
Computer architecture Lecture 12: Superscalar architectures Piotr Bilski.
25
Computer architecture Lecture 12: Superscalar architectures Piotr Bilski
-
Upload
noelia-ady -
Category
Documents
-
view
217 -
download
2
Transcript of Computer architecture Lecture 12: Superscalar architectures Piotr Bilski.

Computer architecture
Lecture 12: Superscalar architectures
Piotr Bilski
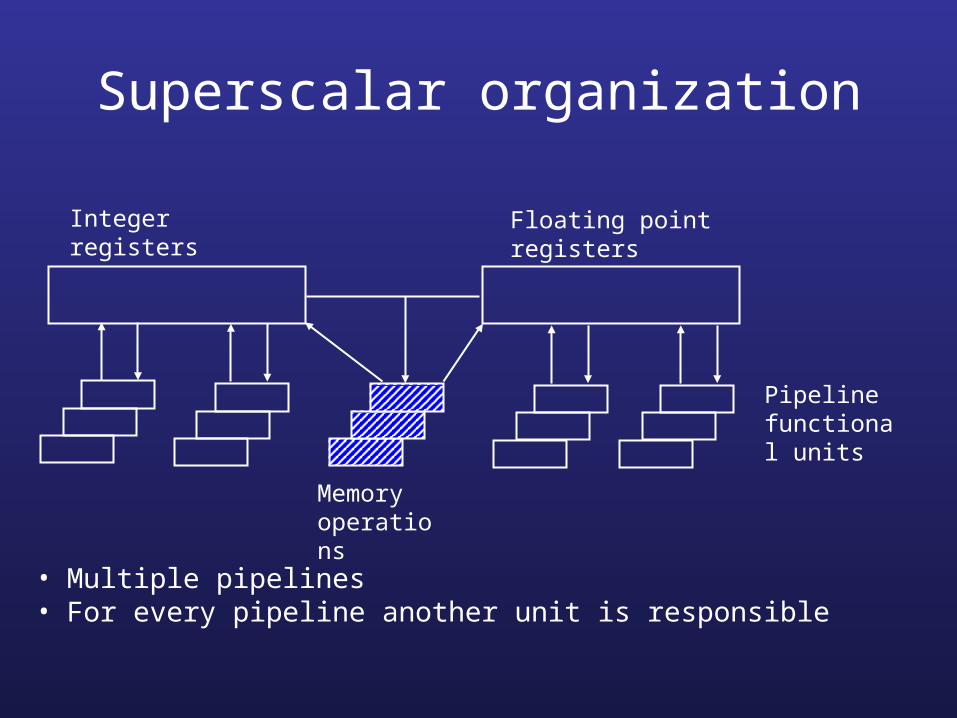
Superscalar organization
• Multiple pipelines• For every pipeline another unit is responsible
Pipeline functional units
Integer registers Floating point registers
Memory operations
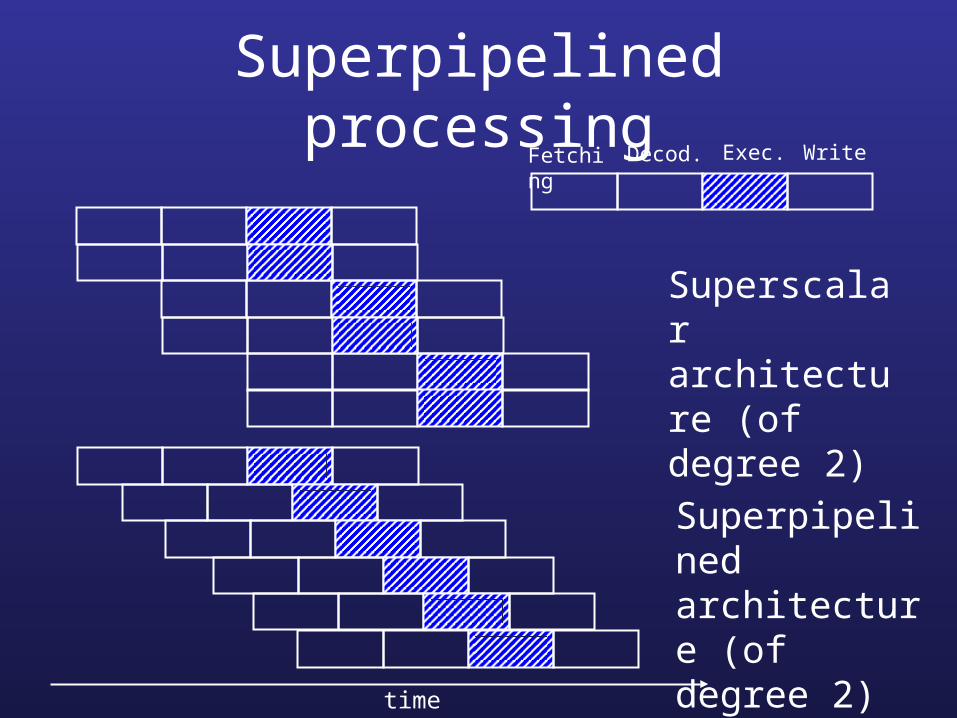
Superpipelined processingFetching Decod. Exec. Write
Superscalar architecture (of degree 2)
Superpipelined architecture (of degree 2)
time

Limitations of the superscalar architecture
• Instruction-level paralelism• Machine-level paralelism• Limitations:
– True data dependency– Procedural dependency– Resource conflict– Output dependency– Anti-dependency
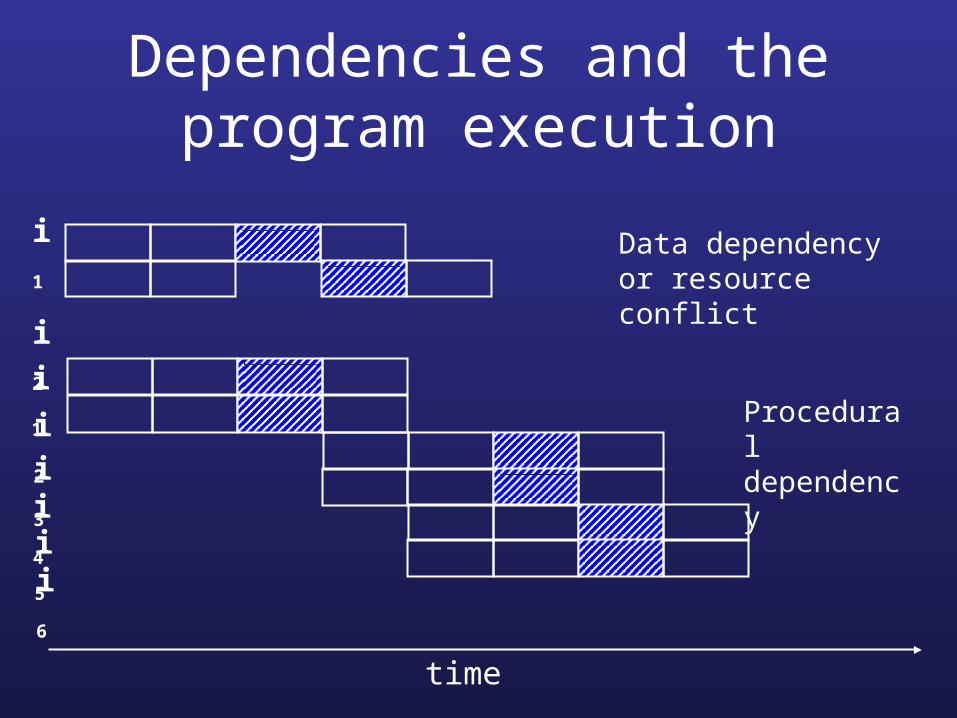
Dependencies and the program execution
time
i1
i2
i1
i2
i3
i4
i5
i6
Data dependency or resource conflict
Procedural dependency

True data dependency
• Both instructions can be fetched and decoded simultaneously
• I2 can not be executed until I1 is executed
I1 Add r1, r2
I2 Move r3, r1

Instruction parallelism
• Requires independence between the subsequent instructions
• Determined by the true data dependencies and procedural dependencies
• For example:
Load R1 R2
Add R3 R3, „1”
Add R4 R4, R2
Add R3 R3, „1”
Add R4 R3, R2
Store [R4] R0

Strategies of issuing instructions
• In-order issue/in-order completion
• In-order issue/out-of-order completion
• Out-of-order issue/out-of-order completion

I1 I2
I3 I4
I3 I4
I4
I5 I6
I6
I1 I2
I1
I3
I4
I5
I6
I1 I2
I3 I4
I5 I6
In-order issue/in-order completion
Decoding Execution Write

In-order issue/out-of-order completion
I1 I2
I3 I4
I4
I5 I6
I6
I1 I2
I1 I3
I4
I5
I6
I2
I1 I3
I4
I5
I6
Decoding Execution Write

Output dependency
• I3 can not be completed before I1
• Changing sequence of the instruction completion is difficult and requires additional hardware solutions
I1: R3 ← R3 op R5
I2: R4 ← R3 + 1
I3: R3 ← R5 + 1
I4: R7 ← R3 op R4

Out-of-order issue/out-of-order completion
I1 I2
I3 I4
I5 I6
I1 I2
I1 I3
I6 I4
I5
I2
I1 I3
I4 I6
I5
I1, I2
I3, I4
I4,I5,I6
I5
Decoding Window Execution Write

Antidependency
• I1: R3 ← R3 op R5• I2: R4 ← R3 + 1• I3: R3 ← R5 + 1• I4: R7 ← R3 op R4
• I3 can not be completed before I2 is executed
• Dependency is reversed

Register renaming
• Changing the sequence of the instruction execution makes impossible determining content of the register in any moment
• The incoming data are assigned free registers from CPU
• Instructions get to data through the number/name of the assigned register

Machine paralelism
• Multiplication of the functional units is justified only after renaming registers
• Instruction window should be large enough to store enuough instructions (>16)
• Branch prediction is necessary
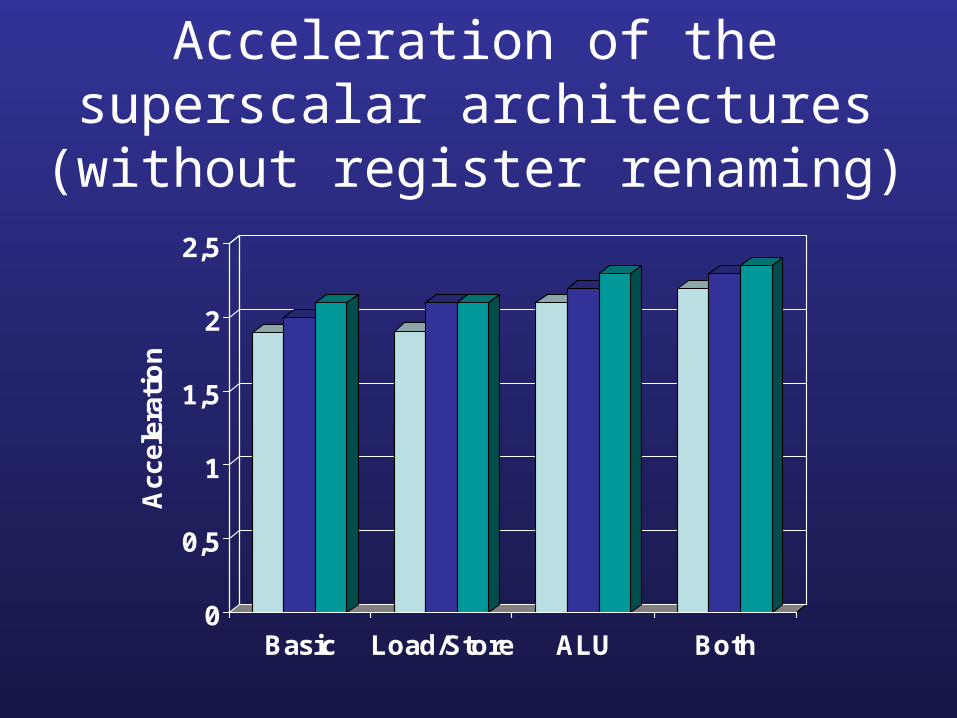
Acceleration of the superscalar architectures (without register
renaming)
0
0,5
1
1,5
2
2,5
Acc
eler
atio
n
Basic Load/Store ALU Both
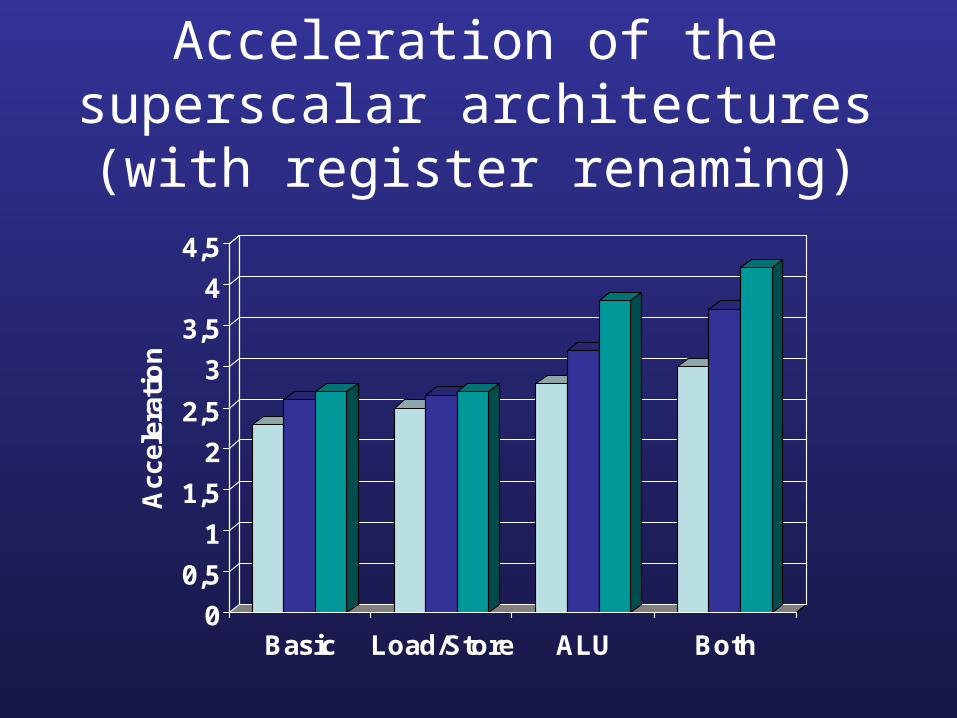
Acceleration of the superscalar architectures (with register renaming)
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
Acc
eler
atio
n
Basic Load/Store ALU Both
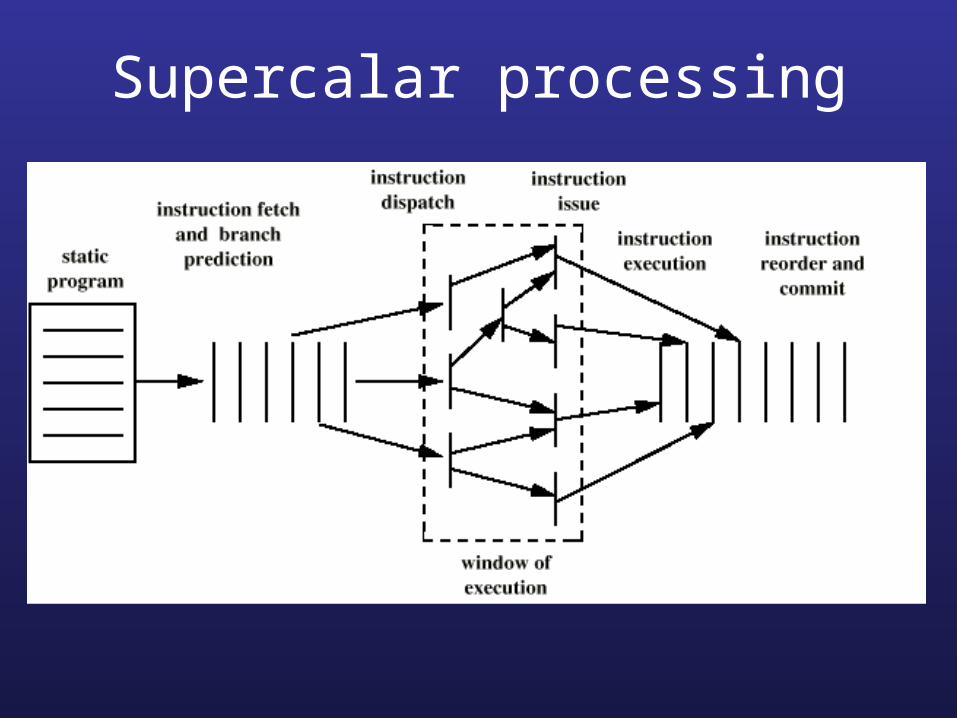
Supercalar processing

Superscalar example – P4
• Processor fetches instructions sequentially
• Instruction is translated into RISC instructions (microoperations)
• Microoperations are processed by th superscalar, 20-element pipelining
• Results of the microoperations are sent to the internal registers and ordered
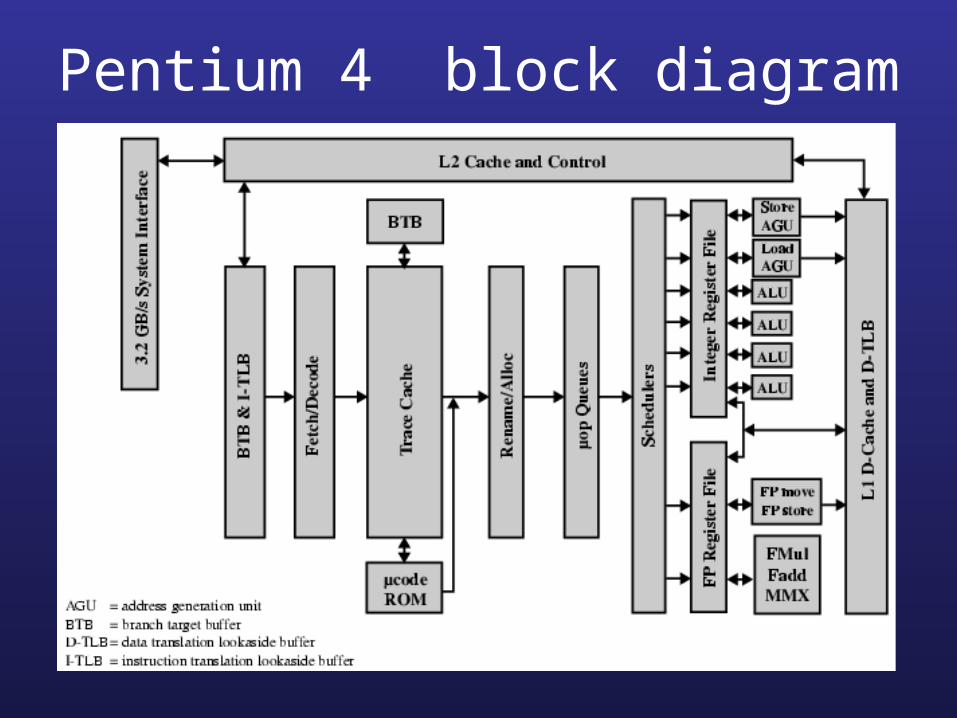
Pentium 4 block diagram

Pentium 4 operation
• Fetch instructions form memory in order of static program
• Translate instruction into one or more fixed length RISC instructions (micro-operations)
• Execute micro-ops on superscalar pipeline– micro-ops may be executed out of order
• Commit results of micro-ops to register set in original program flow order
• Outer CISC shell with inner RISC core• Inner RISC core pipeline at least 20 stages

Pentium 4 pipeline

PowerPC architecture
• Processor consists of the three independent execution units (execution of the three instructions at the same time):
– Branch prediction unit
– Floating point unit
– Integer unit
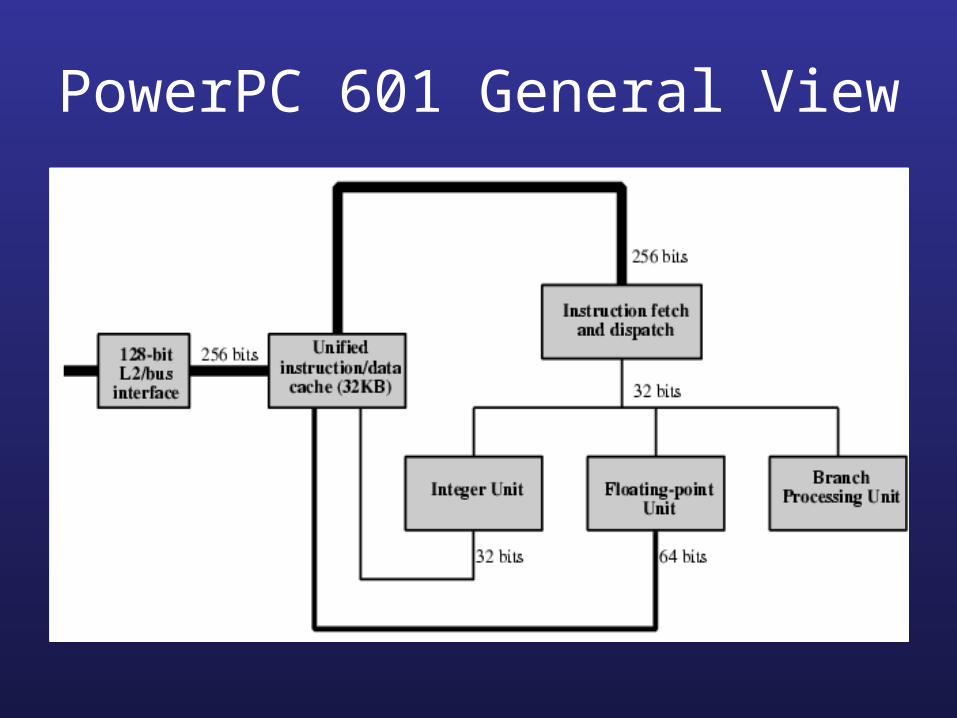
PowerPC 601 General View

PowerPC 601 Pipeline


















