

TCP_HIT/TCP_MISS time series over 5 minutes

TCP_HIT/TCP_MISS time series over a day

QUESTION 3How often are Correlation IDs reused?

TCP_HIT correlation ID distribution
21,472,938 correlation IDs occur only 2 times each

TCP_MISS correlation ID distribution

QUESTION 4Compare production vs. non-production jobs for these questions?

PRODUCTION run Correlation ID distributions

NON-PRODUCTION run Correlation ID distributions

Comparison of first 5 bins for Production/Non-production and HIT/MISS

QUESTION 5What is the average service call duration per traffic
server?
QUESTION 6Determine number of non-zero duration events for
traffic server cache hits and misses?

EVENTS BY TRAFFIC SERVER

PERCENT EVENTS BY TRAFFIC SERVER

Zero/Non-zero percentages by traffic server

TCP_HIT/TCP_MISS events per traffic server

WHAT WE LEARNED

FINDINGS
• Demonstrated the usefulness Hadoop on RHS for analyzing log data in place.
• Found conditions that they did not know could happen– Found “impossible” missing ID cases– Single and double correlation IDs events dominate when they expected larger
numbers of service call chains to dominate
• Need to make sure you have the right data for the questions asked i.e. – correlations ID data does not allow to track how jobs are split

CONCLUSIONS AND FUTURE COLLABORATION
• Look at more Time Series questions, e.g. show farmid jobs and how they overlap in time.
• Develop hadoop based Dashboard to monitor the “health” of the system and create automated alerts.
• Rethink the questions that can be extracted from existing data• Need to be able to examine individual cases to determine whether some application of the system are not using the API properly
• Consider adding/substituting information in the log file to provide more useful information
• Develop Dashboard to monitor the “health” of the system and create automated alerts.

THANK YOU AND Q&A
Questions and Answers
Contact Information
•Jacob Shucart – [email protected]
•Erin Boyd – [email protected]
•Diane Feddema – [email protected]
Thank you!

Check Out Other Red Hat Storage Activities at The Summit
•Enter the raffle to win tickets for a $500 gift card or trip to LegoLand!• Entry cards available in all storage sessions - the more you attend, the more chances you
have to win!
•Talk to Storage Experts:
• Red Hat Booth (# 211)
• Infrastructure • Infrastructure-as-a-Service
•Storage Partner Solutions Booth (# 605)
•Upstream Gluster projects• Developer Lounge
Follow us on Twitter, Facebook: @RedHatStorage


















