
Clustering and Search Techniques in Information Retrieval Systems
39
Karumuri Sri Rama Murthy, Associate Mentor & Research Scholoar, MSIT, School of IT, JNTU Hyderabad. Text Book: Information Storage and Retrieval Systems - Gerald J Kowalski, Mark T Maybury
-
Upload
karumuri-sri-rama-murthy -
Category
Documents
-
view
150 -
download
1
description
Good Resource to Teach Clustering techniques
Transcript of Clustering and Search Techniques in Information Retrieval Systems

Karumuri Sri Rama Murthy,Associate Mentor & Research Scholoar,
MSIT, School of IT, JNTU Hyderabad.
Text Book: Information Storage and Retrieval Systems - Gerald J Kowalski, Mark T Maybury

Finds overall similarities among groups of documents
Finds overall similarities among groups of documents
Picks out some themes, ignores others

“Similar documents tend to be relevant to the same requests”
Issues:◦ Variants: “Documents that are relevant to the
same topics are similar”◦ Simple vs. complex topics◦ Evaluation, prediction
The cluster hypothesis is the main motivation behind document clustering

Document representative◦ Select features to characterize document: terms,
phrases, citations◦ Select weighting scheme for these features:
Binary, raw/relative frequency, divergence measure Title / body / abstract, controlled vocabulary, selected
topics, taxonomy Similarity / association coefficient or
dissimilarity / distance metric

Simple matching
Dice’s coefficient
Cosine coefficient
i
iiyx
i iii
iii
yx
yx22
2
i iii
iii
yx
yx22
YX
YX
YX
YX
2
YX

Non-hierarchic methods=> partitions◦ High efficiency, low effectiveness
Hierarchic methods=> hierarchic structures - small clusters of highly
similar documents nested within larger clusters of less similar documents
◦ Divisive => monothetic classifications◦ Agglomerative => polythetic classifications !!

Generic procedure:◦ The first object becomes the first cluster◦ Each subsequent object is matched against
existing clusters It is assigned to the most similar cluster if the
similarity measure is above a set threshold Otherwise it forms a new cluster
◦ Re-shuffling of documents into clusters can be done iteratively to increase cluster similarity

Generic procedure:◦ Each doc to be clustered is a singleton cluster◦ While there is more than one cluster, the clusters
with maximum similarity are merged and the similarities recomputed
A method is defined by the similarity measure between non-singleton clusters
Algorithms for each method differ in:◦ Space (store similarity matrix ? all of it ?)◦ Time (use all similarities ? use inverted files ?)


How it works◦ Cluster sets of documents into general “themes”,
like a table of contents ◦ Display the contents of the clusters by showing
topical terms and typical titles◦ User chooses subsets of the clusters and re-
clusters the documents within ◦ Resulting new groups have different “themes”
Originally used to give collection overview
Evidence suggests more appropriate for displaying retrieval results in context



The goal of the clustering was to assist in the location of information. This eventually lead to indexing schemes used in organization of items in libraries and standards associated with use of electronic indexes. Clustering of words originated with the generation of thesauri.

There are two types of clustering:
1. Manual Clustering2. Automatic Term Clustering
Manual Clustering:
◦ The First step in the process would be the determination of domain for CLUSTERING which helps in reducing ambiguities that can be caused by homographs.
◦ Words for the new thesaurus are taken from existing thesauri. In the existing thesauri, the concordances from items that cover the domain are used.
◦ The art of construction of manual thesaurus would lie in the selection of words that should be included in it.
◦ Care should be taken that some words should not included such as: Unrelated to the domain of thesauraus Words with high frequency but no information value.

If a concordance is used, other tools such as KWOC, KWIC or KWAC may help in determining useful words. A Key Word Out of Context (KWOC) is another name for a concordance. Key Word In Context(KWIC)displays a possible term in its phrase context.
It is structured to identify easily the location of the term under consideration in the sentence.
Key Word And Context(KWAC) displays the keywords followed by their context.

The KWIC and KWAC are useful in determiningthe meaning of homographs. The term “chips” could be wood chips or memorychips. In both the KWIC and KWAC displays, the editor of the thesaurus can read the sentence fragment associated with the term and determine its meaning.

To create Thesauri, there are many techniques of generating the Term Clusters automatically.
The basis of all those techniques is that if two terms co-occur in the same item frequently then the two terms are about the same concept.
The relationship between all combinations of “n” unique words within the overhead of O(n2 ) is computed by most complete process.
A hierarchy can be created when the number of clusters are generated are very large would be repeated. It can be done by making the initial clusters as the starting point.

The clustering effort should be defined with a domain. To determine the attributes of the objects.(Specific Zones are
focused, reduce errors among relationships) To determine the strength of relationships between
attributes(helps in determining synonyms and the strength of their relationships)
To determine the total set of objects and their relationships.◦ In this step, some kind of algorithm is applied to find the clusters and the items to
be assigned to the clusters.
There are 3 different methods.◦ They are
Complete Term Relation Method Obtain similarity between every pair of words – Uses Vector Model.
Clustering using Existing Clusters. One Pass Assignment.

Clusters are formed on the basis of similarity between every pair of terms.
The Vector model can be used. It is indicated in the form of a matrix.
The rows of matrix represents individual items and the columns of the matrix represents unique words or processing tokens.
The values of the matrix would represent how strongly a particular word would represent the concept in the item.
There should be a measure to calculate the similarity between two terms.
Term1 Term2 Term3
Item1 0 4 0
Item 2 3 1 4
Item 3 3 0 0



The final step in creating clusters is to determine when two objects (words) are in the same cluster. There are many different algorithms available.
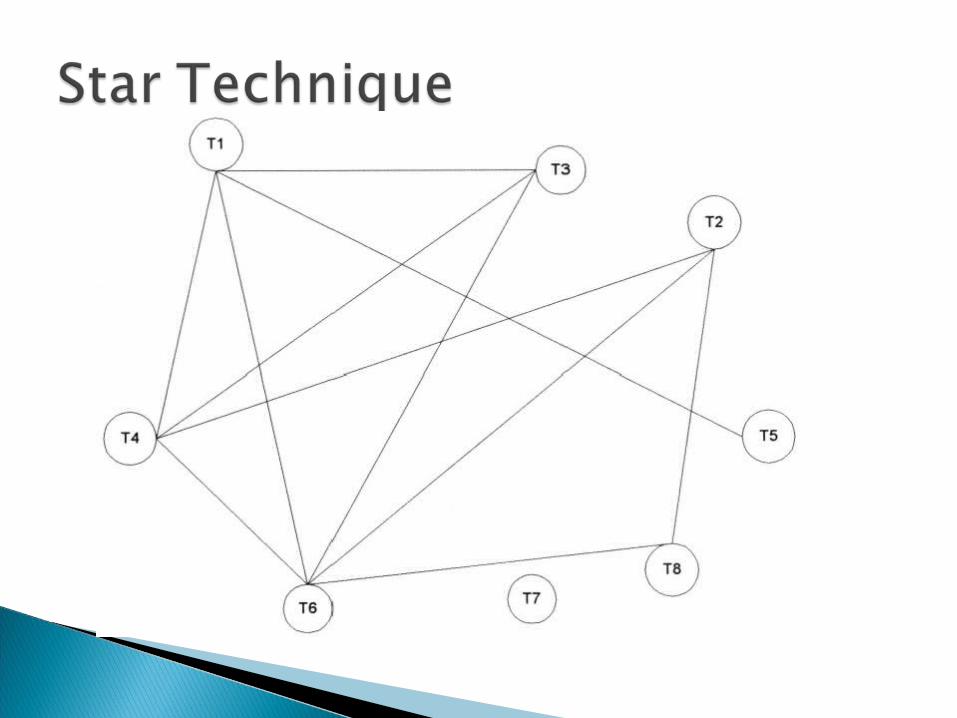
The following algorithms are the most common:◦ cliques, ◦ single link,◦ stars and◦ connected component



1. Select a term that is not in a class and place it in a new class 2. Place in that class all otherterms that are related to it 3. For each term entered into the class, perform step 2 4. When no new terms can be identified in step 2, go to step 1. Applying the algorithm for creating clusters using single link to
the Term Relationship Matrix, Figure 6.4, the following classes are
created:Class 1 (Term 1, Term 3, Term 4, Term 5, Term 6, Term 2, Term8)
Class 2 (Term 7)

Analytical strategy (mostly querying)◦ Analyze the attributes of the information need and
of the problem domain (mental model)
Browsing◦ Follow leads by association (not much planning)
Known site strategy◦ Based on previous searches◦ Indexes or starting points for browsing
Similarity strategy◦ “more like this”

Reading and interpreting
Annotating or summarizing
Analysis◦ Finding trends◦ Making comparisons◦ Aggregating information◦ Identifying a critical subset

General◦ Easy to learn (“walk up and use”)
Intuitive Standardized look-and-feel and functionality
◦ Simple and easy to use◦ Deterministic and restrictive
Specialized◦ Complex, require training (course, tutorial)◦ Increased functionality◦ Customizable, non-deterministic

Boolean vs. free text
Structure analysis vs. bag of words
Phrases / proximity
Faceted / weighted queries (TileBars, FilmFinder)
Graphical support (Venn diagrams, filters)
Support for query formulation (aid-word list, thesauri, spell-checking)

Interaction Styles ◦ Command Language◦ Form Fillin◦ Menu Selection◦ Direct Manipulation◦ Natural Language
Example:◦ How do each apply to Boolean Queries





Interfaces should ◦ give hints about the roles terms play in the collection◦ give hints about what will happen if various terms are
combined◦ show explicitly why documents are retrieved in
response to the query◦ summarize compactly the subset of interest

An old standard, ignored by internet search engines◦ used in some intranet engines, e.g., Cha-Cha


Collection of documents
Real world
Document representations Query
Information need
Anomalous state of knowledge
Matching
Results


















