
Constraint-based Register Allocation and Instruction ... · global register allocation with all...
22
Constraint-based Register Allocation and Instruction Scheduling Roberto Casta˜ neda Lozano – SICS Mats Carlsson – SICS Frej Drejhammar – SICS Christian Schulte – KTH, SICS CP 2012
Transcript of Constraint-based Register Allocation and Instruction ... · global register allocation with all...

Constraint-based Register Allocation and
Instruction Scheduling
Roberto Castaneda Lozano – SICS
Mats Carlsson – SICS
Frej Drejhammar – SICS
Christian Schulte – KTH, SICS
CP 2012

Outline
1 Introduction
2 Program Representation
3 Constraint Model
4 Decomposition
5 Evaluation
6 Conclusion
2 / 22

Problems in Traditional Register Allocation
Traditional compiler:
front-endinstructionselection
instructionscheduling
registerallocation
sourceprogram
assemblyprogram
Problems:
Interdependencies: staging is suboptimal
NP-hardness: sub-optimal, complex heuristic algorithms
“Lord knows how GCC does register allocationright now”. (Anonymous, GCC Wiki)
3 / 22

Can We Do Better?
1 Potentially optimal code: integration, optimization
2 Simplicity, flexibility: separation of modeling and solving
. . . this sounds like something for CP
previous CP approaches:
scheduling only (Malik et al., 2008)
integrated code generation
scheduling, assignment (Kuchcinski, 2003)
selection, scheduling, allocation (Leupers et al., 1997)
→ limitation: local (cannot handle control flow)
4 / 22

Our Approach
Constraint model that unifies
global register allocation with all essential aspects
register assignment, spilling, coalescing, . . .
instruction scheduling
Based on a novel program representation
Robust code generator based on a problem decomposition
Current code quality: on par with LLVM (state of the art)
5 / 22

1 Introduction
2 Program Representation
3 Constraint Model
4 Decomposition
5 Evaluation
6 Conclusion
6 / 22

Liveness and Interference
A temp is live while it might still be used:
t0 ← add . . .
......
jr t0
Two temps interfere if they are live simultaneously
non-interfering temps can share registers
7 / 22

Linear Static Single Assignment Form (LSSA)t0 is global: live in multiple blocks
How to model interference of global temps?
LSSA: decompose global temps into multiple local temps
t1t1 ← add . . .
t2... t3
...
t4jr t4
t1 ≡ t2 t1 ≡ t3
t2 ≡ t4 t3 ≡ t4
Invariant: all temps are local → simple interference model8 / 22

1 Introduction
2 Program Representation
3 Constraint Model
4 Decomposition
5 Evaluation
6 Conclusion
9 / 22

Register Assignment
to which register do we assign each temporary?
10 / 22

Register Assignment as Rectangle Packing
Register Assignment Rectangle Packing
temp live ranges rectangles
temp size rectangle width
interfering temps cannot share registers rectangles cannot overlap
→ based on (Pereira et al., 2008)cycle
0
1
2
3
v0 v1 a0 a1 . . ....
... . . .
t0
t1
t2
t3
11 / 22

Spilling and CoalescingSpilling: saving a temp in memory
Requires copying temps from/to memory
Introduce optional copy instructions:
t1 ← {null, sw, move} t0
which operation implements each copy?
if a copy is inactive (null), its temps are coalesced
cycle
0
1
2
3
v0 v1 a0 a1 . . . ra m1 m2 . . .
...
processor space memory space
. . .
. . .
...
... . . .
t0
t1
null
12 / 22
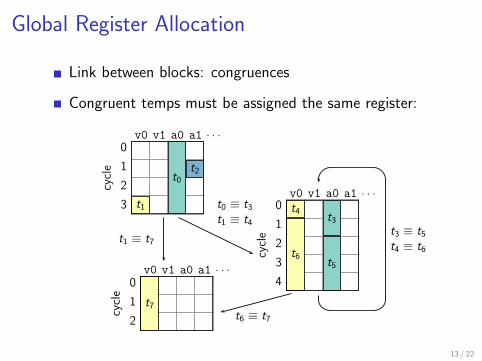
Global Register Allocation
Link between blocks: congruences
Congruent temps must be assigned the same register:
v0 v1 a0 a1 . . .
cycle
0
1
2
3
t0
t1
t2
v0 v1 a0 a1 . . .
cycle
0
1
2
3
4
t3t4
t5t6
v0 v1 a0 a1 . . .
cycle
0
1
2
t7
t0 ≡ t3t1 ≡ t4
t1 ≡ t7
t6 ≡ t7
t3 ≡ t5t4 ≡ t6
13 / 22

Instruction Scheduling
in which cycle is each instruction issued?
Connection to register allocation: live ranges
Classic scheduling model with:
precedencesresource constraints
14 / 22

1 Introduction
2 Program Representation
3 Constraint Model
4 Decomposition
5 Evaluation
6 Conclusion
15 / 22

LSSA Decomposition
Only link between blocks: congruences
instruction cycles?copy operations?register of t0?register of t1?register of t2? instruction cycles?
copy operations?register of t3?register of t4?register of t5?register of t6?
instruction cycles?copy operations?register of t7?
t0 ≡ t3t1 ≡ t4
t1 ≡ t7
t6 ≡ t7
t3 ≡ t5t4 ≡ t6
16 / 22

1 Introduction
2 Program Representation
3 Constraint Model
4 Decomposition
5 Evaluation
6 Conclusion
17 / 22

Experiment Setup
86 functions from bzip2 (SPECint 2006 suite)
Selected MIPS32 instructions with LLVM 3.0
Implementation with Gecode 3.7.3
Sequential search on standard desktop machine
18 / 22
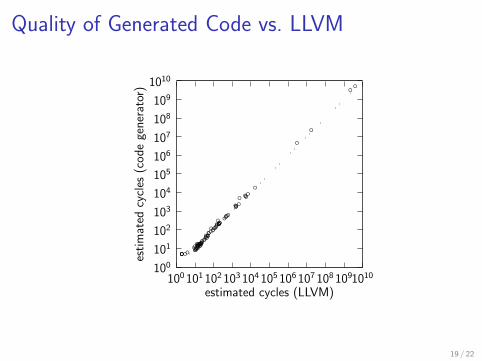
Quality of Generated Code vs. LLVM
1001011021031041051061071081091010
1001011021031041051061071081091010
estimated
cycles
(codegenerator)
estimated cycles (LLVM)
b
b
b
b
b
b
b
bb
bb
b
b
b
b
bb
bb
b
bb
b
b
b
b
bb
b
bb
b
b
b
b
b
b
b
bb
b
b
b
b
bb
bb
b
b
b
bb
b
bb
b
bbb
b
b
bb
b
b
b bbb
b
bb
b
bbbbbbb
bb
b
bb
19 / 22
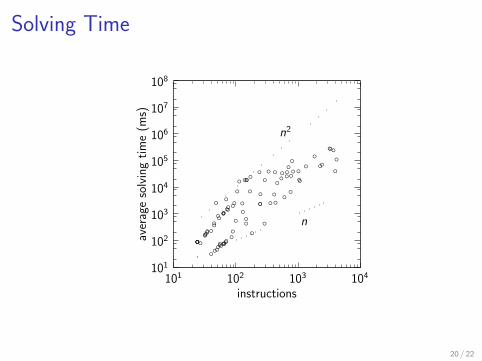
Solving Time
101
102
103
104
105
106
107
108
101 102 103 104
averagesolvingtime(m
s)
instructions
n2
n
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
bb
b b
b
b
b
b
b
b
b
bb
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
bb
b
b
b
b
b
b
b
bb
bb
b
b
b
bb
b
b
b
b
b
b
b
b
b
bb
b
b
b
b
bb
20 / 22

1 Introduction
2 Program Representation
3 Constraint Model
4 Decomposition
5 Evaluation
6 Conclusion
21 / 22

Conclusion
1 Model that unifies:
all essential aspects of register allocationinstruction scheduling
→ state-of-the-art code quality
2 Problem decomposition
→ robust generator for thousands of instructions
Key: tailored problem representation (LSSA form)
Lots of future work:
search heuristics, implied constraints . . .integration with instruction selectionevaluate for other processors and benchmarks
22 / 22


















