
Computation to Core Mapping - Virginia Techaccel.cs.vt.edu/files/lecture9.pdf · 0,0 1,0 2,0 3,0...
29
Computation to Core Mapping Computation to Core Mapping Computation to Core Mapping ─ Lessons learned from a simple application Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
-
Upload
truonghanh -
Category
Documents
-
view
216 -
download
0
Transcript of Computation to Core Mapping - Virginia Techaccel.cs.vt.edu/files/lecture9.pdf · 0,0 1,0 2,0 3,0...

Computation to Core Mapping
Computation to Core MappingComputation to Core Mapping─ Lessons learned from a simple application
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
A Si l A Si l A li tiA li tiA Simple A Simple ApplicationApplicationMatrix Multiplicationp
Used as an example throughout the course
Goal for today:Show the concept of “Computation-to-Core Mapping”
Block schedule, Occupancy, and thread schedule
iAssumptionDeal with square matrix for simplicityLeave memory issues latery
With global memory and local registers
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
2

Computation to Core Mapping
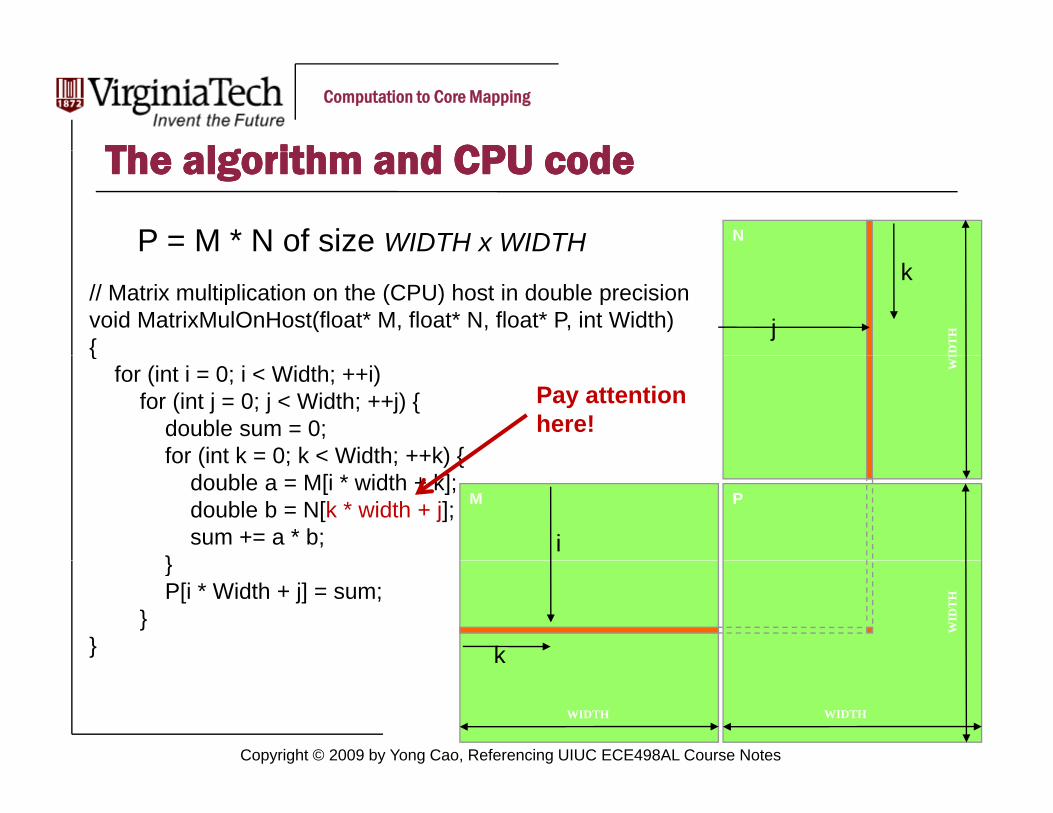
Th lg ith d CPU dTh lg ith d CPU dThe algorithm and CPU codeThe algorithm and CPU code
NP = M * N of size WIDTH x WIDTH
IDT
H
// Matrix multiplication on the (CPU) host in double precisionvoid MatrixMulOnHost(float* M, float* N, float* P, int Width) {
k
j
WI{
for (int i = 0; i < Width; ++i) for (int j = 0; j < Width; ++j) {
double sum = 0;for (int k = 0; k < Width; ++k) {
M P
for (int k = 0; k < Width; ++k) {double a = M[i * width + k];double b = N[k * width + j];sum += a * b;
}i
WID
TH
}P[i * Width + j] = sum;
}} k
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
3WIDTH WIDTH
Computation to Core Mapping
Th lg ith d CPU dTh lg ith d CPU dThe algorithm and CPU codeThe algorithm and CPU code
NP = M * N of size WIDTH x WIDTH
IDT
H
// Matrix multiplication on the (CPU) host in double precisionvoid MatrixMulOnHost(float* M, float* N, float* P, int Width) {
k
j
WI{
for (int i = 0; i < Width; ++i) for (int j = 0; j < Width; ++j) {
double sum = 0;for (int k = 0; k < Width; ++k) {
Pay attention here!
M P
for (int k = 0; k < Width; ++k) {double a = M[i * width + k];double b = N[k * width + j];sum += a * b;
}i
WID
TH
}P[i * Width + j] = sum;
}} k
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
4WIDTH WIDTH
Computation to Core Mapping
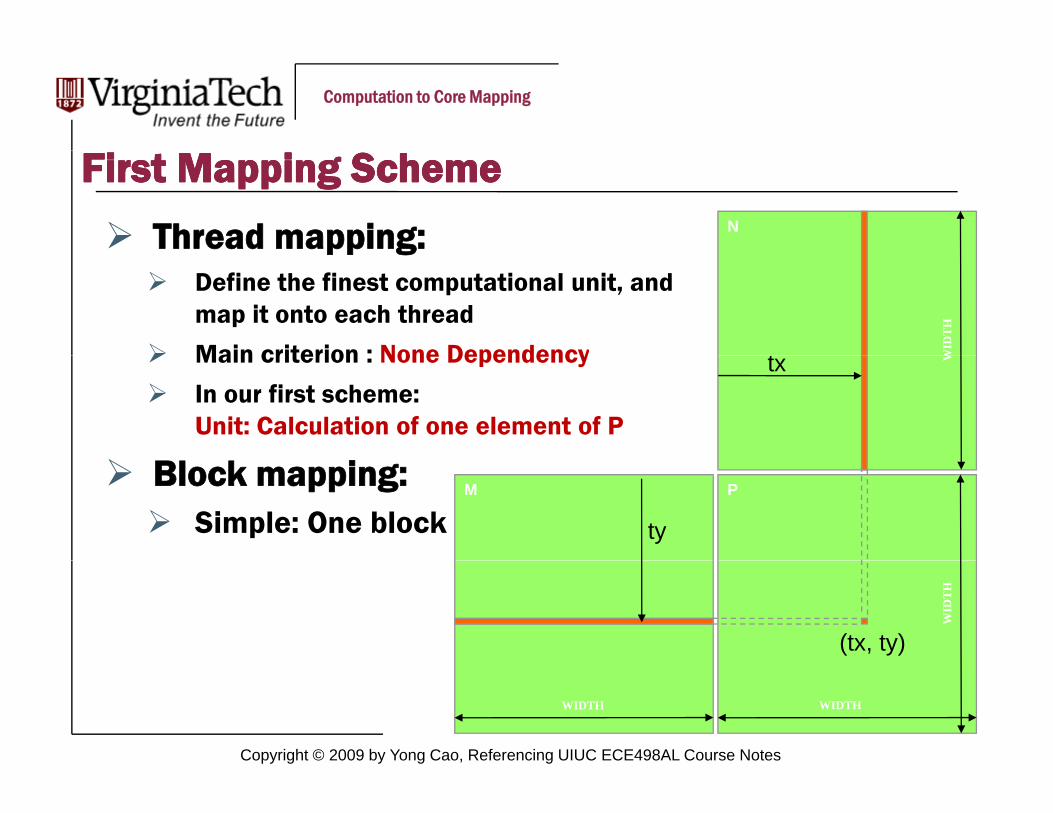
First Mapping SchemeFirst Mapping Scheme
Thread mapping: Npp gDefine the finest computational unit, and map it onto each thread
Main criterion : None Dependency WID
TH
tMain criterion : None Dependency
In our first scheme:Unit: Calculation of one element of P
Wtx
Block mapping:Simple: One block
M P
ty
WID
TH
(tx, ty)
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
5WIDTH WIDTH
Computation to Core Mapping
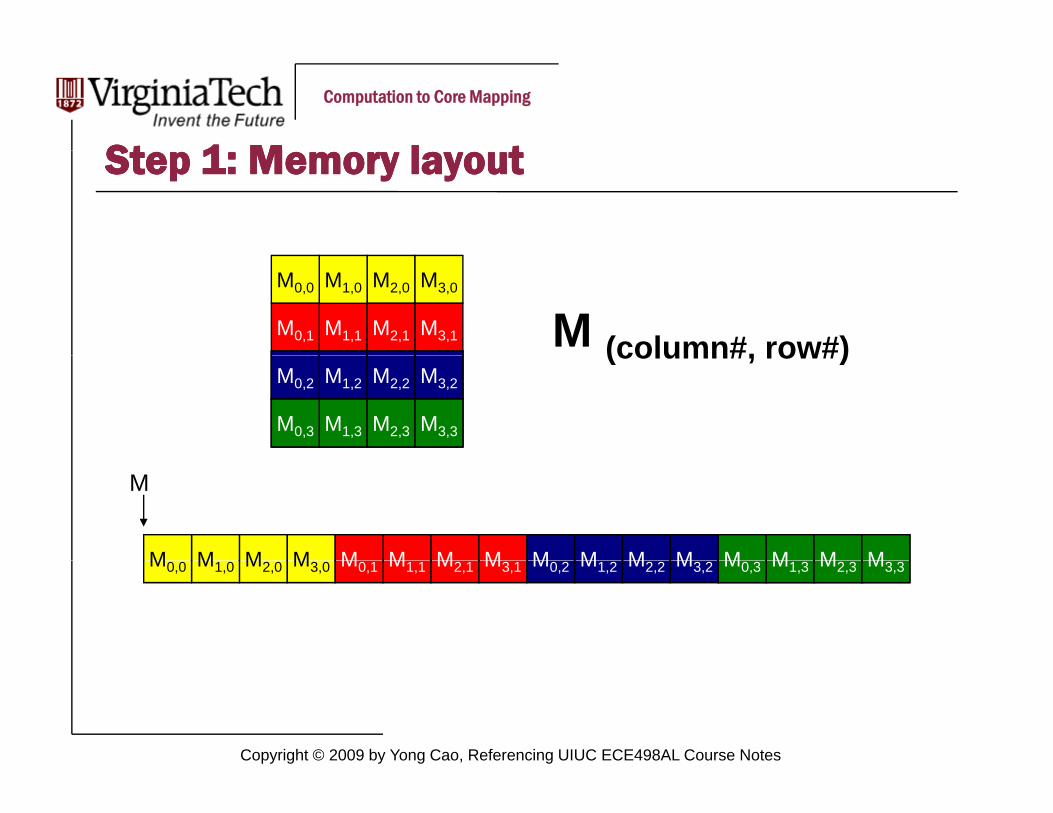
St St 11 M l t M l tStep Step 11: Memory layout: Memory layout
M2,0
M1,1
M1,0M0,0
M0,1
M3,0
M2,1 M3,1 M (column#, row#)M1,2M0,2 M2,2 M3,2
M1,3M0,3 M2,3 M3,3
(column#, row#)
MMM M MM M M MM M M MM M M
M
M2,0M1,0M0,0 M3,0 M1,1M0,1 M2,1 M3,1 M1,2M0,2 M2,2 M3,2 M1,3M0,3 M2,3 M3,3
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
St St 22 I t M t i D t I t M t i D t T f T f (H t (H t C d )C d )Step Step 22: Input Matrix Data : Input Matrix Data Transfer Transfer (Host (Host Code)Code)
void MatrixMulOnDevice(float* M, float* N, float* P, int Width) {{
int size = Width * Width * sizeof(float); float* Md, Nd, Pd;
…1. // Allocate and Load M, N to device memory
cudaMalloc(&Md, size);cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice);cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice);
cudaMalloc(&Nd, size);cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice);
// Allocate P on the devicecudaMalloc(&Pd, size);
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
St St 33 O t t M t i D t O t t M t i D t T f T f (H t (H t C d )C d )Step Step 33: Output Matrix Data : Output Matrix Data Transfer Transfer (Host (Host Code)Code)
2. // Kernel invocation code – to be shown later…
3. // Read P from the devicecudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost);
// Free device matrices// Free device matricescudaFree(Md); cudaFree(Nd); cudaFree (Pd);}
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
St St 44 K l F ti K l F tiStep Step 44: Kernel Function: Kernel Function// Matrix multiplication kernel – per thread code
__global__ void MatrixMulKernel(float* Md, float* Nd, float* Pd, int Width) {
// Pvalue is used to store the element of the matrix// that is computed by the threadfloat Pvalue = 0;
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
9

Computation to Core Mapping
St St 44 K l F ti ( t ) K l F ti ( t )Nd
Step Step 44: Kernel Function (cont.): Kernel Function (cont.)for (int k = 0; k < Width; ++k) {
float Melement = Md[threadIdx.y*Width+k];
WID
TH
float Melement Md[threadIdx.y Width k];float Nelement = Nd[k*Width+threadIdx.x];Pvalue += Melement * Nelement;
}tx
k
Pd[threadIdx.y*Width+threadIdx.x] = Pvalue;}
tx
Md Pd
tyty
WID
TH
txk
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
10WIDTH WIDTH

Computation to Core Mapping
St 5 K l St 5 K l I ti (H t I ti (H t C d ) C d ) Step 5: Kernel Step 5: Kernel Invocation (Host Invocation (Host Code) Code)
// Setup the execution configurationdim3 dimGrid(1 1);dim3 dimGrid(1, 1);
dim3 dimBlock(Width, Width);
// Launch the device computation threads!MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width);
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
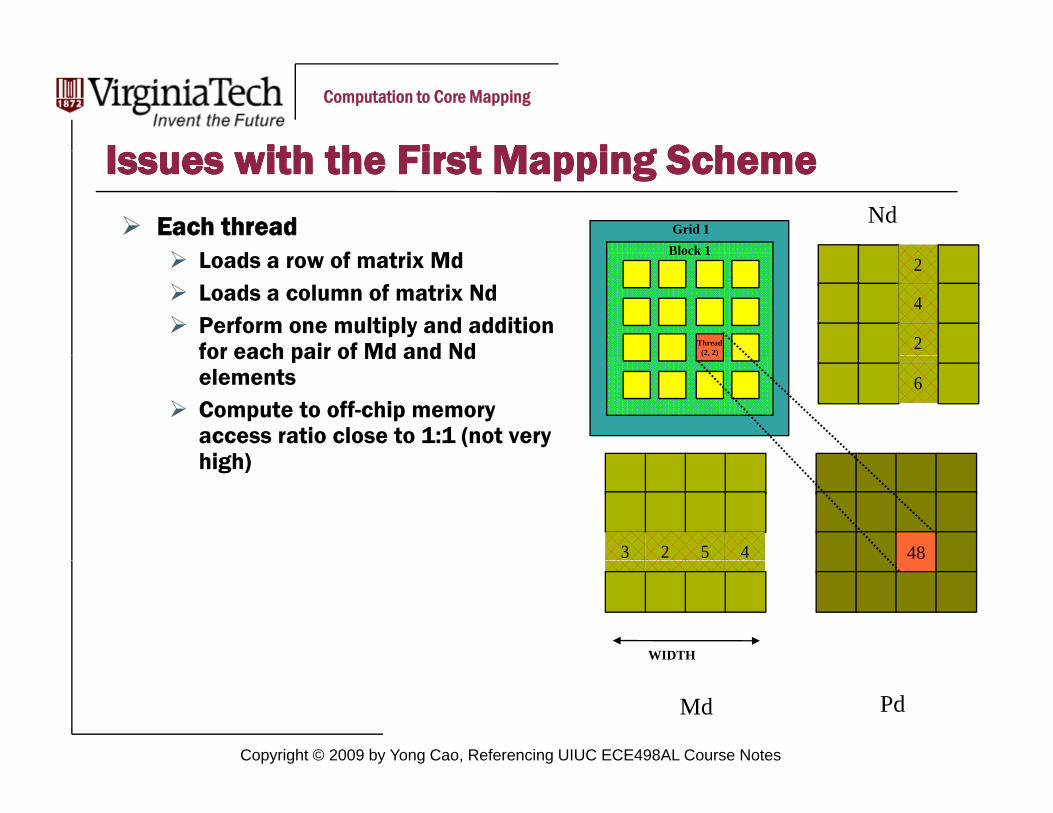
I ith th Fi t M i g S hI ith th Fi t M i g S hIssues with the First Mapping SchemeIssues with the First Mapping SchemeOne Block of threads compute matrix Pd
Grid 1Block 1
Nd
matrix PdOther Multi-processors are not used.
Block 12
4
2Thread(2, 2)
6
( , )
3 2 5 4 48
WIDTH
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
Md Pd
Computation to Core Mapping
I ith th Fi t M i g S hI ith th Fi t M i g S hIssues with the First Mapping SchemeIssues with the First Mapping SchemeEach thread
L d f t i MdGrid 1
Block 1
Nd
Loads a row of matrix MdLoads a column of matrix NdPerform one multiply and addition for each pair of Md and Nd
Block 12
4
2Thread(2, 2)for each pair of Md and Nd
elementsCompute to off-chip memory access ratio close to 1:1 (not very high)
6
( , )
high)
3 2 5 4 48
WIDTH
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
Md Pd
Computation to Core Mapping
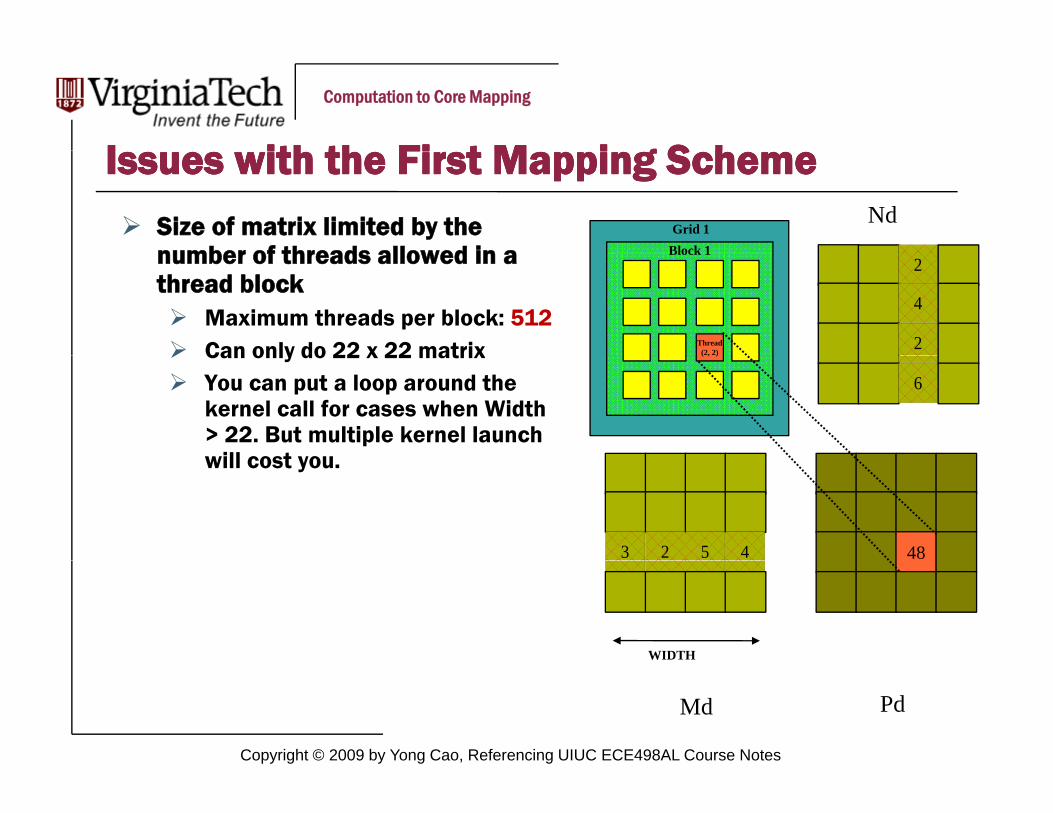
I ith th Fi t M i g S hI ith th Fi t M i g S hIssues with the First Mapping SchemeIssues with the First Mapping SchemeSize of matrix limited by the number of threads allowed in a
Grid 1Block 1
Nd
number of threads allowed in a thread block
Maximum threads per block: 512Can only do 22 x 22 matrix
Block 12
4
2Thread(2, 2)Can only do 22 x 22 matrix
You can put a loop around the kernel call for cases when Width > 22. But multiple kernel launch will cost you
6
( , )
will cost you.
3 2 5 4 48
WIDTH
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
Md Pd
Computation to Core Mapping
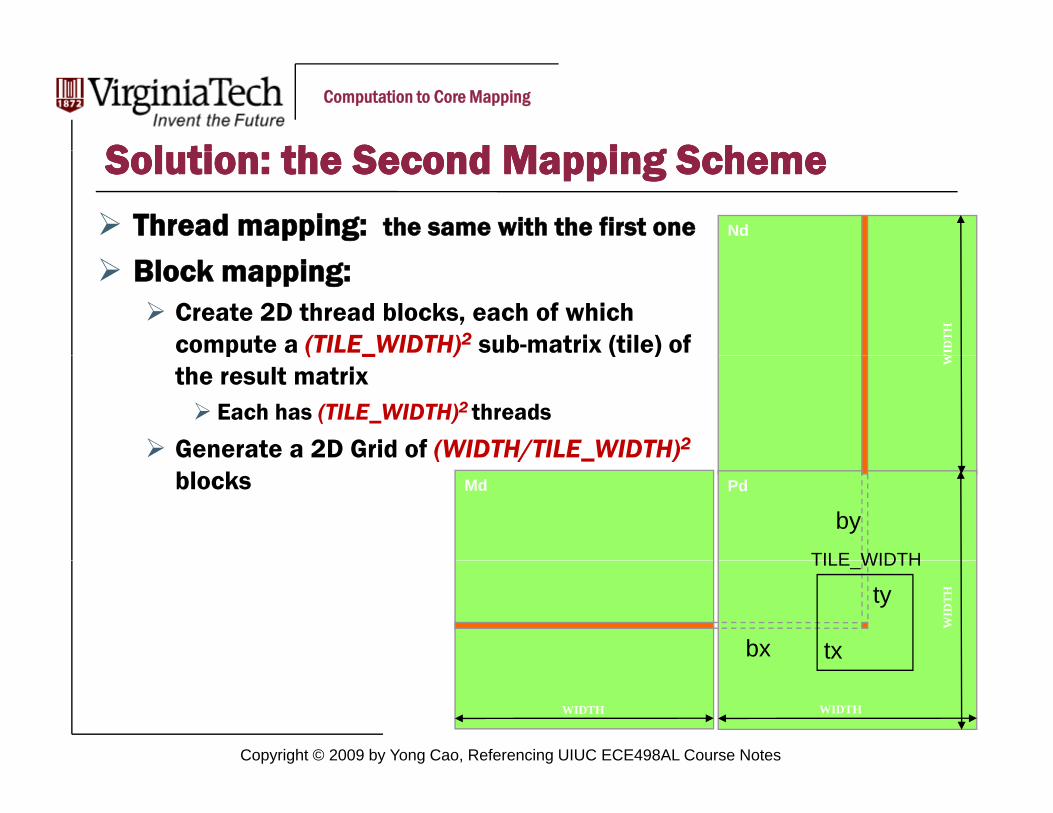
S l ti th S d M i g S hS l ti th S d M i g S hSolution: the Second Mapping SchemeSolution: the Second Mapping SchemeNdThread mapping: the same with the first one
WID
TH
Block mapping:Create 2D thread blocks, each of which compute a (TILE_WIDTH)2 sub-matrix (tile) of
W
p ( _ ) ( )the result matrix
Each has (TILE_WIDTH)2 threads
Generate a 2D Grid of (WIDTH/TILE WIDTH)2
Md Pd
byTILE WIDTH
( / _ )blocks
WID
THty
txbx
TILE_WIDTH
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
15WIDTH WIDTH

Computation to Core Mapping
Ab t th S d M i gAb t th S d M i gAbout the Second MappingAbout the Second Mapping
More blocks (WIDTH/TILE_WIDTH)2 Nd( / )
Support larger matrixThe maximum size of each dimension of a grid of thread blocks is 65535 W
IDT
H
grid of thread blocks is 65535.Max Width = 655352 x TILE_WIDTH2
Use more multi-processors
W
Md Pd
byTILE WIDTH
WID
THty
txbx
TILE_WIDTH
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
16WIDTH WIDTH

Computation to Core Mapping
Alg ith t i g tilAlg ith t i g til
bx
tx0 1 2
Algorithm concept using tilesAlgorithm concept using tilesNd
01 TILE_WIDTH-12
Break-up Pd into tiles
WID
THEach block calculates one tile
Each thread calculates one elementBlock size equal tile sizeBlock size equal tile size
Md Pd
Pdsub10
0
TH
E
Hsub
TILE_WIDTH
by ty 21
TILE_WIDTH-1
1
TIL
E_W
IDT
WID
TH
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
17
WIDTHWIDTH2

Computation to Core Mapping
E lE lExampleExample
Block(0,0) Block(1,0)
P1,0P0,0
P0 1
P2,0 P3,0
P1 1 P3 1P2 1
TILE_WIDTH = 2
0,1 1,1
P0,2 P2,2 P3,2P1,2
3,12,1
P0,3 P2,3 P3,3P1,3
Block(1,1)Block(0,1)
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
Bl k C t tiBl k C t tiBlock ComputationBlock Computation
Nd1 0Nd0 0
Nd1,2
Nd1,1
Nd1,0Nd0,0
Nd0,1
Nd0,2
Nd0,3Nd1,3
1,20,2
Pd1,0Md2,0
Md1,1
Md1,0Md0,0
Md0,1
Md3,0
Md2,1
Pd0,0
Md3,1 Pd0,1
Pd2,0Pd3,0
Pd1,1 Pd3,1Pd2,1
Pd0,2 Pd2,2Pd3,2Pd1,2
Pd0,3 Pd2,3Pd3,3Pd1,3
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
K l C d i g TilK l C d i g TilKernel Code using TilesKernel Code using Tiles__global__ void MatrixMulKernel(float* Md, float* Nd, float* Pd, int Width){{// Calculate the row index of the Pd element and M
int Row = blockIdx.y*TILE_WIDTH + threadIdx.y;// Calculate the column idenx of Pd and N
int Col blockIdx x*TILE WIDTH + threadIdx x;int Col = blockIdx.x*TILE_WIDTH + threadIdx.x;
float Pvalue = 0;// each thread computes one element of the block sub-matrix// pfor (int k = 0; k < Width; ++k)Pvalue += Md[Row*Width+k] * Nd[k*Width+Col];
Pd[Row*Width+Col] = Pvalue;}
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
R i d K l I ti (H t R i d K l I ti (H t C d ) C d ) Revised Kernel Invocation (Host Revised Kernel Invocation (Host Code) Code)
// Setup the execution configurationdim3 dimGrid (Width/TILE WIDTH Width/TILE WIDTH);dim3 dimGrid (Width/TILE_WIDTH, Width/TILE_WIDTH);dim3 dimBlock (TILE_WIDTH, TILE_WIDTH);
// Launch the device computation threads!MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width);
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
Q ti ?Q ti ?Questions?Questions?
For Matrix Multiplication using multiple For Matrix Multiplication using multiple blocks, should I use 8X8, 16X16 or 32X32blocks?blocks?Why?
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
Bl k S h d li gBl k S h d li gBlock SchedulingBlock Scheduling
t0 t1 t2 … tm t0 t1 t2 … tmSM 1SM 0
SP
MT IU
SP
MT IU Blocks
Blocks
Up to 8 blocks to each SM as resource allowsSM in G80 can take up to 768 threads
Could be 256 (threads/block) * 3 blocks
SharedMemory
SharedMemory
Could be 256 (threads/block) 3 blocks Or 128 (threads/block) * 6 blocks, etc.
SM in GT200 can take up to 1024 threads
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
23
Computation to Core Mapping
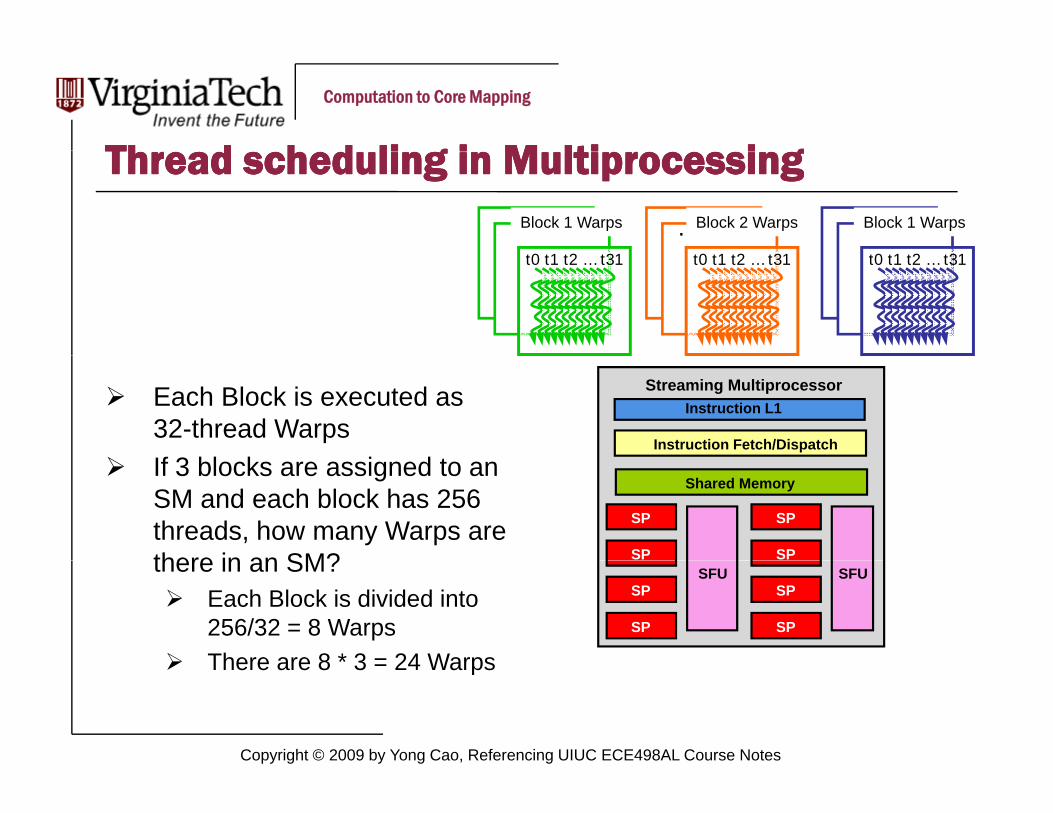
Th d h d li g i M lti i gTh d h d li g i M lti i gThread scheduling in MultiprocessingThread scheduling in Multiprocessing… …Block 1 Warps Block 2 Warps …Block 1 Warps
…t0 t1 t2 … t31
…t0 t1 t2 … t31
…t0 t1 t2 … t31
Each Block is executed as 32-thread WarpsIf 3 bl k i d t
Instruction Fetch/Dispatch
Instruction L1Streaming Multiprocessor
If 3 blocks are assigned to an SM and each block has 256 threads, how many Warps are there in an SM? SP
SP
SP
SP
Shared Memory
there in an SM?Each Block is divided into 256/32 = 8 WarpsThere are 8 * 3 = 24 Warps
SP
SPSFU
SP
SPSFU
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
There are 8 3 = 24 Warps

Computation to Core Mapping
O f M ltiO f M ltiOccupancy of MultiprocessorOccupancy of Multiprocessor
How much a Multiprocessor is occupied:How much a Multiprocessor is occupied:Occupancy = Actually warps / Totally allowed
GT200 SM allows 32 warpspG80 SM allow 24 warps
For example:pOne block per SM, 32 threads per block
(32/32) / 32 = 3.125% (Very bad)
4 blocks per SM, 256 threads per block(256/32) * 4 / 32 = 100% (Very good)
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
CUDA O C l l tCUDA O C l l tCUDA Occupancy CalculatorCUDA Occupancy Calculator
There are three factors:There are three factors:Maximum number of warpsMaximum registers usageMaximum registers usageMaximum share memory usage
DemoDemo
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes

Computation to Core Mapping
A t O Q tiA t O Q tiAnswers to Our QuestionsAnswers to Our Questions
For Matrix Multiplication using multiple blocks, should I use 8X8, 16X16 or 32X32 blocks?For G80 GPU:
For 8X8 we have 64 threads per Block Since each SM can For 8X8, we have 64 threads per Block. Since each SM can take up to 768 threads, there are 12 Blocks. However, each SM can only take up to 8 Blocks, only 512 threads will go into each SM! (Occupancy = 66 6%)into each SM! (Occupancy 66.6%)For 16X16, we have 256 threads per Block. Since each SM can take up to 768 threads, it can take up to 3 Blocks and achieve full capacity unless other resource considerations achieve full capacity unless other resource considerations overrule. (Occupancy = 100%)For 32X32, we have 1024 threads per Block. Not even one can fit into an SM! (Can not support)
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
can fit into an SM! (Can not support)

Computation to Core Mapping
A t O Q ti (C t’)A t O Q ti (C t’)Answers to Our Questions (Cont’)Answers to Our Questions (Cont’)
For Matrix Multiplication using multiple blocks, should I use 8X8, 16X16 or 32X32 blocks?For GT200 GPU:
For 8X8 we have 64 threads per Block Since each SM can For 8X8, we have 64 threads per Block. Since each SM can take up to 1024 threads, there are 16 Blocks. However, each SM can only take up to 8 Blocks, only 512 threads will go into each SM! (Occupancy =50%)into each SM! (Occupancy 50%)For 16X16, we have 256 threads per Block. Each SM takes 4 Blocks and achieve full capacity unless other resource considerations overrule (Occupancy = 100%)considerations overrule. (Occupancy 100%)For 32X32, we have 1024 threads per Block. Each SM takes 1 Block and achieve full capacity unless other resource considerations overrule. (Occupancy = 100%)
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes
considerations overrule. (Occupancy 100%)

Computation to Core Mapping
C t tiC t ti tt C M i gC M i gComputationComputation--toto--Core MappingCore Mapping
Step 1:Step 1:Define your computational unit, map each unit to a thread
Avoid dependencyIncrease compute to memory access ratio
Step 2:Group your threads into blocks
Eliminate hardware limitEliminate hardware limitTake advantage of shared memory
Copyright © 2009 by Yong Cao, Referencing UIUC ECE498AL Course Notes


















