
Cloud malfunction up11
25
Copyright © 2010 Accenture All Rights Reserved. Accenture, its logo, and High Performance Delivered are trademarks of Accenture. Lessons from a Cloud Malfunction An Analysis of a Global System Failure Alex Maclinovsky – Architecture Innovation 12.09.2011
-
Upload
alex-maclinovsky -
Category
Documents
-
view
241 -
download
0
Transcript of Cloud malfunction up11

Copyright © 2010 Accenture All Rights Reserved. Accenture, its logo, and High Performance Delivered are trademarks of Accentu re.
Lessons from a Cloud Malfunction An Analysis of a Global System Failure
Alex Maclinovsky – Architecture Innovation
12.09.2011

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
Introduction
For most of this presentation we will discuss a global
outage of Skype that took place around December
22nd 2010. But this story is not about Skype. It is
about building dependable internet-scale systems
and will be based on Skype case because there are
many similarities among complex distributed
systems, and often certain failure mechanisms
manifest themselves again and again.
Disclaimer: this analysis is not based on insider knowledge: I
relied solely on CIO’s blog, my observations during the event,
and experience in running similar systems.
2

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
Approximate Skype Outage Timeline
3
Weeks
before
incident
A buggy version of windows client released
Bug identified, fixed, new version released
0 min. Cluster of support servers responsible for offline instant
messaging became overloaded and failed
+30 min. Buggy clients receive delayed messages and begin to crash -
20% of total
+1 hour 30% of the publicly available super-nodes down, traffic surges
+2 hours Orphaned clients crowd surviving super-nodes, latter self destruct
+3 hours Cloud disintegrates
+6 hours Skype introduces recovery super-nodes, recovery starts
+12 hours Recovery slow, resources cannibalized to introduce more nodes
+24 hours Cloud recovery complete
+48 hours Cloud stable, resources released
+72 hours Sacrificed capabilities restored

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
Eleven Lessons
1. Pervasive Monitoring
2. Early warning systems
3. Graceful degradation
4. Contagious failure awareness
5. Design for failures
6. Fail-fast and exponential back-off
7. Scalable and fault-tolerant control plane
8. Fault injection testing
9. Meaningful failure messages
10. Efficient, timely and honest communication to the end users
11. Separate command, control and recovery infrastructure
4

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
1 - Pervasive Monitoring
It looks like Skype either did not have sufficient monitoring in place or
their monitoring was not actionable (there were no alarms triggered when
the system started behaving abnormally).
• Instrument everything
• Collect, aggregate and store telemetry
• Make results available in (near)real time
• Constantly monitor against normal operational boundaries
• Detect trends
• Generate events, raise alerts, trigger recovery actions
• Go beyond averages (tp90, tp99, tp999)
5

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
2 - Early warning systems
Build mechanisms that predict that a problem is
approaching via trend analysis and cultivation:
• Monitor trends
• Use “canaries”
• Use PID controllers
• Look for unusual
deviations between
correlated values Skype did not detect that the support cluster is approaching the tip-over point
6
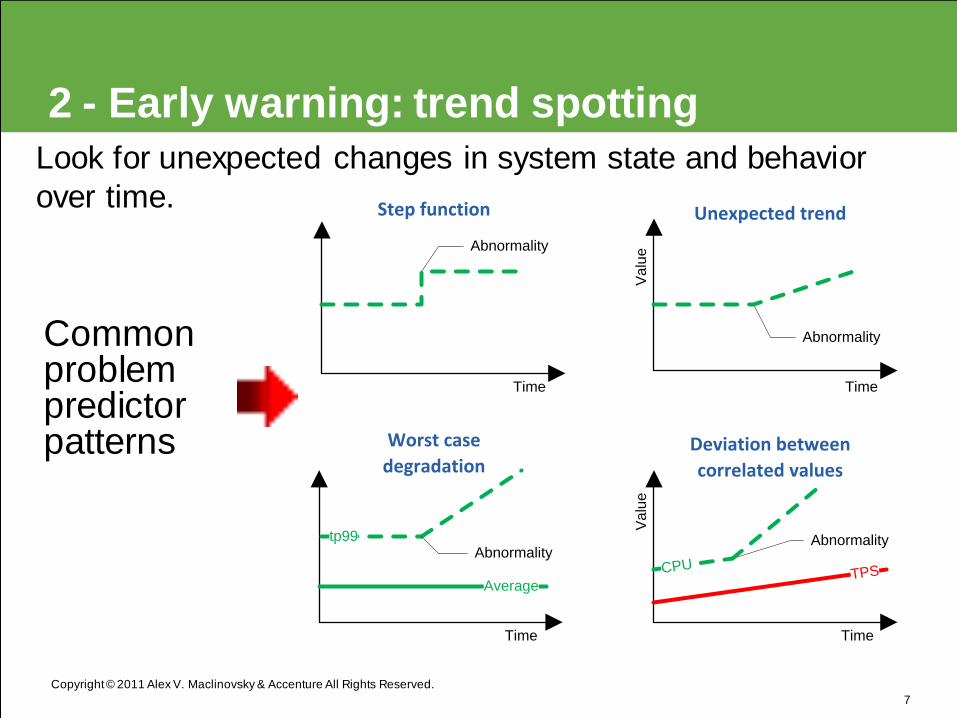
Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
2 - Early warning: trend spotting
Look for unexpected changes in system state and behavior
over time.
7
Time Time
Va
lue
Time TimeV
alu
e
Abnormality
Abnormality
Step function Unexpected trend
Average
tp99
TPSCPUAbnormality
Abnormality
Worst case
degradation Deviation between
correlated values
Common problem predictor patterns

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
3 - Graceful degradation
Graceful degradation occurs when in response to non-
normative operating conditions (e.g. overload, resource
exhaustion, failure of components or downstream
dependencies, etc.) system continues to operate, but provides
a reduced level of service rather than suffering a catastrophic
degradation (failing completely). It should be viewed as a
complementary mechanism to fault tolerance in the design of
highly available distributed systems.
8
Overload protection, such as load shedding or throttling, would have caused this event to fizzle out as a minor QoS violation which most Skype’s users would have never noticed.

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
3 - Graceful degradation - continued
There were two places where overload protection was missing:
9
• simple traditional throttling in the
support cluster would have kept it
from failing and triggering the rest
of the event.
• Once that cluster failed, a more
sophisticated globally distributed
throttling mechanism could have
prevented the contagious failure
of the “supernodes” which was
the main reason for the global
outage.

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
4 - Contagious failure awareness
• P2P cloud outage was a classic example of positive
feedback induced contagious failure scenario
• Occurs when a failure of a component in a redundant
system increases the probability of failure of its peers that
are supposed to take over and compensate for the initial
failure.
• This mechanism is quite common and is responsible for a
number of infamous events ranging from Tu-144 crashes to
the credit default swap debacle
• Grid architectures are susceptible to
contagious failure: e.g. 2009 Gmail outage
10

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
5 - Design for failures
• Since failures are inevitable, dependable
systems need to follow the principles of
Recovery-Oriented Computing (ROC), by
aiming at recovery from failures rather
than failure-avoidance.
• Use built-in auto-recovery:
restart reboot reimage replace
• Root issue was client version-specific, and they
should have assumed it:
– check if there is a newer version and upgrade
– downgrade to select earlier versions flagged as “safe”.
11
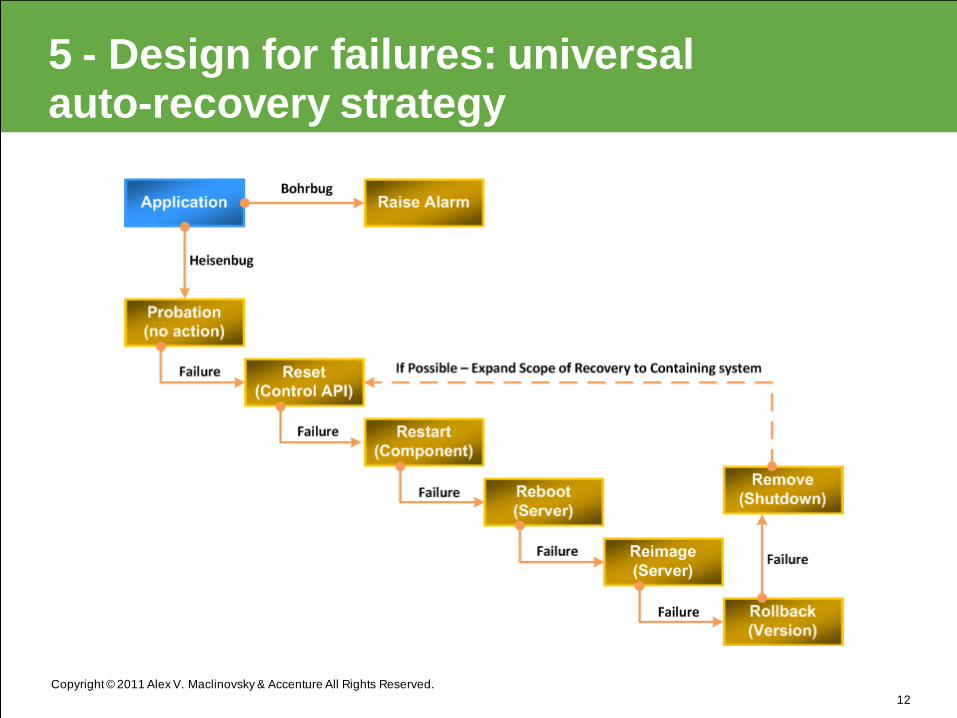
Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
5 - Design for failures: universal auto-recovery strategy
12

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
6 - Fail-fast and exponential back-off
• Vitally important in highly distributed systems
to avoid self-inflicted distributed denial of
service (DDoS) attacks similar to the one
which decimated the supernodes
• Since there were humans in the chain, the
back-off state should have been sticky:
persisted somewhere to prevent circumvention
by constantly restarting of the client
• When building a system where the same
request might be retried by different agents, it
is important to implement persistent global
back-off to make sure that no operations are
retried more frequently that permitted.
13

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
7 - Scalable fault-tolerant control plane
• Build a 23-million-way Big Red Button - ability to
instantly control the "Flash Crowd".
• Most distributed systems focus on scaling the data
plane and assume control plane is insignificant
• Skype’s control plane for the client relied on relay
by the supernodes and was effectively disabled
when the cloud disintegrated
– Backing it up with a simple
RSS-style command feed would
have made it possible to control
the cloud even in dissipated state.
14

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
8 - Fault injection testing
• Skype's problem originated and became critical in
the parts of the system that were dealing with
failures of other components.
• This is very typical – often 50% of the code and
overall complexity is dedicated to fault handling.
• This code is extremely difficult to test outside
rudimentary white-box unit tests, so in most cases
it remains untested.
– Almost never regression tested, making it the most stale
and least reliable part of the system
– Is invoked when the system is experiencing problems 15

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
8 - Fault injection testing framework
• Requires an on-demand fault injection framework.
• Framework intercepts and controls all
communications between components and layers.
• Exposes API to simulate all conceivable kinds of
failures:
– total and intermittent component outages
– communication failures
– SLA violations
16

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
9 - Meaningful failure messages
• Throughout the event, both the client and central
site were reporting assorted problems that were
often unrelated to what was actually happening:
– e.g. at some point my Skype client complained that my
credentials were incorrect
• Leverage crowdsourcing:
– clear and relevant error messages
– easy ways for users to report problems
– real-time aggregation
– secondary monitoring and alerting network
17

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
10 - Communication to the end users
• Efficient, timely and honest communication to the
end users is the only way to run Dependable
Systems
• Dedicated Status site for humans
• Status APIs and Feeds
18

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
11 - Separate command, control and recovery infrastructure
• Have a physically separate and logically
independent emergency command, control and
recovery infrastructure
• Catalog technologies, systems and dependencies
used to detect faults, build, deploy and (re)start
applications, communicate status
• Avoid circular dependencies
• Use separate implementations or old stable
versions
19
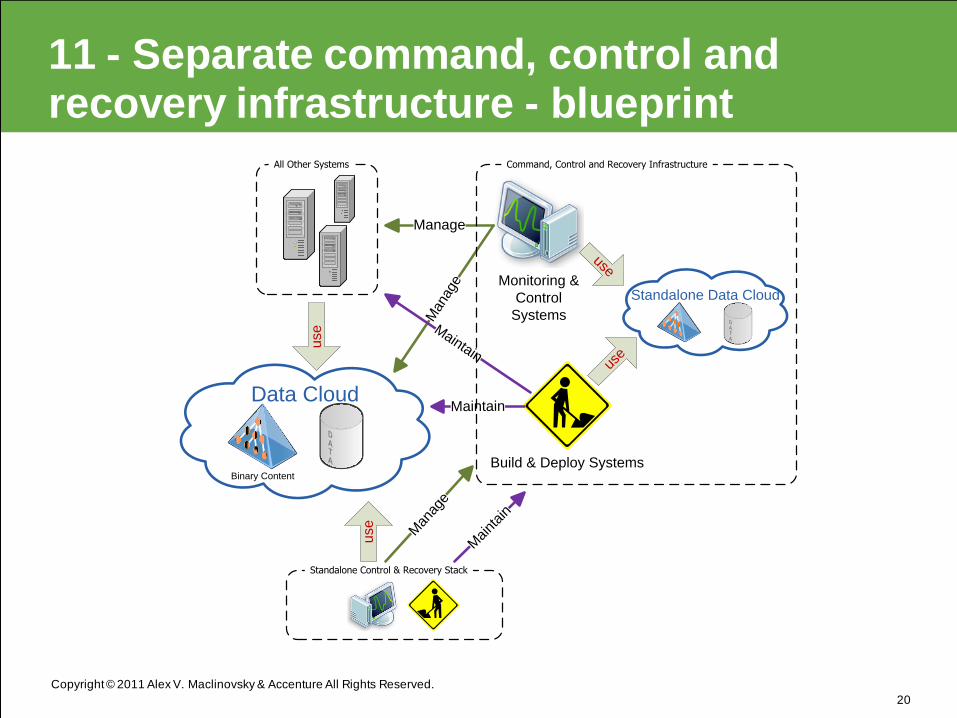
Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
11 - Separate command, control and recovery infrastructure - blueprint
20
Monitoring &
Control
Systems
Data Cloud
Binary Content
use
Manage
Man
age
Build & Deploy Systems
Maintain
Maintain
Standalone Data Cloud
use
use
Standalone Control & Recovery Stack
Man
age
Maint
ain
use
All Other Systems Command, Control and Recovery Infrastructure

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
Cloud Outage Redux
On April 21st 2011 operator error during
maintenance caused an outage of the Amazon
Elastic Block Store (“EBS”) Service, which in turn
brought down parts of the Amazon Elastic Compute
Cloud (“EC2”) and Amazon Relational Database
Service (RDS) Services. The outage lasted 54 hours
and data recovery took several more
days and 0.07% of the EBS volumes
were lost.
The outage affected over 100 sites, including big
names like Reddit, Foursquare and Moby
21

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
EC2 Outage Sequence
22
• An operator error occurs during routine
maintenance operation
• Production traffic routed into low capacity
backup network
• Split brain occurs
• When network is restored, system enters
“re-mirroring storm”
• EBS control plane overwhelmed
• Dependent services start failing

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
Applicable Lessons
1. Pervasive Monitoring
2. Early warning systems
3. Graceful degradation
4. Contagious failure awareness
5. Design for failures
6. Fail-fast and exponential back-off
7. Scalable and fault-tolerant control plane
8. Fault injection testing
9. Meaningful failure messages
10. Efficient, timely and honest communication to the end users
11. Separate command, control and recovery infrastructure
23

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
Further Reading and contact Information
Skype Outage Postmortem - http://blogs.skype.com/en/2010/12/cio_update.html
Amazon Outage Postmortem - http://aws.amazon.com/message/65648/
Recovery-Oriented Computing - http://roc.cs.berkeley.edu/roc_overview.html
Designing and Deploying Internet-Scale Services, James Hamilton - http://mvdirona.com/jrh/talksAndPapers/JamesRH_Lisa_DesigningServices.pptx
Design Patterns for Graceful Degradation, Titos Saridakis - http://www.springerlink.com/content/m7452413022t53w1/
Alex Maclinovsky blogs at http://randomfour.com/blog/
and can be reached via:
24

Copyright © 2011 Alex V. Maclinovsky & Accenture All Rights Reserved.
Questions & Answers


















