CS-2852 Data Structures LECTURE 13B Andrew J. Wozniewicz Image copyright © 2010 andyjphoto.com.
14
CS-2852 Data Structures LECTURE 13B Andrew J. Wozniewicz Image copyright © 2010 andyjphoto.com
-
Upload
hubert-lang -
Category
Documents
-
view
219 -
download
0
Transcript of CS-2852 Data Structures LECTURE 13B Andrew J. Wozniewicz Image copyright © 2010 andyjphoto.com.

CS-2852Data StructuresLECTURE 13B
Andrew J. Wozniewicz
Image copyright © 2010 andyjphoto.com

CS-2852 Data Structures, Andrew J. Wozniewicz
Agenda• Encodings• Morse Code• Huffman Trees

CS-2852 Data Structures, Andrew J. Wozniewicz
Character Encodings• UNICODE (6.0): Different Encodings– UTF-8• 8-bits per character for ASCII chars• Up to 4 bytes per character for other chars
– UTF-16• 2 bytes per character• Some characters encoded with 4 bytes

CS-2852 Data Structures, Andrew J. Wozniewicz
Character Encodings• Standard ASCII– 7 bits per character– 128 distinct values
• Extended ASCII– 8 bits per character– 256 distinct values
• EBCDIC (“manifestation of purest evil” – E. Raymond)
– 8 bits per character– IBM-mainframe specific

CS-2852 Data Structures, Andrew J. Wozniewicz
Fixed-Length Encoding• UTF-8, Extended ASCII: – 8 bits per character
• Always the same number of bits per symbol
• Log2 n bits per symbol to distinguish among n symbols
• More efficient encoding possible, if not all characters are equally likely to appear

CS-2852 Data Structures, Andrew J. Wozniewicz
Variable-Length Encoding

CS-2852 Data Structures, Andrew J. Wozniewicz
Morse Code• The length of each character in Morse
is approximately inversely proportional to its frequency of occurrence in English.
• The most common letter in English, the letter "E," has the shortest code, a single dot.

CS-2852 Data Structures, Andrew J. Wozniewicz
Prefix Codes• Design a code in such a way that no
complete code for any symbol is the beginning (prefix) for any other symbol.
• If the relative frequency of symbols in a message is known: efficient prefix encoding can be found
• Huffman encoding is a prefix code

CS-2852 Data Structures, Andrew J. Wozniewicz
Huffman Encoding• Lossless data compression algorithm• “Minimum-redundancy” code
by David Huffman (1952)• Variable-length code table• The technique works by creating a binary
tree of nodes.• The symbols with the lowest frequency
appear farthest away from the root. • The tree can itself be efficiently encoded and
attached with the message to enable decoding.
CS-2852 Data Structures, Andrew J. Wozniewicz
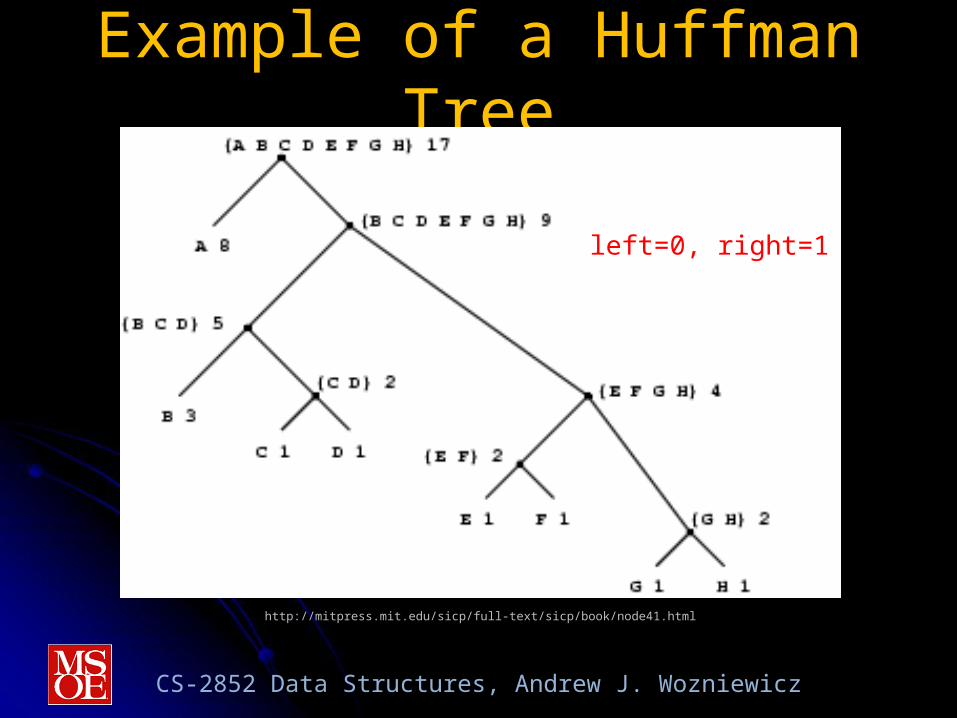
Example of a Huffman Tree
http://mitpress.mit.edu/sicp/full-text/sicp/book/node41.html
left=0, right=1

CS-2852 Data Structures, Andrew J. Wozniewicz
Huffman Algorithm• Begin with the set of leaf nodes,
containing symbols and their frequencies• Find two leaves with the lowest weights
and merge them to produce a node that has these two nodes as its left and right branches. – The weight of the new node is the sum of
the two weights• Remove the two leaves from the original
set and replace them by this new node.

CS-2852 Data Structures, Andrew J. Wozniewicz
Example of Huffman Tree-Building
Initial leaves {(A 8) (B 3) (C 1) (D 1) (E 1) (F 1) (G 1) (H 1)}Merge {(A 8) (B 3) ({C D} 2) (E 1) (F 1) (G 1) (H 1)}Merge {(A 8) (B 3) ({C D} 2) ({E F} 2) (G 1) (H 1)}Merge {(A 8) (B 3) ({C D} 2) ({E F} 2) ({G H} 2)}Merge {(A 8) (B 3) ({C D} 2) ({E F G H} 4)}Merge {(A 8) ({B C D} 5) ({E F G H} 4)}Merge {(A 8) ({B C D E F G H} 9)}Final merge {({A B C D E F G H} 17)}

CS-2852 Data Structures, Andrew J. Wozniewicz
Summary• Encodings• Morse Code• Huffman Trees

Questions?
Image copyright © 2010 andyjphoto.com