
Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
90
Implementing Data Flow in SQL Server Integration Services 2008 Course 10058
-
Upload
billyherrick -
Category
Documents
-
view
56 -
download
0
description
Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
Transcript of Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 1/90
Implementing Data Flow in
SQL Server Integration
Services 2008Course 10058

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 2/90

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 3/90
i
Table of Contents
Defining Data Sources and Destinations .............................................................................................1
Introduction .............................................................................................................................................. 1
Lesson Introduction .............................................................................................................................. 1
Lesson Objectives .................................................................................................................................. 1
Introduction to Data Flows ....................................................................................................................... 2
Data Flow Sources ..................................................................................................................................... 3
Object Linking and Embedding Database (OLE DB) .............................................................................. 3
Flat file ................................................................................................................................................... 3
Raw file .................................................................................................................................................. 4
Excel ...................................................................................................................................................... 4
XML ....................................................................................................................................................... 5
ADO.NET (ActiveX Data Objects)........................................................................................................... 5
Data Flow Destinations ............................................................................................................................. 7
Valid Data Destinations ......................................................................................................................... 7
Invalid Data Destinations ...................................................................................................................... 7
Configuring Access and Excel Data Sources .............................................................................................. 8
Excel ...................................................................................................................................................... 8
Access .................................................................................................................................................... 8
Data Flow Paths ............................................................................................................................... 10
Introduction ............................................................................................................................................ 10
Lesson Introduction ............................................................................................................................ 10
Lesson Objectives ................................................................................................................................ 10
Introduction to Data Flow Paths ............................................................................................................. 11
Data Viewers ........................................................................................................................................... 12
Grid ...................................................................................................................................................... 12
Histogram ............................................................................................................................................ 12
Scatter Plot .......................................................................................................................................... 12
Column Chart ...................................................................................................................................... 12
Implementing Data Flow Transformations: Part 1 ............................................................................. 13

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 4/90
ii
Introduction ............................................................................................................................................ 13
Lesson Introduction ............................................................................................................................ 13
Lesson Objectives ................................................................................................................................ 13
Introduction to Transformations ............................................................................................................ 14
Data Formatting Transformations .......................................................................................................... 15
Character Map transformation ........................................................................................................... 15
Data Conversion transformation ........................................................................................................ 16
Sort transformation ............................................................................................................................ 17
Aggregate transformation................................................................................................................... 17
Column Transformations ........................................................................................................................ 18
Copy Column transformation ............................................................................................................. 18
Derived Column transformation ......................................................................................................... 18
Import Column transformation........................................................................................................... 18
Export Column transformation ........................................................................................................... 19
Multiple Data Flow Transformations ...................................................................................................... 21
Conditional Split transformation ........................................................................................................ 21
Multicast transformation .................................................................................................................... 21
Merge transformation ........................................................................................................................ 22
Merge Join transformation ................................................................................................................. 22
Union All transformation .................................................................................................................... 22
Custom Transformations ........................................................................................................................ 23
Script Component transformation ...................................................................................................... 23
OLE DB Command transformation ...................................................................................................... 24
Slowly Changing Dimension Transformation .......................................................................................... 25
Implementing Data Flow Transformations: Part 2 ............................................................................. 26
Introduction ............................................................................................................................................ 26
Lesson Introduction ............................................................................................................................ 26
Lesson Objectives ................................................................................................................................ 26
Creating a Lookup and Cache Transformation ....................................................................................... 27
Data Analysis Transformations ............................................................................................................... 28
Pivot transformation ........................................................................................................................... 28
Unpivot transformation ...................................................................................................................... 28

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 5/90
iii
Data Mining Query transformation .................................................................................................... 29
Data Sampling Transformations.............................................................................................................. 30
Percentage Sampling transformation ................................................................................................. 30
Row Sampling transformation ............................................................................................................ 30
Row Count transformation ................................................................................................................. 31
Audit Transformations ............................................................................................................................ 32
Fuzzy Transformations ............................................................................................................................ 33
Fuzzy Lookup ....................................................................................................................................... 33
Fuzzy Grouping .................................................................................................................................... 33
Term Transformations ............................................................................................................................ 35
Term Extraction transformation ......................................................................................................... 35
Term Lookup transformation .............................................................................................................. 35
Best Practices .................................................................................................................................. 37
Lab: Implementing Data Flow in SQL Server Integration Services 2008 ............................................... 38
Lab Overview .......................................................................................................................................... 38
Lab Introduction .................................................................................................................................. 38
Lab Objectives ..................................................................................................................................... 38
Scenario................................................................................................................................................... 39
Exercise Information ............................................................................................................................... 40
Exercise 1: Defining Data Sources and Destinations ........................................................................... 40
Exercise 2: Working with Data Flow Paths .......................................................................................... 40
Exercise 3: Implementing Data Flow Transformations ....................................................................... 40
Lab Instructions: Implementing Data Flow in SQL Server Integration Services 2008 ............................. 41
Exercise 1: Defining Data Sources and Destinations ........................................................................... 41
Exercise 2: Working with Data Flow Paths .......................................................................................... 43
Exercise 3: Implementing Data Flow Transformations ....................................................................... 46
Lab Review .............................................................................................................................................. 50
What is the purpose of Data Flow paths? ........................................................................................... 50
What kind of errors can be managed by the error output Data Flow path? ...................................... 50
What data types does the Export Column transformation manage? ................................................. 50
What is the difference between a Type 1 and a Type 2 Slowly Changing Dimension and how are
they represented in the Slowly Changing Dimension transformation? .............................................. 50

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 6/90
iv
What is the difference between a Lookup and a Fuzzy Lookup transformation? .............................. 50
Module Summary ............................................................................................................................ 51
Defining Data Sources and Destinations ................................................................................................. 51
Data Flow Paths ...................................................................................................................................... 51
Implementing Data Flow Transformations: Part 1 ................................................................................. 52
Implementing Data Flow Transformations: Part 2 ................................................................................. 53
Lab: Implementing Data Flow in SQL Server Integration Services 2008 ................................................. 53
Glossary........................................................................................................................................... 54

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 7/90
1
Defining Data Sources and Destinations
Introduction
Lesson Introduction
SSIS provides support for a wide range of data sources and destinations within a package. The starting
point of a Data Flow task is to define the data source. This informs the Data Flow task of the location of
the data that will be moved. Dependent on the data source used, different properties must be
configured. Understanding the properties that are available within a data source will help you configure
them efficiently.
Data source destinations are objects within the Data Flow task that must be configured separately to
data sources. Like data sources, they consist of properties that need to be configured to inform SSIS of
the destination that the data will be loaded into. There are also additional data destinations such as
Analysis Services.
Lesson Objectives
After completing this lesson, you will be able to:
Describe data flows.
Use data flow sources.
Use data flow destinations.
Configure OLE DB data source.
Configure Microsoft Office Access and Microsoft Office Excel data sources.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 8/90
2
Introduction to Data Flows
Data flows are configured within the Data Flow task to determine the location of the source data the
destination that the data will be inserted into and optionally, any transformations that may be
performed on the data as it is being moved between the source and the destination.
SQL Server Integration Services starts by defining a data source. Depending on the data source chosen,different properties will have to be configured.
Typically, you would have to define connection information that would include the server name of the
source data and the database name if accessing a table within a database and the filename if the source
is a text or a raw file.
You can also define more than one data source.
You can then optionally add one or more transformations after the data source is defined.
Transformations are used to modify the data so that it can be standardized.
SQL Server Integration Services provides a wide variety of transformations to meet an organization’s
requirements.
Each transformation contains different properties to control how the data is changed.
You then define data destinations in which the transformed data is loaded into.
Like data sources, the properties that are configured will differ depending on the data destination
chosen and you are not limited to one data destination.
To connect data sources, transformations and data destinations together, you use Data Flow paths tocontrol the flow of the Data Flow tasks.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 9/90
3
Data Flow Sources
SSIS provides a range of data source connections that you can use to access the source data from a wide
variety of technologies. Additional sources are also available for download such as Microsoft Connectors
for Oracle and TERADATA by Attunity and Microsoft SQL Server 2008 Feature Pack.
Object Linking and Embedding Database (OLE DB)
Using OLE DB, you can access the data that exists with SQL Server, Access and Excel. You can also
connect to OLE DB providers for third-party databases. With OLE DB, you can access data directly from
tables or views within a database. You can also use SQL statements to specifically target the data that
you wish to return and take advantage of SQL clauses, such as ORDER BY, to retrieve the data.
Furthermore, parameters can be defined in the SQL statement by using ? (question marks) and mapping
the parameter to SSIS variables. The following properties can be configured:
Connection Manager page. Here, you can define a connection to the server, the database and
the authentication by clicking the New button. The Data Access Mode has a list where you can
define how to access the data. The options in the list can include selecting Table or View, TableName or View name from a variable, a SQL Command or a SQL Command from a variable.
Depending on what is selected, the options can change whereby you can select a specific table,
view, variable or you can manually type the SQL command. There is also a Preview button to
view the data.
Columns page. You can use this page to view the Available External Columns so you can choose
which columns is a part of the data source. They will appear under the External Columns if
selected. You can also rename the output of the column by typing in a different column name in
the Output Column list.
Error Output page. You can use this page to control the error handling options. Should the data
fail, you can ignore the failure, redirect the row or fail the component. This can be specified if
the error is caused by data truncation or general data errors. The Column property lists the
columns that are a part of the data source and you can add an optional description.
Flat file
You can connect to text files by using the Flat file data source connection. This allows you to control how
the text file is structured by defining the column and row delimiter. You can also define if the first row
contains headers and provide information about the width of the columns and the locale of the text file.
The following properties can be configured:
Connection Manager page. Here, you can define a connection to the text file by clicking the New
button. This opens up a Flat File Connection Manager Editor, where you can define the location
of the text file, the column and row delimiter, whether the text is qualified, the locale of the text
file and whether the first row contains headings. Once defined, you can preview the data by
clicking the Preview button. You can also specify whether null columns in the text file are
retained by selecting the check box next to Retain null values from the data source as null values
in the data flow.
Columns page. This page enables you to view the Available External Columns so you can choose
which columns is a part of the data source. If selected, they appear under the External Columns.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 10/90
4
You can also rename the output of the column by typing in a different column name in the
Output Column list.
Error Output page. You can use this page to control the error handling options. Should the data
fail, you can ignore the failure, redirect the row or fail the component. This can be specified if
the error is caused by data truncation or general data errors. The Column property lists the
columns that are part of the data source and you can add an optional description.
In the advance properties, the Fast Parse property provides a fast, simple set of routines for parsing
data. These routines are not locale-sensitive and they support only a subset of date, time and integer
formats. By implementing Fast Parse, a package forfeits its ability to interpret date, time and numeric
data in locale-specific formats.
Raw file
The Raw file data flow source is used to retrieve raw data that was previously written by the Raw File
Destination and allows for fast reading and writing of data and are typically used as an intermediary
data file in a larger data load operation. The Raw file source has less configuration options than the text
file, so no translation of the data is required providing the speed of data extraction. There is no error
output page for this data source, so there is little parsing of the data required. The following properties
can be configured:
Connection Manager page. Here, you can define a connection to the raw file by firstly specify
the Access mode; this can either be a filename or a filename from a variable. If Filename is
selected, you can then browse to the Raw file in the file system. If Filename from Variable is
selected, you can select the variable from a drop-down list.
Columns page. This page enables you to view the Available External Columns so that you can
choose which columns is a part of the data source. If selected, they appear under the External
Columns. You can also rename the output of the column by typing in a different column name in
the Output Column list.
Excel
Excel 2007 requires the OLE DB provider for the Microsoft Office 12.0 Access Database Engine OLE DB.
For earlier versions of Excel, use the Excel Source data source component. The options are similar to the
OLE DB data source, except that you point the connection manager to the Excel file. Any named ranges
that are defined in Excel are the equivalent of tables and views. The following properties can be
configured:
Connection Manager page. Here, you can define a connection to the Excel file by clicking the
New button and browsing to the Excel file in the Excel Connection Manager dialog box. The DataAccess Mode has a list where you can define how to access the data. The list can include
selecting Table or View, Table Name or View name from a variable, a SQL Command or a SQL
Command from a variable. Depending on what is selected, the options can change whereby you
can select a specific table, view, variable or you can manually type in the SQL command by using
the worksheet name as the equivalent to a table name in the FROM clause. There is also a
Preview button to view the data.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 11/90
5
Columns page. You can use this page to view the Available External Columns so that you can
choose which columns is a part of the data source. They appear under the External Columns, if
selected. You can also rename the output of the column by typing in a different column name in
the Output Column list.
Error Output page. You can use this page to control the error handling options. Should the data
fail, you can ignore the failure, redirect the row or fail the component. This can be specified if
the error is caused by data truncation or general data errors. The Column property lists the
columns that are part of the data source and you can add an optional description.
XML
The XML data source helps you retrieve data from an XML source document. You can also include that
the data is read from a schema that is either an inline schema or a separate XML Schema Definition
(XSD) file to ensure that the content of the XML meets with the data integrity checks within the schema.
Data Type Definition (DTD) files are not supported. Schemas can support a single namespace, and does
not support schema collections. The XML source does not validate the data in the XML file against the
XSD file. The following properties can be configured:
Connection Manager page. The Data Access Mode has a list where you can define how to access
the XML data. The list can include selecting XML File Location, XML file from a variable or an
XML Data from a variable. Depending on what is selected, the options can change whereby you
can select a specific file or variable from the list below the Data Access Mode. You can also
define if the XML file or fragment works in conjunction with an XSD file. This can either be
located in the existing XML data, in which case you can select the Use inline Schema check box
or you can refer to a separate XSD file by clicking on the Browse button next to the XSD Location
box. There is also a Preview button to view the data.
Columns page. You can use this page to view the Available External Columns so that you can
choose which columns is part of the data source. They appear under the External Columns, if
selected. You can also rename the output of the column by typing in a different column name inthe Output Column list.
Error Output page. You can use this page to control the error handling options. Should the data
fail, you can ignore the failure, redirect the row or fail the component. This can be specified if
the error is caused by data truncation or general data errors. The Column property lists the
columns that are part of the data source and you can add an optional description.
ADO.NET (ActiveX Data Objects)
You can use the ADO.NET source to connect to a database and retrieve data by using .NET. The options
that are available within the ADO.NET data source are very similar to the OLE DB data source and can
access the .NET provider for OLE DB to create a datareader, which enables you to have a single row of data loaded into memory. However, unlike the OLE DB data source, the ADO.NET data source can also
access non-OLE DB connections like .NET providers for ODBC data providers. The following properties
can be configured:
Connection Manager page. Here, you can define a connection to the server, the database and
the authentication by clicking the New button. The Data Access Mode has a drop-down list
where you can define how to access the data, which can include selecting Table or View, Table

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 12/90
6
Name or View name from a variable, a SQL Command or a SQL Command from a variable.
Depending on what is selected, the options can change whereby you can select a specific table,
view, variable or you can manually type in the SQL command. There is also a Preview button to
view the data.
Columns page. You can use this page to view the Available External Columns so that you can
choose which columns is part of the data source. They appear under the External Columns, if
selected. You can also rename the output of the column by typing in a different column name in
the Output Column list.
Error Output page. You can use this page to control the error handling options. Should the data
fail, you can ignore the failure, redirect the row or fail the component. This can be specified if
the error is caused by data truncation or general data errors. The Column property lists the
columns that are part of the data source and you can add an optional description.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 13/90
7
Data Flow Destinations
Valid Data Destinations
Excel
Recordset
Flat file
SQL Server
OLE DB
SQL Server compact
ADO.NET
Raw file
SQL Server Analysis Services (SSAS) partition
SSAS dimension
SSAS data mining training model
Invalid Data Destinations
SQL Server Reporting Services (SSRS)
Access
XML

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 14/90
8
Configuring Access and Excel Data Sources
Prior to working with the data sources in the Data Flow task, connection managers are created first so
that they can easily be used within the Data Flow task. There are considerations to be mindful of when
using Access and Excel in your SSIS package.
Excel
To connect to Excel, it is important to understand that different connection managers are used
depending on the version of Excel that you are connecting to. To connect to a workbook in Excel 2003 or
an earlier version of Excel, you must create an Excel connection manager from the Connection Managers
area.
To create an Excel connection manager, perform the following steps:
1. In Business Intelligence Development Studio, open the package.
2. In the Connections Managers area, right-click anywhere in the area, and then select New
Connection.3. In the Add SSIS Connection Manager dialog box, select Excel, and then configure the connection
manager.
To connect to a workbook in Excel 2007, you must create an OLE DB connection manager from the
Connection Managers area.
To create an OLE DB connection manager, perform the following steps:
1. In Business Intelligence Development Studio, open the package.
2. In the Connections Managers area, right-click anywhere in the area, and then select New OLE
DB Connection.
3. In the Configure OLE DB Connection Manager dialog box, click New.
4. In the Connection Manager dialog box, for Provider, select Microsoft Office 12.0 Access
Database Engine OLE DB.
Access
To connect to Access, it is important to understand that different connection managers are used
depending on the version of Access that you are connecting to. If you want to connect to a data source
in Access 2003 or an earlier version of Access, you must create an Access connection manager from the
Connection Managers area.
To create an Access connection manager, perform the following steps:
1. In Business Intelligence Development Studio, open the package.
2. In the Connections Managers area, right-click anywhere in the area, and then select New OLE
DB Connection.
3. In the Configure OLE DB Connection Manager dialog box, click New.
4. In the Connection Manager dialog box, for Provider, select Microsoft Jet 4.0 OLE DB Provider,
and then configure the connection manager as appropriate.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 15/90
9
If you want to connect to a data source in Access 2007, you must create an OLE DB connection manager
from the Connection Managers area. To create an OLE DB connection manager, perform the following
steps:
1. In Business Intelligence Development Studio, open the package.
2. In the Connections Managers area, right-click anywhere in the area, and then select New OLE
DB Connection.
3. In the Configure OLE DB Connection Manager dialog box, click New.
4. In the Connection Manager dialog box, for Provider, select Microsoft Office 12.0 Access
Database Engine OLE DB, and then configure the connection manager as appropriate.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 16/90
10
Data Flow Paths
Introduction
Lesson Introduction
Data Flow paths are similar to Control Flow paths in that they control the flow of data within a Data Flowtask. Data Flow paths can be simply used to connect a data source directly to a data destination.
Typically, you use a Data Flow path to determine the order in which a transformation takes place;
specifying the path that is taken should a transformation succeed or fail. This provides the ability to
separate the data that cause errors from the data that is being successfully transformed.
You can add data viewers to the Data Flow path. This enables you to get a snapshot of the data that is
being transformed. This is useful when developing packages when you wish to see the data before and
after it is transformed.
Lesson Objectives
After completing this lesson, you will be able to:
Describe Data Flow paths.
Configure a data flow path.
Describe a data viewer.
Use a data viewer.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 17/90
11
Introduction to Data Flow Paths
Data Flow paths play an important role in controlling the order that data is transformed between a
source connection and the destination connection.
Here you can control the flow of the data flow when a Data Flow component executes successfully, and
control the flow of the data when the Data Flow component fails. This enables you to create robust dataflows.
When a data source or transformation is added to the Data Flow Designer, a green arrow appears
underneath the Data Flow component.
You can click and drag the arrow to connect it another Data Flow component.
This will indicate that on successful execution of the first Data Flow component, the data flow can
provide input data to the next Data Flow component.
When this is done, a red arrow will appear under the original Data Flow component.
You can click and drag this to another Data Flow component, typically a data destination.
This will indicate an error output failure of the Data Flow component.
The data flow can provide a data flow input to the next Data Flow component that it is connected to.
In this manner, you can control the workflow of the Data Flow tasks by using the Data Flow paths.
The Data Flow paths can be configured by double-clicking on a Data Flow path. Properties can include
name and description.
You can also view the metadata of the data that is involved in the data flow.
Data viewers can also be configured so that you can view the data as it is passing through the data flow.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 18/90
12
Data Viewers
A data viewer is a useful debugging tool that enables you to view the data as it passes through the data
flow between two data flow components. You can apply data viewers to any data flow path so that you
can view the state of the data at each stage of the Data Flow task. Data viewers provide four different
methods for viewing the data.
A data viewer window shows data one buffer at a time. By default, the data flow pipeline limits buffers
to about 10,000 rows. If the data flow extracts more than 10,000 rows, it will pass that data through the
pipeline in multiple buffers. For example, if the data flow is extracting 25,000 rows, the first two buffers
will contain about 10,000 rows, and the third buffer will contain about 5,000 rows. You can advance to
the next buffer by clicking the green arrow in the data flow window.
Grid
The Grid data viewer type returns the data in rows and columns in a table. This is useful if you want to
view the impact that a transformation has had on the data.
The data viewer allows you to copy the data within the data viewer so that it can be stored in a separate
file such as an Excel file.
Histogram
Working with numeric data only, the Histogram data viewer type allows you to select one column from
the data flow. The histogram then displays the distribution of numeric data within the specified column.
This is useful if you wish to view the frequency that particular numeric values have within a specific
column. You can also copy the results to an external file.
Scatter Plot
The Scatter Plot data viewer type allows you to select two numeric columns from a data source. This
information is then plotted on the X-axis and Y-axis of a chart.
With this data viewer, you can see how the numeric data from the two columns are related to each
other. This information can be copied to an external file.
Column Chart
The Column Chart data viewer type allows you to select one column from the data flow. This presents a
column chart that shows the number of occurrences of a value within the data.
This can provide an indication of the data values that are stored within the data. The result can be
copied to an external file.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 19/90
13
Implementing Data Flow Transformations: Part 1
Introduction
Lesson Introduction
Data Flow transformations have the ability to ensure that your BI solution provides one version of thetruth when it comes to providing the data to the data warehouse. The transformations can be used to
change the format of data, sort and group data and perform custom transformations that will ensure
that the data is placed within the data warehouse as standardized format that can then be consumed
within Analysis Services as a cube, Reporting Services as reports or a combination of both.
Understanding the capabilities of the many transformations that are available will aid you in building a
trusted data warehouse.
Lesson Objectives
After completing this lesson, you will be able to:
Describe transformations.
Use data formatting transformations.
Use column transformations.
Use multiple Data Flow transformations.
Use custom transformations.
Implement transformations.
Use Slowly Changing Dimension transformation.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 20/90
14
Introduction to Transformations
Transformations are the unique aspect of SQL Server Integration Services within SQL Server that allows
you to change the data as the data is being moved from a source connection to a destination connection
such as a text file to a table within a database.
Transformations can be simple such as performing a straight copy of the data between a source and adestination.
It can be complex such as performing fuzzy lookups on the data being moved.
However, all can be used to standardize and cleanse the data; an important objective when loading a
data warehouse with data.
7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 21/90
15
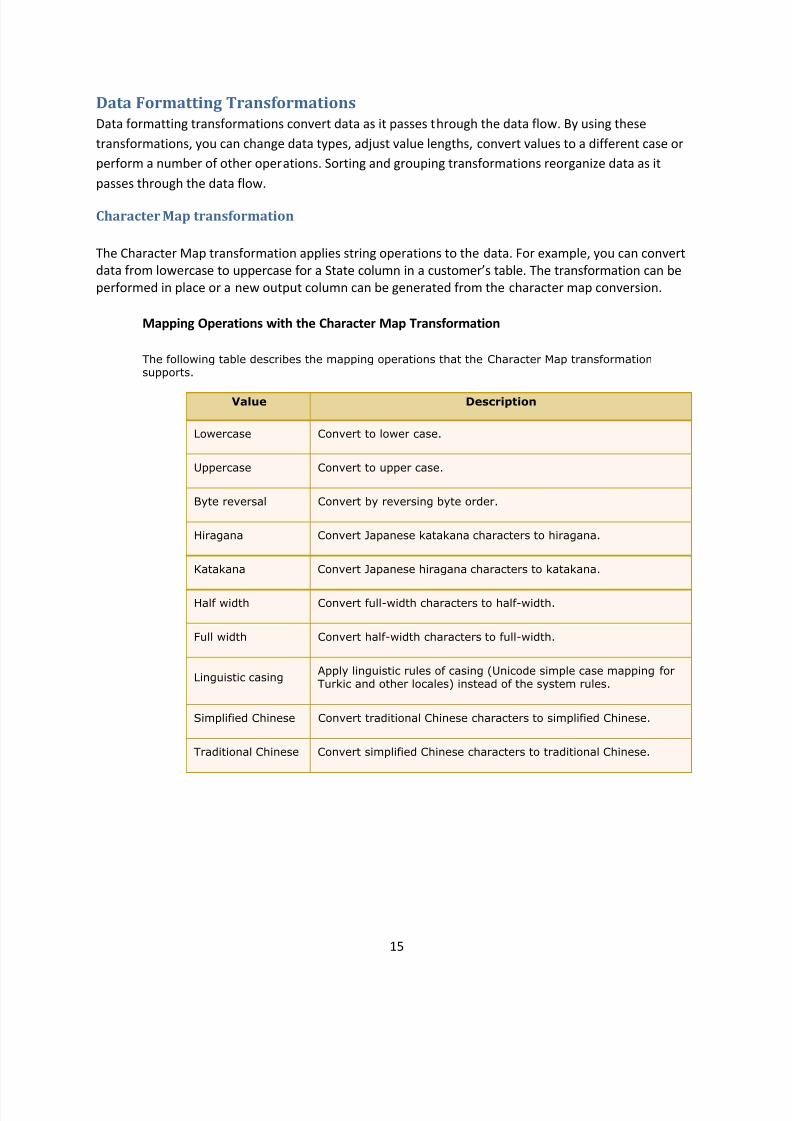
Data Formatting Transformations
Data formatting transformations convert data as it passes through the data flow. By using these
transformations, you can change data types, adjust value lengths, convert values to a different case or
perform a number of other operations. Sorting and grouping transformations reorganize data as it
passes through the data flow.
Character Map transformation
The Character Map transformation applies string operations to the data. For example, you can convert
data from lowercase to uppercase for a State column in a customer’s table. The transformation can be
performed in place or a new output column can be generated from the character map conversion.
Mapping Operations with the Character Map Transformation
The following table describes the mapping operations that the Character Map transformationsupports.
Value Description
Lowercase Convert to lower case.
Uppercase Convert to upper case.
Byte reversal Convert by reversing byte order.
Hiragana Convert Japanese katakana characters to hiragana.
Katakana Convert Japanese hiragana characters to katakana.
Half width Convert full-width characters to half-width.
Full width Convert half-width characters to full-width.
Linguistic casingApply linguistic rules of casing (Unicode simple case mapping forTurkic and other locales) instead of the system rules.
Simplified Chinese Convert traditional Chinese characters to simplified Chinese.
Traditional Chinese Convert simplified Chinese characters to traditional Chinese.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 22/90
16
Mutually Exclusive Mapping Operations
More than one operation can be performed in a transformation. However, some mapping
operations are mutually exclusive. The following table lists restrictions that apply when you use
multiple operations on the same column. Operations in the columns Operation A and Operation
B are mutually exclusive.
Operation A Operation B
Lowercase Uppercase
Hiragana Katakana
Half width Full width
Traditional Chinese Simplified Chinese
Lowercase Hiragana, katakana, half-width, full-width
Uppercase Hiragana, katakana, half-width, full-width
You use the Character Map Transformation Editor dialog box to make the changes by using the following
properties:
Available Input Columns. The Available Input Columns enables you to select the columns that
the operation will affect. When a column is selected, it appears in the Input Columns list.
Destination column. You use the Destination column to determine if the change will generate a
new column or the change is an in-place change.
Operation column. The Operation column provides a drop-down list to specify the operationthat occurs on the data such as Uppercase.
Output Alias column. The Output Alias column allows you to name the column name for a new
column destination or retains the same column name for transformations that are an in-place
change.
Data Conversion transformation
The Data Conversion transformation converts data from one data type to another during the data flow
and creates a new column with the new data. This can be useful when data is extracted from different
data sources and needs standardizing before being loaded into a single destination. Like the Character
Map transformation, this may cause some of the data to be truncated; you can use the Configure Error
Output option to handle such types of errors.
The Data Conversion task can be configured by using the following properties:
Available Input Columns. The Available Input Columns enables you to select the columns that
the operation will affect; when a column is selected, it appears in the Input Columns list.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 23/90
17
Output Alias column. The Output Alias column allows you to define a name for the new column.
You can then set the DataType, Length, Precision and Scale for the data to be converted.
Furthermore, the Code Page is used to define the code page for any columns that use the
DT_STR data type.
Sort transformation
The Sort transformation take data from an input and then sorts the data in ascending or descending
order when passed to the output. The Sort transformation can perform multiple sorts on different
columns within the same transformation and duplicate values can be removed from the Sort operation.
Any columns that are not part of the Sort operation are passed through to the transformation output.
Within the Sort Transformation Editor dialog box, the Available Input Columns enables you to select the
columns that the operation will affect. When a column is selected, it appears in the Input Columns list.
The Output alias defines the name of the output column, which is the same name as the input column
name. The Sort Type property determines if the Sort operation is ascending or descending and the Sort
Order property control which column is sorted first when multiple columns are defined. The lowest
number specified is the first column to be sorted. Comparison Flags can be set to ignore case and ignore
character width. To remove duplicate values, ensure that the Remove rows with duplicate sort values
check box is selected.
The Sort transformation does not support Error Output configuration.
Aggregate transformation
Not only does the Aggregate transformation apply aggregate functions to a set of numeric data to create
a new transformation output, it can also use the Transact-SQL Group By clause, which allows you to
apply aggregate functions to groups of data.
The Aggregate Transformation Editor dialog box contains two tabs that contain properties.
On the Aggregations tab, the Available Input Columns enables you to select the columns that the
operation will affect. When a column is selected, it appears in the Input Columns list. The Output alias
defines the name of the output column. The Operation column determines the aggregate function that
is used or the Group By operator can be defined. Comparison flags can be configured to refine the data
that is aggregated such as ignore spacing.
The Count Distinct Scale property can be used to count the approximate number of distinct values and
Count Distinct Keys properties can be used to provide an exact count of the distinct values.
Alternatively, by clicking the Advanced button, you can use the Key property to provide an exact countof the distinct values or Key Scales to provide an approximate count of the distinct values. These values
can be used to improve performance of the Aggregate transformation. This can be configured in the
Advanced tab as well.
The Aggregate transformation does not support Error Output.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 24/90
18
Column Transformations
Column transformations copy and create columns in the data flow. The transformations enable you to
import large files, such as images or documents, into the data flow or export the same to a file.
Copy Column transformation
The Copy Column transformation takes a data flow input and creates a new column as the
transformation output. You have the ability to create multiple copies of the same column.
The Copy Column Transformation Editor dialog box consists of the Available Input Columns property
that enables you to select the columns, which the Copy Column operation will affect. When a column is
selected, it appears in the Input Columns list. The Output alias allows you to define the name of the
output column.
The Copy Column transformation does not support Error Output configuration.
Derived Column transformation
The Derived Column transformation allows you to create a new column or replace values in an existing
column by using expressions to create a new column derived from a combination of variables, functions,
operators and columns from the transformation input. You can use this task to concatenate columns,
use functions to extrapolate information from existing input columns and perform mathematical
calculations.
The Derived Column Transformation Editor dialog box contains an expression editor used to create
expressions within the Expression property. The Derived Column property allows you to determine if the
operation will create a New Column or replace values in an Existing column. This setting affects the
Derived Column Name property that allows you to specify the name for the column. You can then set
the DataType, Length, Precision and Scale for the data to be derived. Furthermore, the Code Page is
used to define the code page for any columns that use the DT_STR data type.
The Derived Column transformation may cause some of the data to be truncated; you can use the
Configure Error Output to handle such types of errors.
Import Column transformation
The Import Column transformation reads data from a file and imports it to a column in the data flow.
This transformation does the opposite of the Export Column transformation by adding text and images
stored in separate files to a data flow.
The Import Column Transformation task contains three tabs:
Component Properties tab. The Component Properties tab allows you to define a Name and
Description for the task and configure the locale for the task by using the LocaleID property. The
ValidateExternalMetadata defines whether the transformation is validated against external data
during its design or when it is executed.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 25/90
19
Input Columns tab. The Input Columns tab consists of the Available Input Columns property that
enables you to select the columns that the copy column operation will affect. When a column is
selected, it appears in the Input Columns list. The Output alias allows you to define the name of
the output column. The Usage Type property defines if the data imported is READONLY data or
READWRITE data.
Input and Output Properties tab. The Input and Output Properties tab enables you to configure
additional properties for the input and output columns.
Export Column transformation
The Export Column transformation allows you to export images and documents that are stored within
the data flow and export them to a file. Specifically, the data types that can be exported to the file
include DT_IMAGE, DT_TEXT and DT_NTEXT.
The Export Column Transformation Editor dialog box contains the following properties. The Extract
Column property allows you to select the input column to be transferred. The File Path Column must
point to a column within the input columns that specifies the file name. Both of these properties are
mandatory. You can then use the Allow Append and Force Truncate check boxes to determine if a new
file with the images are created or an existing file is used, if present.
How the settings for the Append and Truncate options affect results
Append Truncate File exists Results
False False NoThe transformation creates a new file andwrites the data to the file.
True False NoThe transformation creates a new file andwrites the data to the file.
False True NoThe transformation creates a new file andwrites the data to the file.
True True NoThe transformation fails design timevalidation. It is not valid to set bothproperties to True.
False False YesA run-time error occurs. The file exists, butthe transformation cannot write to it.
False True YesThe transformation deletes and re-creates thefile and writes the data to the file.
True False YesThe transformation opens the file and writesthe data at the end of the file.
True True YesThe transformation fails design time
validation. It is not valid to set bothproperties to True.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 26/90
20
The Write Byte-Order Mark property specifies whether to write a byte-order mark (BOM) to the file. A
BOM is only written if the data has the DT_NTEXT or DT_WSTR data type and is not appended to an
existing data file.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 27/90
21
Multiple Data Flow Transformations
Multiple Data Flow transformations enable you to take a data input and separate the data based on an
expression. For example, in the Conditional Split transformation, if your data flow includes employee
information, you can split the data flow according to the cities in which the employees work. Multiple
Data Flow transformations also enables you to join data together. For example, you can bring data
together from separate data sources by using transformations such as Merge or Union All
transformations.
Conditional Split transformation
The Conditional Split transformation takes a single data flow input and creates multiple data flow
outputs based on multiple conditional expressions defined within the transformation. The order of the
conditional expression is important. If a record satisfies the first condition, the data is moved based on
that condition even if it meets the condition of the second expression. There, the record will no longer
be available to be evaluated against the second condition. Expression can be a combination of functions
and operators to define a condition.
The Conditional Split Transformation Editor dialog box contains an expression editor and a number of
properties that can be used to configure the conditional split. The Order property determines the order
in which the condition is evaluated. You can then provide Output Name for the data that is outputted by
the condition. The Condition property allows you to define an expression that defines the condition.
Examples include:
SUBSTRING(FirstName,1,1) == "A"
TerritoryID == 1
You can use the Configure Error Output to handle errors. Multicast transformation
The Multicast transformation allows you to output multiple copies of the same data flow input to
different data flow outputs. This transformation can be useful when you wish to output the same data
that will be transformed further down the data flow. For example, one output may then be summarized
using an aggregate transformation. The other output used as a basis to provide more detailed
information in a separate data flow.
The properties of the Multicast Transformation Editor dialog box can only be viewed once the outputs of
the transformation have been configured. Within the Editor, you are presented with an Outputs pane onthe left, which shows you the outputs the Multicast transform is generating. By selecting an output, the
Properties pane shows read-only information such as Identification String and ID property. The only
properties that you can change are the Name and Description properties.
The Multicast transformation does not support Error Output configuration.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 28/90
22
Merge transformation
The Merge transformation takes multiple inputs into the transformation and merges the data together
from the separate inputs. A prerequisite to the merge input working successfully is that the input
columns are sorted. Furthermore, the columns that are sorted must also be of compatible data types.
For example, you cannot merge the input that has a character data type with a second input that has anumeric data type.
The Merge Transformation Editor dialog box consists of a number of columns dependent on how many
inputs are connected to the Merge transformation. For example, if three inputs are defined, then four
columns will appear; if two inputs are defined, then three columns appear and so on. The first column is
the Output column that allows you to define a name for the output data flow. The second column is
called Merge Input 1. In this column, you map the input column to the output column. The third column
is called Merge Input 2; again, you map the input column to the output column. If more input columns
are defined, the number of Merge Input columns increase.
The Merge transformation does not support Error Output configuration.
Merge Join transformation
The Merge Join transformation is similar to the Merge transformation. However, you can make use of
the following Transact-SQL clauses to determine how the data is merged. The Transact-SQL clauses
include FULL, LEFT or INNER join. Like the Merge transformation, the input columns must be sorted and
the columns that are joined must have compatible data types. You must also specify the type of join the
Merge transformation will use and how it will handle nulls in the data.
The Merge Join Transformation Editor dialog box has at the top a Join Type drop-down list that allows
you to specify the type of join that will be used in the transformation. The Input property enables you to
select the columns that the Merge Join transformation operation will affect. When a column is selected,it appears in the Input Columns list and the Input column determine from which data flow input the data
is from. The Output alias allows you to define the name of the data flow output.
Union All transformation
The Union All transformation is very similar to the Merge transformation. The key difference is that the
Union All transformation does not require the input columns to be sorted. However, the columns that
are mapped must still have compatible data types.
The Union All Transformation Editor dialog box consists of a number of columns that are dependent on
how many inputs are connected to the Union All transformation. For example, if three inputs aredefined, then four columns will appear; if two inputs are defined, then three columns appear and so on.
The first column is the Output column that allows you to define a name for the output data flow. The
second column is called Union All Input 1. In this column, you map the input column to the output
column. The third column is called Union All Input 2; again, you map the input column to the output
column. If more input columns are defined the number of Union All Input columns increase.
The Union All transformation does not support Error Output configuration.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 29/90
23
Custom Transformations
Many of the transformations that are provided within SSIS will meet many of your business
requirements when performing ETL operations. There may be situations when the transformations
provided may not provide a solution. You can use the Script transformation to create custom
transformations by using .NET. The OLE DB Command transformation allows you to apply Transact-SQL
statements to data within a Data Flow path.
Script Component transformation
The Script Component transformation enables you to add custom data sources, transformations and
destinations by using .NET code, which can be programmed in Visual Basic (VB) 2008 or Visual C# 2008.
It is similar to the Script task within the control flow of an SSIS package but is used within the Data Flow
task.
In order to use the Script task, the local machine on which the package runs must have Microsoft Visual
Studio Tools for Applications installed. This provides a rich environment for building the custom scriptsincluding IntelliSense and its own Object Explorer. You can access Microsoft Visual Studio Tools for
Applications from within the Script Component on the Script page by clicking the Edit Script button. It is
also where you can define the Scripting Language. The Script page also allows you to specify a Name and
Description for the OLE DB Command task. You can also specify a locale with the LocaleID property and
whether the data flow is validated at run time or design time by using the ValidateExternalMetadata
property. You can also specify ReadOnlyVariables and ReadWriteVariables that are available to the
Script Component.
When the Script Component is added to the data flow, you are first prompted to select the Script
Component Type. This will determine if the Script Component is used as a Source, a Transformation or a
Destination and will affect the Script Component Editor. The following properties can be configured:
Input Columns tab. The Input Columns tab consists of the Input Name to determine the data
flow input to use. The Available Input Columns property that enables you to select the columns
which the Script Component operation will affect, when a column is selected it appears in the
Input Columns list. The Output alias allows you to define the name of the output column. The
Usage Type property defines if the data imported is READONLY data or READWRITE data.
Input and Output Properties tab. The Input and Output Properties tab allows you to set the
properties of the input and the output columns.
Connections Manager tab. The Connections Manager tab allows you to define connection
information that is used by the Script Component. This will include a Name and Description
property for the connection. The Connections Manager property allows you to select a
predefined connection manager or Add or Remove connection managers.
Note that the Script Component does not support error outputs.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 30/90
24
OLE DB Command transformation
The OLE DB Command transformation enables you to apply SQL statements to each row within the data
flow. The SQL statement can include data manipulation statements such as INSERT, UPDATE and
DELETE. The SQL statement can accept parameters that are represented as ? (question marks) within
the SQL statement. Each question mark will be called param_0, param_1 and so on. You can use the OLEDB Command transformation to make changes to the data as it passes through the data flow. For
example, a change in the tax rate for selling products can be updated by using the OLE DB Command
transformation as the data runs through the data flow. The changed data becomes the output of the
OLE DB Command transformation.
The Advanced Editor for OLE DB Command dialog box contains four tabs that allow you to configure the
transformation:
Connections Manager tab. The Connections Manager tab allows you to define connection
information that is used within the data flow. This includes a Name and Description property for
the connection. The Connections Manager property allows you to select a predefined
connection manager.
Component Properties tab. The Component Properties tab allows you to specify a Name and
Description for the OLE DB Command task. You can also specify a locale with the LocaleID
property and whether the data flow is validated at run time or design time by using the
ValidateExternalMetadata property. In this same area, the SQLCommand property is where the
SQL statement is defined. You can use property expression to define the content of the
SQLCommand property as well. The CommandTimeout defines the number of seconds the
command has to run and the DefaultCodePage property sets the code page for the SQL
statement.
Column Mappings tab. The Column Mappings tab allows you to map the columns from the data
flow input to the parameters that are defined in the SQLCommand property. This is done by
mapping the Available Input Columns to the Destination Columns. Input and Output Properties tab. The Input and Output Properties tab allows you to set the
properties of the input and the output columns.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 31/90
25
Slowly Changing Dimension Transformation
The Slowly Changing Dimension transformation performs a very important role when loading and
updating data within a dimension table within a data warehouse. Through the Slowly Changing
Dimension transformation, you can manage changes to the data.
Some of the data within a dimension data may remain static. As such, you can define this data as a fixedattribute. Any changes that occur to this data will be treated as an error.
The Slowly Changing Dimension transformation supports two types of Slowly Changing Dimension. Type
1 Slowly Changing Dimension is an overwrite of the original data. This is referred to as a changing
attribute within the wizard. Here, no historical content is retained and this is useful to overwrite invalid
data values.
Type 2 Slowly Changing Dimension is referred to as a historical changing attribute. Here, changing data
will generate a new row of data. The business key will be used to identify that the records are related.
The use of a start and end date is also used to indicate which record is the current record.
The Type 3 Slowly Changing Dimension will make use of an additional attribute within the record to
identify a records original value and an attribute for the most recent value. This is not supported directly
by the Slowly Changing Dimension Wizard. To overcome this, you can use a Slowly Changing Dimension
to identify a Type 3 column as fixed. On the output of these columns, you can then perform inserts and
updates on the column to perform Type 3 updates.
The Slowly Changing Dimension transformation task makes the process of managing dimension data
within a data warehouse straightforward.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 32/90
26
Implementing Data Flow Transformations: Part 2
Introduction
Lesson Introduction
Data Flow transformations can go beyond changing data by providing transformations that can performdata analysis, sampling and auditing.
Lesson Objectives
After completing this lesson, you will be able to:
Use Lookup and Cache transformation.
Use data analysis transformations.
Use data sampling transformations.
Use monitoring transformations.
Use fuzzy transformations. Use term transformations.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 33/90
27
Creating a Lookup and Cache Transformation
The Lookup transformation enables you to take information from an input column and then look up
additional information from another dataset that is linked to the input columns through a common
column. The dataset can be a table, view, SQL query or a cache file.
The Cache transformation has been introduced in SQL Server 2008. The Cache transformation can beused to improve the performance of a Lookup transformation by connecting to a data source and
population a cache file on the server on which the package runs. This means that the Lookup
transformation performs its lookup against the cache file rather than to a remote dataset. The Cache
transformation requires a connection manager to point to the .cache file and contains a Mappings tab
where you can map the input columns to the cache file. Note that one of the columns must be marked
as an index column.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 34/90
28
Data Analysis Transformations
SSIS provides a range of data transformations that enables you to analyze data, as shown in the table
below.
Pivot transformation
The Pivot transformation takes data from a normalized result set and presents the data in a cross
tabulated or denormalized structure. For example, a normalized Orders data set that lists customer
name, product and quantity purchased typically has multiple rows for any customer who purchased
multiple products, with each row for that customer showing order details for a different product. By
pivoting the data set on the product column, the Pivot transformation can output a data set with a
single row per customer. That single row lists all the purchases by the customer, with the product names
shown as column names, and the quantity shown as a value in the product column. Because not every
customer purchases every product, many columns may contain null values.
The Advanced Editor for Pivot dialog box contains three tabs to configure the properties:
Component Properties tab. The Component Properties tab allows you to specify a Name and
Description for the OLE DB Command Task. You can also specify a locale with the LocaleID
property and whether the data flow is validated at run time or design time by using the
ValidateExternalMetadata property.
Input Columns tab. The Input Columns tab consists of the Available Input Columns property that
enables you to select the columns that the Pivot transformation operation will affect. When a
column is selected, it appears in the Input Columns list. The Output alias allows you to define
the name of the output column. The Usage Type property defines if the data imported is
READONLY data or READWRITE data.
Input and Output Properties tab. The Input and Output Properties tab allows you to set the
properties of the input and the output columns. The most important property here is the
PivotUsage property. This determines what role the input column will play in creating the pivot
table and can be configured with the following values:
o 0. The column is not pivoted, and the values are passed through to the transformation
output.
o 1. The column is part of the set key that identifies one or more rows as part of one set.
o 2. The column is a pivot column. At least one column is created from each column value.
This data must be sorted input column.
o 3. The values from this column are placed in columns that are created because of the
pivot.
Unpivot transformation
The Unpivot transformation takes data from a denormalized or cross-tabulated result set and presents
the data in a normalized structure. The Unpivot transformation can be configured with the following
properties.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 35/90
29
At the bottom of the Unpivot Transformation Editor dialog box is the Pivot key value column name.
Here, you define a column heading for the column that will hold the pivoted data that is converted into
normalized data such as Products or Fruits.
The Available Input Columns property enables you to select the input columns that the Unpivot
transformation operation turns into rows. When a column is selected, it appears in the Input Columns
list. Any columns that are not selected are passed through to the data flow output. The Destination
Column allows you to define the name of the destination column in the normalized output.
In the Unpivot scenario, multiple input columns are usually mapped to one destination column. For
example, the Available Input Columns may consist of column headings such as Apples, Pears and
Peaches. All of these input columns are mapped to a destination column named Fruits that may be
defined by the Pivot key value column name property.
The Pivot Key value property specifies the value that is used in the rows in the normalized result set and,
by default, uses the same name as the input column but can be changed.
Data Mining Query transformation
The Data Mining Query transformation enables you to run Data Mining Expression (DMX) statements
that use prediction statements against a mining model. Prediction queries enable you to use data mining
to make predictions about sales or inventory figures as an example. You can then create a data flow
output of the results. One transformation can execute multiple prediction queries if the models are built
on the same data mining structure.
Mining Model tab. The Mining Model tab is used to provide an existing Connection to the
Analysis Services database. You can specify a new connection by clicking the New button. The
Mining Structure allows you to specify the Data Mining Structure that is to be used as a basis for
analysis. A list of mining models is then presented. Query tab. The Query tab allows you to write the DMX prediction query. A Build New Query
button is provided to build the DMX prediction query through a builder.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 36/90
30
Data Sampling Transformations
Data sampling transformations are useful when you want to extract sample data from the data flow or
you want to count the number of rows in the data flow. This can be useful in a number of different
scenarios. Ultimately, the objective is to create a small data output that can be used for testing or
development within the SSIS package.
Percentage Sampling transformation
The Percent Sampling transformation allows you to select a percentage of random rows from a data
flow input. This can be useful to generate a smaller set of data that is representative of the whole data
that can be used for development purposes. For example, in data mining, you can randomly divide a
data set into two data sets; one for training the data-mining model, and one for testing the model.
A random number determines the randomness. If you use the Random Seed property, you can specify a
number that the transformation will use. If you use the same number, it will always return the same
result set if the sampling is based on the same source data.
The Row Sampling transformation contains one screen that holds the properties to be configured.
You can specify the percentage number of rows to take from the data flow input by using the
Percentage of Rows property. You can also provide a name for the data flow outputs generated for both
the Sample Output Name and the Unselected Output Name. You can define your own random seed by
specifying a value in the Specify random seed value property.
Row Sampling transformation
The Row Sampling transformation allows you to select an exact number of random rows from a data
flow input. This can be useful to generate a smaller set of data that is representative of the whole datathat can be used for development purposes. For example, a company can randomly select 50 employees
to receive Christmas prizes for a calendar year against employee database to generate the exact number
of winners.
A random number determines the randomness. If you use the Random Seed property, you can specify a
number that the transformation uses. If you use the same number, it always returns the same result set
if the sampling is based on the same source data.
The Row Sampling transformation contains two pages that hold properties to be configured:
Sampling page. The Sampling page allows you to specify the exact number of rows to take fromthe data flow input by using the Number of Rows property. You can also provide a name for the
data flow outputs generated for both the Sample Output Name and the Unselected Output
Name. You can define your own random seed by specifying a value in the Specify random seed
value property.
Columns page. The Columns page consists of the Available Input Columns property that enables
you to select the columns that the Row Sampling transformation operation affects. When a
column is selected, it appears in the Input Columns list. The Output alias allows you to define
the name of the output column.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 37/90
31
Row Count transformation
A Row Count transformation counts the rows that pass through the data flow and stores the result of
the count in a variable. This variable can then be used elsewhere in the SSIS package. The following
properties can be configured:
Component Properties tab. The Component Properties tab allows you to specify a Name and
Description for the OLE DB Command task. You can also specify a locale with the LocaleID
property and whether the data flow is validated at run time or design time by using the
ValidateExternalMetadata property. The most important property here is the Variable property.
You use this to map the result of the Row Count transformation to a user-defined variable.
Input Columns tab. The Input Columns tab consists of the Available Input Columns property that
enables you to select the columns that the Row Count operation affects. When a column is
selected, it appears in the Input Columns list. The Output alias allows you to define the name of
the output column. The Usage Type property defines if the data imported is READONLY data or
READWRITE data.
Input and Output Properties tab. The Input and Output Properties tab allows you to set the
properties of the input and the output columns.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 38/90
32
Audit Transformations
The Audit transformation allows you to create additional output columns within the data flow that holds
metadata about the SSIS package. This information can be used to provide metadata information that
maps to system variables, which exist within the SSIS package. The following information is available
within the Audit transformation and appears in a drop-down list in the AuditType property:
ExecutionInstanceGUID
PackageID
PackageName
VersionID
ExecutionStartTime
MachineName
UserName
TaskName
TaskId
The only other property to configure in the Audit transformation is the Output Column Name that allows
you to define a name for the columns that are used in the data flow output.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 39/90
33
Fuzzy Transformations
Fuzzy transformations can be very useful for improving the data quality of existing data as well as new
data that is being loaded into your database.
Fuzzy Lookup
The Fuzzy Lookup transformation performs data cleansing tasks such as standardizing data, correcting
data and providing missing values.
Using the fuzziness capability that is available to the Fuzzy Grouping transformation, this logic can be
applied to Lookup operations so that it can return data from a dataset that may closely match the
Lookup value required. This is what separates the Fuzzy Lookup transformation from the Lookup
transformation, which requires an exact match. Note that the connection to SQL Server must resolve to
a user who has permission to create tables in the database.
The Fuzzy Lookup Transformation Editor dialog box consists of three tabs to configure:
Reference Table tab. The Reference Table tab allows you to define connection information that
is used within the data flow. This includes an OLE DB Connection Manager property for the
connection. The Reference table property allows you to select the reference table. You can also
choose whether to create new or use existing indexes with the Store New Index or Use Existing
Index Property.
Columns tab. The Columns tab consists of the Available Input Columns and Available Lookup
Columns property that enables you to select the columns that the Fuzzy Lookup transformation
operation affects. When a column is selected in the Available Lookup Columns, it appears in the
Lookup Columns list. The Output alias allows you to define the name of the output column.
Advanced tab. The Advanced tab sets the Similarity threshold property, which is a slider. The
closer the threshold is to one, the more the rows must resemble each other to qualify as
duplicates. You can also tokenize data using the Token delimiters property.
Fuzzy Grouping
The Fuzzy Group transformation allows you to standardize and cleanse data by selecting likely duplicate
data and comparing it to an alias row of data that is used to standardize the input data. As a result, a
connection is required to SQL Server, as the Fuzzy Group transformation requires a temporary table to
perform its work.
The Fuzzy Group transformation allows you to perform an exact match or a fuzzy match. An exact match
means that the data must exactly match for it to be part of the same group. A fuzzy match groups data
together that is approximately the same. You can determine the fuzziness by configuring numerousproperties to determine how dissimilar data values can be.
The Fuzzy Group Transformation Editor dialog box consists of three tabs:
Connection Managers tab. The Connection Managers tab allows the Fuzzy Group transformation
to create the temporary table required to perform the Fuzzy Group transformation. You use the

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 40/90
34
OLE DB Connection Manager property to point to an existing OLE DB connection or click on New
to create a new OLE DB connection.
Columns tab. The Columns tab consists of the Available Input Columns property that enables
you to select the columns that the Fuzzy Grouping transformation operation affects. When a
column is selected, it appears in the Input Columns list. The Output alias allows you to define
the name of the output column. The Group Output Alias allows you to define a group name for
the data that is grouped together. The Match Type property defines the type of fuzzy operation
that is conducted, which can be exact or fuzzy. You can determine the fuzziness by using the
Minimum Similarity property, a value close to one means that the data is nearly similar and you
use the Similarity Output Alias that generates a new output column that contains the similarity
scores for the selected join. You can specify how leading and trailing values are evaluated by
using the Numerals property and Comparison Flags can be used to ignore spaces or character
widths.
Advanced tab. The Advanced tab sets the Input key column name for the output column that
contains the unique identifier for each input row; Output key column name for the output
column that contains the unique identifier for the alias row of a group of duplicate rows; and
Similarity score column name for the name for the column that contains the similarity score. The
Similarity threshold property is a slider. The closer the threshold is to one; the more the rowsmust resemble each other to qualify as duplicates. You can also tokenize data by using the
Token delimiters property.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 41/90
35
Term Transformations
You have the ability to extract nouns only, noun phrases only or both nouns and noun phases from
descriptive columns with the Term Extraction and Term Lookup transformation.
Term Extraction transformation
The Term Extraction transformation allows data flow inputs to be compared to a built-in dictionary to
extract nouns only, noun phrases only or both nouns and noun phases. However, a noun phrase can
include two words, one word, a noun and the other an adjective. It can also stem nouns to extract the
singular noun from a plural noun, so cars become car. This extraction formulates the basis of the data
flow output. This capability is only available with the English language.
The Term Extraction Transformation Editor dialog box contains three tabs to configure:
Term Extraction tab. The Term Extraction tab specifies a text column that contains text to be
extracted. The Available Input Columns property enables you to select the columns that the
Term Extraction transformation operation affects. You can define an output column name forthe Term that is extracted by using the Term property. The Score property allows you to define a
column name for the score that is assigned to the extracted term column.
Exclusion tab. The Exclusion tab allows you to point to a table that consists of a list of terms that
are excluded from the term extraction. This includes an OLE DB Connection Manager property
for the connection. The Table or View and Column property allows you to select the column
within the table that holds the exclusion terms.
Advanced tab. The Advanced tab allows you to set the term extraction type by using the Term
Type property set to nouns only, noun phrases only or both nouns and noun phases. The Score
type property sets the basis for scoring the terms by using frequency or Term Frequency Inverse
Document Frequency (TFIDF: a term scoring algorithm). You can specify case-sensitive
extractions and set Parameters for the Frequency Threshold, which specifies the frequency a
word must appear before it is extracted and the Maximum length of Term, which defines the
maximum number of characters in a word to perform the term extraction on.
Term Lookup transformation
The Term Lookup transformation can perform an extraction of terms from a reference table rather than
the built-in dictionary. It counts the number of times a term in the Lookup table occurs in the input data
set, and writes the count together with the term from the reference table to columns in the
transformation output.
Reference Table tab. The Reference Table tab allows you to define connection information that is used
within the data flow. This includes an OLE DB Connection Manager property for the connection. TheReference table property allows you to select the reference table.
Term Lookup tab. The Term Lookup tab consists of the Available Input Columns and Available Reference
Columns property that enables you to select the columns that the Term Lookup transformation
operation affects. When a column is selected in the Available Input Columns, it appears in the Pass
through Columns list. The Output Column alias allows you to define the name of the output data flow
column.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 42/90
36
Advanced tab. The Advanced tab has the Use case-sensitive term lookup to add case sensitivity to the
Term Lookup transformation.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 43/90
37
Best Practices
Use the correct data sources from the Data Flow Sources section in the Business Intelligence
Development Studio Toolbox that will extract data.
Use the correct data destinations from the Data Flow Destinations section in the BusinessIntelligence Development Studio Toolbox that will load the data.
Use OLE DB data sources to connect to SQL Server tables, the Access database and Excel 2007
spreadsheet.
Use the ADO.NET data source to connect to ODBC data sources and destinations.
Identify the transformation required to meet the data load requirements.
Use in-built transformations when possible.
Use the Script component Data Flow transformation to create custom data source, data
destinations or transformations.
Use Data Flow paths to control transformations within the Data Flow transformations.
Use the Slowly Changing Dimension transformation to manage changing data in dimension
tables in a data warehouse. Use the Lookup transformation to load a fact table in a data warehouse with the correct data.
Use the Cache transformation in conjunction with the Lookup transformation to improve the
performance of loading fact tables.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 44/90
38
Lab: Implementing Data Flow in SQL Server Integration Services 2008
Lab Overview
Lab Introduction
The purpose of this lab is to focus on using data flows within an SSIS package to populate a simple datawarehouse. You will firstly edit an existing package to add data sources and destinations and use
common transformation to complete the loading of the StageProduct table. You will also implement a
data viewer in this package and run the package to ensure that data is being loaded correctly into the
ProductStage table. You will then create the dimension tables in the data warehouse focusing
specifically on the Slowly Changing Dimension task to manage changing data in the dimension tables.
You will finally explore how to populate the fact table within the data warehouse by using the Lookup
transformation to ensure that the correct data is being loaded into the fact table.
Lab Objectives
After completing this lab, you will be able to:
Define data sources and destinations.
Work with data flow paths.
Implement data flow transformations.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 45/90
39
Scenario
You are a database professional for Adventure Works, a manufacturing company that sells bicycle and
bicycle components through the Internet and a reseller distribution network. You are continuing to work
on using SSIS to populate a simple data warehouse for testing purposes in a database named
AdventureWorksDWDev.
You want to complete the AWStaging package by configuring the Data Flow task that will load data into
the ProductStage table. You will implement simple transformations that you think you will use in the
production data warehouse. To verify that the transformations are working, you will add data viewers to
the data path to view the data before and after the transformation has occurred.
You will then edit the package named AWDataWarehouse. You will firstly edit a Data Flow task to
explore common transformations that are used within the data flow. However, you want to explore the
use of the Slowly Changing Dimension task to manage data changes when transferring data from the
ProductStage to the ProductDim table.
Finally, you will edit the LoadFact Data Flow task that will populate the FactSales table, which will use a
Lookup transformation to ensure that the correct data is loaded into the fact table.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 46/90
40
Exercise Information
Exercise 1: Defining Data Sources and Destinations
In this exercise, you will complete the configuration of the AWStaging package by configuring the Data
Flow task that will populate the ProductStage table. You will define the data source as the
AdventureWorks2008 database. You will then use transformations to ensure that the data that is cleanlyloaded into the ProductStage table. You will then define the data destination as the ProductDim table in
the AdventureworksDWDev database.
Exercise 2: Working with Data Flow Paths
In this exercise, you will add an error Data Flow path from the AdventureWorksDWDev StageProduct
Data Flow task to a text file named StageProductLoadErrors.txt located in D:\Labfiles\Starter folder. You
will add a data viewer before and after the Category Uppercase Character Map transformation. You will
then run the package and review the data viewer before and after the Category Uppercase Character
Map transformation runs to view the differences in the data. After completing the review, you will
remove the data viewers.
Exercise 3: Implementing Data Flow Transformations
In this exercise, you will edit the package AWDataWarehouse. You will firstly edit the Generate Resellers
Data Data Flow task to explore common transformations that are used within the data flow. However,
you want to explore the use of the Slowly Changing Dimension task to manage changes of data when
transferring data from the ProductStage to the ProductDim table that is defined within the Generate
Product Data Data Flow task.
Finally, you will edit the Generate FactSales Data Data Flow task that will populate the FactSales table
that will use a Lookup transformation to ensure that the correct data is loaded into the fact table.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 47/90
41
Lab Instructions: Implementing Data Flow in SQL Server Integration Services
2008
Exercise 1: Defining Data Sources and Destinations
Exercise Overview
In this exercise, you will complete the configuration of the AWStaging package by configuring thedata flow task that will populate the ProductStage table. You will define the data source as the
AdventureWorks2008 database. You will then use transformations to ensure that the data that isloaded into the ProductStage table is done so cleanly. You will then define the data destination asthe ProductDim table in the AdventureworksDWDev database.
Task 1: You are logged on to MIAMI with the username Student and password Pa$$w0rd.
Proceed to the next task
Log on to the MIAMI server.
a. To log on to the MIAMI server, press CTRL+ALT+DELETE.
b. On the Login screen, click the Student icon.
c. In the Password box, type Pa$$w0rd and then click the Forward button.
Task 2: Open Business Intelligence Development Studio and open the solution file AW_BI
solution located in D:\Labfiles\Starter\AW_BI folder
1. Open the Microsoft Business Intelligence Development Studio.
2. Open the AW_BI solution file in D:\Labfiles\Starter\AW_BI folder.
Task 3: Open the AWStaging package in the AW_SSIS project in the AW_BI solution
Open the AWStaging package in Business Intelligence Development Studio.
Task 4: Edit the Load Products Data Flow task and add an OLE DB Source to the data flow
designer that is configure to retrieve data from the Production.Product table in the
AdventureWorks2008 database
1. Open the Load Products Data Flow Designer in the AWStaging package in BusinessIntelligence Development Studio.
2. Add an OLE DB Source data flow source from the Toolbox onto the Data Flow Designer.Name the OLE DB Source data flow source AdventureWorks2008 Products.
3. Edit the AdventureWorks2008 Products OLE DB data source by retrieving the ProductID,
Name, SubCategory name, Category name, ListPrice, Color, Size, Weight,DaystoManufacture, SellStartDate and SellEndDate form the Production.Product,Production.ProductSubcategory and Production.ProductCategory table in theAdventureWorks2008 database. Add a WHERE clause that will return all products greaterthan the date stored in the ProductLastExtract variable.
4. Save the AW_BI solution.
Task 5: Add a Character Map transformation to the Load Products Data Flow Designer that
is configured to transform the data in the Category column to uppercase. Name the
transformation Category Uppercase and set the Data Flow path from the
AdventureWorks2008 Products Data Flow task to the Category Uppercase transformation
1. Add a Character Map transformation from the Toolbox onto the Data Flow Designer. Namethe Character Map transformation Category Uppercase.
2. Set the Data Flow path from the AdventureWorks2008 Products Data Flow task to theCategory Uppercase transformation.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 48/90
42
Task 6: Edit the Category Uppercase Character Map transformation to change the
character set of the Category column to uppercase
1. Edit the Category Uppercase Character Map transformation to change the character set of the Category column to uppercase.
2. Save the AW_BI solution.
Task 7: Edit the Load Products Data Flow task and add an OLE DB Destination to the Data
Flow Designer named AdventureWorksDWDev StageProduct. Then set the Data Flow path
from the Category Uppercase transformation to the AdventureWorksDWDev StageProduct
OLE DB Destination
1. Add an OLE DB Source data flow destination from the Toolbox onto the Data Flow Designer.Name the OLE DB Source data flow source AdventureWorksDWDev StageProduct.
2. Set the Data Flow path from the Category Uppercase transformation to theAdventureWorksDWDev StageProduct OLE DB Destination.
Task 8: Edit the AdventureWorksDWDev StageProduct OLE DB Destination to load the
data into the StageProduct table and remove the Check constraints option
1. Edit the AdventureWorksDWDev StageProduct OLE DB Destination to load the data into the
StageProduct table in the AdventureWorksDWDev database.
2. Edit the AdventureWorksDWDev StageProduct OLE DB Destination by performing columnmapping between the source and destination data.
3. Save and close the AW_BI solution.
Task 9: You have completed all tasks in this exercise
A successful completion of this exercise results in the following outcomes:
a. You have created an OLE DB Source data flow source.
b. You have created a Transact-SQL statement to query the source data.
c. You have created a simple character map transformation.
d. You have created an OLE DB Destination data flow destination.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 49/90
43
Exercise 2: Working with Data Flow Paths
Exercise Overview
In this exercise, you will add an error Data Flow path from the AdventureWorksDWDevStageProduct Data Flow task to a text file named StageProductLoadErrors.txt located inD:\Labfiles\Starter folder. You will then add a data viewer before and after the Category Uppercase
Character Map transformation. You will then run the package and then review the data viewer priorto the Category Uppercase Character Map transformation running and after the Category UppercaseCharacter Map transformation to view the differences in the data. Once completing the review, youwill then remove the data viewers.
Task 1: Open Business Intelligence Development Studio and open the solution file AW_BI
solution located in D:\Labfiles\Starter\AW_BI folder
1. Open the Microsoft Business Intelligence Development Studio.
2. Open the AW_BI solution file in D:\Labfiles\Starter\AW_BI folder.
Task 2: Open the AWStaging package in the AW_SSIS project in the AW_BI solution
Open the AWStaging package in Business Intelligence Development Studio.
Task 3: Edit the Load Products Data Flow task and add a Flat File Destination to the DataFlow Designer that is configure to a text file located in the D:\Labfiles\Starter folder
named StageProductLoadErrors.txt
1. Open the Load Products Data Flow Designer in the AWStaging package in BusinessIntelligence Development Studio.
2. Add a Flat File Destination data flow destination from the Toolbox onto the Data FlowDesigner. Name the Flat File Destination data flow destination StageProduct Load Errors.
Task 4: Create an Error Data Flow path from the AdventureWorksDWDev StageProduct
OLE DB Destination StageProduct Load Errors Flat File Destination
Set the Data Flow path from the AdventureWorksDWDev StageProduct OLE DB Destinationto the StageProduct Load Errors Flat File Destination.
Task 5: Edit the StageProduct Load Errors Flat File Destination creating a connection to
the StageProductLoadErrors.txt located in D:\Labfiles\Starter folder. Name the
connection StageProduct Errors
1. Configure the StageProduct Load Errors Flat File Destination to create a text file namedStageProductLoadErrors.txt located in D:\Labfiles\Starter. Name the connectionStageProduct Errors.
2. Review the column mappings between the AdventureWorksDWDev StageProduct OLE DBDestination and the StageProduct Load Errors Flat File Destination.
Task 6: Edit the AdventureWorksDWDev StageProduct OLE DB Destination to redirect
rows when an error is encountered
Configure AdventureWorksDWDev StageProduct OLE DB Destination to redirect rows when
errors are encountered in the data flow.
Task 7: Add a Grid Data Viewer in the Data Flow path between the AdventureWorks2008
Products OLE DB Source and the Category Uppercase Character Map transformation
Add a Grid Data Viewer in the Data Flow path between the AdventureWorks2008 ProductsOLE DB Source and the Category Uppercase Character Map transformation.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 50/90
44
Task 8: Add a Grid Data Viewer in the Data Flow path between the Category Uppercase
Character Map transformation and the AdventureworksDWDev StageProduct OLE DB
Destination. Then save the AW_BI solution
1. Add a Grid Data Viewer in the Data Flow path between the Category Uppercase CharacterMap transformation and the AdventureworksDWDev StageProduct OLE DB Destination.
2. Save the AW_BI solution.
Task 9: Execute the Load Products Data Flow task to view the data viewers to confirm
that the transform has worked correctly. Observe the data load into the StageProduct
table of the AdventureWorksDWDev database and for any records that have failed verify
that the data has loaded into the StageProductLoadErrors.txt file located in the
D:\Labfiles\Starter folder
1. Execute the Load Products Data Flow task and view the data viewers that execute.
2. View the AdventureWorksDWDev StageProduct OLE DB Destination and confirm that 295rows are inserted into the StageProduct table.
3. View the data in the StageProduct table in the AdventureWorksDWDev database by usingSQL Server Management Studio.
4. Confirm that the StageProductLoadErrors.txt file located in D:\Labfiles\Starter foldercontains 50 records.
Task 10: Clean out the data from the StageProduct table and the
StageProductLoadErrors.txt file. Remove the Data viewers and correct the error that is
Occurring with the LoadProducts Data Flow task
1. In Notepad, delete the data within the StageProductLoadErrors.txt text file.
2. Remove the data from the StageProduct table in the AdventureWorksDWDev database.
In the Query Window, type in the following code.
USE AdventureWorksDWDev
GO
DELETE FROM StageProduct
GOSELECT * FROM StageProduct
3. Stop debugging in Business Intelligence Development Studio and remove the data viewersfrom the Load Products Data Flow task.
4. Edit the AdventureWorks2008 Products OLE DB data source by changing the query toreplace Null values returned in the Color column with the value of None.
Task 11: Clean out the data from the StageProduct table and the
StageProductLoadErrors.txt file. Remove the Data viewers and correct the error that is
Occurring with the LoadProducts Data Flow task
1. Execute the Load Products Data Flow task.
2. Confirm that the StageProductLoadErrors.txt file located in D:\Labfiles\Starter foldercontains 0 records.
3. View the data in the StageProduct table in the AdventureWorksDWDev database by usingSQL Server Management Studio.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 51/90
45
4. Remove the data from the StageProduct table in the AdventureWorksDWDev database.
In the Query Window, type in the following code.
USE AdventureWorksDWDev
GO
DELETE FROM StageProduct
GO
SELECT * FROM StageProduct
Task 12: Save and close the AW_BI solution in Business Intelligence Development Studio
Save and close the AW_BI solution.
Task 13: You have completed all tasks in this exercise
A successful completion of this exercise results in the following outcomes:
a. You have created and configured an error data path.
b. You have added data viewers to the Data Flow path.
c. You have observed the effects of Data Flow paths.
d. You have corrected errors in a data flow and observed the successful completion of
a Data Flow path.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 52/90
46
Exercise 3: Implementing Data Flow Transformations
Exercise Overview
In this exercise, you will edit the package AWDataWarehouse. You will firstly edit the GenerateResellers Data Data Flow task to explore common transformations that are used within the dataflow. However, you want to explore the use of the Slowly Changing Dimension task to manage
changes of data when transferring data from the ProductStage to the ProductDim table that isdefined within the Generate Product Data Data Flow task. Finally, you will edit the GenerateFactSales Data Data Flow task that will populate the FactSales table that will use a lookuptransformation to ensure that the correct data is loaded into the fact table.
Task 1: Open Business Intelligence Development Studio and open the solution file AW_BI
solution located in D:\Labfiles\Starter\AW_BI folder
1. Open the Microsoft Business Intelligence Development Studio.
2. Open the AW_BI solution file in D:\Labfiles\Starter\AW_BI folder.
Task 2: Open the AWDataWarehouse package in the AW_SSIS project in the AW_BI
solution
Open the AWStaging package in Business Intelligence Development Studio.
Task 3: Edit the Generate Resellers Data Data Flow task in the AWDataWarehouse
package and add a OLE DB Source to the Data Flow Designer that is configure to retrieve
data from the dbo.StageReseller table in the AdventureWorksDWDev database
1. Open the Generate Resellers Data Flow task in the AWDataWarehouse package in BusinessIntelligence Development Studio.
2. Add an OLE DB Source data flow source from the Toolbox onto the Data Flow Designer.Name the OLE DB Source data flow source AdventureWorksDWDev StageResellers.
3. Edit the AdventureWorksDWDev StageResellers OLE DB data source by retrieving allcolumns from the StageReseller table in the AdventureWorksDWDev database.
4. Save the AW_BI solution.
Task 4: Add a Conditional Split transformation that will keep all of the Resellers with anAddressType of Main Office within the dimension table data load and output other
address types to a text file named NonMainOffice.txt in the D:\Labfiles\Starter folder.
Name the Conditional Split transformation MainOffice
1. Add a Conditional Split transformation from the Toolbox onto the Data Flow Designer. Namethe Conditional Split transformation Main Office data.
2. Configure the MainOffice Conditional Split transformation to identify records that have anAddressType of Main Office and those records that do not.
3. Create the Flat File Destination and name the Flat File Destination NonMainOffices.
4. Set the Data Flow path from the MainOffice Conditional Split transformation to theNonMainOffices Flat File Destination.
Task 5: Add a Sort transformation named CountryRegionSort below the MainOfficeConditional Split transformation and drag a Data Flow path from the MainOffice
Conditional Split transformation to the CountryRegionSort Sort transformation
1. Add a Sort transformation from the Toolbox onto the Data Flow Designer. Name the Sorttransformation Main Office data.
2. Set the Data Flow path from the MainOffice Conditional Split transformation to theNonMainOffices Flat File Destination.
3. Configure the CountryRegionSort Sort transformation to sort by CountryRegionName.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 53/90
47
Task 6: Edit the Generate Reseller Data Data Flow task and add an OLE DB Destination to
the Data Flow Designer named AdventureWorksDWDev DimReseller. Then set the Data
Flow path from the CountryRegionSort transformation to the AdventureWorksDWDev
DimReseller OLE DB Destination
1. Add an OLE DB Source data flow destination from the Toolbox onto the Data Flow Designer.
Name the OLE DB Source data flow source AdventureWorksDWDev DimReseller.2. Set the Data Flow path from the Category Uppercase transformation to the
AdventureWorksDWDev StageProduct OLE DB Destination.
Task 7: Edit the AdventureWorksDWDev DimReseller OLE DB Destination to load the data
into the DimReseller table and remove the Check constraints option
1. Edit the AdventureWorksDWDev StageProduct OLE DB Destination to load the data into theStageProduct table in the AdventureWorksDWDev database.
2. Edit the AdventureWorksDWDev DimReseller OLE DB Destination by performing columnmapping between the source and destination data.
3. Save the AW_BI solution.
Task 8: Edit the Generate Product Data Data Flow task in the AWDataWarehouse package
and add an OLE DB Source to the Data Flow Designer that is configured to retrieve datafrom the dbo.StageProduct table in the AdventureWorksDWDev database
1. Open the Generate Product Data Data Flow task in the AWDataWarehouse package inBusiness Intelligence Development Studio.
2. Add an OLE DB Source data flow source from the Toolbox onto the Data Flow Designer.Name the OLE DB Source data flow source AdventureWorksDWDev StageProducts.
3. Edit the AdventureWorksDWDev StageProducts OLE DB data source by retrieving allcolumns from the StageProduct table in the AdventureWorksDWDev database.
4. Save the AW_BI solution.
Task 9: Edit the Generate Product Data Data Flow task in the AWDataWarehouse package
and add a Slowly Changing Dimension task that loads data into the DimProduct table and
treats the Category and Subcategory data as changing attributes and theEnglishProductName as a historical attribute. All remaining columns will be treated as a
fixed attribute
1. Open the Generate Product Data Data Flow task in the AWDataWarehouse package inBusiness Intelligence Development Studio.
2. Add a Slowly Changing Dimension Data Flow task to the Data Flow Designer and thencreate a Data Flow path from the AdventureWorksDWDev StageProducts OLE DB datasource to the Slowly Changing Dimension.
3. Run a Slowly Changing Dimension wizard selecting DimProduct as the destination table andProductAlternateKey column as the business key.
4. In the Slowly Changing Dimension wizard, treat the Category and Subcategory data aschanging attributes and the EnglishProductName as a historical attribute. All remaining
columns will be treated as a fixed attribute.5. In the Slowly Changing Dimension wizard, set the wizard to fail transformations with
changes to fixed attributes and use start and end dates to identify current and expiredrecords based on the System::StartTime variable. Disable the inferred members support.
6. Save the AW_BI solution.
Task 10: Review the FactSales table in the AdventureWorksDWDev database removing
the ExtendedAmount, UnitPriceDiscountPct, TotalProductCost and TaxAmount columns.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 54/90
48
Then, edit the Generate FactSales Data Data Flow task to load the FactSales table with
the correct data
1. Open SQL Server Management Studio and view the columns in the FactSales table of theAdventureWorksDWDev database.
2. Maximize Business Intelligence Development Studio and add an OLE DB data source to theAdventureWorks2008 database within the Generate FactSales Data Data Flow task thatuses the SourceFactLoad.sql file located in D:\Labfiles\Starter.
3. Use a Data Conversion transformation to convert the following columns that will be loadedinto the FactSales table in the AdventureWorksDWDev database:
ProductID integer data type to a Unicode string (25) with an output nameProductIDMapping.
BusinessEntityID integer data type to a Unicode string (25) with an output nameResellerIDMapping.
Convert the SalesOrderNumber to a Unicode string (20) with an output name of StringSalesOrderNumber.
Covert the SalesOrderLineNumber to a single byte unsigned integer with an outputname of TinyIntSalesOrderLineNumber.
Convert the UnitPriceDiscount column to a double-precision float data type with anoutput name of cnv_UnitPriceDiscount.
Convert the LineTotal column to a currency data type with an output name of cnv_LineTotal.
4. Add a Lookup Task within the Generate FactSales Data Data Flow task that will look up theProduct Dimension Key based on the ProductAltenateKey.
5. Add a Lookup Task within the Generate FactSales Data Data Flow task that will look up theReseller Dimension Key based on the BusinessEntityID.
6. Add a Raw File destination within the Generate FactSales Data Data Flow task that will beused as the error output for the ResellerKey Lookup task.
7. Add a Lookup Task within the Generate FactSales Data Data Flow task that will look up theTime Key based on the Orderdate column.
8.
Add a Lookup Task within the Generate FactSales Data Data Flow task that will look up theTime Key based on the DueDate column.
9. Add a Lookup Task within the Generate FactSales Data Data Flow task that will look up theTime Key based on the ShipDate column.
10. Add an OLE DB Destination to the data flow and map the input columns correctly to thecolumns in the SalesFact table of the AdventureWorksDWDev database.
Map the following Available Input Columns to the Available Destination Columns:
Available Input Columns Available Destination Column
ProductKey ProductKey
OrderDate Lookup.TimeKey OrderDateKey
DueDate Lookup.TimeKey DueDateKey
ShipDate Lookup.TimeKey ShipDateKey
ResellerKey ResellerKey
StringSalesOrderNumber SalesOrderNumber
TinyIntSalesOrderLineNumber SalesOrderLineNumber

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 55/90
49
RevisionNumber RevisionNumber
OrderQty OrderQuantity
UnitPrice UnitPrice
Cnv_UnitPriceDiscount DiscountAmount
StandardCost ProductStandardCost
Cnv_LineTotal SalesAmount
11. Save the AW_BI solution.
Task 11: Execute the LoadAWDW package that contains the Execute Package tasks that
controls the load of the AdventureWorksDWDev data warehouse and review the data in
the database by using SQL Server Management Studio
1. Open Business Intelligence Development Studio, execute the LoadAWDWDev package.
2. Save and close the AW_BI solution.
Task 12: You have completed all tasks in this exercise
A successful completion of this exercise results in the following outcomes:
You have opened Business Intelligence Development Studio and opened a data flowcomponent within a package.
You have added an OLE DB data source within a data flow.
You have added a conditional split transformation to a data flow task.
You have added a sort transformation to a data flow task.
You have added and edited an OLE DB data destination within a data flow.
You have added and edited a slowly changing dimension transformation.
You have added and edited a lookup transformation to load a fact table with datawithin a data warehouse.
You have added and edited execute package task to control the load of data into adata warehouse.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 56/90
50
Lab Review
In this lab, you used data flows within an SSIS package to populate a simple data warehouse. You firstly
edited an existing package to add data sources and destinations and use common transformation to
complete the loading of the ProductStage table. Then, you implemented a data viewer in this package
and ran the package to ensure that data was loaded correctly into the ProductStage table.
You then created the dimension tables in the data warehouse focusing specifically on the Slowly
Changing Dimension task to manage changing data in the dimension tables. You finally explored to
populate the fact table within the data warehouse by using the Lookup transformation to ensure that
the correct data was loaded into the fact table.
What is the purpose of Data Flow paths?
Data Flow paths are used to control the flow of data within the Data Flow task. You can define a success
Data Flow path represented by a green arrow, which will move the Data Flow path onto the next data
flow component. You can also use an error output Data Flow path to control the flow of data when an
error occurs.
What kind of errors can be managed by the error output Data Flow path?
You can define errors or truncation errors to be managed by the error output Data Flow path.
What data types does the Export Column transformation manage?
The DT_IMAGE, DT_TEXT and DT_NTEXT data types. The Export Column transformation moves this type
of data stored within a table to a file.
What is the difference between a Type 1 and a Type 2 Slowly Changing Dimension and how
are they represented in the Slowly Changing Dimension transformation?
Type 1 is a Slowly Changing Dimension that will overwrite data values within a dimension table. As a
result, no historical data is retained. In the Slowly Changing Dimension Wizard, this is referred to as a
Changing Attribute.
Type 2 Slowly Changing Dimension will insert a new record when the value in a dimension table
changes. As a result, historical data is retained. This is referred to as a Historical Attribute in the Slowly
Changing Dimension Wizard.
What is the difference between a Lookup and a Fuzzy Lookup transformation?
The Lookup transformation enables you to take information from an input column and then look up
additional information from another dataset that is linked to the input columns through a common
column.
Fuzzy Lookup transformation uses logic that can be applied to Lookup operations so that it can return
data from a dataset that may closely match the Lookup value required.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 57/90
51
Module Summary
Defining Data Sources and Destinations
In this lesson, you have learned the following key points:
The ETL operation uses data sources to retrieve the source data, transformations to change the
data and data destinations to load the data into a destination database.
The range of data flow source that enables SSIS to connect to a wide range of data sources
include:
o OLEDB to connect to SQL Server, Microsoft Access 2007 and Microsoft Excel 2007
o Flat file to connect to text and csv files
o Raw file to connect to raw file sources created by raw file destinations
o Microsoft Excel to connect to Microsoft Office Excel 97 –2002
o XML to connect to XML data sources
o ADO.Net sources to connect to a database to create a datareader
The data flow destinations that are available in SSIS include:o OLEDB to connect to SQL Server, Microsoft Access 2007 and Microsoft Excel 2007
o Flat file to connect to text and csv files
o Raw file to connect to raw file sources created by raw file destinations
o Microsoft Excel to connect to Microsoft Office Excel 97 – 2002
o XML to connect to XML data sources
o ADO.Net sources to connect to a database to create a datareader
You can configure an OLE DB Data Source to retrieve data from SQL Server 2008 objects defining
a server name, authentication method and database name.
You can configure data sources for Access by using the OLEDB data source.
You can configure data sources for specific versions of Excel by using OLEDB and Microsoft Excel
data sources and destinations.
Data Flow Paths
In this lesson, you have learned the following key points:
Data flow paths can be used to control the flow of data flows and transformations in an SSIS
package using success data flow paths and error data flow paths.
You can create data flow paths and use them to create inputs into other data flow components.
In addition, you can use data flow paths to create error data flow outputs by clicking and
dragging the data flow path between different data flow components.
Data viewers help you to view the data before and after transformations take place to verify
that, the transformations are working as expected.
The types of data viewers available to check the data within the data flow include:
o Grid that returns the data in rows and columns in a table
o Histogram works with numeric data only, allowing you to select one column from the
data flow

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 58/90
52
o Scatter Plot works with two numeric columns from a data source, providing the X-axis
and Y-axis of a chart
o Column Chart allows you to select one column from the data flow that presents a
column chart that shows the number of occurrences
You can create data viewers with SSIS to view the data flow as the package executes.
Implementing Data Flow Transformations: Part 1
In this lesson, you have learned the following key points:
Transformations in SSIS allow you to change the data as the data is being moved from a source
connection to a destination connection. They can also be used to standardize and cleanse the
data.
You can modify data by using the data formatting transformations, including:
o Character Map transformation for simple data transforms such as uppercase or
lowercase
o Data conversion transformation to convert data in the data flow
o Sort transformation to sort the data ascending or descending within the data flow
o Aggregate transformation that enables you to create a scalar results set or use in
conjunction with a Group By clause to return multiple results
You can manipulate column data by using column transformations, including:
o Copy transformation to copy data between a source and a destination
o Derived Column transformation to create a new column of data
o Import column transformation
o Export column transformation
You can manage the data flow by using Multiple Data Flow transformations, including:
o Conditional Split transformation to separate data based on an expression that acts as acondition for the split
o Multicast transformation that enables you to generate multiple copies of the same data
o Merge transformation that enables you to merge sorted data
o Merge Join transformation that enables you to merge sorted data based on a join
condition
o Union All transformation that enables you to merge unsorted data
You can create custom data sources, destinations and data transformations by using Custom
transformations, including:
o Script transformation that allows you to create custom data sources, destinations and
data transformations using Visual Basic or C#
o
OLE DB command transformation to issue OLE DB commands You can implement simple transformations in the Data Flow of SSIS.
You can use the Slowly Changing Dimension transformation to manage changing data within a
dimension table in a data warehouse.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 59/90
53
Implementing Data Flow Transformations: Part 2
In this lesson, you have learned the following key points:
You can create Lookup and Cache transformations in SQL Server 2008. The Lookup
transformation helps you to take information from an input column and then look up additionalinformation from another dataset that is linked to the input columns through a common column
managing data in a data warehouse. The Cache transformation is used to improve the
performance of a Lookup transformation.
You can analyze data within the data flow by using Data Analysis transformations, including:
o Pivot transformation to create a crosstab result set
o Unpivot transformation to create a normalized result set
o Data Mining Query transformation to use data mining extension to perform data
analysis
You can create a sample of data using Data Sampling transformations, including:
o Percentage Sampling transformation to generate a sample of data based on a
percentage value
o Row Sampling transformation to generate a sample of data based on a set value
o Row Count transformation enables you to perform a row count of data and pass the
value to a variable
Audit Transformation is used to add metadata information to the data flow.
Fuzzy transformations can be used to help standardize data, including:
o Fuzzy Lookup to perform lookups of data against data that mat not exactly match
o Fuzzy Grouping to group data together that are candidates for the same type of data
You can use Term transformations to extract nouns and noun phrases from within the data flow,
including:
o Term Extraction transformation
o Term Lookup transformation
Lab: Implementing Data Flow in SQL Server Integration Services 2008
In this lab, you used data flows within an SSIS package to populate a simple data warehouse. You firstly
edited an existing package to add data sources and destinations and use common transformation to
complete the loading of the ProductStage table. Then, you implemented a data viewer in this package
and ran the package to ensure that data was loaded correctly into the ProductStage table.
You then created the dimension tables in the data warehouse focusing specifically on the Slowly
Changing Dimension task to manage changing data in the dimension tables. You finally explored theways to populate the fact table within the data warehouse by using the Lookup transformation to
ensure that the correct data was loaded into the fact table.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 60/90
54
Glossary
.NET Framework
An integral Windows component that supports building, deploying and running the next generation of applications and Web services. It provides a highly productive, standards-based, multilanguage
environment for integrating existing investments with next generation applications and services, as well
as the agility to solve the challenges of deployment and operation of Internet-scale applications. The
.NET Framework consists of three main parts: the common language runtime, a hierarchical set of
unified class libraries and a componentized version of ASP called ASP.NET.
ad hoc report
An .rdl report created with report builder that accesses report models.
aggregation
A table or structure that contains precalculated data for a cube.
aggregation design
In Analysis Services, the process of defining how an aggregation is created.
aggregation prefix
A string that is combined with a system-defined ID to create a unique name for a partition's aggregation
table.
ancestor
A member in a superior level in a dimension hierarchy that is related through lineage to the current
member within the dimension hierarchy.
attribute
The building block of dimensions and their hierarchies that corresponds to a single column in a
dimension table.
attribute relationship
The hierarchy associated with an attribute containing a single level based on the corresponding column
in a dimension table.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 61/90
55
axis
A set of tuples. Each tuple is a vector of members. A set of axes defines the coordinates of a
multidimensional data set.
ActiveX Data Objects
Component Object Model objects that provide access to data sources. This API provides a layer between
OLE DB and programming languages such as Visual Basic, Visual Basic for Applications, Active Server
Pages and Microsoft Internet Explorer Visual Basic Scripting.
ActiveX Data Objects (Multidimensional)
A high-level, language-independent set of object-based data access interfaces optimized for
multidimensional data applications.
ActiveX Data Objects MultiDimensional.NET
A managed data provider used to communicate with multidimensional data sources.
ADO MD
See Other Term: ActiveX Data Objects (Multidimensional)
ADOMD.NET
See Other Term: ActiveX Data Objects MultiDimensional.NET
AMO
See Other Term: Analysis Management Objects
Analysis Management Objects
The complete library of programmatically accessed objects that let and application manage a running
instance of Analysis Services.
balanced hierarchy
A dimension hierarchy in which all leaf nodes are the same distance from the root node.
calculated column
A column in a table that displays the result of an expression instead of stored data.
calculated field
A field, defined in a query, that displays the result of an expression instead of stored data.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 62/90
56
calculated member
A member of a dimension whose value is calculated at run time by using an expression.
calculation condition
A MDX logical expression that is used to determine whether a calculation formula will be applied against
a cell in a calculation subcube.
calculation formula
A MDX expression used to supply a value for cells in a calculation subcube, subject to the application of
a calculation condition.
calculation pass
A stage of calculation in a multidimensional cube in which applicable calculations are evaluated.
calculation subcube
The set of multidimensional cube cells that is used to create a calculated cells definition. The set of cells
is defined by a combination of MDX set expressions.
case
In data mining, a case is an abstract view of data characterized by attributes and relations to other
cases.
case key
In data mining, the element of a case by which the case is referenced within a case set.
case set
In data mining, a set of cases.
cell
In a cube, the set of properties, including a value, specified by the intersection when one member is
selected from each dimension.
cellset
In ADO MD, an object that contains a collection of cells selected from cubes or other cellsets by a
multidimensional query.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 63/90
57
changing dimension
A dimension that has a flexible member structure, and is designed to support frequent changes to
structure and data.
chart data region
A report item on a report layout that displays data in a graphical format.
child
A member in the next lower level in a hierarchy that is directly related to the current member.
clickthrough report
A report that displays related report model data when you click data within a rendered report builder
report.
clustering
A data mining technique that analyzes data to group records together according to their location within
the multidimensional attribute space.
collation
A set of rules that determines how data is compared, ordered and presented.
column-level collation
Supporting multiple collations in a single instance.
composite key
A key composed of two or more columns.
concatenation
The combining of two or more character strings or expressions into a single character string or
expression, or to combine two or more binary strings or expressions into a single binary string or
expression.
concurrency
A process that allows multiple users to access and change shared data at the same time. SQL Server uses
locking to allow multiple users to access and change shared data at the same time without conflicting
with each other.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 64/90
58
conditional split
A restore of a full database backup, the most recent differential database backup (if any), and the log
backups (if any) taken since the full database backup.
config file
See Other Term: configuration file
configuration
In reference to a single microcomputer, the sum of a system's internal and external components,
including memory, disk drives, keyboard, video and generally less critical add-on hardware, such as a
mouse, modem or printer.
configuration file
A file that contains machine-readable operating specifications for a piece of hardware or software, orthat contains information about another file or about a specific user.
configurations
In Integration Services, a name or value pair that updates the value of package objects when the
package is loaded.
connection
An interprocess communication (IPC) linkage established between a SQL Server application and an
instance of SQL Server.
connection manager
In Integration Services, a logical representation of a run-time connection to a data source.
constant
A group of symbols that represent a specific data value.
container
A control flow element that provides package structure.
control flow
The ordered workflow in an Integration Services package that performs tasks.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 65/90
59
control-break report
A report that summarizes data in user-defined groups or breaks. A new group is triggered when
different data is encountered.
cube
A set of data that is organized and summarized into a multidimensional structure defined by a set of
dimensions and measures.
cube role
A collection of users and groups with the same access to a cube.
custom rollup
An aggregation calculation that is customized for a dimension level or member, and that overrides the
aggregate functions of a cube's measures.
custom rule
In a role, a specification that limits the dimension members or cube cells that users in the role are
permitted to access.
custom variable
An aggregation calculation that is customized for a dimension level or member and overrides the
aggregate functions of a cube's measures.
data dictionary
A set of system tables, stored in a catalog, that includes definitions of database structures and related
information, such as permissions.
data explosion
The exponential growth in size of a multidimensional structure, such as a cube, due to the storage of
aggregated data.
data flow
The ordered workflow in an Integration Services package that extracts, transforms and loads data.
data flow engine
An engine that executes the data flow in a package.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 66/90
60
data flow task
Encapsulates the data flow engine that moves data between sources and destinations, providing the
facility to transform, clean and modify data as it is moved.
data integrity
A state in which all the data values stored in the database are correct.
data manipulation language
The subset of SQL statements that is used to retrieve and manipulate data.
data mart
A subset of the contents of a data warehouse.
data member
A child member associated with a parent member in a parent-child hierarchy.
data mining
The process of analysing data to identify patterns or relationships.
data processing extension
A component in Reporting Services that is used to retrieve report data from an external data source.
data region
A report item that displays repeated rows of data from an underlying dataset in a table, matrix, list or
chart.
data scrubbing
Part of the process of building a data warehouse out of data coming from multiple (OLTP) systems.
data source
In ADO and OLE DB, the location of a source of data exposed by an OLE DB provider.
The source of data for an object such as a cube or dimension. It is also the specification of the
information necessary to access source data. It sometimes refers to object of ClassType clsDataSource.
In Reporting Services, a specified data source type, connection string and credentials, which can be
saved separately to a report server and shared among report projects or embedded in a .rdl file.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 67/90
61
data source name
The name assigned to an ODBC data source.
data source view
A named selection of database objects that defines the schema referenced by OLAP and data mining
objects in an Analysis Services databases.
data warehouse
A database specifically structured for query and analysis.
database role
A collection of users and groups with the same access to an Analysis Services database.
data-driven subscription
A subscription in Reporting Services that uses a query to retrieve subscription data from an external
data source at run time.
datareader
A stream of data that is returned by an ADO.NET query.
dataset
In OLE DB for OLAP, the set of multidimensional data that is the result of running a MDX SELECT
statement.
In Reporting Services, a named specification that includes a data source definition, a query definition
and options.
decision support
Systems designed to support the complex analytic analysis required to discover business trends.
decision tree
A treelike model of data produced by certain data mining methods.
default member
The dimension member used in a query when no member is specified for the dimension.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 68/90
62
delimited identifier
An object in a database that requires the use of special characters (delimiters) because the object name
does not comply with the formatting rules of regular identifiers.
delivery channel type
The protocol for a delivery channel, such as Simple Mail Transfer Protocol (SMTP) or File.
delivery extension
A component in Reporting Services that is used to distribute a report to specific devices or target
locations.
density
In an index, the frequency of duplicate values.
In a data file, a percentage that indicates how full a data page is.
In Analysis Services, the percentage of cells that contain data in a multidimensional structure.
dependencies
Objects that depend on other objects in the same database.
derived column
A transformation that creates new column values by applying expressions to transformation input
columns.
descendant
A member in a dimension hierarchy that is related to a member of a higher level within the same
dimension.
destination
An Integration Services data flow component that writes the data from the data flow into a data source
or creates an in-memory dataset.
destination adapter
A data flow component that loads data into a data store.
dimension
A structural attribute of a cube, which is an organized hierarchy of categories (levels) that describe data
in the fact table.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 69/90
63
dimension granularity
The lowest level available to a particular dimension in relation to a particular measure group.
dimension table
A table in a data warehouse whose entries describe data in a fact table. Dimension tables contain the
data from which dimensions are created.
discretized column
A column that represents finite, counted data.
document map
A navigation pane in a report arranged in a hierarchy of links to report sections and groups.
drillthrough
In Analysis Services, a technique to retrieve the detailed data from which the data in a cube cell was
summarized.
In Reporting Services, a way to open related reports by clicking hyperlinks in the main drillthrough
report.
drillthrough report
A report with the 'enable drilldown' option selected. Drillthrough reports contain hyperlinks to related
reports.
dynamic connection string
In Reporting Services, an expression that you build into the report, allowing the user to select which
data source to use at run time. You must build the expression and data source selection list into the
report when you create it.
Data Mining Model Training
The process a data mining model uses to estimate model parameters by evaluating a set of known and
predictable data.
entity
In Reporting Services, an entity is a logical collection of model items, including source fields, roles,
folders and expressions, presented in familiar business terms.
executable
In Integration Services, a package, Foreach Loop, For Loop, Sequence or task.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 70/90
64
execution tree
The path of data in the data flow of a SQL Server 2008 Integration Services package from sources
through transformations to destinations.
expression
In SQL, a combination of symbols and operators that evaluate to a single data value.
In Integration Services, a combination of literals, constants, functions and operators that evaluate to a
single data value.
ETL
Extraction, transformation and loading. The complex process of copying and cleaning data from
heterogeneous sources.
fact
A row in a fact table in a data warehouse. A fact contains values that define a data event such as a sales
transaction.
fact dimension
A relationship between a dimension and a measure group in which the dimension main table is the
same as the measure group table.
fact table
A central table in a data warehouse schema that contains numerical measures and keys relating facts to
dimension tables.
field length
In bulk copy, the maximum number of characters needed to represent a data item in a bulk copy
character format data file.
field terminator
In bulk copy, one or more characters marking the end of a field or row, separating one field or row in the
data file from the next.
filter expression
An expression used for filtering data in the Filter operator.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 71/90
65
flat file
A file consisting of records of a single record type, in which there is no embedded structure information
governing relationships between records.
flattened rowset
A multidimensional data set presented as a two-dimensional rowset in which unique combinations of
elements of multiple dimensions are combined on an axis.
folder hierarchy
A bounded namespace that uniquely identifies all reports, folders, shared data source items and
resources that are stored in and managed by a report server.
format file
A file containing meta information (such as data type and column size) that is used to interpret datawhen being read from or written to a data file.
File connection manager
In Integration Services, a logical representation of a connection that enables a package to reference an
existing file or folder or to create a file or folder at run time.
For Loop container
In Integration Services, a container that runs a control flow repeatedly by testing a condition.
Foreach Loop container
In Integration Services, a container that runs a control flow repeatedly by using an enumerator.
Fuzzy Grouping
In Integration Services, a data cleaning methodology that examines values in a dataset and identifies
groups of related data rows and the one data row that is the canonical representation of the group.
global assembly cache
A machine-wide code cache that stores assemblies specifically installed to be shared by many
applications on the computer.
grant
To apply permissions to a user account, which allows the account to perform an activity or work with
data.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 72/90
66
granularity
The degree of specificity of information that is contained in a data element.
granularity attribute
The single attribute is used to specify the level of granularity for a given dimension in relation to a given
measure group.
grid
A view type that displays data in a table.
grouping
A set of data that is grouped together in a report.
hierarchy
A logical tree structure that organizes the members of a dimension such that each member has one
parent member and zero or more child members.
hybrid OLAP
A storage mode that uses a combination of multidimensional data structures and relational database
tables to store multidimensional data.
HTML Viewer
A UI component consisting of a report toolbar and other navigation elements used to work with areport.
input member
A member whose value is loaded directly from the data source instead of being calculated from other
data.
input set
The set of data provided to a MDX value expression upon which the expression operates.
isolation level
The property of a transaction that controls the degree to which data is isolated for use by one process,
and is guarded against interference from other processes. Setting the isolation level defines the default
locking behavior for all SELECT statements in your SQL Server session.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 73/90
67
item-level role assignment
A security policy that applies to an item in the report server folder namespace.
item-level role definition
A security template that defines a role used to control access to or interaction with an item in the report
server folder namespace.
key
A column or group of columns that uniquely identifies a row (primary key), defines the relationship
between two tables (foreign key) or is used to build an index.
key attribute
The attribute of a dimension that links the non-key attributes in the dimension to related measures.
key column
In an Analysis Services dimension, an attribute property that uniquely identifies the attribute members.
In an Analysis Services mining model, a data mining column that uniquely identifies each case in a case
table.
key performance indicator
A quantifiable, standardised metric that reflects a critical business variable (for instance, market share),
measured over time.
KPI
See Other Term: key performance indicator
latency
The amount of time that elapses when a data change is completed at one server and when that change
appears at another server.
leaf
In a tree structure, an element that has no subordinate elements.
leaf level
The bottom level of a clustered or nonclustered index.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 74/90
68
leaf member
A dimension member without descendants.
level
The name of a set of members in a dimension hierarchy such that all members of the set are at the same
distance from the root of the hierarchy.
lift chart
In Analysis Services, a chart that compares the accuracy of the predictions of each data mining model in
the comparison set.
linked dimension
In Analysis Services, a reference in a cube to a dimension in a different cube.
linked measure group
In Analysis Services, a reference in a cube to a measure group in a different cube.
linked report
A report that references an existing report definition by using a different set of parameter values or
properties.
list data region
A report item on a report layout that displays data in a list format.
local cube
A cube created and stored with the extension .cub on a local computer using PivotTable Service.
lookup table
In Integration Services, a reference table for comparing, matching or extracting data.
many-to-many dimension
A relationship between a dimension and a measure group in which a single fact may be associated withmany dimension members and a single dimension member may be associated with a many facts.
matrix data region
A report item on a report layout that displays data in a variable columnar format.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 75/90
69
measure
In a cube, a set of values that are usually numeric and are based on a column in the fact table of the
cube. Measures are the central values that are aggregated and analyzed.
measure group
All the measures in a cube that derive from a single fact table in a data source view.
member
An item in a dimension representing one or more occurrences of data.
member property
Information about an attribute member, for example, the gender of a customer member or the color of
a product member.
mining structure
A data mining object that defines the data domain from which the mining models are built.
multidimensional OLAP
A storage mode that uses a proprietary multidimensional structure to store a partition's facts and
aggregations or a dimension.
multidimensional structure
A database paradigm that treats data as cubes that contain dimensions and measures in cells.
MDX
A syntax used for defining multidimensional objects and querying and manipulating multidimensional
data.
Mining Model
An object that contains the definition of a data mining process and the results of the training activity.
Multidimensional Expression
A syntax used for defining multidimensional objects and querying and manipulating multidimensional
data.
named set
A set of dimension members or a set expression that is created for reuse, for example, in MDX queries.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 76/90
70
natural hierarchy
A hierarchy in which at every level there is a one-to-many relationship between members in that level
and members in the next lower level.
nested table
A data mining model configuration in which a column of a table contains a table.
nonleaf
In a tree structure, an element that has one or more subordinate elements. In Analysis Services, a
dimension member that has one or more descendants. In SQL Server indexes, an intermediate index
node that points to other intermediate nodes or leaf nodes.
nonleaf member
A member with one or more descendants.
normalization rules
A set of database design rules that minimizes data redundancy and results in a database in which the
Database Engine and application software can easily enforce integrity.
Non-scalable EM
A Microsoft Clustering algorithm method that uses a probabilistic method to determine the probability
that a data point exists in a cluster.
Non-scalable K-means
A Microsoft Clustering algorithm method that uses a distance measure to assign a data point to its
closest cluster.
object identifier
A unique name given to an object.
In Metadata Services, a unique identifier constructed from a globally unique identifier (GUID) and an
internal identifier.
online analytical processing
A technology that uses multidimensional structures to provide rapid access to data for analysis.
online transaction processing
A data processing system designed to record all of the business transactions of an organization as they
occur. An OLTP system is characterized by many concurrent users actively adding and modifying data.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 77/90
71
overfitting
The characteristic of some data mining algorithms that assigns importance to random variations in data
by viewing them as important patterns.
ODBC data source
The location of a set of data that can be accessed using an ODBC driver.
A stored definition that contains all of the connection information an ODBC application requires to
connect to the data source.
ODBC driver
A dynamic-link library (DLL) that an ODBC-enabled application, such as Excel, can use to access an ODBC
data source.
OLAP
See Other Term: online analytical processing
OLE DB
A COM-based API for accessing data. OLE DB supports accessing data stored in any format for which an
OLE DB provider is available.
OLE DB for OLAP
Formerly, the separate specification that addressed OLAP extensions to OLE DB. Beginning with OLE DB
2.0, OLAP extensions are incorporated into the OLE DB specification.
package
A collection of control flow and data flow elements that runs as a unit.
padding
A string, typically added when the last plaintext block is short.
The space allotted in a cell to create or maintain a specific size.
parameterized report
A published report that accepts input values through parameters.
parent
A member in the next higher level in a hierarchy that is directly related to the current member.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 78/90
72
partition
In replication, a subset of rows from a published table, created with a static row filter or a
parameterized row filter.
In Analysis Services, one of the storage containers for data and aggregations of a cube. Every cube
contains one or more partitions. For a cube with multiple partitions, each partition can be stored
separately in a different physical location. Each partition can be based on a different data source.
Partitions are not visible to users; the cube appears to be a single object.
In the Database Engine, a unit of a partitioned table or index.
partition function
A function that defines how the rows of a partitioned table or index are spread across a set of partitions
based on the values of certain columns, called partitioning columns.
partition scheme
A database object that maps the partitions of a partition function to a set of filegroups.
partitioned index
An index built on a partition scheme, and whose data is horizontally divided into units which may be
spread across more than one filegroup in a database.
partitioned snapshot
In merge replication, a snapshot that includes only the data from a single partition.
partitioned table
A table built on a partition scheme, and whose data is horizontally divided into units which may be
spread across more than one filegroup in a database.
partitioning
The process of replacing a table with multiple smaller tables.
partitioning column
The column of a table or index that a partition function uses to partition a table or index.
perspective
A user-defined subset of a cube.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 79/90
73
pivot
To rotate rows to columns, and columns to rows, in a crosstabular data browser.
To choose dimensions from the set of available dimensions in a multidimensional data structure for
display in the rows and columns of a crosstabular structure.
polling query
A polling query is typically a singleton query that returns a value Analysis Services can use to determine
if changes have been made to a table or other relational object.
precedence constraint
A control flow element that connects tasks and containers into a sequenced workflow.
predictable column
A data mining column that the algorithm will build a model around based on values of the input
columns.
prediction
A data mining technique that analyzes existing data and uses the results to predict values of attributes
for new records or missing attributes in existing records.
proactive caching
A system that manages data obsolescence in a cube by which objects in MOLAP storage are
automatically updated and processed in cache while queries are redirected to ROLAP storage.
process
In a cube, to populate a cube with data and aggregations.
In a data mining model, to populate a data mining model with data mining content.
profit chart
In Analysis Services, a chart that displays the theoretical increase in profit that is associated with using
each model.
properties page
A dialog box that displays information about an object in the interface.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 80/90
74
property
A named attribute of a control, field or database object that you set to define one of the object's
characteristics, such as size, color or screen location; or an aspect of its behavior, such as whether it is
hidden.
property mapping
A mapping between a variable and a property of a package element.
property page
A tabbed dialog box where you can identify the characteristics of tables, relationships, indexes,
constraints and keys.
protection
In Integration Services, determines the protection method, the password or user key and the scope of package protection.
ragged hierarchy
See Other Term: unbalanced hierarchy
raw file
In Integration Services, a native format for fast reading and writing of data to files.
recursive hierarchy
A hierarchy of data in which all parent-child relationships are represented in the data.
reference dimension
A relationship between a dimension and a measure group in which the dimension is coupled to the
measure group through another dimension. This behaves like a snowflake dimension, except that
attributes are not shared between the two dimensions.
reference table
The source table to use in fuzzy lookups.
refresh data
The series of operations that clears data from a cube, loads the cube with new data from the data
warehouse and calculates aggregations.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 81/90
75
relational database
A database or database management system that stores information in tables as rows and columns of
data, and conducts searches by using the data in specified columns of one table to find additional data
in another table.
relational database management system
A system that organizes data into related rows and columns.
relational OLAP
A storage mode that uses tables in a relational database to store multidimensional structures.
rendered report
A fully processed report that contains both data and layout information, in a format suitable for viewing.
rendering
A component in Reporting Services that is used to process the output format of a report.
rendering extension(s)
A plug-in that renders reports to a specific format.
rendering object model
Report object model used by rendering extensions.
replay
In SQL Server Profiler, the ability to open a saved trace and play it again.
report definition
The blueprint for a report before the report is processed or rendered. A report definition contains
information about the query and layout for the report.
report execution snapshot
A report snapshot that is cached.
report history
A collection of report snapshots that are created and saved over time.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 82/90
76
report history snapshot
A report snapshot that appears in report history.
report intermediate format
A static report history that contains data captured at a specific point in time.
report item
Any object, such as a text box, graphical element or data region, that exists on a report layout.
report layout
In report designer, the placement of fields, text and graphics within a report.
In report builder, the placement of fields and entities within a report, plus applied formatting styles.
report layout template
A predesigned table, matrix or chart report template in report builder.
report link
A URL to a hyperlinked report.
report model
A metadata description of business data used for creating ad hoc reports in report builder.
report processing extension
A component in Reporting Services that is used to extend the report processing logic.
report rendering
The action of combining the report layout with the data from the data source for the purpose of viewing
the report.
report server database
A database that provides internal storage for a report server.
report server execution account
The account under which the Report Server Web service and Report Server Windows service run.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 83/90
77
report server folder namespace
A hierarchy that contains predefined and user-defined folders. The namespace uniquely identifies
reports and other items that are stored in a report server. It provides an addressing scheme for
specifying reports in a URL.
report snapshot
A static report that contains data captured at a specific point in time.
report-specific schedule
Schedule defined inline with a report.
resource
Any item in a report server database that is not a report, folder or shared data source item.
role
A SQL Server security account that is a collection of other security accounts that can be treated as a
single unit when managing permissions. A role can contain SQL Server logins, other roles, and Windows
logins or groups.
In Analysis Services, a role uses Windows security accounts to limit scope of access and permissions
when users access databases, cubes, dimensions and data mining models.
In a database mirroring session, the principal server and mirror server perform complementary principal
and mirror roles. Optionally, the role of witness is performed by a third server instance.
role assignment
Definition of user access rights to an item.
In Reporting Services, a security policy that determines whether a user or group can access a specific
item and perform an operation.
role definition
A collection of tasks performed by a user (i.e. browser, administrator).
In Reporting Services, a named collection of tasks that defines the operations a user can perform on a
report server.
roleplaying dimension
A single database dimension joined to the fact table on different foreign keys to produce multiple cube
dimensions.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 84/90
78
RDBMS
See Other Term: relational database management system
RDL
See Other Term: Report Definition Language
Report Definition Language
A set of instructions that describe layout and query information for a report.
Report Server service
A Windows service that contains all the processing and management capabilities of a report server.
Report Server Web service
A Web service that hosts, processes and delivers reports.
ReportViewer controls
A Web server control and Windows Form control that provides embedded report processing in ASP.NET
and Windows Forms applications.
scalar
A single-value field, as opposed to an aggregate.
scalar aggregate
An aggregate function, such as MIN(), MAX() or AVG(), that is specified in a SELECT statement column list
that contains only aggregate functions.
scale bar
The line on a linear gauge on which tick marks are drawn analogous to an axis on a chart.
scope
An extent to which a variable can be referenced in a DTS package.
script
A collection of Transact-SQL statements used to perform an operation.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 85/90
79
security extension
A component in Reporting Services that authenticates a user or group to a report server.
semiadditive
A measure that can be summed along one or more, but not all, dimensions in a cube.
serializable
The highest transaction isolation level. Serializable transactions lock all rows they read or modify to
ensure the transaction is completely isolated from other tasks.
server
A location on the network where report builder is launched from and a report is saved, managed and
published.
server admin
A user with elevated privileges who can access all settings and content of a report server.
server aggregate
An aggregate value that is calculated on the data source server and included in a result set by the data
provider.
shared data source item
Data source connection information that is encapsulated in an item.
shared dimension
A dimension created within a database that can be used by any cube in the database.
shared schedule
Schedule information that can be referenced by multiple items.
sibling
A member in a dimension hierarchy that is a child of the same parent as a specified member.
slice
A subset of the data in a cube, specified by limiting one or more dimensions by members of the
dimension.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 86/90
80
smart tag
A smart tag exposes key configurations directly on the design surface to enhance overall design-time
productivity in Visual Studio 2005.
snowflake schema
An extension of a star schema such that one or more dimensions are defined by multiple tables.
source
An Integration Services data flow component that extracts data from a data store, such as files and
databases.
source control
A way of storing and managing different versions of source code files and other files used in software
development projects. Also known as configuration management and revision control.
source cube
The cube on which a linked cube is based.
source database
In data warehousing, the database from which data is extracted for use in the data warehouse.
A database on the Publisher from which data and database objects are marked for replication as part of
a publication that is propagated to Subscribers.
source object
The single object to which all objects in a particular collection are connected by way of relationships that
are all of the same relationship type.
source partition
An Analysis Services partition that is merged into another and is deleted automatically at the end of the
merger process.
sparsity
The relative percentage of a multidimensional structure's cells that do not contain data.
star join
A join between a fact table (typically a large fact table) and at least two dimension tables.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 87/90
81
star query
A star query joins a fact table and a number of dimension tables.
star schema
A relational database structure in which data is maintained in a single fact table at the center of the
schema with additional dimension data stored in dimension tables.
subreport
A report contained within another report.
subscribing server
A server running an instance of Analysis Services that stores a linked cube.
subscription
A request for a copy of a publication to be delivered to a Subscriber.
subscription database
A database at the Subscriber that receives data and database objects published by a Publisher.
subscription event rule
A rule that processes information for event-driven subscriptions.
subscription scheduled rule
One or more Transact-SQL statements that process information for scheduled subscriptions.
Secure Sockets Layer (SSL)
A proposed open standard for establishing a secure communications channel to prevent the
interception of critical information, such as credit card numbers. Primarily, it enables secure electronic
financial transactions on the World Wide Web, although it is designed to work on other Internet services
as well.
Semantic Model Definition Language
A set of instructions that describe layout and query information for reports created in report builder.
Sequence container
Defines a control flow that is a subset of the package control flow.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 88/90
82
table data region
A report item on a report layout that displays data in a columnar format.
tablix
A Reporting Services RDL data region that contains rows and columns resembling a table or matrix,
possibly sharing characteristics of both.
target partition
An Analysis Services partition into which another is merged, and which contains the data of both
partitions after the merger.
temporary stored procedure
A procedure placed in the temporary database, tempdb and erased at the end of the session.
time dimension
A dimension that breaks time down into levels such as Year, Quarter, Month and Day.
In Analysis Services, a special type of dimension created from a date/time column.
transformation
In data warehousing, the process of changing data extracted from source data systems into
arrangements and formats consistent with the schema of the data warehouse.
In Integration Services, a data flow component that aggregates, merges, distributes and modifiescolumn data and rowsets.
transformation error output
Information about a transformation error.
transformation input
Data that is contained in a column, which is used during a join or lookup process, to modify or aggregate
data in the table to which it is joined.
transformation output
Data that is returned as a result of a transformation procedure.
tuple
Uniquely identifies a cell, based on a combination of attribute members from every attribute hierarchy
in the cube.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 89/90
83
two
A process that ensures transactions that apply to more than one server are completed on all servers or
on none.
unbalanced hierarchy
A hierarchy in which one or more levels do not contain members in one or more branches of the
hierarchy.
unknown member
A member of a dimension for which no key is found during processing of a cube that contains the
dimension.
unpivot
In Integration Services, the process of creating a more normalized dataset by expanding data columns ina single record into multiple records.
value
An expression in MDX that returns a value. Value expressions can operate on sets, tuples, members,
levels, numbers or strings.
variable interval
An option on a Reporting Services chart that can be specified to automatically calculate the optimal
number of labels that can be placed on an axis, based on the chart width or height.
vertical partitioning
To segment a single table into multiple tables based on selected columns.
very large database
A database that has become large enough to be a management challenge, requiring extra attention to
people, processes and processes.
visual
A displayed, aggregated cell value for a dimension member that is consistent with the displayed cell
values for its displayed children.
VLDB
very large database.

7/16/2019 Course 10058 - Implementing Data Flow in SQL Server Integration Services 2008
http://slidepdf.com/reader/full/course-10058-implementing-data-flow-in-sql-server-integration-services-2008 90/90
write back
To update a cube cell value, member or member property value.
write enable
To change a cube or dimension so that users in cube roles with read/write access to the cube or
dimension can change its data.
writeback
In SQL Server, the update of a cube cell value, member or member property value.
Web service
In Reporting Services, a service that uses Simple Object Access Protocol (SOAP) over HTTP and acts as a
communications interface between client programs and the report server.
XML for Analysis
A specification that describes an open standard that supports data access to data sources that reside on
the World Wide Web.
XMLA
See Other Term: XML for Analysis


















