
Conversa Overview. Conversa System Pipeline Tokenization Polygram Analysis Collocation Discovery...
49
Conversa Overview
-
Upload
marlene-boone -
Category
Documents
-
view
222 -
download
0
Transcript of Conversa Overview. Conversa System Pipeline Tokenization Polygram Analysis Collocation Discovery...

Conversa Overview

Conversa System Pipeline
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n=1)
Term clusters
Splits Co-occurrence Vectors
TokensSurroundsCentersOcc. CountsTerm Clusters

Tokenization
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
Tokens/TypesSurroundsCentersOcc. CountsTerm Clusters
He acted awful mysterious like, and finally he asks me if I'd like to own half of a big nugget of gold. I told him I certainly would."
"And then?" asked Sam, as the old miser paused to take a bite of bread and meat.

Tokenization
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n=1)
Term clusters
Splits Co-occurrence Vectors
Tokens/TypesSurroundsCentersOcc. CountsTerm Clusters
Type Count Classand 3 ALPHABETICof 3 ALPHABETIC" 3 PUNCTUATIONhe 2 ALPHABETIC, 2 PUNCTUATIONa 2 ALPHABETICi 2 ALPHABETICacted 1 ALPHABETICawful 1 ALPHABETIC
…
TokenDoc ID
Expr ID Index
he 12 121 1acted 12 121 2awful 12 121 3mysterious 12 121 4like 12 121 5, 12 121 6and 12 121 7
…

Polygram Analysis
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
TokensSurroundsCentersOcc. CountsTerm Clusters
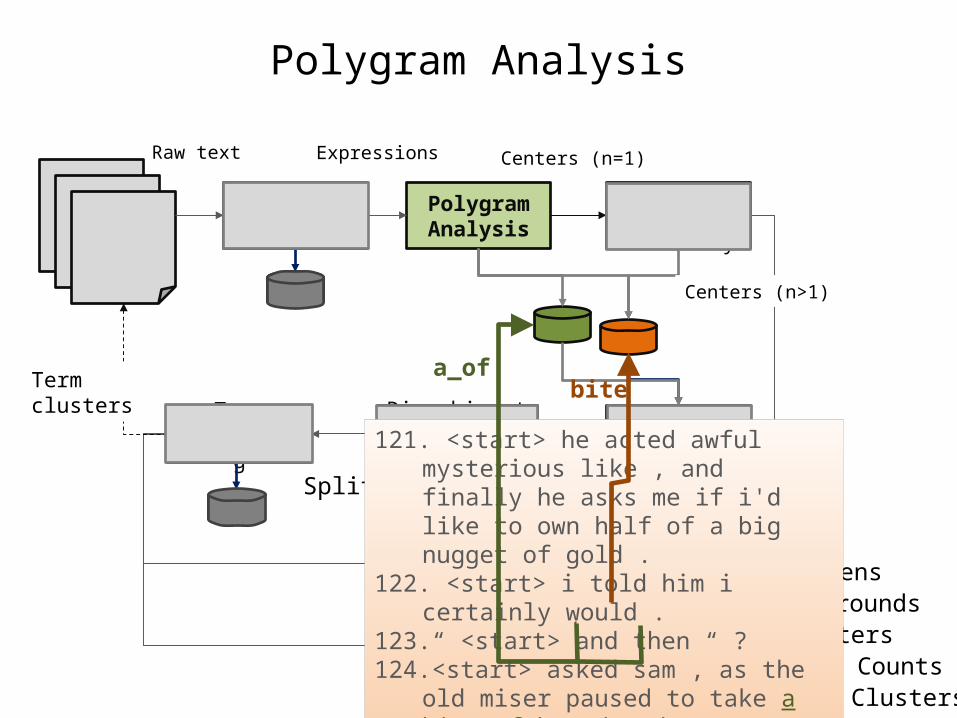
121. <start> he acted awful mysterious like , and finally he asks me if i'd like to own half of a big nugget of gold .
122. <start> i told him i certainly would . 123. “ <start> and then “ ? 124. <start> asked sam , as the old miser
paused to take a bite of bread and meat .
<start>_acted
he

Polygram Analysis
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
TokensSurroundsCentersOcc. CountsTerm Clusters
121. <start> he acted awful mysterious like , and finally he asks me if i'd like to own half of a big nugget of gold .
122. <start> i told him i certainly would . 123. “ <start> and then “ ? 124. <start> asked sam , as the old miser
paused to take a bite of bread and meat .
he_awful
acted

Polygram Analysis
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
TokensSurroundsCentersOcc. CountsTerm Clusters
121. <start> he acted awful mysterious like , and finally he asks me if i'd like to own half of a big nugget of gold .
122. <start> i told him i certainly would . 123. “ <start> and then “ ? 124. <start> asked sam , as the old miser
paused to take a bite of bread and meat .
acted_mysterious
awful
Polygram Analysis
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
TokensSurroundsCentersOcc. CountsTerm Clusters
121. <start> he acted awful mysterious like , and finally he asks me if i'd like to own half of a big nugget of gold .
122. <start> i told him i certainly would . 123. “ <start> and then “ ? 124. <start> asked sam , as the old miser
paused to take a bite of bread and meat .
a_ofbite
Collocation Discovery
Tokenization Polygram Analysis
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
TokensSurroundsCentersOcc. CountsTerm Clusters
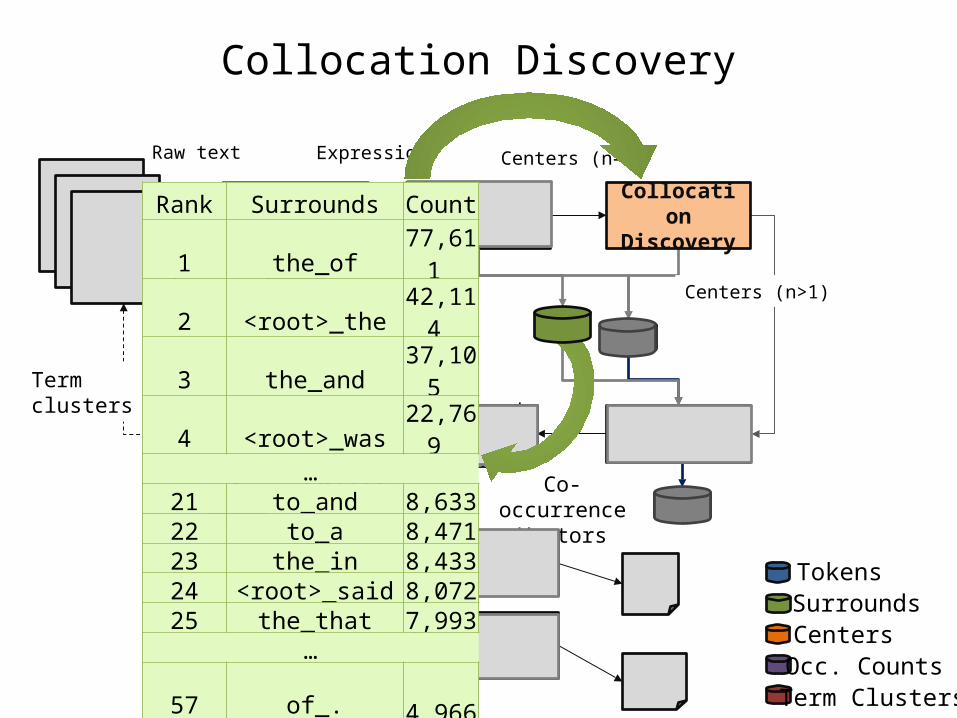
Rank Surrounds Count1 the_of 77,611 2 <root>_the 42,114 3 the_and 37,105 4 <root>_was 22,769
…21 to_and 8,633 22 to_a 8,471 23 the_in 8,433 24 <root>_said 8,072 25 the_that 7,993
…57 of_. 4,966
…71 a_. 4,493
Collocation Discovery

Collocation Discovery
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n=1)
Term clusters
Splits Co-occurrence Vectors
TokensSurroundsCentersOcc. CountsTerm Clusters
121. <start> he acted awful mysterious like , and finally he asks me if i'd like to own half of a big nugget of gold .
122. <start> i told him i certainly would . 123. “ <start> and then “ ? 124. <start> asked sam , as the old miser
paused to take a bite of bread and meat .
a_.
big nugget of gold

Collocation Discovery
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
TokensSurroundsCentersOcc. CountsTerm Clusters
121. <start> he acted awful mysterious like , and finally he asks me if i'd like to own half of a big nugget of gold .
122. <start> i told him i certainly would . 123. “ <start> and then “ ? 124. <start> asked sam , as the old miser
paused to take a bite of bread and meat .
of_.
bread and meat

Constructing Co-Occurrence Matrix
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n=1)
Term clusters
Splits Co-occurrence Vectors
Tokens/TypesSurroundsCentersOcc. CountsTerm Clusters
Rank Surrounds Count1 the_of 77,611 2 <root>_the 42,114 3 the_and 37,105 4 <root>_was 22,769
…
Rank Type Count Class
1 the 626,106 ALPHABETIC
2 . 559,662 TERMINATOR
3 and 364,522 ALPHABETIC
4 to 284,993 ALPHABETIC
5 of 257,403 ALPHABETIC
…
Center Surrounds Doc Expr Indexit <start>_is 3 12 1is it_not 3 12 2
not is_for 3 12 3for not_want 3 12 4
want for_of 3 12 5of want_trouble 3 12 6
trouble of_that 3 12 7

Constructing Co-Occurrence Matrix
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
Tokens/TypesSurroundsCentersOcc. CountsTerm Clusters
Rank Surrounds Count1 the_of 77,611 2 <root>_the 42,114 3 the_and 37,105 4 <root>_was 22,769
…
Rank Type Count Class
1 the 626,106 ALPHABETIC
2 . 559,662 TERMINATOR
3 and 364,522 ALPHABETIC
4 to 284,993 ALPHABETIC
5 of 257,403 ALPHABETIC
…
Center Surrounds Doc Expr Indexit <start>_is 3 12 1is it_not 3 12 2
not is_for 3 12 3for not_want 3 12 4
want for_of 3 12 5of want_trouble 3 12 6
trouble of_that 3 12 7
Surrounds Rank 1 2 3 4 5 6
684 685
1,839 1,840
Center Rank
Type
the_of
the_and
<start>_the
a_of
<start>_was
and_the
day_the
<start>_may
top_the
you_find
1 the 1 2 of 24 28 9 47 3 to 36 15 1 1
4 and 154 9 7 2
36 my
37 when 112 35 3 1 38 so 19 3 11 39 were 40 which 7 3 41 would 2
173 let 1 3
174 days 11 175 sheldon 10 176 part 29 24

Disambiguation and Split
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
Tokens/TypesSurroundsCentersOcc. CountsTerm Clusters
days
part
Disambiguation and Split
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
Tokens/TypesSurroundsCentersOcc. CountsTerm Clusters
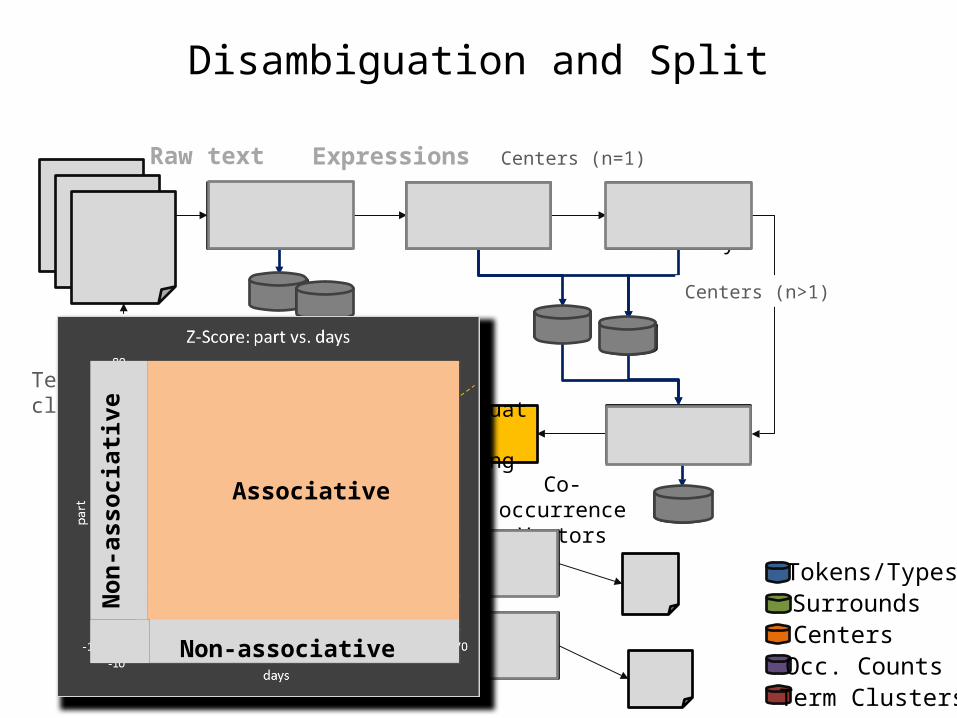
Associative
Non-associative
Non
-ass
ocia
tive

Disambiguation and Split
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
Tokens/TypesSurroundsCentersOcc. CountsTerm Clusters
Associative
Non-associative
Non
-ass
ocia
tive
Associativedays Non-Associative
Associativepart Non-Associative
Zero Counts
Zero Counts
the_of
early_
offirst
_of… th
ree_ofa_
of… of_things
she_no
there_be
great_
to
…

Disambiguation and Split
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits
Co-occurrence Vectors
Tokens/TypesSurroundsCentersOcc. CountsTerm Clusters
Associative
Non-associative
Non
-ass
ocia
tive
Associativedays
Associativepart
Zero Counts
Zero Counts
days Non-Associative
part Non-Associative
Zero Counts
Zero Counts
Zero Counts
Zero Counts

Disambiguation and Split
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
Tokens/TypesSurroundsCentersOcc. CountsTerm Clusters

Disambiguation and Split
Tokenization Polygram Analysis
Collocation Discovery
Co-Occurrence Matrix
Disambiguation & Splitting
Term Clustering
Automatic Annotation
Text Synthesis
Raw text Expressions Centers (n=1)
Centers (n>1)
Term clusters
Splits Co-occurrence Vectors
Tokens/TypesSurroundsCentersOcc. CountsTerm Clusters

Tokenization

Polygram Analysis

Collocation Discovery
• Collocation: a multi-word expression that correspond to some conventional way of saying things. – Non-Compositionality– Non-Substitutionality– Non-Modifiability
• Current Methods– Word Counts on Span– Word-to-Word Comparison
• Assumption of Independence

Collocation Discovery using Stop Words
• High-frequency stop words carry very little semantic content but indicate grammatical relationships with other words
• Can be used to delimit collocations:
Example: frequently occurring stop words {a, in} can detect noun phrases:
"Start the buzz-tail," said Cap'n Bill, with a tremble in his voice.
There was now a promise of snow in the air, and a few days later the ground as covered to the depth of an inch or more.

More examples of collocation discovery…
SurroundsU_V
POS Two-Word Collocation Candidate Examples
the_of Noun sordid appetite for dollars, or the dreary existence of countrythe_and Noun alone on a church-top, with the blue sky and a few tall pinnacles
a_of Noun They heard a faint creaking of the flooring
and_the Verb
Preposition
of a lookout, and would visit the adventurers again the next day.
they sailed in and out over the great snow-covered peaks
as_as Adverb the Rover boys became as light hearted as ever.
the_. Noun following day to join him at the Tavistock Hotel .
and_and Verb
Adjective
Noun
tried not to show it, and sang songs and cheered its opponents.
was [..] quite broad and led upward and in the general direction in snowballing each other and Jack Ness and Aleck Pop.

Definitions
Triplet UVW: combined predecessor, center, and successor of three or more words contained within a sentence
Surrounds: any observed pairing of predecessor and successor words enclosing one or more centers
encloses centers .

Collocation Discovery
Step 1: discover surrounds from the corpus, count their occurrences, and rank order them from highest to lowest occurrence count

Step 1: Collocation Discovery

Step 2: Select SurroundsSelect top k from the rank-ordered surrounds satisfying the surrounds total proportionality criterion
Example: υ=25%, the top 1,848 surrounds are selected for collocation candidate extraction

Step 3: Extract Collocation CandidatesAlgorithm ExtractCollocationCandidates(S,𝔖𝜐) 𝔙∶= ∅ for all expressions in corpus: ∀ 𝑠 ∈𝑆 for all selected surrounds: ∀𝜑 ∈𝔖𝜐 for word indices in s: 𝑖 = 1 𝑡𝑜 ȁ�𝑠ȁ� if word si=predecessor: 𝑠𝑖 = 𝑈𝜑 for word indices in s: 𝑗= 𝑖 + 3 𝑡𝑜 ȁ�𝑠ȁ� if word s[j]=predecessor 𝑗= 𝑊𝜑 Add to collocations candidates:
𝔙∶= 𝔙∪ ራ 𝑠𝑘𝑗−1
𝑘=𝑖+1
Return candidate list, 𝔙

Step 3: Extract Collocation Candidates
Here it leaped [..],
just as a wild beast in
captivity paces angrily [..] .
<Start>
Given Surrounds {a, in}, discover Collocation Candidates:

It was the one that seemed to
have had a hole bored in it and
then plugged up again .
Step 3: Extract Collocation Candidates
<Start>
hole bored is not really a good collocation!

Step 4. Select Collocations
Apply a non-parametric variation of a frequently applied method to determine which collocation candidates co-occur significantly more often than chance.
The null hypothesis assumes words are selected independently at random and claims that the probability of a collocation candidate V is the same as the product of the probabilities of the individual words
𝐻0 :𝑃 (𝑉 )=∏𝑖=1
𝑛
¿¿

Step 4. Select Collocations
• Sample variance s2=P(V) is based on the assumption that the null hypothesis is true
• Selection of a word is essentially a Bernoulli trial with parameter P(V), with sample variance s2=P(V)(1-P(V)) and mean µ=p.
• Since P(V) << 1.0, s2 ≈P(V).
𝑍= 𝑋−𝜇
√ 𝑠2
𝑛
=𝑃 (𝑉 )−∏𝑖=1
𝑛
¿¿¿

Use of the Empirical CDF
Empirical CDF approximate of the true, but unknown distribution, FN:

Confidence Bounds for the Empirical CDFDvoretzky, Kiefer and Wolfowitz (DKW) Inequality provide a method of computing the upper an lower confidence bound for an empirical CDF given a type-I error probability α and the total number of instances within the sample N:
The upper and lower bounds of the empirical CDF can then be calculated:
and
The Gutenberg Youth Corpus with N = 9,743,797 and a selected α=0.05, provides for a very tight uncertainty bound of 95% ± 0.04% and a critical value of 2.51.


Results: Some Accepted CollocationsAccepted Collocation Candidate (α=0.05) Occurrence count
Collocation Confidence
there was 3685 100%don`t know 1181 100%Young Inventor 967 100%Rover Boys 674 100%went on 1295 100%Mr. Damon 537 100%Emerald City 276 99%little girl 407 99%at once 592 99%other side of 299 99%steam yacht 137 98%two men 204 98%was decided 212 97%long ago 99 97%pilot house 86 97%Von Horn 80 97%the living room 41 95%beg your pardon 38 95%quickly as possible 39 95%

Results: Some Rejected Collocations
Rejected Collocation Candidate Occurrence countCollocation Confidence
corner of the house 19 93%may be added here 18 93%as quickly as possible 18 93%late in the afternoon 18 93%she was glad 25 92%have you a member 2 78%paper to his eyes 2 78%quietly drew 2 49%It’ll do 2 32%the chemist’s 2 32%rob began 2 16%you explain 6 16%surprised that 19 16%children might 3 16%been the first 13 16%did i know 2 0%or the 3 0%and that the 2 0%and in the 8 0%

Co-Occurrence Matrix

Splitting
Problem: Solve a multi-membership clustering problem where:– Targets, t, belong to one or more classes, C– All Targets have N Feature Vectors, ft , of occurrence counts [0, ∞) – Class membership is indicated uniquely by one or more feature vectors– Feature Vectors are noisy – random counts may occur that are false
indicators of actual class membership
Objective: Cluster targets by class membership, such that each class forms a distinct, homogeneous sub-tree and each target is placed in class-clusters representing the complete target’s class membership (i.e. a target must appear in one or more class-clusters)

ExampleGiven five words, generate a clustering by POS class membership using surrounds (words before and after) feature counts
Target Class Membership
Eat Verb
Run Noun, Verb
Test Noun, Verb, Adjective
Wise Noun, Adjective
Quickly Adverb
Eat Run Test WiseQuickly
Run Test Test Wise

Splitting Feature Vectors
Fundamental measure of distance is the Pearson Product-Moment Correlation Coefficient:
and and
When most features have counts near 0, if both zA,i , zB,i are > 0, then feature fi strengthens the correlation of A, B
Define fi an correlative feature for target A and B, if zA,i , zB,i > 0; otherwise, fi is defined non-correlative
Split f into two vectors of length N: correlative f (a) and Non-correlative f (n) : if is correlative, , and 0otherwise, 0

Dealing with Noisy Features
Need a statistical test to separate noisy correlative from non-correlative features:Assume a random process is uniformly inserting counts that do not indicate class membershipA Non-Correlative B: AB
A Correlative B: AB
Perform Test on each fi given Type I Error Probability αAssume zA,i , zB,i ~N(0,1) [assumption of normality seems weak, since the distribution of z is so highly skewed – perhaps applying a geometric est. would be more appropriate]
Null Hypothesis H0: fi is non-correlative zA,i = 0 or zB,i = 0
Alt Hypothesis Halt: fi is correlative zA,i > 0 and zB,i > 0
H0 Rejection Region: zA,i > zα and zB,i > zα

Test ExampleFour distinct classes with correlative features:
Three Targets with counts from each class:
Additional Up to 10% noise is distributed uniformly on all N=1000 features
Class CA Class CB Class CC Class CD
Target t1 2,000 500 500
Target t2 1,000 500
Target t3 600 1000
Phi -- Class Probability Distributions: P(fi) in %
1 2 3 4 5 6 7 8 9 10 11 12
CA 25 25 50
CB 33 33 33
CC 30 20 50
CD 30 20 50
Correlative Features Detected at α=20%
-2 0 2 4 6 8-1
0
1
2
3
4
5
6
7
8
1 2 3
4 5
6
7 8 9
10
11
12
13 14 15 16 17
18
19 20 21 22 23 24 25
26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42
43 44 45
46
47
48 49 50 51 52 53 54 55 56
57 58 59 60 61 62 63 64 65
66 67 68 69 70 71 72
73 74 75 76
77 78 79 80 81 82 83 84 85 86 87
88 89 90 91 92
93 94 95 96 97 98
99 100
Target 1 Z-scores
Tar
get
2 Z
-sco
res
-2 0 2 4 6 80
10
20
30
40
50histogram of Z-scores
-2 0 2 4 6-1
0
1
2
3
4
5
6
7
1 2
3
4 5 6
7 8
9
10 11 12 13
14 15
16
17
18
19
20 21
22 23 24 25 26 27 28 29 30 31 32 33 34
35
36 37 38 39
40 41 42 43 44 45 46 47
48 49 50 51 52 53 54 55 56 57 58 59 60 61
62
63 64
65 66 67 68 69 70 71 72 73 74 75 76 77 78 79
80 81
82 83 84
85 86 87 88 89 90
91 92 93 94 95 96 97
98
99 100
Target 2 Z-scores
Tar
get
3 Z
-sco
res
-2 0 2 4 6 80
10
20
30
40
50Histogram of z-scores
-2 0 2 4 6 8-1
0
1
2
3
4
5
6
7
8
1 2
3
4 5 6
7 8
9
10 11 12 13
14 15
16
17
18 19 20 21 22 23
24 25 26 27 28 29 30 31 32 33 34 35
36 37 38 39 40 41
42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61
62
63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81
82 83 84 85 86 87 88 89 90 91 92 93 94
95 96 97 98
99 100
Target 1 Z-scores
Tar
get
3 Z
-sco
res
-2 0 2 4 6 80
10
20
30
40
50Histogram of z-scores
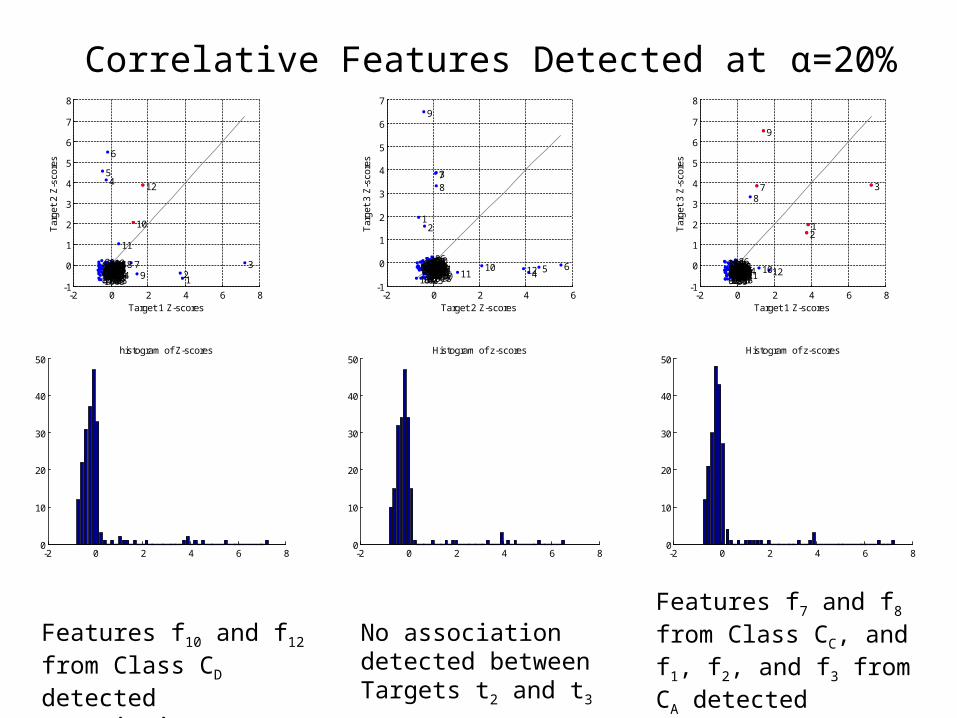
Features f10 and f12 from Class CD detected associating Targets t1 and t2
No association detected between Targets t2 and t3
Features f7 and f8 from Class CC, and f1, f2, and f3 from CA detected associating Targets t1 and t3

Term Clustering

BibliographyBaldwin, T., Kordoni, V., Villavicencio, Al., (2009) Prepositions in Applications: A Survey and Introduction to the Special Issue, Association for Computational Linguistics Volume 38, Number 2
Entity Extraction 04053148: High-Performance Unsupervised Relation Extraction from Large Corpora, Rozenfeld, Felman, ICDM’06
Unsupervised relation discovery based on clusteringUsed small number of existing relationship patterns
05743647: Extracting Descriptive Noun Phrases From Conversational Speech, BBN Technologies, 2002Used the BBN Statistically-derived Information from Text (SIFT) tool to extract noun phrases,
combined with speech recognition, using the Switchboard I tagged corpus
05340924: Named-Entity Techniques for Terrorism Event Extraction and Classification, 2009Thai Language, features derived from the terrorism gazetteer, terrorism ontology, and terrorism
grammar rule, TF-IDF distance for some standard machine learning algorithms (k-neares, SVM, Dtree)
05484737: Text analysis and entity extraction in asymmetric threat response and predictionUse of named entities lexicon and fixed bigrams to extract entities – refer to NIST Automated
Content Explorer (ACE)

Bibliography05484763: Unsupervised Multilingual Concept Discovery from Daily Online News Extracts, 2010
Applies Left and Right context to extract multi-word key terms, then applies hierarchical clustering for concept discovery
News corpus was obtained using RSS feed application called: TheYolk
0548765: Entity Refinement using Latent Semantic Indexing, Agilex, 2010starts with “state-of-the-art” commercial entity extraction software, create LSI representation
multiword text blocks, query LSI space for raked list of major terms
047-058: Evaluation of Named Event Extraction SystemsJava Entity Extractors: Annie, Lingpipe10 evaluated systems indicate problems extracting noun phrases Addresses deficiencies with conferences for NERC: CON-LL, MUC, NIST ACE / Text Analysis Conf:
http://www.nist.gov/tac/2012/KBP/
2002-coling-names –pub: Unsupervised Learning of Generalized Names, 2002Uses patterns from seed terms to learn new terms (but apparently not the surrounds)Seeks to identify generalized names from medical corpora, like “mad cow disease”

Bibliographyqatar-bhomick: Rich Entity Type Recognition in Text, 2010
word-based context-based tagger using perceptron-trained HMM
Collocation Extraction beyond Independence Assumption, ACL 2010Extracting collocations using PMI and Aggregate Markov ModelsGerman collocation gold standardVery low precision results reported
Aromatically Extracting and Representing collocations for language generation (1998), Smadja, McKeownStock Market collocations
An extensive empirical study of collocation extraction methods, ACL Student Research Workshop, 200587 features of similarity for collocationsperformance measured in Precision, Recall


















