
CSC475 Music Information Retrieval - Tags and Musicmarsyas.cs.uvic.ca/mirBook/csc475_tagging.pdf ·...
55
CSC475 Music Information Retrieval Tags and Music George Tzanetakis University of Victoria 2014 G. Tzanetakis 1 / 53
Transcript of CSC475 Music Information Retrieval - Tags and Musicmarsyas.cs.uvic.ca/mirBook/csc475_tagging.pdf ·...

CSC475 Music Information RetrievalTags and Music
George Tzanetakis
University of Victoria
2014
G. Tzanetakis 1 / 53

Table of Contents I
1 Indexing music with tags
2 Tag acquisition
3 Autotagging
4 Evaluation
5 Ideas for future work
G. Tzanetakis 2 / 53

Tags
Definition
A tag is a short phrase or word that can be used tocharacterize a piece of music. Examples: “bouncy”, “heavymetal”, or “hand drums”. Tags can be related to instruments,genres, amotions, moods, usages, geographic origins,musicological terms, or anything the users decide.
Similarly to a text index, a music index associated musicdocuments to tags. A document can be a song, an album, anartist, a record label, etc. We consider songs/tracks to be ourmusical documents.
G. Tzanetakis 3 / 53

Music Index
Vocabulary s1 s2 s3happy .8 .2 .6pop .7 0 .1a capella .1 .1 .5saxophone 0 .7 .9
A query can either be a list of tags or a song. Using the musicindex the system can return a playlist of songs that somehow“match” the specified tags.
G. Tzanetakis 4 / 53

Tag research terminology
Cold-start problem: songs that are not annotated cannot be retrieved.
Popularity bias: songs (in the short head tend to beannotated more thoroughly than unpopular songs (in thelong tail).
Strong labeling versus weak labeling.
Extensible or fixed vocabulary.
Structured or unstructured vocabulary.
Note:
Evaluation is a big challenge due to subjectivity.
Tags generalize classification labels
G. Tzanetakis 5 / 53

Many thanks to
Material for these slides was generously provided by:
Mohamed Sordo Emanule Coviello Doug Turnbull
G. Tzanetakis 6 / 53
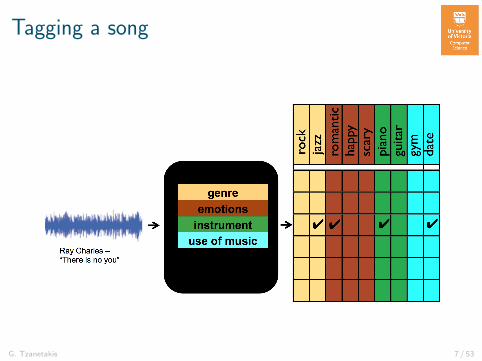
Tagging a song
G. Tzanetakis 7 / 53

Tagging multiple songs
G. Tzanetakis 8 / 53

Text query
G. Tzanetakis 9 / 53

Table of Contents I
1 Indexing music with tags
2 Tag acquisition
3 Autotagging
4 Evaluation
5 Ideas for future work
G. Tzanetakis 10 / 53

Sources of Tags
Human participation:
Surveys
Social Tags
Games
Automatic:
Text mining
Autotagging
G. Tzanetakis 11 / 53

Survey
Pandora: a team of approximately 50 expert music reviewers(each with a degree in music and 200 hours of training)annotate songs using a structured vocabulary of between 150and 200 tags. Tags are “objective” i.e there is a high degreeof inter-reviewer agreement. Between 2000 and 2010, Pandoraannotated about 750, 000 songs. Annotation takesapproximately 20-30 minutes.CAL500: one song from 500 unique artists, each annod by aminimum of 3 nonexpert reviewers using a structuredvocabulary of 174 tags. Standard dataset of training andevaluating tag-based retrieval systems.
G. Tzanetakis 12 / 53

Harvesting social tags
Last.fm is a music discovery Web site that allows users tocontribute social tags through a text box in their audio playerinterface. It is an example of crowd sourcing. In 2007, 40million active users built up a vocabulary of 960, 000 free-texttags and used it to annotate millions of songs. All dataavailable through public web API. Tags typically annotateartists rather than sons. Problems with multiple spelling,polysemous tags (such as progressive).
G. Tzanetakis 13 / 53

Last.fm tags for Adele
G. Tzanetakis 14 / 53

Playing Annotation Games
In ISMIR 2007, music annotation games were presented forthe first time: ListenGame, Tag-a-Tune, and MajorMiner.ListenGame uses a structured vocabulary and is real time.Tag-a-Tune and MajorMiner are inspired by the ESP Game forimage tagging. In this approach the players listen to a trackand are asked to enter “free text” tags until they both enterthe same tag. This results in an extensible vocabulary.
G. Tzanetakis 15 / 53

Tag-a-tune
G. Tzanetakis 16 / 53

Mining web documents
There are many text sources of information associated with amusic track. These include artist biographies, album reviews,song reviews, social media posts, and personal blogs. The setof documents associated with a song is typically processed bytext mining techniques resulting in a vector spacerepresentation which can then be used as input to datamining/machine learning techniques (text mining will becovered in more detail in a future lecture).
G. Tzanetakis 17 / 53

Table of Contents I
1 Indexing music with tags
2 Tag acquisition
3 Autotagging
4 Evaluation
5 Ideas for future work
G. Tzanetakis 18 / 53

cal500.sness.net
G. Tzanetakis 19 / 53

Audio feature extraction
Audio features for tagging are typically very similar to the onesused for audio classification i.e statistics of the short-timemagnitude spectrum over different time scales.
G. Tzanetakis 20 / 53
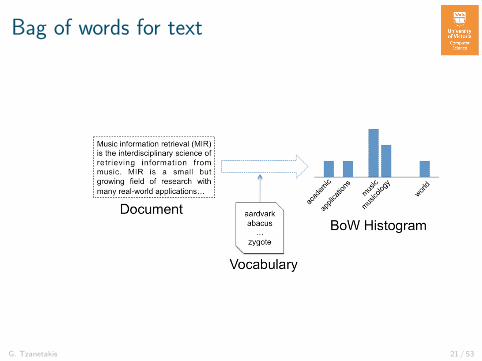
Bag of words for text
G. Tzanetakis 21 / 53
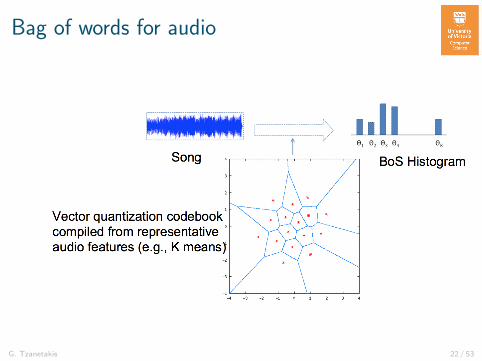
Bag of words for audio
G. Tzanetakis 22 / 53

Multi-label classification (with twists)
“Classic” classification is single label and multi-class. Inmulti-label classification each instance can be assigned morethan one label. Tag annotation can be viewed as multi-labelclassification with some additional twists:
Synonyms (female voice, woman singing)
Subpart relations (string quartet, classical)
Sparse (only a small subset of tags applies to each song)
Noisy
Useful because:
Cold start problem
Query-by-keywords
G. Tzanetakis 23 / 53

Machine Learning for Tag Annotation
A straightforward approach is to treat each tag independentlyas a classification problem.
G. Tzanetakis 24 / 53
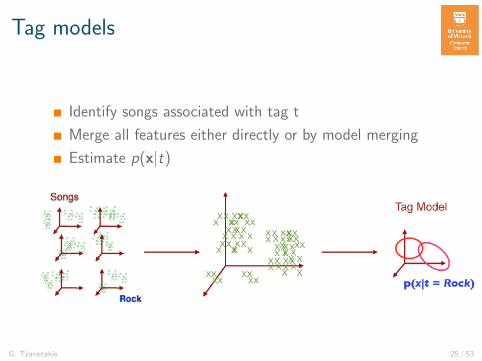
Tag models
Identify songs associated with tag t
Merge all features either directly or by model merging
Estimate p(x|t)
G. Tzanetakis 25 / 53
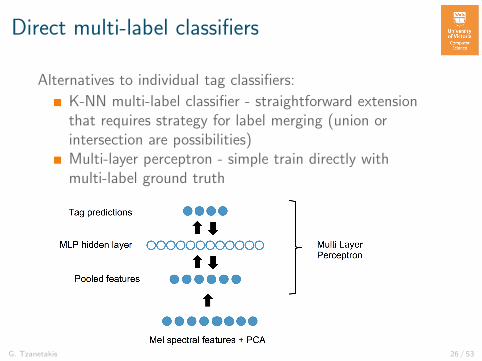
Direct multi-label classifiers
Alternatives to individual tag classifiers:
K-NN multi-label classifier - straightforward extensionthat requires strategy for label merging (union orintersection are possibilities)Multi-layer perceptron - simple train directly withmulti-label ground truth
G. Tzanetakis 26 / 53

Tag co-occurence
G. Tzanetakis 27 / 53

Stacking
G. Tzanetakis 28 / 53
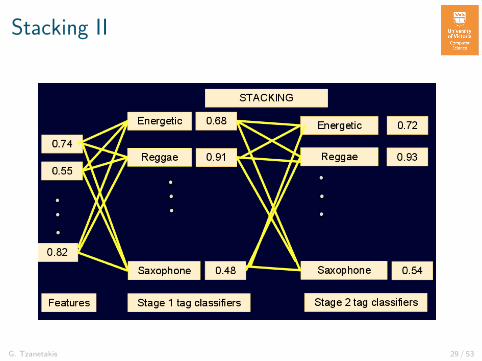
Stacking II
G. Tzanetakis 29 / 53

How stacking can help ?
G. Tzanetakis 30 / 53

Other terms/variants
The main idea behind stacking i.e using the output of aclassification stage as the input to a subsequent classificationstage has been proposed under several different names:
Correction approach (using binary outputs)
Anchor classification (for example classification intoartists used as a feature for genre classification)
Semantic space retrieval
Cascaded classification (in computer vision)
Stacked generalization (in the classification)
Context modeling (in autotagging)
Cost-sensitive stacking (variant)
G. Tzanetakis 31 / 53

Combining taggers/bag of systems
G. Tzanetakis 32 / 53

Table of Contents I
1 Indexing music with tags
2 Tag acquisition
3 Autotagging
4 Evaluation
5 Ideas for future work
G. Tzanetakis 33 / 53

Datasets
There are several datasets that have been used to train andevaluate auto-tagging. They differ in the amount of data theycontain, and the source of the ground truth tag information.
Major Miner
Magnatagatune
CAL500 (the most widely used one)
CAL10K
MediaEval
Reproducibility: common dataset is not enough, ideally exactdetails about the cross-validation folding process andevaluation scripts should also be included.
G. Tzanetakis 34 / 53

Magnatagatune
26K sound clips from magnatune.com
Human annotation from the Tag-a-tune game
Audio features from the Echo Nest
230 artists
183 tags
G. Tzanetakis 35 / 53

CAL-10K Dataset
Number of tracks: 10866
Tags: 1053 (genre and acoustic tags)
Tags/Track: min = 2, max = 25, µ = 10.9, σ = 4.57,median = 11
Most used tags: major key tonality (4547), acousticrhythm guitars (2296), a vocal-centric aesthetic (2163),extensive vamping (2130)
Less used tags: cocky lyrics (1), psychedelic rockinfluences (1), breathy vocal sound (1), well-articulatedtrombone solo (1), lead flute (1)
Tags collected using survey
Available at:http://cosmal.ucsd.edu/cal/projects/AnnRet/
G. Tzanetakis 36 / 53

Tagging evaluation metrics
The inputs to a autotagging evaluation metric are thepredicted tags (#tags by #tracks binary matrix) or tagaffinities (#tags by #tracks) matrix of reals) and theassociated ground truth (binary matrix).
Asymmetry between positives and negatives makesclassification accuracy not a very good metric. Retrievalmetrics are better choices. If the output of the auto-taggingsystem is affinities then many metrics require binarization.
Common binarization variants: select k top scoring tags foreach track, threshold each column of tag affinities to achievethe tag priors in the training set.
G. Tzanetakis 37 / 53

Annotation vs retrieval
One possibility would be to convert matrices into vectors andthen use classification evaluation metrics. This approach hasthe disadvantage that popular tags will dominate andperformance in less-frequent tags (which one could argue aremore important) will be irrelevant. Therefore the commonapproach is to treat each tag column separately and thenaverage across tags (retrieval) or alternatively treat eachtrack row separately and average across tracks (annotation).
Validation schems are similar to classification: cross-validation,repeated cross-validation, and bootstrapping.
G. Tzanetakis 38 / 53
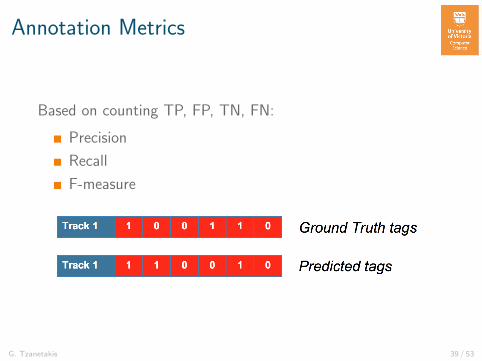
Annotation Metrics
Based on counting TP, FP, TN, FN:
Precision
Recall
F-measure
G. Tzanetakis 39 / 53

Annotation Metrics based on rank
When using affinities it is possible to use rank correlationmetrics:
Spearman’s rank correlation coefficient ρ
Kendal tau τ
G. Tzanetakis 40 / 53

Retrieval measures - Mean Average Precision
Precision at N is the number of relevant songs retrieved out ofN divided by N . Rather than choosing N one can averageprecision for different N and then take the mean over a set ofqueries (tags).
G. Tzanetakis 41 / 53

Retrieval measures - AUC-ROC
G. Tzanetakis 42 / 53

Stacking results I
G. Tzanetakis 43 / 53

Stacking results II
G. Tzanetakis 44 / 53
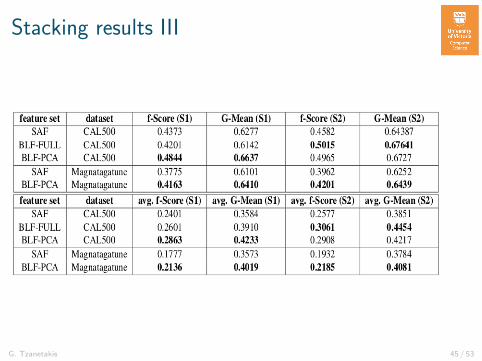
Stacking results III
G. Tzanetakis 45 / 53

Stacking results IV
G. Tzanetakis 46 / 53

Stacking results V
G. Tzanetakis 47 / 53

MIREX Tag Annotation Task
The Music Information Retrieval Evaluation Exchange(MIREX) audio tag annotation task started in 2008
MajorMiner dataset (2300 tracks, 45 tags)
Mood tag dataset (6490 tracks, 135 tags)
10 second clips
3-fold cross-validation
Binary relevance (F-measure, precision, recall)
Affinity ranking (AUC-ROC, Precision at 3,6,9,12,15)
G. Tzanetakis 48 / 53
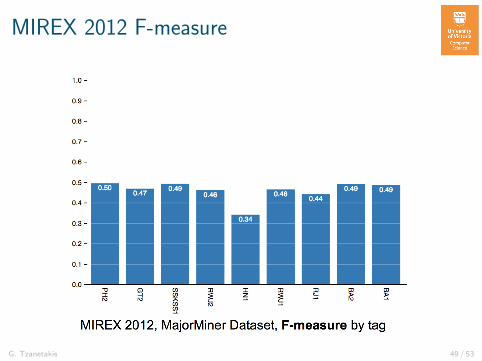
MIREX 2012 F-measure
G. Tzanetakis 49 / 53
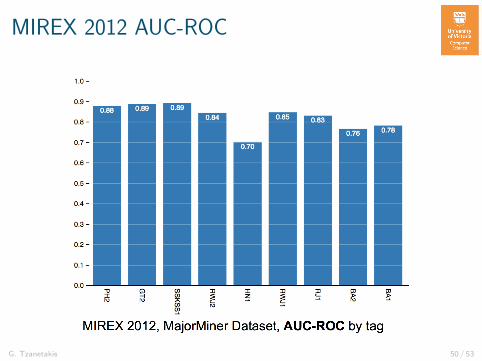
MIREX 2012 AUC-ROC
G. Tzanetakis 50 / 53
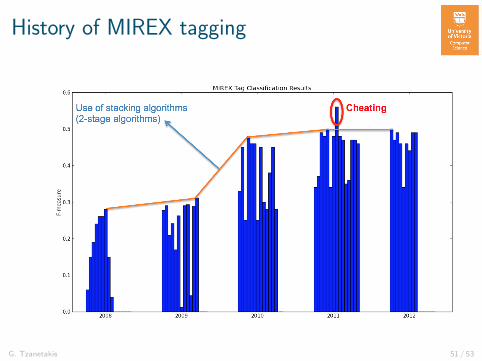
History of MIREX tagging
G. Tzanetakis 51 / 53

Table of Contents I
1 Indexing music with tags
2 Tag acquisition
3 Autotagging
4 Evaluation
5 Ideas for future work
G. Tzanetakis 52 / 53

Open questions
Should the tag annotations be sanitized or should themachine learning part handle it ?
Do auto-taggers generalize outside their collections ?
Stacking seems to improve results (even though onepaper has shown no improvement). How does stackingperform when dealing with synonyms, antonyms, noisyannotations ? Why ?
How can multiple sources of tags be combined ?
G. Tzanetakis 53 / 53

Future work
Weak labeling: in most cases absense of a tag does NOTimply that the tag would not be considered valid by most users
Explore a continuous grading of semi-supervised learningwhere the distinction between supervised andunsupervised is not binary
Explore feature clusering of untagged instances
Include additional sources of information (separate fromtags) such as artist, genre, album
multiple instance learning approaches (for example ifgenre information is available at the album level)
Statistical relational learning
G. Tzanetakis 54 / 53

Future work
The lukewarm start problem: what if some tags are known forthe testing data but not all ?
Missing label type of approaches such as EM
Markov logic inference in structured data
Other ideas:
Online learning where tags enter the system incrementallyand individually rather than all at the same time or for aparticular instance
Taking into account user behavior when interacting witha tag system
Personalization vs Crowd: would clustering users based ontheir tagging make sense ?
G. Tzanetakis 55 / 53


















