
CULA Sparse Reference Manual — sparse_reference vS4 (CUDA 5
39
index Table Of Contents CULA Sparse Reference Manual Introduction Sparse Linear Systems Supported Operating Systems Attributions Getting Started System Requirements Installation Compiling with CULA Sparse Linking to CULA Sparse Uninstallation Using the API Initialization Memory Management Indexing Formats Sparse Matrix Storage Formats Coordinate Format (COO) Compressed Sparse Row (CSR) Format Compressed Sparse Column (CSC) Format More Information Numerical Types Common Solver Configuration Naming Conventions Choosing a Solver and Preconditioner Iterative Solver Results Data Errors Timing Results Residual Vector Data Types culaStatus culaVersion culaIterativeConfig culaIterativeResult culaIterativeFlag culaIterativeResidual culaIterativeTiming culaReordering Options Structures Framework Functions culaSparseInitialize culaSparseShutdown culaIterativeConfigInit culaIterativeConfigString culaIterativeResultString culaGetCusparseMinimumVersion culaGetCusparseRuntimeVersion Iterative Preconditioners No Preconditioner Jacobi Preconditioner Block Jacobi culaBlockjacobiOptions CULA Sparse Reference Manual Introduction This guide documents CULA Sparse’s programming interface. CULA Sparse™ is an implementation of sparse linear algebra routines for CUDA‑enabled NVIDIA graphics processing units (GPUs). This guide is split into the following sections: Using the API ‑ A high level overview of how to use configure, use, and interpret the results from the iterative solvers in the CULA Sparse library. Data Types ‑ A description of the all datatypes used the library. Framework Functions ‑ A description of the functions used to initialize and configure the library. Iterative Preconditioners ‑ An overview of the preconditioners available within CULA Sparse. Iterative Solvers ‑ A description of the iterative solvers functions available in the library. Performance and Accuracy ‑ Information on how to maximize the performance of the library. Also includes a handful of performance charts. Common Errors ‑ Solutions to errors commonly encountered when using the API. Sparse Linear Systems Many problems in science and engineering, particularly those related to partial differential equations (PDEs), can be represented by a linear system where only a few elements in the matrix are non‑zero. For these systems, it would be wasteful, in both storage and computation, to represent all of the elements. To address these common problems, storage formats and methods have been developed to solve sparse matrices with minimal memory and computation requirements. These methods can be broken into two main categories: direct methods and iterative methods. Direct methods, common for dense matrices, attempt to solve system in a two‑step process. Typical algorithms include LU and QR factorization where the linear system is transformed into an equivalent system that can be solved using Gaussian elimination. Direct methods can also be applied to sparse systems but algorithms become increasingly complex in an attempt to minimize storage and computation.
description
An implementation of sparse linear algebra routines for CUDA‐enabled NVIDIA graphics processing units (GPUs).
Transcript of CULA Sparse Reference Manual — sparse_reference vS4 (CUDA 5
index
Table Of Contents
CULA Sparse Reference ManualIntroduction
Sparse Linear SystemsSupported Operating SystemsAttributions
Getting StartedSystem RequirementsInstallationCompiling with CULA SparseLinking to CULA SparseUninstallation
Using the APIInitializationMemory ManagementIndexing FormatsSparse Matrix Storage Formats
Coordinate Format (COO)Compressed Sparse Row(CSR) FormatCompressed Sparse Column(CSC) FormatMore Information
Numerical TypesCommon Solver ConfigurationNaming ConventionsChoosing a Solver andPreconditionerIterative Solver ResultsData ErrorsTiming ResultsResidual Vector
Data TypesculaStatusculaVersionculaIterativeConfigculaIterativeResultculaIterativeFlagculaIterativeResidualculaIterativeTimingculaReorderingOptions Structures
Framework FunctionsculaSparseInitializeculaSparseShutdownculaIterativeConfigInitculaIterativeConfigStringculaIterativeResultStringculaGetCusparseMinimumVersionculaGetCusparseRuntimeVersion
Iterative PreconditionersNo PreconditionerJacobi PreconditionerBlock Jacobi
culaBlockjacobiOptions
CULA Sparse Reference Manual
IntroductionThis guide documents CULA Sparse’s programming interface.CULA Sparse™ is an implementation of sparse linear algebraroutines for CUDA‑enabled NVIDIA graphics processing units(GPUs). This guide is split into the following sections:
Using the API ‑ A high level overview of howto use configure, use, and interpret theresults from the iterative solvers in the CULASparse library.Data Types ‑ A description of the alldatatypes used the library.Framework Functions ‑ A description of thefunctions used to initialize and configure thelibrary.Iterative Preconditioners ‑ An overview of thepreconditioners available within CULASparse.Iterative Solvers ‑ A description of theiterative solvers functions available in thelibrary.Performance and Accuracy ‑ Information onhow to maximize the performance of thelibrary. Also includes a handful ofperformance charts.Common Errors ‑ Solutions to errorscommonly encountered when using the API.
Sparse Linear SystemsMany problems in science and engineering, particularly thoserelated to partial differential equations (PDEs), can berepresented by a linear system where only a few elements inthe matrix are non‑zero. For these systems, it would bewasteful, in both storage and computation, to represent all ofthe elements. To address these common problems, storageformats and methods have been developed to solve sparsematrices with minimal memory and computationrequirements. These methods can be broken into two maincategories: direct methods and iterative methods.
Direct methods, common for dense matrices, attempt to solvesystem in a two‑step process. Typical algorithms include LUand QR factorization where the linear system is transformedinto an equivalent system that can be solved using Gaussianelimination. Direct methods can also be applied to sparsesystems but algorithms become increasingly complex in anattempt to minimize storage and computation.

ILU0culaIlu0Options
Iterative SolversConjugate Gradient (CG)
ParametersculaCgOptions
Biconjugate Gradient (BiCG)ParametersculaBicgOptions
Biconjugate Gradient Stabilized(BiCGSTAB)
ParametersculaBicgstabOptions
Generalized BiconjugateGradient Stabilized (L)(BiCGSTAB(L))
ParametersculaBicgstablOptions
Restarted General MinimumResidual (GMRES(m))
ParametersculaMinresOptions
Minimum residual method(MINRES)
ParametersculaMinresOptions
Performance and AccuracyPerformance Considerations
Double PrecisionProblem SizeStorage FormatsPreconditioner Selection
Accuracy ConsiderationsNumerical PrecisionRelative Residual
API ExampleConfiguring Your Environment
Microsoft Visual StudioGlobal SettingsProject SettingsRuntime Path
Linux / Mac OS X ‑ CommandLine
Configure EnvironmentVariablesConfigure Project PathsRuntime Path
Checking That Libraries areLinked Correctly
Common ErrorsArgument ErrorMalformed MatrixData Errors
Maximum Iterations ReachedPreconditioner FailureStagnationScalar Out of RangeUnknown Iteration Error
Runtime ErrorInitialization ErrorNo Hardware ErrorInsufficient Runtime ErrorInsufficient Compute CapabilityError
The other class of sparse solvers, and those currentlyimplemented in CULA Sparse, are iterative methods. Thesemethods attempt to coverage on solution to the system
by continuously iterating over new solutions until asolution’s residual, typically defined as , is undera given tolerance. At each step, a solution is calculated using atechnique specific to the given algorithm. Because it ispossible for iterative methods to fail to find a solution, theyare commonly configured with a maximum number ofiterations.
A common method to improve the speed at which a solutionconverges is called preconditioning. These methods attempt,at each iteration, to transform the original linear system into anew equivalent system that can more readily be solved. Thisadds overhead, in both memory and time per iteration, but willoften result in a shorter end‑to‑end solution time.
Supported Operating SystemsCULA Sparse intends to support the full range of operatingsystems that are supported by CUDA. Installers are currentlyavailable for Windows, Linux, and MAC OS X in 32‑bit and 64‑bit versions. CULA Sparse has been tested on the followingsystems:
Windows XP / Vista / 7Ubuntu Linux 10.04 (and newer)Red Hat Enterprise Linux 5.3 (and newer)Fedora 11Mac OSX 10.6 Snow Leopard / 10.7 Lion
Please provide feedback on any other systems on which youattempt to use CULA Sparse. Although we are continuallytesting CULA Sparse on other systems, at present we officiallysupport the above list. If your system is not listed, please letus know through the provided feedback channels.
AttributionsThis work has been made possible by the NASA Small BusinessInnovation Research (SBIR) program. We recognize NVIDIA fortheir support.
CULA Sparse is built on NVIDIA CUDA 4.0 and NVIDIACUSPARSE.
CULA Sparse uses COLAMD, covered by the GNU LGPL license.The source code for COLAMD is used in an unmodifiedfashion; a copy of this code is distributed in thesrc/suitesparse directory of this package.
Many of the algorithms and methods from this library weredeveloped based on Yousef Saad’s textbook “Iterative Methodsfor Sparse Linear Systems”.
Getting Started
System RequirementsCULA Sparse utilizes CUDA on an NVIDIA GPU to performlinear algebra operations. Therefore, an NVIDIA GPU withCUDA support is required to use CULA Sparse. A list ofsupported GPUs can be found on NVIDIA’s CUDA Enabled
Ax = b||b J Ax||/||b||
Insufficient Memory ErrorSupport Options
Matrix Submission GuidelinesRoutine Selection Flowcharts
Solver Selection FlowchartPreconditioner SelectionFlowchart
ChangelogRelease S4 CUDA 5.0 (October16, 2012)Release S3 CUDA 4.2 (August14, 2012)Release S2 CUDA 4.1 (January30, 2012)Release S1 CUDA 4.0(November 2, 2011)Release S1 Beta 2 CUDA 4.0(September 27, 2011)Release S1 Beta 1 CUDA 4.0(August 24, 2011)
Quick search
Go
Enter search terms or a module, classor function name.
webpage.
Support for double‑precision operations requires a GPU thatsupports CUDA Compute Model 1.3. To find out whatCompute Model your GPU supports, please refer to the NVIDIACUDA Programming Guide.
Note
CULA Sparse’s performance is primarily influenced by theprocessing power of your system’s GPU, and as such a morepowerful graphics card will yield better performance.
InstallationInstallation is completed via the downloadable installationpackages. To install CULA Sparse, refer to the section belowthat applies to your system.
Windows
Run the CULA Sparse installer and when prompted select thelocation to which to install. The default install location isc:\Program Files\CULA\S#, where S# represents the releasenumber of CULA Sparse.
Linux
It is recommended that you run the CULA Sparse installer asan administrator in order to install to a system‑level directory.The default install location is /usr/local/culasparse.
Mac OS X Leopard
Open the CULA Sparse .dmg file and run the installer locatedinside. The default install location is /usr/local/culasparse.
Note
You may wish to set up environment variables to commonCULA Sparse locations. More details are available in theConfiguring Your Environment chapter.
Compiling with CULA SparseCULA Sparse presents one main C header, cula_sparse.h. Youmust include this header in your C source file to use CULASparse.
Linking to CULA SparseCULA Sparse provides a link‑time stub library, but is otherwisebuilt as a shared library. Applications should link against thefollowing libraries:
Windows
Choose to link against cula_sparse.lib and cula_core.lib as alink‑time option.
Linux / Mac OS X Leopard
Add ‐l cula_core ‐lcula_sparse to your program’s link line.
CULA Sparse is built as a shared library, and as such it mustbe visible to your runtime system. This requires that theshared library is located in a directory that is a member ofyour system’s runtime library path . For more detailedinformation regarding operating‑system‑specific linking
procedures, please refer to the Configuring Your Environmentchapter.
CULA Sparse’s example projects are a good resource forlearning how to set up CULA Sparse for your own project.
Note
CULA Sparse is built against NVIDIA CUDA 4.2 and ships with acopy of the CUDA 4.2 redistributable files. If you have adifferent version of CUDA installed, you must ensure that theCUDA runtime libraries shipped with CULA Sparse are the firstvisible copies to your CULA Sparse program. This can beaccomplished by placing the CULA Sparse bin path earlier inyour system PATH than any CUDA bin path. If a non‑CUDA 4.2runtime loads first, you will experience CULA Sparse errors. Seethe Checking That Libraries are Linked Correctly example for adescription of how to programmatically check that the correctversion is linked.
UninstallationAfter installation, CULA Sparse leaves a record to uninstallitself easily. To uninstall CULA Sparse, refer to the sectionbelow that applies to your system.
Windows
From the Start Menu, navigate to the CULA Sparse menu entryunder Programs, and select the Uninstall option. The CULASparse uninstaller will remove CULA Sparse from your system.
Linux
Run the CULA Sparse installer, providing an ‘uninstall’argument.
e.g. ./cula.run uninstall
Mac OS X Leopard
There is no uninstallation on OS X, but you can remove thefolder to which you installed CULA Sparse for a completeuninstall.
Note
If you have created environment variables with references toCULA Sparse, you may wish to remove them afteruninstallation.
Using the APIThis chapter describes, at a high level, how to use the CULASparse API. Basic information about how to initialize andconfigure an iterative solver is discussed. Furthermore, weintroduce how to collect and interpret the results from theiterative solvers as well any error condition that may occur.
Further specifics are found in the subsequent chapters.
InitializationThe CULA Sparse library is initialized by calling theculaSparseInitialize() function. This function must be calledbefore any of the iterative solvers are invoked. It is possible tocall other CULA framework functions such as

culaSelectDevice() prior to initialization. For interoperabilitywith CULA, this routine will also perform the culaInitialize()operation.
// initialize cula sparse libraryculaSparseInitialize();
Memory ManagementIn CULA Sparse, all functions accept pointers to matricesdefined on the host; that is, matrices allocated with malloc(),new, or std::vector. CULA Sparse will automatically transfer thedata to‑and‑from the accelerated device. This step isperformed concurrently to other operations and yields almostno performance impact for this transfer.
Note: Future versions may relax this requirement and allowdirect device memory access.
// allocate solver data on host using malloc (C)double* data = (double*) malloc( nnz * sizeof(double) );// allocate solver data on host using new[]double* data = new double[nnz];// allocate solver data on host using a std vector (C++)std::vector <double> data( nnz );
Indexing FormatsCULA Sparse supports both 0 (C/C++) and 1 (FORTRAN) basedindexing through the indexing field of the culaIterativeConfigconfiguration structure. The default is zero‑based indexing.
Sparse Matrix Storage FormatsCULA Sparse currently supports three major matrix storageformats: coordinate, compressed row, and compressedcolumn. It is recommended to use the compressed row formatwhen possible.
Coordinate Format (COO)
In the coordinate format, a sparse matrix is represented bythree vectors sized by the number of non‑zero elements ofthe system. The common abbreviation for this length, isused throughout the API and this document.
values ‑ the non‑zero data values within thematrix; length row index ‑ the associated row index of eachnon‑zero element; length column index ‑ the associated column indexof each non‑zero element; length
Consider the following 3x3 matrix with 6 non‑zero elements:
In a zero‑indexed coordinate format, this matrix can berepresented by the three vectors:
nnz
nnz
nnz
nnz
A =⎛⎝⎜⎜
1.02.03.0
4.05.00.0
0.00.06.0
⎞⎠⎟⎟
= [ ]

In the CULA Sparse interface, the values are denoted as a, thecolumn index as colInd, and the row index as rowInd.
Compressed Sparse Row (CSR) Format
In the compressed sparse row format, the row index vector isreplaced by a row pointer vector of size . This vectornow stores the locations of values that start a row; the lastentry of this vector points to one past the final data element.The column index is as in COO format.
Consider the same 3x3 matrix, a zero‑indexed CSR format canbe represented by three vectors:
In the CULA Sparse interface, the values are denoted as a, thecolumn index as colInd, and the row pointer as rowPtr.
Compressed Sparse Column (CSC) Format
In the compressed sparse column format, the column indexvector is replaced by a column pointer vector of size .This vector now stores the locations of values that start acolumn; the last entry of this vector points to one past thefinal data element. The row index is as in COO format.
Consider the same 3x3 matrix, a zero‑indexed CSC formatcan be represented by three vectors:
In the CULA Sparse interface, the values are denoted as , thecolumn pointer as colPtr, and the row index as rowInd.
More Information
For more information regarding these storage formats, werecommend reading Section 3.4, Storage Schemes, YousefSaad’s textbook “Iterative Methods for Sparse Linear Systems”.
Numerical TypesCULA Sparse provides two data types with which you canperform computations.
Symbol Interface Type Meaning
D culaDouble double precisionfloating point
Z culaDoubleComplex double precisioncomplex floating point
The culaDoubleComplex type can be made to be identical to thecuComplex type provided by CUDA, by #define
values
column index
row index
= [ ]1.0 2.0 3.0 4.0 5.0 6.0= [ ]0 0 0 1 1 2= [ ]0 1 2 0 1 2
m + 1
values
column index
row pointer
= [ ]1.0 4.0 2.0 5.0 3.0 6.0= [ ]0 1 0 1 0 2= [ ]0 2 4 6
n + 1
values
row index
column pointer
= [ ]1.0 2.0 3.0 4.0 5.0 6.0
= [ ]0 1 2 0 1 2
= [ ]0 3 5 6
a

CULA_USE_CUDA_COMPLEX prior to including any CULA headers.
Common Solver ConfigurationAll iterative solvers within CULA Sparse utilize a commonconfiguration parameter to steer the execution of the solver.The configuration parameter is represented by theculaIterativeConfig structure and is the first parameter to anysolver function within the library. The configuration parameterinforms the API of the desired solve by specifying:
The tolerance at which a solve is marked asconvergedThe maximum number of iterations to runWhether the input matrices use zero‑ orone‑based indexingWhether a debugging mode should beenabled
More parameters may be added in the future.
Configuration parameters must be set up before a solver canbe called. The configuration parameter is initialized by theculaIterativeConfigInit() function. This function ensures thatall parameters within this structure are set to reasonabledefaults. After calling this function, you may set specificparameters to your needs.
Example configuration:
// create configuration structureculaIterativeConfig config;
// initialize valuesculaIterativeConfigInit(&config);
// configure specific parametersconfig.tolerance = 1.e‐6;config.maxIterations = 300;config.indexing = 0;
Naming ConventionsFour major concepts are conveyed by the function names ofthe iterative system solvers within the CULA Sparse library:
cula{type}{storage}{solver}{precond}(...)
Here, each {...} segment represents a different majorcomponent of the routine. The following table explains each ofthese components:
Name Meaning
type data type used
storage sparse matrix storage format used
solvers iterative method used
precond preconditioner method used
For example, the routine culaDcsrCgJacobi() will attempt tosolve a double precision sparse matrix stored in thecompressed sparse row (CSR) storage format using theconjugate gradient (CG) method with Jacobi preconditioning.
Choosing a Solver and Preconditioner

Choosing a proper solver is typically determined by the classof the input data. For example, the CG method is onlyappropriate for symmetric positive definite matrices.
Preconditioner selection is more of an art ‑ the method chosenis tightly coupled to the specifics of the linear system. That is,the computational tradeoffs of generation and application ofthe preconditioner will be different for different systems.
// call CG solver with Jacobi preconditionerculaStatus status = culaDcsrCgJacobi( &config, n, nz, val, colInd, rowPtr, x, rhs, &result );
Iterative Solver ResultsTo convey the status of a given routine, the iterative solverroutines return a culaStatus code and also populates aculaIterativeResult output structure.
The culaStatus return code is common between the CULA andCULA Sparse libraries. It is a high level status code used toindicate if the associated call has completed successfully.Systemic errors that prevented execution are presented in thiscode, such as not initializing CULA, GPU of insufficientcapability, or out‑of‑memory conditions. Most details ofmathematical progress of a solver will be presented inculaIterativeResult.
if ( culaStatus == culaNoEror ){ // solution within given runtime parameters was found}
The culaIterativeResult structure provides additionalinformation regarding the computation such as:
A flag that denotes the solvers converged ora reason why convergence failedThe number of iterations performed,regardless of whether this led toconvergenceThe solution residual when the solve endedTiming information for the overhead,preconditioner generation, and solving
This structure is returned from all iterative solves.
CULA Sparse also provides a utility function forculaIterativeResult, which is calledculaIterativeResultString(), that constructs a readable stringof information that is suitable for printing. In many cases, thisfunction is able to provide information beyond that which isavailable by inspection of the structure, and so it isrecommended that it be used whenever attempting to debug asolver problem.
// allocate result string bufferconst int bufferSize = 256;char buffer[bufferSize];
// fill buffer with result stringculaIterativeResultString( &result, buffer, bufferSize );
// print result string to screenprintf( "%s\n", buffer );

Example output:
Solver: CG (Jacobi preconditioner)Flag: Converged successfully in 213 iterationsResidual: 9.675273e‐007Total Time: 0.01363s (overhead + precond + solve) Overhead: 3.845e‐005s Precond: 0.001944s Solve: 0.01165s
Data ErrorsIn CULA Sparse, the culaDataError return status is used todescribe any condition for which the solver failed to convergeon solution within the given configuration parameters.
Possible reasons for returning a culaDataError include:
Preconditioner failed to generate; noiterations attemptedMaximum number of iterations exceededwithout reaching desired toleranceAn internal scalar quantity became too largeor small to continueThe method stagnatedThe input data contained values of nan or inf
These possible reasons are enumerated by the flag field of theculaIterativeResult structure.
In some cases, a user may wish to get the best possible resultin a fixed number of iterations. In such a case, a data error canbe interpreted as success if and only if the flag isculaMaxItReached. The residual should then be consulted tojudge the quality of solution obtained in the budgeted numberof iterations.
if ( status == culaDataError && result.flag == culaMaxItReached ){ // solver executed but the method did not converge to tolerance // within the given iteration limit; it is up to programmer // judgement whether the result is now acceptable}
Timing ResultsFor convenience, the culaIterativeResult result structurecontains high precision timing information regarding theruntime of the iterative solver. This timing is broken down intothree major components:
Overhead ‑ This includes memoryallocations, transfers to‑and‑from the GPU,and internal operations such as storage typeconversion.Preconditioner ‑ The time taken to generatethe requested preconditioner. This does notinclude the per‑iteration time to apply thepreconditioner; the per‑iteration time of apreconditioner is included in the solver time.Solver ‑ This represents the time spent inthe actual iteration loop
Additionally, the total time is returned which is a sum of thesethree values. All values are in seconds.
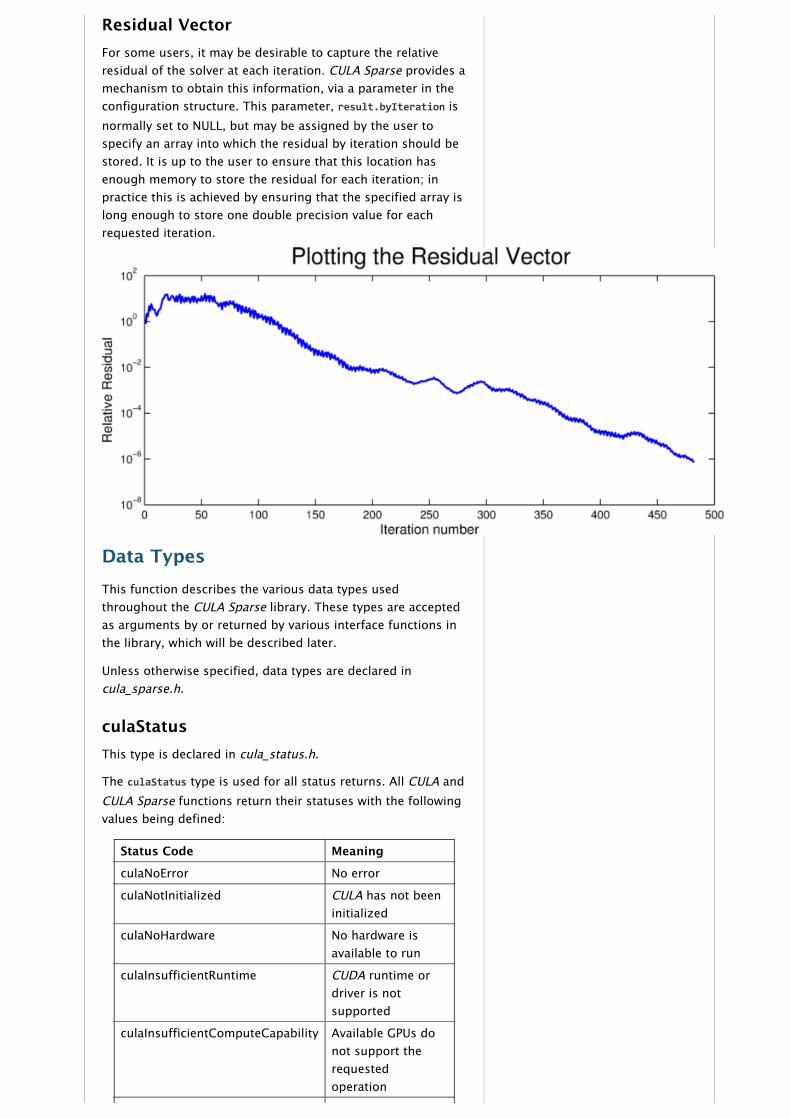
Residual VectorFor some users, it may be desirable to capture the relativeresidual of the solver at each iteration. CULA Sparse provides amechanism to obtain this information, via a parameter in theconfiguration structure. This parameter, result.byIteration isnormally set to NULL, but may be assigned by the user tospecify an array into which the residual by iteration should bestored. It is up to the user to ensure that this location hasenough memory to store the residual for each iteration; inpractice this is achieved by ensuring that the specified array islong enough to store one double precision value for eachrequested iteration.
Data TypesThis function describes the various data types usedthroughout the CULA Sparse library. These types are acceptedas arguments by or returned by various interface functions inthe library, which will be described later.
Unless otherwise specified, data types are declared incula_sparse.h.
culaStatusThis type is declared in cula_status.h.
The culaStatus type is used for all status returns. All CULA andCULA Sparse functions return their statuses with the followingvalues being defined:
Status Code Meaning
culaNoError No error
culaNotInitialized CULA has not beeninitialized
culaNoHardware No hardware isavailable to run
culaInsufficientRuntime CUDA runtime ordriver is notsupported
culaInsufficientComputeCapability Available GPUs donot support therequestedoperation
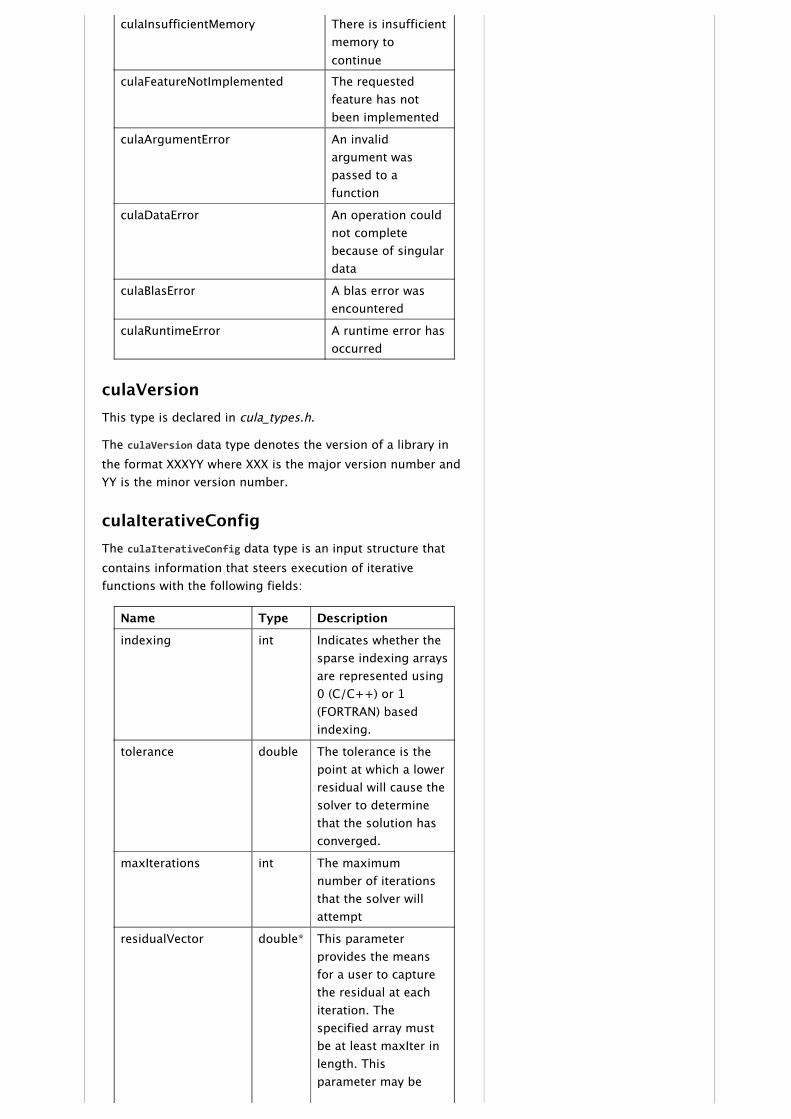
culaInsufficientMemory There is insufficientmemory tocontinue
culaFeatureNotImplemented The requestedfeature has notbeen implemented
culaArgumentError An invalidargument waspassed to afunction
culaDataError An operation couldnot completebecause of singulardata
culaBlasError A blas error wasencountered
culaRuntimeError A runtime error hasoccurred
culaVersionThis type is declared in cula_types.h.
The culaVersion data type denotes the version of a library inthe format XXXYY where XXX is the major version number andYY is the minor version number.
culaIterativeConfigThe culaIterativeConfig data type is an input structure thatcontains information that steers execution of iterativefunctions with the following fields:
Name Type Description
indexing int Indicates whether thesparse indexing arraysare represented using0 (C/C++) or 1(FORTRAN) basedindexing.
tolerance double The tolerance is thepoint at which a lowerresidual will cause thesolver to determinethat the solution hasconverged.
maxIterations int The maximumnumber of iterationsthat the solver willattempt
residualVector double* This parameterprovides the meansfor a user to capturethe residual at eachiteration. Thespecified array mustbe at least maxIter inlength. Thisparameter may be
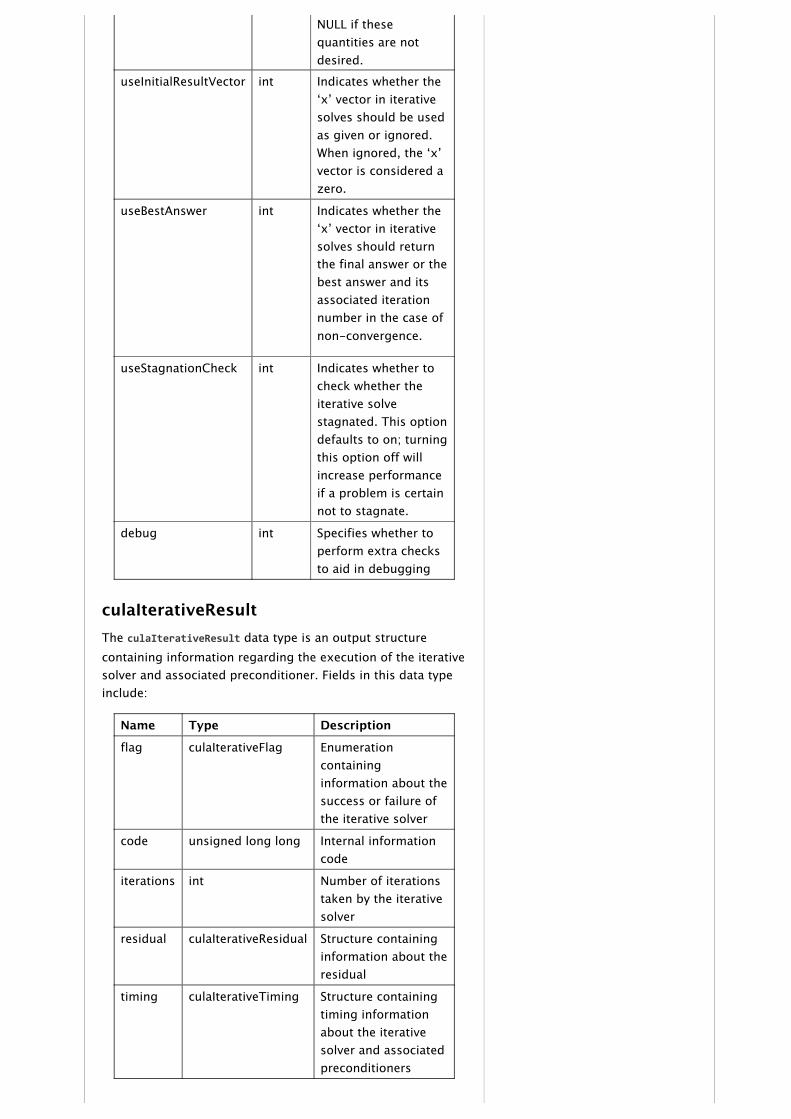
NULL if thesequantities are notdesired.
useInitialResultVector int Indicates whether the‘x’ vector in iterativesolves should be usedas given or ignored.When ignored, the ‘x’vector is considered azero.
useBestAnswer int Indicates whether the‘x’ vector in iterativesolves should returnthe final answer or thebest answer and itsassociated iterationnumber in the case ofnon‑convergence.
useStagnationCheck int Indicates whether tocheck whether theiterative solvestagnated. This optiondefaults to on; turningthis option off willincrease performanceif a problem is certainnot to stagnate.
debug int Specifies whether toperform extra checksto aid in debugging
culaIterativeResultThe culaIterativeResult data type is an output structurecontaining information regarding the execution of the iterativesolver and associated preconditioner. Fields in this data typeinclude:
Name Type Description
flag culaIterativeFlag Enumerationcontaininginformation about thesuccess or failure ofthe iterative solver
code unsigned long long Internal informationcode
iterations int Number of iterationstaken by the iterativesolver
residual culaIterativeResidual Structure containinginformation about theresidual
timing culaIterativeTiming Structure containingtiming informationabout the iterativesolver and associatedpreconditioners

culaIterativeFlagThe culaIterativeFlag data type is an output enumerationcontaining a set of all possible success and mathematical errorconditions that can be returned by the iterative solverroutines. Possible elements include:
Flag Value Meaning
culaConverged The solve convergedsuccessfully
culaMaxItReached Maximum iterationsreached withoutconvergence
culaPreconditionerFailed The specifiedpreconditioner failed
culaStagnation The iterative solvestagnated
culaScalarOutOfRange A scalar value was out ofrange
culaUnknownIterationError An unknown iteration errorwas encountered
For more information about various failure conditions, see theCommon Errors chapter.
culaIterativeResidualThe culaIterativeResidual data type is an output structure thatcontains information about the residual of an iterative functionwith the following fields:
Member Type Description
relative double The relative residual obtained bythe iterative solver whencomputation has completed orhalted
byIteration double* If requested, the residual atevery step of iteration
For more information, see Residual Vector.
culaIterativeTimingThe culaIterativeTiming data type is an output structurecontaining timing information for execution of an iterativefunction with the following fields:
Member Type Description
solve double Time, in seconds, the solveportion of the iterative solvertook to complete
preconditioner double Time, in seconds, thepreconditioner generativeportion of the iterative solvertook to complete
overhead double Time, in seconds, of overheadneeded by the iterative solver;includes memory transfers to‑and‑from the GPU

total double Time, in seconds, the entireiterative solver took tocomplete
For more information see Timing Results.
culaReorderingThe culaReordering data type is an enum that specifies areordering strategy for certain preconditioners. For somematrices, reordering can introduce additional parallelism thatcan allow the solver to proceed more efficiently on a paralleldevice.
Flag Value Meaning
culaNoReordering Do not do any reordering
culaAmdReordering Reorder using theapproximate minimum degreeordering method
culaSymamdReordering Reorder using the symmetricminimum degree orderingmethod (SYMAMD)
Reordering can be expensive in terms of additional memoryrequired. COLAMD requires approximately
extra elements of storage.
Options StructuresSolver and preconditioner options structures allow you to steerthe execution of a given solver and preconditioner. They arethe second and third parameters for all solver functions,respectively. For documentation on individual optionsstructures, see the corresponding solver or preconditionersection.
Initializing these structures is done with a method thatmatches the name of the associated solver or preconditionerwith an Init appended.
// create options structureculaBicgOptions solverOpts;
// initialize valuesculaBicgOptionsInit(&solverOpts);
// configure specific parameters (if applicable)// . . .
Several options structures have reserved parameters. Thesestructures are implemented in this way so as to maintainuniformity in the solver parameter list and to providecompatibility for possible future code changes. Werecommend that you make sure to call the optionsinitialization function (as shown above) for all options in thecase that any parameters are added to it in the future. A NULLpointer may be passed, in which case reasonable defaults willbe assigned. As this may change in future versions, it isrecommended to explicitly construct the structures.
Framework FunctionsThis section describes the helper functions associated CULASparse library. These functions include initializing,
2.2 O NNZ + 7 O N + 4 O M

configuration, and result analysis routines found incula_sparse.h.
culaSparseInitializeDescription
Initializes CULA Sparse Must be called before using any otherfunction. Some functions have an exception to this rule:culaGetDeviceCount, culaSelectDevice, and version queryfunctions
Returns
culaNoError on a successful initialization or a culaStatus enumthat specifies an error
culaSparseShutdownDescription
Shuts down CULA Sparse
culaIterativeConfigInitDescription
Constructs a config structure, initializing it to default values.
Parameters
Name Description
config Pointer to the culaIterativeConfig struct that willbe initialized by this routine.
Returns
culaNoError on success or culaArgumentError if a parameter isinvalid
culaIterativeConfigStringDescription
Associates an iterative config structure with a readable configreport
Parameters
Name Description
config Pointer to the culaIterativeConfig struct thatwill be analyzed by this routine
buf Pointer to a buffer into which information willbe printed (recommend size 256 or greater)
bufsize The size of buf, printed information will notexceed bufsize
Returns
culaNoError on a successful config report orculaArgumentError on an invalid argument to this function
culaIterativeResultStringDescription
Associates an iterative result structure with a readable result

result
Parameters
Name Description
e A culaStatus error code
i A pointer to a culaIterativeResult structure
buf Pointer to a buffer into which information willbe printed (recommend size 256 or greater)
bufsize The size of buf, printed information will notexceed bufsize
Returns
culaNoError on a successful result report orculaArgumentError on an invalid argument to this function
culaGetCusparseMinimumVersionDescription
Reports the CUSPARSE_VERSION that the running version ofCULA was compiled against, which indicates the minimumversion of CUSPARSE that is required to use this library
Returns
An integer in the format XXXYY where XXX is the major versionnumber and YY is the minor version number of CUSPARSE thatthis version of CULA was compiled against. On error, a 0 isreturned.
culaGetCusparseRuntimeVersionDescription
Reports the version of the CUSPARSE runtime that operatingsystem linked against when the program was loaded
Returns
An integer in the format XXXYY where XXX is the major versionnumber and YY is the minor version number of the CUSPARSEruntime. On error, a 0 is returned.
Iterative PreconditionersPreconditioning is an additional step to aid in convergence ofan iterative solver. This step is simply a means of transformingthe original linear system into one which has the samesolution, but which is most likely easier to solve with aniterative solver. Generally speaking, the inclusion of apreconditioner will decrease the number of iterations neededto converge upon a solution. Proper preconditioner selection isnecessary for minimizing the number of iterations required toreach a solution. However, the preconditioning step does addadditional work to every iteration as well as up‑frontprocessing time and additional memory. In some cases thisadditional work may end up being a new bottleneck andimproved overall performance may be obtained using apreconditioner that takes more steps to converge, but theoverall runtime is actually lower. As such, we recommendanalyzing multiple preconditioner methods and looking at thetotal runtime as well the number of iterations required.

This chapter describes several preconditioners, which havedifferent parameters in terms of effectiveness, memory usage,and setup/apply time.
For additional algorithmic details regarding the methodsdetailed in this chapter, we recommend reading the“Preconditioning Techniques” chapter from Yousef Saad’stextbook “Iterative Methods for Sparse Linear Systems”.
No PreconditionerTo solve a system without a preconditioner, simply call thesolving routine without a preconditioner suffix, such asculaDcsrCg(). A NULL pointer may be passed for theprecondOpts parameter.
Jacobi PreconditionerThe Jacobi precondition is a simple preconditioner that is areplication of the diagonal:
The Jacobi preconditioner is very lightweight in generation,memory usage, and application. As such, it is often a strongchoice for GPU accelerated solvers.
As detailed in Iterative Solvers, the Jacobi preconditioner isinvoked by calling an iterative solver with the Jacobi suffixalong with the culaJacobiOptions input struct parameter (seeOptions Structures).
Block JacobiThe Block Jacobi preconditioner is an extension of the Jacobipreconditioner where the matrix is now represented as a blockdiagonal of size :
This preconditioner is a natural fit for systems with multiplephysical variables that have been grouped into blocks.
The Block Jacobi preconditioner requires more computation inboth generation and application than the simpler Jacobipreconditioner. However, both generation and application areparallel operations that map well to the GPU.
As detailed in Iterative Solvers, the block Jacobi preconditioneris invoked by calling an iterative solver with the Blockjacobisuffix along with the culaBlockjacobiOptions input structparameter.
culaBlockjacobiOptions
Name Type Description
blockSize int Block size for the JacobiPreconditioner
= {Mi,kAi,j
0if i = jotherwise
b
= {Mi,kAi,j
0if i and j are within the block subset, botherwise
M =⎡
⎣⎢⎢
B0
'0
(
*(
0
'Bn
⎤
⎦⎥⎥
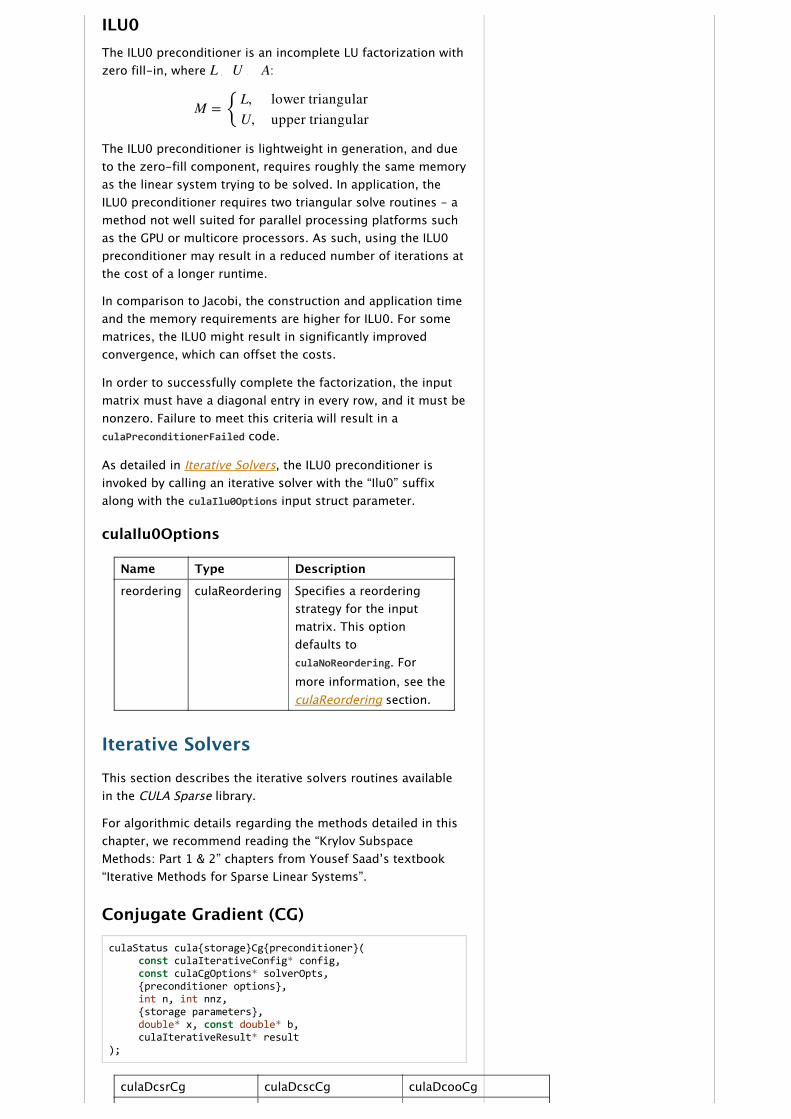
ILU0The ILU0 preconditioner is an incomplete LU factorization withzero fill‑in, where :
The ILU0 preconditioner is lightweight in generation, and dueto the zero‑fill component, requires roughly the same memoryas the linear system trying to be solved. In application, theILU0 preconditioner requires two triangular solve routines ‑ amethod not well suited for parallel processing platforms suchas the GPU or multicore processors. As such, using the ILU0preconditioner may result in a reduced number of iterations atthe cost of a longer runtime.
In comparison to Jacobi, the construction and application timeand the memory requirements are higher for ILU0. For somematrices, the ILU0 might result in significantly improvedconvergence, which can offset the costs.
In order to successfully complete the factorization, the inputmatrix must have a diagonal entry in every row, and it must benonzero. Failure to meet this criteria will result in aculaPreconditionerFailed code.
As detailed in Iterative Solvers, the ILU0 preconditioner isinvoked by calling an iterative solver with the “Ilu0” suffixalong with the culaIlu0Options input struct parameter.
culaIlu0Options
Name Type Description
reordering culaReordering Specifies a reorderingstrategy for the inputmatrix. This optiondefaults toculaNoReordering. Formore information, see theculaReordering section.
Iterative SolversThis section describes the iterative solvers routines availablein the CULA Sparse library.
For algorithmic details regarding the methods detailed in thischapter, we recommend reading the “Krylov SubspaceMethods: Part 1 & 2” chapters from Yousef Saad’s textbook“Iterative Methods for Sparse Linear Systems”.
Conjugate Gradient (CG)
culaStatus cula{storage}Cg{preconditioner}( const culaIterativeConfig* config, const culaCgOptions* solverOpts, {preconditioner options}, int n, int nnz, {storage parameters}, double* x, const double* b, culaIterativeResult* result);
culaDcsrCg culaDcscCg culaDcooCg
L O U ¡ A
M = {L,U,
lower triangularupper triangular
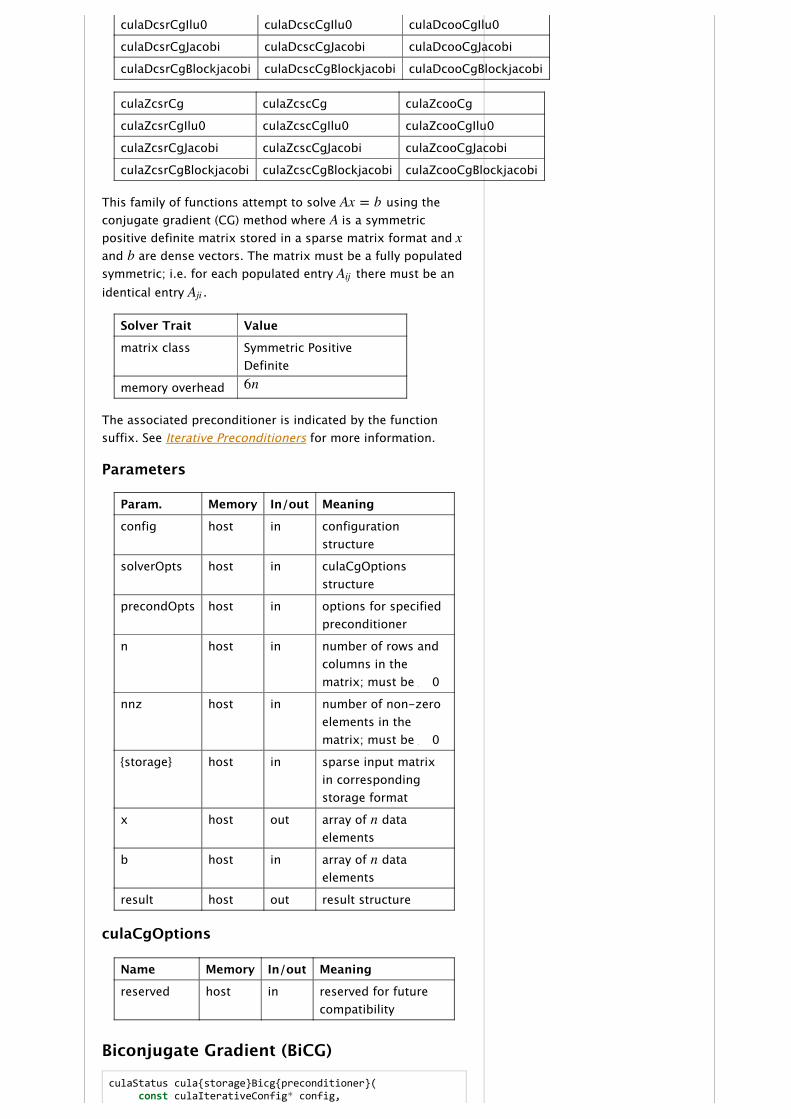
culaDcsrCgIlu0 culaDcscCgIlu0 culaDcooCgIlu0
culaDcsrCgJacobi culaDcscCgJacobi culaDcooCgJacobi
culaDcsrCgBlockjacobi culaDcscCgBlockjacobi culaDcooCgBlockjacobi
culaZcsrCg culaZcscCg culaZcooCg
culaZcsrCgIlu0 culaZcscCgIlu0 culaZcooCgIlu0
culaZcsrCgJacobi culaZcscCgJacobi culaZcooCgJacobi
culaZcsrCgBlockjacobi culaZcscCgBlockjacobi culaZcooCgBlockjacobi
This family of functions attempt to solve using theconjugate gradient (CG) method where is a symmetricpositive definite matrix stored in a sparse matrix format and and are dense vectors. The matrix must be a fully populatedsymmetric; i.e. for each populated entry there must be anidentical entry .
Solver Trait Value
matrix class Symmetric PositiveDefinite
memory overhead
The associated preconditioner is indicated by the functionsuffix. See Iterative Preconditioners for more information.
Parameters
Param. Memory In/out Meaning
config host in configurationstructure
solverOpts host in culaCgOptionsstructure
precondOpts host in options for specifiedpreconditioner
n host in number of rows andcolumns in thematrix; must be 0
nnz host in number of non‑zeroelements in thematrix; must be 0
{storage} host in sparse input matrixin correspondingstorage format
x host out array of dataelements
b host in array of dataelements
result host out result structure
culaCgOptions
Name Memory In/out Meaning
reserved host in reserved for futurecompatibility
Biconjugate Gradient (BiCG)
culaStatus cula{storage}Bicg{preconditioner}( const culaIterativeConfig* config,
Ax = bA
xb
Aij
Aji
6n
¾
¾
n
n
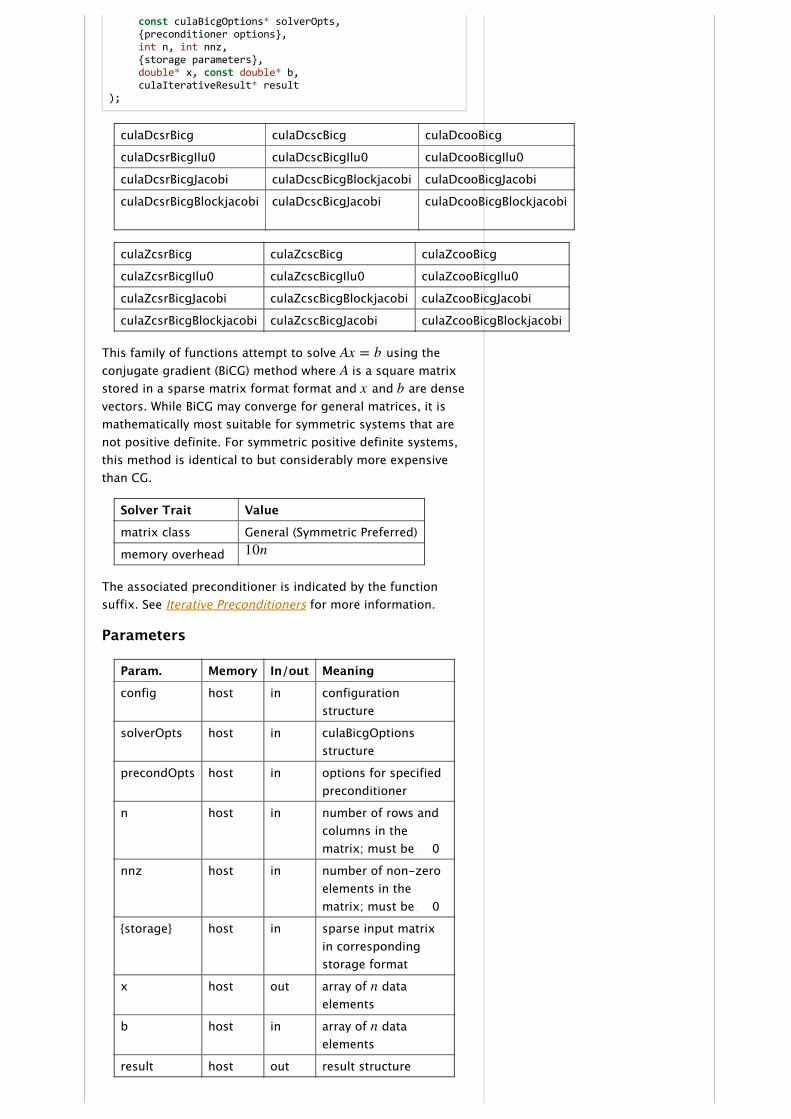
const culaBicgOptions* solverOpts, {preconditioner options}, int n, int nnz, {storage parameters}, double* x, const double* b, culaIterativeResult* result);
culaDcsrBicg culaDcscBicg culaDcooBicg
culaDcsrBicgIlu0 culaDcscBicgIlu0 culaDcooBicgIlu0
culaDcsrBicgJacobi culaDcscBicgBlockjacobi culaDcooBicgJacobi
culaDcsrBicgBlockjacobi culaDcscBicgJacobi culaDcooBicgBlockjacobi
culaZcsrBicg culaZcscBicg culaZcooBicg
culaZcsrBicgIlu0 culaZcscBicgIlu0 culaZcooBicgIlu0
culaZcsrBicgJacobi culaZcscBicgBlockjacobi culaZcooBicgJacobi
culaZcsrBicgBlockjacobi culaZcscBicgJacobi culaZcooBicgBlockjacobi
This family of functions attempt to solve using theconjugate gradient (BiCG) method where is a square matrixstored in a sparse matrix format format and and are densevectors. While BiCG may converge for general matrices, it ismathematically most suitable for symmetric systems that arenot positive definite. For symmetric positive definite systems,this method is identical to but considerably more expensivethan CG.
Solver Trait Value
matrix class General (Symmetric Preferred)
memory overhead
The associated preconditioner is indicated by the functionsuffix. See Iterative Preconditioners for more information.
Parameters
Param. Memory In/out Meaning
config host in configurationstructure
solverOpts host in culaBicgOptionsstructure
precondOpts host in options for specifiedpreconditioner
n host in number of rows andcolumns in thematrix; must be 0
nnz host in number of non‑zeroelements in thematrix; must be 0
{storage} host in sparse input matrixin correspondingstorage format
x host out array of dataelements
b host in array of dataelements
result host out result structure
Ax = bA
x b
10n
¾
¾
n
n

culaBicgOptions
Name Memory In/out Meaning
avoidTranspose host in Avoids repeatedtransposeoperations bycreating atransposed copyof the inputmatrix. May leadto improvedspeeds andaccuracy at theexpense ofmemory andcomputationaloverheads.
Biconjugate Gradient Stabilized(BiCGSTAB)
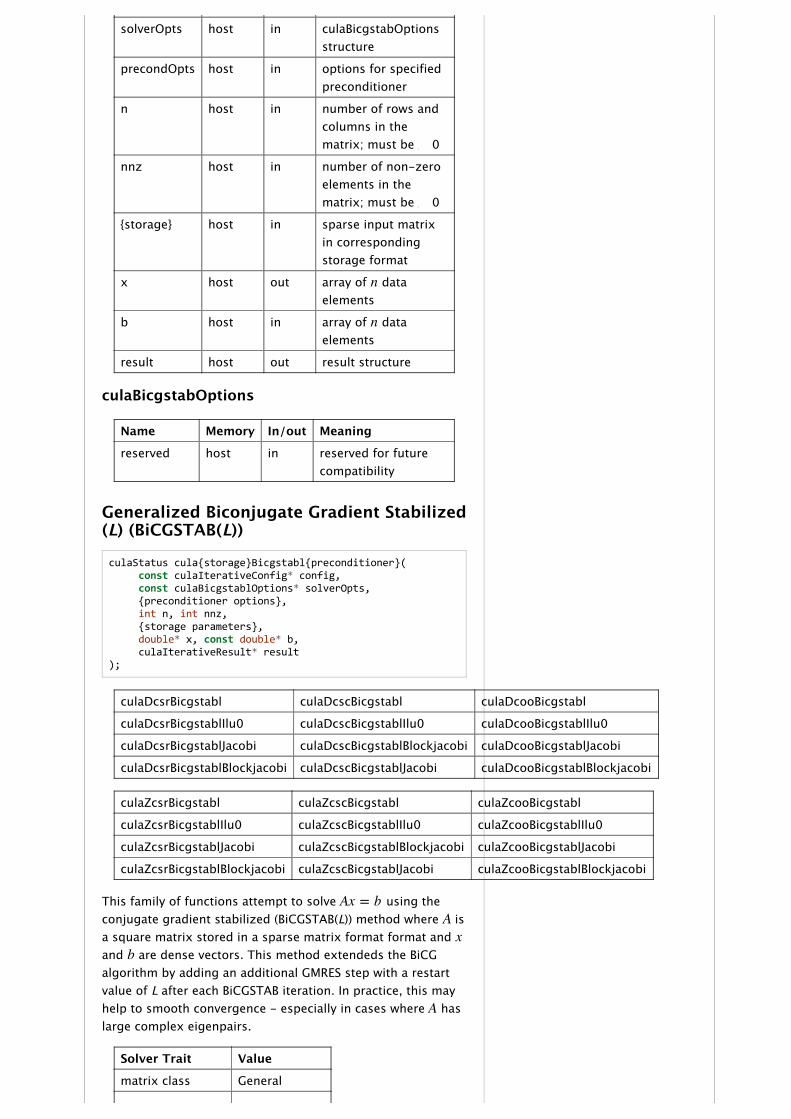
culaStatus cula{storage}Bicgstab{preconditioner}( const culaIterativeConfig* config, const culaBicgstabOptions* solverOpts, {preconditioner options}, int n, int nnz, {storage parameters}, double* x, const double* b, culaIterativeResult* result);
culaDcsrBicgstab culaDcscBicgstab culaDcooBicgstab
culaDcsrBicgstabIlu0 culaDcscBicgstabIlu0 culaDcooBicgstabIlu0
culaDcsrBicgstabJacobi culaDcscBicgstabBlockjacobi culaDcooBicgstabJacobi
culaDcsrBicgstabBlockjacobi culaDcscBicgstabJacobi culaDcooBicgstabBlockjacobi
culaZcsrBicgstab culaZcscBicgstab culaZcooBicgstab
culaZcsrBicgstabIlu0 culaZcscBicgstabIlu0 culaZcooBicgstabIlu0
culaZcsrBicgstabJacobi culaZcscBicgstabBlockjacobi culaZcooBicgstabJacobi
culaZcsrBicgstabBlockjacobi culaZcscBicgstabJacobi culaZcooBicgstabBlockjacobi
This family of functions attempt to solve using theconjugate gradient stabilized (BiCGSTAB) method where is asquare matrix stored in a sparse matrix format format and and are dense vectors. This method was developed to solvenon‑symmetric linear systems while avoiding the irregularconvergence patterns of the Conjugate Gradient Squared (CGS)method.
Solver Trait Value
matrix class General
memory overhead
The associated preconditioner is indicated by the functionsuffix. See Iterative Preconditioners for more information.
Parameters
Param. Memory In/out Meaning
config host in configurationstructure
Ax = bA
xb
10n
solverOpts host in culaBicgstabOptionsstructure
precondOpts host in options for specifiedpreconditioner
n host in number of rows andcolumns in thematrix; must be 0
nnz host in number of non‑zeroelements in thematrix; must be 0
{storage} host in sparse input matrixin correspondingstorage format
x host out array of dataelements
b host in array of dataelements
result host out result structure
culaBicgstabOptions
Name Memory In/out Meaning
reserved host in reserved for futurecompatibility
Generalized Biconjugate Gradient Stabilized(L) (BiCGSTAB(L))
culaStatus cula{storage}Bicgstabl{preconditioner}( const culaIterativeConfig* config, const culaBicgstablOptions* solverOpts, {preconditioner options}, int n, int nnz, {storage parameters}, double* x, const double* b, culaIterativeResult* result);
culaDcsrBicgstabl culaDcscBicgstabl culaDcooBicgstabl
culaDcsrBicgstablIlu0 culaDcscBicgstablIlu0 culaDcooBicgstablIlu0
culaDcsrBicgstablJacobi culaDcscBicgstablBlockjacobi culaDcooBicgstablJacobi
culaDcsrBicgstablBlockjacobi culaDcscBicgstablJacobi culaDcooBicgstablBlockjacobi
culaZcsrBicgstabl culaZcscBicgstabl culaZcooBicgstabl
culaZcsrBicgstablIlu0 culaZcscBicgstablIlu0 culaZcooBicgstablIlu0
culaZcsrBicgstablJacobi culaZcscBicgstablBlockjacobi culaZcooBicgstablJacobi
culaZcsrBicgstablBlockjacobi culaZcscBicgstablJacobi culaZcooBicgstablBlockjacobi
This family of functions attempt to solve using theconjugate gradient stabilized (BiCGSTAB(L)) method where isa square matrix stored in a sparse matrix format format and and are dense vectors. This method extendeds the BiCGalgorithm by adding an additional GMRES step with a restartvalue of L after each BiCGSTAB iteration. In practice, this mayhelp to smooth convergence ‑ especially in cases where haslarge complex eigenpairs.
Solver Trait Value
matrix class General
¾
¾
n
n
Ax = bA
xb
A
n O L + 8n
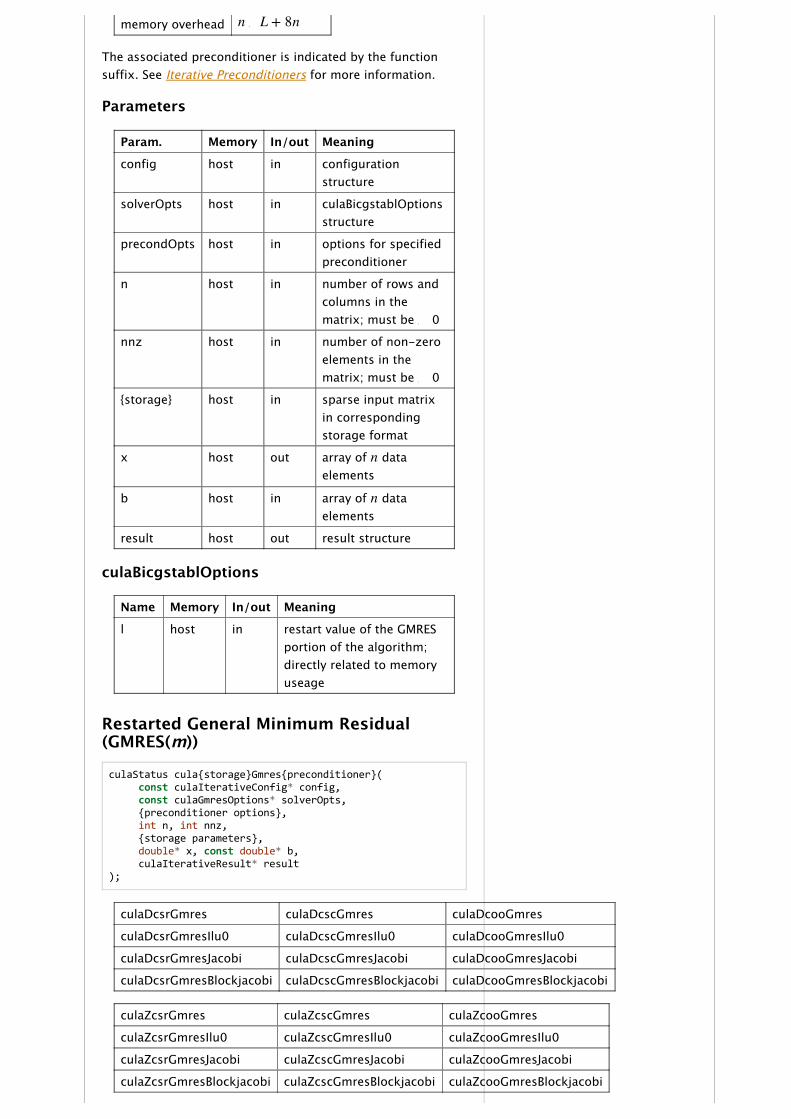
memory overhead
The associated preconditioner is indicated by the functionsuffix. See Iterative Preconditioners for more information.
Parameters
Param. Memory In/out Meaning
config host in configurationstructure
solverOpts host in culaBicgstablOptionsstructure
precondOpts host in options for specifiedpreconditioner
n host in number of rows andcolumns in thematrix; must be 0
nnz host in number of non‑zeroelements in thematrix; must be 0
{storage} host in sparse input matrixin correspondingstorage format
x host out array of dataelements
b host in array of dataelements
result host out result structure
culaBicgstablOptions
Name Memory In/out Meaning
l host in restart value of the GMRESportion of the algorithm;directly related to memoryuseage
Restarted General Minimum Residual(GMRES(m))
culaStatus cula{storage}Gmres{preconditioner}( const culaIterativeConfig* config, const culaGmresOptions* solverOpts, {preconditioner options}, int n, int nnz, {storage parameters}, double* x, const double* b, culaIterativeResult* result);
culaDcsrGmres culaDcscGmres culaDcooGmres
culaDcsrGmresIlu0 culaDcscGmresIlu0 culaDcooGmresIlu0
culaDcsrGmresJacobi culaDcscGmresJacobi culaDcooGmresJacobi
culaDcsrGmresBlockjacobi culaDcscGmresBlockjacobi culaDcooGmresBlockjacobi
culaZcsrGmres culaZcscGmres culaZcooGmres
culaZcsrGmresIlu0 culaZcscGmresIlu0 culaZcooGmresIlu0
culaZcsrGmresJacobi culaZcscGmresJacobi culaZcooGmresJacobi
culaZcsrGmresBlockjacobi culaZcscGmresBlockjacobi culaZcooGmresBlockjacobi
n O L + 8n
¾
¾
n
n
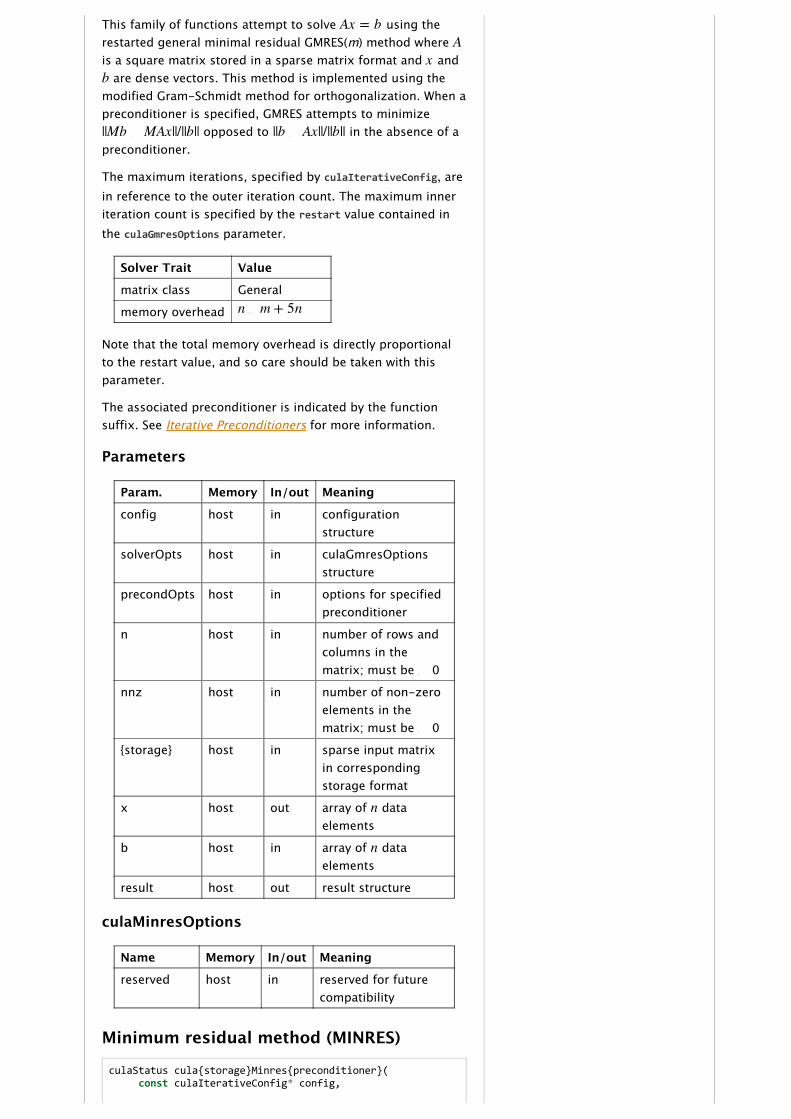
This family of functions attempt to solve using therestarted general minimal residual GMRES(m) method where is a square matrix stored in a sparse matrix format and and
are dense vectors. This method is implemented using themodified Gram‑Schmidt method for orthogonalization. When apreconditioner is specified, GMRES attempts to minimize
opposed to in the absence of apreconditioner.
The maximum iterations, specified by culaIterativeConfig, arein reference to the outer iteration count. The maximum inneriteration count is specified by the restart value contained inthe culaGmresOptions parameter.
Solver Trait Value
matrix class General
memory overhead
Note that the total memory overhead is directly proportionalto the restart value, and so care should be taken with thisparameter.
The associated preconditioner is indicated by the functionsuffix. See Iterative Preconditioners for more information.
Parameters
Param. Memory In/out Meaning
config host in configurationstructure
solverOpts host in culaGmresOptionsstructure
precondOpts host in options for specifiedpreconditioner
n host in number of rows andcolumns in thematrix; must be 0
nnz host in number of non‑zeroelements in thematrix; must be 0
{storage} host in sparse input matrixin correspondingstorage format
x host out array of dataelements
b host in array of dataelements
result host out result structure
culaMinresOptions
Name Memory In/out Meaning
reserved host in reserved for futurecompatibility
Minimum residual method (MINRES)
culaStatus cula{storage}Minres{preconditioner}( const culaIterativeConfig* config,
Ax = bA
xb
||Mb J MAx||/||b|| ||b J Ax||/||b||
n O m + 5n
¾
¾
n
n
const culaMinresOptions* solverOpts, {preconditioner options}, int n, int nnz, {storage parameters}, double* x, const double* b, culaIterativeResult* result);
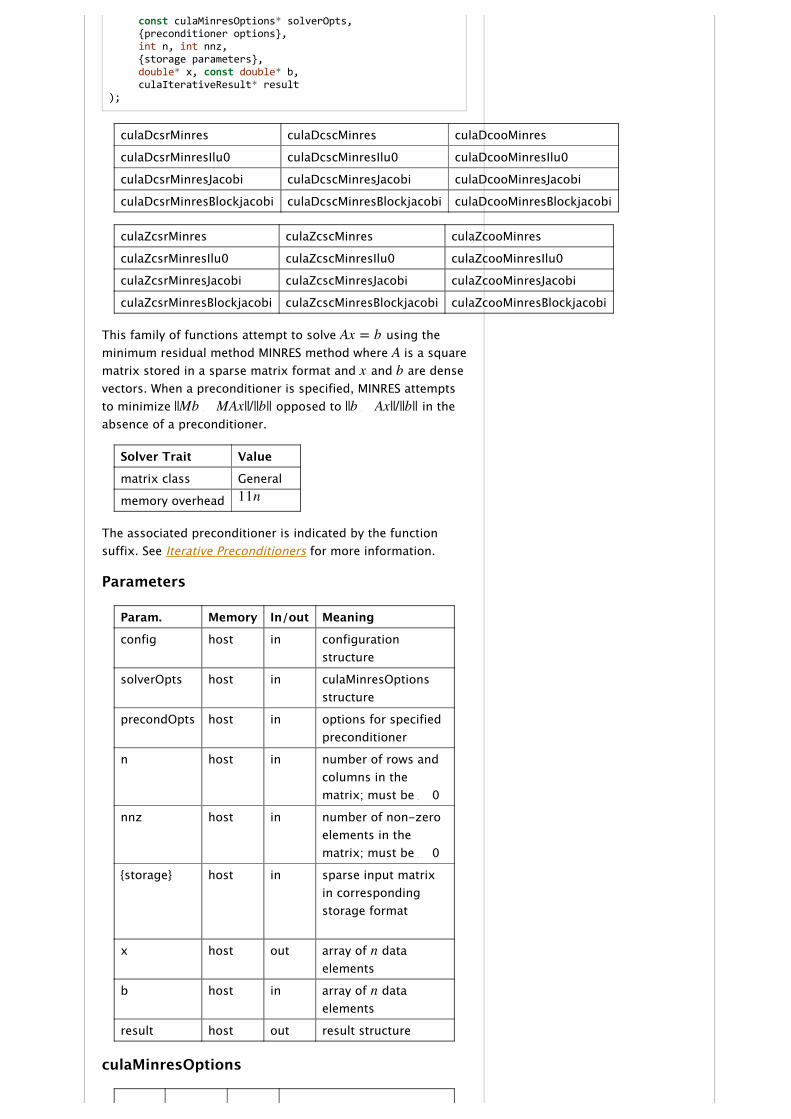
culaDcsrMinres culaDcscMinres culaDcooMinres
culaDcsrMinresIlu0 culaDcscMinresIlu0 culaDcooMinresIlu0
culaDcsrMinresJacobi culaDcscMinresJacobi culaDcooMinresJacobi
culaDcsrMinresBlockjacobi culaDcscMinresBlockjacobi culaDcooMinresBlockjacobi
culaZcsrMinres culaZcscMinres culaZcooMinres
culaZcsrMinresIlu0 culaZcscMinresIlu0 culaZcooMinresIlu0
culaZcsrMinresJacobi culaZcscMinresJacobi culaZcooMinresJacobi
culaZcsrMinresBlockjacobi culaZcscMinresBlockjacobi culaZcooMinresBlockjacobi
This family of functions attempt to solve using theminimum residual method MINRES method where is a squarematrix stored in a sparse matrix format and and are densevectors. When a preconditioner is specified, MINRES attemptsto minimize opposed to in theabsence of a preconditioner.
Solver Trait Value
matrix class General
memory overhead
The associated preconditioner is indicated by the functionsuffix. See Iterative Preconditioners for more information.
Parameters
Param. Memory In/out Meaning
config host in configurationstructure
solverOpts host in culaMinresOptionsstructure
precondOpts host in options for specifiedpreconditioner
n host in number of rows andcolumns in thematrix; must be 0
nnz host in number of non‑zeroelements in thematrix; must be 0
{storage} host in sparse input matrixin correspondingstorage format
x host out array of dataelements
b host in array of dataelements
result host out result structure
culaMinresOptions
Ax = bA
x b
||Mb J MAx||/||b|| ||b J Ax||/||b||
11n
¾
¾
n
n

Name Memory In/out Meaning
restart host in number of inner iterationsat which point thealgorithm restarts; directlyrelated to memory usage
Performance and AccuracyThis chapter outlines many of the performance and accuracyconsiderations pertaining to the CULA Sparse library. Thereare details regarding how to get the most performance out ofyour solvers and provide possible reasons why a particularsolver may be under performing.
Performance Considerations
Double Precision
All of the solvers in CULA Sparse perform calculations indouble precision. While users of the NVIDIA GeForce line maystill see an appreciable speedup, we recommend using theNVIDIA Tesla line of compute cards with greatly improveddouble precision performance.
Since double precision is required, a CUDA device supportingcompute capability 1.3 is needed to use the CULA Sparselibrary. At this time, single precision solvers are excluded.
Problem Size
The modern GPU is optimized to handle large, massivelyparallel problems with a high computation to memory accessratio. As such, small problems with minimal parallelism willperform poorly on the GPU and are much better suited for theCPU where they can reside in cache memory. Typical problemsizes worth GPU‑acceleration are systems with at least 10,000unknowns and at least 30,000 non‑zero elements.
Storage Formats
For storage and performance reasons, the compressed sparserow (CSR) format is preferred as many internal operations havebeen optimized for this format. For other storage formats,CULA Sparse will invoke accelerated conversions routines toconvert to CSR internally. To measure this conversionoverhead, inspect the overhead field of the timing structure inthe culaIterativeResult return structure. These conversionroutines also require an internal buffer of size which forlarge problems may be more memory than is available on theGPU.
Preconditioner Selection
Proper preconditioner selection is necessary for minimizingthe number of iterations required to solve a solution. However,as mentioned in previous chapters, the preconditioning stepdoes add additional work to every iteration. In some cases thisadditional work may end up being a new bottleneck andimproved overall performance may be obtained using apreconditioner that takes more steps to converge, but theoverall runtime is actually lower. As such, we recommendanalyzing multiple preconditioner methods and looking at the
nnz

total runtime as well the number of iterations required.
Accuracy Considerations
Numerical Precision
Iterative methods are typically very sensitive to numericalprecision. Therefore, different implementations of the samealgorithm may take a different number of iterations toconverge to the same solution. This is as expected whendealing with the non‑associative nature of floating pointcomputations.
Relative Residual
Unless otherwise specified, all of CULA Sparse’s iterationcalculations are done with regards to a residual relative to thenorm of the right hand side of the linear system. The definingequation for this is .
API ExampleThis section shows a very simple example of how to use theCULA Sparse API.
#include "culadist/cula_sparse.h"
int main(){ // test data const int n = 8; const int nnz = 8; double a[nnz] = { 1., 2., 3., 4., 5., 6., 7., 8. }; double x[n] = { 1., 1., 1., 1., 1., 1., 1., 1. }; double b[n]; int colInd[nnz] = { 0, 1, 2, 3, 4, 5, 6, 7 }; int rowInd[nnz] = { 0, 1, 2, 3, 4, 5, 6, 7 };
// character buffer used for results and error messages char buf[256];
// status returned by each and every cula routine culaStatus status;
// intialize cula sparse library status = culaSparseInitialize();
// check for initialization error if ( status != culaNoError ) { culaGetErrorInfoString( status, culaGetErrorInfo(), buf, sizeof(buf) ); printf("%s\n", buf); return; }
// configuration structures culaIterativeConfig config; culaBicgOptions solverOpts; culaJacobiOptions precondOpts;
// initialize values status = culaIterativeConfigInit( &config ); status = culaBicgOptionsInit( &solverOpts ); status = culaJacobiOptionsInit( &precondOpts );
// configure specific parameters config.tolerance = 1.e‐6; config.maxIterations = 20; config.indexing = 0; config.debug = 1;
// result structure culaIterativeResult result;
// call bicg with jacobi preconditioner status = culaDcooBicgJacobi( &config, &solverOpts, &precondOpts, n, nnz, a, colInd, rowInd, x, b, &result );
||b J Ax||/||b||
// see if solver failed for a non‐data related reason if ( status != culaNoError && status != culaDataError ) { culaGetErrorInfoString( status, culaGetErrorInfo(), buf, sizeof(buf) ); printf("%s\n", buf); return; }
// print result string culaIterativeResultString( &result, buf, sizeof(buf) ); printf("%s\n", buf);
return;}
Configuring Your EnvironmentThis section describes how to set up CULA Sparse usingcommon tools, such as Microsoft® Visual Studio®, as well ascommand line tools for Linux and Mac OS X.
Microsoft Visual StudioThis section describes how to configure Microsoft VisualStudio to use CULA Sparse. Before following the steps withinthis section, take note of where you installed CULA Sparse (thedefault is C:\Program Files\CULA\S#). To set up Visual Studio,you will need to set both Global‑ and Project‑level settings.Each of these steps is described in the sections below.
Global Settings
When inside Visual Studio, navigate to the menu bar and selectTools > Options. A window will open that offers severaloptions; in this window, navigate to Projects and Solutions >VC++ Directories. From this dialog you will be able toconfigure global executable, include, and library paths, whichwill allow any project that you create to use CULA Sparse.
The table below specifies the recommended settings for thevarious directories that the VC++ Directories dialog makesavailable. When setting up your environment, prepend thepath of your CULA Sparse installation to each of the entries inthe table below. For example, to set the include path for atypical installation, enter C:\Program Files\CULA\include forthe Include Files field.
Option Win32 x64
Executable Files bin bin64
Include Files include include
Library Files lib lib64
With these global settings complete, Visual Studio will be ableto include CULA Sparse files in your application. Before youcan compile and link an application that uses CULA Sparse,however, you will need to set up your project to link CULASparse.
Project Settings
To use CULA Sparse, you must instruct Visual Studio to linkCULA Sparse to your application. To do this, right‑click onyour project and select Properties. From here, navigate toConfiguration Properties > Linker > Input. In the Additional

Dependencies field, enter “cula_core.lib cula_sparse.lib”.
On the Windows platform, CULA Sparse’s libraries aredistributed as a dynamic link library (DLL) (cula_sparse.dll) andan import library (cula_sparse.lib), located in the bin and libdirectories of the CULA Sparse installation, respectively. ByLinking cula_sparse.lib, you are instructing Visual Studio tomake an association between your application and the CULASparse DLL, which will allow your application to use the codethat is contained within the CULA Sparse DLL.
Runtime Path
CULA Sparse is built as a dynamically linked library, and assuch it must be visible to your runtime system. This requiresthat cula_sparse.dll and its supporting dll’s are located in adirectory that is a member of your system’s runtime path. OnWindows, you may do one of several things:
1. Add CULASPARSE_BIN_PATH_32 orCULASPARSE_BIN_PATH_64 to your PATHenvironment variable.
2. Copy cula_sparse.dll and its supporting dll’sto the working directory or your project’sexecutable.
Linux / Mac OS X ‑ Command LineOn a Linux system, a common way of building software is byusing command line tools. This section describes how aproject that is command line driven can be configured to useCULA Sparse.
Configure Environment Variables
The first step in this process is to set up environmentvariables so that your build scripts can infer the location ofCULA Sparse.
On a Linux or Mac OS X system, a simple way to set up CULASparse to use environment variables. For example, on asystem that uses the bourne (sh) or bash shells, add thefollowing lines to an appropriate shell configuration file (e.g..bashrc).
export CULASPARSE_ROOT=/usr/local/culasparseexport CULASPARSE_INC_PATH=$CULASPARSE_ROOT/includeexport CULASPARSE_BIN_PATH_32=$CULASPARSE_ROOT/binexport CULASPARSE_BIN_PATH_64=$CULASPARSE_ROOT/bin64export CULASPARSE_LIB_PATH_32=$CULASPARSE_ROOT/libexport CULASPARSE_LIB_PATH_64=$CULASPARSE_ROOT/lib64
(where CULASPARSE_ROOT is customized to the location youchose to install CULA Sparse)
After setting environment variables, you can now configureyour build scripts to use CULA Sparse.
Note
You may need to reload your shell before you can use thesevariables.
Configure Project Paths
This section describes how to set up the gcc compiler to

include CULA Sparse in your application. When compiling anapplication, you will typically need to add the followingarguments to your compiler’s argument list:
Item Command
Include Path ‐I$CULASPARSE_INC_PATH
Library Path (32‑bitarch)
‐L$CULASPARSE_LIB_PATH_32
Library Path (64‑bitarch)
‐L$CULASPARSE_LIB_PATH_64
Libraries to Linkagainst
‐lcula_core ‐lcula_sparse
For a 32‑bit compile:
gcc ... ‐I$CULASPARSE_INC_PATH ‐L$CULASPARSE_LIB_PATH_32 ... ‐lcula_core ‐lcula_sparse ‐lcublas ‐lcudart ‐lcusparse ...
For a 64‑bit compile (not applicable to Mac OS X):
gcc ... ‐I$CULASPARSE_INC_PATH ‐L$CULASPARSE_LIB_PATH_64 ... ‐lcula_core ‐lcula_sparse ‐lcublas ‐lcudart ‐lcusparse ...
Runtime Path
CULA Sparse is built as a shared library, and as such it mustbe visible to your runtime system. This requires that CULASparse’s shared libraries are located in a directory that is amember of your system’s runtime library path. On Linux, youmay do one of several things:
1. Add CULASPARSE_LIB_PATH_32 orCULASPARSE_LIB_PATH_64 to yourLD_LIBRARY_PATH environment variable.
2. Edit your system’s ld.so.conf (found in /etc)to include either CULASPARSE_LIB_PATH_32or CULASPARSE_LIB_PATH_64.
On the Mac OS X platform, you must edit theDYLD_LIBRARY_PATH environment variable for your shell, asabove.
Checking That Libraries are LinkedCorrectly
#include <cula.h>
int MeetsMinimumCulaRequirements(){ int cudaMinimumVersion = culaGetCudaMinimumVersion(); int cudaRuntimeVersion = culaGetCudaRuntimeVersion(); int cudaDriverVersion = culaGetCudaDriverVersion(); int cublasMinimumVersion = culaGetCublasMinimumVersion(); int cublasRuntimeVersion = culaGetCublasRuntimeVersion(); int cusparseMinimumVersion = culaGetCusparseMinimumVersion(); int cusparseRuntimeVersion = culaGetCusparseRuntimeVersion();
if(cudaRuntimeVersion < cudaMinimumVersion) { printf("CUDA runtime version is insufficient; " "version %d or greater is required\n", cudaMinimumVersion); return 0; }
if(cudaDriverVersion < cudaMinimumVersion) { printf("CUDA driver version is insufficient; " "version %d or greater is required\n", cudaMinimumVersion);
return 0; }
if(cublasRuntimeVersion < cublasMinimumVersion) { printf("CUBLAS runtime version is insufficient; " "version %d or greater is required\n", cublasMinimumVersion); return 0; }
if(cusparseRuntimeVersion < cusparseMinimumVersion) { printf("CUSPARSE runtime version is insufficient; " "version %d or greater is required\n", cusparseMinimumVersion); return 0; }
return 1;}
Common ErrorsThis chapter provides solutions to errors commonlyencountered when using the CULA Sparse library.
As a general note, whenever an error is encountered, considerenabling debugging mode. The configuration parameter offersa debugging flag that, when set, causes CULA Sparse toperform many more checks than it would normally. Thesechecks can be computationally expensive and so are notenabled on a default run. These checks may highlight theissue for you directly, saving you from having to do more timeconsuming debugging. Debugging output will occur as eithera culaStatus return code (i.e., a malformed matrix may beprinted to the console, or returned via the resultculaBadStorageFormat or via the result structure.
Argument ErrorProblem
A function’s culaStatus return code is equal toculaArgumentError.
Description
This error indicates that one of your parameters to yourfunction is in error. The culaGetErrorInfo function will reportwhich particular parameter is in error. Typical errors includeinvalid sizes or null pointers.
For a readable string that reports this information, use theculaGetErrorInfoString() function. Whereas normal mode willnot indicate why the argument is in error, debugging modemay report more information.
Solution
Check the noted parameter against the routine’sdocumentation to make sure the input is valid.
Malformed MatrixProblem
A function’s culaStatus return code is equal toculaBadStorageFormat.
Description

This error indicates that the set of inputs describing a sparsematrix is somehow malformed. This error code is principallyencountered with the configuration structure has activated the“debug” field by setting it to 1. For a readable string thatreports this information, use the culaGetErrorInfoString()function. Whereas normal mode will not indicate why theargument is in error, debugging mode may report moreinformation.
There are many conditions which can trigger this, of which afew common examples are listed below.
For 0‑based indexing, any entry in the row or columnvalues is less than zero or greater than For 1‑based indexing, any entry in the row or columnvalues is less than one or greater than Duplicated indicesEntries in an Index array are not ascendingThe element of an Index array is not set properly;ie it does not account for all elements
There are many others, and the above may not be true for allmatrix types.
Solution
Check the matrix data against the documentation for matrixstorage types to ensure that it meets any necessary criteria.
Data ErrorsUpon a culaDataError return code, it is possible to obtain moreinformation by examining the culaIterativeFlag within theculaIterativeResult structure. This will indicate a problem withof the following errors:
Maximum Iterations Reached
Problem
A function’s culaStatus return code is equal to culaDataErrorand the culaIterativeFlag is indicating culaMaxItReached.
Description
This error indicates that the solver has reached a maximumnumber of iterations before the an answer within the giventolerance was reached.
Solution
Increase the iteration count or lower the desired tolerance.Also, the given solver and/or preconditioner might not beappropriate for your data. If this is the case, try a differentsolver and/or preconditioner. It is also possible that the inputmatrix may not be solvable with any of the methods availablein CULA Sparse.
This might also be a desirable outcome in the case that theuser is seeking the best possible answer within a budgetednumber of iterations. In this case, the “error” can be safelyignored.
Preconditioner Failure
Problem
n J 1
n
n + 1nnz

A function’s culaStatus return code is equal to culaDataErrorand the culaIterativeFlag is indicatingculaPreconditionerFailed.
Description
The preconditioner failed to generate and no iterations wereattempted. This error is usually specific to differentpreconditioner methods but typically indicates that there iseither bad data (i.e., malformed matrix) or a singular matrix.See the documentation for the preconditioner used, as it mayspecify certain conditions which must be met.
Solution
More information can be obtained through theculaIterativeResultString() function. In many cases the inputmatrix is singular and factorization methods such as ILU0 arenot appropriate. In this case, try a different preconditioner andcheck that the structure of your matrix is correct.
Stagnation
Problem
A function’s culaStatus return code is equal to culaDataErrorand the culaIterativeFlag is indicating culaStagnation.
Description
The selected iterative solver has stagnated by calculating thesame residual for multiple iterations in a row. The solver hasexited early because a better solution cannot be calculated.
Solution
A different iterative solver and/or preconditioner may benecessary. It is also possible that the input matrix may not besolvable with any of the methods available in CULA Sparse.
It is implicit when this error is issued that the current residualstill exceeds the specified tolerance, but the result may still beusable if the user is looking only for a “best effort” solution. Inthat case, this “error” can be disregarded.
Scalar Out of Range
Problem
A function’s culaStatus return code is equal to culaDataErrorand the culaIterativeFlag is indicating culaScalarOutOfRange.
Description
The selected iterative solver has encountered an invalidfloating point value during calculations. It is possible themethod has broken down and isn’t able to solve the providedlinear system.
Solution
Therefore, a different iterative solver and/or preconditionermay be necessary. It is also possible that the input matrix maynot be solvable with any of the methods available in CULASparse. Also, it is possible the input matrix has improperlyformed data.
Unknown Iteration Error
Problem
A function’s culaStatus return code is equal to culaDataErrorand the culaIterativeFlag is indicatingculaUnknownIterationError.
Description
The selected iterative solver has encountered an unknownerror.
Solution
This error is unexpected and should be reported the CULASparse development team. Please provide the full output ofculaIterativeResultString() and culaIterativeConfigString().
Runtime ErrorProblem
A function’s culaStatus return code is equal toculaRuntimeError.
Description
An error associated with the CUDA runtime library hasoccurred. This error is commonly seen when trying to pass adevice pointer into a function that is expected a host pointeror vise‑versa.
Solution
Make sure device pointers aren’t being used in a host functionor vise‑versa.
Initialization ErrorProblem
A function’s culaStatus return code is equal toculaNotInitialized.
Description
This error occurs when the CULA Sparse library has not yetbeen initialized.
Solution
Call culaSparseInitialize() prior to any other API calls.Exceptions include device functions and helper routines.
No Hardware ErrorProblem
A function’s culaStatus return code is equal to culaNoHardware.
Description
No CUDA capable device was detected in the system.
Solution
Be sure that your system has a CUDA capable NVIDIA GPUdevice; a full list of CUDA GPUs can be obtained throughNVIDIA’s webpage: http://developer.nvidia.com/cuda‑gpus
Insufficient Runtime Error
Problem
A function’s culaStatus return code is equal toculaInsufficientRuntime.
Description
When explicitly mixing CUDA and CULA functionality, theCUDA runtime must be at least equal to the CUDA runtimeused to build CULA.
Solution
Upgrade your CUDA install to the version that CULA has beenbuilt against. This is typically indicated immediately after theCULA version. If upgrading CUDA is not possible, select anolder CULA install with an appropriate CUDA runtime.
Insufficient Compute Capability ErrorProblem
A function’s culaStatus return code is equal toculaInsufficientComputeCapability.
Description
The CULA Sparse library requires a minimum CUDA ComputeCapability of 1.3 for double precision.
Solution
Be sure that your system has a CUDA device with at leastCompute Capability 1.1; a full list of CUDA GPUs can beobtained through NVIDIA’s webpage:http://developer.nvidia.com/cuda‑gpus
Insufficient Memory ErrorProblem
A function’s culaStatus return code is equal toculaInsufficientMemory.
Description
Insufficient GPU memory was available to complete therequested operation. This includes storage for the input data,output data, and intermediates required by the solver.
Solution
Try another solver and/or preconditioner with a lower memoryrequirement. See each routine for details on how muchmemory is required to store the intermediate values.
Support OptionsIf none of the entries in the Common Errors chapter solve yourissue, you can seek technical support.
EM Photonics provides a user forum athttp://www.culatools.com/forums at which you can seek help.Additionally, if your license level provides direct support, youmay contact us directly.
When reporting a problem, make sure to include the followinginformation:
System InformationCULA VersionVersion of NVIDIA® CUDA Toolkit installed,if anyProblem Description (with code if applicable)
Matrix Submission GuidelinesOccasionally you may need to send us your sparse matrix sothat we can work with it directly. EM Photonics accepts twodifferent sparse matrix formats:
Matlab sparse matrices (.mat)Matrix‑market format (.mtx)
Matlab’s sparse matrices are stored in .mat files. Matlabmatrices can be saved with the ‘save’ command or by selectinga workspace variable and selecting ‘Save As’.
Matrix‑market formats are discussed here:http://math.nist.gov/MatrixMarket/formats.html . This sitecontains routines for several languages for reading and writingto these file types.
For easy transfer to EM Photonics, please compress the matrixusing one of .zip or .tar.gz compression methods.
Routine Selection FlowchartsSelecting the best sparse iterative solver and preconditioner isoften a difficult decision. Very rarely can one simply knowwhich combination will converge quickest to find a solutionwithin the given constraints. Often the best answer requiresknowledge pertaining to the structure of the matrix and theproperties it exhibits. To help aid in the selection of a solverand preconditioner, we have constructed two flow charts tohelp gauge which solver and preconditioner might work best.Again, since there is no correct answer for any given system,we encourage users to experiment with different solvers,preconditioners, and options. These flowcharts are simplydesigned to give suggestions, and not absolute answers.
Solver Selection Flowchart
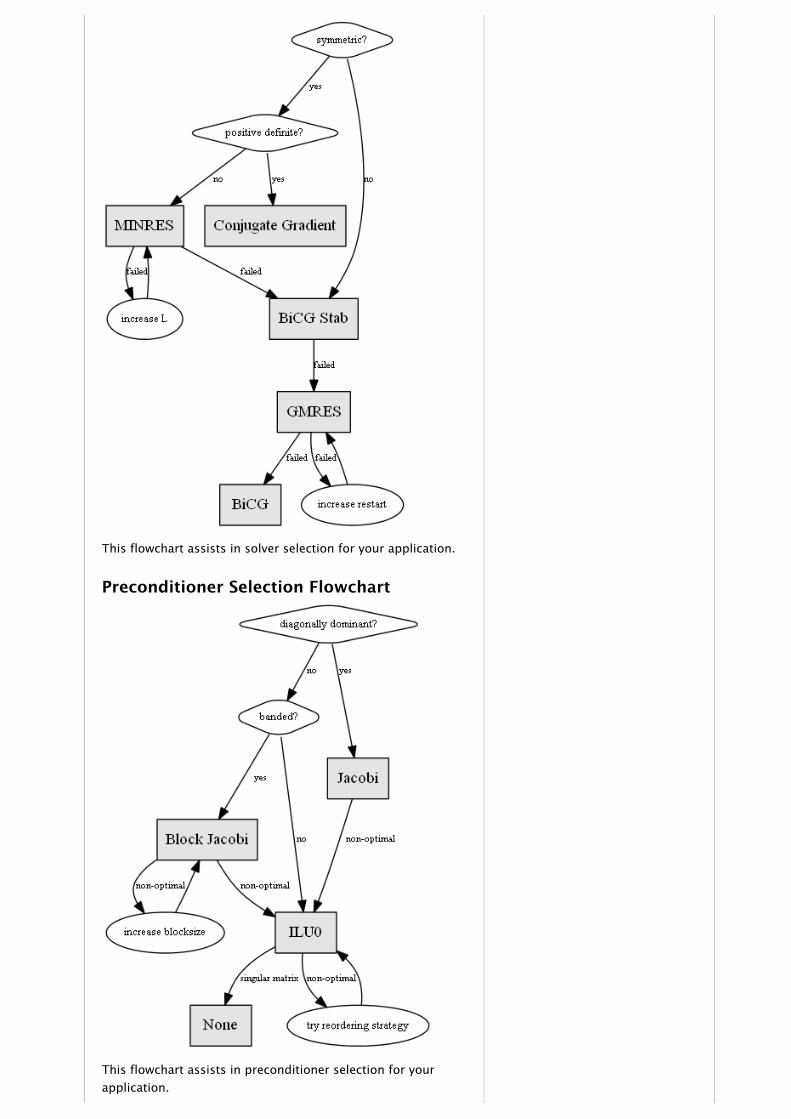
This flowchart assists in solver selection for your application.
Preconditioner Selection Flowchart
This flowchart assists in preconditioner selection for yourapplication.

Changelog
Release S4 CUDA 5.0 (October 16, 2012)Feature: CUDA runtime upgraded to 5.0Feature: K20 support
Release S3 CUDA 4.2 (August 14, 2012)Announcement: All packages are now “universal” andcontain both 32‑bit and 64‑bit binariesFeature: CUDA runtime upgraded to 4.2Feature: Kepler supportChanged: Fortran module is now located in “include”
Release S2 CUDA 4.1 (January 30, 2012)Feature: CUDA runtime upgraded to version 4.1Improved: Stability of COO and CSC interfacesFixed: Now shipping all dependencies required by OSXsystems
Release S1 CUDA 4.0 (November 2, 2011)Feature: Improved speeds for all solversFeature: Matrix reordering option; can lead to large perfgains for ILUFeature: MINRES solverFeature: Fully compatible with CULA R13 and aboveFeature: Option to disable stagnation checking for morespeedFeature: Added iterativeBenchmark example forevaluating the performance of different solvers andoptionsImproved: Result printout will show if useBestAnswerwas invokedChanged: Header renamed to cula_sparse.h; transitionalheader availableNotice: Integrated LGPL COLAMD package; see src folderand license
Release S1 Beta 2 CUDA 4.0 (September 27,2011)
Feature: BiCGSTAB solverFeature: BiCGSTAB(L) solverFeature: Complex (Z) data types available for all solversFeature: Fortran module addedFeature: Configuration parameter to return bestexperienced solutionFeature: Maximum runtime configuration parameterFeature: New example for Fortran interfaceFeature: New example for MatrixMarket dataChanged: Must link two libraries now (cula_sparse andcula_core)
Release S1 Beta 1 CUDA 4.0 (August 24,2011)
Feature: Cg, BiCg, and GMRES solvers

index
Feature: CSC, CSR, COO storage formatsFeature: Jacobi, Block Jacobi, ILU0 preconditionersFeature: Double precision onlyFeature: Support for all standard CUDA platforms; Linux32/64, Win 32/64, OSX
© Copyright 2009‑2012, EM Photonics, Inc.. Created using Sphinx 1.0.7.











![Vs4 review, 2008[1]](https://static.fdocuments.in/doc/165x107/54b9ed8e4a79591b6a8b45bc/vs4-review-20081.jpg)





