
Comparative study of various Machine Learning methods For Telugu Part of Speech tagging -By...
26
Comparative study of various Machine Learning methods For Telugu Part of Speech tagging -By Avinesh.PVS, Sudheer, Karthik IIIT - Hyderabad
-
Upload
blaze-wells -
Category
Documents
-
view
226 -
download
1
Transcript of Comparative study of various Machine Learning methods For Telugu Part of Speech tagging -By...

Comparative study of various Machine Learning methods For Telugu Part of Speech tagging
-ByAvinesh.PVS, Sudheer, Karthik
IIIT - Hyderabad

Introduction POS-tagging is the process of marking up of words with
their corresponding part of speech.
It is not as simple as having a list of words and their part of speech,
because some words have more than one tag.
This problem is commonly found as huge numbers of word-forms are ambiguous.

Introduction (Cont.)
Building a POS-Tagger for Telugu becomes complicated as Telugu words can be freely formed by agglutinating morphemes.
This increases the no of distinct words.
Ex:
tinu (eat)
tinAli (have to eat)
tintunnADu (eating) {he}
tinAlianukuntunnADu (wants to eat)
……. tinu is common in all the words. We can observe that by the
combination of the morphemes new words are formed.

Introduction (cont.)
This co-occurrence is common for verbs (multiple words joining to
form a single verb). Because of this the number of distinct words increases which in turn decreases the accuracy.

Types of Taggers
Taggers can be characterized as rule-based and statistical based. Rule-based taggers use hand-written rules to
distinguish the tag ambiguity.
Stochastic based taggers uses the probabilities of occurrences of words for a particular tag.
Since Indian languages are morphologically rich in nature, developing rule based taggers is a cumbersome process. But, stochastic taggers require large amount of annotated data to train upon.

Models of Statistical Taggers
We have tried out four different models of statistical taggers.
1. Hidden Markov Model 2. Conditional Random Fields 3. Maximum Entropy Model 4. Memory Based Learning

Hidden Markov Model
The Hidden Markov Model (HMM) is a finite set of states, each of which is associated with a (generally multidimensional) probability distribution.
To implement HMM’s we need three kinds of probabilities. Initial state Probabilities State Transition Probabilities P(t2/t1) Emission Probabilities P(w/t)
Statistical methods of Markov source or the hidden Markov modeling have become increasingly popular in the last several years.

Experiments using HMM’s
HMM is implemented using Tri-ngram-Tagger (TnT).
Experiment 1 :( Trigram) This experiment uses the previous two tags .
i.e. P(t2/t1t0) is used to calculate the best tag sequence. t2 : Current tag
t1 : Previous tag t0 : Previous 2nd tag
Correct Tags : 81.59% Incorrect Tags : 18.41%

Experiments using HMM’s (cont...)
Experiment 2 :( Bi-gram) This experiment uses the tag of the previous tag.
i.e. P(t2/t1) is used to calculate the best tag sequence.
t2 : Current tag t1 : Previous tag
Correct Tags : 82.32%Incorrect Tags : 17.68%

Experiments using HMM’s (cont...)
Experiment 3: (Bi-gram with 1/100th approximation)
By 1/100th approximation it means that it outputs alternate tag if the probability is 1/100th of the best tag
Correct Tags : 82.47%
Incorrect Tags : 17.53%

Conditional Random Fields
A conditional random field (CRF) is a framework of probabilistic model to segment and label sequence data. A conditional model specifies the probabilities of possible label sequences given an observation sequence. The need to segment and label sequences arises in many different
problems in several scientific fields.

Experiments using CRF’s
Conditional random field is implemented using “CRF tool kit” Experiment 1: Features:
Unigram: Current word, Previous 2nd word, Previous word, Next word, Next 2nd word.
Bi-gram: The Previous 2nd word and the Previous word, Previous word and the Current word, and Current word and the next word.
Correct Tags : 75.11%Incorrect Tags: 24.89%

Experiments using CRF’s (cont..)
Experiment 2: Features:
Unigram: Current word, Previous 2nd word, Previous word, Next word, Next 2nd word, and their corresponding first 4 and last 4
letters.Bi-gram: The Previous 2nd word and the Previous word, Previous word and the current word.
Correct Tags : 80.26% Incorrect Tags: 19.74%

Experiments using CRF’s (cont..)
Experiment 3:Features:
Unigram: Current word, Previous 2nd word, Previous word, and their corresponding first 3 and last 3 letters.
Bi-gram: The Previous 2nd word and the Previous word, Previous word and the current word.
Correct Tags : 80.55%Incorrect Tags: 19.45%

Maximum Entropy Model
The principle of maximum entropy (Ratnaparakhi, 1999) states that when one has only partial information about the probabilities of possible outcomes of an experiment, one should choose the probabilities so as to maximize the uncertainty about the missing information. In other way, since entropy is a measure of randomness, one should choose the most random distribution subject to whatever constraints are imposed on the problem.

Experiments using MEMM’s
Maximum Entropy Markov Model is implemented using “Maxent”.
Experiment 1:Features: (Unigram)
Current word, Previous 2nd word, Previous word, Previous 2nd words Tag, Previous words Tag, Next word, Next 2nd word, first and last 4 letters of the Current word.
Correct Tags : 80.3%Incorrect Tags : 19.69%

Experiments using MEMM’s (cont..)
Experiment 2:Features:
Current word, Previous 2nd word with its tag, Previous word with its tag, Previous 2nd words tag with Previous words tag , suffixes and prefixes for rare words (with frequency less
than 2).
Correct Tags : 80.09%Incorrect Tags: 19.9%

Experiments using MEMM’s (cont..)
Experiment 3:
Features: Current word, Previous 2nd word with its tag, Previous word with its tag, Previous 2nd words tag with previous words tag, Suffixes and prefixes for all words .
Correct Tags : 82.27%
Incorrect Tags : 17.72%

Memory Based Learning
Memory-based tagging is based on the idea that words occurring in similar contexts will have the same POS tag.
MBL consists of two components: A learning component which is memory-based A performance component which is similarity-based.
The learning component of MBL is memory-based as it involves adding training examples to memory.
In the performance of an MBL system, the product of the learning component is used as a basis for mapping input to output.

Experiments using MBL’s
Memory based learning is implemented using Timbl .
Experiment 1: Using IB1 Algorithm
Correct Tags : 75.39% Incorrect Tags: 24.61%
Experiment 2: Using IGTREE Algorithm
Correct Tags : 75.75%Incorrect Tags : 24.25%

Overall results
Model Result (%)
HMM 82.47
MEMM 82.27
CRF 80.55
MBL 75.75
• The results for the Telugu data was low compared to other languages due to the less availability of annotated data(27336).
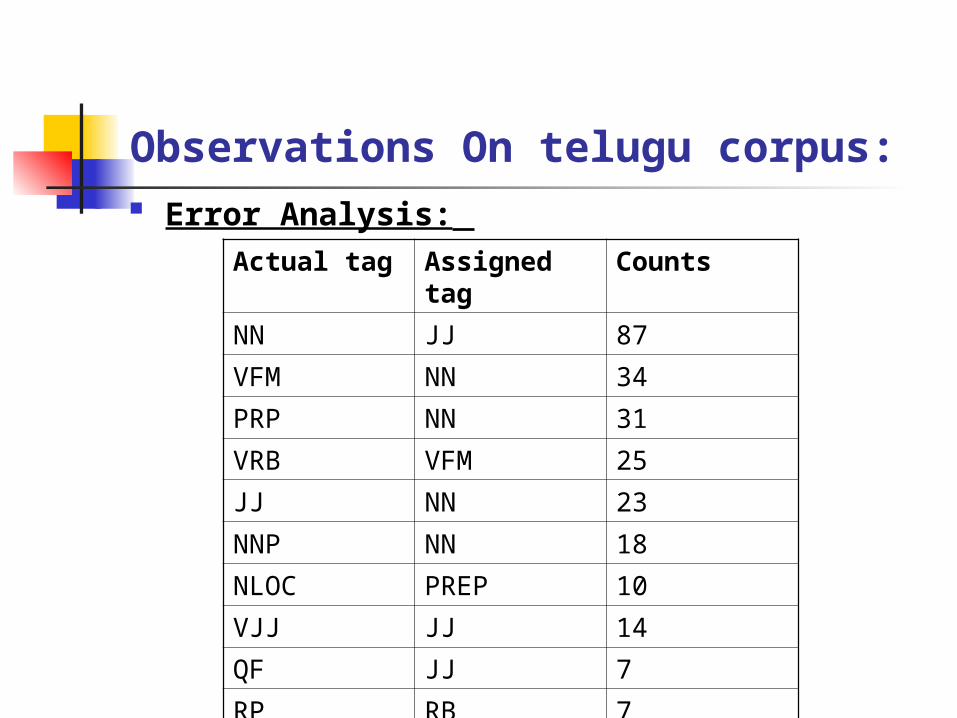
Observations On telugu corpus: Error Analysis:
Actual tag Assigned tag Counts
NN JJ 87
VFM NN 34
PRP NN 31
VRB VFM 25
JJ NN 23
NNP NN 18
NLOC PREP 10
VJJ JJ 14
QF JJ 7
RP RB 7

Observations On Telugu corpus(cond.)
In the Telugu corpus of 27336 words 9801 distinct words are found.
If we see the count of number of words with low frequency, say with the frequency of 1, we find 7143 words.
This is due to the morphological richness in the language.
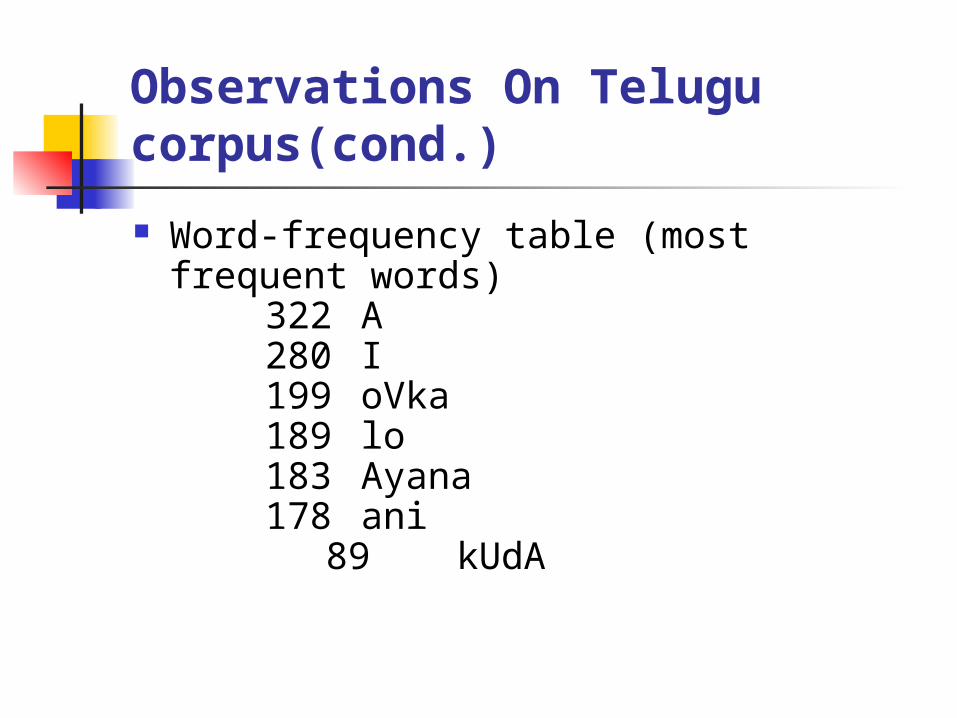
Observations On Telugu corpus(cond.)
Word-frequency table (most frequent words)322 A280 I199 oVka189 lo183 Ayana178 ani
89 kUdA

Conclusion
The accuracy of the Telugu POS Tagging seemed to be low when compared to other Indian Languages due to agglutinative nature of the language.
One could explore using Morphological analyzer by splitting verb part and the morphemes to minimize the distinct words.

Thank you

















