
Conf2014_SplunkSearchOptimization
50
Copyright © 2014 Splunk Inc. Julian Harty SE, Splunk> Search Op@miza@on in 500 easy steps
-
Upload
splunk -
Category
Technology
-
view
847 -
download
2
Transcript of Conf2014_SplunkSearchOptimization

Copyright © 2014 Splunk Inc.
Julian Harty SE, Splunk>
Search Op@miza@on in 500 easy steps

Disclaimer
2
During the course of this presenta@on, we may make forward looking statements regarding future events or the expected performance of the company. We cau@on you that such statements reflect our current expecta@ons and
es@mates based on factors currently known to us and that actual events or results could differ materially. For important factors that may cause actual results to differ from those contained in our forward-‐looking statements,
please review our filings with the SEC. The forward-‐looking statements made in the this presenta@on are being made as of the @me and date of its live presenta@on. If reviewed aSer its live presenta@on, this presenta@on may not contain current or accurate informa@on. We do not assume any obliga@on to update any forward looking statements we may make. In addi@on, any informa@on about our roadmap outlines our general product direc@on and is subject to change at any @me without no@ce. It is for informa@onal purposes only and shall not, be incorporated into any contract or other commitment. Splunk undertakes no obliga@on either to develop the features or func@onality described or to
include any such feature or func@onality in a future release.

Am I in the right Session… and Who is this guy?
3
Goal of Presenta:on: Search Op:miza:on • How the hell do I speed this search up?
Background of your Presenter: Julian Harty • Splunker for 2+ Years -‐ Variety of installa@ons from 10GB to 100TB’s+
• Ex-‐Oracle/MySQL DBA (Recovering) • Contact info [email protected]

Background – Great to Not So Great Growth without op@miza@on = subop@mal performance
-‐> our goal: gejng great performance at scale
4
• More Data • More Users • New Searches • Even More Data
• Even More Users • Even More Searches…
Op@miza@on Steps

Challenge – Why so slow? The maturity of a Splunk deployment
5
Question? Is your environment tuned correctly?
Question? Has your deployment been architected correctly?
Question? Are your searches optimized?
Solution: Architecting And Designing Your Splunk Deployment - Simeon Yep
Solution: Jiffy Lube Quick Tune Up For Your Splunk Environment – Sean Delaney
Solution: Welcome to this session!!!

Agenda: Objec@ves of this Session
6
• The Basics: • Common pinalls -‐ Best prac@ces and what not to do • Take away: Basic steps to a beoer search
• Beyond the Basics: • Search Architecture and Workflow • Detailed Search review – using Job inspector search examples • Take away: Job Inspector Cheat-‐Sheet
• Q&A

Iden@fying Poorly Performing Searches

End User Enquiries
8

SOS – Expensive Searches Search Ac@vity, Usage Paoerns
-‐> SOS –> Search -‐> Search Detail Ac@vity -‐> Expensive Searches
9

For Splunk 6.2 Users – _Introspec@on Index
10

Search Tuning – The Basics

The Basics: Common Search Behavior
12
> be=selec@ve AND be=specific | …
Narrow @me range
> foo bar
> host=web sourcetype=access*
Use Summary Indexing
Use Report Accel or Summary Indexing
Use Fast/Smart Mode where Possible
Bad Behavior Good Behavior
Performance Improvement
Comment
index=xyz 10-‐50% Index and default fields source=www
-‐24h@h 365x 30x Limit Time Range
> foo bar 30% Combine Searches
Fast/Smart 20-‐50% Fast Mode A AND C AND D AND E 5-‐50% Avoid NOTS
Data Models and Report Accelera@on
Summary Indexing
All Time Searches
>*
> foo | search bar
Verbose Mode
Use Intelligently
Use Sparingly
1000%
1000%
Searches over large datasets Searches over long periods
A NOT B

The Basics: Common Op@miza@on Mistakes
13
• Summary indexing is Awesome! – Ini@al reac@on -‐ Summarize EVERYTHING!!!
ê Summarizing too much data negates the point
• Report Accelerate = Turbo buoon – Ini@al reac@on -‐ Report Accelerate EVERYTHING!!!
ê Too many searches = skipped search issues
• Data Models are the answer! – Ini@al reac@on – everything can be included!
ê Convoluted data models can increase workload

OK, But How can you enforce these recommenda@ons?

How do you enforce Best Prac@ces?
15
Architect Perspec:ve: • User educa@on – Best Prac@ces for Users Admin Perspec:ve: Restric@ng User Controls: Pulling in the reins • Restric@ng Role Capabili@es
• Limit index • Limit search terms • Limit search @me range
• Limi@ng Power user role • Restrict Number of RT+ Concurrent Searches

How do you enforce Best Prac@ces?
16
Admin Perspec:ve: • Time range defaults (ui-‐prefs.conf) • Time range Web dropdown op@ons (Times.conf)

OK Now More advanced Op@miza@on: Lets start with -‐ the skinny on How Search Works…
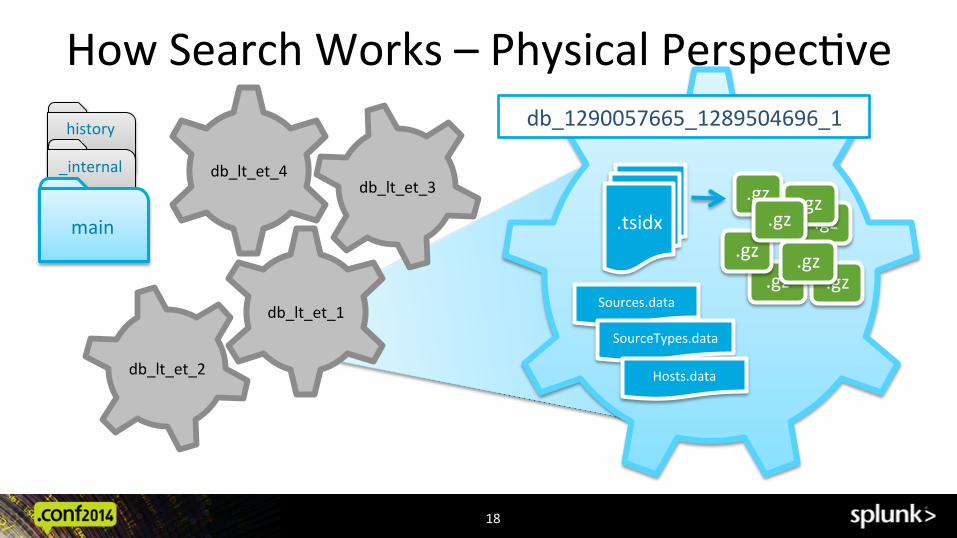
How Search Works – Physical Perspec@ve
18
db_lt_et_4
db_lt_et_2
db_lt_et_1
db_lt_et_3
.tsidx
Sources.data
SourceTypes.data
Hosts.data
.gz .gz
.gz .gz
.gz
.gz .gz
.gz
db_1290057665_1289504696_1 history
_internal
main
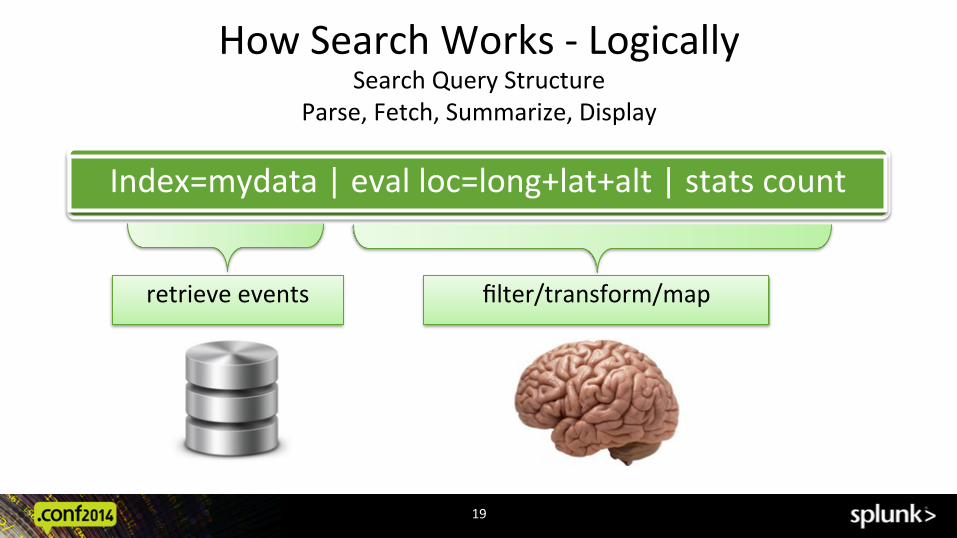
How Search Works -‐ Logically Search Query Structure
Parse, Fetch, Summarize, Display
19
Index=mydata | eval loc=long+lat+alt | stats count
retrieve events filter/transform/map

Splunk Distributed Search
20
4 Steps to a Splunk Search: Parse, Fetch, Summarize, Display
" StreamingCommand: Applies a transforma@on to search results as they travel through the processing pipeline. Eval rex where…
" Repor:ngCommand: Processes search results and generates a repor@ng data structure. Examples: stats, top, and @mechart…

Types of Searches
21
• Dense – Low cardinality – Example: sourcetype=access method=GET
• Sparse – High cardinality – Example: sourcetype=access method=GET ac@on=purchase
• Super Sparse (or Needle in a Haystack) – Very high cardinality – Example: sourcetype=cisco:asa ac@on=denied src=10.2.3.11
• Rare – Use Case: user behavior tracking – Example: sourcetype=magicsource | rare
Dense
Super Sparse
Sparse

Dense Searches (>10% matching results) (scanCount vs eventCount in Job Inspector)
22
Challenge: • CPU and I/O-‐bound
– Ini@al spike in CPU due to decompression of raw events.
– Retrieval rate: 50K events per second per server Solu:on: • Divide and conquer
– Distribute search to an indexing cluster – Parallel compute and merge results
• Report Accelera@on or use of Summaries – divide and Conquer – Report on summarized data vs. raw data
> sourcetype=access_combined method=GET

Sparse Searches
23
Challenge: • CPU-‐bound
– Dominant cost is uncompressing *.gz raw data files – Some@mes need to read far into a file to retrieve a few events
Solu:on: • Avoid cherry picking
– Be selec@ve about exclusions (avoid “NOT foo” or “field!=value”) – Leverage indexed fields
• Filter using whole terms – Instead of > sourcetype=access_combined clientip=192.168.11.*!– Use > sourcetype=access_combined clientip=TERM(192.168.11.2)!
> sourcetype=access_combined status=404

Super Sparse Searches
24
• “Needle in Haystack” • Very I/O intensive • May take up to 2 Seconds
to parse each bucket
> sourcetype=access_combined status=404 10.2.1

Rare Term Searches
25
• Bloom Filters* – Bloom filters stored in each bucket – 50-‐buckets processed per second – I/Os reduced as buckets are excluded from 100-‐200 to just a few – 50-‐100x faster than Super Sparse searches on conven@onal storage,
>1000x faster on SSD (Due to random reads)
> sourcetype=access_combined sessionID=1234
* A Bloom filter is a data structure designed to tell you whether or not an element is present in a set

How can I determine if my search is Dense or Sparse? Use Job Inspector…
26
Component Descrip:on
scanCount The number of events that are scanned or read off disk.
eventCount Number of events that are returned to base search
• For dense searches scanCount ~= eventCount. • For sparse searches, scanCount >> eventCount.
> sourcetype=access_combined status=404 81.11.191.113

Job Inspector Review

Measuring Search Using the Splunk Search Inspector
28 Copyright*©*2011,*Splunk*Inc.* Listen*to*your*data.*
*
Using*the*Search*Inspector*
3*
Timings*from*distributed*peers*
Remote*timeline*
Timings*from*the*search*command.*
Timings from distributed peers
Timings from the search command
Copyright*©*2011,*Splunk*Inc.* Listen*to*your*data.*
*
Using*the*Search*Inspector*
3*
Timings*from*distributed*peers*
Remote*timeline*
Timings*from*the*search*command.*
Key Metrics: • Comple@on Time • Number of Events
Scanned • Search SID
Job Inspector

Job Inspector Walkthrough – Search Command
29
Rawdata: Improving I/O and CPU load KV: Are field extrac@ons efficient Lookups: Used appropriately Autolookups causing issues Typer: Inefficient Evenoypes Alias: Cascading alias

Reading Job Inspector -‐ Search.Index
30
Search.index = Time to parse and read the tsidx files to determine where to read in rawdata How do you op:mize this? • Improving I/O
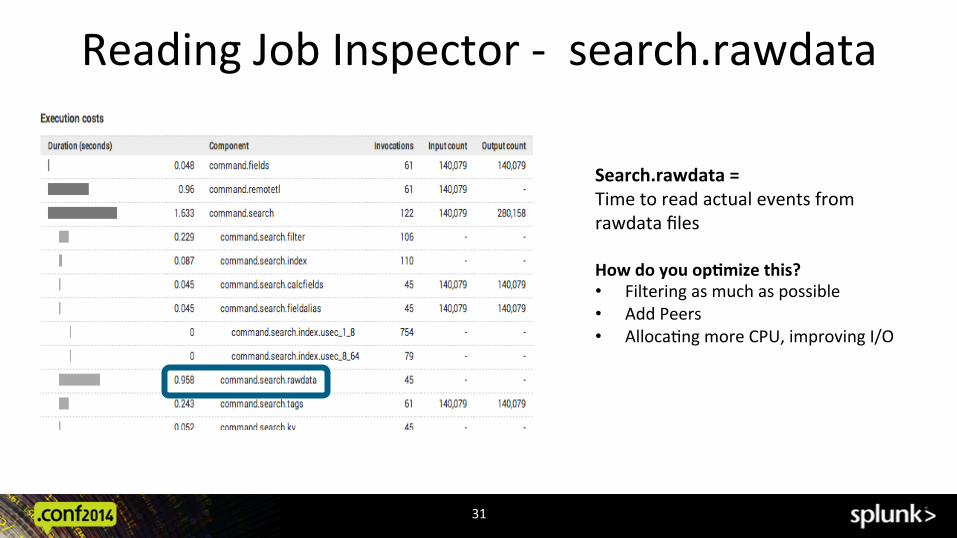
Reading Job Inspector -‐ search.rawdata
31
Search.rawdata = Time to read actual events from rawdata files How do you op:mize this? • Filtering as much as possible • Add Peers • Alloca@ng more CPU, improving I/O

Reading Job Inspector -‐ search.kv
32
Search.KV= Time taken to apply field extrac@ons to events How do you op:mize this? Regex op@miza@ons • Avoid greedy operators .*? • Use of Anchors ^ $ • Non Capturing groups for repeats

Reading Job Inspector -‐ search.lookups
33
Search.lookups = Time to apply lookups to search How do you op:mize this? • Use Appropriately (at end of search) • Autolookups maybe causing issues

Reading Job Inspector -‐ search.typer and tags
34
Search.typer = Time to apply event types to the search How do you op:mize this? • Use Appropriately • Removed unused tags and
evenoypes

Job Inspector Walkthrough – Distributed Search
35
Dispatch.createProviderQueue Time to establish connec@on with peers Dispatch.fetch Time spent wai@ng to fetch events Dispatch.evaluate The @me spent parsing the search and sejng up the data structures needed to run the search. How do you op:mize this? • Improving Peer conduc@vity • Improve Bundle replica@on • Faster storage

Job Inspector Walkthrough – Distributed Search
36
Dispatch.stream.remote Time to retrieve events from each remove peer Issue: 1. Unequal Indexer performance
• Either Hardware mismatch • Uneven distribu@on of indexes
2. AutoLB issues

Job Inspector Conclusions: Search Command Summary
37
Component Descrip:on
index look in tsidx files for where to read in rawdata
rawdata read actual events from rawdata files
kv apply fields to the events
filter filter out events that don’t match (e.g., fields, phrases)
alias rename fields according to props.conf
lookups create new fields based on exis@ng field values
typer assign evenoypes to events
tags assign tags to events

Job Inspector Conclusion: Distributed Search Summary
38
Metric Descrip:on
Area to review
createProviderQueue
The @me to connect to all search peers. Peer conduc@vity
fetch The @me spent wai@ng for or fetching events from search peers. Faster Storage
stream.remote The @me spent execu@ng the remote search in a distributed search environment, aggregated across all peers.
evaluate The @me spent parsing the search and sejng up the data structures needed to run the search.
Possible bundle issues

Addi@onal Key Logfiles related to search
39
Search log: " Stored in $SPLUNK_HOME/var/run/splunk/dispatch/ " Detailed analysis of every step taken by the search
" Search ‘stack trace’

What is the best search command to use?

Stats vs Transac@on
41
Search Goal: compute sta@s@cs on the dura@on of web session (JSESSIONID=unique iden@fier):
> | stats range(_@me) as dura@on by JSESSIONID | chart count by dura@on span=log2
> sourcetype=access_combined | transac@on JSESSIONID | chart count by dura@on
span=log2
Not so Great:
Much BeUer:

Dedup vs Latest
42
Search Goal: Return latest cart ac@on for each web site customer
> sourcetype=access* | stats latest(clien@p) by ac@on
> sourcetype=access*| dedup clien@p sortby -‐_@me |table clien@p, ac@on
Not so Great:
Much BeUer:
Note: dedup can't be used with report accelera@on

Joins and Subsearches
43
Search Goal: Return latest JESSIONID across two sourcetypes
> (sourcetype="access_combined") OR (sourcetype="applogs") | stats latest(*) as * by
JSESSIONID
> sourcetype="access_combined" | join type="inner" JSESSIONID [search sourcetype="applogs" | dedup JSESSIONID | table JSESSIONID, clien@p, othervalue]
Not so Great:
Much BeUer:

Wrap-‐up

In Closing…
45
1. Implemen@ng Architecture best prac@ces for performance at scale • With search behavior in mind…
2. Implemen@ng User Onboarding Best Prac@ces • Basic op@miza@on steps
3. Periodic Performance Review • Applying accelera@on technologies where appropriate • Removing unused searches
4. Review addi@onal sides for
• Search flow detail • Op@mizing Splunk Web

And By the way…
46
Other Sessions to look out for: • How to Actually Use Splunk Data Models -‐ David Clawson
Presented on Tuesday – Check out the session notes
• Jiffy Lube Tune-‐Up for your Splunk Deployment -‐ Sean Delaney Presented on Tuesday – Check out the session notes
• ArchitecCng and Sizing your Splunk Environment -‐ Simeon Yep
2:15-‐3:15 Today
• Splunk Search AcceleraCon Technologies – Gerald Kanapathy 10:30-‐11:30 Tomorrow
My Contact informa:on:
[email protected] @julian_Harty

THANK YOU

Take Away: Basic Steps to a beoer search
48
• Avoid use of * where ever possible.
• Avoid the use of All Time.
• Avoid subsearches searches.
• Incorporate the use default fields (source, sourcetype, host) as well as specific indexes to every search (where possible).
• Use Fast or Smart mode where possible avoid ‘Verbose’ mode.
• Use Report Accelera@on Sparingly (and Strategically) on reports on large datasets.
• Use Summary Indexing when building reports over @me spans beyond target index reten@on.
• Use Job Inspector and Search inspector to get more info (hold on for more details!!!)

A few notes on how to op@mize Splunk Web
49
| fields
Change Segmenta@on
Use Fast Mode Collapse Timeline

Search flow – Local and Distributed
50
Key Files: • Info • Status • Results • Preview
Key Flow: 1. Find which Bundle to use 2. Find Buckets to use (@me range) 3. LISPY TSIDX search 4. Process + Summarizes Events
hop://wiki.splunk.com/Community:HowDistSearchWorks

















