
Data Representation Synthesis PLDI’2011 * , ESOP’12, PLDI’12 * CACM’12
Upload
morris-websterCategory
view
215download
1
Compiler Optimizations Save the Bacon
Susan Eggers
University of Washington
June 2010 Athena Lecture 1
For most of my research career PLDI was the premier forum for compiler opt researchHear 85% do PL rather than nuts and bolts optIn some part serve to lure you backFrom my point compiler opts & HW-SW co-design have been invaluable for showing the architecturesat their best

Role of Compiler Optimization
Made an already effective multithreaded processor perform even better
Made a distributed dataflow computer profitable on applications with no or coarse-grain parallelism
Provided a software-only alternative to purely hardware solutions for eliminating false sharing
Something on Balanced scheduling/
Was the enabling technology for automatically generating high-performance, low-power caches on an FPGA
All compilers optimizations were a straightforward application of known technology
2
Just considering examples from my own career, compiler optimizations have been bacon-saving in a number of ways
Athena LectureJune 2010
None were breakthroughs in opt design
For which it was not intended

Role of Compiler Optimization
Made an already effective multithreaded processor perform even better Simultaneous Multithreading
Made a distributed dataflow machine profitable on applications with no or coarse-grain parallelism
Provided a software-only alternative to purely hardware solutions for eliminating false sharing
Was the enabling technology for automatically generating high-performance, low-power caches on an FPGA CHiMPS
All compilers optimizations were a straightforward application of known technology
3
Explain why compiler opts were so crucial:
Athena LectureJune 2010

Simultaneous Multithreading (SMT):A Brief History
The origins:• Originated at UW in 1994 w/Hank Levy (UW) & Dean Tullsen
(UCSD)• Collaboration w/Joel Emer (Intel) & Rebecca Stamm at DEC• Jack Lo, Sujay Parekh, Luiz Barroso, Kourosh Gharachorloo,
Brian Dewey, Manu Thambi, Josh Redstone, Mike Swift, Luke McDowell, Aaron Eakin, Dimitriy Portnov, Steve Swanson
• 4-context DEC/Compaq Alpha 21464
Today:• 2-context Intel Pentium 4 & Xeon 4 (Hyperthreading)• 4-context IBM Power5 & Power6• 2-context Sun Rock
Athena Lecture 4
On low-end CMPs
biggest seller
June 2010

Where Have All the Cycles Gone? (simulated 8-issue Alpha 21164)
processor busyitlb missdtlb missI-cache missdcache missbranch mispred.control hazardsload delaysshort intlong intshort fplong fpmem conflict
Applications
100
90
80
70
60
50
40
30
20
10
0
Rainbow of colorsIllustrates the issuepoints to a solutionGraph is an accounting of activity
Began in 1994, addressing key issue in uniprocessor designLatency-hiding, throughput-enhancing, ILP-exploiting HWProcessor utilization decreasing & I TP not increasing with issue width
Under 20% utilization, 1.5 IPC out of 8Eliminate 1 bottleneck, problem just shifts to anotherProblem is not a particular latency, but more pervasive

Motivation for Multithreaded Architectures
Major cause of low instruction throughput is the lack of instruction-level parallelism in a single executing thread, not a particular source in latency
Therefore the solution:• has to be more general than building a smarter cache or a more
accurate branch predictor• has to involve more than one thread
Athena Lecture 6June 2010

SMT: The Executive Summary
Simultaneous multithreaded (SMT) processors combined designs from:• out-of-order superscalar processors
• multiple issue width• dynamic instruction scheduling• register renaming
• traditional multithreaded processors• multiple per-thread hardware context
Athena Lecture6
Think registers & PC
HW, to create inde I
OOO exec
June 2010

SMT: The Executive Summary
The combination was a processor with two important capabilities.
1) that could do same-cycle multithreading
=> converting TLP to cross-thread ILP
2) thread-shared hardware resources
Athena Lecture8
Not just utilize TLP, but convert TLP to global ILP
Which could do multithreading within a single cycle,i.e., issue & execute instructions from multiple threadssimultaneously, without HW CS
1 2 3 4
Ti
me
Threads
Fetch Logic
Functional Units
Instruction Queue
Fill all HW, taking whatever proportion they needed dynamicallyParticularly important for few or 1 thread
June 2010

Comparison of Issue Capabilities
Athena Lecture 9
SMT uses same-cycle MTg to compensate for both
Issue slots
If 1 thread has little ILP
If 1 thread has long latency Is
CMP(multi-core)
Visual understanding of how several archs differ wrt issuing & executing Is
in the extreme
Stall, long-latency Is with dependents
Limited by amount of ILP in a single thread, just like a SS
hiding latencies of all kindsready Is can be executed from any thread
June 2010
Huge boost in instruction throughput

Performance Implications
Multiprogramming workload (2.5X on SPEC95, 4X on SPEC2000)
Parallel programs (~1.7X on SPLASH2)
Commercial databases (2-3X on TPC B; 1.5X on TPC D)
Web servers & OS (4X on Apache and Unix)
Single thread (1.5% slowdown)
Roughly 15% increase in chip area (for a 4-thread Alpha 21464)
Athena Lecture 10
Wins for workloads that have:high TLP – naturally threaded, high TP with no overheadlow single-thread ILP – make up for the lack with other threads
high TLP, mostly OS (Digital)
Low-ILP single threads
significant throughput gains with multiple threads
Oracle
Results without changing the compilation strategyJune 2010

What does SMT change?
1. Costs of data sharing
CMPs
Threads reside on distinct processors & inter-thread communication is a big overhead.
Parallelizing compilers attempt to decompose applications to minimize inter-processor communication
Disjoint set of data & iterations for each thread
SMT
Threads execute on the same processor with thread-shared hardware, so inter-thread communication incurs no overhead.
11
OS changes: TID, per-thread internal regs for TLB updates, no shoot-down code
Revisit compiler optimizations: appropriate
fine-grained sharing of processor and memory resources
Athena Lecture
partitioning & distributing data to match the physical topology
L1 $ & TLB
True & false sharing is local
June 2010
For data sharing & maintaining cache coherency
Each can work independently of the others

What does SMT change?
2. Available ILP
Wide-issue processor
Low ILP from a single executing thread
Compiler optimizations try to increase ILP by hiding/reducing instruction latencies.
SMT
Issues instructions from multiple threads each cycle
Better at hiding latencies, because uses instructions from one thread to mask delays in another
12Athena Lecture
Fewer empty issue slots, can overhead still be hidden?
Is latency-hiding necessary?
June 2010
Increasing dyn I count (hoist Is on false path) still often profitableBecause overhead is accommodated in otherwise empty issue slotsLots of empty issue slots

SMT Compiler Strategy
No special SMT compilation is necessary
But if we were …? • optimizing for sharing, not isolation• optimizing for throughput, not latency
13Athena Lecture
Examine opts that automatically parallelize loops or increase ILP1 example each
June 2010

Loop distribution
Distributes iterations & contiguous data across threads, separate data/thread
Athena Lecture 14
Page(s)/thread
June 2010
Dense loop computations
for (j = 1; j < n; j++for (i = 0; i < m; i++) u1[j][i] = u2[j][i] + t/8.0 * z[j][i]
for (j = max(n*pid)/numthreads+1,1); j < min(n*(pid+1)/numthreads+1,n); j++
for (i = 0; i < m; i++) u1[j][i] = u2[j][i] + t/8.0 * z[j][i]
Blocked
i
j
Assuming 4 threads

Loop distribution
Distributes iterations & contiguous data across threads, separate data/thread
Often works, except when: large number of threads, large number of arrays, small TLB
Clusters threads’ data, intra-page thread sharing
Speedups from break-even to 4X
Athena Lecture 15
Page(s)/thread
Blocked
CyclicTLBs: 40/full + 512/4-way (desktop), 32/full + 128/2-way (embedded)
TLB large enough for per-thread pages
Less instruction overhead in calculating array partition bounds
June 2010
Dense loop computations

Tiling
Tiled to exploit data reuse, separate tiles/thread
Often works, except when: large number of threads, large number of arrays, small data cache
Issue of tile-size sweet spot
Threads share a tile & iterations are cyclically distributed across threads
Athena Lecture
Blocked
1 2 31 2 3
3
3
2 41
41
4
4
2
3
1 2
Cyclic
431 2
875 6
9
Temporal locality
16June 2010
Small: lots of reuse, lots of loop control Is (dynamic)Large: less loop control Is, but less reuse

4
4
4
4
Tiling
Tiled to exploit data reuse, separate tiles/thread
Often works, except when: large number of threads, large number of arrays, small data cache
Issue of tiling sweet spot
Threads share a tile & iterations are cyclically distributed across threads
Less sensitive to tile size
Tiles can be large to reduce loop control overhead
Better performance for cache hierarchies of different sizes
Athena Lecture
Blocked
1 2 31 2 3
3
3
2 41
41
4
4
2
3
1 2
Cyclic
1 2
43
17June 2010
Great latency-hiding machineHide miss latencies of big tiles
More adaptable

Guidelines for SMT Compiler Optimization
No special SMT compilation is necessary
Performance improvements occur when: • Embrace rather than avoid fine-grain thread sharing• Optimize for high throughput rather than low latency• Avoid optimizations that increase instruction count
18Athena LectureJune 2010
Compiler-directed prefetching interferes with rich thread mixSoftware speculation for diamond-shaped control should be avoidedIterations in diff HWC rather than SWP, avoid register pressure

CHiMPS Compiler
UW Andrew Putnam (MSR)
XilinxDave BennettEric DellingerJeff MasonHenry StylesPrasanna SundararajanRalph Wittig
19
CHiMPS’ Goal: automatically generate an application-specific cache subsystem for executing high-performance applications on an FPGA
Compiler was enabling technology
Athena LectureJune 2010

Motivation: HPC Applications
FPGAs have performance, power & cost advantages for parallelizable codes
HPC application kernels have inherent parallelism
20Athena Lecture
Targeting a specific segment of application spaceResults have impact on our lives, $12B market in 2008
Domain Applications
Scientific Climate modeling, molecular dynamics, earthquake prediction
Medical Pharmaceuticals, CT scanners, medical imaging
Commercial Oil and gas exploration, automotive safety models
Defense & Security
Radar & air traffic control, satellite image processing, data security
Financial Options pricing, risk assessment
June 2010
Computing has revolutionized these fields, but still starved for compute power,especially as developers improve their analyses & increase their data sets
Entice HPC developers to FPGAs
Despite the potential, not yet adopted in HPC community

The Gotcha
Applications for FPGAs are written in Hardware Description Languages (HDLs), such as Verilog & VHDL• Actively manage FPGA’s distributed memory blocks at the
application level• Schedule movement of data in & out of physical memory• Add logic to avoid memory bank conflicts
HPC developers are experts in their applications domains, program in C• Assume one large memory space that is accessed via
named data structures• Hardware handles data accesses & conflict resolution
21Athena Lecture
HDL vs CMismatch is more than just a language issueCoding in HDLs requires HPC developers to step outside their traditional programming abstractionsUnderstand hardware design concepts, such as clock management, state machines, explicit memory mgnt
June 2010
CMP: FG -> lots communication costCG -> not much parallelism
Primary hurdle is the significant difference in the programming models for FPGAs & CPUs,most importantly how programmers must handle memory
Very few people outside EE can do this
Problem to the adoption of FPGA technology

CHiMPS’ Goals
Ease the transition to FPGAs for HPC developers• using a synthesis compiler that processes C• that can compile largely unmodified source code• support the C memory model• extract the parallelism• run on existing hardware & operating systems• generate bit streams that can scale to future hardware
Attain better performance & lower power than without the FPGA
22Athena Lecture
Use their familiar programming environment
Emphasis on ease-of-use over maximum performanceEmphasis on ease-of-use over maximum performance
Use existing code
June 2010
What does this mean?
What does this mean?
What does this mean?
What does this mean?
carrot
innovative

CHiMPS’ Goals
Ease the transition to FPGAs for HPC developers• using a synthesis compiler that processes C• that can compile largely unmodified source code support the C memory model • extract the parallelism• run on existing hardware & operating systems• generate bit streams that can scale to future hardware
Attain better performance & lower power than without the FPGA
23Athena Lecture
Emphasis on ease-of-use over maximum performanceEmphasis on ease-of-use over maximum performance
June 2010
Automatically build a custom cache system for FPGAs
Why is this hard or interesting?
BRAM = SRAM?

What CHiMPS Does
Build multiple caches, each for the code regions that accesses them
Distribute caches throughout logic blocks (LB) for low-latency access
Customize each cache for how it is used• Banking to match memory parallelism• Port design to match composition of
reads/writes per cycle• Cache size for good clock frequency-
miss rate balance• Cache duplication for task-level
parallelism
24Athena Lecture
Data near computation that uses it
Overall design is a good match for distributed FPGA logic
Sea of generic logic blocks, memory blocks and interconnectConfigure in arbitrary ways to create custom processing elements, in particular to exploit parallelismExecution model is usually DF: HW blocks execute …
$
June 2010
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB
LBLB LBLB LBLB
LBLB
LBLB
$
LBLB
PELBPELB
LBLB
LBLB
LBLB
LBLB
LBLB
$
$
$$
$
$
$
$
Build caches on top of FPGA’s small, inde memory blocksEach targeting particular data structure or regions of memory in an applicationEach located near the logic blocks that use themEach customized for mem access pattern & amount of memory parallelism in the region
# simultaneous R/Ws

CHiMPS Compilation Flow
CHiMPS looks like a standard C compiler
• hardware-independent front end
• hardware-dependent back end
• Interface is RISC-like target language w/ high-level constructs between them
Standard FPGA toolflow
25Athena Lecture
Extract Dataflow Graph
Extract Dataflow Graph
OptimizationOptimization
Alias AnalysisAlias Analysis
Cache Specification
Cache Specification
Datapath Optimization
Datapath Optimization
Resource EstimationResource Estimation
Cache CreationCache Creation
Post HW Gen OptimizationPost HW Gen Optimization
CHiMPS Compiler (Front End)
CHiMPS Compiler (Front End)
CHiMPS Hardware Generator (Back End)
CHiMPS Hardware Generator (Back End)
Place & Route
Place & Route
C CodeC Code
CHiMPS Target Language (CTL)
VHDLVHDL
FPGA Bitstream
FPGA Bitstream
Standard FPGA
Toolflow
CHiMPS Compilation Engine
Loops, functions
June 2010
Important thing for HPC developers is put in C, get out FPGA bit stream, looks the same as CPU
BLACK BULLLETS
VHDL
TOOLFLOW FROM WHERE?

Analyses for Cache Creation
Identify independent regions of memory
alias analysis
ANSI-C restrict keyword
Categorize memory regions by how the data is accessed
Order memory operations within each region
Apply loop interchange
26Athena Lecture
When tight inner loop with loop-carried dependence, make loop-carried dependence is over a coarser grainTo match memory parallelism in the code
Extract Dataflow
Graph
Extract Dataflow
Graph
OptimizationOptimization
Alias Analysis
Alias Analysis
Cache Specification
Cache Specification
CHiMPS Compiler (Front End)
CHiMPS Compiler (Front End)
C CodeC Code
CHiMPS Target Language (CTL)
Insert data dependence between memory ops with anti-dependencesto ensure they will commit in program-generated order
2 pointers don’t point to same memory location
Beginnings of customization:if RO, can replicate, no write ports
June 2010
Static analysis for declared vars, restrict for pointers, sufficient for HPC apps (not a lot of synch, barriers)
HOW HANDLE HAND-OFF TO CPU?
Identifies regions of data that are appropriate for caching & generates software specifications for region-specific caches
Why important??
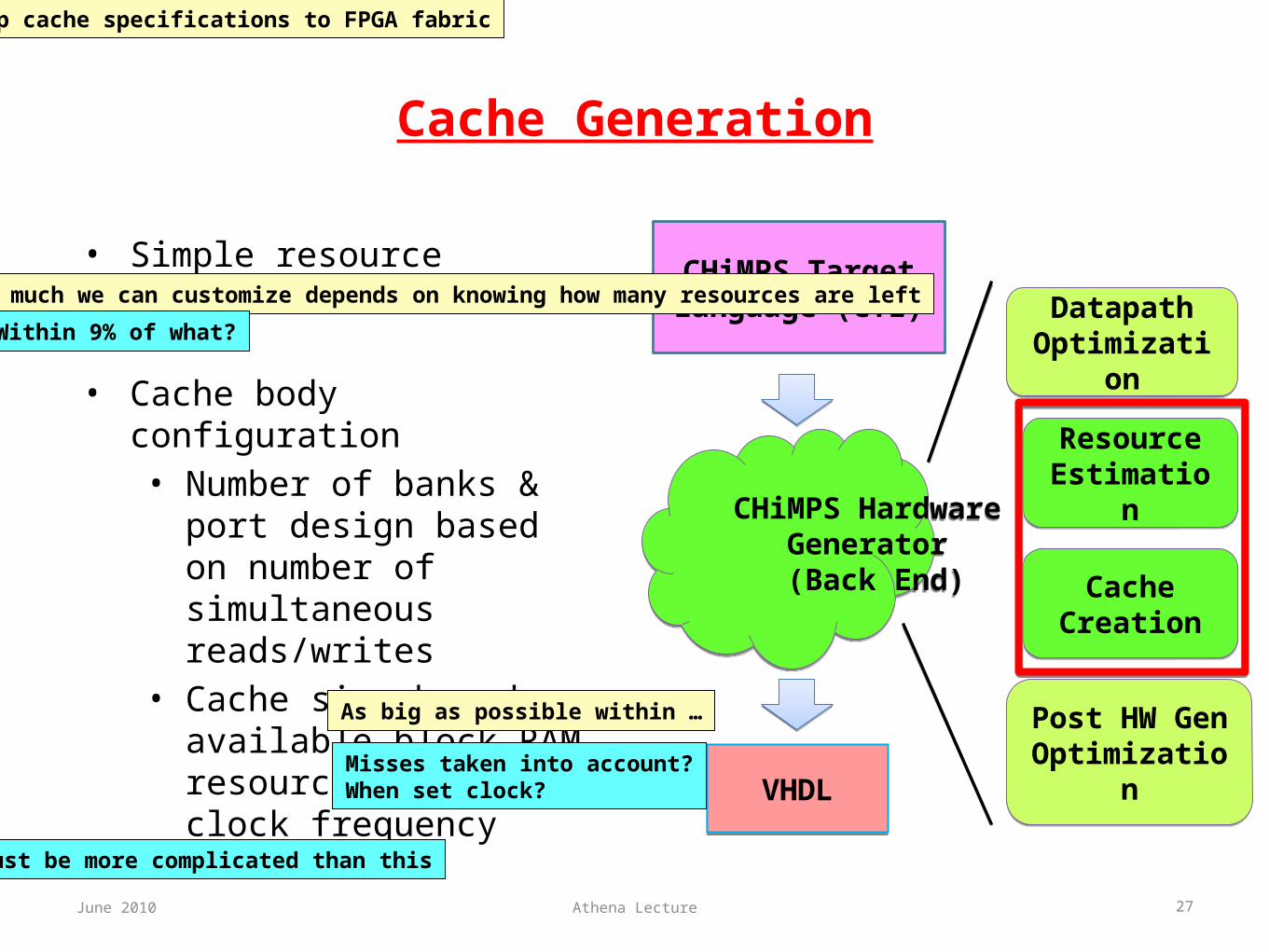
Cache Generation
• Simple resource estimation
• Cache body configuration• Number of banks & port
design based on number of simultaneous reads/writes
• Cache size based on available block RAM resources & target clock frequency
27Athena Lecture
Datapath Optimization
Datapath Optimization
Resource EstimationResource
Estimation
Cache CreationCache
Creation
Post HW Gen OptimizationPost HW Gen Optimization
CHiMPS Hardware Generator (Back End)
CHiMPS Hardware Generator (Back End)
CHiMPS Target Language (CTL)
VHDLVHDL
June 2010
Must be more complicated than this
Map cache specifications to FPGA fabric
How much we can customize depends on knowing how many resources are left
Within 9% of what?
As big as possible within …
Misses taken into account?When set clock?

Post-generation Optimization
Loop Unrolling• Replicates logic blocks within a
loop• Replicates caches (if possible)
Tiling• Duplicates an entire function,
both logic blocks & caches• Each “tile” computes on
independent data sets
28Athena Lecture
Cross-iteration dependences – thought they were inde?
June 2010
Datapath Optimization
Datapath Optimization
Resource EstimationResource
Estimation
Cache CreationCache
Creation
Post HW Gen OptimizationPost HW Gen Optimization
CHiMPS Hardware Generator (Back End)
CHiMPS Hardware Generator (Back End)
CHiMPS Target Language (CTL)
VHDLVHDL
If RO? Anything else? When not possible?
To increase parallelism

What the Compiler Wrought
Seamless use of FPGAs by HPC developers
Efficient support of caching in commercially available FPGAs• 7.8X performance than a CPU• 4.1X lower power consumption• 21.3X performance/watt
29Athena LectureJune 2010
Very straightforward, but the effect is transforming
And get
Could use GPUs, but not for random access, only for streaming data & not get power savings
Most important outcomeFacilitates FPGA programming for HPC developerswithout asking them to sacrifice their familiar, C-based programming environment
lower clock speedsFar more efficient implementation, lower power/computation than CPULess general purpose : no cache coherency, logic units are specialized to their task (including # pipeline stages)Only burning power doing things related to computation
3x – 37x, Xeon –O3
HPC kernels, written by HPC developers
Increases & harnesses memory parallelism (multiple caches, multiple mem banks, HW loop opts)Low cache latency (distributed imple w/ caches near their computation blocks)
Banking not effect, loops opts did

Hardware-Compiler Co-Design
30Athena LectureJune 2010
Architectures are changingArchitects often underestimate the effect of the changes on generated code
If work in isolation,• Might optimize for the wrong thing• Might miss opportunities
• For better performance or power• For use of a more appropriate hardware design

HW/SE Co-design
Made an already effective design perform even better• Simultaneous Multithreading w/logo
Make a less effective design publishable• WaveScalar
Couldn’t find a hardware solution• Eliminating false sharing
Was the enabling technology for automatically generating high-performance, low-power caches on an FPGA• Many-cache
All compilers optimizations were a straightforward application of known technology
31
HW/SE co-design important for success of any archWay in which co-design was used to enhance 3 archs
Athena LectureJune 2010
$ $
None were breakthroughs in opt

SMT vs. Chip Multiprocessing
Common Elements: 8 register sets
6.36 IPC 6.35 IPC
One8-issue SMT,
10 FUs
Eight4-issue CPUs,
32 FUs
32Athena LectureJune 2010

Related Work: C for FPGAs
Datapath: • Spatial Dataflow
Memory:• HDLs with C syntax
• Catapult-C, Handel-C
• Functional Languages• Mitrion-C, SA-C, ROCCC
• Streaming• Streams-C, NAPA-C, Impulse-C
• Monolithic cache for non-FPGA reconfigurable substrates• CASH, Tartan
Development Effort
Per
form
ance
CHiMPSCHiMPS
HDLHDL
StreamingStreaming
Functional LanguagesFunctional Languages
33Athena LectureJune 2010
Each one of these has different tradeoffs between performance and development effort
Retain HDL programming model
Also unfamiliar, prevents unfettered memory reuse
In C but restrict how apps can access memory, no random access, no pointers
Cache was the bottleneck, not available commercially
MonolithicCache
MonolithicCache

Target Platform – Xilinx ACP
34
Multi-socket motherboard
Intel 2.66 GHz 4-core Xeon
Xilinx Virtex-5 LX110T• CPU and FPGA are peers
Share the system bus (FSB)• 8.6 GB/s read bandwidth• 5.0 GB/s write bandwidth• 108 ns memory latency
FPGA
CPU CPU Heatsink
Athena LectureJune 2010

Methodology
Firmware for ACP is still under developmentHybrid evaluation methodology
• Component power, performance from microbenchmarks on ACP• Used as input to cycle-accurate simulator
• Area, frequency based on synthesis to ACP’s FPGA• Benchmark results validated with full VHDL implementation of kernels
on prior platform
Benchmarks are generic, unmodified C except:• pragma selects code for FPGA• restrict keyword: specifies that pointers passed as function
parameters are independent
35Athena LectureJune 2010

Coherence in Many-Cache
Coherence protocol is too heavy-weight for many small caches
Only one cache can hold a writable memory location at a time
Flush data from cache to cache between program phases & back to memory when control passes to CPU
36
Main
M
em
or
y
FPG
APEPE
PEPE
PEPE
PEPE
PEPE
PEPE
PEPE
CPUCPU
Ph
ase
1
Flush
Flush
FlushFlush
Ph
ase
2
a
Phase 2b
Load
Load
Athena LectureJune 2010

![Semantics-Aware Trace Analysis [PLDI 2009]](https://static.fdocuments.in/doc/165x107/547a492ab4795995098b4962/semantics-aware-trace-analysis-pldi-2009.jpg)
















