
Context-based ontology matching and data interlinking · Context-based ontology matching and data...
27
Context-based ontology matching and data interlinking J´ erˆome Euzenat, J´ erˆ ome David, Angela Locoro, Armen Inants To cite this version: J´ erˆomeEuzenat, J´ erˆome David, Angela Locoro, Armen Inants. Context-based ontology match- ing and data interlinking. [Contract] Lindicle. 2015, pp.21. <hal-01180927> HAL Id: hal-01180927 https://hal.archives-ouvertes.fr/hal-01180927 Submitted on 9 Sep 2015 HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci- entific research documents, whether they are pub- lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers. L’archive ouverte pluridisciplinaire HAL, est destin´ ee au d´ epˆ ot et ` a la diffusion de documents scientifiques de niveau recherche, publi´ es ou non, ´ emanant des ´ etablissements d’enseignement et de recherche fran¸cais ou ´ etrangers, des laboratoires publics ou priv´ es.
Transcript of Context-based ontology matching and data interlinking · Context-based ontology matching and data...

Context-based ontology matching and data interlinking
Jerome Euzenat, Jerome David, Angela Locoro, Armen Inants
To cite this version:
Jerome Euzenat, Jerome David, Angela Locoro, Armen Inants. Context-based ontology match-ing and data interlinking. [Contract] Lindicle. 2015, pp.21. <hal-01180927>
HAL Id: hal-01180927
https://hal.archives-ouvertes.fr/hal-01180927
Submitted on 9 Sep 2015
HAL is a multi-disciplinary open accessarchive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come fromteaching and research institutions in France orabroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, estdestinee au depot et a la diffusion de documentsscientifiques de niveau recherche, publies ou non,emanant des etablissements d’enseignement et derecherche francais ou etrangers, des laboratoirespublics ou prives.

NSFC-61261130588 ANR-12-IS02-002-01
Lindicle
Linked data interlinking in a cross-lingual environment跨语言环境中语义链接关键技术研究
Liage des donnees dans un environnement interlingue
D3.1 Context-based ontologymatching and data interlinking
Coordinator: Jerome EuzenatWith contributions from: Jerome Euzenat, Jerome David, Angela Locoro,
Armen Inants
Quality reviewer: Jerome Euzenat
Reference: Lindicle/D3.1/v6
Project: Lindicle ANR-NSFC Joint project
Date: July 8, 2015
Version: 6
State: final
Destination: public

Deliverable 3.1 ANR-NSFC Joint project
Executive Summary
We introduced a distinction in ontology matching between content-based ontology matchingand context-based ontology matching. The former compares the content of ontologies todecide which entities are alike others; the latter considers the relations that ontology entitiesentertain with other resources.
The context-based approach is very well suited to matching multilingual resources sinceit does not consider the linguistic manifestation of concepts which is part of the content. Ithowever requires relations with other resources.
We first introduce the concept of context-based ontology matching by reviewing earlywork and providing a general framework for this matching approach.
We then describe more precisely the instantiation of this approach as path-based contextmatching which relies on algebras of relations for providing precise matching results.
Finally, we discuss the application of context-based techniques to data interlinking. Weshow how it can be used through finding paths across different data sets. However, the typeof relations in data sets is relatively limited so far. It can be extended by designing algebras ofrelations which encompasses ontology and data relations. These allow for inferring relationsacross data sets, ontologies, alignments and link sets. We illustrate the use of such techniquesfor finding inconsistent link sets.
The first part of this deliverable has been published in [Euzenat and Shvaiko 2013] and[Locoro et al. 2014]. Element related to data interlinking are discussed in more depth in[Inants and Euzenat 2015].
2 of 26
Lindicle
Document Information
Project number ANR-NSFC Joint project Acronym Lindicle
跨语言环境中语义链接关键技术研究Full Title Linked data interlinking in a cross-lingual environment
Liage des donnees dans un environnement interlingue
Project URL http://lindicle.inrialpes.fr/
Document URL
Deliverable Number 3.1 TitleContext-based ontology matching and data inter-linking
Work Package Number 3 Title Cross lingual ontology matching based on alignedcross lingual human-readable knowledge bases
Date of Delivery Contractual M24 Actual 2015-07-07
Status final final �Nature prototype � report � dissemination �Dissemination level public � consortium �
Authors (Partner) Jerome Euzenat, Jerome David, Angela Locoro, Armen Inants
Resp. AuthorName Jerome Euzenat E-mail [email protected]
Partner INRIA
Abstract(for dissemination)
Context-based matching finds correspondences between entities from two on-tologies by relating them to other resources. A general view of context-basedmatching is designed by analysing existing such matchers. This view is instan-tiated in a path-driven approach that (a) anchors the ontologies to externalontologies, (b) finds sequences of entities (path) that relate entities to matchwithin and across these resources, and (c) uses algebras of relations for com-bining the relations obtained along these paths. Parameters governing sucha system are identified and made explicit. We discuss the extension of thisapproach to data interlinking and its benefit to cross-lingual data interlinking.First, this extension would require an hybrid algebra of relation that combinesrelations between individual and classes. However, such an algebra may not beparticularly useful in practice as only in a few restricted case it could concludethat two individuals are the same. But it can be used for finding mistakes inlink sets.
KeywordsContext-based data interlinking, Multilingual data interlinking, Context-based ontology matching, Algebras of relations, Semantic web
Version Log
Issue Date Rev No. Author Change
2014-09-20 1 J. Euzenat Initial outline
2014-09-21 2 J. David Included context-based ontology matching descrip-tion
2015-06-19 3 J. Euzenat Summarized experiments
2015-06-24 4 J. Euzenat Elements on context-based data interlinking
2015-06-29 5 J. Euzenat Full revision
2015-07-07 6 J. Euzenat Fixed examples in Data interlinking + executivesummary
3 of 26

Deliverable 3.1 ANR-NSFC Joint project
Table of Contents
1 Introduction 5
2 Context-based matching 62.1 Early work on context-based ontology matching . . . . . . . . . . . . . . . . . 62.2 Scarlet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.3 A generalised view of context-based matching . . . . . . . . . . . . . . . . . . 9
3 Path-driven context-based matching 133.1 General overview and parameters . . . . . . . . . . . . . . . . . . . . . . . . . 133.2 Global inference through context traversal . . . . . . . . . . . . . . . . . . . . 143.3 Composing paths and aggregating correspondences . . . . . . . . . . . . . . . 163.4 Minimal path reduction in path concatenation . . . . . . . . . . . . . . . . . . 173.5 Summary of experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4 Context-based data interlinking 204.1 Path-based data interlinking . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204.2 Context-based data interlinking through ontologies . . . . . . . . . . . . . . . 204.3 Link set debugging through context . . . . . . . . . . . . . . . . . . . . . . . 21
5 Conclusion 24
4 of 26

Lindicle Introduction
1. Introduction
The Semantic Web relies on the expression of formalized knowledge on the Web. Data is ex-pressed in the framework of ontologies (theories describing the vocabulary used for expressingdata). However, due to the decentralisation of the Web, ontologies may be heterogeneousand have to be reconciled. One way to reconcile ontologies is to find correspondences be-tween their entities. This is called ontology matching [Euzenat and Shvaiko 2013] and theresulting set of correspondences is called an alignment. Each correspondence relates entitiesfrom each of the ontologies with a particular relation, e.g., equivalence, subsumption.
Context-based ontology matching works by taking advantage of intermediate resourcesto which the two ontologies to be matched can be connected. This is in contrast withcontent-based matchers, which compare the content of ontologies for matching them, whereascontext-based matching use relationships, called anchors, between the entities of the ontolo-gies to be matched and other ontologies on the web. For instance, in Figure 2.1, Beef fromthe Agrovoc thesaurus and Food from the NAL thesaurus are anchored to the concepts withthe same names in the TAP ontology. Then because Food subsumes Beef in TAP, it isassumed that Food from NAL also subsumes Beef from Agrovoc.
Context-based matchers have already been shown beneficial [Sabou et al. 2008a; Mascardiet al. 2010; Locoro et al. 2014]. However, there is a wide latitude in their design: They dependon the type of resources to be considered (ontologies, encyclopedia, fully informal resources,etc.), how relations are obtained within these resources (asserted, inferred, etc.), how manywill be considered (the first one that provides a result or as many as possible), how entitiesare anchored (simple or complex matchers), and how results are combined when there areseveral correspondences for the same pair of entities (by vote, by conjunction, etc.). Weprovide a general framework highlighting these aspects.
The goal of this report is to better explain the influence of some of these parameters onthe quality of the resulting alignments. For that purpose, we design a flexible context-basedmatcher that offers various ways to parameterise its behaviour. This renders explicit thevarious options and allows us to combine them.
The same type of principles put forward for context-based ontology matching may beused for data interlinking. This may be particularly valuable in a cross-lingual environmentas context-based techniques do not have to deal with language-based data. We consider herehow this may be further developed.
This deliverable is organised as follows: §2 introduces and synthesises the state-of-the-artin context-based matching. §3 presents the architecture of a system, generalising Scarlet,along with the main operations of context-based matching and how they have been param-eterised. §4 discusses the application of context-based approach to data interlinking. §5concludes and outlines future directions for this work.
5 of 26

Deliverable 3.1 ANR-NSFC Joint project
2. Context-based matching
Ontology matching must identify relations between ontology entities from two ontologies.These are returned as correspondences of the form 〈e, r, e′〉 such that e is an entity fromthe first ontology, e′ is an entity from the second ontology and r is the relation assumedto hold between them. Often, matchers associate a measure of their confidence with eachcorrespondence they return. In the following, we consider correspondences between namedontology entities (classes, properties, etc.). Relations may be subsumption (< and > andtheir reflexive versions ≤ and ≥), equivalence (=) or disjointness (⊥) between these entities.
Context-based matching contrasts with content-based matching. Matching ontologieswith content-based techniques compares ontology entities (classes, properties) by relyingonly on its internal content, such as their annotations, structures, and/or semantics. Forthe same purpose, context-based matching also uses the context of these ontologies, e.g.,resources that they annotate, and message exchanges between agents that use them. Forinstance, Figure 2.1 shows two entities from the Agrovoc (FAO)1 and NAL (US DoA)2
thesauri that had to be matched in the food test case of OAEI-2007 [Euzenat et al. 2007].When considering concepts Beef and Food, the use of ontologies found on the Web, such asthe TAP3 ontology, helps deduce that Beef is less general than Food. The same result canalso be obtained with the help of WordNet since Beef is a hyponym (is a kind) of Food.Thus, multiple sources of background knowledge can simultaneously help.
2.1 Early work on context-based ontology matching
Context can take different forms, such as web pages or pictures that have been annotatedwith the concepts of an ontology [Stumme and Madche 2001]. It can also be some generalpurpose resource such as a dictionary (WordNet is very often used in ontology matchers).
We concentrate here on systems that use ontological resources as context for matching.By ontological resources, we mean ontologies or knowledge bases, e.g., formalised data sets.Even with this restriction, several context-based ontology matchers have been elaboratedover the years:
– using domain specific ontologies, e.g., in the field of anatomy [Zhang and Bodenreider2007; Aleksovski 2008];
– using upper-level ontologies [Mascardi et al. 2010; Jain et al. 2011];– using linked data as background knowledge [Jain et al. 2010; Hu et al. 2011];– using all the ontologies available on the Semantic Web, such as in the work on Scar-
let [Sabou et al. 2008a].
By focusing on a specific domain, such as in [Aleksovski 2008] and [Zhang and Bodenreider2007], authors were able to provide deeper insights on ontology concept similarities, especiallybased on the analysis of its respective structural relations, i.e., not only hierarchical, butalso relational in its broadest sense (for example by means of the partOf relation), or byapproximating matching measures when different local hierarchies contain the same conceptor group of concepts.
In [Mascardi et al. 2010] general purpose upper ontologies are exploited to match ontolo-gies by relating entities if and only if they have the same upper level context. GeRoMeSuite
1http://www.fao.org/aims/ag_intro.htm.2http://www.nal.usda.gov/.3http://139.91.183.30:9090/RDF/VRP/Examples/tap.rdf.
6 of 26

Lindicle Context-based matching
Beef FoodAgrovoc NAL
TAP
Beef
MeatOrPoultry
RedMeat
Food
≤
≤
≤
=
=
≤
WordNet
Beef
Food≤
=
=
Beef
Food
= =
Figure 2.1: Scarlet example: several results are returned and must be aggregated (adaptedfrom [Sabou et al. 2008a]). Two paths are found relating Beef in Agrovoc to Food in NALand WordNet. The aggregation of their relations indicates that the former is more specificthan the latter.
has been extended to select several intermediate ontologies before performing matching [Quixet al. 2011].
The BLOOMS system [Jain et al. 2010] is a first attempt to use Linked Open Data(LOD)4 for schema-level matching. It tries to connect categories coming from two schemas,transform them in trees of senses for each concept to be matched, and compare such trees ofsenses for discovering hierarchical relations between such concepts. Its evolution, BLOOMS+[Jain et al. 2011], exploits the Proton upper-level ontology to enhance the LOD schema-levelmatching task.
Scarlet [Sabou et al. 2008a] tries to find a relation between two concepts by using all theontologies on the Web for discovering relational paths that connect them. It is presentedin more details in §2.2. In [Hu et al. 2011], a macro scale analysis of thousands of mappedontologies is carried out in order to detect morphological features as well as power distributionlaws in the resulting graphs. In this way, some hints on what exists now and on how toorganise and evolve existing knowledge on the Web by means of forthcoming ontologies areprovided.
The difficulty of context-based matching is a matter of balance: adding context providesnew information, and hence, helps increase recall, but this new information may also generateincorrect correspondences which decrease precision. However, we showed that carefully tunedcontext-based matching may actually provide more precise results [Locoro et al. 2014].
As can be observed, there are various ways to use ontological resources for context-basedontology matching. Many options can be taken concerning the type of resource to be usedor the way it is connected to the ontologies to be matched. Our goal is to explore theseoptions. For that purpose, we decided to extend an existing ontology matcher.
4http://linkeddata.org/.
7 of 26

Deliverable 3.1 ANR-NSFC Joint project
TAPmidlevel-onto
Agrovoc NALDuck
Duck
Poultry
Food
Poultry
Food
=
≤
=≤
=
≤
Figure 2.2: Scarlet composition example (adapted from [Sabou et al. 2008a]). There is nointermediate ontology providing a correspondence between Duck and Food. However, twointermediate ontologies (midlevel-onto and NAL) provide a path between these conceptsthrough the Poultry concept. The relations along this path show that Duck is more specificthan Food.
2.2 Scarlet
Our starting point was Scarlet5 [Sabou et al. 2008a] because it already took into account theversatility of context-based matching.
Scarlet [Sabou et al. 2008a; Sabou et al. 2008b] is an ontology matcher that operates bycontextualising ontologies with ontologies that can be found on the Web. But Scarlet is morecomplex than this definition, since it involves selecting ontologies for context, matching enti-ties from the initial ontologies and those of the context, and composing the relations obtainedafter matching. The rationale behind Scarlet is that using more ontologies improves the re-sults. The problem raised by the heterogeneity of ontologies is solved by taking advantageof these many heterogeneous ontologies, which is based on the following principles:
– using the ontologies on the Web as context;– composing the relations obtained through these ontologies: this covers reasoning within
the ontology for deducing the relations between entities (Figure 2.1) or reasoning acrossontologies (Figure 4.2).
In more details, Scarlet processing roughly consists of the following steps:
1. harvest ontologies on the Web with either Swoogle [Ding et al. 2005] or Watson [d’Aquinand Motta 2011];
2. select those which are related to the ontologies to match: usually this is achieved byselecting, for each pair of named entities, the ontologies that contain both names;
3. find anchors between the ontologies to match and those that have been selected: hereScarlet uses simple string equivalence;
4. compose the relations between entities through the intermediate ontologies: this isdone by returning the relation found in the ontology (see Figure 4.2);
5. aggregate the obtained results (see Figure 2.1).
When no ontology contains the pair of terms, another implemented variation was to useseveral ontologies and to bridge them in order to increase the chances to find the pair ofterms (see Figure 4.2).
5http://scarlet.open.ac.uk/.
8 of 26

Lindicle Context-based matching
This can become a very complex procedure so it is restricted to finding, for each pair ofontologies, the intersection between the entities subsuming one term and those subsumed bythe other, which helps quickly find subsumption relations (see Figure 3.1).
Three variants of Scarlet have been experimented against Agrovoc (FAO) and NAL (USDoA). The considered variants were:
S1 works with only one intermediate ontology at a time: it retrieves the ontologies coveringboth candidate terms from both ontologies, and delivers all the correspondences thatit finds between matched concepts (Figure 2.1);
S1′ is like S1 but it stops at the first correspondence that it finds;S2 implements path search in the graph of ontologies (Figure 4.2), but only through direct
subsumers (and no subsumees).
A sketch of S1 and S2 strategies is reported in Figure 2.3.
Oa
O′b
O′′
a′
b′≤O′′′
a′′b′′≤
= ===
≤O
aO′b
O′′
a′
c≤O′′′
c′
b′≤
=
=
≤
≤
Figure 2.3: Ontology matching (left) within one ontology (S1) and (right) across ontologies(S2).
In all cases, the search for anchors was provided by strict string matching on terms asbags of words, and candidate ontologies were provided by Swoogle. Because of the lack of afull reference alignment in the data set, results were manually assessed and only reported onprecision. They provide an average value of 70% precision. This is expected with the givenanchoring strategy, indeed, anchoring with string equivalence usually provides high precision.This result has even been improved by using word-sense disambiguation techniques, whichallow for better discriminating similar terms [Gracia et al. 2007]. However, this is rathergood given that Scarlet returns subsumption relations.
We went on by further generalising the Scarlet approach [Euzenat and Shvaiko 2013;Locoro et al. 2014].
2.3 A generalised view of context-based matching
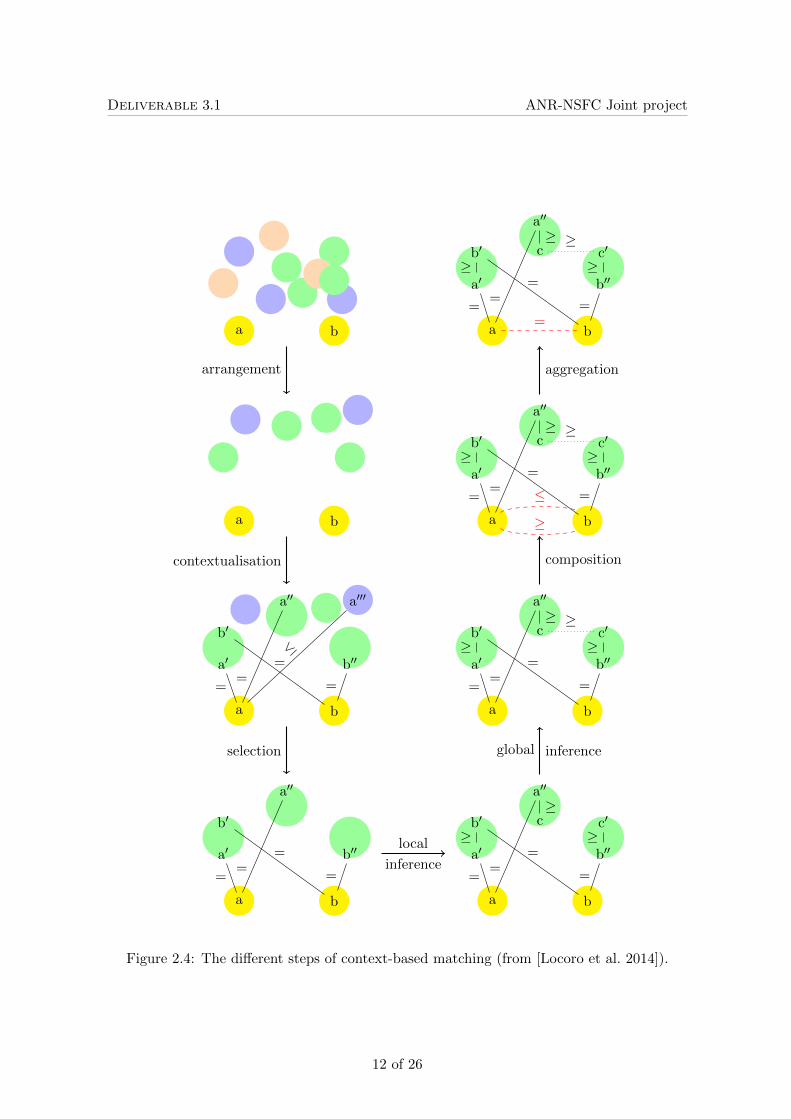
Because context-based matching is very versatile, we synthesise its behaviour in a generalisedview that aims at covering and extending existing matchers. For that purpose, we decomposethe context-based matching process in 7 steps described in Figure 2.4:
Ontology arrangement preselects and ranks the ontologies to be explored as intermediateontologies. The preselection may retain all the ontologies from the Web or ontologiesbelonging to a particular type, such as upper ontologies, domain dependent ontologies,e.g., medical or biological ontologies, competencies, popular ontologies, recommendedontologies, or any customised set of ontologies.
9 of 26

Deliverable 3.1 ANR-NSFC Joint project
The ordering may be based on the likeliness for the ontology to be useful, usuallymeasured by a distance. Such a distance may be based on the proximity of the ontologywith the ontology to be matched [David and Euzenat 2008], the existence of alignmentsbetween them [David et al. 2010], or the availability of quickly computable anchors.
Contextualisation, or anchoring, finds anchors between the ontologies to be matched andthe candidate intermediate ontologies. These anchors are obtained through an ontologymatching method or by using existing alignments. They can be correspondences of anytypes including various relations and confidence measures. In principle, any ontologymatching method may be used for anchoring; in practice, this is usually a fast methodbecause anchoring is only a preliminary step.
Ontology selection restricts the candidate ontologies that will actually be used. Thisselection relies usually on the computed anchors by selecting those ontologies in whichanchors are present.
Local inference obtains relations between entities of a single ontology. It may be reducedto logical entailment. It may also use weaker procedures, especially when intermediateresources have no formal semantics, e.g., thesauri. It could then be replaced by the useof asserted relations of the ontologies or relations obtained through composing existingones.
Global inference finds relations between two concepts of the ontologies to be matchedby concatenating relations obtained from local inference and correspondences acrossintermediate ontologies
Composition determines the relation holding between the source and target entities bycomposing the relations in the path (sequence of relations) connecting them. Thecomposition method may be functional (= · = is =), order-based (< · ≤ is <) orrelational (⊥· ≥ is ⊥).
Aggregation combines relations obtained between the same pair of entities. It can eithersimply return all correspondences or return only one correspondence with an aggre-gated relation. Aggregation itself can be based on various methods such as relationaggregation operators (e.g., conjunction), popularity (selecting the relation which isobtained from the most paths) or confidence (selecting the relation with the highestconfidence).
These steps extend those provided in the descriptions of Scarlet [Sabou et al. 2008a]:contextualisation was called anchoring, selection was considered, local and global inferenceas well as composition were gathered in a set of “derivation rules” and aggregation was calledcombining. GeRoMeSuite has also identified the arrangement (called selection), anchoring,local inference (including composition), and aggregation steps [Quix et al. 2011] to which aconsistency check is added. This presentation provides a finer decomposition of context-basedmatching that can be used for instantiating differently each (optional) step.
We may see context-based matching under a fully logical point of view: local and globalinference are replaced by entailment tests and composition and aggregation are replaced bylogical deduction. In such a case, beyond anchoring, matching is reduced to reasoning in anetwork of ontologies. Hence, when the technology of reasoning in networks of ontologies willbe fully developed, it will be possible, in principle, to reduce the seven steps to anchoringand reasoning. Matchers such as LogMap [Jimenez-Ruiz and Cuenca Grau 2011] currentlyapply this, but only between the two ontologies to match.
10 of 26

Lindicle Context-based matching
Such a framework is intellectually very seducing and mostly compatible with the frame-work proposed above. Indeed, local inference, relation composition and relation aggregationare approximations of their logical counterpart. Only global inference may be too local forfully approximating entailment in a network of ontologies.
11 of 26
Deliverable 3.1 ANR-NSFC Joint project
a′
b′
b′′
a′′
a b
=
==
=
a′
b′
b′′
c′
≥
a′′
c≥
a b
=
==
=
≥
a′′′
a′
b′
b′′
a′′
a b
=
==
=
≤a′
b′ c′
b′′
c
a′′
a b
=
==
=
≥
≥
≥
≥
a b
a′
b′ c′
b′′
c
a′′
a b
=
==
=
≥
≥
≥
≥
≤
≥
a b
a′
b′ c′
b′′
c
a′′
a b
=
==
=
≥
≥
≥
≥
=
arrangement
contextualisation
selection
local
inference
global inference
composition
aggregation
Figure 2.4: The different steps of context-based matching (from [Locoro et al. 2014]).
12 of 26

Lindicle Path-driven context-based matching
3. Path-driven context-based matching
A new version of Scarlet, named Scarlet 2.0, has been developed along the framework of theprevious section [Locoro et al. 2014]. Its characteristics are as follows:
– it still takes advantage of Watson [d’Aquin and Motta 2011; d’Aquin et al. 2007] givingaccess to the ontologies of the Web;
– like the initial Scarlet, it uses intensively a path traversal strategy,– it uses algebras of relations for expressing the relationships between concepts,– it offers precise parameterisation, so as to study the influence of their values.
We describe this approach as path-driven because the implementation uses the notion ofpaths, i.e., it considers ontologies and alignments as graphs whose ontology entities are thenodes and the statements and correspondences are the edges. In this setting, matching twoconcepts consists of (a) finding a path in this graph between them, and (b) computing therelation carried by this path. For instance, in Figure 2.1, there are two paths, one of whichis agrovoc:Beef = tap:Beef ≤ tap:MeatOrPoultry ≤ tap:ReadMeat ≤ tap:Food = nal:Food.The composition of the relations in the edges of this path yields ≤ as the relation betweenagrovoc:Beef and nal:Food.
The reason for considering the same restricted framework as Scarlet is that it is possibleto control precisely the way the algorithm explores the search space (through ontology se-lection or limitation of its exploration). Introducing more sophisticated methods, either foranchoring or for inferring, remains mostly possible. We avoided it in order to obtain clearinitial observations in the presence of simple methods.
3.1 General overview and parameters
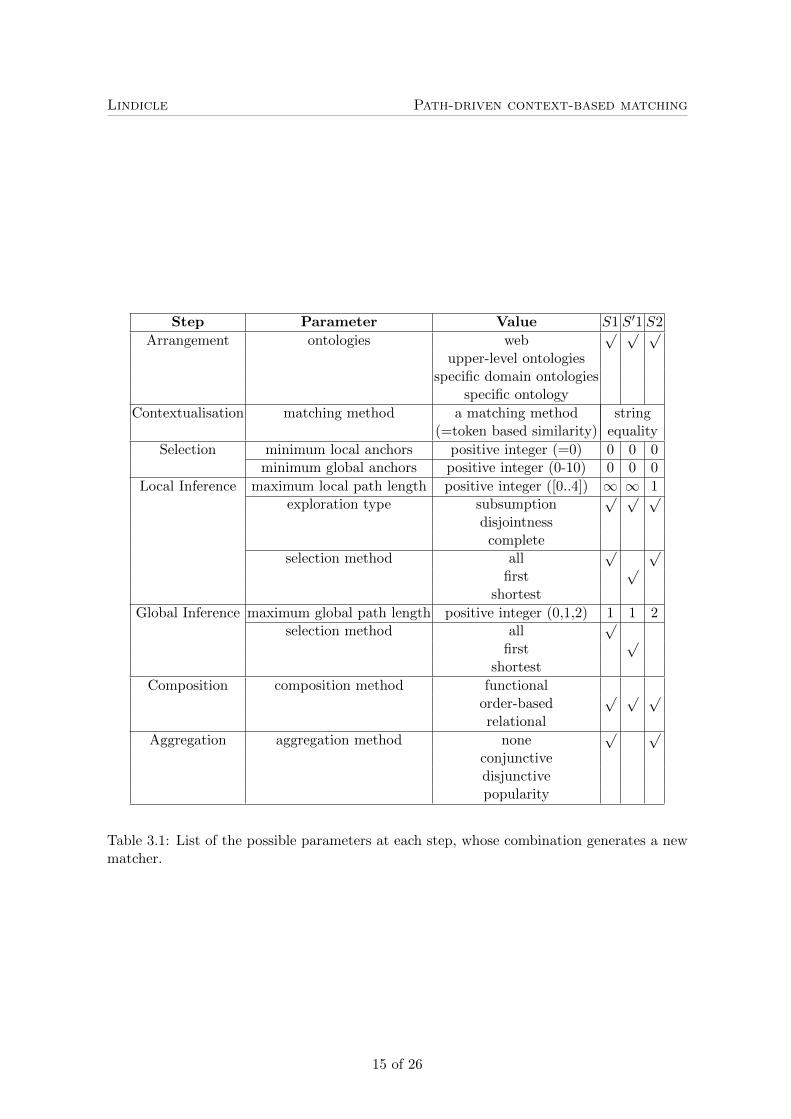
We describe below the techniques implemented in Scarlet 2.0 with respect to the frameworkof Section 2.3. The parameters governing the behaviour of the system are identified (initalics) and their further values are provided in Table 3.1.
Ontology arrangement does not do any preselection and potentially considers all ontolo-gies from the Web as provided by Watson.
Contextualisation, uses a simple matching method. This step is parameterised by theontology matching method used for anchoring. It does not take advantage of confidencemeasures. Scarlet 2.0 can use any matcher implementing the Alignment API1. In thisexperiment, we will only use a simple token-based string equality (each label is reducedto a set of tokens which are compared with string equality).
Ontology selection is governed by two thresholds on the number of anchors that have tobe found between the ontologies to be matched. A first parameter called minimumlocal anchors, is the minimal number of pairs of ontology entities that have anchorsin an ontology. A second parameter, minimum global anchors, is the minimal totalnumber of anchors found in an intermediate ontology. Obviously, if the first value isgreater than or equal to the second one, then the second one is useless. If both valuesare 0, then all ontologies are selected.
Local inference is implemented by local path exploration: it traverses an intermediate on-tology to retrieve paths, i.e., sequences of asserted relations between entities. In this
1http://alignapi.gforge.inria.fr/.
13 of 26

Deliverable 3.1 ANR-NSFC Joint project
implementation, it will attempt at finding paths between anchors, or finding subsump-tion paths of a given length around anchors (for global inference). This explorationprocess uses three parameters: (1) the maximum local path length for restricting thelength of the exploration; (2) the exploration type for determining which types of re-lations are followed; (3) the selection method for selecting which paths between a pairof entities have to be retained, e.g., the first one, the shortest one, all of them.
Global inference is implemented by global path exploration, i.e., it generates paths be-tween two concepts of the ontologies to be matched by concatenating various localpaths from distinct ontologies, such that the concept at the end of each local path isanchored to the concept at the beginning of the next local path. The maximum globalpath length parameter determines the maximal number of ontologies that may be tra-versed to return a relation between two entities. If this is 0, then the algorithm is inthe case of classical (content-based) ontology matching, and matching will be reducedto anchoring. Like before, the selection method indicates which paths are selected, e.g.,the first one, the shortest one, or all of them. The graphs traversal algorithm is furtherpresented in §3.2.
Composition In this approach, the composition method used for composing relations is thestandard composition of algebras of relations (see §3.3 for details).
Aggregation relies on an aggregation method for aggregating the relations obtained betweenthe same pair of entities. This is either an algebraic operation such as conjunction ordisjunction, e.g., the conjunction between ≤ and ≥ is =, though their disjunction is<,=, >, or popularity aggregation, which selects the relation obtained from the mostpaths.
Table 3.1 summarises the parameters identified at each step of this process and thedifferent values that they can take. It also provides approximate values for reproducing theoriginal Scarlet strategies.
We present in more detail three aspects of this procedure: graphs traversal (§3.2), relationcomposition and aggregation using algebras of relations (§3.3), and minimal path reduction(§3.4).
3.2 Global inference through context traversal
For all pairs of concepts for which a correspondence could not be found in any of the inter-mediary ontologies used during the context-matching operation, global inference can connectthe paths obtained in several context ontologies. We call:
0-context traversal content-based matching;1-context traversal context-based matching using only one context ontologies;n-context traversal context-based matching using at most n intermediate ontologies.
We describe the behaviour of 2-context traversal, which traverses two intermediary ontolo-gies. Given two concepts a ∈ o and b ∈ o′ and their respective set of intermediary ontologiesOa and Ob to which they are anchored, for any pair of ontologies 〈oa, ob〉 ∈ Oa × Ob, the2-context traversal algorithm looks if there exists an anchor 〈ca,=, cb〉 between them suchthat:
1. ca is either a subsumer or a subsumee of a ∈ oa, found by exploring oa until a givenpath length;
14 of 26
Lindicle Path-driven context-based matching
Step Parameter Value S1 S′1 S2
Arrangement ontologies web√ √ √
upper-level ontologiesspecific domain ontologies
specific ontology
Contextualisation matching method a matching method string(=token based similarity) equality
Selection minimum local anchors positive integer (=0) 0 0 0minimum global anchors positive integer (0-10) 0 0 0
Local Inference maximum local path length positive integer ([0..4]) ∞ ∞ 1exploration type subsumption
√ √ √
disjointnesscomplete
selection method all√ √
first√
shortest
Global Inference maximum global path length positive integer (0,1,2) 1 1 2selection method all
√
first√
shortest
Composition composition method functionalorder-based
√ √ √
relational
Aggregation aggregation method none√ √
conjunctivedisjunctivepopularity
Table 3.1: List of the possible parameters at each step, whose combination generates a newmatcher.
15 of 26

Deliverable 3.1 ANR-NSFC Joint project
Oa
O′b
Oa
a′
c≤
=
Ob
b′′′
c′′′
≤
c′
d
b′
≤
≤
c′′
b′′
≤=
=
=
=
=
=
≤
Figure 3.1: 2-context traversal. Of the three paths found between a and b, two return the ≤relation and the third one returns all the possible relations (Γ).
2. cb is either a subsumer or a subsumee of b ∈ ob, found by exploring ob until a givenpath length.
Once such an anchor is found, the path selection, composition and aggregation for the pairput in correspondence are applied in the usual way. A visual sketch of the algorithm isdepicted in Figure 3.1.
The difference between the 2-context traversal strategy and strategy S2 of Scarlet liesin that the intermediate concept c is now searched through the whole length of a local pathinstead of stopping at the direct subsumers or subsumees of the concepts to be matched.
3.3 Composing paths and aggregating correspondences
One of the benefits of an approach exploring different paths for finding relations is thatit may return several possible relations between two entities. Such relations may confirmor contradict each other and this has to be considered in the aggregation step. For thisreason, we use an algebra of alignment relations [Euzenat 2008; Inants and Euzenat 2015]that structures the set of possible relations.
Such an algebra of relations is based on a set of jointly exhaustive and pairwise disjointrelations Γ. This means that for any pair of concepts, there exists exactly one relationin Γ, which characterises their relative positions. Algebras of relations allow for expressinguncertainty through the use of subsets of Γ, which are interpreted disjunctively. For instance,the often used relation≤, standing for “subsumed by” or “equals to”, really stands for {<,=},the disjunction of “subsumed by” and “equals to”. The complete lattice of the 31 disjunctiverelations of such an algebra is reported in [Euzenat 2008]. For our purposes, some of themhave been named. Table 3.2 shows the complete list of named relations and some of thedisjunctive combinations, along with their symbol, a description of their interpretation, andthe short label used to refer to them in the rest of this report.
The benefits of algebras of relations is that they provide well-defined aggregation opera-tors: conjunction or disjunction of such relations correspond to set intersection and union,respectively. Hence, the relations obtained through traversing the graph of ontologies maybe aggregated with:
16 of 26

Lindicle Path-driven context-based matching
Set of relations Short Label (symbol) Description
= equiv (=) equivalence relation
< subClass (<) strict subsumption relation
> superClass (>) strict inverse subsumption relation
G overlaps (G) overlaps relation
⊥ disjoint (⊥) disjoint relation
>,= subsumesOrEqual (≥) subsumes or equivalent relations
<,= subsumedOrEqual (≤) is subsumed or equivalent relations
>, G subsumesOverlap subsumes or overlaps relations
<, G subsumedOverlaps is subsumed or overlaps relations
>, G,⊥ notSubsumed (�) is not subsumed relation
<, G,⊥ notSubsumes (�) does not subsume relation
>,<, G,= notIncompatible ( 6⊥) not disjoint relation
. . . other combinations obtained bydisjunction or conjunction
<,>, G,=,⊥ all (Γ) all relations
Table 3.2: Relation symbols that may result from a composition or aggregation operationfor the algebra of alignment relations. The first part of the table features the 5 base relationsbetween concepts.
conjunction if we consider that each path provides an exact, but non precise, relation andthat several paths contribute precising it. When the conjunction gives the ∅ relation,the resulting correspondence is inconsistent.
disjunction if we consider that each path provides a possible relation without excludingthe others.
An alternative aggregation method, independent from the algebra, is the popularity method,which retains the most frequent relation in the set of correspondences between a pair ofentities. If several relations have the same popularity, then they are disjunctively aggregated.
Algebras of relations also provide a composition operation (·), usually based on a table.For instance, {>,=} · {>} is {>} and {>,=} · {<} is 6⊥. This operation is important incontext traversal. These traversals return paths which carry sequences of relations betweenconcepts. The composition operator reduces this sequence to a relation preserving as muchinformation as possible.
For instance, a real path found by the system is:BodyOfWater = BodyOfWater ≥ FreshWaterLake ≤ Lake = Lakewhose composition brings to the notIncompatible relation ( 6⊥). Intuitively, this means that ifBodyOfWater and Lake are two concepts with a sub-concept in common, viz., FreshWater-Lake, they should not be disjoint (because in this algebra concepts are assumed non empty).Thanks to composition, the information that the two concepts are not disjoint is preserved.
3.4 Minimal path reduction in path concatenation
During the path exploration procedure, it may happen that paths are extensions of shorterpaths. Figure 3.2 shows an example of two such paths for the same pair of concepts, onepath (Path 2) being the extension of the other (Path 1). They are:
1. Hotel = Hotel ≤ ResidenceBuilding = ResidenceBuilding ≤ Residence = Residence,which by composition (= · ≤ · = · ≤ · =) yields ≤
17 of 26

Deliverable 3.1 ANR-NSFC Joint project
Hotel Residence
BuildingResidence
ResidenceBuilding
≤≤
Hotel
ResidenceBuilding
Building
≤
≤
=
Path 2
=
Path 1
=
=
≤
Figure 3.2: Two alternative paths between the same pair or concepts. One path is theextension of the other.
2. Hotel = Hotel ≤ ResidenceBuilding ≤ Building = Building ≥ ResidenceBuilding ≤Residence = Residence, which by composition (= · ≤ · ≤ · = · ≥ · ≤ · =) yields Γ.
If both paths are retained, they will be aggregated:
– conjunction gives the final correspondence 〈Hotel ≤ Residence〉;– disjunction gives the final correspondence 〈Hotel Γ Residence〉;– popularity based aggregation would result in both final correspondences 〈Hotel ≤ Residence〉,
and 〈Hotel Γ Residence〉, as they are equally occurring. In this case a disjunction ofboth the final relations is computed, the final correspondence being 〈Hotel Γ Residence〉.
So, there is a risk of having non precise correspondences if all such paths are gatheredand it is preferable to select them. There may be several ways to do it:
– select the one that goes across less ontologies: both paths traverse two ontologies, soin this example both paths 1 and 2 would be selected;
– select the shortest one: the former is the shortest, so in this example the path selectedwould be path 1;
– select the most precise one: the former is the most precise one because ≤⊆ Γ.
In our case, a procedure for always selecting the shortest path between the source and thetarget concepts is applied.
3.5 Summary of experiments
In [Locoro et al. 2014], we conducted a pinpoint analysis on context-based matching byvarying some of these parameters.
These experiments establish general observations on the behaviour of such systems, andconfirm what was previously observed:
– Not restricting the considered ontologies provides significantly more correspondencesthan selecting them a priori and this increases F-measure, although precision decreases.
– Increasing global and local path length also provides more correspondences and in-creases F-measure; the effect of local path length increase is higher than that of globalpath length.
– Ontology selection is the main parameter impacting time performance.
18 of 26

Lindicle Path-driven context-based matching
Algebras of relations allowed for finely characterising the added benefits of these pa-rameter values from the standpoint of the correctness of returned correspondences and theinfluence of the type of correspondences on this correctness. The observations are as follows:
– As paths get longer, new correct correspondences are still found;– As paths get longer, correct correspondences may become non precise by additional
relations;– As paths get longer, incorrect correspondences do not become more correct and im-
precise correspondences do not become more precise.
In summary, these experiments show once again that context-based ontology matchingincreases the quality of obtained results through multiplying sources of information. Evenif conjunction obtains the best results, it seems that finer strategies could still improve thequality of alignments.
We plan to further develop the implementation and investigate more configurations inmore situations. Developing and testing alternative aggregation strategies will also be anoutcome of this work.
We disregarded confidence measures returned by matchers. They could be consideredat each step of the framework and combined with relations [Euzenat 2008; Atencia et al.2012] for refining the obtained results. Similarly, logical reasoning may be integrated withincontext-based matching.
19 of 26

Deliverable 3.1 ANR-NSFC Joint project
4. Context-based data interlinking
The same principles that have been applied to context-based ontology matching could beconsidered for data interlinking. This could be especially beneficial in cross-lingual match-ing/interlinking since there is no need that matched resources use the same natural language.We discuss below how these principles may, or may not, be adapted.
4.1 Path-based data interlinking
The first application simply consists of composing relations between individuals of variousdata sets. owl:sameAs and owl:differentFrom are such types of relations between individuals.We will note them as = and 6= respectively. The composition table of such relations may beused in order to generate new ones. Indeed, their well known composition table is displayedin Table 4.1.
r\r′ = 6=
= = 6=
6= 6= =, 6=
Table 4.1: A2 composition table.
Figure 4.1 provides a simple example of using an authority list for interlinking data.Indeed, Viaf is a sort of meta-authority that aggregates authors of many national libraries.Hence, it is like a huge link set. The DBPedia entry for Emilly Bronte is asserted as thesame as VIAF entry 97097302 which is itself assured as the same as the entry for Ellis Bellin the German national library (Deutschen Nationalbibliothek) 1061106306. This allows todeduce the equivalence between these two entities.
Figure 4.2 generalizes this approach by taking advantage of more data sets showing thatlinks across data sets may be used in order to link chinese DBPedia for Emily Bronte to theEllis Bell entry in the German National Library.
We plan to apply this approach to data interlinking when there is sufficient intermediarydata sets.
4.2 Context-based data interlinking through ontologies
In principle, whatever has been considered for context-based ontology matching applies todata interlinking: it should be possible to compose relations between individuals and classesfreely. There are relations between classes [Euzenat 2008], relations between individuals(§4.1) as well as relations between classes and individuals such as rdf:type (∈, 3).
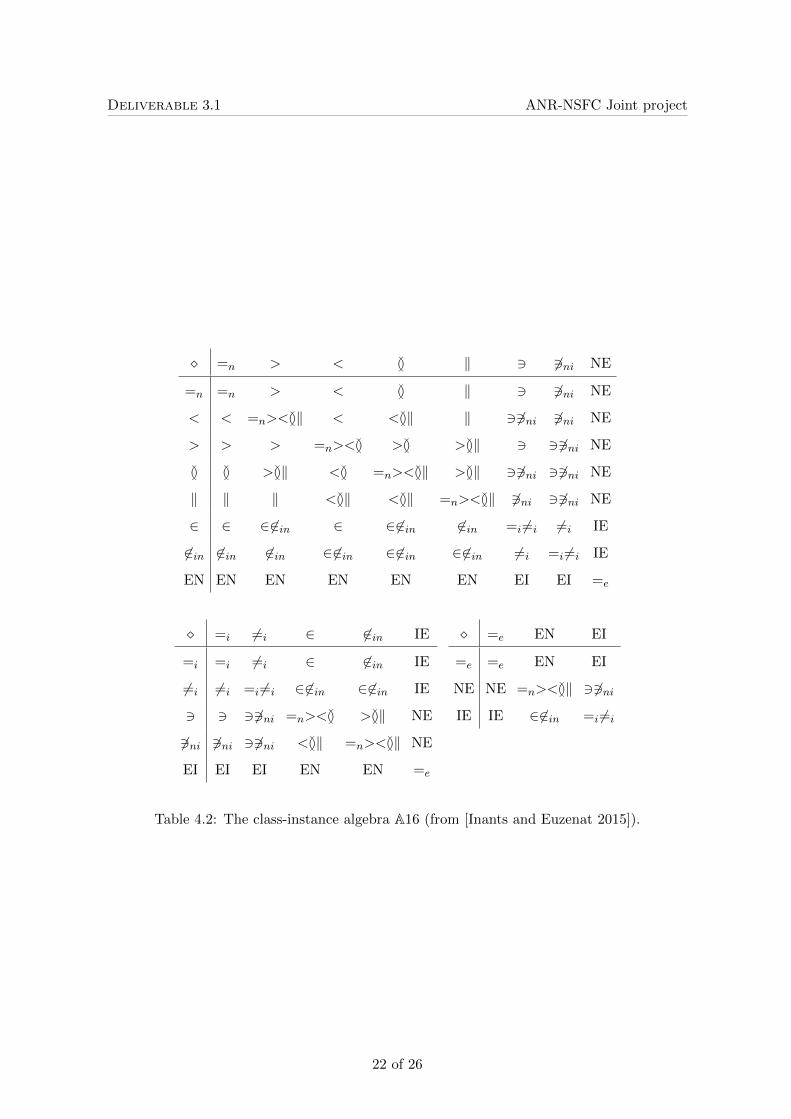
However, there are no immediate composition tables across heterogenous domains. Wehave investigated this topic both from the perspective of these specific algebras of relations[Inants and Euzenat 2015] and more generally. The resulting composition table can be foundin Table 4.2.
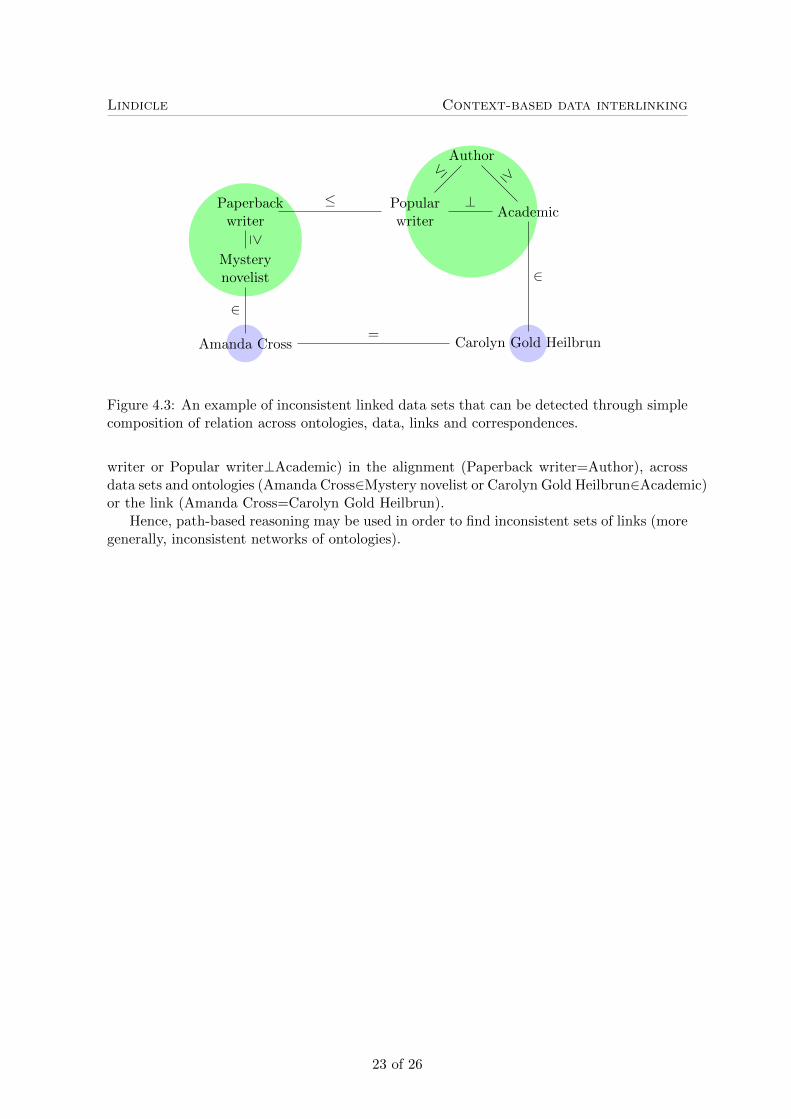
For instance, in Figure 4.3, the relation 6= between the instances “Amanda Cross” and“Carolyn Gold Heilbrun” can be inferred by composition. Indeed, composing {∈} · {<,=} · {=} · {⊥} · {3} is equivalent to {∈} · {⊥} · {3} which actually yields {6=}. Moreprecisely, in the notation of A16, {∈} � {<,=n} � {=n} � {‖} � {3} can progressively reduced
20 of 26

Lindicle Context-based data interlinking
http://dbpedia.org/resource/Emily Bronte http://d-nb.info/gnd/1061106306
VIAF
http://viaf.org/viaf/97097302/
==
=
Figure 4.1: Context-based data interlinking using Viaf as a context. Because VIAF resolvesboth Emilly Bronte and Ellis Bell as the same person, the link can be found (this was alreadytrue of the initial sources actually).
zhdbp:艾米莉·勃朗特
dbp:Emilly Bronte
gnd:1061106306
viaf:97097302
=
=
=
=
Figure 4.2: Path-based data interlinking using Viaf as a context.
to {∈,∈}�{=n}�{‖}�{3}, to {∈}�{‖}�{3}, to {6∈in}�{3}, and finally to {6=i}. This is aninstance of path-based data interlinking in which some relation can actually be inferred. Thismay be useful when such owl:differentFrom relations are needed; for instance, for extractinglink keys [Atencia et al. 2014].
Unfortunately, this approach is unlikely to provide results as relations between classesare not constraining enough to provide precise relations between individuals (the resultingrelation will, in most cases, be {=, 6=}).
4.3 Link set debugging through context
However, such reasoning may be used for debugging link sets. Indeed, if the composition ofrelations leads to the empty relation, then it is for sure that there is a problem.
For instance, in Figure 4.3 again, the relation {6=} has been inferred between “AmandaCross” and “Carolyn Gold Heilbrun”. However, they also have the = relation between themand {6=} ∩ {=} = ∅ showing that the displayed data is inconsistent.
There may be several ways to deal with this inconsistency: suppressing any of the involvedrelations, i.e., suppressing relations in any of the ontologies (Mystery novelist≤Paperback
21 of 26
Deliverable 3.1 ANR-NSFC Joint project
� =n > < G ‖ 3 63ni NE
=n =n > < G ‖ 3 63ni NE
< < =n><G‖ < <G‖ ‖ 363ni 63ni NE
> > > =n><G >G >G‖ 3 363ni NE
G G >G‖ <G =n><G‖ >G‖ 363ni 363ni NE
‖ ‖ ‖ <G‖ <G‖ =n><G‖ 63ni 363ni NE
∈ ∈ ∈6∈in ∈ ∈6∈in 6∈in =i 6=i 6=i IE
6∈in 6∈in 6∈in ∈6∈in ∈6∈in ∈6∈in 6=i =i 6=i IE
EN EN EN EN EN EN EI EI =e
� =i 6=i ∈ 6∈in IE
=i =i 6=i ∈ 6∈in IE
6=i 6=i =i 6=i ∈6∈in ∈6∈in IE
3 3 363ni =n><G >G‖ NE
63ni 63ni 363ni <G‖ =n><G‖ NE
EI EI EI EN EN =e
� =e EN EI
=e =e EN EI
NE NE =n><G‖ 363ni
IE IE ∈6∈in =i 6=i
Table 4.2: The class-instance algebra A16 (from [Inants and Euzenat 2015]).
22 of 26
Lindicle Context-based data interlinking
Amanda Cross
Paperbackwriter
Mysterynovelist
Carolyn Gold Heilbrun
Author
Popularwriter
Academic
≥
≤ ≥
∈
≤ ⊥
∈
=
Figure 4.3: An example of inconsistent linked data sets that can be detected through simplecomposition of relation across ontologies, data, links and correspondences.
writer or Popular writer⊥Academic) in the alignment (Paperback writer=Author), acrossdata sets and ontologies (Amanda Cross∈Mystery novelist or Carolyn Gold Heilbrun∈Academic)or the link (Amanda Cross=Carolyn Gold Heilbrun).
Hence, path-based reasoning may be used in order to find inconsistent sets of links (moregenerally, inconsistent networks of ontologies).
23 of 26

Deliverable 3.1 ANR-NSFC Joint project
5. Conclusion
Context-based matching is based on the assumption that putting ontologies in the context ofother ontologies may improve matching. In this report, we provided a framework identifyingimportant steps of context-based ontology matching and parameters that may influence itsbehaviour.
We explained how such a framework may be extended to data interlinking but thisrequires to compose relations across classes and individuals. Such techniques may also beused for debugging ontologies, data sets, alignments and link sets. We plan to put the pathbased approach using links transitivity into practice by using either multilingual thesauri orthe transitivity from XLore to dpbedia.fr through dbpedia.en.
24 of 26

Lindicle BIBLIOGRAPHY
Bibliography
Aleksovski, Zharko (2008). “Using background knowledge in ontology matching”. PhD thesis.Vrije Universiteit Amsterdam (cit. on p. 6).
Atencia, Manuel, Alexander Borgida, Jerome Euzenat, Chiara Ghidini, and Luciano Serafini(2012). “A formal semantics for weighted ontology mappings”. In: Proc. 11th Interna-tional semantic web conference (ISWC), Boston (MA US), pp. 17–33 (cit. on p. 19).
Atencia, Manuel, Jerome David, and Jerome Euzenat (2014). “Data interlinking throughrobust linkkey extraction”. In: Proc. 21st european conference on artificial intelligence(ECAI), Praha (CZ), pp. 15–20 (cit. on p. 21).
d’Aquin, Mathieu and Enrico Motta (2011). “Watson, more than a Semantic Web searchengine”. In: Semantic web journal 2.1, pp. 55–63 (cit. on pp. 8, 13).
d’Aquin, Mathieu, Claudio Baldassarre, Laurent Gridinoc, Sophia Angeletou, Marta Sabou,and Enrico Motta (2007). “Characterizing Knowledge on the Semantic Web with Wat-son”. In: EON, pp. 1–10 (cit. on p. 13).
David, Jerome, Jerome Euzenat, and Ondrej Svab-Zamazal (2010). “Ontology Similarity inthe Alignment Space”. In: International Semantic Web Conference (1), pp. 129–144 (cit.on p. 10).
David, Jerome and Jerome Euzenat (2008). “On fixing semantic alignment evaluation mea-sures”. en. In: Proc. 3rd ISWC workshop on ontology matching (OM), Karlsruhe (DE).Ed. by Pavel Shvaiko, Jerome Euzenat, Fausto Giunchiglia, and Heiner Stuckenschmidt,pp. 25–36 (cit. on p. 10).
Ding, Li, Rong Pan, Tim Finin, Anupam Joshi, Yun Peng, and Pranam Kolari (2005).“Finding and Ranking Knowledge on the Semantic Web”. In: Proc. 4th InternationalSemantic Web Conference (ISWC), pp. 156–170 (cit. on p. 8).
Euzenat, Jerome and Pavel Shvaiko (2013). Ontology matching. en. 2nd. Heidelberg (DE):Springer-Verlag. 520 pp. (cit. on pp. 2, 5, 9).
Euzenat, Jerome, Antoine Isaac, Christian Meilicke, Pavel Shvaiko, Heiner Stuckenschmidt,Ondrej Svab, Vojtech Svatek, Willem Robert van Hage, and Mikalai Yatskevich (2007).“Results of the Ontology Alignment Evaluation Initiative 2007”. In: Proc. 2nd Interna-tional Workshop on Ontology Matching (OM) at the International Semantic Web Con-ference (ISWC) and Asian Semantic Web Conference (ASWC). Busan (KR), pp. 96–132(cit. on p. 6).
Euzenat, Jerome (2008). “Algebras of ontology alignment relations”. en. In: Proc. 7th inter-national semantic web conference (ISWC), Karlsruhe (DE). Vol. 5318. Lecture notes incomputer science, pp. 387–402 (cit. on pp. 16, 19, 20).
Gracia, Jorge, Vanessa Lopez, Mathieu d’Aquin, Marta Sabou, Enrico Motta, and EduardoMena (2007). “Solving Semantic Ambiguity to Improve Semantic Web based OntologyMatching”. In: Proc. 2nd ISWC Ontology Matching workshop (OM 2007), Busan (KR),pp. 1–12 (cit. on p. 9).
Hu, Wei, Jianfeng Chen, Hang Zhang, and Yuzhong Qu (2011). “How Matchable Are FourThousand Ontologies on the Semantic Web”. In: Proc. 8th Extended Semantic Web Con-ference (ESWC), pp. 290–304 (cit. on pp. 6, 7).
Inants, Armen and Jerome Euzenat (2015). “An Algebra of Qualitative Taxonomical Re-lations for Ontology Alignments”. In: Proc. 14th international semantic web conference(ISWC), Bethlehem (PA US). Lecture notes in computer science (cit. on pp. 2, 16, 20,22).
Jain, Prateek, Pascal Hitzler, Amit Sheth, Kunal Verma, and Peter Yeh (2010). “Ontologyalignment for linked open data”. In: Proc. 9th International Semantic Web Conference
25 of 26

Deliverable 3.1 ANR-NSFC Joint project
(ISWC). Vol. 6496. Lecture Notes in Computer Science. Shanghai (CN), pp. 401–416(cit. on pp. 6, 7).
Jain, Prateek, Peter Yeh, Kunal Verma, Reymonrod Vasquez, Mariana Damova, Pascal Hit-zler, and Amit Sheth (2011). “Contextual Ontology Alignment of LOD with an UpperOntology: A Case Study with Proton”. In: Proc. 8th Extended Semantic Web Conference(ESWC), pp. 80–92 (cit. on pp. 6, 7).
Jimenez-Ruiz, Ernesto and Bernardo Cuenca Grau (2011). “LogMap: Logic-Based and Scal-able Ontology Matching”. In: Proc. 10th International Semantic Web Conference (ISWC).Vol. 7031. Lecture Notes in Computer Science. Springer, pp. 273–288 (cit. on p. 10).
Locoro, Angela, Jerome David, and Jerome Euzenat (2014). “Context-based matching: designof a flexible framework and experiment”. en. In: Journal on data semantics 3.1, pp. 25–46(cit. on pp. 2, 5, 7, 9, 12, 13, 18).
Mascardi, Viviana, Angela Locoro, and P. Rosso (2010). “Automatic Ontology Matching viaUpper Ontologies: A Systematic Evaluation”. In: IEEE Trans. Knowl. Data Eng. 22.5,pp. 609–623 (cit. on pp. 5, 6).
Quix, Christoph, Pratanu Roy, and David Kensche (2011). “Automatic selection of back-ground knowledge for ontology matching”. In: Proc. International Workshop on SemanticWeb Information Management (SWIM), Athens (GR). ACM, p. 5 (cit. on pp. 7, 10).
Sabou, Marta, Matthieu d’Aquin, and Enrico Motta (2008a). “Exploring the Semantic Webas Background Knowledge for Ontology Matching”. In: J. Data Semantics 11, pp. 156–190 (cit. on pp. 5–8, 10).
Sabou, Martha, Mathieu d’Aquin, and Enrico Motta (2008b). “SCARLET: SemantiC Re-lAtion DiscoveRy by Harvesting OnLinE OnTologies”. In: ESWC, pp. 854–858 (cit. onp. 8).
Stumme, Gerd and Alexander Madche (2001). “FCA-Merge: Bottom-Up Merging of Ontolo-gies”. In: Proc. 17th International Joint Conference on Artificial Intelligence (IJCAI).Seattle (WA US), pp. 225–234 (cit. on p. 6).
Zhang, Songmao and Olivier Bodenreider (2007). “Experience in aligning anatomical ontolo-gies”. In: International Journal on Semantic Web and Information Systems 3.2, pp. 1–26(cit. on p. 6).
26 of 26


















