
Object Recognition. So what does object recognition involve?

Auton Robot (2016) 40:175–192DOI 10.1007/s10514-015-9451-2
Construction of a 3D object recognition and manipulationdatabase from grasp demonstrations
David Kent1 · Morteza Behrooz2 · Sonia Chernova2
Received: 5 May 2014 / Accepted: 30 June 2015 / Published online: 10 July 2015© Springer Science+Business Media New York 2015
Abstract Object recognition and manipulation are criticalfor enabling robots to operate in household environments.Many grasp planners can estimate grasps based on objectshape, but they ignore key information about non-visualobject characteristics. Object model databases can accountfor this information, but existing methods for databaseconstruction are time and resource intensive. We presentan easy-to-use system for constructing object models for3D object recognition and manipulation made possible byadvances in web robotics. The database consists of pointclouds generated using a novel iterative point cloud registra-tion algorithm. The system requires no additional equipmentbeyond the robot, and non-expert users can demonstrategrasps through an intuitiveweb interface.Wevalidate the sys-temwith data collected fromboth a crowdsourcing user studyand expert demonstration. We show that the demonstrationapproach outperforms purely vision-based grasp planningapproaches for a wide variety of object classes.
Electronic supplementary material The online version of thisarticle (doi:10.1007/s10514-015-9451-2) contains supplementarymaterial, which is available to authorized users.
B David [email protected]
Morteza [email protected]
Sonia [email protected]
1 Department of Robotics Engineering, Worcester PolytechnicInstitute, Worcester, MA, USA
2 Department of Computer Science, Worcester PolytechnicInstitute, Worcester, MA, USA
Keywords Object manipulation · Grasp demonstration ·Crowdsourcing
1 Introduction
The abilities to recognize and manipulate a variety of objectsare critical for robots operating autonomously in householdenvironments. These environments often contain a large vari-ety of objects with which a robot may need to interact. Assuch, a robot must automatically determine useful propertiesof encountered objects, or make use of a database of knownobjects. Automatic grasp detection can lead to difficultiesin determining usability characteristics for arbitrary objects,e.g. a bottle of water should not be grasped in such a way thatthe opening is obstructed, preventing pouring. A database ofknown objects enables this type of information to be encodedinto the object models.
A major disadvantage of using object recognition data-bases is that they require a significant amount of work toconstruct. Large object recognition databases do exist, butresearchers are then limited to using only the objects ortypes of objects with corresponding database entries, whichin turn limits the environments in which a robot can oper-ate. Adding new models to a database requires obtaining adetailed model of each new object or object type. The cur-rent state of the art is to use a turntable with sensors mountedaround it in a specific setup (Lai et al. 2011; Kasper et al.2012). This is a time consuming approach, and it cannot beused for learning in a real-world environment, where such adetailed setup is impractical. Learning object models basedon real-world observations encountered during operation inthe target environment is a more challenging problem sincethe object angles and relationships between multiple views
123

176 Auton Robot (2016) 40:175–192
are unknown. Additionally, the challenges of collecting suf-ficient training data and object labels must also be overcome.
It is difficult to determine usability information for a setof objects using an autonomous process without any priorknowledge of the object, as environments can have a largenumber of objects that must all be grasped with different cri-teria inmind. Complicating the grasping issue further, certaindifficult-to-observe physical characteristics of objects, suchas weight distribution, fragility of materials, or other mate-rial properties, need to be accounted for when performing asuccessful grasp. Grasp demonstration by human users pro-vides a natural way to convey hard-to-observe informationto robots, although it can be repetitive and time consuming.
The developing field of web robotics provides new solu-tions for the collection of training data for both object recog-nition and grasp demonstration. Crowdsourcing improvesthese repetitive tasks by reducing the time and effort requiredfromeach individual user, while still providing large amountsof data. One successful method of taking advantage ofthe Internet for object recognition is in using large anno-tated datasets from online image search engines, such asFlickr or Google (Chatzilari et al. 2011; Torralba et al.2008).Wepresent a differentmethod of incorporating crowd-sourcing into an object recognition and grasping system, inwhich participants connect remotely to a robot and labelobjects while demonstrating grasps through teleoperation.This allows for robot-specific data beyond object labels,such as successful grasp examples, to be collected via theweb. With participants demonstrating both object recogni-tion and manipulation techniques, the data can automaticallyreflect usability characteristics.Wepresent amethodof incor-porating data collected from crowdsourcing into an objectrecognition and grasping database, resulting in an automatedgrasping technique that inherently accounts for usability con-straints.
This article makes three contributions. First, we presenta web-based system for the collection of point cloud dataand demonstrated grasps for a desired set of objects. Wedesigned this system specifically to allow inexperienced par-ticipants to remotely demonstrate grasps and collect objectdata while controlling a sophisticated robotic manipulationplatform through a web browser. Furthermore, the systemmakes it easy to add new objects, and requires no furtherequipment than the robot itself. We present a data collec-tion user study in which we explore three study conditionsto determine how to most effectively engage participants andimprove their success rate, thereby providing us with greateramounts of usable data in a shorter period of time.
The second contribution is a system for constructing afunctional object recognition system using only point clouddata gathered in an unstructured environment. The systemconstructs 3D object models given a set of point cloud rep-resentations of objects collected from various object views,
using a novel graph-based point cloud registration algorithmthat identifies disparate sets of overlapping point clouds andintelligently merges each set of point clouds with commonfeatures. We demonstrate that when combined with objectlabels provided by either a researcher or through crowd-sourcing, these 3D object models can be used for objectrecognition. We present results of using this object recog-nition system with the object database constructed from acrowdsourcing user study. We also include further analysisusing supplemental data collected from a larger and morevaried set of objects.
The final contribution is a system for incorporating grasp-ing data into the object recognition database, while stillmeeting the original goals of the recognition database, i.e.that it should be easy to add new objects, and no extraequipment other than the robot and the objects themselveswould be required. Both this ease of use and lack of setupallows the process to be crowdsourced, which is appealingto researchers who want to quickly expand the capabilitiesof their system. We also compare the effectiveness of thecrowdsourced grasps to expert demonstrated grasps, and weshow the advantages that this grasping system has over agrasp planner based solely on the geometry of the object.
2 Related work
This section begins with an overview of crowdsourcing foruser studies involving robots, followed by a discussion ofexisting methods for constructing object recognition data-bases, and concludes with a survey of approaches for graspplanning.
2.1 Crowdsourcing
Crowdsourcing, or obtaining information from a largeamount of people over the Internet, is a technique with grow-ing relevance for robotics (Kehoe et al. 2015). In particular,it has the potential to change the way researchers conductuser studies. These user studies require a remote lab setting,in which users can control a robot through the web. Onesuch example of a remote lab is the PR2 remote lab, whichprovided a framework for allowing trained and expert usersto interact with a shared PR2 over the Internet (Crick et al.2012; Pitzer et al. 2012). This remote lab was not designedwith untrained users in mind, and as such it was not suitedto large-scale crowdsourced user studies. Addressing thisproblem led to the development of the robot managementsystem (RMS) (Toris et al. 2014), which provides tools forresearchers to create, manage, and deploy user study inter-faces that allow naive users to directly control robots througha web browser. RMS allows anyone with an Internet connec-tion to remotely participate in a user study from the comfort
123

Auton Robot (2016) 40:175–192 177
of their ownhome.Alongwith its ability to reach large groupsof people, RMS includes automatic user scheduling, whichallows user study sessions to be run with little to no break inbetween. These properties make RMS an excellent systemfor implementing a crowdsourcing experiment.
Sorokin et al. conducted previouswork using crowdsourc-ing for novel object grasping (Sorokin et al. 2010). In thiswork, the researchers divided object modeling into subprob-lems of object labeling, human-provided segmentation, andfinal model verification. Workers on Amazon MechanicalTurk (AMT), a microtask crowdsourcing marketplace, com-pleted these simpler tasks. Sorokin demonstrated successfulobject recognition and grasping using the results obtainedfrom AMTworkers. Microtask crowdsourcing marketplacesdo have some limitations, however. The system does notallow for direct control of a robot, and researchers mustdesign tasks to be simple and quick to ensure for high qual-ity data. With new web robotics systems such as RMS (Toriset al. 2014), we can performmore complicated tasks, includ-ing the grasp pose demonstrations used in this article.
Chung et al. used crowdsourcing to provide demonstra-tions for a goal-based learning method applied to objectconstruction (Chung et al. 2014). They showed that, formany applications, goal imitation can provide better resultsthan trajectory imitation, and furthermore this method can begreatly accelerated by crowdsourcing, providing a large num-ber of varied goals. We use a similar goal-based approach tolearning grasps for object manipulation, although we extendthe crowdsourcing aspect to giver users control of a physicalrobot, which immediately provides detection of failed graspdemonstrations.
Crowdsourcing has been successfully applied to otheraspects of robotics, as well. Tellex et al. used crowdsourc-ing to learn natural language commands for controlling robotnavigation and manipulation (Tellex et al. 2011). Crick et al.showed that crowdsourcing could be used to test interfacesfor teaching a robot to navigate a maze, showing that remoteusers perform better when limited only to information thatthe robot has (Crick et al. 2011). Other studies have shownthat crowdsourcing can be used to learn human-robot inter-action behaviors, and that gamification of the data collectionprocess helps to motivate users to provide useful data (Cher-nova et al. 2011; Breazeal et al. 2013).
Quality of data is an important concern in crowdsourcing.The relative anonymity of remote participants as comparedto traditional user study participants decreases motivationto provide high quality data. Harris explores incentivizationmodels for improving the quality of crowdsourced data byproviding numerical rewards based on the success of partic-ipants. Furthermore, the study has shown that providing aperceived negative numerical reward on participant failurecan further improve the quality of data (Harris 2011). Webuilt on these ideas by designing a scoring system involv-
ing both positive and negative rewards to motivate remoteparticipants to provide accurate data in a timely manner.
2.2 Object recognition databases
One method for crowdsourcing object recognition involvesthe use of online image search databases. Chatzilari et al.demonstrate that a database consisting of annotated imagesdownloaded from Flickr is sufficient to recognize objects(Chatzilari et al. 2011). A downside to this approach is thatit is limited to the set of keywords used during download.Generalizing this type of approach to work for any potentialobject, Torralba et al. constructed a dataset by downloading760 Gigabytes of annotated images using every non-abstractnoun in the English language over the course of 8 months(Torralba et al. 2008). Because of the limitations that arisefrom keyword selection, we avoided the use of online data-bases for the object recognition system presented in thisarticle. Furthermore, there are no large databases comparableto online image searches that also contain object manipula-tion data (e.g. grasp points).
There are many alternative methods to creating objectrecognition databases that do not use the Internet. Lai et al.provide an example of a common approach to building 3Dmodels (Lai et al. 2011). Using a constantly rotating turntableand a set of camerasmounted atmultiple angles from the tablehorizon, accurate 3D object models can be constructed foruse in object recognition. Kasper et al. also used a turntableto construct 3D object models for the KIT object modelsdatabase, although they required a larger and more expen-sive array of sensors (Kasper et al. 2012). A disadvantageof these approaches is that they require an accurate setupof sensors and turntables to produce an accurate model, andeach new object must be scanned individually using sucha process. As with using online databases, these techniquesalso do not allow for the collection of grasp information.
There is also a set of methods that use a technique simi-lar to the turntable approach, except that instead of using aturntable, they have a robot grasp the object, rotate it in frontof its sensor, and repeat this process until a full object modelcan be formed (Kraft et al. 2008; Krainin et al. 2011). Thesetechniques are convenient in that they do not require externalsetup, and the robot can perform the action autonomously.While they can produce accurate models, their disadvantageslie in finding a good way to determine an initial grasp, and assuch they often have the disadvantages of vision-based graspplanners, discussed in Sect. 2.3.
In contrast with ordered point cloudmodel reconstruction,there are also methods to combine unordered point clouddata. Automatic registration of overlapping point clouds canbe accomplished through feature matching (Rusu et al. 2009;Sehgal et al. 2010), correlation of extended Gaussian images
123

178 Auton Robot (2016) 40:175–192
(Makadia et al. 2006), and geometric optimization (Mitraet al. 2004).
Computer vision researchers have demonstrated manyapproaches that construct 3D object models from ordered(Azevedo et al. 2009; Esteban and Schmitt 2004) andunordered (Brown and Lowe 2005) sets of 2D images aswell. These approaches are effective for generating 3D mod-els, but similar problems arise as with the turntable method,as they do not allow for the collection of grasping informationabout the objects.
2.3 Grasp planning
Many methods already exist for vision-based grasp plannersthat use data from depth images. Many of these approachesforgo object recognition and rely solely on geometric analy-sis of partial views of novel objects to compute effectivegrasp points (Stückler et al. 2013; Jiang et al. 2011; Saxenaet al. 2008). Vision-based grasp planners can be effective forgraspingmany objects, but they do not account for any objectinformation beyond an object’s visible shape.
In this workwe useWillowGarage’s PR2 robot. This plat-form has two common off-the-shelf grasp planners. One usespoint cloud data without an object recognition component(Hsiao et al. 2010), which is susceptible to the same prob-lems as the previously discussed vision-based grasp planners.The other grasp planner incorporatesWillowGarage’s house-hold objects database (Garage2010),whichmatches detectedobjects to complete 3Dmodels, and includes a set of examplegrasps calculated for each model using the GraspIt! sim-ulator. The database was designed to work with a limitedset of commonly available objects. It relies on detailed 3Dmodeling and is constrained to objects that are either rota-tionally symmetric, or have no indentations or concavities.As a result, the approach is less suitable to new environmentsbecause of the difficulty in adding new object models. Addi-tionally, the grasps in the household objects database werecalculated solely based on object shape; they do not accountfor other object properties such as weight or material. Ourmethod aims to solve the same problem as the PR2’s graspplanners, i.e. to determine a successful grasp pose given anincomplete point cloud of an object, but we seek to improvethe quality of the grasps from a usability standpoint, removethe restrictions on object shape, and simplify the process ofadding new objects.
Work has also been done on autonomous grasp evaluationbased on usability characteristics. Baier and Zhang (2006)present four grasp usability criteria, and include analyticalmethods for evaluating them. The four criteria are pour-in,pour-out, handover, and movement. The pour criteria arespecific to objects that require unobstructed openings forpouring, but the second two criteria generalize well to all
objects, in that they measure the ease of which an objectcan be re-grasped, as well as a grasp’s resistance to move-ment. These criteria represent some usability characteristicsof objects, but there are many unrepresented characteristicsthat are specific to other objects.Additionally, there is also theissue of determining which usability characteristics shouldapply to which objects. Both of these issues make it diffi-cult to explicitly define usability characteristics for arbitraryobject sets.
These usability characteristics are, however, naturallyknown by humans, and Xue et al. present a system forleveraging human knowledge, as well as other non-visionbased object characteristics, into a multi-modal grasp plan-ning system (Xue et al. 2009). The system requires datacollection of an object’s shape, texture, and weight, andalso allows input from human instructors who demonstrateareas that either must be touched during grasping, or must beavoided as obstacles. The drawback of this approach is that itrequires a complicated setup, including a digitizer, turntable,movable stereo camera setup, and a tactile glove. Thisapproach is also unsuitable for crowdsourcing, as it requires atrained demonstrator to give semantic information about eachobject.
Other object model databases exist that include grasp-ing information, such as the partial-view-based data-drivengrasping system presented in Goldfeder et al. (2009b). Thissystem adds the object recognition component to the partial-view depth image grasp planners, and retrieves grasp pointsfrom an online database. The system is more concernedwith the recognition side of the problem, though, and doesnot address where the grasp data comes from or how itcan be used. Another object model and grasping databaseaddresses the problem of defining grasps by using a set ofgrasps exhaustively calculated offline based on CADmodels(Morales et al. 2006); this requires any object to be modeledin detail before it can be used. Similarly, Goldfeder et al.present a large-scale database constructed with grasps calcu-lated using the GraspIt! simulator (Goldfeder et al. 2009a).The simulator was used to replace human grasp demonstra-tions to reduce time constraints in constructing a database ofthousands of objects. As a result, the database includes manybaseline form closure grasps for each object.
An alternative to calculating grasp points is to learn themthrough trial and error. Detry et al. present an autonomousexperimentation system where a robot learns grasp points byrepeatedly attempting to grasp an object at various points andadjusting probabilistic grasping models based on the results(Detry et al. 2011).We use a similar idea for evaluating graspmodels, except we use crowdsourced human-demonstratedgrasps to decrease the amount of time of the trial-and-errorlearning system, while also leveraging human knowledge ofobject usability characteristics.
123

Auton Robot (2016) 40:175–192 179
Fig. 1 A pipeline showing auser connecting to a robotenvironment via the RMS
3 The robot management system
The RMS is an open-source framework that allowsresearchers to quickly and easily install, configure, anddeploy a secure and stable remote lab system.1 The RMSallows naive users to create accounts, gain access to robots,and participate in research studies.
The framework is designed in a robot and interfaceindependent manner. At its core, the RMS is a customcontent management system written in PHP backed by aMySQL database. Its main goal is to keep track of differ-ent ROS enabled robotic environments, interfaces, users, andresearch studies with little need of additional programmingby researchers. Furthermore, the system is fully integratedand takes advantage of the tools and libraries developedas part of the Robot Web Tools effort (Alexander et al.2012). By doing so, such a system enables researchers tofocus on the goals of their research without needing to spendcountless hours testing and implementing a customweb solu-tion. The RMS was developed with the following goals inmind:
– Robot and interface independent design– Support for easy creation and management of new wid-gets and interfaces
– Secure user authentication and authorization– Creation, management, logging, and analysis of multi-condition user studies
– Website content management
The complete pipeline for RMS is shown in Fig. 1. Wewill briefly explain parts of the pipeline relevant to this arti-cle below, including robot, environment, interface, and userstudymanagement. For more details on the complete system,see Toris et al. (2014).
Managing robots and their environments The RMSfocuses much of its efforts on managing robots and robot
1 Documentation and source code are available at http://www.ros.org/wiki/rms. Tutorials are available at http://www.ros.org/wiki/rms/Tutorials.
environments. We define a robot environment as a singlerobot and its associated surroundings. The RMS uses thegenericness of ROS message and service types to allow thecontrol and sensor displays of an abstract set of robots.Withinour research group alone, the RMS has been easily connectedto complex, research-grade robots such as the PR2 fromWil-low Garage and the youBot from KUKA, to simple robotssuch as the Rovio from WowWee. The job of the RMS is tokeep track of how to connect to each robotic environmentand its associated control and sensor feeds. Researchers canquickly configure each environment by adding informationsuch as camera feeds, arm and base control services, or pointcloud topics. In this work, we use a PR2 robot with a headmountedKinect sensor. TheRMS allows us to stream camerafeeds from the PR2 and point cloud data from the Kinect toremote user study participants, while also allowing remoteusers to control the robot’s end effectors through ROS mes-sages.
Interface management An important feature of theRMS isthe ability to manage different interface layouts. This allowsthe ability to conduct studies such as A/B interface test-ing or creating interfaces based on varying levels of userexpertise. In this work, we use the RMS to define three ver-sions of a PR2 teleoperation interface with varying levels offeedback.
User study management Researchers can create user stud-ies that can then have one ormore associated conditions. Eachcondition is also associated with an interface. For our userstudy, further described inSect. 4,wedefined three study con-ditions corresponding to varying levels of feedback, and thenassociated each condition with an interface that displayedthe appropriate level of feedback. With conditions defined,researchers are then able to schedule individual experiments(trials). Such a trial consists of mapping a user to a given con-dition (and thus interface), environment, and start/end time.The RMS then keeps track of this information and will alloweach particular user to gain access to the appropriate roboticenvironment using a given interface at the correct times. Theusers will only be allowed to use the interface once their timeslot begins, andwill be automatically disconnected once theirtime has ended.
123

180 Auton Robot (2016) 40:175–192
4 Data collection
Leveraging the RMS, we conducted a crowdsourced userstudy to gather object recognition and grasping data for thedatabase. In this section, we describe our data collectionprocess, user interface and three study conditions.
4.1 Experimental setup
For the data collection study we recruited 42 participantsthrough advertising on the campus of Worcester PolytechnicInstitute and in the surrounding area. The study setup con-sisted of a PR2 robot placed in a fixed position. The robotfaced a table containing ten household objects arranged inrandom positions and orientations, as shown in Fig. 2. Thetable itself consisted of six sections marked with boundarylines.
The study was conducted using RMS, which enabled par-ticipants to remotely connect to a PR2 interface from theirhome computers using only awebbrowser. Theweb interfaceconsisted of two main components, shown in Fig. 3. In theview component, participants could switch between videofeeds from the cameras in each of the PR2’s arms, as wellas the RGB video stream from a head-mounted MicrosoftKinect sensor. Participants could also control the directionthe head was pointing to adjust the video feed view by usingthe arrow keys. In the control component, participants usedinteractive markers on a simulated robot model to change theposition and orientation of the physical robot’s end effectors.Thiswindow also showed the segmented point clouds of eachobject detected on the table.
Participants connected to the robot for sessions consist-ing of twenty minutes. Upon initial connection, the interfacedisplayed the set of instructions shown in Fig. 4. Theseinstructions explained both the interface controls and the par-ticipant’s goal, in as compact a space as possible. At any timeduring the user study, participants could show the instructions
Fig. 2 Physical setup of the user study
Fig. 3 An example of the web interface used in the remote user study.The interface element (a), shown in red, displayed the participant’s cur-rent score. This element was active for the score only and full feedbackconditions. The interface element (b), shown in green, displayed com-ments based on the participant’s performance. This element was activefor the full feedback condition only (Color figure online)
Fig. 4 The user study instructions shown in the interface. For the NoFeedback condition, any mention of points and scores were removed
again by clicking on the Show/Hide Instructions button. Allparticipants were instructed to pick up as many objects aspossible within the allotted time. After grasping an object,the interface asked participants to label the object. The inter-face then highlighted a randomly selected section of the tablesurface where participants were to place the object. In thismanner, the user study was automatically resetting, in thateach newparticipant began the studywith a different arrange-ment of objects, determined by how the previous user placedeach object. Participants were classified into one of threestudy conditions, as described in Sect. 4.2.
Upon successfully picking up an object, the system stored:
– the segmented point cloud of the grasped object using thehead-mounted Kinect,
– the position and orientation of the PR2’s gripper,– force data from the sensor array on each gripper finger,and
– the object label provided by the participant.
The system stored this data in a database for later use inconstructing3Dobjectmodels. The randomizedobject place-ment allowed for the collection of data for multiple commonorientations of each object, without the need for a researcher
123

Auton Robot (2016) 40:175–192 181
Fig. 5 Left An example of point cloud data gathered upon a successfulobject pickup. Right an object model constructed from the databasegenerated by the user study
to change the object orientations between each user session.Figure 5 shows an example of point cloud data gathered inthe user study, as well as an object model constructed fromthat data.
While using a simulated environment would have allowedconcurrent session execution, thus gatheringmore data, usinga physical setup also has some advantages. First, data col-lected from the physical robot maintains consistency withthe robot’s calibration and environmental conditions, such aslighting. Second, it allows the interface to immediately pro-vide feedback on whether a grasp succeeds or fails, withoutthe need to accurately model complex physics interactions.This makes it easier to quickly collect data for new objects,as they don’t need to be modeled first for simulation.
4.2 Feedback and participant motivation
Because this was our first user study using RMS to collectdata entirely from remote users, we collected further data todetermine how best to motivate participants to provide highquality data. We equally divided participants among threeconditions:
– No feedback—Participants were simply instructed topick up as many objects as possible within the allottedtime.
– Score only—Participants were shown a score thatrewarded them for accomplishing the goals of the study.Participantswere given 100 points for successfully grasp-ing an object, 50 points for successfully placing an objectwithin the correct table section, and −10 points foreach failed pickup attempt. The scores were stored inan online leaderboard so that participants could competewith eachother.
– Full feedback—In addition to the score described above,the interface also provided text feedback, shown inTable 1, offering praise for successful pickups, encour-agement to keep trying after failed pickups, and sugges-tions to revisit the instructions if they remained idle fora long period of time.
Table 1 Feedback for the full feedback study condition
Activation condition Text feedback
Successful pickup or placement Nice job!
Way to go!
Great job!
Keep it up!
Nice work!
Nicely done!
Failed pickup or placement Give it another try!
Nice try!
Keep at it!
You can do this!
Never give up!
Idle for 20 s Let’s get some objects!
Take your time to figure itout...
Idle for 30 s If you are confused, tryclicking on theShow/Hide Instructionsbutton below...
Object off of table You’re holding an object offof the table edge
In the No Feedback condition, participants had only theinstruction set to guide their actions, and so the tasks theychose to complete were based entirely on their respectiveinterpretations of the instructions. Since we conducted thestudy remotely, participants could not ask questions to clar-ify what they were supposed to do, and we could not correctany misinterpretations of the instructions. This conditionprovided a point of comparison for how participants wouldperformwithout any feedback to guide their interpretation ofthe task.
The Score Only condition added a numerical feedbackelement to the study. We designed the scoring system toreinforce the elements of the study that were most importantto our data collection. As such, participants were rewardedmost for successful object grasps, which were the primarydata collected during the user study. To further stress theimportance of object grasping, we gave negative feedbackonly for missed object grasps. Correct object placement wasa secondary goal, as it aided in the self-resetting nature of thestudy, hence the lower point reward. Overall, the scoring alsoadded an element of competition, motivating participants topick up as many objects as they could to compete with otherparticipants.
While the score added a feedback element based directlyon a participant’s actions, we also wanted to determinewhether semantic feedback would improve a participant’sperformance. The Full Feedback condition added feedbackin the form of pre-authored phrases displayed in response to
123

182 Auton Robot (2016) 40:175–192
specific actions. Aswith the score, we designed these phrasesto provide positive reinforcement for successfully complet-ing important actions in the user study, but unlike the score,the text feedback could also encourage participants to keeptrying when they failed important actions. The text feedbackalso helped to supplement the participants’ understandingof the environment by displaying a warning when the robotwas holding an object off of the table edge, which could bedifficult to see given the limited camera views.
We designed the score feedback to fit in with the interfacecolor scheme in a non-distracting manner, while catchingthe eye of participants with a flipping animation when theirscore was increased or decreased. Similarly, we designed thefeedback text to catch the participant’s attention using com-plimentary colors, while being small enough to not distractfrom the task at hand. Examples of a score and displayed textin the interface can be seen in elements A and B of Fig. 3,respectively.
Importantly, the point cloud and grasp data collectionprocess was the same across all three study conditions.The purpose of this study was to examine which conditionresulted in the highest quantity and quality of data.
5 Object model construction
Given the set of individual segmented point clouds of eachobject collected using the above data collection method, thenext step was to create more complete object models fromthese individual views. First, we used the Point CloudLibrary(PCL) (Rusu and Cousins 2011) to implement a pairwisepoint cloud registration pipeline. This process allows themerging of any two point clouds into a single point cloudaccording to correlated SIFT features.
Theoretically, we could construct a complete objectmodelby iteratively performing this pairwise point cloud reg-istration process for all of an object’s data. In practice,however, pairing point clouds arbitrarily in this way is highlysusceptible to error propagation. Aside from minor errorspropagating, a single incorrect merge early on in the processcan result in highly inaccurate models. It is therefore criticalto distinguish successful merges from failed merges, wherewe define a successful merge as one in which all overlappingpoints common to both point clouds are correctly aligned, sothat a human being would verify it as a single object.
We present a novel approach for building object modelsthrough iterative point cloud registration. For each pair ofpoint clouds, we first calculate a set of metrics that charac-terize the potential merge with respect to different properties.Using these metrics, and a training set of hand labeled suc-cessful and failed pairwise point cloud registrations, we thentrain a decision tree to predict successful merges. Finally,we leverage the decision tree to construct a graph represen-
tation of candidate pairwise merges that are then iterativelyperformed to generate the object model.
5.1 Classification of successful merges
In considering a candidate merge, we define one point cloudmodel as the base point cloud B, and the other as the tar-get point cloud T . R represents the point cloud that resultsfrom registering T onto B, and we define bn , tn , and rn asthe individual points within B, T , and R, respectively. Welet distanceXY Z(i, j) and distanceRG B(i, j) representthe Euclidean distance in XYZ space and RGB color spacebetween points i and j , respectively; nn(p, X) represents thenearest neighbor of point p in point cloud X . Finally, para-meter δ represents a predefined Euclidean distance thresholdbetween two points in a point cloud.
Based on this representation, we use the following set ofmetrics to describe a candidate point cloud resulting from apairwise registration:
– Overlap (mo)—percentage of overlapping points afterregistration
mo = |{i |bi − nn(bi , T ) < δ, i ∈ B}||B| (1)
– Distance error (md Err )—the mean of the distance errorbetween merged point pairs
md Err = 1
|B|∑
i
distanceXY Z(bi , nn(bi , T )) (2)
– Color error (mcErr )—the mean of the color differencebetween overlapping points
mcErr = 1
n
∑
n
distanceRG B(bn, nn(bn, T )),
n ∈ {i |bi − nn(bi , T ) < δ, i ∈ B} (3)
– Average color difference (mcAvg)—average color differ-ence between point clouds B and T
mcAvg = abs(avg(bi .r + bi .g + bi .b)
−avg(ti .r + ti .g + ti .b)),
i ∈ B, j ∈ T (4)
– Color deviation difference (mcDev)—difference in stan-dard deviation of color between point clouds B and T
mcDev = abs(stdev(bi .r + bi .g + bi .b)
−stdev(ti .r + ti .g + ti .b)),
i ∈ B, j ∈ T (5)
123

Auton Robot (2016) 40:175–192 183
– Size difference (msize)—difference in the number ofpoints between point clouds B and T
msize = abs(|B| − |T |) (6)
– Spread difference (mspread )—difference in the spread(i.e. the distance between the two most distant pointswithin a point cloud) of point clouds B and T
mspread = abs(max(distanceXY Z(bi , b j ))
−max(distanceXY Z(tk, tl))),
i, j ∈ B; k, l ∈ T ; i �= j; k �= l (7)
We designed these metrics to represent different charac-teristics of the data. mo and md Err measure differences inphysical shape of the two point clouds. Furthermore, mo pro-vides an indication of how much new data is added to cloudB by registering it with cloud T . mcErr , mcAvg , and mcDev
measure differences in point cloud color; where mcAvg indi-cates the overall similarity in color of the point clouds,mcDev
indicates whether the two point clouds have similar rangeof color, and mcErr measures differences of color betweenoverlapping points of clouds B and T . The remaining met-rics represent a comparison of the overall size of the pointclouds, with msize relating their total number of points andmspread relating their maximum physical lengths.
Initial threshold tests showed the metrics are useful forclassifying merges. For example when using mo, the metricexperimentally determined to bemost effective at classifyingsuccessful merges, 72.4% of the training data was correctlyclassified, with a false positive rate of 16.1%. We also notethat, since some of themetrics are significantly affectedwhena candidate merge has a low mo (most notably, the candidatewill likely have a higher distance error and a higher size dif-ference),we require amore sophisticated classifier to accountfor this.
As such, we leveraged thesemetrics to train a decision treeto predict successful merges.We constructed a training set byapplying the seven metrics to 174 instances of pairwise pointcloud registrations selected from the user study data. Thisincluded both successful and failedmerges, and each instancewas appropriately labeled. Using this dataset, we used theC4.5 algorithm (Quinlan 1993) to generate a decision treeto classify whether a pairwise registration was successful orfailed based on the registration metrics. The final decisiontree correctly classified 86.8% of the training data, with afalse positive rate of 4.6%.Minimizing the false positive rateasmuch as possiblewas themost important factor in selectingthe final classifier, as accepting a failed merge propagateserror throughout the rest of the object model constructionprocess. The decision tree used mo as the most important
classification metric, with md Err , mcAvg , and mspread alsoused as important metrics.
5.2 Graph-based object model generation
To construct the object model, we developed an algorithm(Algorithm 1) that first generates a graph structure repre-senting all of the point clouds for each individual object in agraph, and then selectively registers pairs of point clouds togenerate one ormore objectmodels. The algorithm initializesa graph with a node representing each point cloud (line 3).It next iteratively considers all pairs of nodes, and constructsedges between them for which the decision tree predicts asuccessful pairwise merging of the two point clouds repre-sented by the nodes (lines 4–8). The resulting graph structurerepresents the similarities between the various views of theobject.
The objectmodel is constructed by collapsing the graph bymerging nodes until no edges remain. The algorithm selects arandom edge of the graph and performs pairwise registrationon the point clouds connected by the selected edge (lines 10–11). The algorithm then removes the nodes for the two pointclouds, and replaces them with a single node representingthe new merged point cloud (lines 12–14). Again using thedecision tree, the algorithm constructs edges from the newnode to the remainder of the nodes in the graph (lines 15–19).The process then repeats until there are no graph edges left.
Algorithm 1 Object model construction by graphRequire: List<PointCloud> P1: List<PointCloud> nodes;2: List<Edge> edges;3: nodes.addAll(P);4: for all ni , n j in nodes do5: if isSuccessfulRegistration(ni , n j ) then6: edges.add(Edge(ni , n j ));7: end if8: end for9: while edges is non-empty do10: Edge e = edges.pop();11: PointCloud p = pairwiseRegister(e.node1, e.node2);12: nodes.remove(e.node1, e.node2);13: edges.removeEdgesContaining(e.node1);14: edges.removeEdgesContaining(e.node2);15: for all ni in nodes do16: if isSuccessfulRegistration(p, ni ) then17: edges.add(Edge(p, ni ));18: end if19: end for20: end while
Figure 6 provides a visual example of the object modelconstruction algorithm for a set of 8 point clouds {A, B, C, D,E, F, G,H}, all collected from the same object (step 1). In step2, each pairwise combination of the point clouds is checkedfor successful registrations, resulting in the graph shown in
123

184 Auton Robot (2016) 40:175–192
Fig. 6 Avisual example of themodel construction graph.Graph nodesrepresent point clouds, dashed edges represent unchecked pairwiseregistrations, and solid edges represent predicted successful pairwiseregistrations
step 3. The algorithm then randomly selects point clouds Band C to be merged, resulting in a new graph shown in step 4with a new set of unchecked point cloud pairs. In step 5, theunchecked pairs are tested for successful registration. For thenext step, the algorithm randomly selects point clouds E andG formerging. This process of testing andmerging continuesuntil no successfulmerges remain, and step 15 shows the finalset of models {ABCFH, DEG}.
The result is that the process can represent each objectby multiple object models composed of merged point cloudsfrom different views. For objects that look significantly dif-ferent depending on the viewing angle (e.g. the front andback cover of a book), this removes the risk of poorly merg-ing point clouds taken from significantly different angles andpropagating that error through future iterative registration.This method also provides flexibility for adding new data;if any new data is obtained, it can be merged into the exist-
ing data by initializing graph nodes for both the previouslymerged object models and the new data.
The entire model construction algorithm takes a set ofpoint clouds as input, and produces a set of object modelsfor each object to be used in object recognition. The algo-rithm can be run either per object, where a separate graph isconstructed for the point clouds associated with each indi-vidual object, or for the entire dataset, where a single graphis constructed using all of the point clouds as nodes. The lat-ter approach has a significantly higher runtime, but as thisis essentially a training algorithm, it does not have to run inreal-time.
5.3 Object recognition
In order to test the usefulness of the models created by theprocess described above, we implemented an object recog-nition system based on processes similar to those used inthemodel construction. Specifically, using the same pairwisepoint cloud registration pipeline implemented for the modelconstruction, the object recognition algorithm attempts toregister a point cloud from an unknown object to each objectmodel in the recognition database. By calculating themetricslisted above, the algorithm assigns a measure of error to eachattempted pairwise registration. The recognition algorithmthen classifies the query object as the database object thatresulted in the lowest error.
We define the registration error, serr , as a linear combi-nation of the normalized distance error and the normalizedcolor error.
serr = α ∗ norm(md Err ) + (1 − α) ∗ norm(mcErr ) (8)
The parameter α can be set within the range [0, 1] to adjustthe relative weighting of the distance error and color error.Setting α closer to 0 causes the algorithm to prioritize differ-ences in color rather than shape; likewise setting α closer to 1causes the algorithm to prioritize differences in shape ratherthan color. For all experiments presented in this article, weset α to 0.5, since we consider differences in shape and colorto be equally important in our object sets.
We note that this recognition algorithm was designedspecifically to evaluate the models generated by our process.Its runtime scales linearly with the number of models in thedatabase, and so in practice we recommend first filtering can-didate models by pre-computable attributes, such as averagecolor, model dimensions, etc.
6 Grasp learning
Now that we have the ability to model and recognize objectsin 3D, we turn to the problem of learning grasp poses. In
123

Auton Robot (2016) 40:175–192 185
Fig. 7 One object model with all of the associated grasp poses demon-strated from the user study
this section, we first describe how grasps are mapped to the3D model, and then present an outlier filtering algorithmthat removes obviously erroneous grasps. We then presentan online training algorithm that learns probabilistic successrates for the remaining grasps, to both determine the orderin which grasps should be attempted and remove any erro-neous grasps missed during the outlier filtering phase. Theresult is a database of object models with associated graspposes ordered by success rate. Figure 8 provides examplesof visualized output from each major step of the process.
6.1 Grasp model
As described in Sect. 4, each point cloud sample recordedby our system also contains the associated grasp point. Bycreating a merged object model using the above process, wecreate a 3D object model with multiple associated grasps.We accomplish this by extending the registration algorithmdescribed in Sect. 5 to combine the individual grasps into alist of grasps associated with the object model. Each pairwiseregistration within the algorithm produces a transformationmatrix. Applying this transformation matrix to the demon-strated grasp pose at each pairwise registration step results ineach object model also containing an associated set of graspsin its local reference frame. Figure 7 shows one of the objectmodels generated from the user study, and further examplesare shown in the left column of Fig. 8.
6.2 Outlier filtering
With the object models constructed, the next step of thegrasp learning system focuses on evaluating the usefulnessof the demonstrated grasps. This is a crucial step because
Fig. 8 A visualization of the grasp learning pipeline for three objectmodels. The figure shows only a subsample of the collected grasps tobetter facilitate visualization. Left all grasp examples from data col-lection. Middle remaining grasps after outlier filtering. Right final setof grasps after online training, sorted into high-probability (green) andlow-probability (red) grasps.All of these exampleswere generated fromthe user study data (Color figure online)
demonstrated grasps can result in low quality grasp poses,due to poor object segmentation or grasps that accidentallynudge an object before lifting it up. This is particularly truewith crowdsourced grasps demonstrated by non-expert users,where quality of data cannot be guaranteed.
The grasp training algorithm, described further in the nextsection, also detects and removes unsuccessful grasps froman object model. This is an online algorithm that requiresthe robot to determine each grasp’s quality through trial anderror, and as such it becomes time consuming with largenumbers of grasps. The goal of the outlier filtering phaseis to eliminate as many grasps as possible with an offlinealgorithm, before the object models are passed through tothe online grasp training phase.
With only a point cloud representation of an arbitraryobject, it is difficult to determine the effectiveness of a graspbased solely on its location relative to the point cloud. To pre-vent the removal of potentially successful grasps, the onlygrasps that can be removed with high certainty are thosethat lie on the outside of the point clouds. Specifically, thealgorithm fits a bounding box around the point cloud, andremoves any grasps that are located outside of the boundingbox at a distance greater than half the length of the robot’sopen gripper. These grasps will most likely miss the objectentirely; this can be seen in Fig. 8, where one outlying graspis removed for both the bowl and the phone.
123

186 Auton Robot (2016) 40:175–192
Algorithm 2 Epsilon-greedy grasp trainingRequire: List<Grasps> grasps1: List<Grasps> exploredGrasps;2: ε = 1;3: while grasps.size() > 0 do4: r = rand(0, 1);5: if r < ε then6: Grasp g = pickRandom(grasps);7: else8: Grasp g = maxGraspProbability(exploredGrasps);9: end if10: Boolean success = testGrasp(g);11: updateGraspProbability(g, success);12: g.numAttempts ++;13: if g.numAttempts ≥ N then14: exploredGrasps.push(g);15: grasps.remove(g);16: end if17: ε = 0.975 ∗ ε;18: end while
6.3 Grasp training
The final phase of the grasp learning system learns proba-bilistic success rates for each grasp, which are then used todetermine a grasp order for each object. An epsilon-greedyalgorithm, Algorithm 2, learns these probabilities by testingeach grasp repeatedly with the robot. The algorithm beginswith a list of grasps to be tested, an empty list for storing suf-ficiently explored grasps, and by initializing the explorationvariable, ε (lines 1–2). The algorithm continues to select andtest grasps until every grasp associatedwith amodel has beenattempted a minimum of N times (lines 3 and 13). Duringeach loop iteration, the algorithm selects grasps by either ran-domly exploring the set of untested grasps, or by selectingan already explored grasp with the highest chance of success(lines 4–9). The robot then performs the selected grasp, eval-uates its success, and updates the success rate and number ofgrasp attempts accordingly (lines 10–12).
The value of ε determines the exploration strategy bywhich new or previously attempted grasps are selected.Higher values of ε result in more frequent exploration; con-versely, lower values of ε result in more frequent executionof the previously explored grasps. The algorithm begins witha high value of epsilon, which decays exponentially (line 17)as the training continues. As such, the algorithm first spendsmost of its time attempting unexplored grasps, and as timegoes on, it spends more time refining the success rates forthe learned grasps. Over time, ε decays to zero, and fur-ther exploration of untested grasps will no longer occur. Forlarger grasp sets, such as a large crowdsourced dataset ofgrasp demonstrations, the algorithm can be adjusted to ter-minate after it finds a sufficient number of successful grasps,by changing the loop condition in line 3.
Upon completion of the training, the algorithm discardsany grasps with a success rate of zero from the model. For
example, Fig. 8 shows one grasp removed from both thebone and the phone after the training algorithm determinedthat the grasps had no chance of success. The example alsoshows high-probability (graspProbabili t y > 0.5) graspsin green. These grasps will be attempted first, and the low-probability grasps (0 < graspProbabili t y ≤ 0.5), shownin red, will only be attempted if all of the high-probabilitygrasps are unreachable from the current robot position.
The results presented below used training with N set to3. Increasing N can increase the accuracy of the successrates, at the trade-off of increasing training time. To makeup for this short training time, we continue to update thegrasp model online after the dedicated training process iscomplete. This lifelong learning could lead to slow adapt-ability once the number of grasp attempts gets high, whichcould be improved by keeping grasp success data over a slid-ing window of previous attempts. For this article, we did notperform any long-term testing with the grasping database,and all results were gathered using this continual learning.We leave improvements for long-term use to future work.
7 Results
In this section, we present results of the user study and ofthe object recognition and grasp learning system. We firstpresent the results regarding the effectiveness of the dif-ferent feedback levels from each user study condition, todetermine which method best facilitates crowdsourced datacollection. We then evaluate the usefulness of object data-bases created using the system described in Sects. 5 and 6for both object recognition and object manipulation, basedon both user study data and researcher demonstrated data.
7.1 User study evaluation
To determine whether the different feedback conditionsimproved participant performance, we analyzed the numberof successful pickups, failed pickups, successful placements,and failed placements from participants in each condition.The most relevant measures for the user study were the totalnumber of pickups, as this determines how much data eachexperiment contributed to the object recognition database,and the rate of successful placements, as this indicates howwilling participants were to follow given instructions. Fig-ure 9 shows plots of the number of pickups and rate of correctplacement.
The pickup data has a trend suggesting that feedbackcan improve participant performance in a crowdsourcingsituation. Not only do the two feedback conditions showparticipants outperforming the No Feedback condition, butparticipants in the Full Feedback condition had a greaternumber of successful pickups than participants in the Score
123

Auton Robot (2016) 40:175–192 187
Fig. 9 The number of successful pickups per participant (left) and therate at which participants correctly placed objects within the boundariesof the randomized table section (right), organized by condition. Thehorizontal axis denotes the condition: (1) full feedback, (2) score only,and (3) no feedback
Only condition. A similar trend appears in the rate of correctplacement, although the differences between the Full Feed-back and Score Only conditions are less apparent.
While there appear to be clear trends showing that inter-faces with more feedback improve both the performance ofparticipants and their willingness to follow instructions, werequire more data to reach statistical significance. We leavethe verification of these trends through the collection of moredata to future work.
7.2 Object recognition evaluation
In the following section, we present an evaluation of theobject recognition database using the object recognition sys-tem described in Sect. 5.3. We evaluate the recognitionsuccess rate for both the set of objects used in the crowdsourc-
Fig. 10 The ten household objects used in the user study
ing user study, aswell as a supplemental object set containinga greater number of varied objects.
7.2.1 User study object set
The data collected from the crowdsourcing user study pro-vided a set of point clouds for each object; Fig. 10 shows theobject set used in the study. The amount of point clouds col-lected varied in the range of 3 to 27 point clouds per object,as participants could pick up any of the objects as many timesas they chose.
As mentioned in Sect. 5, the object model constructionalgorithm could have generated models without first orga-nizing the data by object. This works in theory, since thelearned decision tree can determinewhether two point cloudsbelong to different objects as theywill result in a failedmerge.In practice, however, the potential for an incorrect registra-tion between two different but similar looking objects createsa dangerous risk of error propagation, thus we deem theapproach not robust enough for practical use. Further refine-ment to the decision tree could reduce this risk, but that isbeyond the scope of this article.
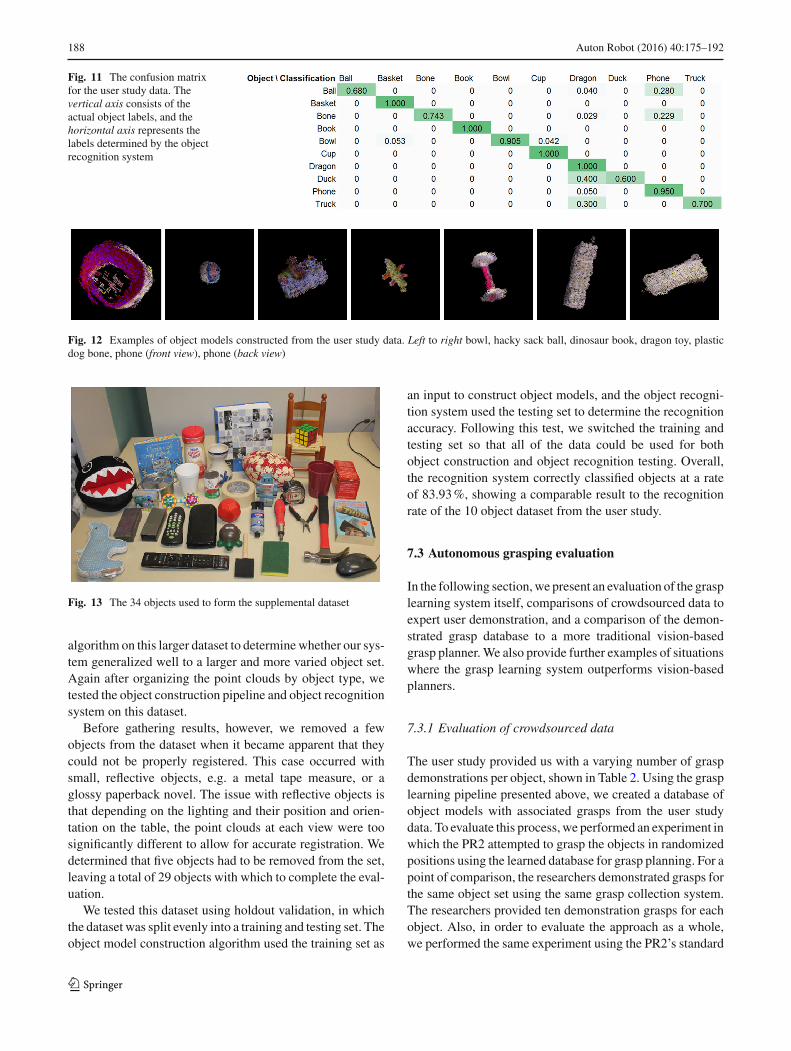
To better demonstrate the generalizability of the objectconstruction and recognition system, we evaluated the datausing repeated random sub-sampling validation. For eachiteration of testing, the point clouds for each object were ran-domly split into a training set (used for model construction)and a test set (used for object recognition). We performedfive iterations of testing. Overall, the recognition systemcorrectly classified objects at a rate of 88.7% +/− 5.1%.Figure 11 shows the confusion matrix for the set of objects,where entries along the main diagonal represent correct clas-sifications and any other cell represents a misclassification.Figure 12 provides examples of object models generated bythe object model construction algorithm.
7.2.2 Supplemental object set
In addition to the data collected from the user study, we col-lected supplemental data on a larger set of thirty-four objects,shown in Fig. 13. The purpose of this supplemental data wasto determine how well the recognition system scaled to alarger object set, containing objects of similar shapes (e.g.multiple cups, books, and remotes) and similar colors (e.g.a set of tools with the same color scheme). This data didnot include any grasping information, as it was collected tofurther test the object recognition system. We designed thisdata collection procedure to mimic the data collected in theuser study. We placed each object in randomized poses andlocations on the table, and stored 20 segmented point cloudscaptured from an Asus Xtion Pro depth sensor mountedabove a table at a similar height and angle as the PR2’shead-mounted Kinect. We analyzed the performance of the
123
188 Auton Robot (2016) 40:175–192
Fig. 11 The confusion matrixfor the user study data. Thevertical axis consists of theactual object labels, and thehorizontal axis represents thelabels determined by the objectrecognition system
Fig. 12 Examples of object models constructed from the user study data. Left to right bowl, hacky sack ball, dinosaur book, dragon toy, plasticdog bone, phone (front view), phone (back view)
Fig. 13 The 34 objects used to form the supplemental dataset
algorithm on this larger dataset to determinewhether our sys-tem generalized well to a larger and more varied object set.Again after organizing the point clouds by object type, wetested the object construction pipeline and object recognitionsystem on this dataset.
Before gathering results, however, we removed a fewobjects from the dataset when it became apparent that theycould not be properly registered. This case occurred withsmall, reflective objects, e.g. a metal tape measure, or aglossy paperback novel. The issue with reflective objects isthat depending on the lighting and their position and orien-tation on the table, the point clouds at each view were toosignificantly different to allow for accurate registration. Wedetermined that five objects had to be removed from the set,leaving a total of 29 objects with which to complete the eval-uation.
We tested this dataset using holdout validation, in whichthe dataset was split evenly into a training and testing set. Theobject model construction algorithm used the training set as
an input to construct object models, and the object recogni-tion system used the testing set to determine the recognitionaccuracy. Following this test, we switched the training andtesting set so that all of the data could be used for bothobject construction and object recognition testing. Overall,the recognition system correctly classified objects at a rateof 83.93%, showing a comparable result to the recognitionrate of the 10 object dataset from the user study.
7.3 Autonomous grasping evaluation
In the following section,we present an evaluation of the grasplearning system itself, comparisons of crowdsourced data toexpert user demonstration, and a comparison of the demon-strated grasp database to a more traditional vision-basedgrasp planner.We also provide further examples of situationswhere the grasp learning system outperforms vision-basedplanners.
7.3.1 Evaluation of crowdsourced data
The user study provided us with a varying number of graspdemonstrations per object, shown in Table 2. Using the grasplearning pipeline presented above, we created a database ofobject models with associated grasps from the user studydata. To evaluate this process, we performed an experiment inwhich the PR2 attempted to grasp the objects in randomizedpositions using the learned database for grasp planning. For apoint of comparison, the researchers demonstrated grasps forthe same object set using the same grasp collection system.The researchers provided ten demonstration grasps for eachobject. Also, in order to evaluate the approach as a whole,we performed the same experiment using the PR2’s standard
123

Auton Robot (2016) 40:175–192 189
Table 2 Number of successful grasps demonstrated by user study par-ticipants
Object Basket Bone Book Bowl Cup Dragon Duck Phone Truck
Grasps 22 15 10 27 3 8 8 16 5
Fig. 14 The grasping success rate, per object, for the database cre-ated from the crowdsourcing user study’s grasp demonstrations, theresearcher’s grasp demonstrations, and the PR2’s standard grasp plan-ning algorithm
grasp planning algorithm (Hsiao et al. 2010) instead of ourdatabase. The results are shown in Fig. 14.
In general, the PR2 grasped the objects with a successrate of at least 80% using grasps learned from both the userstudy data and the researcher demonstrated data. Of note isthe black cup, which failed under all three grasping systems.This occurred because theKinect could not properly segmentthe object due to its reflectiveness and the lighting conditionsof the experiment. Another outlier is the truck, which wasrarely grasped successfully during the user study, and thealgorithm could not construct a complete object model fromthe crowdsourced data. The final outlier of the user studydata is the dog bone, which was grasped much less success-fully using the user study data. This was likely due to thefact that the user study data produced a comparatively lownumber of high-probability grasps for this object, as shownin Fig. 15. We suspect that with more crowdsourced data, thebone would be grasped as effectively with the user study dataas with the researcher demonstrated data.
Comparing the demonstrated grasps to the grasps gener-ated from the PR2’s planner, we can see some interestingresults. For many of the objects, the methods have little dif-ference in success rate, and no method clearly outperformsthe others. In a few specific cases, however, the learned graspsoutperform the geometrically planned grasps. The first caseis the basket, which has many potential grasp areas due to its
Fig. 15 A comparison of the ratio of high-probability(graspProbabili t y > 0.5) grasps to total grasps for the userstudy data and the researcher demonstrated data data
subdivided sections, as well as the handle on top. The geo-metric planner had difficulty determining which grasp wouldbemost effective, and often selected grasps that were blockedby the handle or the inner edges of the subdivided sections.The demonstrated grasps, however, often picked up the objectby the handle on top, since that is where a humanwould natu-rally grasp the object. This grasp was more successful whenexecuted by the robot, since the handle is in an open areanot blocked by other parts of the object. The second case isthe duck, which was simply too small for the PR2’s plan-ner to consistently analyze. The learned grasps worked well,though, since they required no planning. The final case is thetruck, where the geometric planner occasionally failed due tograsping the moving wheels of the object, which caused thetruck to slip from the gripper. Thanks to human knowledgeof the truck’s moving wheels, the demonstrated grasps didnot have this problem.
Figure 15 shows the difference in quality between thecrowdsourced user study grasps and the researcher demon-strated grasps. The ratio of high-probability grasps to totalgrasps was significantly higher for the researcher demon-strated data than for the user study data. The graph shows thatmany more grasps were removed from the database by thegrasp learning system for the user study data. The non-expertusers could demonstrate high-quality grasps, but it oftentook more attempts than with the researchers’ more consis-tent high-quality grasp demonstrations. This is not really anissue, however, as crowdsourcing is designed to collect largeamounts of data, and we designed the grasp learning systemto sort through the inconsistent data that crowdsourcing tendsto produce. Also of note is that the researcher demonstratedgrasps did not always have a success rate of 1.0. This likelyoccurred due to sensor error, and reinforces the need for the
123

190 Auton Robot (2016) 40:175–192
Fig. 16 Example grasps calculated by a geometric grasp planner (top) and demonstrated by an expert user (bottom)
grasp learning process, regardless of whether the grasps weredemonstrated by expert or non-expert users.
7.3.2 Advantages of demonstrated grasps
Following the results of comparing the demonstrated graspsto the PR2’s geometrically calculated grasps, the researchersdemonstrated additional grasps for a supplemental objectset. Each object in this set represents a special case of con-straints for grasping,which the geometric plannerwas unableto detect. Figure 16 shows each supplemental object withboth an example calculated grasp and an example demon-strated grasp. The first object, the water bottle, is difficultfor the PR2 to grasp because most of the bottle’s surfaceis too slippery for the gripper to hold securely. There is agraspable region at the neck of the bottle, but the geometricplanner would often grasp below it on the smoother surface.Next is the coffee creamer, which presents a challenge tothe PR2 since its diameter is about the same distance as thewidth of the robot’s open gripper, causing small miscalcu-lations to result in missed grasps. The grasp planner favorsgrasps from above, but the object has a much more con-sistent grasp from the side. The hammer represents objectswith extreme weight distributions, which slip from the grip-per when the object is not grasped near its balance point.The monkey has a removable part, its hat, and again due tothe geometric planner’s preference for grasps from above,the PR2’s planner picks up only the hat instead of the mon-key. Finally, the vase represents objects containing fragileparts. The PR2’s grasp planner always attempts to grasp theflower, which will both ruin the flower and fail to pick up thevase.
In each case, the learned grasps are superior to the geo-metrically calculated grasps for overall grasping success rate.
Fig. 17 A comparison of grasp rates for the supplemental object set
Figure 17 shows a comparison for each object. For the waterbottle and coffee creamer, switching to a grasp from theside at an appropriate height improved the grasp successrate to 100%; accounting for the balance point significantlyimproved the success rate for the hammer, which otherwisewas grasped at random positions along the handle; for themonkey and the vase, the demonstrated grasps resulted insuccesses where the geometrically planned grasps could notsucceed at all.
8 Conclusion
Our work seeks to overcome the drawbacks of existing tech-niques for generating 3D object recognition data sets formobilemanipulation.Wepresented a novel approach for con-structing an object recognition database from crowdsourced
123

Auton Robot (2016) 40:175–192 191
information, contributing a framework for collecting datathrough the web, preliminary results of a study on the effectsof incentives on online user behavior, a novel computationalmethod for construction of 3D object models through itera-tive point cloud registration, and a system for evaluating theeffectiveness of demonstrated grasps.
We validated the object recognition approach with datacollected from a remote user study experiment, as well aswith a larger supplemental dataset. The developed objectrecognition system was successful, correctly classifyingobjects at a rate of 88.7% for the experimental data and83.93% for the larger supplemental dataset.
We showed that by using crowdsourcing, we can leveragehuman knowledge to create databases for autonomous objectmanipulation. We have shown that, with a sufficient amountof data collected and an appropriate system for determin-ing which data is useful, non-expert users can demonstrategrasps that a robot can use to successfully manipulate house-hold objects. Furthermore, this data can be collected usinga minimal amount of setup, requiring nothing more than therobot and the object set. Due to the varied quality of crowd-sourced data, this system requiresmore data collection than ifexpert users were demonstrating the grasps. The advantagesof crowdsourcing mitigate this extra data collection, though,as it still requires less time and effort per individual user thanif a researcher took the time to demonstrate all of the graspson their own.
The presented techniques form a strong foundation forfuture research into mobile manipulation in real world envi-ronments. The user study, object model construction, andgrasp learning systems presented here are but one of manypossible ways of using the new techniques that web robot-ics has to offer. The object recognition and grasping databasebuilt by this system is a strong example of the power of apply-ing crowdsourcing to robotics.
Acknowledgments I would like to thank Professor Odest ChadwickeJenkins of Brown University for allowing the use of the PR2 robotthroughout the user study and validation experiments. Furthermore,I would like to thank fellow graduate students Russell Toris for thedevelopment of the RMS, andMorteza Behrooz for his help in conduct-ing the user study. This work was supported by the National ScienceFoundation Award Number 1149876, CAREER: Towards Robots thatLearn from Everyday People, PI Sonia Chernova, and Office of NavalResearch Grant N00014-08-1-0910 PECASE: Tracking Human Move-mentUsingModels of PhysicalDynamics andNeurobiomechanicswithProbabilistic Inference, PI Odest Chadwicke Jenkins.
References
Alexander, B., Hsiao, K., Jenkins, C., Suay, B., & Toris, R. (2012).Robot web tools [ROS topics]. IEEE Robotics Automation Maga-zine, 19(4), 20–23.
Azevedo, T. C., Tavares, Ja M R, & Vaz, M. A. (2009). 3D objectreconstruction from uncalibrated images using an off-the-shelf
camera. In Ja M R Tavares & R. N. Jorge (Eds.), Advances incomputational vision and medical image processing, volume 13of computational methods in applied sciences (pp. 117–136). TheNetherlands: Springer.
Baier, T., & Zhang, J. (2006). Reusability-based semantics for graspevaluation in context of service robotics. In IEEE InternationalConference on Robotics and Biomimetics, 2006. ROBIO ’06, pp.703–708.
Breazeal, C., DePalma, N., Orkin, J., Chernova, S., & Jung, M. (2013).Crowdsourcing human-robot interaction: New methods and sys-tem evaluation in a public environment. Journal of Human-RobotInteraction, 2(1), 82–111.
Brown, M., & Lowe, D. (2005). Unsupervised 3D object recognitionand reconstruction in unordered datasets. In Fifth InternationalConference on 3-D Digital Imaging and Modeling, 2005. 3DIM2005, pp. 56–63.
Chatzilari, E., Nikolopoulos, S., Papadopoulos, S., Zigkolis, C., &Kompatsiaris, Y. (2011). Semi-supervised object recognition usingflickr images. In 9th International Workshop on Content-BasedMultimedia Indexing (CBMI), 2011, pp. 229–234.
Chernova, S., DePalma, N., Morant, E., & Breazeal, C. (2011). Crowd-sourcing human-robot interaction: Application from virtual tophysical worlds. In IEEE International Symposium on Robot andHuman Interactive Communication, Ro-Man ’11.
Chung, M., Forbes, M., Cakmak, M., & Rao, R. (2014). Acceleratingimitation learning through crowdsourcing. In IEEE InternationalConference on Robotics and Automation (ICRA), pp. 4777–4784.
Crick, C., Jay, G., Osentoski, S., & Jenkins, O. (2012). ROS and ros-bridge: Roboticists out of the loop. In th ACM/IEEE InternationalConference on Human-Robot Interaction (HRI), pp. 493–494.
Crick, C., Osentoski, S., Jay, G., & Jenkins, O. (2011). Human androbot perception in large-scale learning from demonstration. InACM/IEEE International Conference on Human-Robot Interac-tion (HRI 2011).
Detry, R., Kraft, D., Kroemer, O., Bodenhagen, L., Peters, J., Krüger,N., et al. (2011). Learning grasp affordance densities. Paladyn,2(1), 1–17.
Esteban, C. H., & Schmitt, F. (2004). Silhouette and stereo fusion for3D object modeling. Computer Vision and Image Understanding,96(3), 367–392. (Special issue on model-based and image-based3D scene representation for interactive visualization).
Garage, W. (2010). The household_objects SQL Database.Goldfeder, C., Ciocarlie, M., Dang, H., & Allen, P. K. (2009a). The
Columbia grasp database. In IEEE International Conference onRobotics and Automation, 2009. ICRA’09, pp. 1710–1716.
Goldfeder, C., Ciocarlie, M., Peretzman, J., Dang, H., & Allen,P. (2009b). Data-driven grasping with partial sensor data. InIEEE/RSJ International Conference on Intelligent Robots and Sys-tems, 2009, pp. 1278–1283.
Harris, C. (2011). You’re hired! An examination of crowdsourcingincentive models in human resource tasks. In WSDM Workshopon Crowdsourcing for Search and Data Mining (CSDM), pp. 15–18.
Hsiao, K., Chitta, S., Ciocarlie, M., & Jones, E. (2010). Contact-reactive grasping of objects with partial shape information. InIEEE/RSJ International Conference on Intelligent Robots and Sys-tems (IROS), 2010, pp. 1228–1235.
Jiang, Y., Moseson, S., & Saxena, A. (2011). Efficient grasping fromRGBD images: Learning using a new rectangle representation.In IEEE International Conference on Robotics and Automation(ICRA), 2011, pp. 3304–3311.
Kasper, A., Xue, Z., & Dillmann, R. (2012). The KIT object modelsdatabase: An object model database for object recognition, local-ization and manipulation in service robotics. The InternationalJournal of Robotics Research, 31(8), 927–934.
123

192 Auton Robot (2016) 40:175–192
Kehoe, B., Patil, S., Abbeel, P., & Goldberg, K. (2015). A survey ofresearch on cloud robotics and automation. IEEE Transactions onAutomation Science and Engineering, 12(2), 398–409.
Kraft, D., Pugeault, N., Baseski, E., Popovic, M., Kragic, D., Kalkan,S., et al. (2008). Birth of the object: Detection of objectness andextractionof object shape throughobject action complexes.SpecialIssue on Cognitive Humanoid Robots of the International Journalof Humanoid Robotics (IJHR), 5(2), 247–265.
Krainin, M., Curless, B., & Fox, D. (2011). Autonomous generationof complete 3d object models using next best view manipula-tion planning. In IEEE International Conference on Robotics andAutomation (ICRA), 2011, pp. 5031–5037.
Lai, K., Bo, L., Ren, X., & Fox, D. (2011). A large-scale hierarchi-cal multi-view rgb-d object dataset. In 2011 IEEE InternationalConference on Robotics and Automation (ICRA), pp. 1817–1824.
Makadia, A., Patterson, A., & Daniilidis, K. (2006). Fully automaticregistration of 3D point clouds. IEEE Computer Society Confer-ence on Computer Vision and Pattern Recognition, 1, 1297–1304.
Mitra, N. J., Gelfand, N., Pottmann, H., & Guibas, L. (2004). Registra-tion of point cloud data from a geometric optimization perspective.In Proceedings of the 2004 Eurographics/ACM SIGGRAPH Sym-posium on Geometry Processing, SGP ’04, pp. 22–31, New York,NY, USA. ACM.
Morales, A., Asfour, T., Azad, P., Knoop, S., & Dillmann, R. (2006).Integrated grasp planning and visual object localization for ahumanoid robot with five-fingered hands. In IEEE/RSJ Interna-tional Conference on Intelligent Robots and Systems, 2006, pp.5663–5668.
Pitzer, B., Osentoski, S., Jay, G., Crick, C., & Jenkins, O. (2012). PR2remote lab: An environment for remote development and exper-imentation. In 2012 IEEE International Conference on Roboticsand Automation (ICRA), pp. 3200–3205.
Quinlan, J. R. (1993). C4.5: Programs for machine learning. Burling-ton: Morgan Kaufmann.
Rusu, R., Blodow,N., &Beetz,M. (2009). Fast point feature histograms(FPFH) for 3D registration. In IEEE International Conference onRobotics and Automation, 2009. ICRA ’09, pp. 3212–3217.
Rusu, R., & Cousins, S. (2011). 3D is here: Point cloud library (PCL).In IEEE International Conference on Robotics and Automation(ICRA), 2011, pp. 1–4.
Saxena, A., Wong, L. L., & Ng, A. Y. (2008). Learning grasp strategieswith partial shape information. In AAAI, 8, 1491–1494.
Sehgal,A.,Cernea,D.,&Makaveeva,M. (2010).Real-time scale invari-ant 3D range point cloud registration. In A. Campilho&M. Kamel(Eds.), Image analysis and recognition, volume 6111 of LectureNotes in Computer Science, pp. 220–229. Springer: Berlin Heidel-berg.
Sorokin, A., Berenson, D., Srinivasa, S. S., & Hebert, M. (2010). Peo-ple helping robots helping people: Crowdsourcing for graspingnovel objects. In IEEE/RSJ International Conference on Intelli-gent Robots and Systems (IROS), 2010, pp. 2117–2122.
Stückler, J., Steffens, R., Holz, D., & Behnke, S. (2013). Efficient3D object perception and grasp planning for mobile manipula-tion in domestic environments.Robotics and Autonomous Systems,61(10), 1106–1115. Selected Papers from the 5th European Con-ference on Mobile Robots (ECMR 2011).
Tellex, S., Kollar, T., Dickerson, S., Walter, M., Banerjee, A., Teller, S.,& Roy, N. (2011). Understanding natural language commands forrobotic navigation and mobile manipulation. In Proceedings of theNational Conference on Artificial Intelligence (AAAI).
Toris, R., Kent, D., & Chernova, S. (2014). The robot management sys-tem: A framework for conducting human-robot interaction studiesthrough crowdsourcing. Journal of Human-Robot Interaction, 3,25–49.
Torralba, A., Fergus, R., & Freeman, W. T. (2008). 80 million tinyimages: A large data set for nonparametric object and scenerecognition. IEEE Transactions on Pattern Analysis and MachineIntelligence, 30(11), 1958–1970.
Xue, Z., Kasper, A., Zoellner, J., & Dillmann, R. (2009). An automaticgrasp planning system for service robots. In International Confer-ence on Advanced Robotics, 2009. ICAR 2009, pp. 1–6.
David Kent received a B.S. inRobotics Engineering and Com-puter Science from WorcesterPolytechnic Institute in 2012,and is currently pursuing aM.S. in Robotics Engineering atWorcester Polytechnic Institute.His research interests includerobot learning from demonstra-tion, crowdsourcing, and robotgrasping.
Morteza Behrooz received hisB.S. degree in Computer Engi-neering from University ofTehran in 2012. He receivedhis M.S. degree in ComputerScience from Worcester Poly-technic Institute in 2014 and isnow a PhD student in Com-puter Science at the Univer-sity of California, Santa Cruz.His research interests includeHuman-Robot interaction, col-laboration and social games.
Sonia Chernova received aPh.D. from Carnegie MellonUniversity in 2009 working withManuela Veloso. Before join-ing Worcester Polytechnic Insti-tute, she spent one year work-ing with Cynthia Breazeal asa postdoc at the MIT MediaLab. She is the director of theRobot Autonomy and Interac-tive Learning (RAIL) lab. Herresearch interests span interac-tive robot learning, human-robotinteraction, and human computa-tion.
123

















