
CSCI-4320/6360: Parallel Programming & Computing Tues./Fri. 12-1:30 p.m. MPI File I/O
40
PPC 2013 - MPI Parallel File I/O 1 CSCI-4320/6360: Parallel Programming & Computing Tues./Fri. 12-1:30 p.m. MPI File I/O Prof. Chris Carothers Computer Science Department MRC 309a [email protected] www.cs.rpi.edu/~chrisc/COURSES/PARALLEL/SPRING-2013 Adapted from: people.cs.uchicago.edu/~asiegel/courses/cspp51085/.../mpi-io.ppt
-
Upload
hyatt-black -
Category
Documents
-
view
28 -
download
0
description
Prof. Chris Carothers Computer Science Department MRC 309a [email protected] www.cs.rpi.edu/~chrisc/COURSES/PARALLEL/SPRING-2013 Adapted from: people.cs.uchicago.edu/~asiegel/courses/cspp51085/.../mpi-io.ppt. - PowerPoint PPT Presentation
Transcript of CSCI-4320/6360: Parallel Programming & Computing Tues./Fri. 12-1:30 p.m. MPI File I/O

PPC 2013 - MPI Parallel File I/O 1
CSCI-4320/6360: Parallel Programming & Computing
Tues./Fri. 12-1:30 p.m.MPI File I/O
Prof. Chris CarothersComputer Science Department
www.cs.rpi.edu/~chrisc/COURSES/PARALLEL/SPRING-2013Adapted from: people.cs.uchicago.edu/~asiegel/courses/cspp51085/.../mpi-io.ppt

PPC 2013 - MPI Parallel File I/O 2
Common Ways of Doing I/O in Parallel Programs
• Sequential I/O:– All processes send data to rank 0, and 0 writes it to the
file

PPC 2013 - MPI Parallel File I/O 3
Pros and Cons of Sequential I/O
• Pros:– parallel machine may support I/O from only one
process (e.g., no common file system)– Some I/O libraries (e.g. HDF-4, NetCDF,
PMPIO) not parallel– resulting single file is handy for ftp, mv– big blocks improve performance– short distance from original, serial code
• Cons:– lack of parallelism limits scalability, performance
(single node bottleneck)

PPC 2013 - MPI Parallel File I/O 4
Another Way• Each process writes to a separate file
• Pros: – parallelism, high performance
• Cons: – lots of small files to manage
– LOTS OF METADATA – stress parallel filesystem
– difficult to read back data from different number of processes
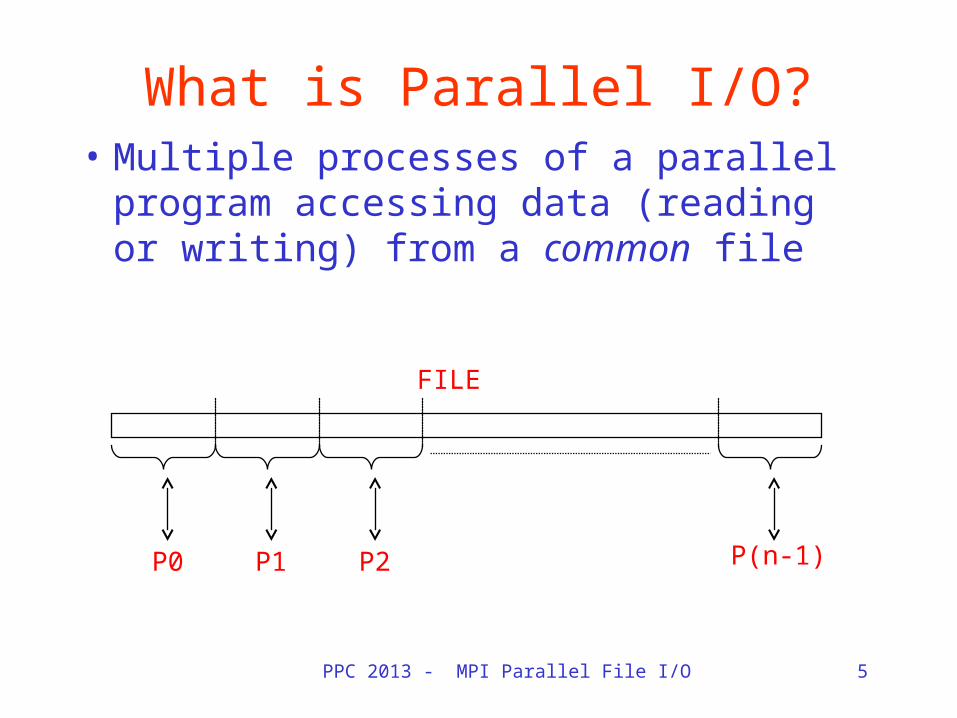
PPC 2013 - MPI Parallel File I/O 5
What is Parallel I/O?• Multiple processes of a parallel
program accessing data (reading or writing) from a common file
FILE
P0 P1 P2 P(n-1)

PPC 2013 - MPI Parallel File I/O 6
Why Parallel I/O?• Non-parallel I/O is simple but
– Poor performance (single process writes to one file) or
– Awkward and not interoperable with other tools (each process writes a separate file)
• Parallel I/O– Provides high performance– Can provide a single file that can be used
with other tools (such as visualization programs)

PPC 2013 - MPI Parallel File I/O 7
Why is MPI a Good Setting for Parallel I/O?
• Writing is like sending a message and reading is like receiving.
• Any parallel I/O system will need a mechanism to– define collective operations (MPI
communicators)– define noncontiguous data layout in memory
and file (MPI datatypes)– Test completion of nonblocking operations (MPI
request objects)
• i.e., lots of MPI-like machinery

PPC 2013 - MPI Parallel File I/O 8
MPI-IO Background• Marc Snir et al (IBM Watson) paper
exploring MPI as context for parallel I/O (1994)
• MPI-IO email discussion group led by J.-P. Prost (IBM) and Bill Nitzberg (NASA), 1994
• MPI-IO group joins MPI Forum in June 1996
• MPI-2 standard released in July 1997
• MPI-IO is Chapter 9 of MPI-2

PPC 2013 - MPI Parallel File I/O 9
Using MPI for Simple I/O
FILE
P0 P1 P2 P(n-1)
Each process needs to read a chunk of data from a common file
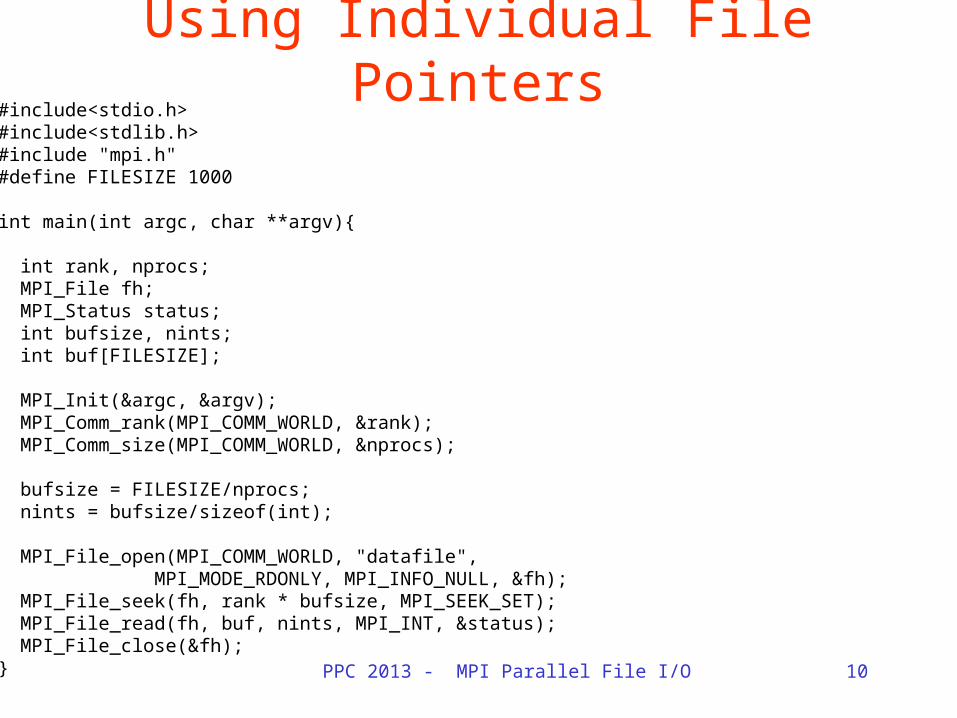
PPC 2013 - MPI Parallel File I/O 10
Using Individual File Pointers#include<stdio.h>#include<stdlib.h>#include "mpi.h"#define FILESIZE 1000
int main(int argc, char **argv){
int rank, nprocs; MPI_File fh; MPI_Status status; int bufsize, nints; int buf[FILESIZE]; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &nprocs); bufsize = FILESIZE/nprocs; nints = bufsize/sizeof(int); MPI_File_open(MPI_COMM_WORLD, "datafile", MPI_MODE_RDONLY, MPI_INFO_NULL, &fh); MPI_File_seek(fh, rank * bufsize, MPI_SEEK_SET); MPI_File_read(fh, buf, nints, MPI_INT, &status); MPI_File_close(&fh);}

PPC 2013 - MPI Parallel File I/O 11
Using Explicit Offsets
#include<stdio.h>#include<stdlib.h>#include "mpi.h"#define FILESIZE 1000
int main(int argc, char **argv){
int rank, nprocs; MPI_File fh; MPI_Status status; int bufsize, nints; int buf[FILESIZE]; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &nprocs); bufsize = FILESIZE/nprocs; nints = bufsize/sizeof(int); MPI_File_open(MPI_COMM_WORLD, "datafile", MPI_MODE_RDONLY, MPI_INFO_NULL, &fh); MPI_File_read_at(fh, rank*bufsize, buf, nints, MPI_INT, &status); MPI_File_close(&fh);}

PPC 2013 - MPI Parallel File I/O 12
Function DetailsMPI_File_open(MPI_Comm comm, char *file, int mode, MPI_Info info, MPI_File *fh) (note: mode = MPI_MODE_RDONLY, MPI_MODE_RDWR, MPI_MODE_WRONLY, MPI_MODE_CREATE, MPI_MODE_EXCL,
MPI_MODE_DELETE_ON_CLOSE, MPI_MODE_UNIQUE_OPEN, MPI_MODE_SEQUENTIAL, MPI_MODE_APPEND)
MPI_File_close(MPI_File *fh)
MPI_File_read(MPI_File fh, void *buf, int count, MPI_Datatype type, MPI_Status *status)
MPI_File_read_at(MPI_File fh, int offset, void *buf, int count, MPI_Datatype type, MPI_Status *status)
MPI_File_seek(MPI_File fh, MPI_Offset offset, in whence); (note: whence = MPI_SEEK_SET, MPI_SEEK_CUR, or MPI_SEEK_END)
MPI_File_write(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status)MPI_File_write_at( …same as read_at … );(Note: Many other functions to get/set properties (see Gropp et al))

PPC 2013 - MPI Parallel File I/O 13
Writing to a File• Use MPI_File_write or MPI_File_write_at
• Use MPI_MODE_WRONLY or MPI_MODE_RDWR as the flags to MPI_File_open
• If the file doesn’t exist previously, the flag MPI_MODE_CREATE must also be passed to MPI_File_open
• We can pass multiple flags by using bitwise-or ‘|’ in C, or addition ‘+” in Fortran

PPC 2013 - MPI Parallel File I/O 14
MPI Datatype Interlude• Datatypes in MPI
– Elementary: MPI_INT, MPI_DOUBLE, etc• everything we’ve used to this point
• Contiguous– Next easiest: sequences of elementary types
• Vector– Sequences separated by a constant “stride”

PPC 2013 - MPI Parallel File I/O 15
MPI Datatypes, cont
• Indexed: more general– does not assume a constant stride
• Struct– General mixed types (like C structs)

PPC 2013 - MPI Parallel File I/O 16
Creating simple datatypes• Let’s just look at the simplest types:
contiguous and vector datatypes.• Contiguous example
– Let’s create a new datatype which is two ints side by side. The calling sequence is
MPI_Type_contiguous(int count, MPI_Datatype oldtype, MPI_Datatype *newtype);
MPI_Datatype newtype;
MPI_Type_contiguous(2, MPI_INT, &newtype);
MPI_Type_commit(newtype); /* required */
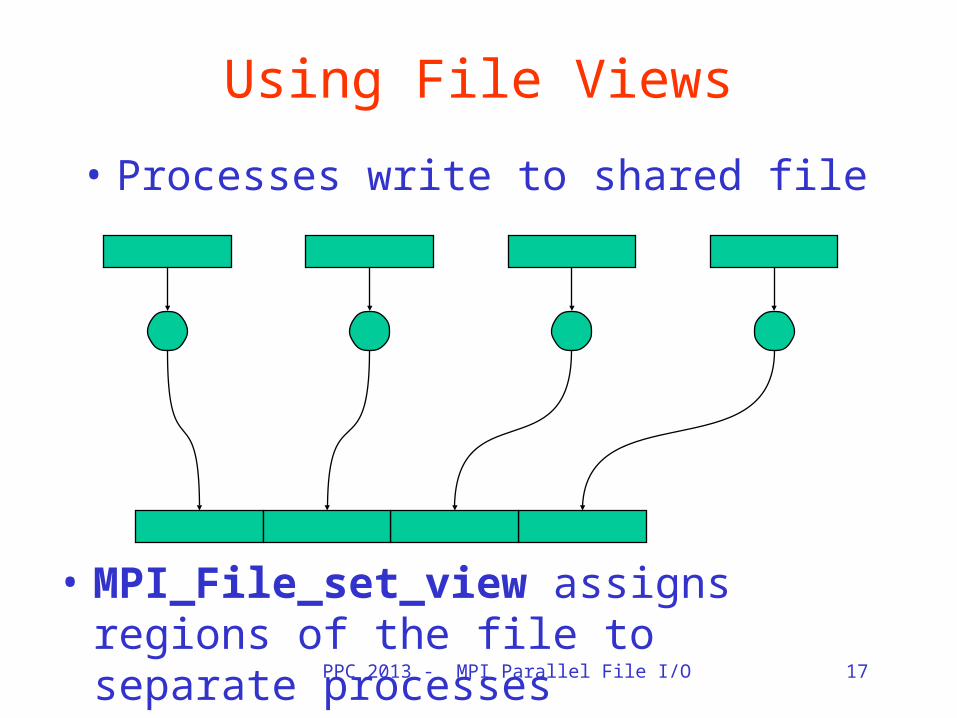
PPC 2013 - MPI Parallel File I/O 17
Using File Views
• Processes write to shared file
• MPI_File_set_view assigns regions of the file to separate processes

PPC 2013 - MPI Parallel File I/O 18
File Views• Specified by a triplet (displacement, etype, and filetype)
passed to MPI_File_set_view
• displacement = number of bytes to be skipped from the start of the file
• etype = basic unit of data access (can be any basic or derived datatype)
• filetype = specifies which portion of the file is visible to the process
• This is a collective operation and so all processors/ranks must use the same data rep, etypes in the group determined when the file was open..

PPC 2013 - MPI Parallel File I/O 19
File Interoperability
• Users can optionally create files with a portable binary data representation
• “datarep” parameter to MPI_File_set_view• native - default, same as in memory, not
portable• internal - impl. defined representation
providing an impl. defined level of portability• external32 - a specific representation defined in
MPI, (basically 32-bit big-endian IEEE format), portable across machines and MPI implementations

PPC 2013 - MPI Parallel File I/O 20
File View ExampleMPI_File thefile;
for (i=0; i<BUFSIZE; i++) buf[i] = myrank * BUFSIZE + i;
MPI_File_open(MPI_COMM_WORLD, "testfile", MPI_MODE_CREATE | MPI_MODE_WRONLY, MPI_INFO_NULL, &thefile);
MPI_File_set_view(thefile, myrank * BUFSIZE, MPI_INT, MPI_INT, "native",
MPI_INFO_NULL);
MPI_File_write(thefile, buf, BUFSIZE, MPI_INT, MPI_STATUS_IGNORE);
MPI_File_close(&thefile);

PPC 2013 - MPI Parallel File I/O 21
Ways to Write to a Shared File
• MPI_File_seek
• MPI_File_read_at
• MPI_File_write_at
• MPI_File_read_shared
• MPI_File_write_shared
• Collective operations
combine seek and I/Ofor thread safety
use shared file pointergood when order doesn’t matter
like Unix seek

PPC 2013 - MPI Parallel File I/O 22
Collective I/O in MPI
• A critical optimization in parallel I/O
• Allows communication of “big picture” to file system
• Framework for 2-phase I/O, in which communication precedes I/O (can use MPI machinery)
• Basic idea: build large blocks, so that reads/writes in I/O system will be large
Small individualrequests
Large collectiveaccess

PPC 2013 - MPI Parallel File I/O 23
Collective I/O• MPI_File_read_all, MPI_File_read_at_all, etc
• _all indicates that all processes in the group specified by the communicator passed to MPI_File_open will call this function
• Each process specifies only its own access information -- the argument list is the same as for the non-collective functions

PPC 2013 - MPI Parallel File I/O 24
Collective I/O
• By calling the collective I/O functions, the user allows an implementation to optimize the request based on the combined request of all processes
• The implementation can merge the requests of different processes and service the merged request efficiently
• Particularly effective when the accesses of different processes are noncontiguous and interleaved

PPC 2013 - MPI Parallel File I/O 25
Collective non-contiguousMPI-IO examples
#define “mpi.h”#define FILESIZE 1048576#define INTS_PER_BLK 16
int main(int argc, char **argv){ int *buf, rank, nprocs, nints, bufsize; MPI_File fh; MPI_Datatype filetype; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &nprocs); bufsize = FILESIZE/nprocs; buf = (int *) malloc(bufsize); nints = bufsize/sizeof(int);
MPI_File_open(MPI_COMM_WORLD, “filename”, MPI_MODE_RD_ONLY, MPI_INFO_NULL, &fh); MPI_Type_vector(nints/INTS_PER_BLK, INTS_PER_BLK, INTS_PER_BLK*nprocs, MPI_INT, &filetype); MPI_Type_commit(&filetype); MPI_File_set_view(fh, INTS_PER_BLK*sizeof(int)*rank, MPI_INT, filetype, “native”, MPI_INFO_NULL); MPI_File_read_all(fh, buf, nints, MPI_INT, MPI_STATUS_IGNORE);
MPI_Type_free(&filetype); free(buf) MPI_Finalize(); return(0);}

PPC 2013 - MPI Parallel File I/O 26
More on MPI_Read_all• Note that the _all version has the same
argument list
• Difference is that all processes involved in MPI_Open must call this the read
• Contrast with the non-all version where any subset may or may not call it
• Allows for many optimizations

PPC 2013 - MPI Parallel File I/O 27
Split Collective I/O
MPI_File_write_all_begin(fh, buf, count, datatype);// available on Blue Gene/L, but may not improve // performancefor (i=0; i<1000; i++) { /* perform computation */}
MPI_File_write_all_end(fh, buf, &status);
• A restricted form of nonblocking collective I/O
• Only one active nonblocking collective operation allowed at a time on a file handle
• Therefore, no request object necessary

PPC 2013 - MPI Parallel File I/O 28
Passing Hints to the Implementation
MPI_Info info;
MPI_Info_create(&info);
/* no. of I/O devices to be used for file striping */MPI_Info_set(info, "striping_factor", "4");
/* the striping unit in bytes */MPI_Info_set(info, "striping_unit", "65536");
MPI_File_open(MPI_COMM_WORLD, "/pfs/datafile", MPI_MODE_CREATE | MPI_MODE_RDWR, info, &fh);
MPI_Info_free(&info);

PPC 2013 - MPI Parallel File I/O 29
Examples of Hints (used in ROMIO)
• striping_unit
• striping_factor
• cb_buffer_size
• cb_nodes
• ind_rd_buffer_size
• ind_wr_buffer_size
• start_iodevice
• pfs_svr_buf
• direct_read
• direct_write
MPI-2 predefined hints
New Algorithm Parameters
Platform-specific hints

PPC 2013 - MPI Parallel File I/O 30
I/O Consistency Semantics
• The consistency semantics specify the results when multiple processes access a common file and one or more processes write to the file
• MPI guarantees stronger consistency semantics if the communicator used to open the file accurately specifies all the processes that are accessing the file, and weaker semantics if not
• The user can take steps to ensure consistency when MPI does not automatically do so

PPC 2013 - MPI Parallel File I/O 31
Example 1• File opened with MPI_COMM_WORLD. Each process writes to a
separate region of the file and reads back only what it wrote.
MPI_File_open(MPI_COMM_WORLD,…)MPI_File_write_at(off=0,cnt=100)MPI_File_read_at(off=0,cnt=100)
MPI_File_open(MPI_COMM_WORLD,…)MPI_File_write_at(off=100,cnt=100)MPI_File_read_at(off=100,cnt=100)
Process 0 Process 1
• MPI guarantees that the data will be read correctly

PPC 2013 - MPI Parallel File I/O 32
Example 2• Same as example 1, except that each process
wants to read what the other process wrote (overlapping accesses)
• In this case, MPI does not guarantee that the data will automatically be read correctly
• In the above program, the read on each process is not guaranteed to get the data written by the other process!
/* incorrect program */MPI_File_open(MPI_COMM_WORLD,…)MPI_File_write_at(off=0,cnt=100)MPI_BarrierMPI_File_read_at(off=100,cnt=100)
/* incorrect program */MPI_File_open(MPI_COMM_WORLD,…)MPI_File_write_at(off=100,cnt=100)MPI_BarrierMPI_File_read_at(off=0,cnt=100)
Process 0 Process 1

PPC 2013 - MPI Parallel File I/O 33
Example 2 contd.• The user must take extra steps to ensure
correctness• There are three choices:
– set atomicity to true– close the file and reopen it– ensure that no write sequence on any
process is concurrent with any sequence (read or write) on another process/MPI rank• Can hurt performance….

PPC 2013 - MPI Parallel File I/O 34
Example 2, Option 1Set atomicity to true
MPI_File_open(MPI_COMM_WORLD,…)MPI_File_set_atomicity(fh1,1)MPI_File_write_at(off=0,cnt=100)MPI_BarrierMPI_File_read_at(off=100,cnt=100)
MPI_File_open(MPI_COMM_WORLD,…)MPI_File_set_atomicity(fh2,1)MPI_File_write_at(off=100,cnt=100)MPI_BarrierMPI_File_read_at(off=0,cnt=100)
Process 0 Process 1

PPC 2013 - MPI Parallel File I/O 35
Example 2, Option 2Close and reopen file
MPI_File_open(MPI_COMM_WORLD,…)MPI_File_write_at(off=0,cnt=100)MPI_File_closeMPI_BarrierMPI_File_open(MPI_COMM_WORLD,…)MPI_File_read_at(off=100,cnt=100)
MPI_File_open(MPI_COMM_WORLD,…)MPI_File_write_at(off=100,cnt=100)MPI_File_closeMPI_BarrierMPI_File_open(MPI_COMM_WORLD,…)MPI_File_read_at(off=0,cnt=100)
Process 0 Process 1

PPC 2013 - MPI Parallel File I/O 36
Example 2, Option 3• Ensure that no write sequence on any
process is concurrent with any sequence (read or write) on another process
• a sequence is a set of operations between any pair of open, close, or file_sync functions
• a write sequence is a sequence in which any of the functions is a write operation

PPC 2013 - MPI Parallel File I/O 37
Example 2, Option 3
MPI_File_open(MPI_COMM_WORLD,…)MPI_File_write_at(off=0,cnt=100)MPI_File_sync
MPI_Barrier
MPI_File_sync /*collective*/
MPI_File_sync /*collective*/
MPI_Barrier
MPI_File_syncMPI_File_read_at(off=100,cnt=100)MPI_File_close
MPI_File_open(MPI_COMM_WORLD,…)
MPI_File_sync /*collective*/
MPI_Barrier
MPI_File_syncMPI_File_write_at(off=100,cnt=100)MPI_File_sync
MPI_Barrier
MPI_File_sync /*collective*/MPI_File_read_at(off=0,cnt=100)MPI_File_close
Process 0 Process 1

PPC 2013 - MPI Parallel File I/O 38
General Guidelines for Achieving High I/O Performance
• Buy sufficient I/O hardware for the machine
• Use fast file systems, not NFS-mounted home directories
• Do not perform I/O from one process only
• Make large requests wherever possible
• For noncontiguous requests, use derived datatypes and a single collective I/O call

PPC 2013 - MPI Parallel File I/O 39
Optimizations
• Given complete access information, an implementation can perform optimizations such as:– Data Sieving: Read large chunks and
extract what is really needed– Collective I/O: Merge requests of
different processes into larger requests– Improved prefetching and caching

PPC 2013 - MPI Parallel File I/O 40
Summary• MPI-IO has many features that can help users
achieve high performance
• The most important of these features are the ability to specify noncontiguous accesses, the collective I/O functions, and the ability to pass hints to the implementation
• Users must use the above features!
• In particular, when accesses are noncontiguous, users must create derived datatypes, define file views, and use the collective I/O functions


















