
Cours Max Vrais
18
© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 1 Estimation par maximum de vraisemblance Approche numérique
-
Upload
boisolivier -
Category
Documents
-
view
1 -
download
0
description
cours max vrai
Transcript of Cours Max Vrais

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 1
Estimation par maximum de vraisemblance
Approche numérique

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 2
But de l’estimation en statistique
L’estimation a pour but de trouver les valeurs possibles de θ telles que la densité f(x;θ) s’ajuste le mieux aux données disponibles
Différentes méthodes possibles : méthode des moments, du maximum de vraisemblance ou des moindres carrés.
X : Variable ou vecteur aléatoire d’intérêt
X1, X2, …. Xn
Échantillon de données
f(x;θ)
Densité de probabilité sur X
f() est connu, θ inconnu
© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 3
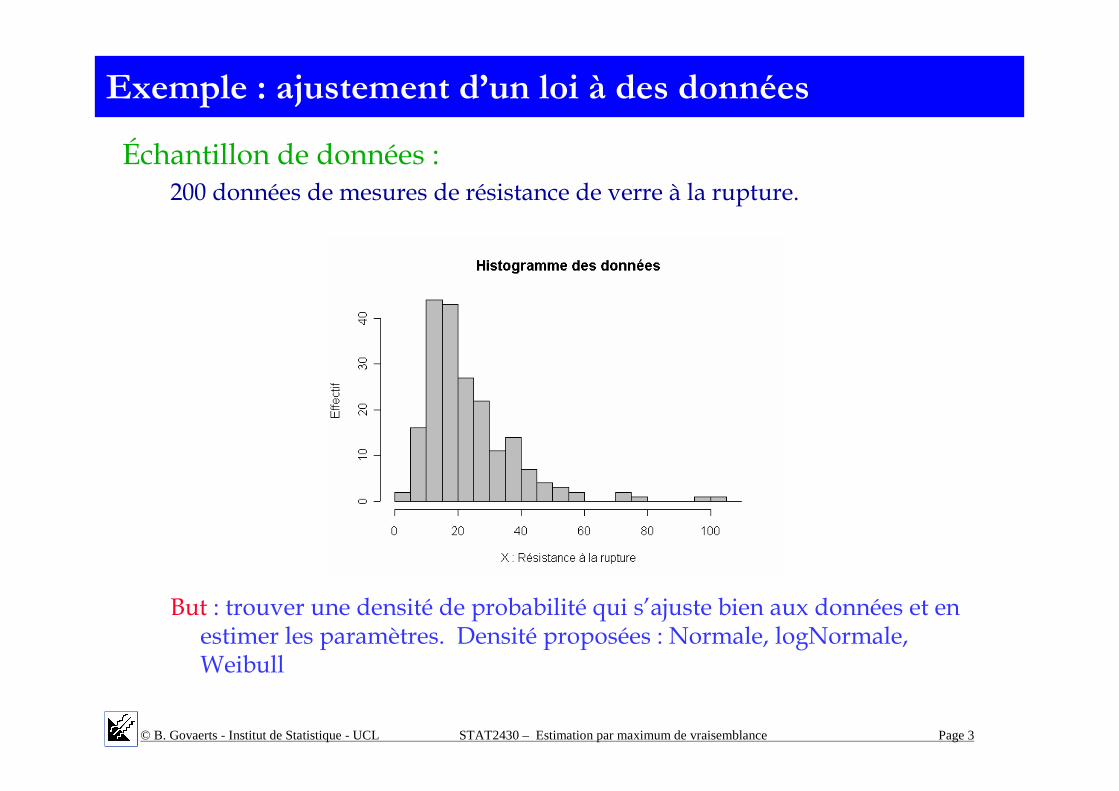
Exemple : ajustement d’un loi à des données
Échantillon de données : 200 données de mesures de résistance de verre à la rupture.
But : trouver une densité de probabilité qui s’ajuste bien aux données et en estimer les paramètres. Densité proposées : Normale, logNormale, Weibull

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 4
Estimation par maximum de vraisemblance
Fonction de vraisemblanceSoit X une variable aléatoire de densité de probabilité f(x;θ) où θ est un vecteur de k
paramètres : θ=(θ1, θ2,... θk)Soit X1,X2… Xn un échantillon de données indépendantes.La fonction de vraisemblance associée est définie par :
Estimateur de maximum de vraisemblance (EMV)
L’estimateur de maximum de vraisemblance de θ est la valeur de θ qui maximise la fonction de vraisemblance L(θ).
En pratique on maximise le logarithme de la fonction de vraisemblance :
Si une approche analytique par dérivation ne fonctionne pas, on procède numériquement.
∏=
=n
iixfL
1
);()( θθ
∑=
==n
iixfLl
1
));(log())(log()( θθθ

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 5
Propriétés des EMV
Un estimateur de maximum de vraisemblance est asymptotiquement sans biais, de distribution Normale et de
variance minimale :
I(θ) est la matrice d’information de Fischer définie par :
))(,(ˆ 1 θθθ −→ INdist
)());(log('
)('
)(1
22
θθθθ
θθθ
θ HxflIn
ii −=
∂∂∂−=
∂∂∂−= ∑
=
matrice Hessienne

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 6
Propriété d’invariance des estimateurs de MV
Soit γ=g(θ) un paramètre fonction du vecteur des paramètres estimés par maximum de vraisemblance. La propriété d’invariance assure que l’estimateur de maximum de vraisemblance de γ vaut :
Les propriétés asymptotiques de cet estimateur sont similaires aux propriétés de l’EMV :
θθθγ de MV de estimateurl'est ˆoù )ˆ(ˆ g=
)()(où
))()()'(,(ˆ 1
θθ
θ
θθθγγ
gG
GIGNdist
∂∂=
→ −

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 7
Ajustement d’un distribution Normale : approche analytique
Densité normale
Fonction de vraisemblance
Log vraisemblance
Minimisation
Estimateurs de maximum de vraisemblance
)2
)(exp(
2
1),;();(
2
2
2
2
σµ
πσσµθ −−== x
xfxf
∏∏==
−−==n
i
in
ii
xxfL
12
2
21
)2
)(exp(
2
1);()(
σµ
πσθθ
∑∑==
−−−−==n
i
in
ii
xnnxfl
12
22
1 2
)()2log(
2)log(
2));(log()(
σµπσθθ
∑∑
∑∑
==
==
−=⇒=−+−=∂
∂
==⇒=−=∂∂
n
ii
n
i
i
n
ii
n
i
i
xn
xnl
Xxn
xl
1
22
14
2
22
112
)ˆ(1
ˆ02
)(
2)(
1ˆ0
2
)(2)(
µσσ
µσ
θσ
µσ
µθµ
∑=
−==n
ii Xx
nX
1
22 )(1
ˆˆ σµ

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 8
Exemple : ajustement d’une Normale
Estimateurs de MV
Valeur de la log vraisemblance
75.222)(1
ˆ23.46ˆ1
22 =−=== ∑=
n
ii Xx
nX σµ
39.824ˆ2
)ˆ()2log(
2)ˆlog(
2)(
12
22 −=−−−−= ∑
=
n
i
ixnnl
σµπσθ
N(23.46, 222.75)

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 9
Approche numérique de l’EMV
Quand une solution analytique n’existe pas ou ne peut facilement être trouvée pour les EMV, on procède numériquement.
La fonction R nlm() (nlmin() dans S+) permet de minimiser une fonction à plusieurs variables. On va donc minimiser –l(θ). L’algorithme utilisé est itératif et est une variante de l’algorithme de Newton.
A faire :• Ecrire une fonction qui permet de calculer –l(θ)• Minimiser cette fonction avec nlm en donnant des valeurs de départ pour
les paramètres à estimer.

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 10
Exemple : Ajustement numérique d’une Normale
• Fonction de vraisemblance à minimiser –l(θ)> vraisnor
function (par,x)
{mu=par[1]
sig2=par[2]
n=length(x)
logvrais=-(n/2)*log(2*pi*sig2)-sum((x-mu)^2/(2*sig2))
return(-logvrais)}
• Appel de la fonction de minimisationnlm(vraisnor,par=c(10,10),x=x)
• Résultat
$minimum
[1] 824.3943
$estimate
[1] 23.46570 222.75373
$gradient
[1] 1.717000e-05 6.512322e-07
$code
[1] 1
$iterations
[1] 19

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 11
La distribution logNormale
Un variable est logNormale si son logarithme est Normale. Elle prend ses valeurs dans R0
+ et permet d’ajuster des phénomènes asymétriques.
� Densité logNormale
� Moments
� Exemples
)2
))(log(exp(
2
1),;();(
2
2
2
2
σµ
πσσµθ −−== x
xxfxf
)2exp()1)(exp()()2/exp()( 222 σµσσµ +−=+= XVXE

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 12
EMV des paramètres d’une distribution logNormale
Densité lognormale
Fonction de vraisemblance
Log vraisemblance
Minimisation
Estimateurs de maximum de vraisemblance de E(X) et V(X)
)2
))(log(exp(
2
1),;();(
2
2
2
2
σµ
πσσµθ −−== x
xxfxf
∏∏==
−−==n
i
i
i
n
ii
x
xxfL
12
2
21
)2
))(log(exp(
2
1);()(
σµ
πσθθ
∑∑∑===
−−−−−==n
i
in
ii
n
ii
xx
nnxfl
12
2
1
2
1 2
))(log()log()2log(
2)log(
2));(log()(
σµπσθθ
∑∑
∑∑
==
==
−=⇒=−+−=∂
∂
=⇒=−=∂∂
n
ii
n
i
i
n
ii
n
i
i
xn
xnl
xn
xl
1
22
14
2
22
112
)ˆ)(log(1
ˆ02
))(log(
2)(
)log(1
ˆ02
))(log(2)(
µσσ
µσ
θσ
µσ
µθµ
)ˆˆ2exp()1)ˆ(exp()(ˆ)2/ˆˆexp()(ˆ 222 σµσσµ +−=+= XVXE

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 13
Exemple : ajustement d’une logNormale
Estimateurs de MV
Valeur de la log vraisemblance
84.219)ˆˆ2exp()1)ˆ(exp()(ˆ49.23)2/ˆˆexp()(ˆ
335.0)ˆ)(log(1
ˆ99.2)log(1
ˆ
222
1
22
1
=+−==+=
=−=== ∑∑==
σµσσµ
µσµ
XVXE
xn
xn
n
ii
n
ii
logN(2.99,0.335)
31.772ˆ2
)ˆ()log()2log(
2)ˆlog(
2))ˆ;(log()ˆ(
12
2
1
2
1
−=−−−−−== ∑∑∑===
n
i
in
ii
n
ii
xx
nnxfl
σµπσθθ

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 14
Exemple : Ajustement numérique d’une logNormale
• Fonction de vraisemblance à minimiser –l(θ)> vraislogn
function (par,x)
mu=par[1]
sig2=par[2]
n=length(x)
logvrais=-sum(log(x))-n*log(sqrt(2*pi*sig2))-sum((log(x)-mu)^2/(2*sig2))
return(-logvrais)}
• Appel de la fonction de minimisationnlm(vraislogn,par=c(1,1),x=x)
• Résultat
$minimum
[1] 772.3136
$estimate
[1] 2.9889810 0.3353075
$gradient
[1] 1.939801e-05 -2.501110e-06
$code
[1] 1
$iterations
[1] 21

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 15
La distribution Weibull
La variable aléatoire de Weibull à 2 paramètres prend ses valeurs entre dans R0
+ et permet d’ajuster des phénomènes asymétriques.
� Densité Weibull
� Moments
� Exemples
))/(exp(),;();(1
αα
βββ
αβαθ xx
xfxf −
==−
))/11()/21(()()/11()( 22 ααβαβ +Γ−+Γ=+Γ= XVXE

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 16
Exemple : ajustement d’une Weibull
La vraisemblance est trop complexe, on ne peut résoudre le problème analytiquement !
• Fonction de vraisemblance à minimiser –l(θ)> vraisweibfunction (par,x)
mu=par[1]sig2=par[2]
n=length(x)logvrais=n*log(a)-n*a*log(b)+(a-1)*sum(log(x))-sum((x/b)^a)return(-logvrais)}
• Appel de la fonction de minimisationnlm(vraisweib,par=c(10,21),x=x)
• Résultat
$minimum[1] 788.5652
$estimate[1] 1.718531 26.501480$gradient[1] 1.203332e-04 -1.139379e-05$code[1] 1$iterations[1] 39
Weib(1.73, 26.5)

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 17
Inférence sur les paramètres de la lognormale (1)
Matrice de variance covariance des paramètres
Calcul de la matrice Hessienne : analytiquement ou numériquement
>res=nlm(vraislogn,par=c(1,1),x=x,hessian=T)>res$hessian
[,1] [,2]
[1,] 596.4673409 -0.2631740
[2,] -0.2631740 888.3756777
Calcul de la matrice de variance covariance des paramètres> solve(res$hessian)
[,1] [,2]
[1,] 1.676538e-03 4.966605e-07
[2,] 4.966605e-07 1.125650e-03
Attention, comme on minimise –log vraisemblance, on ne doit plus mettre un signe « - » devant la matrice Hessienne donnée par R avant de l’inverse r.
θθ
θθθ
θθθˆ
1
1
211 ));(log(
'))ˆ(())ˆ((ˆ)ˆ(
=
−
=
−−
∂∂∂−=−== ∑
n
iixfHIV

© B. Govaerts - Institut de Statistique - UCL STAT2430 – Estimation par maximum de vraisemblance Page 18
Inférence sur les paramètres de la lognormale (2)
Intervalle de confiance asymptotique sur un paramètre
Exemple : IC à 95% sur µ :
Intervalle de confiance asymptotique sur une fonction γ=g(θ) d’un paramètre
Exemple : IC à 95% sur Ε(X) :
θθα θ
θθθθγ
ˆ2/1
)()ˆ(
'
)(ˆ
=− ∂
∂∂
∂± gV
gzi
]07.3,91.2[00167.096.199.2 =×±
)ˆ(ˆˆ2/1 ii Vz θθ α−±
077.1745.11
49.23
00113.00000.0
000.000167.0)745.1149.23(
),(
),(
)ˆ()ˆ,ˆcov(
)ˆ,ˆcov()ˆ(),(),())(ˆ(
)2/ˆˆexp(2
1),()2/exp(
),(
49.23)2/ˆˆexp()ˆ()(ˆ
2
2
2
22
2
2
22
22
22
2
2
=
=
∂∂
∂∂
∂∂
∂∂=
+=∂
∂+=∂
∂=+==
σσµ
µσµ
σσµσµµ
σσµ
µσµ
σµσ
σµσµµσµ
σµθ
g
g
V
VggXEV
gg
gXE
]52.25,46.21[077.196.149.23 =×±


















