
AI Wolf Contest -Development of Game AI using Collective Intelligence-


Computer Chess Computer Chess A natural domain for studying AI A natural domain for studying AI
The game is well structured. Perfect information game. Early programmers and AI researchers were
often amateur chess players as well.

Brief History of Computer ChessBrief History of Computer Chess
Maelzel’s Chess MachineMaelzel’s Chess Machine
1769 Chess automaton by Baron Wolfgang von Kempelen of Austria
Appeared to automatically move the pieces on a board on top of the machine and played excellent chess.
Puzzle of the machine playing solved in 1836 by Edgar Allen Poe.

Brief History of Computer ChessBrief History of Computer ChessMaelzel’s Chess MachineMaelzel’s Chess Machine

Early 1950’sEarly 1950’s - First serious paper on computer chess was written by Claude Shannon. Described minimax search with a heuristic static evaluation function and anticipated the need for more selective search algorithms.
19561956 - Invention of alpha-beta pruning by John McCarthy. Used in early programs such as Samuel’s checkers player and Newell, Shaw and Simon’s chess program.
Brief History of Computer ChessBrief History of Computer Chess

19821982 - Development of Belle by Condon and Thomson. Belle - first machine whose hardware was specifically designed to play chess, in order to achieve speed and search depth.
19971997 - Deep Blue machine was the first machine to defeat the human world champion, Garry Kasparov, in a six-game match.
Brief History of Computer ChessBrief History of Computer Chess

CheckersCheckers
19521952 - Samuel developed a checkers program that learned its own evaluation through self play.
19921992 - Chinook (J. Schaeffer) wins the U.S Open. At the world championship, Marion Tinsley beat Chinook.

OthelloOthello
Othello programs better than the best humans. Large number of pieces change hands in each
move. Best Othello program today is Logistello (Michael
Buro).

BackgammonBackgammon
Unlike the above games backgammon includes a roll of the dice, introducing a random element.
Best backgammon program TD -gammon(Gerry Tesauro). Comparable to best human players today.
Learns an evaluation function using temporal-difference.

Card gamesCard games In addition to a random element there is hidden
information introduced. Best bridge GIB (M.Ginsberg) Bridge games are not competitive with the best
human players. Poker programs are worse relative to their human
counterparts. Poker involves a strong psychological element
when played by people.


Other games - SummaryOther games - Summary
The greater the branching factor the worse the performance.
Go - branching factor 361 very poor performance. Checkers - branching factor 4 - very good performance.
Backgammon - exception. Large branching factor still gets good results.

Brute-Force SearchBrute-Force Search
We begin considering a purely brute-force approach to game playing.
Clearly, this will only be feasible for small games, but provides a basis for further discussions.
Example - 5-stone NimExample - 5-stone Nim
played with 2 players and pile of stones. Each player removes one or two stones from the pile. player who removes the last stone wins the game.
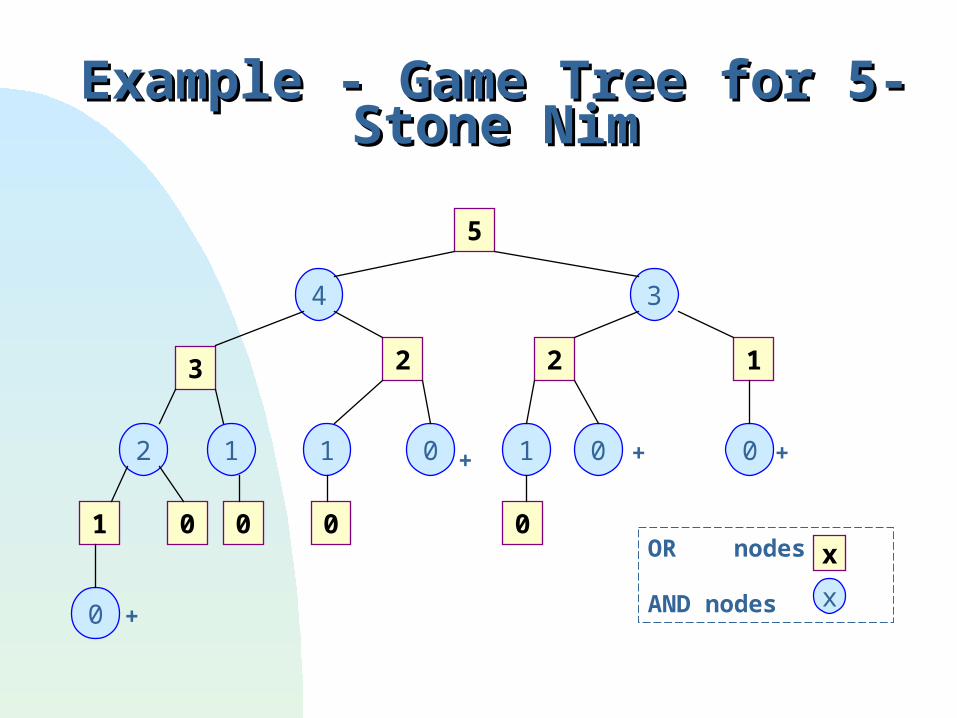
Example - Game Tree for 5-Stone NimExample - Game Tree for 5-Stone Nim
5
4 3
3 2 2 1
2 1 1 0 1 0 0
1 0 0 0 0
0
OR nodes
AND nodes
x
x+
+ + +

MinimaxMinimax
Minimax theoremMinimax theorem - Every two-person zero-sum game is a forced win for one player, or a forced draw for either player, in principle these optimal minimax strategies can be computed.
Performing this algorithm on tic-tac-toe results in the root being labeled a draw.

A strategy
A strategy is a method which tells the player how to play in each possible scenario.
Can be described implicit or explicit An explicit strategy is a subtree of the search
tree which branches only at the opponent moves.
The size of the subtree b^d/2

Example - strategy for 5-Stone NimExample - strategy for 5-Stone Nim
5
4 3
3 2 2 1
2 1 1 0 1 0 0
1 0 0 0 0
0
OR nodes
AND nodes
x
x+
+ + +

MinMax propgation
Start from the leaves. At each step, evaluate the value of all
descendants: take the maximum if it is A’s turn, or the
minimum if it is B’s turn The result will be the value of the tree.

Illustration of MinMax principle


Heuristic Evaluation FunctionsHeuristic Evaluation Functions
ProblemProblem: How to evaluate positions, where brute force is out of the question?
SolutionSolution: Use a heuristic static evaluationheuristic static evaluation functionfunction to estimate the merit of a position when the final outcome has not yet been determined.

Example of heuristic FunctionExample of heuristic Function
ChessChess : Number of pieces on board of each type multiplied
by relative value summed up for each color. By subtracting the weighted material of the black player from the weighted material of the white player we receive the relative strength of the position for each player.

A heuristic static evaluation function for a two player game is a function from a state to a number.
The goal of a two player game is to reach a winning state, but the number of moves required to get there is unimportant.
Other features must be taken into account to get to an overall evaluation function.
Heuristic Evaluation FunctionsHeuristic Evaluation Functions

Given a heuristic static evaluation function, it is straightforward to write a program to play a game.
From any given position, we simply generate all the legal moves, apply our static evaluator to the position resulting from each move, and then move to the position with the largest or smallest evaluation, depending if we are MIN/MAX
Heuristic Evaluation FunctionsHeuristic Evaluation Functions

Example - tic-tac-toeExample - tic-tac-toeBehavior of Evaluation FunctionBehavior of Evaluation Function
Detect if game over.
If X is the Maximizer, the function should return if there are three X’s in a row and - if there are three O’s in a row.
Count of the number of different rows, columns, and diagonals occupied by O.

Example: First moves of tic-tac-toeExample: First moves of tic-tac-toe
X
XX
3-03-0 = = 334-04-0==44 2-02-0 = = 22

This algorithm is extremely efficient, requiring time that is only linear in the number of legal moves.
It’s drawback is that it only considers immediate consequences of each move (doesn’t look over the horizon).
Example - tic-tac-toeExample - tic-tac-toeBehavior of Evaluation FunctionBehavior of Evaluation Function

Minimax SearchMinimax Search
Where does X go?
1 0 1 0 -1 -1 0 -1 0 -2
X X X
4-34-3 = = 11 4-24-2 = = 22

Minimax searchMinimax search Search as deeply as possible given the computational
resources of the machine and the time constraints on the game.
Evaluate the nodes at the search frontier by the heuristic function.
Where MIN is to move, save the minimum of it’s children’s values. Where MAX is to move, save the maximum of it’s children’s values.
A move is made to a child of the root with the largest or smallest value, depending on whether MAX or MIN is moving.

Minimax searchMinimax search example Minimax Tree
4
4 141413121121019876235
1412218624
14284
24
MAX
MIN

Nash equilibriumNash equilibrium:
Once an agreement has been reached, it is not worthwhile for any of the players to deviate from that agreement given that the other players do not deviate.
Example: The market place: agreement: no one sells a hot dog for less than 10$ Is it worthwhile for me to reduce the price?? No, they will burn my stand.

Example: prisoners dilemma
quite
quite rat
rat3
3
11
03
30
quite
quite rat
rat3
3
11
dead3
3dead
equilibrium No equilibrium
Should the prisoner “rat” on his friend?

Nash equilibrium The principal branch values are in Nash equilibrium
4
4 141413121121019876235
1412218624
14284
24
MAX
MIN

Alpha-Beta PruningAlpha-Beta Pruning
By using alpha-beta pruning the minimax value of the root of a game tree can be determined without having to examine all the nodes.

Alpha-Beta Pruning ExampleAlpha-Beta Pruning Example
4
4 217635
<=2<=16<=34
<=2>=64
24
a
b
og
rl pkhfe
c
d j
i
q
n
m
MAX
MIN

Alpha-BetaAlpha-Beta
Deep pruning - Right half of tree in example.
Next slide code for alpha-beta pruning :
MAXIMINMAXIMIN - assumes that its argument node is a maximizing node.
MINIMAXMINIMAX - the same.
V(N)V(N) - Heuristic static evaluation of node N.

MAXIMIN ( node: N ,lowerbound : alpha ,upperbound: beta)
IF N is at the search depth, RETURN V(N)
FOR each child Ni of N
value = MINIMAX(Ni,alpha,beta)
IF value > alpha , alpha := value
IF alpha >= beta ,return alpha
RETURN alpha
MINIMAX ( node: N ,lowerbound : alpha ,upperbound: beta)
IF N is at the search depth, RETURN V(N)
FOR each child Ni of N
value = MAXIMIN(Ni,alpha,beta)
IF value < beta , beta := value
IF beta <= alpha, return alpha
RETURN beta

Performance of Alpha-BetaPerformance of Alpha-Beta
Efficiency depends on the order in which the nodes are encountered at the search frontier.
Optimal - b½ - if the largest child of a MAX node is generated first, and the smallest child of a MIN node is generated first.
Worst - b.
Average b¾ - random ordering.

Games with chance chance nodes: nodes where chance events
happen (rolling dice, flipping a coin, etc) Evaluate expected value by averaging outcome
probabilities: C is a chance node P(di) probability of rolling di (1,2, …, 12)
S(C,di) is the set of positions generated by applying all legal moves for roll di to C


Games with chance
Backgammon board

Search tree with probabilities MAX
MIN
2 4 7 4 6 0 5 -2
0.5 0.50.5 0.5
2 4 0 -2
3 -1

Search tree with probabilities

Additional EnhancementsAdditional Enhancements
A number of additional improvements have been developed to improve performance with limited computation.
We briefly discuss the most important of these below.

Node OrderingNode Ordering
By using node ordering we can get close to b½ .
Node ordering instead of generating the tree left-to-right, we reorder the tree based on the static evaluations of the interior nodes.
To save space only the immediate children are reordered after the parent is fully expanded.

Iterative DeepeningIterative Deepening
Another idea is to use iterative deepening. In two player games using time, when time runs out, the move recommended by the last completed iteration is made.
Can be combined with node ordering to improve pruning efficiency. Instead of using the heuristic value we can use the value from previous iteration.

QuiescenceQuiescence
Quiescence search is to make a secondary search in the case of a position whose values are unstable.
This way obtains a stable evaluation.

Transposition TablesTransposition Tables
For efficiency, it is important to detect when a state has already been searched.
In order to detect a searched state, previously generated game states, with their minimax values are saved into a transposition tabletransposition table.

Opening BookOpening Book
Most board games start with the same initial state.
A table of good initial moves is used, based on human expertise, known as an opening bookopening book.

Endgame DatabasesEndgame Databases
A database of endgame moves, with minimax values, is used.
In checkers, endgame for less than eight or fewer pieces on board.
A technique for calculating endgame databases, retrograde analysis.

Special Purpose HardwareSpecial Purpose Hardware
The faster the machine ,the deeper the search in the time available and the better it plays.
The best machines today are based on special-purpose hardware designed and built only to play chess.

Selective SearchSelective Search
The fundamental reason that humans are competitive with computers is that they are very selectiveselective in their choice of positions to examine, unlike programs which do full-widthfull-width fixed depthfixed depth searches.
Selective search: to search only on a “interesting” domain.
ExampleExample - Best first minimax.

Best First MinimaxBest First Minimax
Given a partially expanded minimax tree, the backed up minimax value of the root is determined by one of the leaf nodes, as is the value of every node on the path from the root to that leaf.
This path is known as principal variationprincipal variation, and the leaf is known as principal leafprincipal leaf.
In general, the best-first minimax will generate an unbalanced tree, and make different move decisions than full-width-fixed-depth alpha-beta.

Best First minimax search- Best First minimax search- ExampleExample
6
64
Principal leaf -
expand it

Best First minimax search- Best First minimax search- ExampleExample
4
24
5 2Principal leaf -
expand it

Best First minimax search- Best First minimax search- ExampleExample
2
21
5 28 1
Principal leaf -
expand it

Best First minimax search- Best First minimax search- ExampleExample
5
51
5 78 1
73

Best First searchBest First search
Full width search is a good insurance against missing a move (and making a mistake).
Most game programs that use selective searches use a combined algorithm that starts with a full-width search to a nominal length, and then searches more selectively below that depth.


















