
CS 8520: Artificial Intelligence
53
CSC 8520 Spring 2010. Paula Matuszek CS 8520: Artificial Intelligence Machine Learning 1 Paula Matuszek Spring, 2010
-
Upload
derek-powers -
Category
Documents
-
view
25 -
download
1
description
CS 8520: Artificial Intelligence. Machine Learning 1 Paula Matuszek Spring, 2010. CSC 8520 Spring 2010. Paula Matuszek. http://xkcd.com/720/. CSC 8520 Spring 2010. Paula Matuszek. What is learning?. - PowerPoint PPT Presentation
Transcript of CS 8520: Artificial Intelligence

CSC 8520 Spring 2010. Paula Matuszek
CS 8520: Artificial Intelligence
Machine Learning 1
Paula Matuszek
Spring, 2010

3CSC 8520 Spring 2010. Paula Matuszek
What is learning?• “Learning denotes changes in a system
that ... enable a system to do the same task more efficiently the next time.” –Herbert Simon
• “Learning is constructing or modifying representations of what is being experienced.” –Ryszard Michalski
• “Learning is making useful changes in our minds.” –Marvin Minsky

4CSC 8520 Spring 2010. Paula Matuszek
Why learn?• Understand and improve efficiency of human learning
– Improve methods for teaching and tutoring people (better CAI)
• Discover new things or structure that were previously unknown to humans– Examples: data mining, scientific discovery
• Fill in skeletal or incomplete specifications about a domain– Large, complex AI systems cannot be completely derived by hand
and require dynamic updating to incorporate new information.
– Learning new characteristics expands the domain or expertise and lessens the “brittleness” of the system
• Build software agents that can adapt to their users or to other software agents
• Reproduce an important aspect of intelligent behavior

5CSC 8520 Spring 2010. Paula Matuszek
Learning Systems• Many machine learning systems can be viewed as
an iterative process of – produce a result,
– evaluate it against the expected results
– tweak the system
• Machine learning is also used for systems which discover patterns without prior expected results.
• May be open or black box– Open: changes are clearly visible in KB and
understandable to humans
– Black Box: changes are to a system whose internals are not readily visible or understandable.

6CSC 8520 Spring 2010. Paula Matuszek
Learner Architecture• Any learning system needs to somehow
implement four components:– Knowledge base: what is being learned.
Representation of a problem space or domain.– Performer: does something with the knowledge base to
produce results– Critic: evaluates results produced against expected
results– Learner: takes output from critic and modifies
something in KB or performer.
• May also need a “problem generator” to test performance against.

7CSC 8520 Spring 2010. Paula Matuszek
A Very Simple Learning Program
• Animals Guessing Game– Representation is a binary tree– Performer is a tree walker interacting with a
human– Critic is the human player– Learning component elicits new questions and
modifies the binary tree

8CSC 8520 Spring 2010. Paula Matuszek
What Are We Learning?• Direct mapping from current state to
actions
• Way to infer relevant properties of the world from the current percept sequence
• Information about changes and prediction of results of actions
• Desirability of states and actions
• Goals

9CSC 8520 Spring 2010. Paula Matuszek
Representation• How do you describe your problem?
– I'm guessing an animal: binary decision tree– I'm playing chess: the board itself, sets of rules
for choosing moves– I'm categorizing documents: vector of word
frequencies for this document and for the corpus of documents
– I'm fixing computers: frequency matrix of causes and symptoms
– I'm OCRing digits: probability of this digit; 6x10 matrix of pixels; % light; # straight lines

10
CSC 8520 Spring 2010. Paula Matuszek
Performer• How do you take action?
– Guessing an animal: walk the tree and ask associated questions
– Playing chess: chain through the rules to identify a move; use conflict resolution to choose one; output it.
– Categorizing documents: apply a function to the vector of features (word frequencies) to determine which category to put document in
– Fixing computers: use known symptoms to identify potential causes, check matrix for additional diagnostic symptoms.
– OCRing digits: input the features for a digit, output probability that it's 0-9.

11
CSC 8520 Spring 2010. Paula Matuszek
Critic• How do you judge correct actions?
– Guessing an animal: human feedback
– Fixing computers: Human input about symptoms and cause observed for a specific case
– OCRing digits: Human-categorized training set.
– Categorizing documents: match to a set of human-categorized test documents.
– Categorizing documents: which are most similar in language or content?
– Playing chess: who won? (Credit assignment problem)
• Can be generally categorized as supervised, unsupervised, reinforcement.

12
CSC 8520 Spring 2010. Paula Matuszek
Learner• What does the learner do?
– Guessing an animal: elicit a question from the user and add it to the binary tree
– Fixing computers: update frequency matrix with actual symptoms and outcome
– OCRing digits: modify weights on a network of associations.
– Categorizing documents: modify the weights on the function to improve categorization
– Playing chess: increase the weight for some rules and decrease for others.

13
CSC 8520 Spring 2010. Paula Matuszek
General Model of Learning AgentE
nvironment
Agent
Critic
Learning Element
Problem Generator
Performer with KB
Performance Standard
Sensors
Effectors
feedback
learning goals
changes
knowledge

14
CSC 8520 Spring 2010. Paula Matuszek
Some major paradigms of machine learning• Rote learning: Hand-encoded mapping from inputs to stored
representation. “Learning by memorization.” • Interactive learning: Human/AI interaction produces mapping.• Inductive Learning: Specific examples --> general conclusions. • Deductive Learning: Find more efficient logically-entailed rules.• Analogy: Determining correspondence between two different
representations. Case-based reasoning • Clustering: Unsupervised identification of natural groups in data• Discovery: Unsupervised, specific goal not given • Genetic algorithms: “Evolutionary” search techniques, based on
an analogy to “survival of the fittest”
These are not mutually exclusive.

15
CSC 8520 Spring 2010. Paula Matuszek
Approaches to Learning Systems• Can also be classified by degree of human
involvement required, in the critic or the learner component.– All human input– Computer-guided human input– Human-guided computer learning– All computerized, no human input

16
CSC 8520 Spring 2010. Paula Matuszek
Rote Learning:• In people: straight memorization• In computer systems: Knowledge engineering;
direct entry of rules and facts• This is all human input. This is the traditional
approach to developing ontologies, for instance• Knowledge base is captured knowledge• Performer is an inference engine, ontology
browser, or other user of the KB• Learner is the editor use to develop the KB + the
human• Critic is entirely offline, as the human examines
or tests the system.

17
CSC 8520 Spring 2010. Paula Matuszek
Interactive• Methods in which the computer interacts with the
human to expand the knowledge base• Classic example is Animals.
• Another classic example is Teiresias1.– Modified rules in Emycin by interacting with human– I conclude XXX. Is this the correct diagnosis?
• No
– I concluded XXX based on YYY and ZZZ. Is this rule correct, incorrect, or incomplete?
• Incomplete
– What additional tests should be added to the rule?1. B. Buchanan and E. Shortliffe, Rule-Based Expert Systems. Reading, MA: Addison-Wesley, 1984.

18
CSC 8520 Spring 2010. Paula Matuszek
The inductive learning problem• Extrapolate from a given set of examples to
make accurate predictions about future examples
• Concept learning or classification– Given a set of examples of some
concept/class/category, determine if a given example is an instance of the concept or not
– If it is an instance, we call it a positive example– If it is not, it is called a negative example

19
CSC 8520 Spring 2010. Paula Matuszek
Inductive Learning Framework• Representation must extract from possible
observations a feature vector of relevant features for each example.
• The number of attributes and values for the attributes are fixed (although values can be continuous).
• Each example is represented as a specific feature vector.
• Each example can be interpreted as a point in an n-dimensional feature space, where n is the number of attributes

20
CSC 8520 Spring 2010. Paula Matuszek
Feature Spaces• Which features to include in the vector is a
major question in developing an inductive learning system:– They should be relevant to the prediction to be
made– They should be (mostly) observable for every
example– They should be as much as possible independent of
one another

21
CSC 8520 Spring 2010. Paula Matuszek
Hypotheses• The task of a supervised learning system can be viewed
as learning a function which predicts the outcome from the inputs: – Given a training set of N example pairs (x1, y1) (x2,y2)...
(xn,yn), where each yj was generated by an unknown function y = f(x), discover a function h that approximates the true function y
• h is our hypothesis, and learning is the process of finding a good h in the space of possible hypotheses
• Prefer simplest consistent with the data
• Tradeoff between fit and generalizability
• Tradeoff between fit and computational complexity

22
CSC 8520 Spring 2010. Paula Matuszek
Rule Induction• Given
– Features– Training examples– Output for training examples
• Generate automatically a set of rules or a decision tree which will allow you to judge new objects
• Basic approach is – Combinations of features become antecedents or
links– Examples become consequents or nodes

23
CSC 8520 Spring 2010. Paula Matuszek
Rule Induction Example• Starting with 100 cases, 10 outcomes, 15 variables
• Form 100 rules, each with 15 antecedents and one consequent.
• Collapse rules.
• Cancellations: If we have– C, A => B and –C, A => B, collapse to A => B
• Drop Terms:– D, E => F and D, G => F, collapse to D => F
• Test rules and undo collapse if performance gets worse
• Additional heuristics for combining rules.

24
CSC 8520 Spring 2010. Paula Matuszek
Rose DiagnosisYellow Leaves Wilted Leaves Brown Spots
Fungus N Y Y
Bugs N Y Y
Nutrition Y N N
Fungus N N Y
Fungus Y N Y
Bugs Y Y NR1: If not yellow leaves and wilted leaves and brown spots then fungus.
…
R6: If wilted leaves and yellow leaves and not brown spots then bugs

25
CSC 8520 Spring 2010. Paula Matuszek
Rose Diagnosis• Cases 1 and 4 have opposite values for wilted leaves, so
create new rule:– R7: If not yellow leaves and brown spots then fungus.
• KB is rules. Learner is system collapsing and test rules. Critic is the test cases. Performer is rule-based inference.
• Problems:– Over-generalization
– Irrelevance
– Need data on all features for all training cases
– Computationally painful.
• Useful if you have enough good training cases.
• Output can be understood and modified by humans

26
CSC 8520 Spring 2010. Paula Matuszek
Decision Tree Induction
• Very common data mining technique.
• Given:– Examples– Attributes– Goal (classification, typically)
• Pick “important” attribute: one which divides set cleanly.
• Recur with subsets not yet classified.

27
CSC 8520 Spring 2010. Paula Matuszek
Expressiveness• Decision trees can express any function of the input attributes.• E.g., for Boolean functions, truth table row → path to leaf:
• Trivially, there is a consistent decision tree for any training set with one path to leaf for each example (unless f nondeterministic in x) but it probably won't generalize to new examples
• Prefer to find more compact decision trees

28
CSC 8520 Spring 2010. Paula Matuszek
ID3• A greedy algorithm for decision tree construction
originally developed by Ross Quinlan, 1987 • Top-down construction of decision tree by recursively
selecting “best attribute” to use at the current node in tree– Once attribute is selected, generate children nodes, one
for each possible value of selected attribute– Partition examples using possible values of attribute,
assign subsets of examples to appropriate child node– Repeat for each child node until all examples
associated with a node are either all positive or all negative
• Best attribute is one with highest information gain

29
CSC 8520 Spring 2010. Paula Matuszek
Choosing an attribute• Idea: a good attribute splits the examples into subsets that
are (ideally) "all positive" or "all negative"
• Patrons? is a better choice

30
CSC 8520 Spring 2010. Paula Matuszek
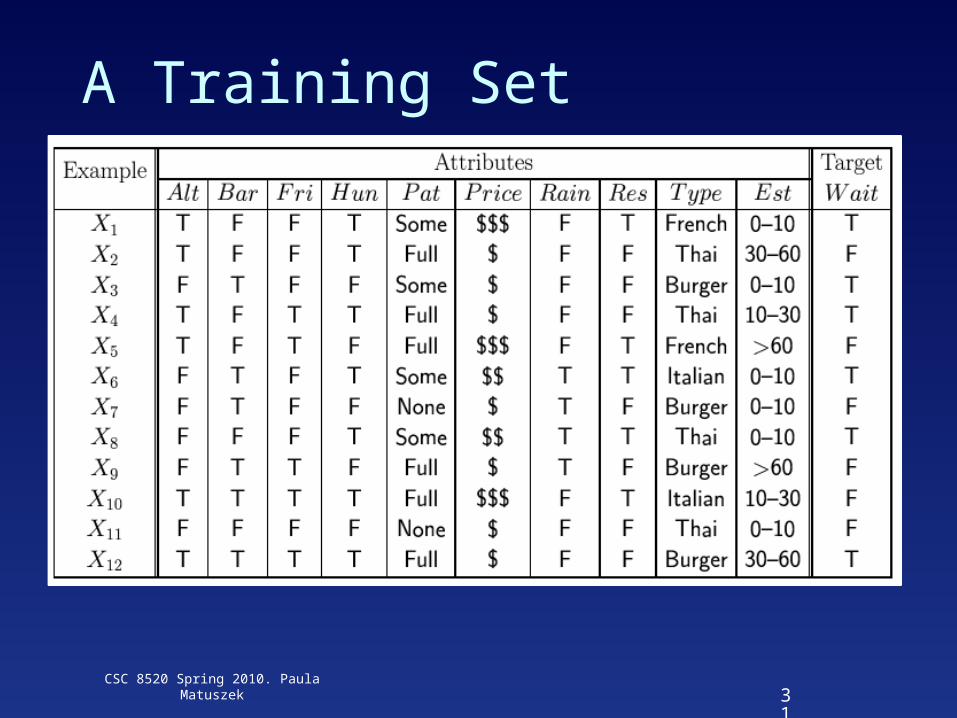
Textbook restaurant domain• Develop a decision tree to model the decision a patron
makes when deciding whether or not to wait for a table at a restaurant
• Two classes: wait, leave
• Ten attributes: Alternative available? Bar in restaurant? Is it Friday? Are we hungry? How full is the restaurant? How expensive? Is it raining? Do we have a reservation? What type of restaurant is it? What’s the purported waiting time?
• Training set of 12 examples
• ~ 7000 possible cases
31
CSC 8520 Spring 2010. Paula Matuszek
A Training Set

32
CSC 8520 Spring 2010. Paula Matuszek
A Decision Tree from Introspection

33
CSC 8520 Spring 2010. Paula Matuszek
Learned Tree
• Substantially simpler than “true” tree---a more complex hypothesis isn’t justified by small amount of data

34
CSC 8520 Spring 2010. Paula Matuszek
How well does it work?Many case studies have shown that decision trees are at least as accurate as human experts. – A study for diagnosing breast cancer had humans
correctly classifying the examples 65% of the time; the decision tree classified 72% correct
– British Petroleum designed a decision tree for gas-oil separation for offshore oil platforms that replaced an earlier rule-based expert system
– Cessna designed an airplane flight controller using 90,000 examples and 20 attributes per example

35
CSC 8520 Spring 2010. Paula Matuszek
Evaluating Classifying Systems
• Standard methodology:1. Collect a large set of examples (all with correct classifications)
2. Randomly divide collection into two disjoint sets: training and test
3. Apply learning algorithm to training set
4. Measure performance with respect to test set
• Important: keep the training and test sets disjoint!
• To study the efficiency and robustness of an algorithm, repeat steps 2-4 for different training sets and sizes of training sets
• If you improve your algorithm, start again with step 1 to avoid evolving the algorithm to work well on just this collection

36
CSC 8520 Spring 2010. Paula Matuszek
Strengths of Decision Trees• Strengths include
– Fast to learn and to use– Simple to implement– Can convert result to a set of easily
interpretable rules– Empirically valid in many commercial
products– Handles noisy data (with pruning)

37
CSC 8520 Spring 2010. Paula Matuszek
Weaknesses and Issues• Weaknesses include:
– Univariate splits/partitioning (one attribute at a time) limits types of possible trees
– Large decision trees may be hard to understand
– Requires fixed-length feature vectors – Non-incremental (i.e., batch method)– Overfitting

38
CSC 8520 Spring 2010. Paula Matuszek
Additional Decision Tree Factors• Overfitting: pruning eliminates leaves which are adding
little accuracy • Missing input factors: if output you are measuring doesn’t
depend on inputs you are capturing, won’t get good learning. Know your domain.
• Missing input data: ignore in information gain calculations• Multivalued and continuous inputs: modify information
gain calculations; find “split points” • Continuous outputs: Regression tree
C4.5 and C5.0 are extension of ID3 that accounts for unavailable values, continuous attribute value ranges, pruning of decision trees, rule derivation.

39
CSC 8520 Spring 2010. Paula Matuszek
Summary: Decision tree learning• One of most widely used learning methods in practice
• Can out-perform human experts in many problems
• Strengths include– Fast– Simple to implement– Can convert result to a set of easily interpretable rules– Empirically valid in many commercial products– Handles noisy data
• Weaknesses include:– Univariate splits/partitioning (one attribute at a time) limits types
of possible trees– Large decision trees may be hard to understand– Requires fixed-length feature vectors – Non-incremental (i.e., batch method)

40
CSC 8520 Spring 2010. Paula Matuszek
Learning by Analogy: Case-based Reasoning
• Case-based systems are a significant chunk of AI in their own right. A case-based system has two major components: – Case base
– Problem solver
• The case base contains a growing set of cases, analogous to either a KB or a training set.
• Problem solver has– A case retriever and
– A case reasoner.
• May also have a case installer.

41
CSC 8520 Spring 2010. Paula Matuszek
Case-based Reasoning• A case must be described in terms of a set of
features.
• Case-based reasoner – Follows or matches case as far as possible
– If that doesn’t lead to a solution, generalizes application of solution
– Combines solutions or features from several retrieved cases
• Can operate without reasoner by returning all retrieved cases to user

42
CSC 8520 Spring 2010. Paula Matuszek
Case-Based Retrieval• Cases are described as a set of features• Retrieval uses methods such as
– Nearest neighbor: compare all features to all cases in KB and choose closest match
– Indexed: compute and store some indices with each case and retrieve matching indices
– Domain-based model clustering: CB is organized into a domain model; insertion is harder, but retrieval is easier.
• Example: “documents like this one” – Features are the word frequencies in the document

43
CSC 8520 Spring 2010. Paula Matuszek
Case-based Reasoning
• Definition of relevant features is critical:– Need to get the ones which influence
outcomes– At the right level of granularity
• The reasoner can be a complex planning and what-if reasoning system, or a simple query for missing data.
• Only really becomes a “learning” system if there is a case installer as well.

44
CSC 8520 Spring 2010. Paula Matuszek
Unsupervised Learning• Typically used to refer to clustering
methods which don’t require training cases– No prior definition of goal– Typical aim is “put similar things together”
• Document clustering• Recommender systems• Grouping inputs to a customer response system
• Combinations of hand-modeled and automatic can work very well: Google News, for instance.
• Still requires good feature set

45
CSC 8520 Spring 2010. Paula Matuszek
REALLY Unsupervised Learning• Turn the machine loose to learn on its own• Needs
– A representation. Still need some idea of what we are trying to learn!
– Good natural language processing– A context
• People don’t learn very well unsupervised.• Currently some interesting research for instance-
level knowledge. • Much harder to acquire structural or relational
knowledge – but we are getting there.

46
CSC 8520 Spring 2010. Paula Matuszek
More Aspects of Machine Learning
• Machine learning varies by degree of human intervention:– Rote -- human builds KB. Cyc– Human assisted -- human adds knowledge
directed by machine. Animals, Teiresias– Human scored -- human provides training
cases. Neural nets, ID3, CART.– Completely automated. -- Nearest Neighbor,
other statistical groupings, data mining.

47
CSC 8520 Spring 2010. Paula Matuszek
More Aspects of Machine Learning• Machine Learning varies by degree of transparency
– Hand-built KBs are by definition clear to humans
– Human-aided trees like Animals are also generally clear and meaningful, could easily be modified by humans
– Inferred rules like ID3's are generally understood by humans but may not be intuitively obvious. Modifying them by hand may lead to worse results.
– Systems like neural nets are typically black box: you can look at the functions and weights but it's hard to interpret them in any human-meaningful way and essentially impossible to modify them by hand.

48
CSC 8520 Spring 2010. Paula Matuszek
More Aspects of Machine Learning• Machine learning varies by goal of the
process– Extend a knowledge base– Improve some kind of decision making, such as
guessing an animal or classifying diseases.– Improve overall performance of a program, such
as game playing– Organize large amounts of data– Find patterns or "knowledge" not previously
known, often to take some action.

49
CSC 8520 Spring 2010. Paula Matuszek
The Web• Machine learning is one of those fields
where the web is changing everything!• Three major factors
– One problematic aspect of machine learning research is finding enough data.
• This is NOT an issue on the web!
– Another problematic aspect is getting a critic• Web offers a lot of opportunities
– A third is identifying good practical uses for machine learning
• Lots of online opportunities here

50
CSC 8520 Spring 2010. Paula Matuszek
Finding Enough Data• The web is an enormous repository of machine-
readable data. What are some of the things we can we do with it?– Learn instance knowledge.
Searching for Common Sense, Matuszek et al, 2005.
– Learn categories. Acquisition of Categorized Named Entities for Web Search, Pasca, CIKM’04, Washington, DC, 2004.
– Learn new concepts. Strategies for Lifelong Knowledge Acquisition from the Web. Michele Banko and Oren Etzioni, K-CAP, Whistler, BC, 2007.

51
CSC 8520 Spring 2010. Paula Matuszek
Getting Critics• People spend a lot of time on the web• The success of sites like Wikipedia is evidence that people
are willing to volunteer time and effort– The Open Mind– TrueKnowledge– Learner– GWAP: The ESP game – And more academically:
AAAI Spring 2005 Symposium: Knowledge Collection from Volunteer Contributors (KCVC)
• At another level of involvement: environments where AIs can interact with humans– MUDs: Julia.– Chatbots: The Personality Forge– Online role-playing games: Genecys, Half Life.

52
CSC 8520 Spring 2010. Paula Matuszek
Online Uses for Machine Learning
• Improved search: learn from click-throughs.
• Recommendations: learn from peoples’ opinions and choices.
• Online games. AIs add to the background but can’t be too static.
• Better targeting for ads. More learning from click-throughs.
• Customer Response Centers. Clustering, improved retrieval of responses.

53
CSC 8520 Spring 2010. Paula Matuszek
Summary• Valuable both because we want to understand
how humans learn and because it improves computer systems
• May learn representation or actions or both• Variety of methods, some knowledge-based and
some statistical• Currently very active research area• Web is providing a lot of new opportunities• Still a long way to go


















