Hadoop Operations Powered By ... Hadoop (Hadoop Summit 2014 Amsterdam)
Upload
alaina-boydCategory
view
213download
0
Cloud Distributed Computing Environment
Content of this lecture is primarily from the book “Hadoop, The Definite
Guide 2/e)

• Hadoop is an open-source software system that provides a distributed computing environment on cloud (data centers)
• It is a state-of-the-art environment for Big Data Computing
• It contains two key services: - reliable data storage using the Hadoop Distributed
File System (HDFS) - distributed data processing using a technique
called MapReduce.

History of Hadoop
• Hadoop was created by Doug Cutting, the creator of Apache Lucence, the widely used text search library.
• Hadoop has its origins in Apache Nutch, an open source web search engine.

• In 2004, Google published the paper that introduce MapReduce to the world.
• Early in 2005, the Nutch developers had a working MapReduce implementation in Nutch, and by the middle of that year, all the major Nutch algorithms had been ported to run using MapReduce and NDFS

• In Februray 2006, NDFS and the MapReduce moved out of Nutch to form an independent subproject of Lucene called Hadoop
• At around the same time, Doug Cutting joined Yahoo!, which provided dedicated team and the resources to turn Hadoop into a system that ran at web scale.
• In February 2008, Yahoo! Announced that its production search index was being generated by 10,000-core Hadoop cluster

• In January 2008, Hadoop was made its own top-level project at Apache, confirmming its success and its diverse, active community
• By the same time, Hadoop has been used by many companies besides Yahoo!, such as Last.fm, Facebook, and the New York Times.
• In April 2008, Hadoop broke a world record to become the fastest system to sort terabyte of data
• In November 2009, Google reported that its MapReduce implmentation sorted one terabyte in 68 seconds.

Introduction
• HDFS is a filesystem designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware.
- Very large file: some hadoop clusters stores petabytes of data.
- Streaming data access: HDFS is built around the idea that the most efficient data processing pattern is a write-once, read-many-times pattern.
- Commodity hardware: Hadoop doesn’t require expensive, highly reliable harware to run on. It is designed to run on clusters of commodity hardware.

Basic Concepts
• Blocks - Files in HDFS are broken into block-sized
chunks. Each chunk is stored in an independent unit.
- By default, the size of each block is 64 MB.

- Some benefits of splitting files into blocks. -- a file can be larger than any single disk in
the network.
-- Blocks fit well with replication for providing fault tolerance and availability. To insure against corrupted blocks and disk/machine failure, each block is replicated to a small number of physically separate machines.

• Namenodes and Datanodes - The namenode manages the filesystem namespace. -- It maintains the filesystem tree and the metadata
for all the files and directories. -- It also contains the information on the locations of
blocks for a given file. - datanodes: stores blocks of files. They report back to
the namenodes periodically

The Command-Line InterfaceCopy a file from local filesystem to HDFS.
Copy a file from HDFS to local filesystem.
Compare these two local files


Hadoop FileSystems
• The Java abstract class org.apache.hadoop.fs.FileSystem represents a filesystem in Hadoop. There are
several concrete implementation of this abstract class. HDFS is one of them.


HDFS Java Interface
• How to read data from HDFS in Java programs• How to write data to HDFS in Java programs

• Reading data using the FileSystem API


• Writing data

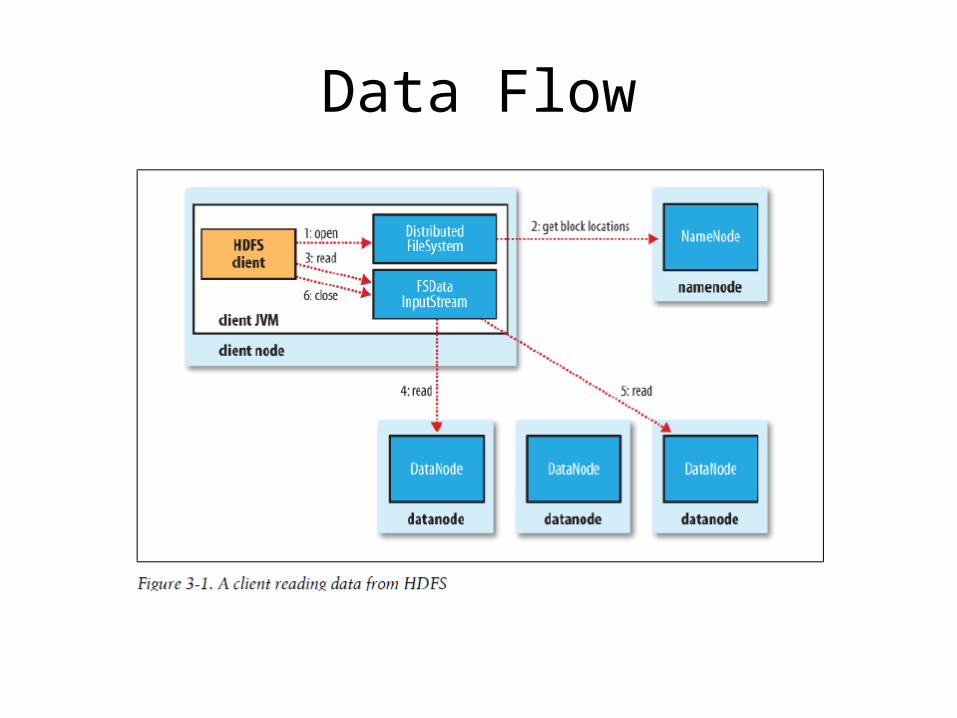
Data Flow