
COE 509 Parallel Numerical Computing Lecture 4: The Future of Numerical Linear Algebra Libraries:...
35
COE 509 Parallel Numerical Computing Lecture 4: The Future of Numerical Linear Algebra Libraries: Automatic Tuning of Sparse Matrix Kernels The Next LAPACK and ScaLAPACK
-
Upload
jessie-berry -
Category
Documents
-
view
218 -
download
4
Transcript of COE 509 Parallel Numerical Computing Lecture 4: The Future of Numerical Linear Algebra Libraries:...

COE 509
Parallel Numerical Computing
Lecture 4: The Future of Numerical Linear Algebra Libraries: Automatic Tuning of
Sparse Matrix KernelsThe Next LAPACK and ScaLAPACK

OSKI: Optimized Sparse Kernel Interface
Richard Vuduc (LLNL), James Demmel, Katherine Yelick
Hormozd Gahvari, Mark Hoemmen, Ankit Jain, Ben Lee, Scott Lindeneau, Rajesh Nishtala, Wei Tu
Berkeley Benchmarking and OPtimization (BeBOP) Projectbebop.cs.berkeley.eduEECS Department, University of California, Berkeley

Motivation for Automatic Performance Tuning
• Sparse matrix operations consume most solver time– Sparse matrix-vector multiply (SpMV)– SpMV: runs at 10% of machine peak or less
• Improving SpMV’s performance is hard– Performance depends on machine, kernel, matrix– Matrix known at run-time– Best data structure + implementation can be surprising– Tuning becoming more difficult over time
• Our approach: empirical modeling and search– Up to 4x speedups and 31% of peak for SpMV– Several other kernels: triangular solve, ATA*x, Ak*x– Proof-of-concept: Demonstrate with Omega3P, T3P– OSKI Library released, will be integrated into PETSc

Motivation: Tuning is difficult
• n = 21216• nnz = 1.5 M• kernel: SpMV
• Source: NASA structural analysis problem
• 8x8 dense substructure
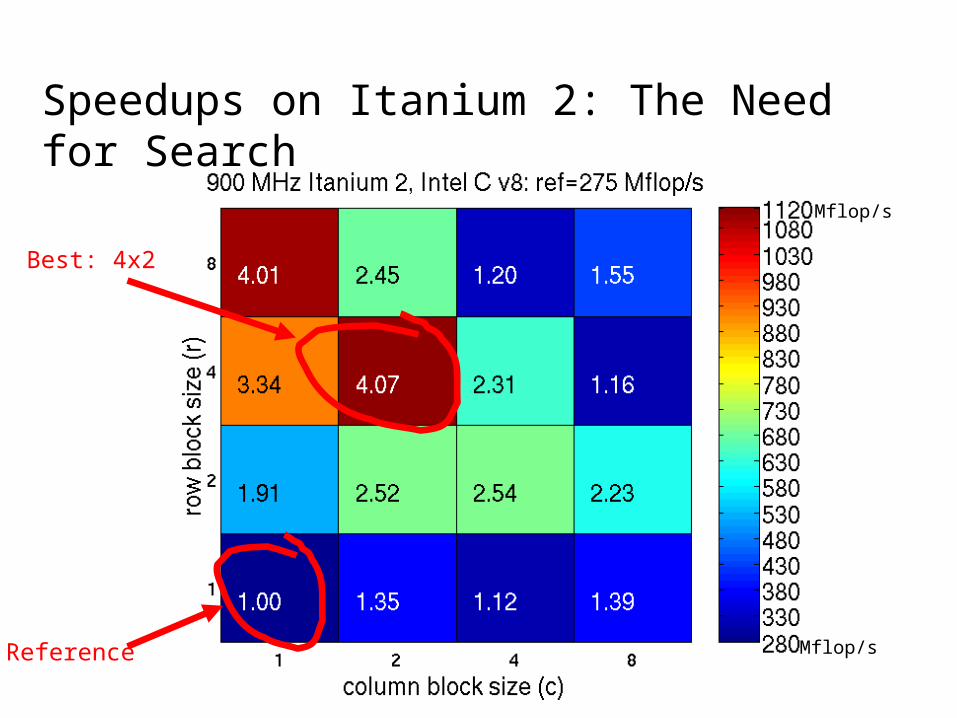
Speedups on Itanium 2: The Need for Search
Reference
Best: 4x2
Mflop/s
Mflop/s
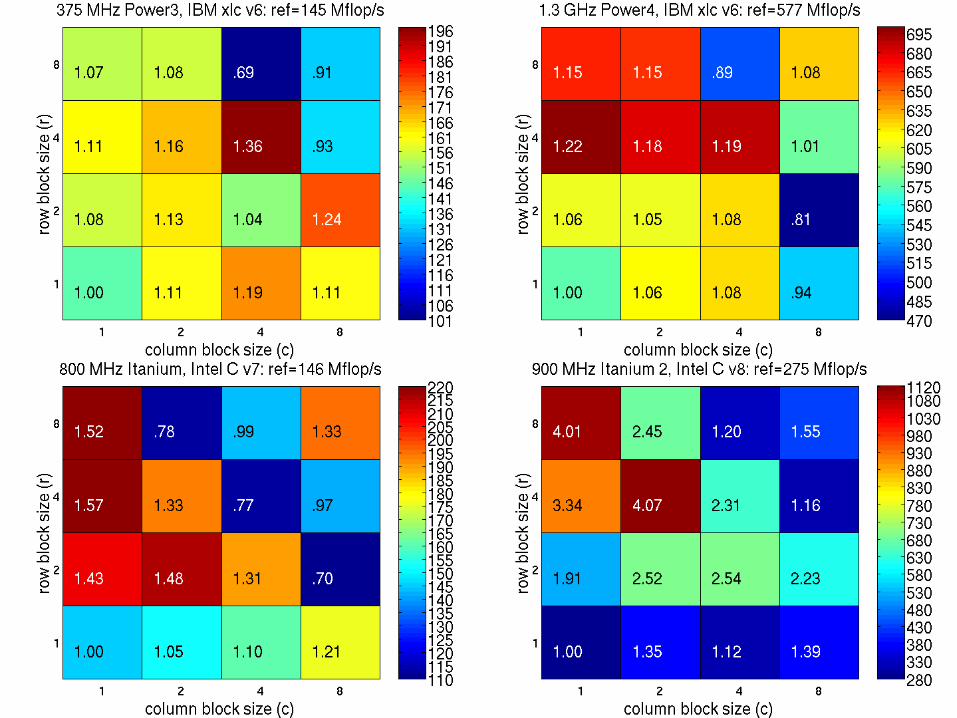
SpMV Performance—raefsky3
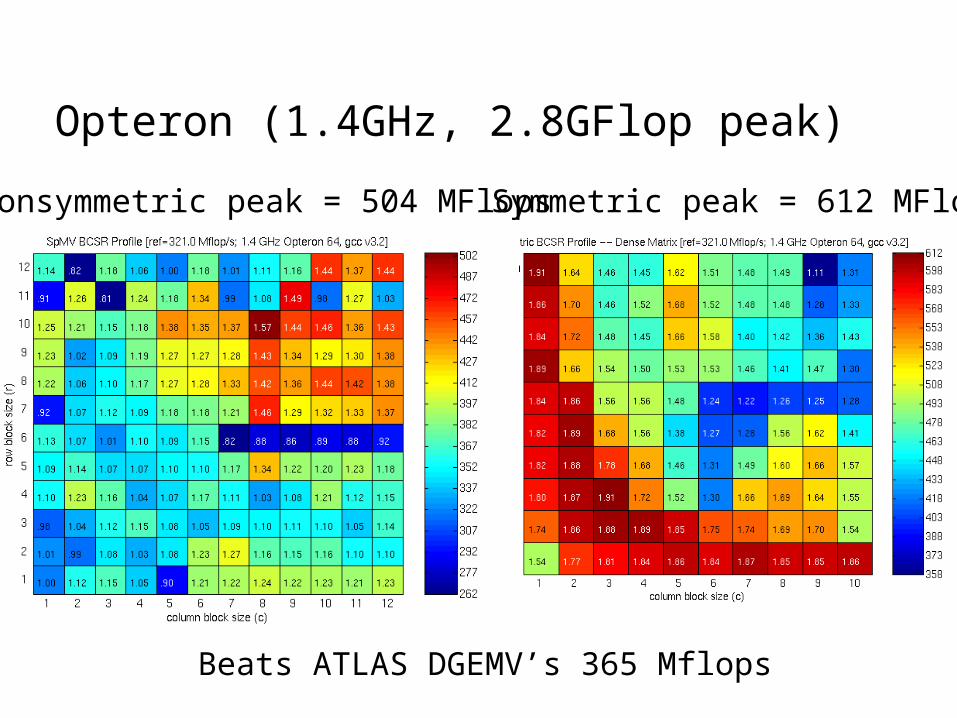
Symmetric peak = 612 MFlops
Opteron (1.4GHz, 2.8GFlop peak)
Beats ATLAS DGEMV’s 365 Mflops
Nonsymmetric peak = 504 MFlops
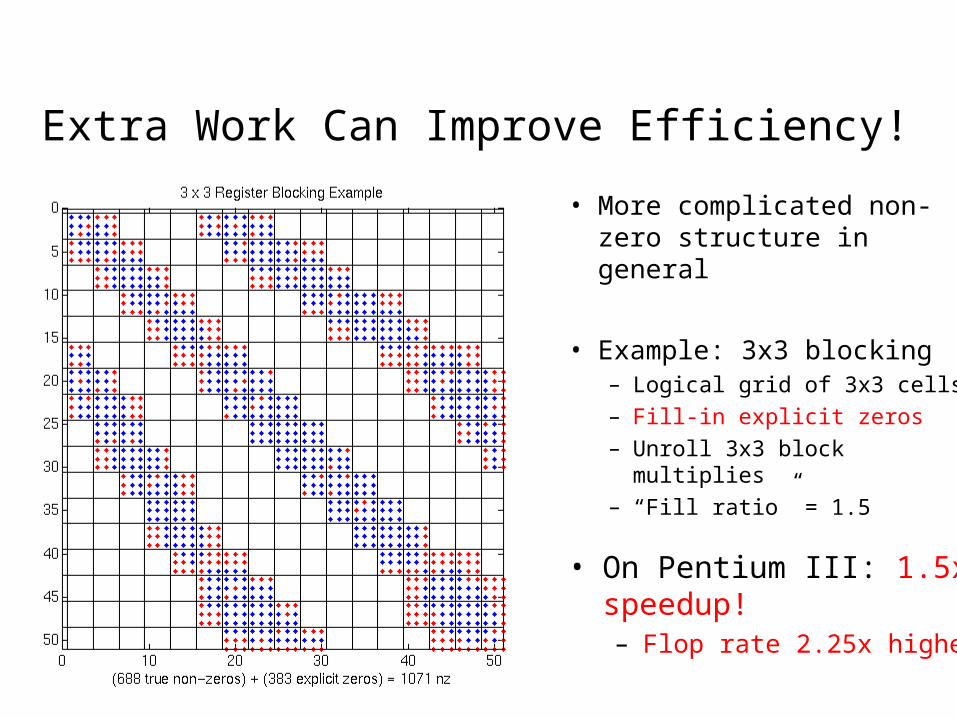
Extra Work Can Improve Efficiency!
• More complicated non-zero structure in general
• Example: 3x3 blocking– Logical grid of 3x3 cells
– Fill-in explicit zeros
– Unroll 3x3 block multiplies
– “Fill ratio” = 1.5
• On Pentium III: 1.5x speedup!– Flop rate 2.25x higher

OSKI: Optimized Sparse Kernel Interface
• Sparse kernels tuned for user’s matrix & machine– Hides complexity of run-time tuning – Low-level BLAS-style functionality
• Sparse matrix-vector multiply (SpMV), triangular solve (TrSV), …
– Includes fast locality-aware kernels: ATAx, …– Initial target: cache-based superscalar uniprocessors
• For “advanced” users & solver library writers– Available as stand-alone open-source library (BSD
license)– PETSc extension in progress
• Written in C (can call from Fortran)

Optimizations Available in the Initial Release
• Optimizations for SpMV (bold heuristics)– Register blocking (RB): up to 4x over CSR– Variable block splitting: 2.1x over CSR, 1.8x over RB– Diagonals: 2x over CSR– Reordering to create dense structure + splitting: 2x over
CSR– Symmetry: 2.8x over CSR, 2.6x over RB– Cache blocking: 3x over CSR– Multiple vectors (SpMM): 7x over CSR– And combinations…
• Sparse triangular solve– Hybrid sparse/dense data structure: 1.8x over CSR
• Higher-level kernels– AAT*x, ATA*x: 4x over CSR, 1.8x over RB– A*x: 2x over CSR, 1.5x over RB

How OSKI Tunes (Overview)
Benchmarkdata
1. Build forTargetArch.
2. Benchmark
Heuristicmodels
1. EvaluateModels
Generatedcode
variants
2. SelectData Struct.
& Code
Library Install-Time (offline) Application Run-Time
To user:Matrix handlefor kernelcalls
Workloadfrom program
monitoring HistoryMatrix

Cost of Tuning
• Non-trivial run-time tuning cost: up to ~40 mat-vecs– Dominated by conversion time
• User calls “tune” routine explicitly– Exposes cost– Tuning time limited using estimated workload
• Provided by user or inferred by library• User may save tuning results
– To apply on future runs with similar matrix– Stored in “human-readable” format

Features
• Explicit Hints– Can suggest particular tuning technique
• Implicit Tuning: Ask library to infer workload– Library profiles all kernel calls– May periodically re-tune
• Scripting language for selecting customized transformations– Mechanism to save/restore transformations
• “Plug-in” extensibility– Very advanced users may customize library (at run-time)

Example applications
• T3P – Accelerator Design – Ko– Register blocking, Symmetric Storage, Multiple
vector– 1.68x faster on Itanium 2 for one vector– 4.4x faster for 8 vectors
• Omega3P – Accelerator Design – Ko– Register blocking, Symmetric storage, Reordering– 2.1x faster on Power4
• Semiconductor Industry: – 1.9x speedup over SPOOLES in CG at design firm

Current and Future Work (1)
• Release 1.0 and docs available at bebop.cs.berkeley.edu/oski– Comments on interface welcome!
• Future work– PETSc integration– Port to additional architectures
• Vectors• SMPs• Distributed memory
– Additional tuning heuristics

Current and Future Work (2)
• Incorporation into HPCS Benchmark– Evaluate platforms based on tuned SpMV
performance
• Tuning higher level algorithms and kernels like [Ax,A2x,…,Akx]– Models indicate large speedups possible
• Tuning collective communication routines– 2x speedups in NAS FT using UPC/GASNet

Awards• Best Paper, Intern. Conf. Parallel Processing, 2004
– “Performance models for evaluation and automatic performance tuning of symmetric sparse matrix-vector multiply”
• Best Student Paper, Intern. Conf. Supercomputing, Workshop on Performance Optimization via High-Level Languages and Libraries, 2003– Best Student Presentation too, to Richard Vuduc– “Automatic performance tuning and analysis of sparse triangular solve”
• Finalist, Best Student Paper, Supercomputing 2002– To Richard Vuduc– “Performance Optimization and Bounds for Sparse Matrix-vector Multiply”
• Best Presentation Prize, MICRO-33: 3rd ACM Workshop on Feedback-Directed Dynamic Optimization, 2000– To Richard Vuduc– “Statistical Modeling of Feedback Data in an Automatic Tuning System”

The Future of LAPACK and ScaLAPACK
www.netlib.org/lapack-dev
Jim Demmel - UC BerkeleyJack Dongarra – U Tennessee Knoxville

Outline• Motivation• Participants • Goals
1. Better numerics (faster and more accurate algorithms)
2. Expand contents (more functions, more parallel implementations)
3. Improve ease of use4. Better software engineering5. Automate performance tuning 6. Better maintenance and support7. Increase community involvement
• Questions for the audience

Motivation
• LAPACK and ScaLAPACK are widely used– Adopted by Cray, Fujitsu, HP, IBM, IMSL, MathWorks, NAG,
NEC, SGI, …– >50M web hits @ Netlib (incl. CLAPACK, LAPACK95)
• Many ways to improve them, based on– Own algorithmic research– Enthusiastic participation of research community– On-going user/vendor survey (url below)– Opportunities and demands of new architectures,
programming languages– DOE SciDAC needs
• New releases planned (NSF support)• Your feedback desired
– www.netlib.org/lapack-dev

Success Stories (with NERSC, LBNL)
Cosmic Microwave Background Analysis, BOOMERanG collaboration, MADCAP code
ScaLAPACK
>250 users of ScaLAPACK and LAPACK at NERSC, 2005

Participants
• UC Berkeley:– Jim Demmel, Ming Gu, W. Kahan, Beresford Parlett, Xiaoye Li,
Osni Marques, Christof Voemel, David Bindel, Yozo Hida, Jason Riedy, Jianlin Xia, Jiang Zhu, undergrads…
• U Tennessee, Knoxville– Jack Dongarra, Victor Eijkhout, Julien Langou, Julie Langou, Piotr
Luszczek, Stan Tomov• Other Academic Institutions
– UT Austin, UC Davis, Florida IT, U Kansas, U Maryland, North Carolina SU, San Jose SU, UC Santa Barbara
– TU Berlin, FU Hagen, U Madrid, U Manchester, U Umeå, U Wuppertal, U Zagreb
• Research Institutions– CERFACS, LBL
• Industrial Partners – Cray, HP, Intel, MathWorks, NAG, SGI

Goal 1 – Better Numerics
• Fastest algorithm providing “standard” backward stability– MRRR algorithm for symmetric eigenproblem / SVD:
Parlett / Dhillon / Voemel / Marques / Willems– Up to 10x faster HQR: Byers / Mathias / Braman– Extensions to QZ: Kågström / Kressner– Faster Hessenberg, tridiagonal, bidiagonal reductions:
van de Geijn, Bischof / Lang , Howell / Fulton– Recursive blocked layouts for packed formats:
Gustavson / Kågström / Elmroth / Jonsson/

Goal 1 – Better Numerics
• Fastest algorithm providing “standard” backward stability– MRRR algorithm for symmetric eigenproblem / SVD:
Parlett / Dhillon / Voemel / Marques / Willems– Up to 10x faster HQR: Byers / Mathias / Braman– Extensions to QZ: Kågström / Kressner– Faster Hessenberg, tridiagonal, bidiagonal reductions:
van de Geijn, Bischof / Lang , Howell / Fulton– Recursive blocked layouts for packed formats:
Gustavson / Kågström / Elmroth / Jonsson/
• New: Most accurate algorithm providing “standard” speed – Iterative refinement for Ax=b, least squares
• Assume availability of Extra Precise BLAS (Li/Hida/…)• www.netlib.org/blas/blast-forum/
– Retirement of QR-based SVD: Drmac/Veselic

Goal 1 – Better Numerics
• Fastest algorithm providing “standard” backward stability– MRRR algorithm for symmetric eigenproblem / SVD:
Parlett / Dhillon / Voemel / Marques / Willems– Up to 10x faster HQR: Byers / Mathias / Braman– Extensions to QZ: Kågström / Kressner– Faster Hessenberg, tridiagonal, bidiagonal reductions:
van de Geijn, Bischof / Lang , Howell / Fulton– Recursive blocked layouts for packed formats:
Gustavson / Kågström / Elmroth / Jonsson/
• New: Most accurate algorithm providing “standard” speed – Iterative refinement for Ax=b, least squares
• Assume availability of Extra Precise BLAS (Li/Hida/…)• www.netlib.org/blas/blast-forum
– Retirement of QR - based SVD: Drmac/Veselic
• What is not fast or accurate enough?

What goes into Sca/LAPACK?
For all linear algebra problems
For all mathematical structures
For all data structures and types
For all programming models (SW & HW)
Produce a (stable, tuned) algorithm (including condition estimates, etc)
Need to prioritize
PerhapsAutomate?

Goal 2 – Expanded Content
• Ideal: Make content of ScaLAPACK mirror LAPACK as much as possible
• Add New functions (examples)– Updating / downdating of factorizations: Stewart,
Langou– More generalized SVDs: Bai , Wang– More generalized Sylvester/Lyapunov eqns:
Kågström, Jonsson, Granat– Structured eigenproblems
• O(n2) version of roots(p) – Gu, Chandrasekaran, Zhu et al• Selected matrix polynomials: Mehrmann, Bai
• How should we prioritize missing functions?

Goal 3: Improved Ease of Use (1)
• Which interface do you prefer?
A \ B
CALL PDGESVX( FACT, TRANS, N ,NRHS, A, IA, JA, DESCA, AF, IAF, JAF, DESCAF, IPIV, EQUED, R, C, B, IB, JB, DESCB, X, IX, JX, DESCX, RCOND, FERR, BERR, WORK, LWORK, IWORK, LIWORK, INFO)
• It depends on who you ask.

Goal 3: Improved Ease of Use (2)• Support both experts and “typical” users (more of latter!)• Easy interfaces vs access to details & performance
– No universal agreement on “easiest interface”• Leave decision to higher level packages
– Expert users want access to details• Higher performance, own storage management,
numerical issues– “Typical” users want simplicity, even if lower performance
• Tentative decision (depends on community feedback)– Keep simple driver / expert driver / computational routines– Coordinate with higher level tool builders for usability
• PETSc, Matlab, …– Add matrix redistribution routines to ScaLAPACK to handle
general input layouts without performance penalties

Goal 4: Better Software Engineering (1)• Ideal
– Express all algorithms in “high level form” – Generate all implementations (different HW & SW)
automatically– Automatic tuning too
• Reality– Need good tools now to produce useful code in 3-4
years– No fully adequate tools exist (open research
question)• Telescoping languages, FLAME, Bernoulli, …

Goal 4: Better Software Engineering (2)
• Tentative Proposal for new LAPACK– F95 core using subset of F95 features– “Friendly” wrappers in multiple languages
•Use Babel, CCA– How much performance would we lose by
relegating all SMP / Multicore parallelism to BLAS?•Need experimental data

Goal 4: Better Software Engineering (3)• ScaLAPACK is more demanding
– LAPACK on large and changing set of architectures and communication networks
– Large software design space• Languages: F95, CAF, UPC, …• Communication substrates: MPI (many flavors), GASNet, …• Programming styles: BSP, aggressive overlap of
communication & computation, …– Many architectures (should track hardware)
• Sequential, multicore, SMP, Distributed memory– As function of algorithm, n, p, architecture, software
• What is tradeoff between performance and programming effort?
• Collecting data to decide what to do• How should we tradeoff performance and SWE?
– Some users value performance more than others– Higher performance may mean fewer routines produced

Goal 5 – Automate Performance Tuning
• Not just BLAS• Many calls to ILAENV() to get block sizes, etc.
– Not systematically tuned for new architectures
• Extend automatic tuning techniques of ATLAS, etc. to these other parameters– Automation important as architectures evolve

Conclusions and Questions
• Lots to do in Dense Linear Algebra– New numerical algorithms– Continuing challenges
• Parallelism, performance tuning, software engineering
• Questions– What (new) functions are most important to include
in Sca/LAPACK?– How should we tradeoff performance / accuracy /
ease of SWE?

The End
bebop.cs.berkeley.edu
www.netlib.org/lapack-dev


















