
Connecting Hadoop and Oracle - DOAG Deutsche ORACLE ... · gluent.com 1 Connecting Hadoop and...
41
1 Connecting Hadoop and Oracle Tanel Poder a long time computer performance geek
Transcript of Connecting Hadoop and Oracle - DOAG Deutsche ORACLE ... · gluent.com 1 Connecting Hadoop and...

gluent.com 1
ConnectingHadoopandOracle
TanelPoderalongtimecomputerperformancegeek

gluent.com 2
Intro:Aboutme
• TanelPõder• OracleDatabasePerformancegeek(18+years)• ExadataPerformancegeek• LinuxPerformancegeek• HadoopPerformancegeek
• CEO&co-founder:
ExpertOracleExadatabook
(2nd editionisoutnow!)
Instantpromotion

gluent.com 3
Theworldischanging.

gluent.com 4
GluentOracle
TeradataNoSQL
BigDataSources
MSSQL
AppX
AppY
AppZ
Gluentasadatavirtualizationlayer
OpenDataFormats!

gluent.com 5
GluentAdvisor(DatabaseOffload)
1. Analyzes DBstorageuseandaccesspatternsforsafeoffloading
2. 500+Databasesanalyzed
3. 10+PB analyzed– 81% offloadable
4. 2-24x queryspeedup
10PBInterestedinanalyzingyourdatabase?

gluent.com 6
WhyHadoop?

gluent.com 7
WhyHadoop?
• ScalabilityinSoftware!
• OpenDataFormats• Future-proof!
• OneData,ManyEngines!
Hive Impala Spark Presto Giraph
SQL-on-Hadoopisonlyoneofmanyapplicationsof
Hadoop
GraphProcessingFulltextsearchImageProcessingLogprocessing
Streams

gluent.com 8
All processingcanbeclosetodata!
• OneofthemantrasofHadoop:• "Movingcomputationischeaperthanmovingdata"
• Hadoopdataprocessingframeworks hidethecomplexityofplacingthecomputationofdataontheirlocal(orclosest)clusternodes• Nosuper-expensiveinterconnectnetwork,MPI&schedulingcomplexity• Noneedforsharedstorage(expensiveSAN+StorageArrays!)
• Nowyoucanbuildasupercomputerfromcommoditypizzaboxes!
Node1+disks
Node2+disks
Node3+disks
Node4+disks
Node5+disks
Node6+disks
Node...+disks
NodeN+disks
Yourcode
Yourcode
Yourcode
Yourcode
Yourcode
Yourcode
Yourcode
Yourcode
Distributedparallelexecutionframework Impala,Hive,Spark, HBase/coproc.etc…
YourCode

gluent.com 9
OneData,ManyEngines!
• Decouplingstoragefromcompute+opendataformats=flexiblefuture-proofdatasystems!
HDFS
Parquet Avro XML CSV
AmazonS3
Parquet WebLog
Kudu
Column-store
ImpalaSQLHive Xyz…
Solr /Search SparkMR
libkudulibparquet

gluent.com 10
3majorbigdataplumbingscenarios
1. Load datafromHadooptoOracle
2. Offload datafromOracletoHadoop
3. Query HadoopdatainOracle
Abigdifferencebetweendatacopy andon-
demanddataquery tools

gluent.com 11
UseCase:MoveDatato/fromHadoop:Sqoop
• AparallelJDBC<->HDFSdatacopy tool• Apache2.0licensed(likemostotherHadoopcomponents)• GeneratesMapReducejobsthatconnecttoOraclewithJDBC
OracleDB
MapReduceMapReduceMapReduceMapReduce JDBC
SQOOP
file
Hadoop/HDFSfilefile
file
file
Hivemetadata

gluent.com 12
Example:CopyDatatoHadoopwithSqoop
• Sqoopis"just"aJDBCDBclientcapableofwritingtoHDFS• Itisveryflexible
sqoop import --connect jdbc:oracle:thin:@oel6:1521/LIN112 --username system--null-string '' --null-non-string '' --target-dir=/user/impala/offload/tmp/ssh/sales--append -m1 --fetch-size=5000 --fields-terminated-by '','' --lines-terminated-by ''\\n'' --optionally-enclosed-by ''\"'' --escaped-by ''\"'' --split-by TIME_ID --query "\"SELECT * FROM SSH.SALES WHERE TIME_ID < TO_DATE('
1998-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS','NLS_CALENDAR=GREGORIAN') AND \$CONDITIONS\""
Justanexampleofsqoopsyntax

gluent.com 13
Sqoopusecases
1. CopydatafromOracletoHadoop• Entireschemas,tables,partitionsoranySQLqueryresult
2. CopydatafromHadooptoOracle• ReadHDFSfiles,converttoJDBCarraysandinsert
3. Copychangedrows fromOracletoHadoop• SqoopsupportsaddingWHEREsyntaxtotablereads:• WHERE last_chg > TIMESTAMP'2015-01-10 12:34:56'
• WHERE ora_rowscn > 123456789

gluent.com 14
SqoopwithOracleperformanceoptimizations- 1
• IscalledOraOOP• WasaseparatemodulebyGuyHarrisonteamatQuest(Dell)• IncludedinstandardSqoopv1.4.5+ andSqoop2comingtoo!
• sqoop import direct=true …
• ParallelSqoopOraclereadsdonebyblockrangesorpartitions• Previouslyrequiredwideindexrangescans toparallelizeworkload
• ReadOracledatawithfulltablescans anddirectpathreads• MuchlessIO,CPU,buffercacheimpactonproductiondatabases

gluent.com 15
SqoopwithOracleperformanceoptimizations- 2
• DataloadingintoOracleviadirectpathinsert ormerge• Bypassbuffercacheandmostredo/undogeneration
• HCCcompressionon-the-flyforloadedtables• ALTER TABLE fact COMPRESS FOR QUERY HIGH
• Allfollowingdirectpathinsertswillbecompressed
• Sqoopisprobablythebesttoolfordatacopy/move usecase• Forbatchdatamovementneeds• IfusedwiththeOracleoptimizations

gluent.com 16
Whataboutreal-timechangereplication?
• OracleChangeDataCapture• Supportedin11.2– butnotrecommendedbyOracleanymore• Desupportedin12.1
• OracleGoldenGateorDBVisitReplicate
• Somemanualwork/scriptinginvolvedwithallthesetools:
1. SqoopthesourcetablesnapshotstoHadoop2. Replicatechangesto"delta"tablesonHDFSorinHBase3. Usea"merge"viewonHive/Impalatomergebasetable withdelta

gluent.com 17
“Applying”updates/changesinHadoop
• HDFSfilesareappend-only bydesign(scalabilityreasons)• NorandomwritesorchangingofexistingHDFSfiledata
• Basetable+deltatableapproach1. Abasetable containsoriginal(batchoffloaded)data2. Adeltatable containsanynewversionsofdata3. Amergeview performsanouterjointoshowlatestdatafrombase
tableordeltatable(ifany)4. Optional“compaction”– mergingbase+delta togetherinbackground
• HiveACIDtransactionsusethisapproachunderthehood• Cloudera’sKUDU projectusessimilarconceptwithoutHDFS
• …butdeltascanbeinmemoryandstoredinflash(ifavailable)

gluent.com 18
References:IncrementaldataupdatesinHadoop
• Cloudera(Impala)• http://blog.cloudera.com/blog/2015/11/how-to-ingest-and-query-
fast-data-with-impala-without-kudu/
• Cloudera(Kudu)• https://blog.cloudera.com/blog/2015/09/kudu-new-apache-hadoop-
storage-for-fast-analytics-on-fast-data/
• Hortonworks (Hive)• http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-
2.3.0/bk_dataintegration/content/incrementally-updating-hive-table-with-sqoop-and-ext-table.html

gluent.com 19
UseCase:Query Hadoopdataasifitwasin(Oracle)RDBMS
Theultimategoal(formeatleast:)
• LowcostandscalabilityofHadoop…
• …togetherwiththesophisticationofOracleSQLengine
• Keepusingyourexisting(Oracle)applicationswithoutre-engineering&rewritingSQL

gluent.com 20
WhatdoSQLqueriesdo?
1. Retrievedata
2. Processdata
3. Returnresults
DiskreadsDecompressionFilteringColumnextraction&pruning
JoinParalleldistributeAggregateSort
FinalresultcolumnprojectionSenddatabackovernetwork…ordumptodisk

gluent.com 21
Howdoesthequeryoffloadingwork?(Ext.tab)
-----------------------------------------------------------| Id | Operation | Name |-----------------------------------------------------------
| 0 | SELECT STATEMENT | || 1 | SORT ORDER BY | ||* 2 | FILTER | || 3 | HASH GROUP BY | ||* 4 | HASH JOIN | ||* 5 | HASH JOIN | ||* 6 | EXTERNAL TABLE ACCESS FULL| CUSTOMERS_EXT |
|* 7 | EXTERNAL TABLE ACCESS FULL| ORDERS_EXT || 8 | EXTERNAL TABLE ACCESS FULL | ORDER_ITEMS_EXT |-----------------------------------------------------------
Dataretrievalnodes
Dataprocessingnodes
• Dataretrieval nodesdowhattheyneedtoproducerows/cols• ReadOracledatafiles,readexternaltables,callODBC,readmemory
• Intherestoftheexecutionplan,everythingworksasusual

gluent.com 22
Howdoesthequeryoffloadingwork?
Dataretrievalnodesproducerows/columns
Dataprocessingnodesconsumerows/columns
Dataprocessing nodesdon'tcarehowandwheretherowswerereadfrom,thedataflowformatisalwaysthesame.

gluent.com 23
Howdoesthequeryoffloadingwork?(ODBC)
--------------------------------------------------------| Id | Operation | Name | Inst |IN-OUT|
--------------------------------------------------------| 0 | SELECT STATEMENT | | | || 1 | SORT ORDER BY | | | |
|* 2 | FILTER | | | || 3 | HASH GROUP BY | | | ||* 4 | HASH JOIN | | | ||* 5 | HASH JOIN | | | |
| 6 | REMOTE | orders | IMPALA | R->S || 7 | REMOTE | customers | IMPALA | R->S || 8 | REMOTE | order_items | IMPALA | R->S |
--------------------------------------------------------Remote SQL Information (identified by operation id):----------------------------------------------------
6 - SELECT `order_id`,`order_mode`,`customer_id`,`order_status` FROM `soe`.`orders` WHERE `order_mode`='online' AND `order_status`=5 (accessing 'IMPALA.LOCALDOMAIN' )
7 – SELECT `customer_id`,`cust_first_name`,`cust_last_name`,`nls_territory`,
`credit_limit` FROM `soe`.`customers` WHERE `nls_territory` LIKE 'New%' (accessing 'IMPALA.LOCALDOMAIN' )
8 - SELECT `order_id`,`unit_price`,`quantity` FROM `soe`.`order_items` (accessing'IMPALA.LOCALDOMAIN' )
Dataretrievalnodes
RemoteHadoopSQL
Dataprocessingbusinessasusual

gluent.com 24
ExampleUseCase
DataWarehouseOffload

gluent.com 25
DimensionalDWdesign
Hotnesso
fdata
DWFACTTABLESinTeraBytes
HASH(customer_id)
RANGE
(order_d
ate)
OldFactdatararelyupdated
Facttablestime-partitioned
DDDD
D
D
DIMENSIONTABLESinGigaBytes
Monthstoyearsofhistory
Aftermultiplejoinsondimensiontables–afullscanisdoneon
thefacttable
Somefilterpredicatesdirectlyonthefacttable(timerange),countrycodeetc)

gluent.com 26
DWDataOffloadtoHadoop
CheapScalableStorage(e.g HDFS+Hive/Impala)
HotDataDim.Tables
HadoopNode
HadoopNode
HadoopNode
HadoopNode
HadoopNode
ExpensiveStorage
ExpensiveStorage
Time-partitionedfacttable HotDataColdDataDim.Tables

gluent.com 27
1.CopyDatatoHadoopwithSqoop
• Sqoopis"just"aJDBCDBclientcapableofwritingtoHDFS• Itisveryflexible
sqoop import --connect jdbc:oracle:thin:@oel6:1521/LIN112 --username system--null-string '' --null-non-string '' --target-dir=/user/impala/offload/tmp/ssh/sales--append -m1 --fetch-size=5000 --fields-terminated-by '','' --lines-terminated-by ''\\n'' --optionally-enclosed-by ''\"'' --escaped-by ''\"'' --split-by TIME_ID --query "\"SELECT * FROM SSH.SALES WHERE TIME_ID < TO_DATE('
1998-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS','NLS_CALENDAR=GREGORIAN') AND \$CONDITIONS\""
Justanexampleofsqoopsyntax

gluent.com 28
2.LoadDataintoHive/Impalainread-optimizedformat
• Theadditionalexternaltablestepgivesbetterflexibilitywhenloadingintothetargetread-optimizedtable
CREATE TABLE IF NOT EXISTS SSH_tmp.SALES_ext (PROD_ID bigint, CUST_ID bigint, TIME_ID timestamp, CHANNEL_ID bigint, PROMO_ID bigint, QUANTITY_SOLD bigint, AMOUNT_SOLD bigint
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ESCAPED BY '"' LINES TERMINATED BY '\n'
STORED AS TEXTFILE LOCATION '/user/impala/offload/tmp/ssh/sales'
INSERT INTO SSH.SALES PARTITION (year) SELECT t.*, CAST(YEAR(time_id) AS SMALLINT) FROM SSH_tmp.SALES_ext t

gluent.com 29
3a.QueryDataviaaDBLink/HS/ODBC
• (I'mnotcoveringtheODBCdriverinstallandconfig here)
SQL> EXPLAIN PLAN FOR SELECT COUNT(*) FROM ssh.sales@impala;Explained.
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);--------------------------------------------------------------| Id | Operation | Name | Cost (%CPU)| Inst |IN-OUT|--------------------------------------------------------------| 0 | SELECT STATEMENT | | 0 (0)| | || 1 | REMOTE | | | IMPALA | R->S |--------------------------------------------------------------
Remote SQL Information (identified by operation id):----------------------------------------------------
1 - SELECT COUNT(*) FROM `SSH`.`SALES` A1 (accessing 'IMPALA’)
TheentirequerygetssenttoImpalathankstoOracleHeterogenous Services
gluent.com 30
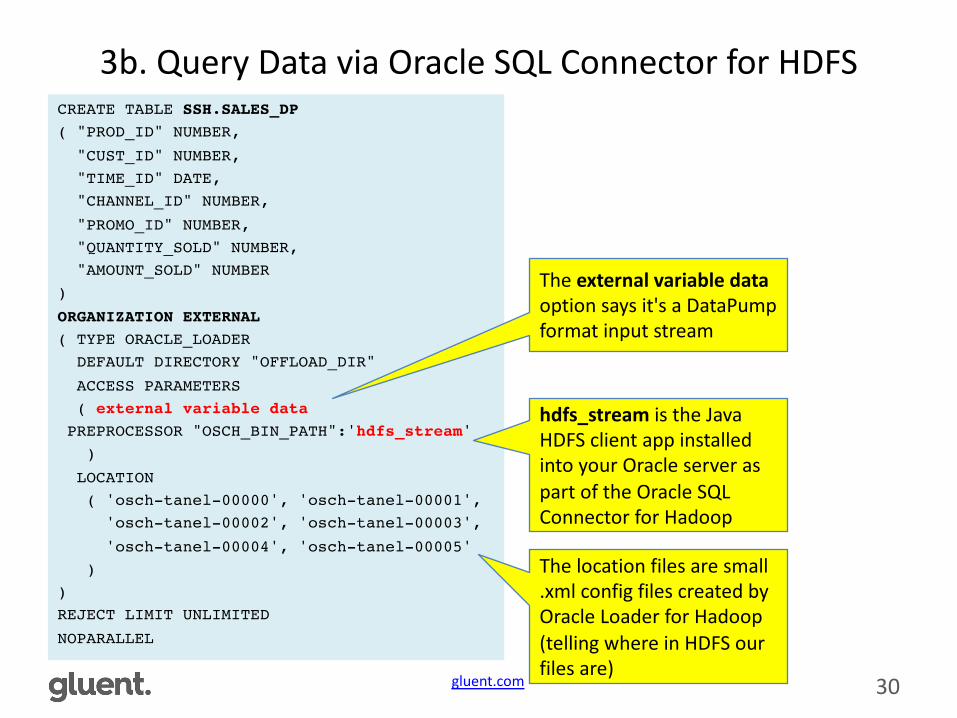
3b.QueryDataviaOracleSQLConnectorforHDFSCREATE TABLE SSH.SALES_DP( "PROD_ID" NUMBER,
"CUST_ID" NUMBER,"TIME_ID" DATE,"CHANNEL_ID" NUMBER,
"PROMO_ID" NUMBER,"QUANTITY_SOLD" NUMBER,"AMOUNT_SOLD" NUMBER
)
ORGANIZATION EXTERNAL( TYPE ORACLE_LOADER
DEFAULT DIRECTORY "OFFLOAD_DIR"
ACCESS PARAMETERS( external variable data
PREPROCESSOR "OSCH_BIN_PATH":'hdfs_stream')
LOCATION( 'osch-tanel-00000', 'osch-tanel-00001',
'osch-tanel-00002', 'osch-tanel-00003',
'osch-tanel-00004', 'osch-tanel-00005' )
)REJECT LIMIT UNLIMITED
NOPARALLEL
Theexternalvariabledataoptionsaysit'saDataPumpformatinputstream
hdfs_stream istheJavaHDFSclientappinstalledintoyourOracleserveraspartoftheOracleSQLConnectorforHadoop
Thelocationfilesaresmall.xmlconfig filescreatedbyOracleLoaderforHadoop(tellingwhereinHDFSourfilesare)

gluent.com 31
3b.QueryDataviaOracleSQLConnectorforHDFS
• ExternalTableaccessisparallelizable!• MultipleHDFSlocationfilesmustbecreatedforPX(donebyloader)
SQL> SELECT /*+ PARALLEL(4) */ COUNT(*) FROM ssh.sales_dp;
----------------------------------------------------------------------------------| Id | Operation | Name | TQ |IN-OUT| PQ Distrib |----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | || 1 | SORT AGGREGATE | | | | || 2 | PX COORDINATOR | | | | || 3 | PX SEND QC (RANDOM) | :TQ10000 | Q1,00 | P->S | QC (RAND) |
| 4 | SORT AGGREGATE | | Q1,00 | PCWP | || 5 | PX BLOCK ITERATOR | | Q1,00 | PCWC | || 6 | EXTERNAL TABLE ACCESS FULL| SALES_DP | Q1,00 | PCWP | |
----------------------------------------------------------------------------------
OracleParallelSlavescanaccessadifferentDataPumpfilesonHDFS
Anyfilterpredicatesarenotoffloaded.Alldata/columnsareread!

gluent.com 32
3c.QueryDataviaBigDataSQL
SQL> CREATE TABLE movielog_plus2 (click VARCHAR2(40))3 ORGANIZATION EXTERNAL
4 (TYPE ORACLE_HDFS5 DEFAULT DIRECTORY DEFAULT_DIR6 ACCESS PARAMETERS (7 com.oracle.bigdata.cluster=bigdatalite8 com.oracle.bigdata.overflow={"action":"truncate"}9 )10 LOCATION ('/user/oracle/moviework/applog_json/')
11 )12 REJECT LIMIT UNLIMITED;
• Thisisjustonesimpleexample:
ORACLE_HIVEwoulduseHivemetadatatofigureoutdatalocationandstructure(butstoragecellsdothediskreadingfromHDFSdirectly)

gluent.com 33
4.GluentQueryperformancewin! OracleonlyqueryCPU
SamequerywithGluent
GluentpushesCPUheavy-liftingtoHadoop
Demovideoavailableathttp://gluent.com/request-a-demo/

gluent.com 34
Howtoquerythefulldataset?
• UNIONALL• LatestpartitionsinOracle:(SALEStable)• OffloadeddatainHadoop:(SALES@impala orSALES_DP ext tab)
SELECT PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, PROMO_ID, QUANTITY_SOLD, AMOUNT_SOLD
FROM SSH.SALESWHERE TIME_ID >= TO_DATE(' 1998-07-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
UNION ALL
SELECT "prod_id", "cust_id", "time_id", "channel_id", "promo_id", "quantity_sold", "amount_sold"
FROM SSH.SALES@impalaWHERE "time_id" < TO_DATE(' 1998-07-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')
CREATE VIEW app_reporting_user.SALES AS

gluent.com 35
Hybridtablewithselectiveoffloading
CheapScalableStorage(e.g HDFS+Hive/Impala)
HotDataDim.Tables
HadoopNode
HadoopNode
HadoopNode
HadoopNode
HadoopNode
ExpensiveStorage
TABLEACCESSFULLEXTERNALTABLEACCESS/DBLINK
SELECT c.cust_gender, SUM(s.amount_sold)
FROM ssh.customers c, sales_v s
WHERE c.cust_id = s.cust_idGROUP BY c.cust_gender
SALESunion-allviewHASHJOIN
GROUPBY
SELECTSTATEMENT

gluent.com 36
PartiallyOffloadedExecutionPlan--------------------------------------------------------------------------| Id | Operation | Name |Pstart| Pstop | Inst |--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | || 1 | HASH GROUP BY | | | | ||* 2 | HASH JOIN | | | | || 3 | PARTITION RANGE ALL | | 1 | 16 | || 4 | TABLE ACCESS FULL | CUSTOMERS | 1 | 16 | || 5 | VIEW | SALES_V | | | || 6 | UNION-ALL | | | | |
| 7 | PARTITION RANGE ITERATOR| | 7 | 68 | || 8 | TABLE ACCESS FULL | SALES | 7 | 68 | || 9 | REMOTE | SALES | | | IMPALA |--------------------------------------------------------------------------
2 - access("C"."CUST_ID"="S"."CUST_ID")
Remote SQL Information (identified by operation id):----------------------------------------------------
9 - SELECT `cust_id`,`time_id`,`amount_sold` FROM `SSH`.`SALES` WHERE `time_id`<'1998-07-01 00:00:00' (accessing 'IMPALA' )

gluent.com 37
Performance
• VendorX:"WeloadNTerabytesperhour"
• VendorY:"WeloadNBillionrowsperhour"
• Q:Whatdatatypes?• SomuchcheapertoloadfixedCHARs• …butthat'snotwhatyourrealdatamodellookslike.
• Q:Howwiderows?• 1widevarchar column or500numericcolumns?
• DatatypeconversionisCPUhungry!
Makesureyouknowwhereinstackyou'llbepayingtheprice
Andisitonceoralwayswhenaccessed?

gluent.com 38
Performance:DataRetrievalLatency
• Cloudera Impala• Lowlatency(subsecond)
• Hive• WaituntilHive2.0isavailable(HortonworksHDP2.5- Q32016)• Hive2.0interactivequerieswithLLAP(LiveLongandProcess)• Otherwiseyou'llwaitforjobsandJVMstostartupforeveryquery• WithLLAP,JVMcontainerswillnotbestartedforsimplescans/filters
• OracleSQLConnectorforHDFS• Multi-secondlatencyduetohdfs_streamJVMstartup
• OracleBigDataSQL• Lowlatencythanksto"ExadatastoragecellsoftwareonHadoop"
Timetofirstrow/byte

gluent.com 39
BigDataSQLPerformanceConsiderations
• Onlydataretrieval (theTABLEACCESSFULLetc)isoffloaded!• Scanning,filtering,projectionpushdown
• Alldataprocessing stillhappensintheDBlayer(onDBCPUs)• GROUPBY,JOIN,ORDERBY,AnalyticFunctions,PL/SQLetc
• JustlikeonExadata…• Storagecellsonlyspeedupdataretrieval

gluent.com 40
Q&A

gluent.com 41
Thanks!
Weliberateenterprisedata!http://gluent.com
Also,theusual:
http://[email protected]


















