
COMP381 by M. Hamdi 1 Commercial Superscalar and VLIW Processors.
33
1 COMP381 by M. Hamdi Commercial Commercial Superscalar and Superscalar and VLIW Processors VLIW Processors
-
date post
22-Dec-2015 -
Category
Documents
-
view
230 -
download
0
Transcript of COMP381 by M. Hamdi 1 Commercial Superscalar and VLIW Processors.

1COMP381 by M. Hamdi
CommercialCommercial Superscalar and Superscalar and VLIW ProcessorsVLIW Processors

2COMP381 by M. Hamdi
Superscalar Processors
0-8 instruction per cycleStatic scheduling
all pipe line hazards are checkedinstructions in order
Pipeline control logic will check hazards between the instructions in execution phase and the new instruction sequences. In case of hazard, only those instructions preceding that one in the instruction sequence will be issued.
Issue HWPipeline
Instruction Memory
Issue Packet
Complexity of HWThis stage is pipelined in all dynamic super scalar system

3COMP381 by M. Hamdi
Example: Superscalar of degree 3
fetch decode execute write back

4COMP381 by M. Hamdi
Cache/Cache/MemoryMemory
Fetch Fetch UnitUnit
EUEU
EUEU
EUEU
Register FileRegister FileMulti Operation
Multiple Instruction
Instruction
Basic Superscalar Approach
Decode/Decode/Issue Issue UnitUnit

5COMP381 by M. Hamdi
1Fetch
2Fetch
3Decode
4Decode
5Decode
6Rename
7ROB Rd
8Rdy/Sch
9Dispatch
10Exec
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Typical P6 Pipeline
Typical Pentium 4 Pipeline
Pentium 4 Pipeline Stages vs. Pentium 3 Pipeline Stages

6COMP381 by M. Hamdi
Pentium 3 Pipeline Architecture
• It is a It is a 3-way3-way issue supersclar issue supersclar
• It has 5 execution units (Integer ALU, integer multiply, FP It has 5 execution units (Integer ALU, integer multiply, FP multiply, FP add, FP divide)multiply, FP add, FP divide)

7COMP381 by M. Hamdi
Pentium 3 Pipeline stages
1 Fetch
2 Fetch
3 Decode
4 Decode
5 Decode
6 Rename registers
7 ROB (reordering instructions)
8 Rdy/Sch (Scheduling Instructions to be executed)
9 Dispatch
10 Exec

8COMP381 by M. Hamdi
Pentium 4 pipeline stages
Stage Work
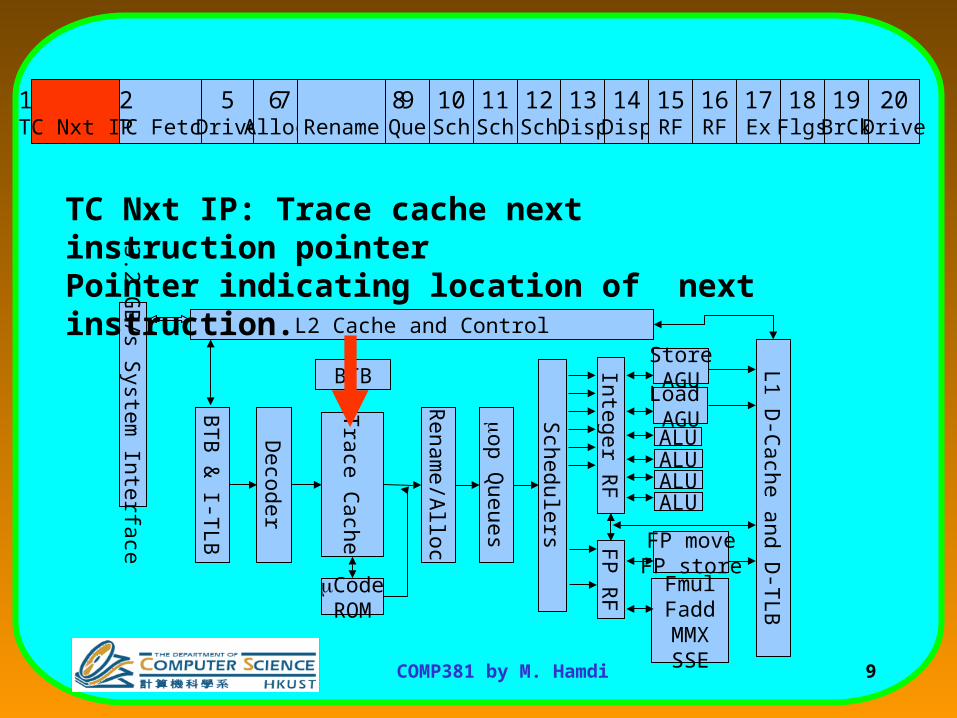
1 Trace Cache next instruction pointer
2 Trace Cache next instruction pointer
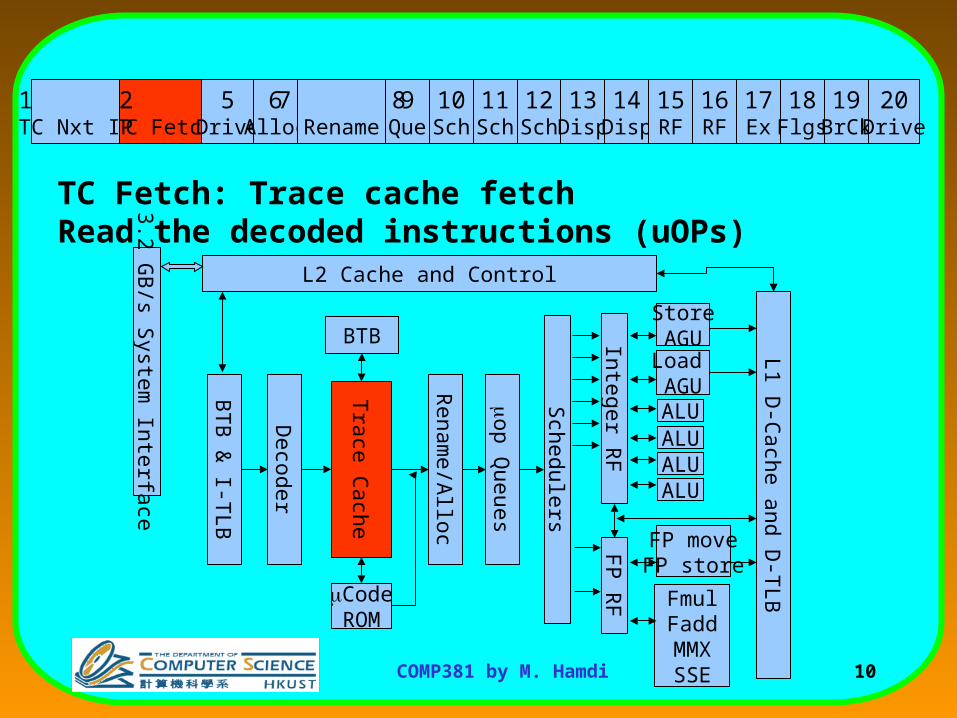
3 Trace Cache fetch
4 Trace Cache fetch
5 Drive
6 Allocation
7 Rename
8 Rename
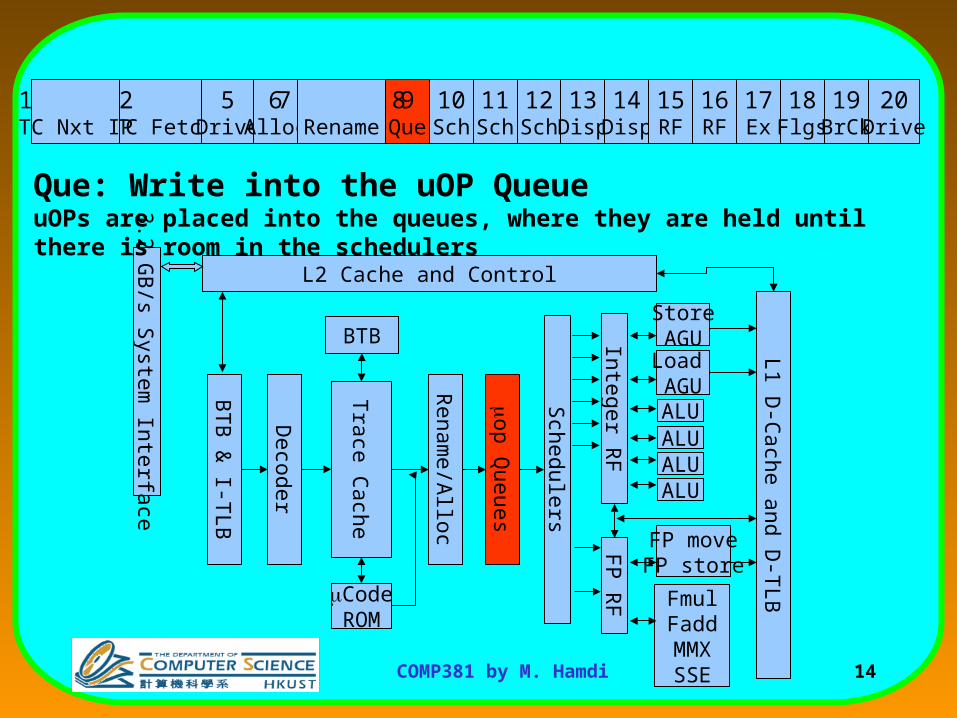
9 Queue
10 Schedule
11 Schedule
12 Schedule
13 Dispatch
14 Dispatch
15 Register Files
16 Register Files
17 Execute
18 Flags
19 Branch Check
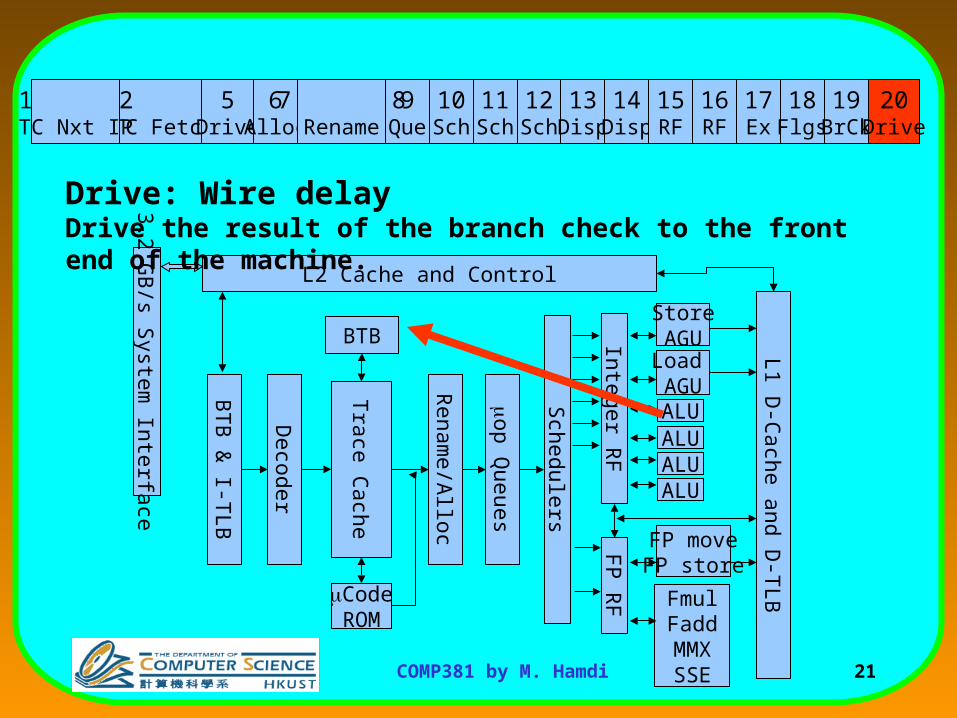
20 Drive
Increasing the number of pipeline stages increases the clock frequency
• It took the industry 28 years to hit 1 GHz and only 18 months to reach 2 GHz.
• The price paid for deeper pipelines is that it is very difficult to ovoid stalls (That is why when Pentium 4 was introduced its performance was worse than Pentium 3.)
It is a 5-issue supersclar It is a 5-issue supersclar processorprocessor
9COMP381 by M. Hamdi
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
BTC Nxt IP: Trace cache next instruction pointerPointer indicating location of next instruction.
10COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
TC Fetch: Trace cache fetchRead the decoded instructions (uOPs)

11COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Drive: Wire delayDrive the uOPs to the allocator

12COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Alloc: Allocate resources required for execution. Theresources include Load buffers, Store buffers, etc..

13COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Rename: Register renaming
14COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Que: Write into the uOP QueueuOPs are placed into the queues, where they are held until there is room in the schedulers

15COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Sch: ScheduleWrite into the schedulers and compute dependencies. Watch for dependency to resolve.

16COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Disp: DispatchSend the uOPs to the appropriate execution unit.

17COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
RF: Register FileRead the register file. These are the source(s) for the pending operation (ALU or other).

18COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Ex: ExecuteExecute the uOPs on the appropriate execution port.

19COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Flgs: FlagsCompute flags (zero, negative, etc..). These are typically input to a branch instruction.

20COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Br Ck: Branch CheckThe branch operation compares result of actual branch direction with the prediction.
21COMP381 by M. Hamdi
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Drive: Wire delayDrive the result of the branch check to the front end of the machine.

22COMP381 by M. Hamdi
CommercialCommercial EPIC EPIC ProcessorsProcessors
ItaniumItanium

23COMP381 by M. Hamdi
Itanium® Processor Family Architecture•EPIC: explicitly parallel instruction computing
•Instruction encoding•Bundles and templates
•Large register resources •128 integer
•128 floating point
•Support for•Software pipelining
•Predication
•Speculation (Control, Data, Load)

24COMP381 by M. Hamdi
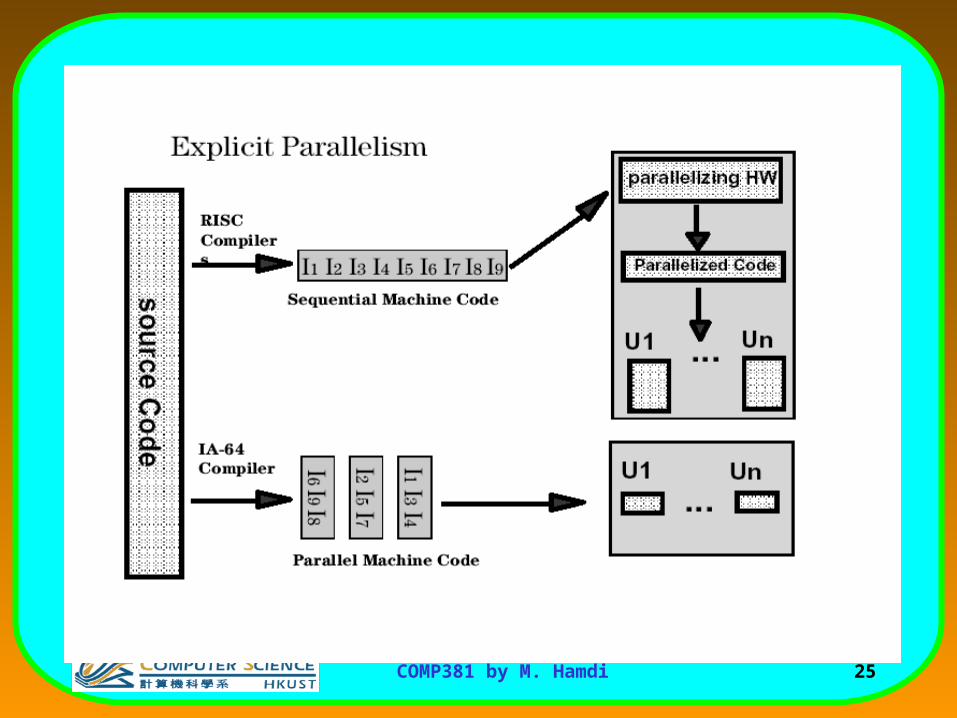
EPIC – Explicitly Parallel Instruction Computing
•Focused on parallel execution
•Instructions are issued in bundles
•Instructions distributed among processor’s execution units according to type
•Currently up to two complete bundles can be dispatched per clock cycle
– Pipeline stages: 10 (Itanium®1), 8 (Itanium® 2)
25COMP381 by M. Hamdi

26COMP381 by M. Hamdi
Instruction Format: Bundles & Templates
•Bundle•Set of three instructions (41 bits each)
•Template •Identifies types of instructions in bundle

27COMP381 by M. Hamdi
Instruction Format: Bundles & Templates
•Instruction types
– M: Memory
– I: Shifts and multimedia
– A: Integer Arithmetic and Logical Unit
– B: Branch
– F: Floating point
– L+X: Long (move, branch, …)

28COMP381 by M. Hamdi
MEM MEM INT INT FP FP B B B
128-bit instruction bundles from I-cacheS2 S1 S0 T
Fetch one or more bundles for execution(Implementation, Itanium® takes two.)
Try to execute all instructions inparallel, depending on available units.
Retired instruction bundles
Processor
Explicitly Parallel Instruction ComputingEPIC
functional units
MEM MEM INT INT FP FP B B B

29COMP381 by M. Hamdi
instrinstrinstr ;;instrinstr ;;instrintsrinstrinstrinstr ;;instrinstr ;;instr…
instr instr instr tmplinstr instr instr tmplinstr instr nop tmplinstr nop nop tmplinstr instr nop tmplinstr instr nop tmplintsr instr instr tmpl…
instr instr instr tmplinstr instr instr tmpl
Handwritten code
Code generator
Instruction bundles
FetchExecution
Code generator creates bundles,possibly including nops.
Can the bundle pairExecute in parallel ?
Itanium® fetches 2 bundles at a time for execution.They may or may not execute in parallel.
There are two difficulties:1) Finding instruction triplets matching the defined templates.2) Matching pairs of bundles that can execute in parallel.

30COMP381 by M. Hamdi
Today‘s Architecture Challenges
•Performance barriers :
- Memory latency
- Branches
- Loop pipelining and call / return overhead
- Hardware-based instruction scheduling
- Unable to efficiently schedule parallel execution
- Too few registers
- Unable to fully utilize multiple execution units

31COMP381 by M. Hamdi
Improving Performance
•To achieve improved performance, Itanium(R) architecture code accomplishes the following:- Increases instruction level parallelism (ILP)
- Improves branch handling
- Hides memory latencies

32COMP381 by M. Hamdi
Instruction level parallelism (ILP)
•Increase ILP by:•More resources
• Large register files
• Avoiding register contention
•3-instruction wide word• Bundle
• Facilitates parallel processing of instructions
•Enabling the compiler/assembly writer to explicitly indicate parallelism

33COMP381 by M. Hamdi
Itanium 8-stage Pipelines
• In-order issue, out-of-order completion– All functional units are fully pipelined
• Small branch misprediction penalties
FP1 FP2
IPG ROT
Inst
ruct
ion
Bu
ffe
r
EXP REN REG
MM1 MM2
EXE DET WRB
L1D1 L1D2 L1D3
FP3 FP4
MemoryMemory
IntInt
MultiMediaMultiMedia
Floating PointFloating Point


















