
Con$nued(from(last$me:(( Race(Detec$on(in(Cilk(Computaons(
44
Con$nued from last $me: Race Detec$on in Cilk Computa$ons
Transcript of Con$nued(from(last$me:(( Race(Detec$on(in(Cilk(Computaons(

Con$nued from last $me: Race Detec$on in Cilk Computa$ons

Canonical Series-‐Parallel (SP) Parse Tree S
e1
S
P
F1 S
e2 P
F2 e3
S
e4
S
P
F4 S
e5 P
F5 e6
S
e7
S
P
F7 S
e8 P
F8 e9
e10 F: e1; spawn F1; e2; spawn F2; e3; sync; e4; spawn F4; e5; spawn F5; e6; sync; e7; spawn F4; e8; spawn F8; e9; sync; e10;
Spine

Lemma 1 [LCA in SP tree]: The least common ancestor (LCA) of two strands determines whether the strands are logically in series or in parallel: • if e ≺ e’ if LCA(e, e’) is an S node and e is to the leQ of e’
(e precedes e’) • if e ‖ e’ if LCA(e, e’) is an P node.
Canonical Series-‐Parallel (SP) Parse Tree

Lemma 1 [LCA in SP tree]: The LCA of two strands determines whether the strands are logically in series or in parallel: • if e ‖ e’ if and only if LCA(e, e’) is an P node.
(The other case, where e ≺ e’ is just a Corollary of this Lemma.)
Canonical Series-‐Parallel (SP) Parse Tree
Case 1 (⟹): Assume for the purpose of contradic$on, e ‖ e’, but their LCA is an S node.
G1 G2
e1
e2
: Sink of G1 and source of G2
Then there must be a path from e1 to e2. Contradic$on!
Since the LCA is an S node, the dag G1 containing e1 must be connected in series with the dag G2 containing e2 :
Canonical Series-‐Parallel (SP) Parse Tree
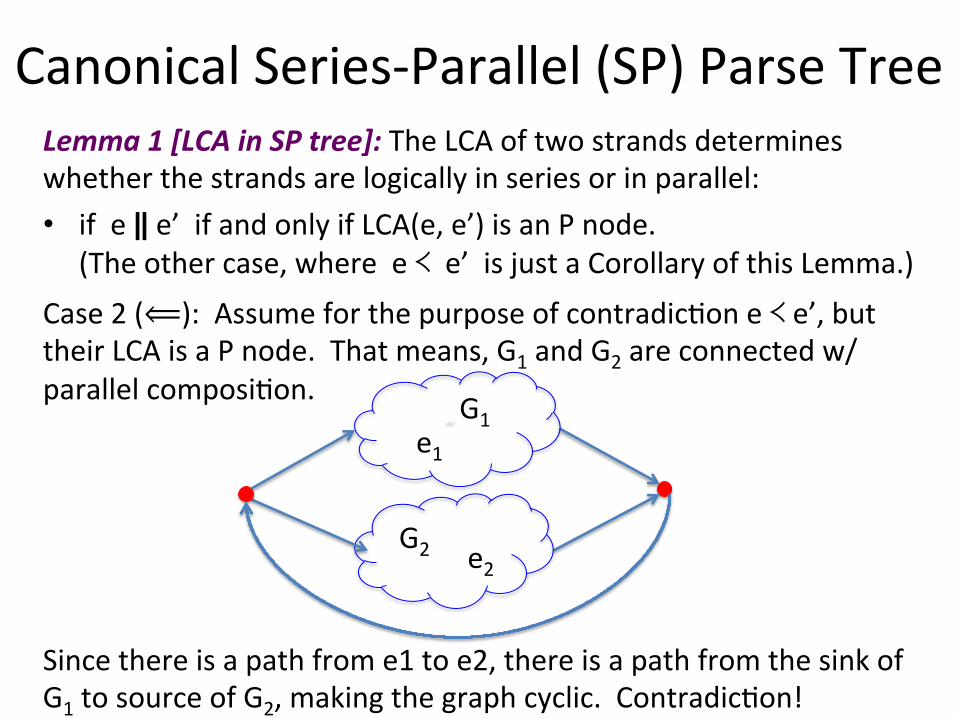
Case 2 (⟸): Assume for the purpose of contradic$on e ≺ e’, but their LCA is a P node. That means, G1 and G2 are connected w/ parallel composi$on. ˝
G1 e1
G2 e2
Since there is a path from e1 to e2, there is a path from the sink of G1 to source of G2, making the graph cyclic. Contradic$on!
Lemma 1 [LCA in SP tree]: The LCA of two strands determines whether the strands are logically in series or in parallel: • if e ‖ e’ if and only if LCA(e, e’) is an P node.
(The other case, where e ≺ e’ is just a Corollary of this Lemma.)

Lemma 1 [LCA in SP tree]: The least common ancestor (LCA) of two strands determines whether the strands are logically in series or in parallel: • if e ≺ e’ if LCA(e, e’) is an S node and e is to the leQ of e’
(e precedes e’) • if e ‖ e’ if LCA(e, e’) is an P node.
Canonical Series-‐Parallel (SP) Parse Tree

Overview of Nondeterminator • A serial tool -‐-‐-‐ it executes a Cilk computa$on serially, but analyzes the parallel constructs for a given input.
• The program is compiled so that every load and store in the user program is instrumented.
• As the program executes, the Nondeterminator maintains: • a shadow space that keeps track of the memory accesses
seen by the execu$on thus far; • an SP-‐bag data structure that keeps track of the series-‐
parallel rela$onship among strands (so implicitly it’s keep track of the shape of the SP parse tree).
• Race is reported when two logically parallel strands access the same memory loca$on in a conflic$ng way.
• Guarantee: reports a race if and only if the computa$on (program + input) contains a race.

The SP-‐Bags Data Structure For each ac$ve procedure on the call stack, the Nondeterminator maintains an S bag and a P bag: • S-‐Bag SF : Contains IDs of F’s completed descendants (including
F itself) that logically precede the currently execu$ng strand. • P-‐Bag PF : Contains IDs of F’s completed descendants that
operate logically in parallel with the currently execu$ng strand.
0 1 2 3 4 5 6 7 8 9 10 11 12: The slowdown of eight benchmark Cilk programs checked with
the Nondeterminator. The slowdown, shown as a dark bar, is the ratio ofthe Nondeterminator runtime to the original optimized runtime ( )of the benchmark. For comparison, the slowdown of an ordinary debuggingversion ( ) of each benchmark is shown as a light bar.
TimeAlgorithm Thread Per Space
creation & accesstermination
English-Hebrewlabeling [16] O p O pt O vt min np vtp
Taskrecycling [7] O t O t O vt t2Offset-spanlabeling [12] O p O p O v min np vpSP-bagsalgorithm O α v v O α v v O v
p maximum depth of nested parallelismt maximum number of logical concurrent threadsv number of shared locations being monitoredn number of threads in an execution
: Comparison of determinacy-racedetection algorithms. The func-tion α is the very slowly growing inverse of Ackermann’s function intro-duced by Tarjan in his analysis of an efficient disjoint-set data structure. Forall conceivably practical inputs, the value of this function is at most 4. Thetime for the SP-bags algorithm is an amortized bound.
we prove that the running time of the algorithm isO T α v v whenrun on a Cilk program that takes time T on one processor and uses vshared-memory locations, where α is Tarjan’s functional inverse ofAckermann’s function [21].The SP-bags algorithm is a serial algorithm. It uses the fact that
any Cilk program can be executed on one processor in a depth-first(C-like) fashion and conforms to the semantics of the C programthat results when all and keywords are removed. Asthe SP-bags algorithm executes, it employs several data structuresto determine which procedure instances have the potential to exe-cute “in parallel” with each other, and is thereby able to check fordeterminacy races.The SP-bags algorithm maintains two shadow spaces of shared
memory called writer and reader. For each location of sharedmemory, each shadow space has a corresponding location. Everyspawned procedure1 is given a unique ID at runtime. For each loca-tion l in shared memory, the ID of the procedure that wrote the lo-cation is stored in location l of the writer shadow space. Similarly,location l of the reader shadow space stores the ID of a procedurewhich previously read location l, although in this case, the ID is notnecessarily that of the most recent reader. The SP-bags algorithmupdates the shadow spaces as it executes.
1Technically, by “procedure” we mean “procedure instance,” that is, the runtimestate of the procedure.
F1
F4 F6
F6 F9
F14
F8
F13SF9 PF9
PF13SF13
F2 F3F1 F5
F7
F12
SF1 PF1
SF6 PF6F11
F9F10
F13
: A snapshot of the SP-bags data structures during the execu-tion of a Cilk program. The ovals in the figure represent procedures thatare currently on the runtime stack: F1 spawns F6, which spawns F9, whichspawns F13. Each procedure contains an S-bag and a P-bag. Each descen-dant of a completed child of a procedure F belongs either to F’s S-bag or toF’s P-bag. For example, F2, F3, F4, and F5 are descendants of F1 that com-plete before F1 spawns F6, and so these procedures belong to either F1’s S-bag or its P-bag. In addition, every procedure F belongs to its own S-bag.
The SP-bags algorithm uses the fast disjoint-set data structure [6,Chapter 22] analyzed by Tarjan [21]. The data structure maintains adynamic collection Σ of disjoint sets and provides three elementaryoperations:
x : Σ Σ x .
X Y : Σ Σ X Y X Y . The sets X andY are de-stroyed.
x : Returns the set X Σ such that x X .
Tarjan shows that any m of these operations on n sets take a total ofO mα m n time.During the execution of the SP-bags algorithm, two “bags” of
procedure ID’s are maintained for every Cilk procedure on the callstack, as illustrated in Figure 7. These bags have the following con-tents:
The S-bag SF of a procedure F contains the ID’s of those de-scendants of F’s completed children that logically “precede”the currently executing thread, as well as the ID for F itself.The P-bag PF of a procedure F contains the ID’s of those de-scendants of F’s completed children that operate logically “inparallel” with the currently executing thread.
The S-bags and P-bags are represented as sets using a disjoint-setdata structure.The SP-bags algorithm itself is given in Figure 8. As the Cilk pro-
gram executes in a serial, depth-first fashion, the SP-bags algorithmperforms additional operations whenever one of the five followingactions occurs: , , , , and . The cor-rectness of the SP-bags algorithm is presented in Section 4, but wegive an informal explanation of its operation here.As the SP-bags algorithm executes, it updates the contents of
the S-bags and P-bags whenever one of the actions , ,occurs. Whenever a procedureF is spawned, SF is initially
made to contain F, because F’s subsequent instructions are in se-ries with its earlier instructions. Whenever a subprocedure F re-turns to its parent F, the contents of SF are emptied into PF , sincethe procedures in SF can execute in parallel with any subproceduresthat F might spawn in the future before performing a . Whena occurs, PF is emptied into its SF , since all of F’s previously

The SP-‐Bags Data Structure For each ac$ve procedure on the call stack, the Nondeterminator maintains an S bag and a P bag: • S-‐Bag SF : Contains IDs of F’s completed descendants (including
F itself) that logically precede the currently execu$ng strand. • P-‐Bag PF : Contains IDs of F’s completed descendants that
operate logically in parallel with the currently execu$ng strand.
F1
F2
F3
........
F4
F5
F6
........
....
....
sync block Fi= parse tree of any spawned procedure
e1
e2
When e1 executes, SF = {F1, F2, F3}. When e2 executes, SF = {F1, F2, F3} and PF = {F4, F5}.

The SP-‐Bags Data Structure The Nondeterminator uses a disjoint-‐set data structure to maintain the S and P bags of procedures on the call stack.
Defini?on [Disjoint-‐Set Data Structure (Union-‐Find)]: Union-‐Find maintains a collec$on ∑ of disjoint sets. For two sets X and Y, X & Y ∊ ∑ ⟹ X ∩ Y = ∅ . For each set X ∊ ∑ typically has a designated "leader" element x ∊ X which is used to "name" the set. The data structure maintains the collec$on ∑ and answers the following queries:
• Make-‐set(e): ∑ ⟵ ∑ ∪ { {e} } Adds a new set {e} into the collec$on ∑ .
• Union(X, Y): ∑ ⟵ ∑ -‐ {X,Y} ∪ {X U Y} Removes individual sets X and Y and replaces them with the union of X and Y.
• Find-‐set(e): Returns X ∊ ∑ such that e ∊ X . Note that sets in ∑ is named by their leaders, so this returns the leader represen$ng the set.

The SP-‐Bags Data Structure The Nondeterminator uses a disjoint-‐set data structure to maintain the S and P bags of procedures on the call stack.
Defini?on [Disjoint-‐Set Data Structure (Union-‐Find)]: Union-‐Find maintains a collec$on ∑ of disjoint sets. For two sets X and Y, X & Y ∊ ∑ ⟹ X ∩ Y = ∅ . For each set X ∊ ∑ typically has a designated "leader" element x ∊ X which is used to "name" the set. The data structure maintains the collec$on ∑ and answers the following queries:
• Make-‐set(e) • Union(X, Y) • Find-‐set(e)
Theorem [Opera?ons on Disjoint-‐set Data structure] (Tarjan 1975): Any sequence of m opera$ons on n sets can be performed in O(m A(m, n)), where A is the inverse Ackermann's func$on (a really really slow growing func$on).

The SP-‐Bags Algorithm The SP-‐Bags algorithm is the algorithm used by the Nondeterminator and it performs two types of opera$ons.
• spawn procedure F: SF ⟵ Make-‐set(F); (F is the leader) PF ⟵ ∅
• sync in procedure F: SF ⟵ Union(SF , PF); PF ⟵ ∅
• return from F' to F (F' is spawned): PF ⟵ Union(PF , SF'); (Note that PF' must be empty at this point.)
The first type updates the S and P bags for all procedures on the call stack, which is triggered during the DFS traversal of the SP parse tree.

The SP-‐Bags Algorithm The SP-‐Bags algorithm is the algorithm used by the Nondeterminator and it performs two types of opear$ons.
Shadow memory: • writer[v]: the ID of the last
procedure that wrote to v. • reader[v]: the ID of the a
procedure that read v (not necessarily the last one).
The second type uses the SP-‐bags data structure to detect determinacy races when the user program accesses a memory loca$on.
• write loca@on v by procedure F: if (Find-‐set(reader[v]) is a P-‐bag Or Find-‐set(writer[v]) is a P-‐bag) then report race; writer[v] ⟵ F;
• read loca@on v by procedure F: if (Find-‐set(writer[v]) is a P-‐bag then report race; if (Find-‐set(reader[v]) is an S-‐bag then reader[v] ⟵ F; (Replace reader only when it's in an S-‐bag)

Jus$fica$on of the SP-‐Bags Algorithm The SP-‐Bags algorithm is the algorithm used by the Nondeterminator and it performs two types of opear$ons.
• spawn procedure F: SF ⟵ Make-‐set(F); (F is the leader) PF ⟵ ∅
Recall: • S-‐Bag SF : Contains IDs of F’s completed descendants (including F itself)
that logically precede the currently execu$ng strand. • P-‐Bag PF : Contains IDs of F’s completed descendants that operate
logically in parallel with the currently execu$ng strand.
This opera$on is valid since the S-‐bag of F by defini$on contains itself, and F has no valid child yet.

Jus$fica$on of the SP-‐Bags Algorithm The SP-‐Bags algorithm is the algorithm used by the Nondeterminator and it performs two types of opear$ons.
• sync in procedure F: SF ⟵ Union(SF , PF); PF ⟵ ∅
Recall: • S-‐Bag SF : Contains IDs of F’s completed descendants (including F itself)
that logically precede the currently execu$ng strand. • P-‐Bag PF : Contains IDs of F’s completed descendants that operate
logically in parallel with the currently execu$ng strand.
AQer a sync, we switch to a strand e right aQer sync from some strand e' right before sync. Originally PF contains IDs of F’s completed descendants that operate logically in parallel with e'. These procedures now must operate in series with e (and anything else that F will spawn). Thus, it's valid to move the IDs in PF into SF.

Jus$fica$on of the SP-‐Bags Algorithm The SP-‐Bags algorithm is the algorithm used by the Nondeterminator and it performs two types of opear$ons.
• return from F' to F (F' is spawned): PF ⟵ Union(PF , SF'); (Note that PF' must be empty at this point.)
Before a func$on F' returns, PF' is empty, since there is always an implicit sync. Also, SF' contains all the logical descendants of F', which are also logical descendants of F, and can now execute in parallel with any procedures that F might spawn in the future (before the next sync).
Recall: • S-‐Bag SF : Contains IDs of F’s completed descendants (including F itself)
that logically precede the currently execu$ng strand. • P-‐Bag PF : Contains IDs of F’s completed descendants that operate
logically in parallel with the currently execu$ng strand.
Q: What if F' is called but not spawned?

Jus$fica$on of the SP-‐Bags Algorithm To understand the second type of opera$ons, we need some lemmas first.
Recall Lemma 1 [LCA in SP tree]: • if e ‖ e’ if and only if LCA(e, e’) is an P node.
Lemma 2: Let strands e1, e2, and e3 execute serially in order. If e1 ≺ e2 and e1 ‖ e3, then e2 ‖ e3.
Proof: Suppose for the sake of contradic$on that e2 ≺ e3 . Then, by transi$vity, we'd have e1 ≺ e3 . Contradic$on.
Note that the parallel rela@on ‖ , unlike precedes ≺ , is not transi@ve.
P
S
e1 e3
e2 In this tree, e1 ‖ e3 and e1 ‖ e3 but e1 ‖ e3 .

Jus$fica$on of the SP-‐Bags Algorithm To understand the second type of opera$ons, we need some lemmas first.
Lemma 3 [Pseudotransi?vity of ‖] : Let strands e1, e2, and e3 execute serially in order. If e1 ‖ e2 and e2 ‖ e3, then e1 ‖ e3.
Proof: Since we do a depth-‐first traversal of the tree, the only possible op$ons for the tree that have them in the right serial order are:
a1
a2
e1 e2
e3
In both cases, we know that both LCA(e1, e2) and LCA(e2, e3) are P nodes. So the LCA(e1, e3), which is a1 , must also be a P node.
a1
e1
e2 e3
a2
Recall Lemma 1 [LCA in SP tree]: • if e ‖ e’ if and only if LCA(e, e’) is an P node.

Jus$fica$on of the SP-‐Bags Algorithm Define h(a) to be the procedure that immediately enclose strand a.
Lemma 4 [SP-‐Bags maintenance] : Let e1 be executed before e2, and let a = LCA(e1, e2) in the SP parse tree. • if e1 ≺ e2 ⟹ h(e1) is in an S-‐bag(h(a)) when e2 executes. • if e1 ‖ e2 ⟹ h(e1) is in a P-‐bag(h(a)) when e2 executes.
Proof sketch: Case 1: Since a is an S-‐node, a must belongs to either the spine or within a sync block. S
e
S
P
F1 S
e P
F2 e
a
e
S
P
F4 S
e1 P
F5 e
S
e2
S
P
F7 S
e P
F8 e
e If a belongs to the spine, then e1 belongs to a's leQ subtree and e2 to a's right subtree. Either h(e1) = h(a) or h(e1) is a descendant of h(a). If h(e1) is h(a), h(e1) is already in h(a)'s S bag.

Jus$fica$on of the SP-‐Bags Algorithm Define h(a) to be the procedure that immediately enclose strand a.
Lemma 4 [SP-‐Bags maintenance] : Let e1 be executed before e2, and let a = LCA(e1, e2) in the SP parse tree. • if e1 ≺ e2 ⟹ h(e1) is in an S-‐bag(h(a)) when e2 executes. • if e1 ‖ e2 ⟹ h(e1) is in a P-‐bag(h(a)) when e2 executes.
Proof sketch: Case 1: Since a is an S-‐node, a must belongs to either the spine or within a sync block. S
e
S
P
F1 S
e P
F2 e
a
e
S
P
F4 S
e P
F5 e
S
e2
S
P
F7 S
e P
F8 e
e If h(e1) is not h(a), h(e1) moves up into some bags in the call stack when its ancestor returns. Once the sync corresponds to a's leQ subtree executes, h(e1) moves into h(a)'s S bag (and stays there).

Jus$fica$on of the SP-‐Bags Algorithm Define h(a) to be the procedure that immediately enclose strand a.
Lemma 4 [SP-‐Bags maintenance] : Let e1 be executed before e2, and let a = LCA(e1, e2) in the SP parse tree. • if e1 ≺ e2 ⟹ h(e1) is in an S-‐bag(h(a)) when e2 executes. • if e1 ‖ e2 ⟹ h(e1) is in a P-‐bag(h(a)) when e2 executes.
Proof sketch: Case 2: Since a is an P-‐node.
S
e
S
P
F1 S
e P
F2 e
S
e
S
a
F4 S
e P
F5
S
e
S
P
F7 S
e P
F8 e
e
In this case, a must be within a sync block and e1 belongs to the leQ subtree and e2 to the right. At this point, the leQ child of a P node is always a spawned procedure F' that gets placed into h(a)'s P bag when the F' returns. Since no sync has occurred yet, F' must s$ll be in a P bag when e2 executes.
e2

Proof of the SP-‐Bags Race Detec$on Theorem [SP-‐Bags correctneess] : The SP-‐Bags algorithm reports a race in a Cilk computa$on if and only if a determinacy race exists.
Proof sketch: The (⟹) case is straight-‐forward. If the SP-‐Bags reports a race, that means it detected two strands logically in parallel that accesses the same memory loca$on in a conflic$ng way. Thus, if it reports a race, a determinacy race exists.

Proof of the SP-‐Bags Race Detec$on Theorem [SP-‐Bags correctneess] : The SP-‐Bags algorithm reports a race in a Cilk computa$on if and only if a determinacy race exists.
Proof sketch: The (⟸) case is trickier. We want to show that if a det. race exists, the SP-‐Bags algorithm reports it. Let e1 ‖ e2 and have a race on v. Assume e1 executes before e2 . If there are several races, choose e2 to be the race whose strand executes earliest in the serial order.
Case 1: Say e1 writes to v and e2 reads it. Suppose when e2 executes, writer[v] = h(e) for some e. If e = e1 then we are done, since we know that h(e1) is in a P bag of LCA(e1, e2) (by Lemma SP-‐bags maintenance). If e is not e1, then e must have been executed aQer e1 and before e2. Then either e1 ≺ e, then e ‖ e2 by Lemma 2* shown earlier. Or e1 ‖ e, then there is already a race between e1 and e, which contradicts our assump$on about e2 being the earliest race.
* Lemma 2: Let strands e1, e2, and e3 execute serially in order. If e1 ≺ e2 and e1 ‖ e3, then e2 ‖ e3.

Proof of the SP-‐Bags Race Detec$on Theorem [SP-‐Bags correctneess] : The SP-‐Bags algorithm reports a race in a Cilk computa$on if and only if a determinacy race exists.
Proof sketch: The (⟸) case is trickier. We want to show that if a det. race exists, the SP-‐Bags algorithm reports it. Let e1 ‖ e2 and have a race on v. Assume e1 executes before e2 . If there are several races, choose e2 to be the race whose strand executes earliest in the serial order.
Case 2: Say e1 writes to v and e2 writes it. This is similar to case 1.

Proof of the SP-‐Bags Race Detec$on Theorem [SP-‐Bags correctneess] : The SP-‐Bags algorithm reports a race in a Cilk computa$on iff a determinacy race exists.
Proof sketch: The (⟸) case is trickier. We want to show that if a det. race exists, the SP-‐Bags algorithm reports it. Let e1 ‖ e2 and have a race on v. Assume e1 executes before e2 . If there are several races, choose e2 to be the race whose strand executes earliest in the serial order.
Case 3: Say e1 reads to v and e2 writes it. Again, suppose reader[v] = e. If e = e1, then then we are done, since we know that h(e1) is in a P bag of LCA(e1, e2) (by Lemma SP-‐bags maintenance). So, we can assume e ≠ e1 . There are two possibili$es. Case 3.1: reader[v] was e1 at some point, but eventually got overwriwen by e (there can be some e' in reader[v] in between e1 and e). This can occur only if e1 ≺ e . Since e1 ≺ e and e1 ‖ e2 , e ‖ e2 , (again by Lemma 2*) so a race is reported.
* Lemma 2: Let strands e1, e2, and e3 execute serially in order. If e1 ≺ e2 and e1 ‖ e3, then e2 ‖ e3.

Proof of the SP-‐Bags Race Detec$on Theorem [SP-‐Bags correctneess] : The SP-‐Bags algorithm reports a race in a Cilk computa$on iff a determinacy race exists.
Proof sketch: The (⟸) case is trickier. We want to show that if a det. race exists, the SP-‐Bags algorithm reports it. Let e1 ‖ e2 and have a race on v. Assume e1 executes before e2 . If there are several races, choose e2 to be the race whose strand executes earliest in the serial order.
Case 3: Say e1 reads to v and e2 writes it. Again, suppose reader[v] = e. If e = e1, then then we are done, since we know that h(e1) is in a P bag of LCA(e1, e2) (by Lemma SP-‐bags maintenance). So, we can assume e ≠ e1 . There are two possibili$es. Case 3.2: reader[v] was never updated to be e1 . Let's assume when e1 executes, reader[v] = e'. Then it must be that e ‖ e1 or we'd have updated reader[v]. Then by Lemma Pseudotransivity of ‖ , e' ‖ e2 , and a race is reported. *Pseudotransi?vity of ‖ : e1, e2, and e3 execute serially in order. If e1 ‖ e2 and e2 ‖ e3 , then e1 ‖ e3.

Extensions for Parallel Race Detec$on

What We Need in a Det. Race Detector
• SP-‐Bags data structure: maintaining the series-‐parallel ordering of strands.
• Shadow space that contains: – The last writer to a loca$on v; and – The last serial reader to a loca$on v. (But we are totally dropping the parallel readers.)
Ques?on: Can we extend the SP-‐Bags algorithm to race detect a Cilk computa?on execu?ng in parallel?

Where Things Break
• The SP-‐Bags data structure maintenance is inherently serial: it keeps track of procedure IDs that are in series / parallel with respect to the "currently execu$ng strand."
• The shadow memory only keeps track of the last serial reader (that the execu$on encounters), which is insufficient.

On-‐the-‐Fly Maintenance of Series-‐Parallel Rela$onships
The English-‐Hebrew orderings: Figure 1: A dag representing a multithreaded computation. The edgesrepresent threads, labeled u0, u1, . . . u8. The diamonds represent forks,and the squares indicate joins.
Figure 2: The parse tree for the computation dag shown in Figure 1. Theleaves are the threads in the dag. The S-nodes indicate series relationships,and the P-nodes indicate parallel relationships.
present unless the corresponding left subtree has been fully elabo-rated. Both subtrees of a P-node, however, can be partially elabo-rated. In a language like Cilk, a serial execution unfolds the parsetree in the manner of a left-to-right walk. For example, in Figure 2,a serial execution executes the threads in the order of their indices.
A typical serial, on-the-fly data-race detector simulates the exe-cution of the program as a left-to-right walk of the parse tree whilemaintaining various data structures for determining the existenceof races. The core data structure maintains the series-parallel re-lationships between the currently executing thread and previouslyexecuted threads. Specifically, the race detector must determinewhether the current thread is operating logically in series or inparallel with certain previously executed threads. We call a dy-namic data structure that maintains the series-parallel relationshipbetween threads an SP-maintenance data structure. The data struc-ture supports insertion, deletion, and SP queries: queries as towhether two nodes are logically in series or in parallel.
The Nondeterminator [13,20] race detectors use a variant of Tar-jan’s [30] least-common-ancestor algorithm, as the basis of theirSP-maintenance data structure. To determine whether a thread ui
logically precedes a thread uj , denoted ui ≺ uj , their SP-bags al-gorithm can be viewed intuitively as inspecting their least commonancestor lca(ui, uj) in the parse tree to see whether it is an S-nodewith ui in its left subtree. Similarly, to determine whether a threadui operates logically in parallel with a thread uj , denoted ui ‖ uj ,the SP-bags algorithm checks whether lca(ui, uj) is a P-node. Ob-serve that an SP relationship exists between any two nodes in theparse tree, not just between threads (leaves).
For example, in Figure 2, we have u1 ≺ u4, because S1 =lca(u1, u4) is an S-node and u1 appears in S1’s left subtree. Wealso have u1 ‖ u6, because P1 = lca(u1, u6) is a P-node. The(serially executing) Nondeterminator race detectors perform SP-maintenance operations whenever the program being tested forks,joins, or accesses a shared-memory location. The amortized costfor each of these operations is O(α(v, v)), where α is Tarjan’sfunctional inverse of Ackermann’s function and v is the number
Algorithm Space Time perper node Thread Query
creation
English-Hebrew [27] Θ(f) Θ(1) Θ(f)Offset-Span [26] Θ(d) Θ(1) Θ(d)
SP-Bags [20] Θ(1) Θ(α(v, v)) Θ(α(v, v))SP-Order Θ(1) Θ(1) Θ(1)
f = number of forks in the programd = maximum depth of nested parallelismv = number of shared locations being monitored
Figure 3: Comparison of serial, SP-maintenance algorithms. The run-ning times of the English-Hebrew and offset-span algorithms are worst-casebounds, and the SP-bags and SP-order algorithms are amortized. The func-tion α is Tarjan’s functional inverse of Ackermann’s function.
of shared-memory locations used by the program. As a conse-quence, the asymptotic running time of the Nondeterminator isO(T1α(v, v)), where T1 is the running time of the original pro-gram on 1 processor.
The SP-bags data structure has two shortcomings. The first isthat it slows the asymptotic running time by a factor of α(v, v).This factor is nonconstant in theory but is nevertheless close enoughto constant in practice that this deficiency is minor. The second,more important shortcoming is that the SP-bags algorithm reliesheavily on the serial nature of its execution, and hence it appearsdifficult to parallelize.
Some early SP-maintenance algorithms use labeling schemeswithout centralized data structures. These labeling schemes areeasy to parallelize but unfortunately are much less efficient thanthe SP-bags algorithm. Examples of such labeling schemes includethe English-Hebrew scheme [27] and the offset-span scheme [26].These algorithms generate labels for each thread on the fly, but oncegenerated, the labels remain static. By comparing labels, these SP-maintenance algorithms can determine whether two threads operatelogically in series or in parallel. One of the reasons for the ineffi-ciency of these algorithms is that label lengths increase linearlywith the number of forks (English-Hebrew) or with the depth offork nesting (offset-span).
Results
In this paper we introduce a new SP-maintenance algorithm, calledthe SP-order algorithm, which is more efficient than the SP-bagsalgorithm. This algorithm is inspired by the English-Hebrewscheme, but rather than using static labels, the labels are maintainedby an order-maintenance data structure [10, 15, 17, 33]. Figure 3compares the serial space and running times of SP-order with theother algorithms. As can be seen from the table, SP-order attainsasymptotic optimality.
We also present a parallel SP-maintenance algorithm which isdesigned to run with a Cilk-like work-stealing scheduler [12, 21].Our SP-hybrid algorithm consists of two tiers: a global tier basedon our SP-order algorithm, and a local tier based on the Nondeter-minator’s SP-bags algorithm. Suppose that a fork-join program hasn threads, T1 work, and a critical-path length of T∞. Whereas theCilk scheduler executes a computation with work T1 and critical-path length T∞ in asymptotically optimal TP = O(T1/P + T∞)expected time on P processors, SP-hybrid executes the computa-tion in O((T1/P + PT∞) lg n) time on P processors while main-taining SP relationships. Thus, whereas the underlying computa-tion achieves linear speedup when P = O(T1/T∞), SP-hybridachieves linear speed-up when P = O(
√
T1/T∞), but the work isincreased by a factor of O(lg n).
The nodes in the leQ subtree of an S-‐node always precede those in the right subtree.

On-‐the-‐Fly Maintenance of Series-‐Parallel Rela$onships
The English-‐Hebrew orderings: Figure 1: A dag representing a multithreaded computation. The edgesrepresent threads, labeled u0, u1, . . . u8. The diamonds represent forks,and the squares indicate joins.
Figure 2: The parse tree for the computation dag shown in Figure 1. Theleaves are the threads in the dag. The S-nodes indicate series relationships,and the P-nodes indicate parallel relationships.
present unless the corresponding left subtree has been fully elabo-rated. Both subtrees of a P-node, however, can be partially elabo-rated. In a language like Cilk, a serial execution unfolds the parsetree in the manner of a left-to-right walk. For example, in Figure 2,a serial execution executes the threads in the order of their indices.
A typical serial, on-the-fly data-race detector simulates the exe-cution of the program as a left-to-right walk of the parse tree whilemaintaining various data structures for determining the existenceof races. The core data structure maintains the series-parallel re-lationships between the currently executing thread and previouslyexecuted threads. Specifically, the race detector must determinewhether the current thread is operating logically in series or inparallel with certain previously executed threads. We call a dy-namic data structure that maintains the series-parallel relationshipbetween threads an SP-maintenance data structure. The data struc-ture supports insertion, deletion, and SP queries: queries as towhether two nodes are logically in series or in parallel.
The Nondeterminator [13,20] race detectors use a variant of Tar-jan’s [30] least-common-ancestor algorithm, as the basis of theirSP-maintenance data structure. To determine whether a thread ui
logically precedes a thread uj , denoted ui ≺ uj , their SP-bags al-gorithm can be viewed intuitively as inspecting their least commonancestor lca(ui, uj) in the parse tree to see whether it is an S-nodewith ui in its left subtree. Similarly, to determine whether a threadui operates logically in parallel with a thread uj , denoted ui ‖ uj ,the SP-bags algorithm checks whether lca(ui, uj) is a P-node. Ob-serve that an SP relationship exists between any two nodes in theparse tree, not just between threads (leaves).
For example, in Figure 2, we have u1 ≺ u4, because S1 =lca(u1, u4) is an S-node and u1 appears in S1’s left subtree. Wealso have u1 ‖ u6, because P1 = lca(u1, u6) is a P-node. The(serially executing) Nondeterminator race detectors perform SP-maintenance operations whenever the program being tested forks,joins, or accesses a shared-memory location. The amortized costfor each of these operations is O(α(v, v)), where α is Tarjan’sfunctional inverse of Ackermann’s function and v is the number
Algorithm Space Time perper node Thread Query
creation
English-Hebrew [27] Θ(f) Θ(1) Θ(f)Offset-Span [26] Θ(d) Θ(1) Θ(d)
SP-Bags [20] Θ(1) Θ(α(v, v)) Θ(α(v, v))SP-Order Θ(1) Θ(1) Θ(1)
f = number of forks in the programd = maximum depth of nested parallelismv = number of shared locations being monitored
Figure 3: Comparison of serial, SP-maintenance algorithms. The run-ning times of the English-Hebrew and offset-span algorithms are worst-casebounds, and the SP-bags and SP-order algorithms are amortized. The func-tion α is Tarjan’s functional inverse of Ackermann’s function.
of shared-memory locations used by the program. As a conse-quence, the asymptotic running time of the Nondeterminator isO(T1α(v, v)), where T1 is the running time of the original pro-gram on 1 processor.
The SP-bags data structure has two shortcomings. The first isthat it slows the asymptotic running time by a factor of α(v, v).This factor is nonconstant in theory but is nevertheless close enoughto constant in practice that this deficiency is minor. The second,more important shortcoming is that the SP-bags algorithm reliesheavily on the serial nature of its execution, and hence it appearsdifficult to parallelize.
Some early SP-maintenance algorithms use labeling schemeswithout centralized data structures. These labeling schemes areeasy to parallelize but unfortunately are much less efficient thanthe SP-bags algorithm. Examples of such labeling schemes includethe English-Hebrew scheme [27] and the offset-span scheme [26].These algorithms generate labels for each thread on the fly, but oncegenerated, the labels remain static. By comparing labels, these SP-maintenance algorithms can determine whether two threads operatelogically in series or in parallel. One of the reasons for the ineffi-ciency of these algorithms is that label lengths increase linearlywith the number of forks (English-Hebrew) or with the depth offork nesting (offset-span).
Results
In this paper we introduce a new SP-maintenance algorithm, calledthe SP-order algorithm, which is more efficient than the SP-bagsalgorithm. This algorithm is inspired by the English-Hebrewscheme, but rather than using static labels, the labels are maintainedby an order-maintenance data structure [10, 15, 17, 33]. Figure 3compares the serial space and running times of SP-order with theother algorithms. As can be seen from the table, SP-order attainsasymptotic optimality.
We also present a parallel SP-maintenance algorithm which isdesigned to run with a Cilk-like work-stealing scheduler [12, 21].Our SP-hybrid algorithm consists of two tiers: a global tier basedon our SP-order algorithm, and a local tier based on the Nondeter-minator’s SP-bags algorithm. Suppose that a fork-join program hasn threads, T1 work, and a critical-path length of T∞. Whereas theCilk scheduler executes a computation with work T1 and critical-path length T∞ in asymptotically optimal TP = O(T1/P + T∞)expected time on P processors, SP-hybrid executes the computa-tion in O((T1/P + PT∞) lg n) time on P processors while main-taining SP relationships. Thus, whereas the underlying computa-tion achieves linear speedup when P = O(T1/T∞), SP-hybridachieves linear speed-up when P = O(
√
T1/T∞), but the work isincreased by a factor of O(lg n).
The nodes in the leQ subtree of an S-‐node always precede those in the right subtree. English order: the nodes in the leQ subtree of a P-‐node precede those in the right subtree.
1
2 3
4
5
6 7
8

On-‐the-‐Fly Maintenance of Series-‐Parallel Rela$onships
The English-‐Hebrew orderings: Figure 1: A dag representing a multithreaded computation. The edgesrepresent threads, labeled u0, u1, . . . u8. The diamonds represent forks,and the squares indicate joins.
Figure 2: The parse tree for the computation dag shown in Figure 1. Theleaves are the threads in the dag. The S-nodes indicate series relationships,and the P-nodes indicate parallel relationships.
present unless the corresponding left subtree has been fully elabo-rated. Both subtrees of a P-node, however, can be partially elabo-rated. In a language like Cilk, a serial execution unfolds the parsetree in the manner of a left-to-right walk. For example, in Figure 2,a serial execution executes the threads in the order of their indices.
A typical serial, on-the-fly data-race detector simulates the exe-cution of the program as a left-to-right walk of the parse tree whilemaintaining various data structures for determining the existenceof races. The core data structure maintains the series-parallel re-lationships between the currently executing thread and previouslyexecuted threads. Specifically, the race detector must determinewhether the current thread is operating logically in series or inparallel with certain previously executed threads. We call a dy-namic data structure that maintains the series-parallel relationshipbetween threads an SP-maintenance data structure. The data struc-ture supports insertion, deletion, and SP queries: queries as towhether two nodes are logically in series or in parallel.
The Nondeterminator [13,20] race detectors use a variant of Tar-jan’s [30] least-common-ancestor algorithm, as the basis of theirSP-maintenance data structure. To determine whether a thread ui
logically precedes a thread uj , denoted ui ≺ uj , their SP-bags al-gorithm can be viewed intuitively as inspecting their least commonancestor lca(ui, uj) in the parse tree to see whether it is an S-nodewith ui in its left subtree. Similarly, to determine whether a threadui operates logically in parallel with a thread uj , denoted ui ‖ uj ,the SP-bags algorithm checks whether lca(ui, uj) is a P-node. Ob-serve that an SP relationship exists between any two nodes in theparse tree, not just between threads (leaves).
For example, in Figure 2, we have u1 ≺ u4, because S1 =lca(u1, u4) is an S-node and u1 appears in S1’s left subtree. Wealso have u1 ‖ u6, because P1 = lca(u1, u6) is a P-node. The(serially executing) Nondeterminator race detectors perform SP-maintenance operations whenever the program being tested forks,joins, or accesses a shared-memory location. The amortized costfor each of these operations is O(α(v, v)), where α is Tarjan’sfunctional inverse of Ackermann’s function and v is the number
Algorithm Space Time perper node Thread Query
creation
English-Hebrew [27] Θ(f) Θ(1) Θ(f)Offset-Span [26] Θ(d) Θ(1) Θ(d)
SP-Bags [20] Θ(1) Θ(α(v, v)) Θ(α(v, v))SP-Order Θ(1) Θ(1) Θ(1)
f = number of forks in the programd = maximum depth of nested parallelismv = number of shared locations being monitored
Figure 3: Comparison of serial, SP-maintenance algorithms. The run-ning times of the English-Hebrew and offset-span algorithms are worst-casebounds, and the SP-bags and SP-order algorithms are amortized. The func-tion α is Tarjan’s functional inverse of Ackermann’s function.
of shared-memory locations used by the program. As a conse-quence, the asymptotic running time of the Nondeterminator isO(T1α(v, v)), where T1 is the running time of the original pro-gram on 1 processor.
The SP-bags data structure has two shortcomings. The first isthat it slows the asymptotic running time by a factor of α(v, v).This factor is nonconstant in theory but is nevertheless close enoughto constant in practice that this deficiency is minor. The second,more important shortcoming is that the SP-bags algorithm reliesheavily on the serial nature of its execution, and hence it appearsdifficult to parallelize.
Some early SP-maintenance algorithms use labeling schemeswithout centralized data structures. These labeling schemes areeasy to parallelize but unfortunately are much less efficient thanthe SP-bags algorithm. Examples of such labeling schemes includethe English-Hebrew scheme [27] and the offset-span scheme [26].These algorithms generate labels for each thread on the fly, but oncegenerated, the labels remain static. By comparing labels, these SP-maintenance algorithms can determine whether two threads operatelogically in series or in parallel. One of the reasons for the ineffi-ciency of these algorithms is that label lengths increase linearlywith the number of forks (English-Hebrew) or with the depth offork nesting (offset-span).
Results
In this paper we introduce a new SP-maintenance algorithm, calledthe SP-order algorithm, which is more efficient than the SP-bagsalgorithm. This algorithm is inspired by the English-Hebrewscheme, but rather than using static labels, the labels are maintainedby an order-maintenance data structure [10, 15, 17, 33]. Figure 3compares the serial space and running times of SP-order with theother algorithms. As can be seen from the table, SP-order attainsasymptotic optimality.
We also present a parallel SP-maintenance algorithm which isdesigned to run with a Cilk-like work-stealing scheduler [12, 21].Our SP-hybrid algorithm consists of two tiers: a global tier basedon our SP-order algorithm, and a local tier based on the Nondeter-minator’s SP-bags algorithm. Suppose that a fork-join program hasn threads, T1 work, and a critical-path length of T∞. Whereas theCilk scheduler executes a computation with work T1 and critical-path length T∞ in asymptotically optimal TP = O(T1/P + T∞)expected time on P processors, SP-hybrid executes the computa-tion in O((T1/P + PT∞) lg n) time on P processors while main-taining SP relationships. Thus, whereas the underlying computa-tion achieves linear speedup when P = O(T1/T∞), SP-hybridachieves linear speed-up when P = O(
√
T1/T∞), but the work isincreased by a factor of O(lg n).
The nodes in the leQ subtree of an S-‐node always precede those in the right subtree. English order: the nodes in the leQ subtree of a P-‐node precede those in the right subtree. Hebrew order: the nodes in the right subtree of a P-‐node precede those in the leQ.
1
2 3
4
5
6 7
8
( , 1)
( , 2)
( , 4)
( , 3)
( , 5)
( , 6) ( , 7)
( , 8)
Under a S-‐node: E[uleQ] < E[uright] H[uleQ] < H[uright]
Under a P-‐node: E[uleQ] < E[uright] H[uleQ] > H[uright]
Key observa@on:

On-‐the-‐Fly Maintenance of Series-‐Parallel Rela$onships
The English-‐Hebrew orderings: Figure 1: A dag representing a multithreaded computation. The edgesrepresent threads, labeled u0, u1, . . . u8. The diamonds represent forks,and the squares indicate joins.
Figure 2: The parse tree for the computation dag shown in Figure 1. Theleaves are the threads in the dag. The S-nodes indicate series relationships,and the P-nodes indicate parallel relationships.
present unless the corresponding left subtree has been fully elabo-rated. Both subtrees of a P-node, however, can be partially elabo-rated. In a language like Cilk, a serial execution unfolds the parsetree in the manner of a left-to-right walk. For example, in Figure 2,a serial execution executes the threads in the order of their indices.
A typical serial, on-the-fly data-race detector simulates the exe-cution of the program as a left-to-right walk of the parse tree whilemaintaining various data structures for determining the existenceof races. The core data structure maintains the series-parallel re-lationships between the currently executing thread and previouslyexecuted threads. Specifically, the race detector must determinewhether the current thread is operating logically in series or inparallel with certain previously executed threads. We call a dy-namic data structure that maintains the series-parallel relationshipbetween threads an SP-maintenance data structure. The data struc-ture supports insertion, deletion, and SP queries: queries as towhether two nodes are logically in series or in parallel.
The Nondeterminator [13,20] race detectors use a variant of Tar-jan’s [30] least-common-ancestor algorithm, as the basis of theirSP-maintenance data structure. To determine whether a thread ui
logically precedes a thread uj , denoted ui ≺ uj , their SP-bags al-gorithm can be viewed intuitively as inspecting their least commonancestor lca(ui, uj) in the parse tree to see whether it is an S-nodewith ui in its left subtree. Similarly, to determine whether a threadui operates logically in parallel with a thread uj , denoted ui ‖ uj ,the SP-bags algorithm checks whether lca(ui, uj) is a P-node. Ob-serve that an SP relationship exists between any two nodes in theparse tree, not just between threads (leaves).
For example, in Figure 2, we have u1 ≺ u4, because S1 =lca(u1, u4) is an S-node and u1 appears in S1’s left subtree. Wealso have u1 ‖ u6, because P1 = lca(u1, u6) is a P-node. The(serially executing) Nondeterminator race detectors perform SP-maintenance operations whenever the program being tested forks,joins, or accesses a shared-memory location. The amortized costfor each of these operations is O(α(v, v)), where α is Tarjan’sfunctional inverse of Ackermann’s function and v is the number
Algorithm Space Time perper node Thread Query
creation
English-Hebrew [27] Θ(f) Θ(1) Θ(f)Offset-Span [26] Θ(d) Θ(1) Θ(d)
SP-Bags [20] Θ(1) Θ(α(v, v)) Θ(α(v, v))SP-Order Θ(1) Θ(1) Θ(1)
f = number of forks in the programd = maximum depth of nested parallelismv = number of shared locations being monitored
Figure 3: Comparison of serial, SP-maintenance algorithms. The run-ning times of the English-Hebrew and offset-span algorithms are worst-casebounds, and the SP-bags and SP-order algorithms are amortized. The func-tion α is Tarjan’s functional inverse of Ackermann’s function.
of shared-memory locations used by the program. As a conse-quence, the asymptotic running time of the Nondeterminator isO(T1α(v, v)), where T1 is the running time of the original pro-gram on 1 processor.
The SP-bags data structure has two shortcomings. The first isthat it slows the asymptotic running time by a factor of α(v, v).This factor is nonconstant in theory but is nevertheless close enoughto constant in practice that this deficiency is minor. The second,more important shortcoming is that the SP-bags algorithm reliesheavily on the serial nature of its execution, and hence it appearsdifficult to parallelize.
Some early SP-maintenance algorithms use labeling schemeswithout centralized data structures. These labeling schemes areeasy to parallelize but unfortunately are much less efficient thanthe SP-bags algorithm. Examples of such labeling schemes includethe English-Hebrew scheme [27] and the offset-span scheme [26].These algorithms generate labels for each thread on the fly, but oncegenerated, the labels remain static. By comparing labels, these SP-maintenance algorithms can determine whether two threads operatelogically in series or in parallel. One of the reasons for the ineffi-ciency of these algorithms is that label lengths increase linearlywith the number of forks (English-Hebrew) or with the depth offork nesting (offset-span).
Results
In this paper we introduce a new SP-maintenance algorithm, calledthe SP-order algorithm, which is more efficient than the SP-bagsalgorithm. This algorithm is inspired by the English-Hebrewscheme, but rather than using static labels, the labels are maintainedby an order-maintenance data structure [10, 15, 17, 33]. Figure 3compares the serial space and running times of SP-order with theother algorithms. As can be seen from the table, SP-order attainsasymptotic optimality.
We also present a parallel SP-maintenance algorithm which isdesigned to run with a Cilk-like work-stealing scheduler [12, 21].Our SP-hybrid algorithm consists of two tiers: a global tier basedon our SP-order algorithm, and a local tier based on the Nondeter-minator’s SP-bags algorithm. Suppose that a fork-join program hasn threads, T1 work, and a critical-path length of T∞. Whereas theCilk scheduler executes a computation with work T1 and critical-path length T∞ in asymptotically optimal TP = O(T1/P + T∞)expected time on P processors, SP-hybrid executes the computa-tion in O((T1/P + PT∞) lg n) time on P processors while main-taining SP relationships. Thus, whereas the underlying computa-tion achieves linear speedup when P = O(T1/T∞), SP-hybridachieves linear speed-up when P = O(
√
T1/T∞), but the work isincreased by a factor of O(lg n).
1
2 3
4
5
6 7
8
( , 1)
( , 2)
( , 4)
( , 3)
( , 5)
( , 6) ( , 7)
( , 8)
Under a S-‐node: E[uleQ] < E[uright] H[uleQ] < H[uright]
Under a P-‐node: E[uleQ] < E[uright] H[uleQ] > H[uright]
Observa@on #1:
Ques?on: Can we maintain the two labeling on the fly as the computa?on executes?
Observa@on #2: One doesn't need to assign specific labels for each strand; a rela$ve-‐ordering suffices.

The SP-‐Order Algorithm SP-‐Order(X): // X is a node is the SP tree if IsLeaf(X)
execute strand X return
// otherwie X is an internal node OM-‐Insert(Eng, X, leQ[X], right[X]) if IsSNode(X)
OM-‐Insert(Heb, X, leQ[X], right[X]) else
OM-‐Insert(Heb, X, right[X], leQ[X]) SP-‐Order(leQ[X]) SP-‐Order(right[X])
To detect race between two strands, check if they are in the same rela$ve order to each other in both Eng and Heb.
OM-‐Insert(L, X, Y1, Y2): In the ordering L, insert new element Y1 and Y2 immediately aQer X.

The SP-‐Order Algorithm SP-‐Order(X): // X is a node is the SP tree if IsLeaf(X)
execute strand X return
// otherwie X is an internal node OM-‐Insert(Eng, X, leQ[X], right[X]) if IsSNode(X)
OM-‐Insert(Heb, X, leQ[X], right[X]) else
OM-‐Insert(Heb, X, right[X], leQ[X]) SP-‐Order(leQ[X]) SP-‐Order(right[X])
To detect race between two strands, check if they are in the same rela$ve order to each other in both Eng and Heb.
Before/aQer execu$ng an S node:
English:
Hebrew:
Figure 6: An illustration of how SP-order operates at an S-node. (a) Asimple parse tree with an S-node S and two children L and R. (b) Theorder structures before traversing to S. The clouds represent the rest of theorder structure, which does not change when traversing to S. (c) The resultof the inserts after traversing to S. The left child L and then the right childR are inserted after S in both lists.
Figure 7: An illustration of how SP-order operates at a P-node. (a) Asimple parse tree with an P-node P and two children L and R. (b) Theorder structures before traversing to P . The clouds are the rest of the orderstructure, which does not change when traversing to P . (c) The result ofthe inserts after traversing to P . The left child L then the right child R areinserted after P in the English order, and R then L are inserted after P inthe Hebrew order.
Corollary 6. Consider a fork-join multithreaded program withrunning time T1 on a single processor. Then, a determinacy-racedetector using SP-order runs in O(T1) time.
To conclude this section, we observe that SP-order can be madeto work on the fly no matter how the input SP parse tree unfolds.Not only can lines 8–9 of Figure 5 be executed in either order, thebasic recursive call could be executed on nodes in any order thatrespects the parent-child and SP relationships. For example, onecould unfold the parse tree in essentially breadth-first fashion at P-nodes as long as the left subtree of an S-node is fully expandedbefore its right subtree is processed. An examination of the proofof Lemma 3 shows why we have this flexibility. The invariant inthe proof considers only a node and its children. If we expand anysingle node, its children are inserted into the order-maintenancedata structures in the proper place independent of what other nodeshave been expanded.
3 The SP-hybrid algorithm
This section describes the structure of the SP-hybrid parallel SP-maintenance algorithm. We begin by discussing how an SP parsetree is provided as input to SP-hybrid and explaining some of theproperties of Cilk that SP-hybrid exploits. We then describe thetwo-tier structure of the algorithm, which combines elements of
SP-order from Section 2 and SP-bags from [20]. We investigate thesynchronization issues that must be faced in order to parallelize SP-order and why a naive parallelization does not yield good bounds.We then overview SP-hybrid itself and present pseudocode for itsimplementation.
SP-hybrid’s input and Cilk
Like the SP-order algorithm, the SP-hybrid algorithm accepts asinput a fork-join multithreaded program expressed as an SP parsetree. The algorithm SP-hybrid provides weaker query semanticsthan the serial SP-order algorithm; these semantics are exactly whatis required for on-the-fly determinacy-race detection. Whereas SP-order allows queries of any two threads that have been unfoldedin the parse tree, SP-hybrid requires that one of the threads be acurrently executing thread. For a fork-join program with n threads,T1 work, and a critical path of length T∞, the parallel SP-hybridalgorithm can be made to run (in Cilk) in O((T1/P + PT∞) lg n)expected time.
Although SP-hybrid provides these performance bounds for anyfork-join program, it can only operate “on the fly” for programswhose parse trees unfold in a Cilk-like manner. Specifically, SP-hybrid is described and analyzed as a Cilk program, and as such,it takes advantage of two properties of the Cilk scheduler to ensureefficient execution. First, any single processor unfolds the parsetree left-to-right. Second, it exploits the properties of Cilk’s “work-stealing” scheduler, both for correctness and efficiency. AlthoughSP-hybrid operates correctly and efficiently on the a posteriori SPparse tree for any fork-join program, it only operates “on-the-fly”when the parse tree unfolds similar to a Cilk computation.
Cilk employs a “work-stealing” scheduler, which executes anymultithreaded computation having work T1 and critical-path lengthT∞ in O(T1/P + T∞) expected time on P processors, which isasymptotically optimal. The idea behind work stealing is that whena processor runs out of its own work to do, it “steals” work fromanother processor. Thus, the steals that occur during a Cilk com-putation break the computation, and hence the computation’s SPparse tree, into a set of “traces,” where each trace consists of a setof threads all executed by the same processor. These traces have ad-ditional structure imposed by Cilk’s scheduler. Specifically, when-ever a thief processor steals work from a victim processor, the workstolen corresponds to the right subtree of the P-node that is highestin the SP-parse tree walked by the victim. Cilk’s scheduler providesan upper bound of O(PT∞) steals with high probability.
A naive parallelization of SP-order
A straightforward way to parallelize the SP-order algorithm is toshare the SP-order data structure among the processors that are ex-ecuting the input fork-join program. The problem that arises, how-ever, is that processors may interfere with each other as they modifythe data structure, and thus some method of synchronization mustbe employed to provide mutual exclusion.
A common way to handle mutual exclusion is through the use oflocks. For example, suppose that each processor obtains a globallock prior to every OM-INSERT or OM-PRECEDES operation onthe shared SP-order data structure, releasing the lock when the op-eration is complete. Although this parallel version of SP-order iscorrect, the locking can introduce significant performance penal-ties.
Consider a parallel execution of this naive parallel SP-order al-gorithm on P processors. During a single operation by a processoron the shared SP-order data structure, all P − 1 other processorsmay stall while waiting for the lock required to perform their ownoperations. Let us assume, as is reasonable, that no processor waitson a lock unless another processor owns the lock. Thus, if we at-tribute the cost of waiting for a lock to the processor that owns the
Figure 6: An illustration of how SP-order operates at an S-node. (a) Asimple parse tree with an S-node S and two children L and R. (b) Theorder structures before traversing to S. The clouds represent the rest of theorder structure, which does not change when traversing to S. (c) The resultof the inserts after traversing to S. The left child L and then the right childR are inserted after S in both lists.
Figure 7: An illustration of how SP-order operates at a P-node. (a) Asimple parse tree with an P-node P and two children L and R. (b) Theorder structures before traversing to P . The clouds are the rest of the orderstructure, which does not change when traversing to P . (c) The result ofthe inserts after traversing to P . The left child L then the right child R areinserted after P in the English order, and R then L are inserted after P inthe Hebrew order.
Corollary 6. Consider a fork-join multithreaded program withrunning time T1 on a single processor. Then, a determinacy-racedetector using SP-order runs in O(T1) time.
To conclude this section, we observe that SP-order can be madeto work on the fly no matter how the input SP parse tree unfolds.Not only can lines 8–9 of Figure 5 be executed in either order, thebasic recursive call could be executed on nodes in any order thatrespects the parent-child and SP relationships. For example, onecould unfold the parse tree in essentially breadth-first fashion at P-nodes as long as the left subtree of an S-node is fully expandedbefore its right subtree is processed. An examination of the proofof Lemma 3 shows why we have this flexibility. The invariant inthe proof considers only a node and its children. If we expand anysingle node, its children are inserted into the order-maintenancedata structures in the proper place independent of what other nodeshave been expanded.
3 The SP-hybrid algorithm
This section describes the structure of the SP-hybrid parallel SP-maintenance algorithm. We begin by discussing how an SP parsetree is provided as input to SP-hybrid and explaining some of theproperties of Cilk that SP-hybrid exploits. We then describe thetwo-tier structure of the algorithm, which combines elements of
SP-order from Section 2 and SP-bags from [20]. We investigate thesynchronization issues that must be faced in order to parallelize SP-order and why a naive parallelization does not yield good bounds.We then overview SP-hybrid itself and present pseudocode for itsimplementation.
SP-hybrid’s input and Cilk
Like the SP-order algorithm, the SP-hybrid algorithm accepts asinput a fork-join multithreaded program expressed as an SP parsetree. The algorithm SP-hybrid provides weaker query semanticsthan the serial SP-order algorithm; these semantics are exactly whatis required for on-the-fly determinacy-race detection. Whereas SP-order allows queries of any two threads that have been unfoldedin the parse tree, SP-hybrid requires that one of the threads be acurrently executing thread. For a fork-join program with n threads,T1 work, and a critical path of length T∞, the parallel SP-hybridalgorithm can be made to run (in Cilk) in O((T1/P + PT∞) lg n)expected time.
Although SP-hybrid provides these performance bounds for anyfork-join program, it can only operate “on the fly” for programswhose parse trees unfold in a Cilk-like manner. Specifically, SP-hybrid is described and analyzed as a Cilk program, and as such,it takes advantage of two properties of the Cilk scheduler to ensureefficient execution. First, any single processor unfolds the parsetree left-to-right. Second, it exploits the properties of Cilk’s “work-stealing” scheduler, both for correctness and efficiency. AlthoughSP-hybrid operates correctly and efficiently on the a posteriori SPparse tree for any fork-join program, it only operates “on-the-fly”when the parse tree unfolds similar to a Cilk computation.
Cilk employs a “work-stealing” scheduler, which executes anymultithreaded computation having work T1 and critical-path lengthT∞ in O(T1/P + T∞) expected time on P processors, which isasymptotically optimal. The idea behind work stealing is that whena processor runs out of its own work to do, it “steals” work fromanother processor. Thus, the steals that occur during a Cilk com-putation break the computation, and hence the computation’s SPparse tree, into a set of “traces,” where each trace consists of a setof threads all executed by the same processor. These traces have ad-ditional structure imposed by Cilk’s scheduler. Specifically, when-ever a thief processor steals work from a victim processor, the workstolen corresponds to the right subtree of the P-node that is highestin the SP-parse tree walked by the victim. Cilk’s scheduler providesan upper bound of O(PT∞) steals with high probability.
A naive parallelization of SP-order
A straightforward way to parallelize the SP-order algorithm is toshare the SP-order data structure among the processors that are ex-ecuting the input fork-join program. The problem that arises, how-ever, is that processors may interfere with each other as they modifythe data structure, and thus some method of synchronization mustbe employed to provide mutual exclusion.
A common way to handle mutual exclusion is through the use oflocks. For example, suppose that each processor obtains a globallock prior to every OM-INSERT or OM-PRECEDES operation onthe shared SP-order data structure, releasing the lock when the op-eration is complete. Although this parallel version of SP-order iscorrect, the locking can introduce significant performance penal-ties.
Consider a parallel execution of this naive parallel SP-order al-gorithm on P processors. During a single operation by a processoron the shared SP-order data structure, all P − 1 other processorsmay stall while waiting for the lock required to perform their ownoperations. Let us assume, as is reasonable, that no processor waitson a lock unless another processor owns the lock. Thus, if we at-tribute the cost of waiting for a lock to the processor that owns the
English:
Hebrew: Figure 6: An illustration of how SP-order operates at an S-node. (a) Asimple parse tree with an S-node S and two children L and R. (b) Theorder structures before traversing to S. The clouds represent the rest of theorder structure, which does not change when traversing to S. (c) The resultof the inserts after traversing to S. The left child L and then the right childR are inserted after S in both lists.
Figure 7: An illustration of how SP-order operates at a P-node. (a) Asimple parse tree with an P-node P and two children L and R. (b) Theorder structures before traversing to P . The clouds are the rest of the orderstructure, which does not change when traversing to P . (c) The result ofthe inserts after traversing to P . The left child L then the right child R areinserted after P in the English order, and R then L are inserted after P inthe Hebrew order.
Corollary 6. Consider a fork-join multithreaded program withrunning time T1 on a single processor. Then, a determinacy-racedetector using SP-order runs in O(T1) time.
To conclude this section, we observe that SP-order can be madeto work on the fly no matter how the input SP parse tree unfolds.Not only can lines 8–9 of Figure 5 be executed in either order, thebasic recursive call could be executed on nodes in any order thatrespects the parent-child and SP relationships. For example, onecould unfold the parse tree in essentially breadth-first fashion at P-nodes as long as the left subtree of an S-node is fully expandedbefore its right subtree is processed. An examination of the proofof Lemma 3 shows why we have this flexibility. The invariant inthe proof considers only a node and its children. If we expand anysingle node, its children are inserted into the order-maintenancedata structures in the proper place independent of what other nodeshave been expanded.
3 The SP-hybrid algorithm
This section describes the structure of the SP-hybrid parallel SP-maintenance algorithm. We begin by discussing how an SP parsetree is provided as input to SP-hybrid and explaining some of theproperties of Cilk that SP-hybrid exploits. We then describe thetwo-tier structure of the algorithm, which combines elements of
SP-order from Section 2 and SP-bags from [20]. We investigate thesynchronization issues that must be faced in order to parallelize SP-order and why a naive parallelization does not yield good bounds.We then overview SP-hybrid itself and present pseudocode for itsimplementation.
SP-hybrid’s input and Cilk
Like the SP-order algorithm, the SP-hybrid algorithm accepts asinput a fork-join multithreaded program expressed as an SP parsetree. The algorithm SP-hybrid provides weaker query semanticsthan the serial SP-order algorithm; these semantics are exactly whatis required for on-the-fly determinacy-race detection. Whereas SP-order allows queries of any two threads that have been unfoldedin the parse tree, SP-hybrid requires that one of the threads be acurrently executing thread. For a fork-join program with n threads,T1 work, and a critical path of length T∞, the parallel SP-hybridalgorithm can be made to run (in Cilk) in O((T1/P + PT∞) lg n)expected time.
Although SP-hybrid provides these performance bounds for anyfork-join program, it can only operate “on the fly” for programswhose parse trees unfold in a Cilk-like manner. Specifically, SP-hybrid is described and analyzed as a Cilk program, and as such,it takes advantage of two properties of the Cilk scheduler to ensureefficient execution. First, any single processor unfolds the parsetree left-to-right. Second, it exploits the properties of Cilk’s “work-stealing” scheduler, both for correctness and efficiency. AlthoughSP-hybrid operates correctly and efficiently on the a posteriori SPparse tree for any fork-join program, it only operates “on-the-fly”when the parse tree unfolds similar to a Cilk computation.
Cilk employs a “work-stealing” scheduler, which executes anymultithreaded computation having work T1 and critical-path lengthT∞ in O(T1/P + T∞) expected time on P processors, which isasymptotically optimal. The idea behind work stealing is that whena processor runs out of its own work to do, it “steals” work fromanother processor. Thus, the steals that occur during a Cilk com-putation break the computation, and hence the computation’s SPparse tree, into a set of “traces,” where each trace consists of a setof threads all executed by the same processor. These traces have ad-ditional structure imposed by Cilk’s scheduler. Specifically, when-ever a thief processor steals work from a victim processor, the workstolen corresponds to the right subtree of the P-node that is highestin the SP-parse tree walked by the victim. Cilk’s scheduler providesan upper bound of O(PT∞) steals with high probability.
A naive parallelization of SP-order
A straightforward way to parallelize the SP-order algorithm is toshare the SP-order data structure among the processors that are ex-ecuting the input fork-join program. The problem that arises, how-ever, is that processors may interfere with each other as they modifythe data structure, and thus some method of synchronization mustbe employed to provide mutual exclusion.
A common way to handle mutual exclusion is through the use oflocks. For example, suppose that each processor obtains a globallock prior to every OM-INSERT or OM-PRECEDES operation onthe shared SP-order data structure, releasing the lock when the op-eration is complete. Although this parallel version of SP-order iscorrect, the locking can introduce significant performance penal-ties.
Consider a parallel execution of this naive parallel SP-order al-gorithm on P processors. During a single operation by a processoron the shared SP-order data structure, all P − 1 other processorsmay stall while waiting for the lock required to perform their ownoperations. Let us assume, as is reasonable, that no processor waitson a lock unless another processor owns the lock. Thus, if we at-tribute the cost of waiting for a lock to the processor that owns the
English:
Hebrew:
Figure 6: An illustration of how SP-order operates at an S-node. (a) Asimple parse tree with an S-node S and two children L and R. (b) Theorder structures before traversing to S. The clouds represent the rest of theorder structure, which does not change when traversing to S. (c) The resultof the inserts after traversing to S. The left child L and then the right childR are inserted after S in both lists.
Figure 7: An illustration of how SP-order operates at a P-node. (a) Asimple parse tree with an P-node P and two children L and R. (b) Theorder structures before traversing to P . The clouds are the rest of the orderstructure, which does not change when traversing to P . (c) The result ofthe inserts after traversing to P . The left child L then the right child R areinserted after P in the English order, and R then L are inserted after P inthe Hebrew order.
Corollary 6. Consider a fork-join multithreaded program withrunning time T1 on a single processor. Then, a determinacy-racedetector using SP-order runs in O(T1) time.
To conclude this section, we observe that SP-order can be madeto work on the fly no matter how the input SP parse tree unfolds.Not only can lines 8–9 of Figure 5 be executed in either order, thebasic recursive call could be executed on nodes in any order thatrespects the parent-child and SP relationships. For example, onecould unfold the parse tree in essentially breadth-first fashion at P-nodes as long as the left subtree of an S-node is fully expandedbefore its right subtree is processed. An examination of the proofof Lemma 3 shows why we have this flexibility. The invariant inthe proof considers only a node and its children. If we expand anysingle node, its children are inserted into the order-maintenancedata structures in the proper place independent of what other nodeshave been expanded.
3 The SP-hybrid algorithm
This section describes the structure of the SP-hybrid parallel SP-maintenance algorithm. We begin by discussing how an SP parsetree is provided as input to SP-hybrid and explaining some of theproperties of Cilk that SP-hybrid exploits. We then describe thetwo-tier structure of the algorithm, which combines elements of
SP-order from Section 2 and SP-bags from [20]. We investigate thesynchronization issues that must be faced in order to parallelize SP-order and why a naive parallelization does not yield good bounds.We then overview SP-hybrid itself and present pseudocode for itsimplementation.
SP-hybrid’s input and Cilk
Like the SP-order algorithm, the SP-hybrid algorithm accepts asinput a fork-join multithreaded program expressed as an SP parsetree. The algorithm SP-hybrid provides weaker query semanticsthan the serial SP-order algorithm; these semantics are exactly whatis required for on-the-fly determinacy-race detection. Whereas SP-order allows queries of any two threads that have been unfoldedin the parse tree, SP-hybrid requires that one of the threads be acurrently executing thread. For a fork-join program with n threads,T1 work, and a critical path of length T∞, the parallel SP-hybridalgorithm can be made to run (in Cilk) in O((T1/P + PT∞) lg n)expected time.
Although SP-hybrid provides these performance bounds for anyfork-join program, it can only operate “on the fly” for programswhose parse trees unfold in a Cilk-like manner. Specifically, SP-hybrid is described and analyzed as a Cilk program, and as such,it takes advantage of two properties of the Cilk scheduler to ensureefficient execution. First, any single processor unfolds the parsetree left-to-right. Second, it exploits the properties of Cilk’s “work-stealing” scheduler, both for correctness and efficiency. AlthoughSP-hybrid operates correctly and efficiently on the a posteriori SPparse tree for any fork-join program, it only operates “on-the-fly”when the parse tree unfolds similar to a Cilk computation.
Cilk employs a “work-stealing” scheduler, which executes anymultithreaded computation having work T1 and critical-path lengthT∞ in O(T1/P + T∞) expected time on P processors, which isasymptotically optimal. The idea behind work stealing is that whena processor runs out of its own work to do, it “steals” work fromanother processor. Thus, the steals that occur during a Cilk com-putation break the computation, and hence the computation’s SPparse tree, into a set of “traces,” where each trace consists of a setof threads all executed by the same processor. These traces have ad-ditional structure imposed by Cilk’s scheduler. Specifically, when-ever a thief processor steals work from a victim processor, the workstolen corresponds to the right subtree of the P-node that is highestin the SP-parse tree walked by the victim. Cilk’s scheduler providesan upper bound of O(PT∞) steals with high probability.
A naive parallelization of SP-order
A straightforward way to parallelize the SP-order algorithm is toshare the SP-order data structure among the processors that are ex-ecuting the input fork-join program. The problem that arises, how-ever, is that processors may interfere with each other as they modifythe data structure, and thus some method of synchronization mustbe employed to provide mutual exclusion.
A common way to handle mutual exclusion is through the use oflocks. For example, suppose that each processor obtains a globallock prior to every OM-INSERT or OM-PRECEDES operation onthe shared SP-order data structure, releasing the lock when the op-eration is complete. Although this parallel version of SP-order iscorrect, the locking can introduce significant performance penal-ties.
Consider a parallel execution of this naive parallel SP-order al-gorithm on P processors. During a single operation by a processoron the shared SP-order data structure, all P − 1 other processorsmay stall while waiting for the lock required to perform their ownoperations. Let us assume, as is reasonable, that no processor waitson a lock unless another processor owns the lock. Thus, if we at-tribute the cost of waiting for a lock to the processor that owns the
Before/aQer execu$ng a P node:
English:
Hebrew:
L and R are the leQ and right children in the SP parse tree.
Naïve paralleliza@on: the Order Maintenance data structure becomes a scalability boZleneck.

SP-‐Hybrid • Recall: between successful steals, each worker's behavior
mirrors the serial execu$on. trace: the execu$on done by a worker between steals.
• A two-‐$er scheme: global $er: use a global Order Maintenance data structure to maintain the ordering between traces. -‐ a clever design of a concurrent data structure allows one to query the data structure without locking. local $er: within a trace, query SP rela$onships using the SP-‐bags data structure.
Challenge: traces are defined dynamically as steals occur, so how do we keep track of that?

SP-‐Hybrid • Recall: between successful steals, each worker's behavior
mirrors the serial execu$on. trace: the execu$on done by a worker between steals.
• A two-‐$er scheme: global $er: use a global Order Maintenance data structure to maintain the ordering between traces. -‐ a clever design of a concurrent data structure allows one to query the data structure without locking. local $er: within a trace, query SP rela$onships using the SP-‐bags data structure.
Challenge: traces are defined dynamically as steals occur, so how do we keep track of that?

Spli|ng Traces On-‐the-‐Fly
Figure 11: The split of a trace U around a P-node X in terms of a canon-ical Cilk parse tree. The tree walk of U is executing in left [X] when thesubtree rooted at right [X] is stolen by a thief processor. The shaded re-gions contain the nodes belonging to each of the subtraces produced by thesplit. The two circles not enclosing any text indicate portions of the parsetree that have not yet been visited by the tree walk of U .
Figure 12: An ordering of the new traces resulting from a steal as shown inFigure 11. Each circle represents a trace.
single processor working on a trace. The FIND-TRACE operation,however, may be executed by any processor, and thus the imple-mentation must operate correctly in the face of multiple FIND-TRACE operations.
The implementation of SP-bags proposed in [20] uses the classi-cal disjoint-set data structure with “union by rank” and “path com-pression” heuristics [14, 29, 31]. On a single processor, this datastructure allows all local-tier operations to be supported in amor-tized O(α(m,n)) time, where α is Tarjan’s functional inverse ofAckermann’s function, m is the number of local-tier operations,and n is the number of threads. Moreover, the worst-case time forany operation is O(lg n).
The classical disjoint-set data structure does not work “out ofthe box” when multiple FIND-TRACE operations execute concur-rently. The reason is that although these operations are queries, thepath-compression heuristic modifies the data structure, potentiallycausing concurrent operations to interfere.8 Consequently, our im-plementation of the local tier uses the disjoint-set data structurewith union by rank only, which supports each operation in O(lg n)worst-case time.
The SP-bags implementation used by SP-hybrid follows that of[20], except that we must additionally support the SPLIT operation.At the time of a split, the subtraces U (1), U (2), and U (3) may all
8In fact, concurrent path compression does not affect the correctness ofthe algorithm, assuming that reads and writes execute atomically. The per-formance analysis become more complicated. We conjecture that a betterrunning time can be obtained using the classical data structure.
contain many threads. Thus, splitting them off from the trace Umay take substantial work. Fortunately, SP-bags overcomes thisdifficulty by allowing a split to be performed in O(1) time.
Consider the S- and P-bags at the time a thread in the procedureF is stolen and the five subtraces U (1), U (2), U (3), U (4), and U (5)
are created. The S-bag of F contains exactly the threads in the sub-trace U (1). Similarly, the P-bag of F contains exactly the threadsin the subtrace U (2). The SP-bags data structure is such that mov-ing these two bags to the appropriate subtraces requires only O(1)pointer updates. The subtrace U (3) owns all the other S- and P-bagsthat belonged to the original trace U , and thus nothing more needbe done, since U (3) directly inherits U ’s threads. The subtracesU (4) and U (5) are created with empty S- and P-bags. Thus, thesplit can be performed in O(1) time, since only O(1) bookkeepingneeds to be done including updating pointers.
6 Correctness of SP-hybrid
This section proves the correctness of the SP-hybrid algorithm. Webegin by showing that the traces maintained by SP-hybrid are con-sistent with the subtrace properties defined in Section 5. We thenprove that the traces are ordered correctly to determine SP relation-ships. Finally, we conclude that SP-hybrid works.
Due to the way the splits work, we can no longer prove a theo-rem as general as Lemma 1. That is to say, we can only accuratelyderive the relationship between two threads if one of them is a cur-rently executing thread.9 Although this result is weaker than for theserial algorithm, we do not need anything stronger for a race detec-tor. Furthermore, these are exactly the semantics provided by thelower-tier SP-bags algorithm.
The following lemma shows that when a split occurs, the sub-traces are consistent with the subtraces properties given in Sec-tion 5.
Lemma 7. Let Ui be a trace that is split around a P-node X . Then,the subtrace properties of Ui are maintained as invariants by SP-HYBRID.
Proof. The subtrace properties of Ui hold at the time of the splitaround the P-node X , when the subtraces were created, by defini-tion. If a subtrace is destroyed by splitting, the property holds forthat subtrace vacuously.
Consider any thread u at the time it is inserted into some trace U .Either U is a subtrace of Ui or not. If not, then the properties holdfor the subtrace Ui vacuously. Otherwise, we have five cases.
Case 1: U = Ui(1). This case cannot occur. Since Ui
(1) ismentioned only in lines 19–27 of Figure 8, it follows that Ui
(1) isnever passed to any call of SP-HYBRID. Thus, no threads are everinserted into Ui
(1).Case 2: U = Ui
(2). Like Case 1, this case cannot occur.Case 3: U = Ui
(3). We must show that Ui(3) = {u : u ∈ de-
scendants(left [X])}. The difficulty in this case is that when thetrace Ui is split, we have Ui = Ui
(3), that is, Ui and Ui(3) are
aliases for the same set. Thus, we must show that the invariantholds for all the already spawned instances of SP-HYBRID thattook Ui as a parameter, as well as those new instances that takeUi
(3) as a parameter. As it turns out, however, no new instancestake Ui
(3) as a parameter, because (like Cases 1 and 2) Ui(3) is
neither passed to SP-HYBRID nor returned.Thus, we are left to consider the already spawned instances
of SP-HYBRID that took Ui as a parameter. One such instanceis the outstanding SP-HYBRID(left [X], Ui) in line 13. If u ∈descendants(left [X]), then we are done, and thus, we only need
9Specifically, we cannot determine the relationship between threads inU(1) and U(2), but we can determine the relationship between any othertwo traces.
X: A thief steals here
U(1): the strands that precedes X U(2): the strands that is in parallel w/ X U(3): the strands in X's leQ subtree
(that is currently being executed by the vicim)
U(4): the strands in X's right subtree (ini$ally empty and will be populated by the thief)
U(5): the strands that follows X (ini$ally empty)
Each U(i) is a trace containing a set of strands.
Figure 11: The split of a trace U around a P-node X in terms of a canon-ical Cilk parse tree. The tree walk of U is executing in left [X] when thesubtree rooted at right [X] is stolen by a thief processor. The shaded re-gions contain the nodes belonging to each of the subtraces produced by thesplit. The two circles not enclosing any text indicate portions of the parsetree that have not yet been visited by the tree walk of U .
Figure 12: An ordering of the new traces resulting from a steal as shown inFigure 11. Each circle represents a trace.
single processor working on a trace. The FIND-TRACE operation,however, may be executed by any processor, and thus the imple-mentation must operate correctly in the face of multiple FIND-TRACE operations.
The implementation of SP-bags proposed in [20] uses the classi-cal disjoint-set data structure with “union by rank” and “path com-pression” heuristics [14, 29, 31]. On a single processor, this datastructure allows all local-tier operations to be supported in amor-tized O(α(m,n)) time, where α is Tarjan’s functional inverse ofAckermann’s function, m is the number of local-tier operations,and n is the number of threads. Moreover, the worst-case time forany operation is O(lg n).
The classical disjoint-set data structure does not work “out ofthe box” when multiple FIND-TRACE operations execute concur-rently. The reason is that although these operations are queries, thepath-compression heuristic modifies the data structure, potentiallycausing concurrent operations to interfere.8 Consequently, our im-plementation of the local tier uses the disjoint-set data structurewith union by rank only, which supports each operation in O(lg n)worst-case time.
The SP-bags implementation used by SP-hybrid follows that of[20], except that we must additionally support the SPLIT operation.At the time of a split, the subtraces U (1), U (2), and U (3) may all
8In fact, concurrent path compression does not affect the correctness ofthe algorithm, assuming that reads and writes execute atomically. The per-formance analysis become more complicated. We conjecture that a betterrunning time can be obtained using the classical data structure.
contain many threads. Thus, splitting them off from the trace Umay take substantial work. Fortunately, SP-bags overcomes thisdifficulty by allowing a split to be performed in O(1) time.
Consider the S- and P-bags at the time a thread in the procedureF is stolen and the five subtraces U (1), U (2), U (3), U (4), and U (5)
are created. The S-bag of F contains exactly the threads in the sub-trace U (1). Similarly, the P-bag of F contains exactly the threadsin the subtrace U (2). The SP-bags data structure is such that mov-ing these two bags to the appropriate subtraces requires only O(1)pointer updates. The subtrace U (3) owns all the other S- and P-bagsthat belonged to the original trace U , and thus nothing more needbe done, since U (3) directly inherits U ’s threads. The subtracesU (4) and U (5) are created with empty S- and P-bags. Thus, thesplit can be performed in O(1) time, since only O(1) bookkeepingneeds to be done including updating pointers.
6 Correctness of SP-hybrid
This section proves the correctness of the SP-hybrid algorithm. Webegin by showing that the traces maintained by SP-hybrid are con-sistent with the subtrace properties defined in Section 5. We thenprove that the traces are ordered correctly to determine SP relation-ships. Finally, we conclude that SP-hybrid works.
Due to the way the splits work, we can no longer prove a theo-rem as general as Lemma 1. That is to say, we can only accuratelyderive the relationship between two threads if one of them is a cur-rently executing thread.9 Although this result is weaker than for theserial algorithm, we do not need anything stronger for a race detec-tor. Furthermore, these are exactly the semantics provided by thelower-tier SP-bags algorithm.
The following lemma shows that when a split occurs, the sub-traces are consistent with the subtraces properties given in Sec-tion 5.
Lemma 7. Let Ui be a trace that is split around a P-node X . Then,the subtrace properties of Ui are maintained as invariants by SP-HYBRID.
Proof. The subtrace properties of Ui hold at the time of the splitaround the P-node X , when the subtraces were created, by defini-tion. If a subtrace is destroyed by splitting, the property holds forthat subtrace vacuously.
Consider any thread u at the time it is inserted into some trace U .Either U is a subtrace of Ui or not. If not, then the properties holdfor the subtrace Ui vacuously. Otherwise, we have five cases.
Case 1: U = Ui(1). This case cannot occur. Since Ui
(1) ismentioned only in lines 19–27 of Figure 8, it follows that Ui
(1) isnever passed to any call of SP-HYBRID. Thus, no threads are everinserted into Ui
(1).Case 2: U = Ui
(2). Like Case 1, this case cannot occur.Case 3: U = Ui
(3). We must show that Ui(3) = {u : u ∈ de-
scendants(left [X])}. The difficulty in this case is that when thetrace Ui is split, we have Ui = Ui
(3), that is, Ui and Ui(3) are
aliases for the same set. Thus, we must show that the invariantholds for all the already spawned instances of SP-HYBRID thattook Ui as a parameter, as well as those new instances that takeUi
(3) as a parameter. As it turns out, however, no new instancestake Ui
(3) as a parameter, because (like Cases 1 and 2) Ui(3) is
neither passed to SP-HYBRID nor returned.Thus, we are left to consider the already spawned instances
of SP-HYBRID that took Ui as a parameter. One such instanceis the outstanding SP-HYBRID(left [X], Ui) in line 13. If u ∈descendants(left [X]), then we are done, and thus, we only need
9Specifically, we cannot determine the relationship between threads inU(1) and U(2), but we can determine the relationship between any othertwo traces.
English:
Hebrew:
Upon a steal, insert into the global $er:

What We Need in a Det. Race Detector
• SP-‐Hybrid: global $er: an Order-‐Maintenance data structure maintains the series-‐parallel ordering of traces. local $er: within a single trace, query the SP-‐Bags data structure.
• Shadow space that contains: – The last writer to a loca$on v; and – The last serial reader to a loca$on v. (But we are totally dropping the parallel readers.)

Where Things Break
• The shadow memory only keeps track of the last serial reader (that the execu$on encounters), which is insufficient.
Lemma 2: Let strands e1, e2, and e3 execute serially in order. If e1 ≺ e2 and e1 ‖ e3, then e2 ‖ e3. Lemma 3 [Pseudotransi?vity of ‖] : Let strands e1, e2, and e3 execute serially in order. If e1 ‖ e2 and e2 ‖ e3, then e1 ‖ e3.
Recall the lemmas we need to show that SP-‐Bags algorithm works correctly:
Ques?on: When execu?ng in parallel, what do we need to maintain in the shadow space?

Ex: Keeping One Reader Is Not Enough
Recall how to update shadow memory: • write loca@on v by procedure F:
writer[v] ⟵ F; (Always update writer)
• read loca@on v by procedure F: if (Find-‐set(reader[v]) is an S-‐bag then reader[v] ⟵ F;
(Replace only serial reader)
e1:r e2:r
e3:w
Say e1, e2, and e3 executed in that order in parallel execu$on. Say e1 and e2 read v and e3 wrote to v.
When e3 executes, reader[v] contains e1 , since e1 ‖ e2 . We miss a race!
What if we always update the reader[v] with the last reader?

Ex: Keeping One Reader Is Not Enough
Recall how to update shadow memory: • write loca@on v by procedure F:
writer[v] ⟵ F; (Always update writer)
• read loca@on v by procedure F: if (Find-‐set(reader[v]) is an S-‐bag then reader[v] ⟵ F;
(Replace only serial reader)
e1:r e2:r e3:w
Say e1, e2, and e3 executed in that order in parallel execu$on. Say e1 and e2 read v and e3 wrote to v.
When e3 executes, reader[v] contains e1 , since e1 ‖ e2 . We miss a race!
What if we always update the reader[v] with the last reader?
Then when e3 executes, reader[v] contains e2 and we can s$ll miss a race!

Keeping two readers
It turns out that, it's sufficient to keep two readers -‐-‐-‐ we just need to keep track of the "leQ-‐most" Rl and "right-‐most" reader Rr for each memory loca$on v.
When e reads v: if e comes before Rl[v] in serial order, or e ≺ Rl[v]
Rl[v] = e if e comes aQer Rr[v] in serial order, or Rr[v] ≺ e
RR[v] = e

References [1] Nondeterminator and SP-‐Bags algorithms: Efficient Detec.on of Determinacy Races in Cilk Programs by Mingdong Feng and Charles E. Leiserson. IN Proceedings of the Ninth Annual ACM Symposium on Parallel Algorithms and Architectures (SPAA), 1997 [2] On parallel race detec@on in Cilk computa@ons: On-‐the-‐Fly Maintenance of Series-‐Parallel Rela.onships in Fork-‐Join Mul.threaded Programs by Michael A. Bender, Jeremy T. Fineman, Seth Gilbert, and Charles E. Leiserson. In Proceedings of the Sixteenth ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), 2004.
[3] Race detec@on using English-‐Hebrew labeling scheme: Tools for the Efficient Development of Efficient Parallel Programs by Itzhak Nudler and Larry Rudolph. In Proceedings of the First Israeli Conference on Computer Systems Engineering, 1986. [4] Keeping two readers for parallel race detec@on in fork-‐join mul@threaded programs: On-‐the-‐Fly Detec.on of Data Races for Programs with Nested Fork-‐Join Parallelism by John Mellor-‐Crummey. In Proceedings of Supercompu$ng, 1991.


















