

CUDA for High Performance Computing · CUDA for High Performance Computing Massimiliano Fatica...
40
Transcript of CUDA for High Performance Computing · CUDA for High Performance Computing Massimiliano Fatica...

2
Outline
GPU architecture
CUDA
Applications overview
Linpack on heterogeneous cluster

3
GPU Performance History
• GPUs are massively multithreaded many-core chips• Hundreds of cores, thousands of concurrent threads
• High memory bandwidth ( up to 140 GB/s )
• Huge economies of scale
• Still on aggressive performance growth

4
GPU architecture

5
Parallel Computing Architecture of the GPU
Throughput architecture
Thousands of threads
Hardware managed threads
Scalar SIMT
Local 16k shared memory
Double precisionS
ha
red
Me
mo
ry
Sh
are
d M
em
ory
Sh
are
d M
em
ory

6
CUDA Computing with Tesla T10240 SP processors at 1.44 GHz: 1 TFLOPS peak
30 DP processors at 1.44Ghz: 86 GFLOPS peak
128 threads per processor: 30,720 threads total
Tesla T10
Bridge System Memory
Work Distribution
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I -C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C -C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C- C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C -C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C -C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C- C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I -C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I -C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C -C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I -C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C -C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
DRAM
ROP L2
DRAM
ROP L2
DRAM
ROP L2
DRAM
ROP L2
DRAM
ROP L 2
DRAM
ROP L 2
DRAM
ROP L2
DRAM
ROP L2
Host CPU
Interconnection Network
SM
SP
DP
SP
SP SP
SP SP
SP SP
I-Cache
MT Issue
C-Cache
SFU SFU
SharedMemory

7
Double Precision
Special Function Unit (SFU)
TP Array Shared Memory
Tesla T10
240 SP thread processors:
30 DP thread processors
Full scalar processor
IEEE 754 double precisionfloating point
Thread Processor (TP)
FP/Int
Multi-banked Register File
SpcOpsALUs
Thread Processor Array (TPA)

8
Double Precision Floating PointNVIDIA GPU
Precision IEEE 754
Rounding modes for FADD and FMUL All 4 IEEE, round to nearest, zero, inf, -inf
Denormal handling Full speed
NaN support Yes
Overflow and Infinity support Yes
Flags No
FMA Yes
Square root Software with low-latency FMA-based convergence
Division Software with low-latency FMA-based convergence
Reciprocal estimate accuracy 24 bit
Reciprocal sqrt estimate accuracy 23 bit
log2(x) and 2^x estimates accuracy 23 bit

9
T10P
G80
DNA Sequence AlignmentDNA Sequence Alignment Dynamics of Black holesDynamics of Black holes
G80
T10P
Cholesky Cholesky FactorizationFactorization LB Flow LightingLB Flow Lighting Ray TracingRay Tracing
Reverse Time MigrationReverse Time Migration
Doubling Performance With The T10P
Video ApplicationVideo Application

10
CUDA

11
CUDA is C for Parallel Processors
CUDA is industry-standard C
Write a program for one thread
Instantiate it on many parallel threads
Familiar programming model and language
CUDA is a scalable parallel programming model
Program runs on any number of processors without recompiling

12
GPU Sizes Require Scalability
GPU
Interconnection Network
SMC
Geometry Controller
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C -Cache
SFU SFU
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C-Cache
SFU SFU
Texture Unit
Tex L1
SMC
Geometry Controller
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C -Cache
SFU SFU
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C-Cache
SFU SFU
Texture Unit
Tex L1
SMC
Geometry Controller
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C -Cache
SFU SFU
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C-Cache
SFU SFU
Texture Unit
Tex L1
SMC
Geometry Controller
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C -Cache
SFU SFU
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C-Cache
SFU SFU
Texture Unit
Tex L1
SMC
Geometry Controller
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C -Cache
SFU SFU
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C-Cache
SFU SFU
Texture Unit
Tex L1
SMC
Geometry Controller
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C -Cache
SFU SFU
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C-Cache
SFU SFU
Texture Unit
Tex L1
SMC
Geometry Controller
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C -Cache
SFU SFU
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C-Cache
SFU SFU
Texture Unit
Tex L1
SMC
Geometry Controller
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C -Cache
SFU SFU
SP
SharedM emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C-Cache
SFU SFU
Texture Unit
Tex L1
DRAM
ROP L2
DRAM
ROP L2
DRAM
ROP L 2
DRAM
ROP L2
DRAM
ROP L2
DRAM
ROP L2
Bridge System Memory
Work Distribution
Host CPU
SM
SP
SharedMemory
SP
SP SP
SP SP
SP SP
I-Cache
MT Issue
C-Cache
SFU SFU
128 SP Cores
GPU
Interconnection Network
SMC
Geometry Controller
SP
Shared
M emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C-Cache
SFU SFU
SP
Shared
M emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C- Cache
SFU SFU
Texture Unit
Tex L 1
SMC
Geometry Controller
SP
Shared
M emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C-Cache
SFU SFU
SP
Shared
M emory
SP
SP SP
SP SP
SP SP
I-Cache
M T Issue
C-Cache
SFU SFU
Texture Unit
Tex L 1
DRAM
ROP L2
DRAM
ROP L2
Bridge Memory
Work Distribution
Host CPU
SM
SP
SharedMemory
SP
SP SP
SP SP
SP SP
I-Cache
MT Issue
C-Cache
SFU SFU
32 SPCores
GPU
Bridge System Memory
Work Distribution
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I -C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C -C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C- C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C -C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C -C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C- C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I -C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I -C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C -C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
`
SM C
` `
SP
D P
SP
SP SP
SP SP
SP SP
I -C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
Textur e U nit
Tex L 1
SP
D P
SP
SP SP
SP SP
SP SP
I - C ache
M T Issue
C -C ache
SFU SFU
Shar ed
M em or y
SP
D P
SP
SP SP
SP SP
SP SP
I- C ache
M T Issue
C - C ache
SFU SFU
Shar ed
M em or y
DRAM
ROP L2
DRAM
ROP L2
DRAM
ROP L2
DRAM
ROP L 2
DRAM
ROP L2
DRAM
ROP L2
DRAM
ROP L 2
DRAM
ROP L2
Host CPU
Interconnection Network
SM
SP
DP
SP
SP SP
SP SP
SP SP
I-Cache
MT Issue
C-Cache
SFU SFU
SharedMemory
240 SP Cores

13
The Key to Computing on the GPU
Hardware Thread Management
Thousands of lightweight concurrent threads
No switching overhead
Hide instruction and memory latency
Shared memory
User-managed data cache
Thread communication / cooperation within blocks
Random access to global memory
Any thread can read/write any location(s)

14
CUDA Uses Extensive Multithreading
CUDA threads express fine-grained data parallelismMap threads to GPU threadsVirtualize the processorsYou must rethink your algorithms to be aggressively parallel
CUDA thread blocks express coarse-grained parallelismMap blocks to GPU thread arraysScale transparently to any number of processors
GPUs execute thousands of lightweight threadsOne DX10 graphics thread computes one pixel fragmentOne CUDA thread computes one result (or several results)Provide hardware multithreading & zero-overhead scheduling

15
Example: Serial DAXPY routine
Serial program: compute y = ! x + y with a loop
void daxpy_serial(int n, double a, double *x, double *y){ for(int i = 0; i<n; ++i) y[i] = a*x[i] + y[i];}
Serial execution: call a function
daxpy_serial(n, 2.0, x, y);

16
Example: Parallel DAXPY routine
Parallel execution: launch a kernel
uint size = 256; // threads per blockuint blocks = (n + size-1) / size; // blocks needed
daxpy_parallel<<<blocks, size>>>(n, 2.0, x, y);
Parallel program: compute with 1 thread per element
__global__void daxpy_parallel(int n, double a, double *x, double *y){ int i = blockIdx.x*blockDim.x + threadIdx.x;
if( i<n ) y[i] = a*x[i] + y[i];}

17
Simple “C” Description For Parallelism
void daxpy_serial(int n, double a, double *x, double *y)
{
for (int i = 0; i < n; ++i)
y[i] = a*x[i] + y[i];
}
// Invoke serial DAXPY kernel
daxpy_serial(n, 2.0, x, y);
__global__ void daxpy_parallel(int n, double a, double *x, double *y)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i];
}
// Invoke parallel DAXPY kernel with 256 threads/block
int nblocks = (n + 255) / 256;
daxpy_parallel<<<nblocks, 256>>>(n, 2.0, x, y);
Standard C Code
Parallel C Code

18
CUDA Computing Sweet Spots
Parallel Applications :
High arithmetic intensity:
Dense linear algebra, PDEs, n-body, finite difference, …
High bandwidth:Sparse linear algebra, sequencing (virus scanning, genomics), sorting, …
Visual computing:Graphics, image processing, tomography, machine vision, …

19
Pervasive Parallel Computing with CUDA
CUDA brings data-parallel computing to the massesOver 100 M CUDA-capable GPUs deployed since Nov 2006
Wide developer acceptanceDownload CUDA from www.nvidia.com/cuda
Over 150K CUDA developer downloads
A GPU “developer kit” costs ~$200 for 500 GFLOPS
Data-parallel supercomputers are everywhere!CUDA makes this power readily accessible
Enables rapid innovations in data-parallel computing
Parallel computing rides the commodity technology wave

20
Libraries
!"##$ !"%&'( !")**
CUDA Compiler
+
CUDA Tools
),-"..,/000*/123,/
System
*+45,0!6/789
Application SoftwareIndustry Standard C Language
4 cores
21
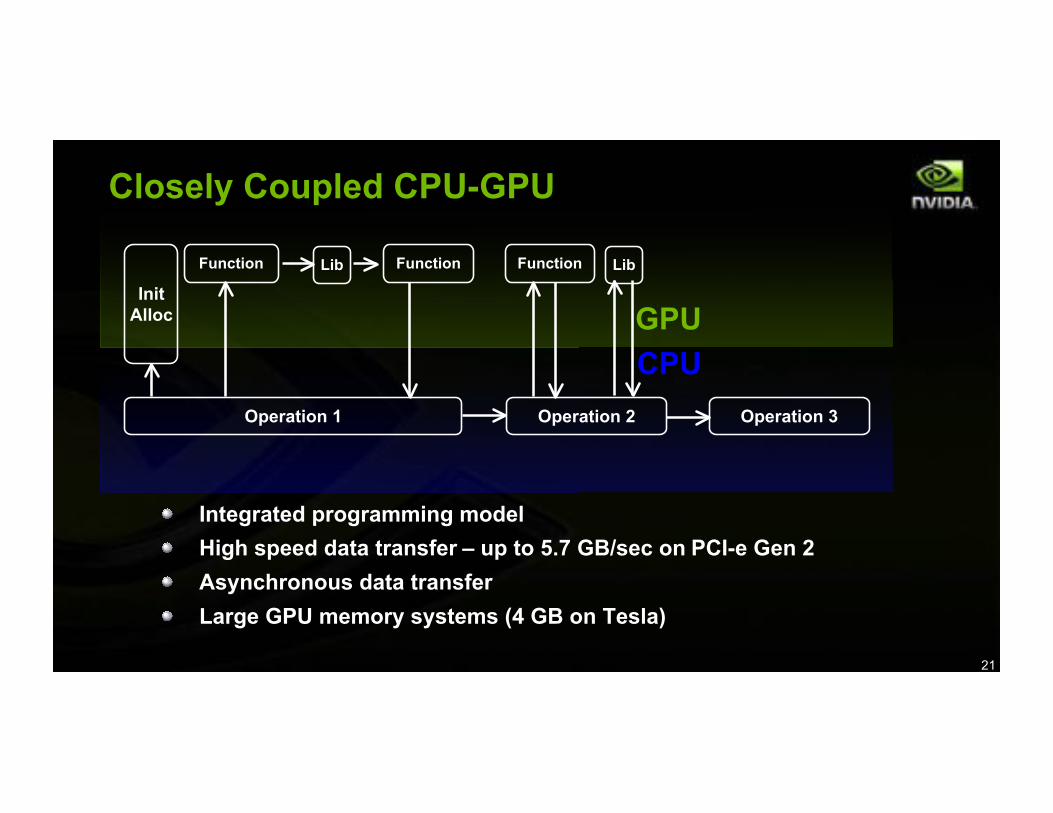
Closely Coupled CPU-GPU
Operation 1 Operation 2 Operation 3
InitAlloc
Function Lib LibFunction Function
CPU
GPU
Integrated programming model
High speed data transfer – up to 5.7 GB/sec on PCI-e Gen 2
Asynchronous data transfer
Large GPU memory systems (4 GB on Tesla)

22
Compiling CUDA
Target code
VirtualVirtual
PhysicalPhysical
NVCC CPU Code
PTX Code
PTX to TargetCompiler
G80 … GTX
C CUDAApplication

23
What’s Next for CUDA
FortranFortran Multiple Multiple GPUsGPUs
LinkerLinkerDebuggerDebugger ProfilerProfiler
C++C++

24
Applications

25
CUDA Zone: www.nvidia.com/cuda
Resources, examples, and pointers for CUDA developers

26
Linear Algebra
Several groups working on linear algebra:
•MAGMA: Matrix Algebra on GPU and Multicore Architecture ( Dongarra and Demmel)
•Mixed precision iterative refinement ( LU Dongarra; multigrid Goddeke)
•GPU VISPL (Vector Image Signal Processing Library) from GeorgiaTech
•Concurrent Number Cruncher (INRIA): Jacobi-preconditioned Conjugate Gradient
•FLAME library at UT Austin
•……
•LU, Cholesky, QR (Volkov) , Kyrlov methods (CG, GMRES) , multigrid

27
Folding@home Performance Comparison
QuickTime™ and a decompressor
are needed to see this picture.
F@H kernel based on GROMACS code

28
Lattice Boltzmann
1000 iterations on a 256x128x128 domain
Cluster with 8 GPUs: 7.5 sec
Blue Gene/L 512 nodes: 21 sec
10000 iterations on irregular 1057x692x1446 domain
with 4M fluid nodes
955 MLUPS42 s8 C1060
252 MLUPS159 s2 C1060
53 MLUPS760 s1 C870
Blood flow pattern in a human coronary artery, Bernaschi et al.

29
Oil and Gas: Migration Codes
“Based on the benchmarks of the current prototype
[128 node GPU cluster], this code should outperform
our current 4000-CPU cluster”
Leading global independent energy company

30
“Homemade” Supercomputer Revolution
FASTRA
8 GPUs in a Desktop
CalcUA
256 Nodes (512 cores)
http://fastra.ua.ac.be/en/index.html

31
Financial Case StudyA typical complex derivative:
Basket Equity-Linked Structured Note.
SciFinance automatically generates
the parallelized source code using
the quant’s description. Runs 34x times faster with one
GPU and 56X on two GPU.
All timings on a Dell XPS 720 with Intel Quad-Core 2.6GHz CPU + NVIDIA GeForce 8800GTX GPUs.
Std. Deviation ofPV
Serial
(sec)
1 GPU
(sec)
2 GPU
(sec)
0.02% 43.3 1.27
X 34
0.77
X 56
(*Basket Equity-Linked Structured Note - Heston SV model*)
MonteCarlo; Sobol; CUDA;
SDE[delta[S] = (r-q) S delta[t] + Sqrt[v] S dW1;
delta[v] = kappa(theta-v) delta[t] + sigma Sqrt[v] dW2];
StdWiener[{dW1,dW2}];
Discretize[QuadraticExponential];
Initial[S=S0; v=v0; HasRedeemed=0; AccruedBonus=0];
Payoff[if[HasRedeemed=True,
EarlyPayout,
if[Sum[KI]>=Trigger, Min[S/SRef], 1 + MaturityCoupon]]];
32
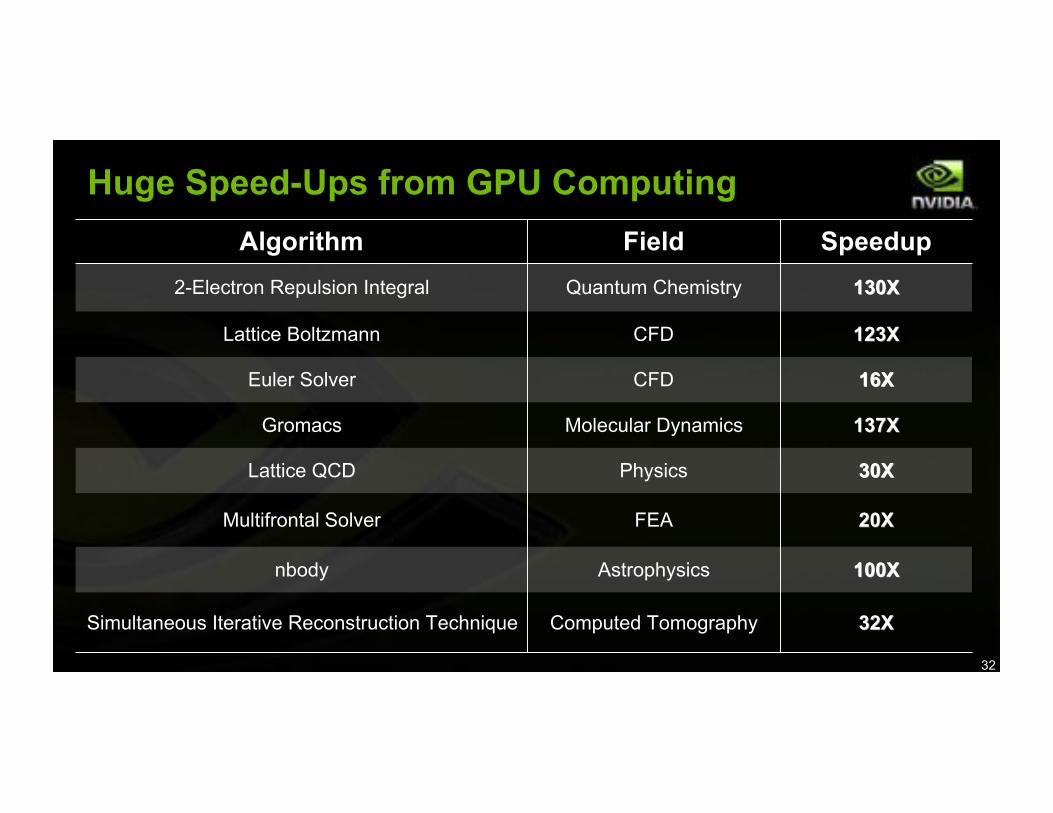
Huge Speed-Ups from GPU Computing
Algorithm Field Speedup
2-Electron Repulsion Integral Quantum Chemistry 130X130X
Lattice Boltzmann CFD 123X123X
Euler Solver CFD 16X16X
Gromacs Molecular Dynamics 137X137X
Lattice QCD Physics 30X30X
Multifrontal Solver FEA 20X20X
nbody Astrophysics 100X100X
Simultaneous Iterative Reconstruction Technique Computed Tomography 32X32X

33
Linpack

34
LINPACK Benchmark
The LINPACK benchmark is very popular in the HPC
space, because it is used as a performance measure for
ranking supercomputers in the TOP500 list.
The most widely used implementation is the HPL software
package from the Innovative Computing Laboratory at the
University of Tennessee:
it solves a random dense linear system in double
precision arithmetic on distributed-memory computers.

35
CUDA Accelerated LINPACK
Both CPU cores and GPUs are used in synergy with minor
or no modifications to the original source code (HPL 2.0):
- An host library intercepts the calls to DGEMM and
DTRSM and executes them simultaneously on the GPUs
and CPU cores.
- Use of pinned memory for fast PCI-e transfers (up to
5.7GB/s on x16 gen2 slots)
- Code is available from NVIDIA

36
DGEMM: C = alpha A B + beta C
DGEMM(A,B,C) = DGEMM(A,B1,C1) U DGEMM(A,B2,C2)
Find the optimal split, knowing the relative performances of the GPU and CPU cores on DGEMM
The idea can be extended to multi-GPU configuration and to handle huge matrices
(GPU) (CPU)
37
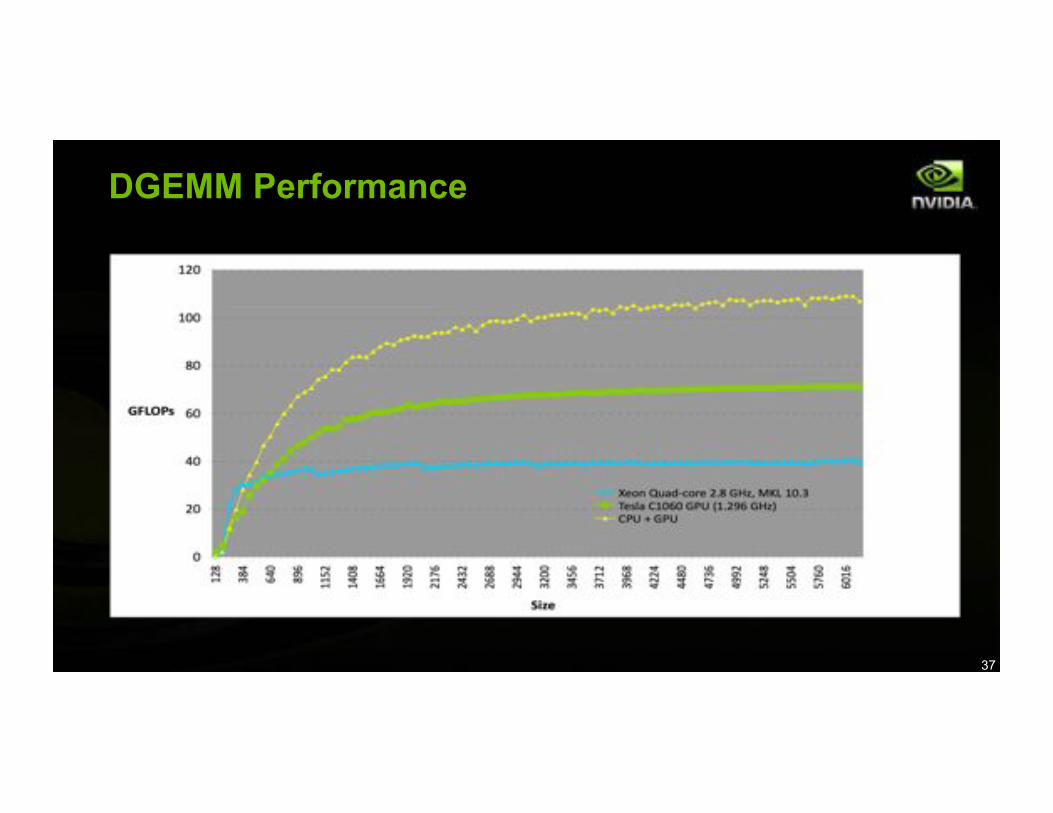
DGEMM Performance

38
Results on workstation
SUN Ultra 24 workstation with an Intel Core2 Extreme Q6850
(3.0Ghz) CPU, 8GB of memory plus a Tesla C1060 (1.296Ghz) card.
-Peak DP CPU performance of 48 GFlops
-Peak DP GPU performance of 77 Gflops (60*clock)
===========================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR00L2L2 23040 960 1 1 97.91 8.328e+01--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0048141 ...... PASSED
===========================================================================
83.2 Gflops sustained on a problem size using less than 4GB of memory: 66% of efficiency

39
Results on cluster
Cluster with 8 nodes, each node connected to half of a Tesla S1070-500 system:
-Each node has 2 Intel Xeon E5462 ( 2.8Ghz with 1600Mhz FSB) , 16GB of
memory and 2 GPUs (1.44Ghz clock).
-The nodes are connected with SDR Infiniband.
===========================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2R4 92164 960 4 4 479.35 1.089e+03
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0026439 ...... PASSED
===========================================================================
1.089 Tflop/s sustained using less than 4GB of memory per MPI process.
The first system to break the Teraflop barrier was ASCI Red (1.068 Tflop/s) in June 1997 with
7264 Pentium Pro processors. The GPU accelerated cluster occupies 8U.

40
Oil & Gas Finance Medical Biophysics Numerics Audio Video Imaging
Heterogeneous Computing
CPUCPU
GPUGPU
100M CUDA GPUs


















